10 Polars Tools and Techniques To Level Up Your Data Science



Episode Deep Dive
Guest introduction and background
Christopher Trudeau is a Python educator, fractional CTO, author, and frequent speaker on various Python podcasts. He helps organizations implement robust software systems, often serving as an outsourced or fractional CTO. Christopher has been a guest on Talk Python multiple times, previously discussing Django and web development topics. In this episode, Christopher shares his recent work with Polars, a modern, Rust-powered DataFrame library for Python, and highlights a collection of complementary Polars extensions and libraries.
What to Know If You're New to Python
If you are new to Python and want to follow along with concepts such as data frames, data validation, or even data manipulation at scale, these essential items will help you keep up:
- Python's data ecosystem heavily relies on libraries like Pandas and Polars for data analysis. Understanding how data frames work (columns, rows, filtering, and expressions) is fundamental.
- Many Python libraries that claim high performance or advanced features (like Polars) often use underlying compiled languages such as Rust or C for speed.
- Basic Python I/O (reading files, working with CSV data, handling errors) is an important starting point. That knowledge transfers well into Polars or Pandas.
- Familiarity with Virtual Environments or other Python environment setups will make installing and trying out these libraries much easier.
Key points and takeaways
- Polars as a Faster, More Pythonic DataFrame Library
Polars stands out for its performance advantages and more object-oriented (and arguably more Pythonic) interface compared to legacy libraries like Pandas. It features lazy evaluation, where calculations can be optimized and reordered automatically for better speed and memory usage. The library also integrates well with existing Python data science tools like Matplotlib, Seaborn, and Plotly.
- Links and tools:
- Polars official docs: https://pola-rs.github.io/polars-book/
- Polars GitHub: https://github.com/pola-rs/polars
- Links and tools:
- Awesome Polars: A Curated List of Extensions and Resources
There is an "awesome polars" curated list on GitHub collecting libraries, blog posts, and articles about Polars. Many of the libraries covered below come directly from this collection. It's a go-to index for discovering new Polars-related projects and resources.
- Links and tools:
- Awesome Polars list: https://github.com/ddotta/awesome-polars
- Links and tools:
- Data Validation and Cleaning with DataFramely and Patito
Ensuring data integrity is vital in data science. The DataFramely library provides declarative, Polars-native validation, while Patito offers Pydantic-style models for Polars. Both tools catch or filter out bad rows and allow rule-based checks, making the cleaning step more predictable.
- Links and tools:
- DataFramely: https://github.com/quantco/dataframely
- Patito: https://github.com/JacobGerra/patito
- Links and tools:
- Polars IP Tools for IP Address Analysis
For those analyzing server logs or needing IP-based geolocation data, Polars IP Tools streamlines working with IP addresses. It integrates with MaxMind GeoIP and Spur VPN databases, quickly filtering private networks or matching IP ranges. This is especially useful for web analytics, security, and marketing data.
- Links and tools:
- Polars IP Tools: https://github.com/Hutchin-Labs/polars_ip_tools
- Links and tools:
- Fuzzy Matching and String Similarities
Two libraries stand out for approximate string matching: Polars Fuzzy Match, which uses the Nucleo Rust library under the hood, and polars-strsim, implementing various string distance algorithms (e.g., Levenshtein, Jaccard). These help match slightly inconsistent text data, such as user inputs, misspellings, or partial file names.
- Links and tools:
- polars-fuzzy-match: https://github.com/bnmock/polars_fuzzy_match
- polars-strsim: https://github.com/JeremyFoxcroft/polars_strsim
- Links and tools:
- Encrypting Sensitive Data with polars-encryption
polars-encryption offers AES-based encryption and decryption for specific columns in a Polars DataFrame. Useful for HIPAA-compliant applications, personal data security, or any scenario requiring encryption at rest, it lets you plug in encryption or decryption in your Polars workflow with minimal overhead.
- Links and tools:
- polars-encryption: https://github.com/niazigrg/polars-encryption
- Links and tools:
- Date and Time Utilities via xdt
xdt is an experimental but official Polars-contrib library adding specialized datetime functions, such as localized formatting, skipping weekends in generated date ranges, and even converting to/from Julian dates for astronomers and other advanced use cases. Some of its features have been merged into Polars proper, while others remain separate to avoid bloating the Polars core.
