Ultra High Speed Message Parsing with msgspec



Episode Deep Dive
Guests
Jim Crist-Harif is an experienced engineering manager and Python developer currently working at Voltron Data on the IBIS project. With a strong background in the PyData ecosystem and contributions to open-source projects like Dask, Jim brings deep insights into high-performance data processing and serialization frameworks. You can learn more about Jim on his website, GitHub, and Mastodon.
Key Takeaways
1. Versatile and Efficient Data Serialization
msgspec provides a versatile and efficient solution for data serialization and validation, making it an excellent tool for Python developers seeking speed and flexibility in their applications.
- msgspec: A high-performance data modeling and validation framework for Python.
- Supported Formats: JSON, MessagePack, YAML, and TOML.
- Purpose: Designed as a faster alternative to Pydantic and dataclasses.
2. Superior Performance Benchmarks
- msgspec's decoding is significantly faster than ORJSON and the standard library's JSON module, boasting up to 150x faster performance compared to Pydantic V1 and 10-20x faster than Pydantic V2.
- Efficiency: Zero-cost schema validation without runtime overhead.
3. Struct Types for Low Memory Usage
- Struct Types: Slot classes implemented as C extensions, offering low memory usage and high-speed attribute access.
- Benefits: More efficient than standard Python classes and dataclasses, enabling faster serialization and deserialization.
- Links
4. Robust Schema Validation and Evolution
- Schema Validation: Ensures data integrity during serialization and deserialization.
- Schema Evolution: Supports forward and backward compatibility, allowing different versions of clients and servers to communicate seamlessly.
- Links
5. Flexible Function-Based API
- Function-Based API: Uses functions for encoding and decoding, enhancing flexibility and parity across different types.
- Usage Example:
msgspec.JSON.decode(data, type=list[Interaction])
- Links
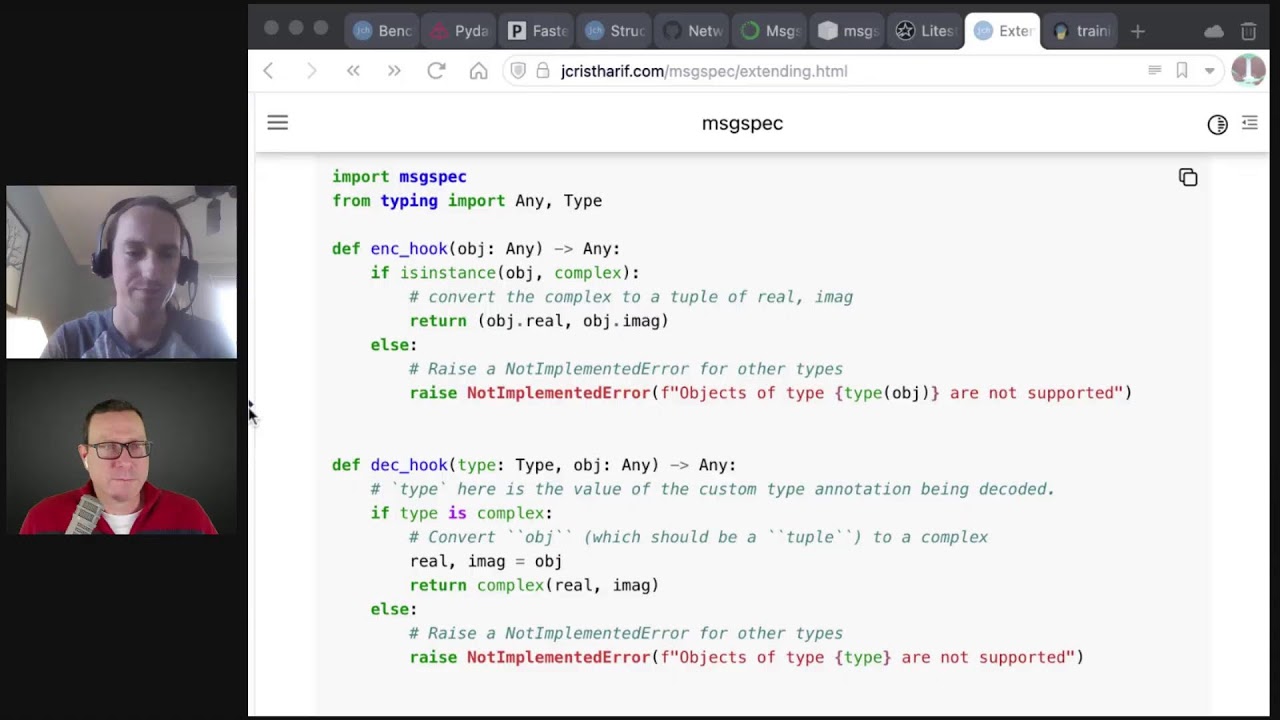
6. Custom Type Extensions
- Extensibility: Add encode and decode hooks for custom types, enabling seamless serialization of user-defined data structures.
- Examples: Complex numbers, MongoDB ObjectIDs.
- Links
7. Advanced Garbage Collection Optimizations
- Optimizations: Allows certain struct types to disable garbage collection, reducing memory overhead and improving performance in high-throughput scenarios.
- Benefits: Efficient memory management and reduced GC pauses, essential for distributed systems and in-memory data processing.
Links
8. Seamless Integration with Web Frameworks
- Compatibility: Works with modern Python web frameworks like Litestar.
- API Performance: Enhances API performance through efficient serialization.
- Example: Integration with Litestar discussed in the Litestar Episode.
9. Post-Init Methods for Enhanced Data Integrity
- Post-Init Methods: Allow additional processing after deserialization to enforce complex constraints and ensure data integrity.
- Usage: Implement custom validations without overriding the generated initializer.
Links
10. Active Development and Community Support
- Roadmap: Plans to enhance type validation features and expand capabilities.
- Community: Open to contributions and actively evolving to meet the needs of the Python community.
- Maintenance: Seeking maintainers as the project grows to ensure long-term sustainability.
- Links
Quotes and Stories
On the Purpose of msgspec:
"The goal was to replicate more of the experience writing Rust or Go, where the serializer stands in the background rather than the base model standing in the foreground."
On Struct Implementation:
"Everything in msgspec is implemented fully as a C extension. Getting these to work required reading a lot of the CPython source code because we're doing some things that I don't want to say that they don't want you to do."
On Benchmarking:
"Our JSON parser in msgspec is one of the fastest in Python, depending on your message structure and how you're invoking it."
Overall Takeaway
msgspec offers Python developers and data scientists a robust, high-performance alternative for data modeling and validation. By leveraging C extensions and innovative struct types, msgspec not only accelerates serialization processes but also ensures efficient memory usage and seamless schema evolution. Whether you're building APIs, working with distributed systems, or handling large volumes of data, msgspec provides the tools to enhance your Python applications' performance and maintainability. Embracing msgspec can lead to cleaner, faster, and more reliable code, making it a valuable addition to any Python toolkit.
Links from the show
Jim @ GitHub: github.com
Jim @ Mastdon: @jcristharif@hachyderm.io
msgspec: github.com
Projects using msgspec: github.com
msgspec on Conda Forge: anaconda.org
msgspec on PyPI: pypi.org
Litestar web framework: litestar.dev
Litestar episode: talkpython.fm
Pydantic V2 episode: talkpython.fm
JSON parsing with msgspec article: pythonspeed.com
msgspec bencharmks: jcristharif.com
msgspec vs. pydantic v1 and pydantic v2: github.com
Watch this episode on YouTube: youtube.com
Episode #442 deep-dive: talkpython.fm/442
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 If you're a fan of Pydantic or data classes, you'll definitely be interested in this episode.
00:04 We are talking about a super fast data modeling and validation framework called msgspec.
00:09 And some of the types in here might even be better for general purpose use than Python's
00:15 native classes.
00:15 Join me and Jim, Chris Hariff, to talk about his framework, msgspec.
00:19 This is Talk Python To Me, episode 442, recorded November 2nd, 2023.
00:25 Welcome to Talk Python To Me, a weekly podcast on Python.
00:43 This is your host, Michael Kennedy.
00:44 Follow me on Mastodon, where I'm @mkennedy, and follow the podcast using @talkpython,
00:49 both on fosstodon.org.
00:52 Keep up with the show and listen to over seven years of past episodes at talkpython.fm.
00:57 We've started streaming most of our episodes live on YouTube.
01:01 Subscribe to our YouTube channel over at talkpython.fm/youtube to get notified about upcoming
01:06 shows and be part of that episode.
01:08 This episode is sponsored by Posit Connect from the makers of Shiny.
01:14 Publish, share, and deploy all of your data projects that you're creating using Python.
01:19 Streamlit, Dash, Shiny, Bokeh, FastAPI, Flask, Reports, Dashboards, and APIs.
01:24 Posit Connect supports all of them.
01:27 Try Posit Connect for free by going to talkpython.fm/posit, P-O-S-I-T.
01:32 And it's brought to you by us over at Talk Python Training.
01:36 Did you know that we have over 250 hours of Python courses?
01:41 Yeah, that's right.
01:42 Check him out at talkpython.fm/courses.
01:45 Jim.
01:48 Hello.
01:48 Hello.
01:48 Welcome to Talk Python.
01:49 It's awesome to have you here.
01:50 Yeah.
01:51 Thanks for having me.
01:51 Yeah, of course.
01:52 I spoke to the Litestar guys, you know, at Litestar.dev and had them on the show.
01:57 And I was talking about their DTOs, different types of objects they can pass around in their
02:03 APIs and their web apps.