- Links and tools:
- xdt: https://github.com/pola-rs-contrib/xdt
- Links and tools:
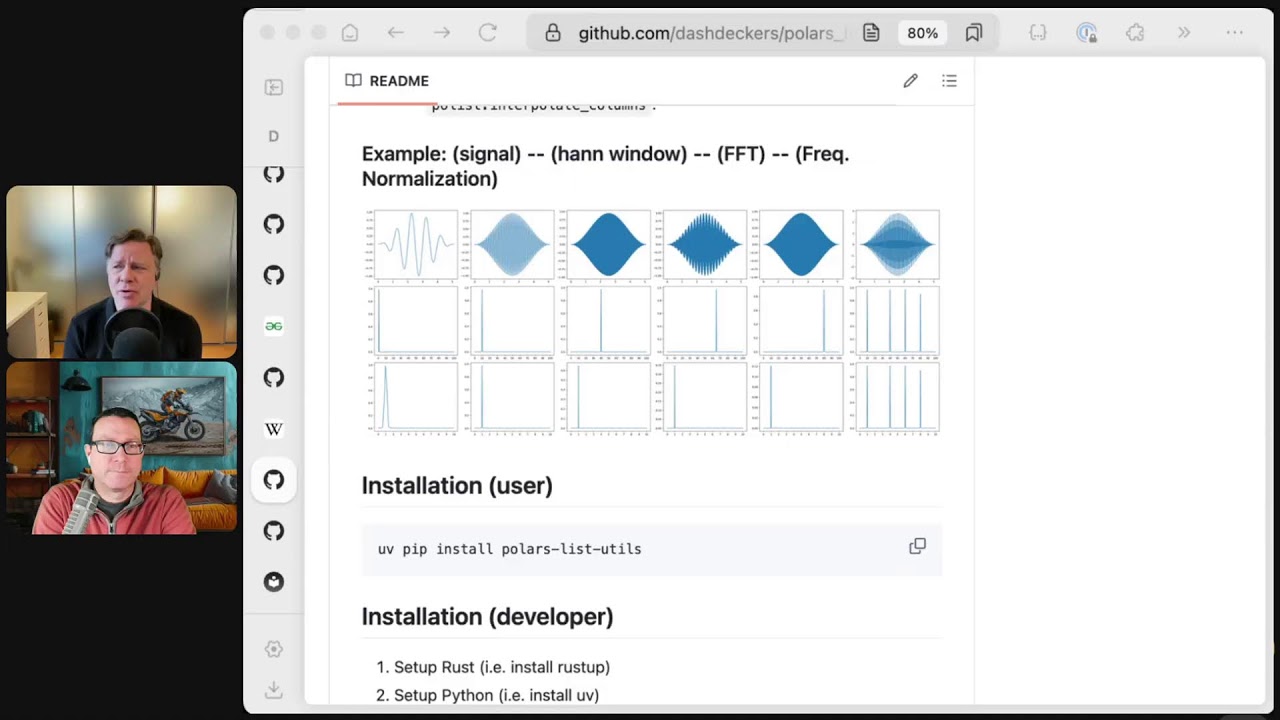
- General Utility Extensions (Harley, Polars List Utils, and More)
Libraries like Harley (a port of PiSpark's "Quinn"), Polars List Utils, and others offer additional utility functions for string manipulation (trimming whitespace, approximate equality checks) or working with nested list columns (aggregations, Fourier transforms, etc.). These "kitchen sink" extensions often save time by automating repetitive tasks.
- Links and tools:
- Harley: https://github.com/TimBurge/harley
- Polars List Utils: https://github.com/travishammond/polars_list_utils
- Links and tools:
- Regression and Statistical Tools (polars_ols)
The Polars OLS library lets you run least-mean-square or OLS calculations directly on Polars DataFrames, ideal for quick regression or signal processing tasks. If you're working with large datasets and want to avoid bridging back to another library for these calculations, polars_ols is a seamless option.
- Links and tools:
- polars_ols: https://github.com/azmirr/polars_ols
- Links and tools:
- Bridging and Comparing Polars with Other Libraries
Converting between Pandas, Dask, or other DataFrame libraries is straightforward: Polars has built-in
to_pandas()andfrom_pandas()methods. Tools like Narwhal help you partially automate or unify code to run across multiple DataFrame frameworks. This portability lowers the barrier to switching from one library to another, letting you test Polars' speed benefits without major rewrites.