02:04 And like FastAPI, they've got this concept where you kind of bind a type, like a class
02:09 or something, to an input, to a web API.
02:12 And it does all that sort of magic like FastAPI.
02:15 And I said, oh, so you guys probably work with PyDanty.
02:17 It's like, yes, but let me tell you about msgspec.
02:19 Because that's where the action is.
02:21 They were so enamored with your project that I just had to reach out and have you on.
02:25 It looks super cool.
02:26 I think people are going to really enjoy learning about it.
02:28 Thanks.
02:29 Yeah, it's nice to hear that.
02:30 Yeah.
02:31 We're going to dive into the details.
02:33 It's going to be a lot of fun.
02:33 Before we get to them, though, give us just a quick introduction on who you are.
02:37 So people don't know you yet.
02:39 So my name is Jim Christreif.
02:41 I am currently an engineering manager doing actually mostly dev work at Voltron Data, working
02:47 on the IBIS project, which is a completely different conversation than what we're going to have today.
02:51 Prior to that, I popped around a couple of startups and was most of them doing Dask was the main
02:58 thing I've contributed to in the past on an open source Python front.
03:01 For those not aware, Dask is a distributed compute ecosystem.
03:04 I come from the PyData side of the Python ecosystem, not the web dev side.
03:09 Nice.
03:09 Yeah, I've had Matthew Rocklin on a couple of times, but it's been a while, so people don't
03:13 necessarily know.
03:13 But it's like super distributed pandas, kind of.
03:18 Grid computing for pandas, sort of.
03:20 Or say like Spark written in Python.
03:22 Sure.
03:23 You know, another thing that's been on, kind of on my radar, but I didn't really necessarily
03:27 realize it was associated with you.
03:29 Tell people just a bit about IBIS.
03:31 Like IBIS is looking pretty interesting.
03:33 IBIS is, I don't want to say the wrong thing.
03:35 IBIS is a portable data frame library is the current tagline we're using.
03:39 If you're coming from R, it's dplyr for Python.
03:42 It's more than that.
03:43 And it's not exactly that, but that's a quick mental model.
03:46 So you write data frame like code.
03:49 We're not pandas compatible.
03:50 We're pandas like enough that you might find something familiar.
03:53 And it can compile down to generate SQL for 18 plus different database backends.
03:58 Also like PySpark and a couple other things.
04:01 Okay.
04:01 So you write your code once and you kind of run it on whatever.
04:03 I see.
04:03 And you do pandas like things, but it converts those into database queries.
04:08 Is that?
04:08 Yeah.
04:09 Yeah.
04:09 So it's a data frame API.
04:10 It's not pandas compatible, but if you're familiar with pandas, you should be able to pick it up.
04:16 You know, we cleaned up what we thought as a bunch of rough edges of the pandas API.
04:19 Yeah.
04:19 Were those pandas one or pandas two rough edges?
04:22 Both.
04:22 It's, I don't know.
04:23 It's pandas like.
04:25 Sure.
04:25 Yeah.
04:26 This looks really cool.
04:27 That's a topic for another day, but awesome.
04:29 People can check that out.
04:30 But this time you're here to talk about your personal project, msgspec.
04:37 Am I saying that right?
04:38 Or you say MSG or msgspec?
04:40 Message spec is how it is.
04:42 I think a lot of these projects sometimes need a little, like here's the MP3 you can press play on.
04:48 Like how it's meant to be said, you know?
04:50 I mean, sometimes it's kind of obvious, like PyPI versus PyPI.
04:55 Other times it's just like, okay, I know you have a really clever name.
04:58 Yes, I know.
04:59 People say NumPy all the time.
05:01 I'm like, I don't want to, I try to not correct guests because it's, it's not kind.
05:05 But I also feel awkward.
05:06 They will say NumPy and I'll say, how do you feel about NumPy?
05:08 Like NumPy's great.
05:09 I'm like, okay, we're just going back and forth like this for the next hour.
05:12 It's fine.
05:12 But yeah, it's, it's always, I think some of these could use a little, like a little play.
05:17 So msgspec.
05:18 Tell people about what it is.
05:19 Yeah.
05:20 So gone through a couple of different taglines.
05:22 The current one is a fast serialization and validation library with a built-in support for
05:26 JSON, message pack, YAML, and TOML.
05:29 If you are familiar with Pydantic, that's probably one of the closest, you know, most popular libraries
05:34 that does a similar thing.
05:35 You define kind of a structure of your data using type annotations and msgspec will parse
05:40 your data to ensure it is that structure and does so efficiently.
05:44 It's also compatible with a lot of the other serialization libraries.
05:48 You could also use it as a stand-in for JSON, you know, with the JSON dumps, JSON loads.
05:53 You don't need to specify the types.
05:55 Right.
05:55 It's, I think the mental model of kind of like, it swims in the same water or the same pond
06:01 as Pydantic, but it's also fairly distinguished from Pydantic, right?
06:06 As we're going to explore throughout our chat here.
06:09 The goal from my side, one of the goals was to replicate more of the experience writing
06:14 Rust or Go with Rust-SERDE or Go's JSON, where the serializer kind of stands in the background
06:19 rather than my experience working with Pydantic, where it felt like the base model kind of stood
06:24 in the foreground.
06:25 You're defining the model.
06:27 Serialization kind of comes onto the types you've defined, but you're not actually working
06:30 with the serializers on the types themselves.
06:32 Got it.
06:32 So an example, let me see if I do have it.
06:35 An example might be if I want to take some message I got from, some response I got from
06:41 an API, I want to turn it into a Pydantic model or I'm writing an API.
06:44 I want to take something from a client, whatever.
06:46 I'll go and create a Pydantic class.
06:48 And then the way I use it is I go to that class and I'll say star, star, dictionary I got.
06:55 And then it comes to life like that, right?
06:57 Where there's a little more focus on just the serialization and it has this capability.
07:03 But like you said, it's optional in the sense.
07:06 Yeah.
07:06 In msgspec, all types are on equal footing.
07:11 So we use functions, not methods, because if you want to decode into a list of ints, I
07:17 can't add a method to a list.
07:18 You know, it's a Python built-in type.
07:20 Yeah.
07:20 So you'd say msgspec dot JSON dot decode your message and then you'd specify the type
07:26 annotation as part of that function call.
07:29 So it could be, you know, list bracket int.
07:31 Right.
07:31 So you'll say decode and then you might say type equals list of your type or like you
07:37 say, list of int.
07:37 And that's hard when you have to have a class that knows how to basically become what the
07:42 model, the data passed in is, even if it's just a list, some Pydantic classes, you got
07:48 to kind of jump through some hoops to say, hey, Pydantic, I don't have a thing to give
07:52 you.
07:52 I want a list of those things.
07:54 And that's the top level thing is, you know, bracket bracket.
07:56 It's not, it's not any one thing I can specify in Python easily.
08:00 Yeah.
08:00 To be fair to the Pydantic project, I believe in V2, the type adapter.
08:04 Yes, exactly.
08:05 Object can work with that.
08:06 But that is, you know, it's a different way of working with it.
08:09 I wanted to have one API that did it all.
08:12 Sure.
08:12 And it's awesome.
08:13 They made it.
08:13 I mean, I want to just put this out front.
08:15 Like, I'm a massive fan of Pydantic.
08:17 What Samuel's done there is incredible.
08:19 And it's just, it's really made a big difference in the way that people work with data and Python.
08:24 It's awesome.
08:25 But it's also awesome that you have this project that is an alternative and it makes different assumptions.
08:29 And you can see those really play out in like the performance or the APIs.
08:33 So, you know, like Pydantic encourages you to take your classes and then send them the data.
08:39 But you've kind of got to know, like, oh, there's this type adapter thing that I can give a list of my class and then make it work.
08:45 Right.
08:45 But it's not just, oh, you just fall into that by trying to play with the API, you know?
08:50 Yeah.
08:51 Yeah.
08:51 And I think having, being able to specify any type means we work with standard library data classes.
08:56 The same as we work with our built-in struct type or we also work with attrs types.
09:00 You know, everything is kind of on equal footing.
09:02 Yeah.
09:02 And what I want to really dig into is your custom struct type that has some really cool properties.
09:10 Not class properties, but components.
09:11 Features of the class of the type there.
09:14 Yeah.
09:14 Let's look at a couple of things here.
09:16 So, as you said, it's fast and I love how somehow italicies on the word fast makes it feel even faster.
09:23 Like it's leaning forward, you know, it's leaning into the speed.
09:26 A fast serialization and validation library.
09:28 The validation is kind of can be, but not required, right?
09:32 The types can be, but they don't have to be.
09:34 So, I think that's one of the ways it really differs from Pydantic.
09:37 But the other is Pydantic is quite focused on JSON, whereas this is JSON, message pack, YAML, and TOML.
09:45 Everyone knows what JSON is.
09:47 I always thought of TOML as kind of like YAML.
09:49 Are they really different?
09:51 It's another configuration focused language.
09:54 I think some people do JSON for config files, but I personally don't like to handwrite JSON.
09:59 YAML and TOML are like more human friendly, in quotes, forms of that.
10:04 YAML is a superset of JSON.
10:06 TOML is its own thing.
10:08 Got it.
10:08 And then message pack is a binary JSON-like file format.
10:12 Yeah, message pack.
10:13 I don't know how many people work with that.
10:15 Where would people run into message pack?
10:16 Yeah.
10:17 If they were, say, consuming an API, or what API framework would people be generating message
10:22 pack in Python, typically?