- Links and tools:
- Narwhal bridging: https://pypi.org/project/narwhal/
- Christopher's Fractional CTO Perspective Christopher also discussed his professional role as a fractional CTO, helping teams build software systems and manage agile processes. He emphasized how experienced technical leaders can guide essential but sometimes "boring" tasks, like CI/CD or data validation, while ensuring the development team remains focused on delivering features that matter.
- No direct library link, but his professional approach underlines the importance of balanced, maintainable software solutions.
Interesting quotes and stories
"I'm an irrational CTO. I'm radical two over seven, that's how much CTO I am." -- Christopher Trudeau (commenting on the concept of a fractional CTO with a playful math pun)
"The difference between calling Django a 'dinosaur' vs a 'shark' is that sharks have been around as long as dinosaurs but they're still alive and well, just like Django." -- Christopher Trudeau
"There's a phrase that I stole in my book: People talk about Django being old, but it's more like a shark than a dinosaur, still going strong!" -- Christopher Trudeau
"For me, Polars just feels more Pythonic with its chained function calls and expressions. It has a lot less of that black magic that you sometimes see in Pandas." -- Christopher Trudeau
Key definitions and terms
- DataFrame: A 2D, tabular data structure with labeled columns, often used for data analysis in Python.
- Lazy Evaluation: Deferring computations until the results are actually needed, allowing automatic optimization of query plans and operations.
- Fuzzy Matching: Approximate string matching to handle typos, slight spelling variations, or partial text.
- Encryption at Rest: Keeping data stored on disk (files, databases) in an encrypted form to protect against unauthorized access.
- OLS (Ordinary Least Squares): A method of linear regression aiming to minimize the sum of squared differences between predicted and observed values.
Learning resources
Below are some resources that can help you go deeper into Polars, Python, and related data topics:
- Polars for the Power Users: Transform Your Data Analysis Game Christopher Trudeau's dedicated course at Talk Python Training, covering Polars from fundamentals to advanced techniques.
- Python for Absolute Beginners Ideal for those just getting started with Python, covering language basics and best practices.
- Talk Python Episode on Narwhal Discover how to bridge code between Pandas and Polars seamlessly with the Narwhal library. (Episode #480 with Marco Garelli)
- Polars Official Documentation The authoritative guide for Polars usage, API references, and examples.
Overall takeaway
Polars is a compelling alternative (or complement) to the widely used Pandas library, bringing speed, lazy evaluation, and a clean API. Even more exciting is the growing ecosystem of Polars extensions for everything from data validation to fuzzy matching and encryption, making it easier than ever to build high-performance and secure data-processing pipelines in Python. Whether you are completely new to Python data science or shifting from Pandas to a Rust-enhanced solution, this episode highlights the many tools and techniques you can explore to level up your data analytics game.
Links from the show
Polars for Power Users Course: training.talkpython.fm
Awesome Polars: github.com
Polars Visualization with Plotly: docs.pola.rs
Dataframely: github.com
Patito: github.com
polars_iptools: github.com
polars-fuzzy-match: github.com
Nucleo Fuzzy Matcher: github.com
polars-strsim: github.com
polars_encryption: github.com
polars-xdt: github.com
polars_ols: github.com
Least Mean Squares Filter in Signal Processing: www.geeksforgeeks.org
polars-pairing: github.com
Pairing Function: en.wikipedia.org
polars_list_utils: github.com
Harley Schema Helpers: tomburdge.github.io
Marimo Reactive Notebooks Episode: talkpython.fm
Marimo: marimo.io
Ahoy Narwhals Podcast Episode Links: talkpython.fm
Watch this episode on YouTube: youtube.com
Episode #510 deep-dive: talkpython.fm/510
Episode transcripts: talkpython.fm
Theme Song: Developer Rap
🥁 Served in a Flask 🎸: talkpython.fm/flasksong
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Are you using Polars for your data science work?
00:02 There are many benefits to Polars directly, of course, but you might not be aware of all the excellent tools and libraries that make Polars even better.
00:11 Examples include Patito, which combines Pydantic and Polars for data validation,
00:17 and Polars underscore encryption, which adds AES encryption to selected columns.
00:23 We have Christopher Trudeau back on Talk Python To Me to tell us all about his list of excellent libraries
00:30 to power up your Polars game, and even talk a bit about his new Polars course.
00:36 This is Talk Python To Me, episode 510, recorded May 22nd, 2025.
00:58 Check it out, folks.
00:59 we've got a new geeky theme song. I hope you enjoy this fun start to the episode.
01:04 If you want to download the entire mp3, grab it at talkpython.fm/flask song. Enjoy.
01:12 Welcome to Talk Python To Me, a weekly podcast on Python. This is your host, Michael Kennedy.
01:18 Follow me on Mastodon where I'm @mkennedy and follow the podcast using at talkpython,
01:23 both accounts over at fosstodon.org and keep up with the show and listen to over nine years of
01:29 at talkpython.fm. If you want to be part of our live episodes, you can find the live streams over
01:35 on YouTube. Subscribe to our YouTube channel over at talkpython.fm/youtube and get notified
01:40 about upcoming shows. This episode is brought to you by Sentry. Don't let those errors go unnoticed.
01:46 Use Sentry like we do here at Talk Python. Sign up at talkpython.fm/sentry. And it's brought
01:52 to you by Agency. Discover agentic AI with Agency. Their layer lets agents find, connect, and work
01:59 together any stack anywhere start building the internet of agents at talkpython.fm/agency
02:05 spelled a-g-n-t-c-y christopher welcome to talk python welcome back to talk python thank you
02:12 third time's the charm we'll see how it goes it's gonna go well i'm sure um we've got a really fun
02:18 topic lined up i think this is one of those kinds of shows where there's there's going to be something
02:24 for everybody. There might be a lot for some people and there's going to be like, oh, that's
02:29 the thing that made it worth listening because we're going to talk about a bunch of different
02:33 extensions, tools, techniques, et cetera, for working with Polars, one of the exciting data
02:38 frame libraries that we have these days. So super excited to have you here to tell us about that.
02:44 And I'm really interested to hear how it works with Django because that's what you talk about
02:48 and coming, right?
02:50 I honestly, I haven't done it.
02:53 There's no reason it shouldn't, but I have yet to actually combine the two pieces together.
02:59 Well, I have used Flask and Pandas together, so surely Django and Polaris will go together.
03:05 I know actually that they would.
03:07 Shouldn't be a problem.
03:08 I think it's one of the beauties of these kinds of libraries is at the heart,
03:13 although there are rust underneath or other things underneath to get you the performance,
03:17 they're still just Python.
03:20 So, you know, you've got access to the code and you can do what you want.
03:23 Yeah, I think there's probably some combinations that people don't typically think of.
03:27 Like, for example, one of the things that I like to do is I've got some dashboard-y thing,
03:34 either for Talk Python in the course, I can't remember, but I want a bar graph.
03:37 And so I do some matplotlib thing and have it generate a picture and just return that as a picture dynamically at a URL,
03:45 you know, and just set the source.
03:47 to the image to be wherever that thing is generated from.
03:50 So there are really cool combinations, though I suspect we will not be doing much of our typical web stuff this show, will we?
03:57 I'll drop mentions to my book because I have to.
04:01 That's the way it's supposed to work.
04:02 But otherwise, yeah, we'll stick to the data science world this time around.
04:06 Yeah, well, let's start there.
04:07 I know people probably have listened to you on the show or on the RealPython podcast or in other places that you're doing all the things.
04:14 But, you know, tell us about yourself.
04:17 Feel free to mention your book so people know about them as well.
04:19 There you go.
04:21 Yeah, there's an old joke.
04:22 How do you know somebody runs a marathon?
04:24 Well, they'll effing tell you.
04:25 Well, authors are more or less in the same package.
04:28 It's a contractual obligation.
04:30 It is.
04:31 I wrote it about in my book, Chris.
04:32 There you go.
04:33 Exactly.
04:34 That's right.
04:34 And I guess while I've got you on air, you know, thank you for writing the foreword.
04:39 So yeah, I guess now I should sell myself as an author.
04:46 It's nowhere near as impressive as people think it's sound to be.
04:50 I guess I spend my spare time doing sort of Python education-y stuff with you and other
04:56 organizations, and writing is kind of part of that.
04:59 My day job is still helping organizations do technical stuff.
05:04 Sometimes that's architectural advice, and sometimes that's things like Agile and Lean
05:09 process driven things. My marketing people tell me to sell myself as a fractional CTO.