10:23 That's a good question.
10:24 So, going back to the creation of this project, actually, msgspec sounds a lot like message
10:29 pack.
10:30 And that was intentional.
10:30 It does, yeah.
10:31 Because that's what I wrote it for originally.
10:33 So, as I said at the beginning, I'm one of the original contributors to Dask.
10:37 Worked on Dask forever.
10:38 And the Dask distributed scheduler uses message pack for its RPC serialization layer.
10:43 That kind of fell out of what was available at the time.
10:46 We benchmarked a bunch of different libraries.
10:48 And that was the fastest way to send bytes between nodes in 2015.
10:52 Sure.
10:53 The distributed scheduler's RPC framework has kind of grown haphazardly over time.
10:58 And there were a bunch of bugs due to some hacky things we were doing with it.
11:01 And also, it was slower than we would have wanted.
11:03 So, this was an attempt to write a faster message pack library for Python that also did
11:09 fancier things.
11:10 Supported more types.
11:11 Did some schema validation because we wanted to catch the worker is sending this data and
11:16 the scheduler is getting it and saying it's wrong.
11:18 And we wanted to also add in a way to make schema evolution, meaning that I can have different
11:25 versions of my worker and scheduler and client process and things kind of work.
11:28 If I add new features to the scheduler, they don't break the client.
11:33 You know, we have a nice forward and backward compatibility story.
11:36 And so, that's what kind of fell out.
11:38 Yeah, it's a really nice feature.
11:39 We're going to dive into that.
11:40 But, you know, you might think, oh, well, just update your client or update the server.
11:45 But there's all sorts of situations that get really weird.
11:47 Like, if you have Redis as a caching layer and you create a message pack object and stick
11:54 it in there and then you deploy a new version of the app, it could maybe can't,
11:58 deserialize anything in the cache anymore because it says something's missing or something's
12:02 there that it doesn't expect.
12:04 Right.
12:04 And so, this evolution is important there.
12:07 If you've got long running work and you stash it into a database and you pull it back out,
12:10 like all these things where it kind of lives a little outside the process, all of a sudden
12:14 it starts to matter that before you even consider like clients that run separate code.
12:19 Right.
12:19 Like you could be the client, just different places in time.
12:22 Yeah.
12:22 Yeah.
12:23 So, adding a little bit more structure to how you define messages in a way to make the
12:26 scheduler more maintainable.
12:27 That work never landed.
12:28 It's as it is with open source projects.
12:31 It's a democracy and also a democracy.
12:33 And, you know, you don't always, paths can be done at dead ends.
12:36 I still think it'll be valuable in the future, but some stuff was changing the scheduler and
12:40 serialization is no longer the bottleneck that it was two and a half years ago when this originally
12:45 started.
12:46 So, let me put this in context for people to maybe make it relevant.
12:49 Like maybe right now someone's got a FastAPI API and they're using Pydantic and obviously
12:55 it generates all the awesome JSON they want.
12:58 Is there a way to, how would you go about creating, say, a Python server-based system set
13:06 of APIs that maybe as an option take message pack or maybe use that as a primary way?
13:11 Like it could be maybe, you know, passing an accept header.
13:14 To take message pack?
13:15 If you want to exchange message pack, client server, Python right now, what do you do?
13:19 That's a good question.
13:20 To be clear, I am not a web dev.
13:22 I do not do this for a living.
13:23 I think there is no standard application slash message pack.
13:26 I think people can use it if they want, but that's not a, it's a standardized thing the
13:31 same way that JSON is.
13:32 Yeah.
13:32 I think that Litestar as a framework does support this out of the box.
13:35 I don't know about FastAPI.
13:37 I'm sure there's a way to hack it in as there is with any ASGI server.
13:41 Yeah, Litestar, like I said, I had Litestar on those guys maybe a month ago and...
13:45 Yeah, super, super cool about that.
13:47 So, yeah, I know that they support msgspec and a lot of different options there, but,
13:52 you know, you could just, I imagine you could just return binary bits between you and your
13:57 client.
13:58 I'm thinking of like latency sensitive microservice type things sort of within your data center.
14:04 How can you lower serialization, deserialization, serialization, like all that cost that could
14:08 be the max, you know, the biggest part of what's making your app spend time and energy?
14:14 Michael out there says, would love PyArrow parquet support for large data.
14:18 There's been a request for Aero integration with msgspec.
14:22 I'm not exactly sure what that would look like.
14:24 Aero containers are pretty efficient on their own.
14:26 Breaking them out into a bunch of objects or stuff to work with msgspec doesn't necessarily
14:31 make sense in my mind.
14:32 But anyway, if you have ideas on that, please open an issue or comment on the existing issue.
14:36 Yeah, indeed.
14:37 All right.
14:38 So let's see.
14:39 Some of the highlights are high performance encoders and decoders across those protocols
14:43 we talked.
14:44 You have benchmarks.
14:45 We'll look at them for in a minute.
14:46 You have a really nice, a lot of support for different types that can go in there that
14:51 can be serialized, but there's also a way to extend it to say, I've got a custom type that
14:56 you don't think is serializable to whatever end thing, a message pack, JSON, whatever.
15:01 But I can write a little code that'll take it either way.
15:04 You know, dates are something that drive me crazy, but it could be like an object ID out
15:09 of MongoDB or other things that seem like they should go back and forth, but don't, you know,
15:13 right?
15:13 So that's really nice.
15:14 And then zero cost schema validation, right?
15:18 It validates, decodes and validates JSON two times as fast as ORJSON, which is one of
15:22 the high performance JSON decoders.
15:24 And that's just decoding, right?
15:26 And then the struct thing that we're going to talk about, which the struct type is kind
15:30 of what brings the parody with Pydantic, right?
15:33 Yeah.
15:34 You could think of it as Pydantic's base model.
15:36 It's our built-in data class-like type.
15:38 Nice.
15:38 So structs are data class-like.
15:40 Like everything in msgspec are implemented fully as a C extension.
15:45 Getting these to work required reading a lot of the CPython source code because we're doing
15:50 some things that I don't want to say that they don't want you to do.
15:54 We're not doing them wrong, but they're not really documented.
15:57 So for example, when you subclass for msgspec.struct, that's using a metaclass mechanism,
16:03 which is a way of defining types to define types.
16:06 And the metaclass is written in C, which CPython doesn't make easy to do.
16:11 So it's a C extension metaclass that creates new C types.
16:16 They're pretty speedy.
16:17 They are 10 to 100x faster for most operations than even handwriting a class that does the
16:23 same thing, but definitely more than data classes or attrs.
16:25 Yeah.
16:26 It's super interesting.
16:27 And I really want to dive into that.
16:28 I almost can see the struct type being relevant even outside of msgspec in general, potentially.
16:34 So yeah, we'll see about that.
16:36 But it's super cool.
16:37 And Michael also points out, like, he's the one who made the issue.
16:40 So sorry about that.
16:42 He's commented already, I suppose, in a sense.
16:45 But yeah, awesome.
16:46 Cool.
16:47 All right.
16:47 So let's do this.
16:49 I think probably the best way to get started is we could talk through an example.
16:53 And there's a really nice article by Itmar Turner-Trowing, who's been on the show a couple
16:59 of times, called Faster, More Memory-Efficient Python, JSON parsing with msgspec.
17:04 And just as a couple of examples that I thought maybe we could throw up.
17:06 And you could talk to, speak to your thoughts, like, why does the API work this way?
17:11 Here's the advantages and so on.
17:13 Yeah.
17:13 So there's this big, I believe this is the GitHub API, just returning these giant blobs of stuff
17:17 about users.
17:18 Okay.
17:19 And it says, well, if we want to find out what users follow what repos or how many,
17:24 given a user, how many repos do they follow, right?
17:27 We could just say, with open, read this, and then just do a JSON load.
17:31 And then do the standard dictionary stuff, right?
17:34 Like, for everything, we're going to go to the element that we got out and say, bracket some
17:38 key, bracket some key.
17:40 You know, it looks like key not found errors are just lurking in here all over the place.
17:44 But, you know, it's, you should know that maybe it'll work, right?
17:48 If you know the API, I guess.
17:49 So it's like, this is the standard way.
17:51 How much memory does this use?
17:52 How much time does it take?
17:53 Look, we can basically swap out ORJSON.
17:57 I'm not super familiar with ORJSON.
17:59 Are you?
17:59 Yeah.
18:00 ORJSON is compatible-ish with the standard lib JSON, except that it returns bytes rather
18:05 than strings.
18:06 Got it.
18:06 Okay.
18:07 There's also iJSON, I believe, which makes it streaming.
18:10 So there's that.
18:11 And then it says, okay, well, how would this look if we're going to use msgspec?
18:15 And in his example, he's using structured data.
18:19 So the structs, this is like the Pydantic version, but it doesn't have to be this way,
18:23 but it is this way, right?
18:25 This is the one he chose.
18:26 So maybe just talk us through, like, how would you solve this problem using message
18:30 spec and classes?
18:31 Yeah.
18:31 So as he's done here in this blog post, he's defined a couple struct types for the various
18:37 levels of this message.
18:38 So repos, actors, and interactions, and then parses the message directly into those types.
18:45 So the final call there is passing in the red message and then specifying the type as a list
18:51 of interactions, which are tree down into actors and repos.
18:54 Exactly.
18:55 So this is what you mentioned earlier about having more function-based.
18:58 So you just say decode, give it the string or the bytes, and you say type equals list of
19:04 bracket, top-level class.
19:06 And just like Pydantic, these can be nested.
19:09 So there's an interaction, which has an actor.
19:10 There's an actor class, which has a login, which has a type.
19:13 So your Pydantic model for how those kind of fit together is pretty straightforward, right?
19:19 Pretty similar.
19:19 Yeah.
19:20 And then you're just programming with classes.
19:21 Awesome.
19:22 Yep.
19:22 And it'll all work well with, like, mypy or Pyright or whatever you're using if you're doing
19:26 static analysis tools.
19:27 Yeah.
19:27 So you've thought about making sure that not just does it work well from a usability perspective,
19:32 but it, like, the type checkers don't go crazy.
19:35 Yeah.
19:35 And any, you know, editor integration you have should just work.
19:38 Nice.
19:39 Because there's sometimes, oh gosh, I think maybe FastAPIs changes, but you'll have things
19:45 like you would say the type of an argument being passed in, if it's, say, coming off the
19:50 query string, you would say it's depend.
19:52 It's a type depends, not an int, for example.
19:56 It's because it's being pulled out of the query string.
19:58 I think that's FastAPI.
19:59 And while it makes the runtime happy and the runtime says, oh, I see you want to get this
20:04 int from the query string, the type checkers and stuff are like, depends.
20:09 What is this?
20:09 Like, this is an int.
20:10 Why are you trying to use this depends as an int?
20:12 This doesn't make any sense.
20:13 I think it's a bit of a challenge to have the runtime, the types drive the runtime, but
20:17 still not freak it out, you know?
20:19 Yeah.
20:19 I think that the Python typing ecosystem, especially with the recent changes in new versions and
20:25 the annotated wrapper, are moving towards a system where these kinds of APIs can be spelled
20:30 natively in ways that the type checkers will understand.
20:33 But if your project that existed before these changes, you obviously had some preexisting
20:38 way to make those work that might not play as nicely.
20:41 So there's the upgrade cost of the project.
20:43 I'm not envious of the work that Samuel Covenant team have had to do to upgrade Pydantic to erase
20:49 some old warts in the API that they found.
20:50 It's nice to see what they've done and it's impressive.
20:52 But it's, I have the benefit of starting this project after those changes in typing
20:56 ecosystem existed.
20:57 You know, can look at hindsight mistakes others have made and learn from them.
21:01 Yeah, that's really excellent.
21:01 They have done, like I said, I'm a big fan of Pydantic and it took them almost a year.
21:06 I interviewed Samuel about that change and it was no joke.
21:09 You know, it was a lot of work.
21:10 But, you know, what they came up with, pretty compatible, pretty much feels like the same
21:15 Pydantic.
21:15 But, you know, if you peel back the covers, it's definitely not.
21:18 All right.
21:19 So the other interesting thing about Ipmar's article here is the performance side.
21:23 So it's okay.
21:23 Do you get fixed memory usage or does it vary based on the size of the data?
21:28 And do you get schema validation?
21:29 Right.
21:30 So standard lib, just straight JSON module, 420 milliseconds.
21:35 OR JSON, the fast one, a little less than twice as fast, 280 milliseconds.
21:39 iJSON for iterable JSON.
21:42 300, so a little more than the fast one.
21:45 Message spec, 90 milliseconds.
21:47 That's awesome.
21:48 That's like three times as fast as the better one.
21:51 Over four times as fast as the built-in one.
21:54 It also is doing, you know, quote unquote, more work.
21:56 It's validating the response as it comes in.
21:58 Exactly.
21:59 So you're sure that it's correct then too.
22:01 All those other ones are just giving you dictionaries and YOLO.
22:04 Do what you want with them, right?
22:06 But here you're actually, all those types that you described, right?
22:09 The interaction and the actors and the repos and the class structure, that's all validation.
22:13 So in on top of that, you've created classes which are heavier weight than dictionaries because
22:18 general classes are heavier weight than dictionaries because they have the dunder dict that has
22:23 all the fields in there effectively anyway, right?
22:26 That's not true for structs.
22:28 Structs are slot classes.
22:29 Yes.
22:30 Structs.
22:30 They are a lighter weight to allocate than a dictionary or a standard class.
22:34 That's one of the reasons they're faster.
22:35 Yeah.
22:35 Structs are awesome.
22:36 And so the other thing I was going to point out is, you know, you've got 40 megabytes
22:39 of memory usage versus 130.
22:41 So almost four times less than the standard module.
22:45 And the only thing that beats you is the iterative one because it literally only has one in memory
22:50 at a time, right?
22:50 One element.
22:51 Yeah.
22:52 So this benchmark is kind of hiding two things together.
22:56 So there is the output, what you're parsing.
22:59 Everything here except for iJSON is going to parse the full input into something.
23:03 One big batch.
23:04 It's more efficient than orJSON or the standard lib in this respect because we're only extracting
23:08 the fields we care about.
23:09 But you're still going to end up with a list of a bunch of objects.
23:11 iJSON is only going to pull one in a memory at a time.
23:14 So it's going to have less in memory there.
23:16 And then you have the memory usage of the parsers themselves, which can also vary.
23:21 So orJSON's memory usage in its parser is a lot higher than msgspecs, regardless
23:26 of the output size.
23:27 There's a little more internal state.
23:29 So this is a pretty interesting distinction that you're calling out here.
23:33 So for example, if people check out this article, which I'll link, there's like tons of stuff
23:39 that people don't care about in the JSON, like the avatar URL, the gravatar ID, you know,
23:45 the reference type, whether it's a brand, like this stuff that you just don't care about,
23:49 right?
23:49 But to parse it in, you got to read that.
23:51 But what's pretty cool you're saying is like, in this case, the class that Edmar came up with
23:56 is just repo driving from struct.
23:59 It just has a name.
23:59 There's a bunch of other stuff in there, but you don't care about it.
24:02 And so what you're saying is like, if you say that that's the decoder, it looks at that
24:06 and goes, there's a bunch of stuff here.
24:07 We're not loading that.
24:09 We're just going to look for the things you've explicitly asked us to model, right?
24:13 There's no sense in doing the work if you're never going to look at it.
24:16 A lot of different serialization frameworks.
24:18 I can't remember how Pydantic responds when you do this, but, you know, the comments beyond
24:23 Pydantic, so it doesn't really matter, is they'll freak out to say, oh, there's extra
24:27 stuff here.
24:28 What am I supposed, you know, for example, this repo, it just has name, but in the data model,
24:32 it has way more in the JSON data.
24:35 So you try to deserialize it.
24:37 It'll go, well, I don't have room to put all this other stuff.
24:39 Things are, you know, freak out.
24:40 And this one is just like, no, we're just going to filter down to what you asked for.
24:43 I really, it's nice in a couple of ways.
24:45 It's nice from performance, nice from clean code.
24:47 I don't have to put all those other fields I don't care about, but also from, you talked
24:51 about the evolution friendliness, right?
24:53 Because what's way more common is that things git added rather than taken away or changed.
24:59 It's like, well, the complexity grows.
25:01 Now repos also have this, you know, related repos or sub repos or whatever the heck they
25:06 have, right?
25:06 And this model here will just let you go, whatever, don't care.
25:10 Yeah.
25:10 If GitHub updates their API and adds new fields, you're not going to get an error.
25:14 And if they remove a field, you should get a nice error that says expected, you know,
25:19 field name, and now it's missing.
25:20 You can track that down a lot easier than a random key error.
25:24 I agree.
25:24 I think, okay, let's, let's dive into the struct a little bit because that's where we're
25:28 kind of on that now.
25:29 And I think this is one of the highlights of what you built.
25:32 Again, it's kind of the same mental model as people are familiar with some data classes
25:36 with Pydantic and attrs and so on.
25:39 So when I saw your numbers, I won't come back and talk about benchmarks with numbers.
25:43 But I just thought like, wow, this is fast.
25:45 And while the memory usage is low, you must be doing something native.
25:49 You must be doing something crazy in here.
25:51 That's not just Dunder slots.
25:53 While Dunder slots is awesome.
25:55 There's more to it than that, right?
25:57 And so they're written in C, quite speedy and lightweight.
26:01 So measurably faster than data classes, attrs and Pydantic.
26:04 Like, tell us about these classes.
26:06 Like, this is, this is pretty interesting.
26:07 It's mentioned earlier.
26:08 They're not exactly, but they're, they're basically slots classes.
26:11 So Python's data model, actually CPython's data model is either a class is a standard class
26:16 where it stores its attributes in a dict.
26:19 That's not exactly true.
26:20 There's been some optimizations where the keys are stored separately alongside the class structure
26:25 and all the values are stored on the object instances.
26:27 But in model, there's dict classes and there's slots classes, which you pre-declare your attributes
26:32 to be in this, this Dunder slots interval.
26:35 And those get stored in line in the same allocation as the object instance.
26:40 There's no pointer chasing.
26:41 What that means is that you can't set extra attributes on them that weren't pre-declared,
26:45 but also things are a little bit more efficient.
26:48 We create those automatically when you subclass from a struct type.
26:51 And we do a bunch of other interesting things that are stored on the type.
26:55 That is why we had to write a metaclass in C.
26:58 I went to read it.
26:59 I'm like, whoa, okay.
27:00 Maybe we'll come back to this.
27:01 There's a lot of stuff going on in that type.
27:03 One of the problems with this hobby project is that I wrote this for fun
27:07 and a little bit of work related, but mostly fun.
27:09 And it's not the easiest code base for others to step into.
27:12 It fits my mental model, not necessarily everyone's.