05:15 I have a hard time saying that with a straight face, but you know, got to put it on the brochure. So there you go.
05:20 Well, if you don't want to take it so seriously, you could be an improper fraction.
05:24 There you go.
05:25 You could be like a two ace CTO.
05:28 I'm an irrational CTO. That actually makes sense.
05:34 I'm radical two over seven. Let's go. That's how much a CTO I am.
05:38 More seriously, though, I'm sure there are people listening who find that idea pretty interesting, fractional CTO or sort of fractional something beyond just like low level coder.
05:48 Tell people what that what is that like?
05:50 How do you get into that?
05:51 I got into it because I kind of fell into software management early on in my career.
05:57 There was a company I was at where I was it was a Windows based shop and I was hired as the Unix guy.
06:05 We all had this naive idea that we could port the product to Unix easily.
06:10 So I was their sole Unix architect person.
06:14 After about six months worth of work, we figured out this just wasn't going to happen.
06:18 And my VP got pregnant and went, want to be a manager?
06:21 And basically handed me the keys.
06:24 So I kind of learned by being thrown in the deep end as to how to do the technical management type stuff.
06:30 So my career has always kind of been a bit of a balance between that.
06:33 I like smaller organizations and I like helping them grow. So what that tends to mean is when it's really early on, when you're number two or three, you're coding like a line developer. And as the organization grows, you spend less time doing that. And because I've spent a lot of time in startups, I've done that journey many times.
06:50 So the fractional CTO idea essentially is to try to help smaller organizations that wouldn't necessarily be able to afford a full-time CTO with that kind of thing and sort of provide the kind of advice from things I've learned throughout that process over the years and then sort of help out as you go along.
07:09 And sometimes that's come in with a very specific target of help us architect something.
07:16 And sometimes that's more of a, we need some, it's sometimes referred to as adult supervision,
07:23 where somebody comes in and just sort of offers sort of the process advice, right?
07:30 Right.
07:31 Who's going to be this adult in the room that says, no, we're not rewriting that in a new JavaScript framework.
07:36 It was a third time this year.
07:37 Yeah. And often it's very hard in a startup to concentrate on things like CI/CD and testing and all the rest of it because you're trying to get to market. So it's all about those features. Well, if you don't balance that, it's going to bite you later on. Right. So I try to help with sort of that overall bigger picture as part of the organizations and get them going.
08:00 Cool. Yeah, I find even outside of that kind of stuff, sometimes it's hard to focus on the boring but important features that matter rather than like, hey, wouldn't it be cool if we refactored this or made that faster? Like, it doesn't need to be faster yet until you have more customers. What you need is this other thing, this PDF export that nobody wants to write.
08:18 Yeah. And as developers, you know, like the entertaining part of our job is learning the new thing. And oftentimes that's learning the new library. And sometimes that's great. And sometimes that's wasting a whole bunch of time because the old library would have been just as good and keep sort of plowing along. Right.
08:35 There's a phrase that I stole in my book.
08:38 See, I keep bringing it back to the book.
08:41 People talk about Django being old and it's like the difference between, you know, it's a dinosaur.
08:45 No, no, it's a shark.
08:47 They're still around.
08:48 They're still valuable.
08:49 They're just as old as the dinosaurs, but they're still part of the ecosystem.
08:56 Interesting.
08:57 Hopefully, you know, the gray hair at the temples here helps me provide a little more insight into that than, say, somebody fresh out of school.
09:07 Mm-hmm.
09:07 Yeah, you see those gray hairs?
09:09 That's C++.
09:10 Exactly.
09:14 Yeah, indeed.
09:14 Okay.
09:15 Well, let's talk data science and let's talk Polars.
09:18 So I guess there's a lot of people who have heard of Polars and are experts.
09:23 I see out in the live audience already.
09:25 There are some folks whose things they've created for Polars we're going to talk about in this show, actually.
09:31 So some people need no introduction to Polars.
09:34 But there are many people listening to the show who are just getting into Python, using this as one of the footholds to kind of get a feel for the space.
09:42 And they might go like, what is Polars?
09:44 Sure.
09:45 You know?
09:45 And what's a data frame?
09:47 Like, tell us about this.
09:48 Yeah, I was about to say, before we get to the Polars, maybe we should just start with a data frame.
09:52 So a data frame is kind of an in-memory spreadsheet sort of thing.