27:15 Yeah.
27:15 I can tell you weren't looking for VC funding because you didn't write it in Rust.
27:18 Seems to be the common denominator these days.
27:22 Yeah.
27:22 Why C?
27:23 Just because CPython's already in C?
27:25 And that's the...
27:26 And I use C.
27:27 I do know Rust, but for what I wanted to do in the use case I had in mind,
27:31 I wanted to be able to touch the C API directly.
27:34 And that felt like the easiest way to go about doing it.
27:39 This portion of Talk Python To Me is brought to you by Posit, the makers of Shiny, formerly RStudio, and especially Shiny for Python.
27:47 Let me ask you a question.
27:49 Are you building awesome things?
27:51 Of course you are.
27:52 You're a developer or a data scientist.
27:53 That's what we do.
27:54 And you should check out Posit Connect.
27:56 Posit Connect is a way for you to publish, share, and deploy all the data products that you're building using Python.
28:04 People ask me the same question all the time.
28:07 Michael, I have some cool data science project or notebook that I built.
28:10 How do I share it with my users, stakeholders, teammates?
28:13 Do I need to learn FastAPI or Flask or maybe Vue or React.js?
28:18 Hold on now.
28:19 Those are cool technologies, and I'm sure you'd benefit from them.
28:22 But maybe stay focused on the data project?
28:24 Let Posit Connect handle that side of things.
28:27 With Posit Connect, you can rapidly and securely deploy the things you build in Python.
28:31 Streamlit, Dash, Shiny, Bokeh, FastAPI, Flask, Quattro, Reports, Dashboards, and APIs.
28:38 Posit Connect supports all of them.
28:40 And Posit Connect comes with all the bells and whistles to satisfy IT and other enterprise requirements.
28:46 Make deployment the easiest step in your workflow with Posit Connect.
28:50 For a limited time, you can try Posit Connect for free for three months by going to talkpython.fm.posit.
28:57 That's talkpython.fm.posit.
28:59 The link is in your podcast player show notes.
29:02 Thank you to the team at Posit for supporting Talk Python.
29:05 Okay, so from a consumer of this struct class, I just say class.
29:11 And your example is user.
29:12 You say class, user, parentheses, derived from struct.
29:14 In the field, colon, type.
29:16 So like name, colon, string, groups, colon, set of, str, and so on.
29:20 It looks like standard data classes type of stuff.
29:23 But what you're saying is your meta class goes through and looks at that and says, okay,
29:27 we're going to create a class called user, but it's going to have slots called name, email,
29:31 and groups, among other things, right?
29:33 Like does that magic for us?
29:35 Yeah.
29:35 And then it sets up a bunch of internal data structures that are stored on the type.
29:39 Okay.
29:40 Give me a sense of like, like, what's something, why do you got to put that in there?
29:43 What's in there?
29:44 So the way data classes work, after they do all the type parsing stuff, which we have
29:48 to do too, they then generate some code and eval it to generate each of the methods.
29:54 So when you're importing or when you define a new data class, it generates an init method
29:59 and evals it and then stores it on the instance.
30:01 That means that you have little bits of bytecode floating around for all of your new methods.
30:05 msgspec structs instead, each of the standard methods that the implementation provides, which
30:10 would be, you know, init, wrapper, equality checks, copies, you know, various things are
30:16 single C functions.
30:19 And then the type has some data structures on it that we can use to define those.
30:25 So we have a single init method for all struct types that's used everywhere.
30:29 And as part of the init method, we need to know the fields that are defined on the struct.
30:34 So we have some data stored on there about like the field names, default values, various
30:38 things.
30:38 Nice.
30:38 Because they're written in C rather than, you know, Python bytecode, they could be a lot
30:42 faster.
30:43 And because we're not having to eval a new method every time we define a struct, importing
30:47 structs is a lot faster than data classes.
30:49 Something, I'm not going to guess, I have to look up on my benchmarks, but they are basically
30:54 as efficient to define as a handwritten class where data classes have a bunch of overhead.
30:59 If you've ever written a project that has, you know, a hundred of them, importing
31:02 can slow down.
31:03 Yeah.
31:03 Okay.
31:03 Because you basically are dynamically building them up, right?
31:06 Yeah.
31:06 In data class story.
31:07 Yeah.
31:08 So you've got kind of the data class stuff.
31:10 You got, as you said, dunder net, repper, copy, et cetera.
31:13 But you also have dunder match args for pattern matching.
31:16 That's pretty cool.
31:18 And dunder rich repper for pretty printing support with rich.
31:21 Yeah.
31:22 If you just rich.print, it'll take that, right?
31:24 What happens then?
31:25 It preprints it similar to like how a data class should be rendered.
31:28 Rich is making a pretty big impact.
31:29 So rich is special.
31:31 I enjoy using it.
31:32 This is excellent.
31:33 You've got all the stuff generated.
31:35 So much of it isn't C and super lightweight and fast.
31:38 But from the way we think of it, it's just a Python class, even a little less weird than
31:43 data classes, right?
31:44 Because you don't have to put a decorator on it.
31:45 You just derive from this thing.
31:47 So that's super cool.
31:48 Yeah.
31:49 Super neat.
31:50 The hope was that these would feel familiar enough to users coming from data classes or
31:54 adders or Pydantic or all the various models that learning a new one wouldn't be necessary.
32:00 They're the same.
32:02 Excellent.
32:02 One difference if you're coming from Pydantic is there is no method defined on these by default.
32:06 So you define a struct with fields A, B, and C. Only A, B, and C exist as attributes on that class.
32:13 You don't have to worry about any conflicting names.
32:14 Okay.
32:15 So for example, like the Pydantic ones have, I can't remember, the V1 versus V2.
32:22 It's like, I can't remember, like two dictionary effectively, right?
32:25 Where they'll like dump out the JSON or strings or things like that.
32:28 In V1, there's a method dot JSON.
32:30 Yeah, that's right.
32:31 Which if you have a field name JSON will conflict.
32:33 They are remedying that by adding a model prefix for everything, which I think is a good idea.
32:38 I think that's a good way of handling it.
32:40 Yeah.
32:40 Yeah.
32:40 It's like model underscore JSON or dict or something like that.
32:43 Yeah.
32:43 Cool.
32:43 Yeah, that's one of the few breaking changes they actually, unless you're deep down in
32:47 the guts of Pydantic that you might encounter.
32:49 Yeah.
32:50 You don't have to worry about that stuff because you're more function-based, right?
32:53 You would say decode, or I guess, yeah, decode.
32:57 Here's some data, some JSON or something.
33:00 And then the thing you decode it into would be your user type.
33:03 You'd say type equals user rather than going to the user directly, right?
33:07 Can we put our own properties and methods and stuff on these classes and that'll work all right?
33:12 Yeah.
33:13 To a user, you should think of this as a data class that doesn't use a decorator.
33:17 Okay.
33:17 They should be identical unless you're ever trying to touch the dunder data class fields attribute
33:23 that exists on data classes.
33:24 There should be no runtime differences as far as you can tell.
33:27 And when you're doing the schema validation, it sounds like you're basically embracing the
33:31 optionality of the type system.
33:35 If you say int, it has to be there.
33:36 If you say optional int or int pipe none, it may not be there, right?
33:40 No.
33:40 It's close.
33:41 I'm going to be pedantic here a little bit.
33:43 The optional fields are ones that have default values set.
33:46 So optional bracket int without a default is still a required field.
33:50 It's just one that could be an int or none.
33:52 You'd have to have a literal none passed in.
33:53 Otherwise, we'd error.
33:54 This more matches with how mypy interprets the type system.
33:57 Got it.
33:57 Okay.
33:58 So if I had an optional thing, but it had no value, I'd have to explicitly set it to
34:02 none.
34:02 Yes.
34:03 Or would, yeah.
34:03 Or it'd have to be there in the data every time.
34:06 Like other things, you have default factories, right?
34:09 Passing a function that gets called.
34:10 If it does, I guess if it doesn't exist, right?
34:12 If the data's in there, it's being deserialized, it won't.
34:15 Okay.
34:15 Excellent.
34:16 And I guess your decorator creates the initializer.
34:19 But another thing that I saw that you had was you have this post init, which is really nice.
34:24 Like a way to say like, okay, it's been deserialized.
34:26 Let me try a little further.
34:28 Tell us about this.
34:29 This is cool.
34:29 Yeah, it's coming from data classes.
34:31 They have the same method.
34:32 So if you need to do any extra thing after init, you can use it here rather than trying to override
34:37 the built-in init, which we don't let you do.
34:40 Right.
34:40 Because it has so much magic to do.
34:42 Like let it do it.
34:43 And you don't want to override that anyway.
34:45 You'll have to deal with like passing all the arguments.
34:48 Yeah, it runs Python instead of maybe C, all these things, right?
34:51 So post init would exist if you have more complex constraints, right?
34:56 Currently, that's one reason to use it.
34:58 We currently don't support custom validation functions.
35:01 There's no .validate, decorator, various frameworks, different ways of defining these.
35:06 We have some constraints that are built in.
35:07 You can constraint the number to be greater than some value, but there's no way to specify
35:12 custom constraints currently.
35:14 It's on the roadmap.
35:15 It's a thing we want to add.
35:16 Post init's a way to hack around that.
35:18 So right now, you're looking at the screen.
35:20 You have a post init defined, and you're checking if low is greater than high, raise an error.
35:25 And that'll bubble up through decodes and raise an ice user facing validation error.
35:29 In the long run, we'd like that to be done a little bit more field-based.