09:55 It's a data structure that consists of rows and columns.
09:58 And you do the same kind of things that you might do in Excel, but in your code.
10:04 There are a whole bunch of advantages to doing it in your code over doing it in Excel.
10:07 And in fact, the course that we're going to talk about gets into some of that.
10:11 But there are a bunch of different libraries out there that help you do this.
10:14 The big one that has been around for probably the longest and is the most popular is Pandas.
10:21 Pandas has made some interesting design decisions.
10:25 And as a result, there are some other more recent additions to the space that are trying to address some of those things that Pandas has done.
10:34 And Polars has become one of the more popular ones.
10:37 I saw just as we kicked in here, there was a comment already about, I like the coding style of Polars better than Pandas.
10:43 And this to me, this is also why I actually prefer Polars.
10:47 The interface to it is a lot more like object-oriented code, and it feels more Pythonic to me.
10:56 And as a result, it tends to be one of the libraries that I now head towards if I need to muck with a bunch of data and do those kind of data framey things.
11:05 It is almost every benchmark out there has marked it as being significantly faster than Pandas.
11:12 So that's a nice little advantage.
11:14 And it also includes methods to convert your data into pandas and other data frames as well.
11:22 So if you do get stuck and there's something that isn't there and because it's a newer library,
11:27 you can always just go, oh, give me the pandas version of this, run my pandas commands,
11:31 and then bring it back into the polar space where you make it a little more comfortable.
11:35 So it's a nice...
11:35 Right, it's two pandas and a from pandas sort of thing, yeah.
11:38 Yeah, and so it's a nice flexible sort of approach and it's a quick bear.
11:43 And one of the things I find, I'm not trying to dump on Pandas.
11:48 It's going to sound like that occasionally, but I really do.
11:51 I like the library.
11:52 It's very, very powerful, very, very useful.
11:54 It uses a lot of black magic.
11:56 And I find as a developer, as somebody with a software engineering background, sometimes
12:02 code can be distracting where you look at it and go, how does that even compile?
12:05 What is that?
12:06 What are they doing?
12:07 And that pulls me away from the, I'm trying to do something.
12:11 And I find some of the stuff in Pandas kind of falls into that bucket.
12:14 Whereas you just do nice little chained function calls in Polars.
12:18 And so you're reading, you know, filter, select kinds of things.
12:22 And it feels a lot cleaner to me.
12:25 So it tends to be where I want to go.
12:28 And then the other big advantage of it, which some of the other data frame libraries have,
12:33 but Pandas, as far as I know, doesn't, is lazy evaluation.
12:37 And this is the idea of rather than executing each operation as you call it, you can chain a bunch of things together and then call them all at the same time.
12:46 This tends to give you large amounts of speed up.
12:49 So, for example, if you're reading in a CSV file and you want to do something only on certain rows in that CSV file, the filter can throw those rows that aren't important.
12:58 And then you would only run the operation on those rows that you were interested in.
13:03 Of course, that tends to be an awful lot faster than going through every single row at a time.
13:08 It also tends to use less memory for the same reason, because you don't have to keep as much in memory at any given time.
13:15 So lazy evaluation can be a really, really powerful tool, particularly if you're using with really, really large data frames.
13:22 So that to me is, you know, the coding style was a nice selling point.
13:27 But being able to see that performance difference with the lazy evaluation was really what hit it home for me.
13:33 Yeah, they're both super cool. You know, I talked to Richie Bink, who is a creator of Polars, about three years ago or so on the podcast. And it was very interesting to talk about some of the philosophies. So, for example, the lazy evaluation is great because you could theoretically change the order. Like if I'm going to do some complicated math computation on a thing, we'll talk about some of those.
13:56 And then I'm going to filter it down based on some unrelated criteria like state or whatever, gender, who knows, and then get the answer.
14:05 If I did that in pandas, it would do the math on every single thing and then filter it down and give you the answer.
14:10 And maybe take the US as an example, that might be one fiftieth of the data that you wouldn't have to multiply.
14:16 So with Polars, it can even optimize.
14:19 Well, if there's a filter, do the filter first and then the calculation.
14:22 Yeah.
14:23 So it's got kind of an optimizer built in there as well.
14:26 This technology is very similar to what happens in databases.
14:30 So if you're doing more complex SQL, behind the scenes, the database for you goes and tries to optimize that to try to figure out what the best way of doing this for you.