35:32 Somewhere to come from other frameworks.
35:34 It is tricky, though, because the validation goes onto one field or the other.
35:38 You don't have composite validators necessarily, right?
35:41 And so there's totally valid values of this low, but whatever it is, it has to be lower than high.
35:47 But how do you express that relationship?
35:49 So I think this is awesome.
35:50 Other areas where it could be interesting is under some circumstances, maybe you've got to compute some field also that's in there that's not set.
35:59 I don't know.
35:59 There's some good options in here.
36:00 I like it a lot.
36:01 Yeah, I guess the errors just come out as just straight out of like something went wrong with under post init rather than field low has this problem.
36:08 It's a little harder to relate an error being raised to a specific field if you raise it in a post init.
36:13 Yeah.
36:13 Also, since you're looking at this, and I'm proud that I got this to work, the errors raised in post init use chained exceptions.
36:20 So you can see a little bit of the cause of where it comes from.
36:22 And getting those to work at the Python C API is completely undocumented and a little tricky to figure out.
36:28 It's a lot of reading how the interpreter does it and making me write, you know, 12 incantations to get them to bubble up right.
36:34 Yeah, I do not envy you working on this struct, this base class.
36:38 But I mean, that's where part of the magic is, right?
36:41 And that's why I wanted to dive into this because I think it behaves like Python classes, but it has these really special features that we don't normally get, right?
36:49 Like low memory usage, high performance, accessing the fields.
36:53 Is that any quicker or is it like standard struct level quick?
36:57 Attribute access and settings should be the same as any other class.
37:00 Things that are faster are init.
37:02 Reper, not that that should matter.
37:04 If you're looking for a high performance reper, that's...
37:06 You're doing it wrong.
37:07 Seems like you're doing something wrong.
37:08 Equality checks, comparisons, so sorting, you know, less than, greater than.
37:12 I think that's it.
37:12 Everything else should be about the same.
37:14 So field ordering, you talked about like evolution over time.
37:17 Does it, does this matter?
37:19 Field ordering is mostly defining how, what happens if you do subclasses and stuff.
37:22 This whole section is, if you're not subclassing, shouldn't hopefully be relevant to you.
37:27 So we match how data class handles things for ordering.
37:30 Okay.
37:30 So I could have my user, but I could have a super user that derives from my user that derives
37:35 from struct and things will still hang together.
37:37 And so figuring out how all the fields order out through that subclassing is what this doc
37:41 is about.
37:41 Yeah.
37:42 Another type typing system thing you can do a lot is have explicitly claimed something
37:46 as a class variable.
37:47 You know, Python is weird about its classes and what makes a variable that's associated
37:53 with a class and or not.
37:55 Right.
37:56 So with these type of classes, you would say like class example colon, and then you have
37:59 x colon int.
38:00 Right.
38:01 And that appears, will appear on the static type, like example.x, but it also imbues each
38:06 object with its own copy of that x.
38:08 Right.
38:09 Which is like a little bit, is it a static thing or part of the type or is it not?
38:14 It's kind of funky.
38:14 But you also can say that explicitly from the typing, you say this is a class variable.
38:19 What happens then?
38:20 Right.
38:20 Like, so standard attributes exist on the instances where a class var exists on the class itself.
38:26 Class fars are accessible on an instance, but the actual data is stored on the class.
38:31 So you don't have an extra copy.
38:33 I see.
38:33 So if there's some kind of singleton type of thing or just one of them.
38:37 Yeah.
38:37 Yeah.
38:37 It has to do with how Python does attribute resolution where it'll check on the instance
38:43 and then on the type and also there's descriptors in there, you know, somewhere.
38:46 Interesting.
38:47 Okay.
38:47 Like other things, I suppose it's pretty straightforward that you take these types and you use them
38:53 to validate them.
38:53 But one of the big differences with msgspec.struct versus pydantic.base model and others is the
39:00 validation doesn't happen all the time.
39:02 It just happens on encode decode.
39:04 Right.
39:05 Like you could call the constructor and pass in bad data or like it just doesn't pay attention.
39:10 Right.
39:11 Yeah.
39:11 Why is it like that?
39:12 So this is one of the reasons I wrote my own thing rather than building off of something
39:17 existing like pydantic.
39:18 Side tangent here, just to add history context here.
39:21 Message spec was started about three years ago.
39:22 The JSON and it kind of fell into its full model about two years ago.
39:26 So this has existed for around two years.
39:27 Yeah.
39:28 We're pre the pydantic rewrite.
39:30 Anyway, the reason I wanted all of this was when you have your own code, where bugs can
39:36 come up.
39:36 Are bugs in your own code?
39:37 I've typed something wrong.
39:39 I've made a mistake and I want that to be checked.
39:41 Or it can be user data that's coming in.
39:43 Or, you know, maybe it's a distributed system and it's still my own code.
39:46 It's just a file or database.
39:47 Yeah.
39:47 Whatever.
39:48 Yeah.
39:48 We have many mechanisms of testing our own code.
39:51 You can write tests.
39:52 You have static analysis tools like mypy, Pyright, or checking.
39:55 It's a lot easier for me to validate that a function I wrote is correct.
39:59 Got it.
39:59 There are other tools I believe that we should lean on rather than runtime validation in those
40:05 cases.
40:05 But when we're reading in external data, whether it's coming over the wire, coming from a file,
40:10 coming from user input in some way, we do need to validate because the user could have
40:13 passed us something that doesn't match our constraints.
40:17 As soon as you started trusting user input, you're in for a bad time.
40:20 We don't want to arbitrarily be trusting.
40:21 We do validate on JSON decoding.
40:24 We validate on message pack decoding.
40:25 We also have a couple of functions for doing in-memory conversions.
40:28 So there's msgspec convert, msgspec to built-ins for going the other way.
40:33 So that's for doing conversion of runtime data that you got from someone rather than a specific
40:37 format.
40:37 Yeah, because if you're calling this constructor and passing the wrong data, mypy should check
40:42 that.
40:42 PyCharm should check that.
40:44 Maybe Ruff would catch it.
40:46 I'm not sure.
40:46 But there's a bunch of tools.
40:48 Yeah, Ruff doesn't have a type checker yet.
40:49 TBD on that.
40:51 Yeah, OK.
40:52 Yeah, being able to check these statically, it means that we don't have to pay the cost
40:57 every time we're running, which I don't think we should.
40:59 That's extra runtime performance that we don't need to be spending.
41:02 Yeah, definitely.
41:03 Check it on the boundaries, right?
41:04 Check it where it comes into the system, and then it should be good.
41:07 The other reason I was against adding runtime validation to these structs is I want all types
41:11 to be on equal footing.
41:12 And so if I am creating a list, the list isn't going to be doing any validation because it's
41:17 the Python built-in.
41:18 Same with data classes, same with attrs, types, whatever.
41:21 And so only doing a validation when you construct some object type that subclasses from a built-in
41:26 that I've defined, or a type I've defined, doesn't give parity across all types and might
41:31 give a user misconceptions about when something is validated and when they can be sure it's
41:35 correct first when it hasn't.
41:36 Yeah.
41:37 Have you seen bear type?
41:38 I have.
41:39 Yeah.
41:39 Bear type's a pretty interesting option.
41:41 If people really want runtime validation, they could go in and throw bear type onto their
41:46 system and let it do its thing.
41:48 Even if you're not doing it, you should read the docs just for the sheer joy that these
41:51 docs are.
41:52 Oh, they are pretty glorious.
41:53 Yeah, I'll do it.
41:54 It's kind of like burying the lead a little down here, but they described themselves as
41:58 bear type brings Rust and C++ inspired zero-cost abstractions into the lawless world of the
42:04 dynamically typed Python by enforcing type safety at the granular level of functions and methods
42:09 against type hints standardized by the Python community of O order one, non-amortized worst
42:14 case time with negligible constant factors.
42:17 Oh my gosh.
42:18 So much fun, right?
42:20 They're just joking around here, but it's a pretty cool library.
42:22 If you want runtime type checking, it's pretty fast.
42:25 Okay.
42:25 Interesting.
42:26 You talked about the pattern matching.
42:28 I'll come back to that.
42:29 One thing I want to talk about.
42:30 Well, okay.
42:31 Frozen.
42:31 Frozen instances.
42:32 This comes from data classes.
42:34 Without the instances being frozen, the structs are mutable.
42:37 Yeah, I can get one, change its value, serialize it back out, things like that.
42:42 Yep.
42:42 But frozen, I suppose, means what you would expect, right?
42:44 Yeah.
42:45 Frozen has the same meaning as a data class equivalent.
42:47 How deep does frozen go?
42:49 So for example, is it frozen all the way down?
42:51 So in the previous example from Itamar, it had the top level class and then other structs
42:57 that were nested in there.
42:58 If I say the top level is frozen, do the nested ones themselves become frozen?
43:02 No.
43:03 So frozen applies to the type.
43:05 So if you define a type as frozen, that means you can't change values that are set as attributes
43:10 on that type.
43:10 But you can still change things that are inside it.
43:13 So if a frozen class contains a list, you can still append stuff to the list.
43:16 There's no way to get around that except if we were to do some deep, deep, deep magic,
43:20 which we shouldn't.
43:21 It would definitely slow it down if you had to go through and recreate frozen lists every
43:25 time you saw a list and stuff like that.
43:27 Yeah.
43:27 Okay.
43:27 And then there's one about garbage collection in here.
43:30 Yeah.
43:31 Which is pretty interesting.
43:32 There we go.
43:33 Disabling garbage collection.
43:35 This is under the advanced category.
43:36 Warning box around this that tells you not to.
43:39 What could go wrong?
43:40 Come on.
43:40 Part of this was experimenting with the DAS distributed scheduler, which is a unique application,
43:46 I think, for people that are writing web stuff in that all of its data is kept in memory.
43:50 There's no backing database that's external.
43:52 And so it is as fast to respond as the bits of in-memory computation it needs to do before
43:58 it sends out a new task to a worker.
43:59 So in this case, their serialization performance matters.
44:03 But also, it's got a lot of in-memory state.
44:05 It's a dict of types of lots of chaining down.
44:09 The way the CPython garbage collector works is that these large dictionaries could add GC overhead.
44:15 Every time a GC thing happens, it has to scan the entire dictionary.
44:19 Any container thing could contain another.
44:20 And once you do that, there could be a cycle.
44:22 And then for very large graphs, GC pauses could become noticeable.
44:27 Yes.
44:27 This is an experiment and seeing ways around that.
44:29 Because we've done some deep magic with how structs work, we can disable GC for subclasses,
44:34 user-defined types, which CPython does not expose normally and really isn't something you
44:40 probably want to be doing in most cases.
44:42 But if you do, you get a couple benefits.
44:44 The types are smaller.
44:45 Every instance needs to include some extra state for tracking GC.
44:49 I believe on recent builds, it's 16 bytes.
44:52 So it's two pointers.
44:53 So that's, you know, you're saving 16 bytes print.
44:56 That's non-trivial.
44:56 Yeah.
44:57 If you got a huge list of them, that could be a lot.
44:59 Yeah.
44:59 And two, they don't, they're not traced.
45:02 And so if you have a lot of them, that's reducing reduction in tracing overhead every time
45:07 a GC pass happens.
45:08 GC puts more overhead on top of stuff than you would think.
45:12 So I did some crazy GC stuff over at Talk Python and training with my courses.
45:16 You go to slash sitemap.xml.
45:19 I don't know how many entries are in the sitemap, but there are 30,000 lines of sitemap.
45:24 Like many, many, many, many, many, many thousands of URLs up to come back with details.
45:29 Just to generate that page in one request with the default Python settings in Python 3.10,
45:35 I think it was, it was doing 77 garbage collections while generating this page.
45:40 That's not ideal.
45:43 I switched it to just change or tweak how frequently the GC runs.
45:46 So like every 70,000, no, every 50,000 allocations instead of every 700.
45:51 And the site runs 20% faster now and uses the same amount of memory, right?
45:55 And so this is not exactly what you're talking about here, but it's in the, it plays in the
46:00 same space as like, you can dramatically change the things that are triggering this and dramatically
46:05 change the performance potentially.
46:08 The caveat is you better not have cycles.
46:10 Yeah.
46:11 So the other thing with these is, as you pointed out, is the indicator of when a GC pass happens
46:16 has to do with how many GC aware types have been allocated.
46:19 Yep.
46:19 And so if your market type is not a GC type, then the counter is an increment.
46:22 You're not paying that cost.
46:23 Right.
46:24 You can allocate all the integers you want all day long.
46:26 It'll never affect the GC.
46:27 But if you start allocating classes, dictionaries, tuples, et cetera, that is like, well, those
46:31 could contain cycles.
46:32 You have 700 more than you've deallocated since last time.
46:35 I'm going to go check it.
46:36 One place this comes up is if you have, say, a really, really large JSON file.
46:41 Because any deserialization is an alien allocation heavy workload, which means that you can have
46:46 a GC pause happen, you know, several times during it because you've allocated, you know,
46:50 that many types.
46:51 Turning up GC for these types lets you avoid those GC pauses, which gives you actual runtime
46:56 benefits.
46:56 A different way of doing this that is less insane is to just disable GC during the decode.
47:01 Do a, you know, GC disable, JSON decode, GC enable, and you only do a GC pass once.
47:07 Especially because JSON as a tree-like structure can never create cycles.
47:10 You're not going to be having an issue there.
47:12 But you're probably allocating a lot of different things that are container types.
47:15 And so it looks to the GC like, oh, this is some really sketchy stuff.
47:20 We better get on the game here.
47:21 But you know, as you said, there's no cycles in JSON.
47:25 So there's a lot of scenarios like that, like database queries.
47:29 You know, I got a thousand records back from a table.
47:31 They're all some kind of container.
47:33 So minimum one GC happens just to read back that data.
47:36 But you know, there's no cycles.
47:38 So why is the GC happening?
47:39 You can kind of control that a little bit.
47:41 Or you just turn the number up to 50,000 like I did.
47:43 It still happens, but less.
47:46 A lot less.
47:46 Yeah.
47:47 So this is pretty interesting, though, that you just set GC equals false.
47:50 Where do you set this?
47:51 Is this like in the derived bit?
47:54 It's part of the class definition.
47:56 So we make use of class definition keyword arguments.
48:00 So it goes after the struct type in the subclass.
48:03 You do, you know, my class, open over at the C, struct, comma, GC equals false, close, comma,
48:08 colon, rest of the class.
48:10 Yeah, that's where I thought.
48:11 But it is a little funky.
48:12 Yeah.
48:13 I mean, it kind of highlights the meta class action going on there, right?
48:16 What else should people know about these structs?
48:18 They're fast and they can be used for not just serialization.
48:21 So if you are just writing a program and you happen to have msgspec on your system,
48:25 it should be faster to use them than data classes.
48:27 Whether that matters is, of course, application dependent.
48:30 But they're like generally a good idea.
48:32 They happen to live in this serialization library, but that's just because that's where I wrote
48:35 them.
48:36 Yeah, that's where they.
48:37 In a future world, we might split them out into a sub package.
48:39 Yeah.
48:40 Fast struck.
48:41 Pippin saw fast struck.
48:42 Who knows?
48:43 Yet to be named.
48:45 So better than data classes.
48:47 I mean, they have the capabilities of data classes.
48:48 So that's cool.
48:49 But better than straight up regular classes, like Bayer classes, you know, class colon name.
48:54 Are opinionated a little bit.
48:56 They're how I think people probably should be writing classes.
48:59 And they're opinionated in a bit.
49:00 That means that you can't write them in ways that I don't want you to.
49:03 So the way a struct works is you define attributes on it using type annotations.
49:07 And we generate a fast init method for you.
49:09 We don't let you write your own init.
49:11 In the subclass, you can't override init.
49:13 The generated one is the one you get.
49:15 That means that like if you're trying to create an instance from something that isn't those field
49:19 names, you can't do that.
49:21 You need to use a new class method for writing those.
49:23 I believe this is how people, at least on projects I work on, generally use classes.
49:27 So I think it's a fine limitation.
49:29 But it is putting some guardrails around how the arbitrariness of how you can define a Python
49:35 class.
49:35 You could have a, you know, a handwritten class that has two attributes, X and Y, and your
49:40 init takes, you know, parameters A and B.
49:43 Sure.
49:43 Or maybe it just takes X and it always defaults Y unless you go and change it after or whatever,
49:48 right?
49:48 I guess you could do sort of do that with default values, right?
49:51 But you couldn't prohibit it from being passed in.
49:53 I'm feeling some factory classes.
49:55 The attrs docs have a whole, whole page telling people about why this pattern is, is better
50:01 and nudging them to do this.
50:02 So this isn't a new idea.
50:03 Yeah.
50:03 Go check out attrs and see what they're saying as well.
50:06 There's probably a debate in the issues somewhere on GitHub.
50:08 There always is a debate.
50:10 Yeah.
50:10 Let's see.
50:10 Let's go get a bunch of stuff up here I want to talk about.
50:12 I guess really quickly, since there's a lot of like C native platform stuff, right?
50:17 This is available on, you know, pip install msgspec.
50:21 We're getting a wheel.
50:22 It seemed like it worked fine on my M2 MacBook Air.
50:26 Like what are the platforms that I get a wheel that don't have to worry about compiling?
50:30 So we use CI BuildWheel for building everything.
50:33 And I believe I've disabled some of the platforms.
50:36 The ones that are disabled are mostly disabled because CI takes time.
50:40 I need to minimize them.
50:42 But everything common should exist, including Raspberry Pi and various ARM builds.
50:46 Excellent.
50:47 Okay.
50:47 Yeah.
50:47 It seemed like it worked just fine.
50:49 I didn't really know that it was like doing a lot of native code stuff, but it seems like
50:53 it.
50:53 And also available on Conda, Conda Forge.
50:55 So that's cool.
50:56 If you Conda, you can also just Conda install it.
50:59 Kind of promised talking about the benchmarks a little bit, didn't I?
51:02 So benchmarks are always...
51:04 If you click on the graph on the bottom, it'll bring you to it.
51:06 Yeah.
51:06 They're always rife with like, that's not my benchmark.
51:10 I'm doing it different, you know?
51:11 But give us a sense of just...
51:13 It says fast, italicies leaning forward.
51:16 Give us a sense of like, where does this land?
51:18 Is it, you know, 20% faster or is it a lot better?
51:21 Yeah.
51:21 So as you said, benchmarks are a problem.
51:22 The top of this benchmark docs is a whole argument against believing them and telling you to run
51:27 your own.
51:27 So take a grain of salt.
51:29 I started benchmarking this mostly just to know how we stacked up.
51:33 It's important if you're making changes to know if you're getting slower.
51:35 It's also important to know what the actual trade-offs of your library are.
51:38 All software engineering is trade-offs.
51:40 So msgspec is generally fast.
51:43 The JSON parser in it is one of the fastest in Python or the fastest, depending on what
51:50 your message structure is and how you're invoking it.
51:52 It at least is on par with or JSON, which is generally what people consider to be the fast
51:56 parser.
51:57 Right.
51:57 That's where they go when they want fast.
51:59 Yeah.
51:59 Yes.
51:59 If you are specifying types, so if you, you know, add in a type annotation to a JSON decode
52:05 call with msgspec, even if you're decoding the whole message, you're not doing
52:08 a subset.
52:08 We're about 2x faster than our JSON.
52:10 You actually get a speed up by defining your types because struct types are so efficient
52:15 to allocate versus a deck.
52:17 That's kind of the opposite of what you might expect, right?
52:19 It seems like we're doing more work, but we're actually able to do less because we can
52:23 take some more, you know, efficient fast paths.
52:25 And then a thousand objects with validation compared to.
52:29 Yeah.
52:29 Mesher, Murrow, Seatters, Pydantic, and so on.
52:34 Probably the last one.
52:34 This was a grab bag of various validation libraries that seemed popular.
52:38 Mashemar is the one that DBT uses.
52:40 I think they're the primary consumer of that.
52:42 Catters is for attrs.
52:43 Pydantic is, you know, ubiquitous.
52:45 This right here in this benchmark graph we're looking at is against Pydantic V1.
52:50 I have not had a chance to update our benchmarks to go against V2.
52:54 There's a separate gist somewhere that has got some numbers there.
52:57 Standard number they throw out is like 22 times faster.
53:00 So it still puts you multiples faster.
53:02 In that benchmark, we're averaging 10 to 20x faster than Pydantic V2.
53:06 In numbers I run against V1, we're about 80 to 150x faster.
53:11 So it really is structure dependent.
53:13 Yeah, sure.
53:14 Do you have one field or do you have a whole bunch of stuff?
53:17 Yeah, exactly.
53:17 And what types of fields?
53:19 To be getting more into the weeds here, JSON parsing is not easy.
53:24 Message pack parsing is like the format was designed for computers to handle it.
53:27 It's, you know.
53:28 Seven bytes in there is an integer here.
53:30 Yeah, okay.
53:31 Where JSON is human readable and parsing strings into stuff is slow.
53:35 Right.
53:35 The flexibility equals slowness, yeah.
53:37 Our string parsing routines in msgspec are faster than the ones used by orJSON.
53:43 Our integer parsing routines are slower.
53:46 But there's a different trade-off there.
53:47 Interesting.
53:48 Okay.
53:48 Yeah, I think this is, it just seems so neat.
53:50 There's so much flexibility, right, with all the different formats.
53:53 And the restrictions on the class, they exist, but they're unstruck.
53:56 But they're not insane, right?
53:58 I mean, you build proper OOP type of things.
54:02 You don't need super crazy hierarchies.
54:04 Like, that's where you get in trouble with that stuff anyway.
54:06 So don't do it.
54:07 I guess we don't have much time left.
54:09 One thing I think we could talk about a bit maybe would be, I find it, the extensions.
54:13 Just maybe talk about parsing stuff that is kind of unknown.
54:16 This is pretty interesting.
54:17 So the way we allow extension currently, there's an intention to change this and expand it.
54:23 But currently, extending adding new types is done via a number of different hooks.
54:28 They're called when a new type is encountered.
54:30 So custom user defined type of some form.
54:32 I liked doing this rather than adding it into the annotation because if I have a new type, I want it to exist probably everywhere.
54:38 And I don't want to have to keep adding in and use the serializer and deserializer as part of the type annotations.
54:45 So to define a new type that you want to encode, you can add an encode hook, which takes in the instance and returns something that msgspec knows how to handle.
54:54 This is similar to, you know, if you're coming from standard library JSON, there's a default callback.
54:59 It's the same.
54:59 We renamed it to be a little better name in my mind, but it's the same thing.
55:02 Right.
55:03 So your example here is taking a complex number, but storing it as a tuple of real and imaginary numbers, but then pulling it back into a proper complex number object.
55:12 Super straightforward.
55:13 Yeah.
55:13 But makes it possible.
55:14 Yeah.
55:15 Yeah.
55:15 That's really cool.
55:16 So people can apply this.
55:17 And this, I guess, didn't really matter on the output destination, does it?
55:21 Your job here is to take a type that's not serializable to one that is, and then whether that goes to a message pack or JSON or whatever is kind of not your problem.
55:31 Yeah.
55:31 And then the decode hook is the inverse.
55:32 You get a bunch of stuff that is, you know, core types, ints, strings, whatever, and you compose them up into your new custom type.
55:39 Jim, I think we're getting about out of time here.
55:41 But I just want to point out, like, if people hit the user guide, there's a lot of cool stuff here.
55:44 And there's a whole performance tips section that people can check out.
55:50 You know, if we had more time, maybe we'd go into them.
55:52 But, like, for example, you can call msgspec dot JSON dot encode, or you can create an encoder and say the type and stuff and then reuse that.
55:59 Right.
55:59 Those kinds of things.
56:01 Yeah.
56:01 There's another method that is, again, a terrible internal hack for reusing buffers.
56:07 So you don't have to keep allocating byte buffers every message.
56:09 You can allocate a byte array once and use it for everything.
56:12 Save some memory.
56:13 Let me ask, Ellie's got a question.
56:14 I'm going to read some words that don't mean anything to me, but they've made to you.
56:17 How does the performance of message pack plus msgspec with the array-like equals true optimization compared to flat buffers?
56:25 So by default, objects, so struct types, data classes, whatever, encode as objects in the stream.
56:31 So a JSON object has keys and values, right?
56:34 If you have a point with fields X and Y, it's got X and Y, you know, one, two.
56:39 We have an array-like optimization, which lets you drop the field names.
56:42 And so that would instead include as an array of, you know, one comma two, dropping the X and Y.
56:47 Reduces the message size on the wire.
56:48 If the other side knows what the structure is, it can, you know, pull that back up into a type.
56:53 In terms of message pack as a format, plus with the array-like optimization, the output size should be approximately the same as you would expect it to come out of flat buffers.
57:03 The Python flat buffers library is not efficient for creating objects from the binary.
57:09 So it's going to be a lot faster to pull it in.
57:11 Obviously, this is then a very custom format.
57:13 You're doing a weird thing.
57:15 And so compatibility with other ecosystems will be slower.
57:18 Or it's not slower necessarily, but you'll have to write them yourself.
57:21 Yeah.
57:21 Not everything knows how to read the message pack.
57:23 More brittle, potentially.
57:24 Yeah.
57:25 Yes.
57:25 Yeah.
57:25 But for Python, talking to Python, that's probably the fastest way to go between processes.
57:29 And probably a lot faster than JSON or YAML or something like that.
57:33 Okay.
57:33 Excellent.
57:34 I guess, you know, there's many more things to discuss, but we're going to leave it here.
57:38 Thanks for being on the show.
57:39 Final call to action.
57:40 People want to get started with message pack.
57:43 Are you accepting PRs if they want to contribute?
57:45 What do you tell them?
57:47 First, I encourage people to try it out.
57:48 I'm available, you know, to answer questions on GitHub and stuff.
57:51 It is obviously a hobby project.
57:53 So, you know, if the usage bandwidth increases significantly, we'll have to get some more
57:58 maintainers on and hopefully we can make this more maintainable over time.
58:01 But once the sponsor funds exceed $10,000, $20,000, $30,000 a month, like you'll reevaluate
58:06 your...
58:07 No, just kidding.
58:07 Sure.
58:08 Sure.
58:08 But yeah, please try it out.
58:10 Things work, should be hopefully faster than what you're currently using and hopefully intuitive
58:15 to use.
58:15 We've done a lot of work to make sure the API is friendly.
58:17 Yeah.
58:17 It looks pretty easy to get started with.
58:19 The docs are really good.
58:20 No, thank you.
58:21 Congrats on the cool project.
58:22 Thanks for taking the time to come on the show and tell everyone about it.
58:25 Thanks.
58:25 Yeah.
58:26 See you later.
58:26 Bye.
58:27 This has been another episode of Talk Python To Me.
58:29 Thank you to our sponsors.
58:31 Be sure to check out what they're offering.
58:33 It really helps support the show.
58:35 This episode is sponsored by Posit Connect from the makers of Shiny.
58:39 Publish, share, and deploy all of your data projects that you're creating using Python.
58:44 Streamlit, dash, dash, dash, dash, dash, dashboards, dashboards, dashboards, and APIs.
58:50 Posit Connect supports all of them.
58:52 Try Posit Connect for free by going to talkpython.fm/posit.
58:57 P-O-S-T.
58:58 Want to level up your Python?
59:00 We have one of the largest catalogs of Python video courses over at Talk Python.
59:04 Our content ranges from true beginners to deeply advanced topics like memory and async.
59:09 And best of all, there's not a subscription in sight.
59:12 Check it out for yourself at training.talkpython.fm.
59:15 Be sure to subscribe to the show.
59:17 Open your favorite podcast app and search for Python.
59:20 We should be right at the top.
59:21 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
59:26 and the direct RSS feed at /rss on talkpython.fm.
59:30 We're live streaming most of our recordings these days.
59:33 If you want to be part of the show and have your comments featured on the air,
59:37 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
59:41 This is your host, Michael Kennedy.
59:43 Thanks so much for listening.
59:45 I really appreciate it.
59:46 Now get out there and write some Python code.
59:48 Thank you.