14:39 And Polars has that built in as well.
14:42 It's got it built in on your calls specifically.
14:46 So you can take advantage of that even if it isn't the lazy evaluation.
14:49 But it can really, really shine in the case of lazy evaluation.
14:52 So if you're doing a complex query all in one chunk, like a group by with a bunch of different aggregates,
14:57 it does still do the same thing, which again gives you one of the ways that it'll speed up.
15:02 But particularly with lazy evaluation where you might chain together 15 or 20 calls,
15:08 it'll figure out for you what the best order on that is and that can make a big difference.
15:12 You can also see what it wants to do and what its execution plan is.
15:19 I don't understand the output.
15:24 it's deep relational algebra but for those who are into this stuff you can actually see exactly what it's doing
15:31 and it gives you a little peek behind the curtain this portion of Talk Python I Me is brought to you by Sentry
15:40 over at Talk Python Sentry has been incredibly valuable for tracking down errors in our web apps
15:46 our mobile apps and other code that we run I've told you the story how more than once
15:50 I've learned that a user was encountering a bug through Sentry and then fixed the bug and let them
15:55 know it was fixed before they contacted me. That's pretty incredible. Let me walk you through the few
16:00 simple steps that you need to add error monitoring and distributed tracing to your Python web app.
16:06 Let's imagine we have a Flask app with a React front end and we want to make sure there are no
16:10 errors during the checkout process for some e-commerce page. I don't know about you, but anytime
16:16 money and payments are involved, I always get a little nervous writing code. We start by simply
16:21 instrumenting the checkout flow. To do that, you enable distributed tracing and error modern train
16:26 in both your Flask backend and your React frontend. Next, we want to make sure that you have enough
16:32 context that the frontend and backend actions can be correlated into a single request. So we enrich
16:38 a sentry span with data context. In your React checkout.jsx, you'd wrap the submit handler in a
16:46 ban call. Then it's time to see the request live in a dashboard. We build a real-time Sentry dashboard.
16:51 You spin up one using span metrics to track key attributes like cart size, checkout duration,
16:56 and so on, giving you one pane for both performance and error data. That's it. When an error happens,
17:03 you open the error on Sentry, and you get end-to-end request data and error tracebacks to easily spot
17:09 what's going on. If your app and customers matter to you, you definitely want to set up Sentry like
17:14 we have here at Talk Python.
17:16 Visit talkpython.fm/sentry and use the code TALKPYTHON, all caps, just one word.
17:22 That's talkpython.fm/sentry, code talkpython.
17:26 Thank you to Sentry for supporting the show.
17:30 With databases, there's usually some way to ask for what's called an explain.
17:35 Like you got some query, instead of saying run the query, parse it and do the optimizer
17:39 and then tell me what you would do.
17:40 And that can be really helpful for saying like finding an index or something.
17:43 Yeah.
17:44 Is it actually using this index or is it not?
17:46 But then there's something like that in polars as well, yeah?
17:48 Yeah, and it calls it explain as well.
17:50 So when you've got the lazy object, you can call explain on it and it'll show it.
17:55 It also has a graphical equivalent, so it'll spit out a little image, that sort of flow chart-y kind of thing that shows you what it is as well.
18:03 So if you prefer the pictures over the obscure Greek letter references, then that can show you what's going on.
18:11 Yeah, very nice, very nice.
18:12 All right.
18:13 Well, we are going to not talk about the exact subject of your course that you wrote, but I think we should maybe give it a quick shout out.
18:23 So your course that you wrote at Talk Python is Polars for the Power Users, Transform Your Data Analysis Game.
18:29 What we're going to talk about is a bunch of different cool tools that extend and power up polars.
18:35 But if people are interested in learning polars more from scratch, they could take your course.
18:39 So I'll be sure to link to that in the show notes.
18:40 Maybe give people a super quick rundown on what's on the course, and then we'll talk about all the items.
18:47 Sure.
18:48 As you might guess from the title, it kind of teaches your Polars.
18:51 And you can see on the screen there, there's a bunch of different icons as well.
18:56 What we're trying to do is essentially take you to that next step.
19:01 So if you're doing data science-y stuff in Excel and you're trying to figure out how to move to the Python world with this,
19:09 then this is kind of a course to try and help you do that.
19:13 And it does it through the Polars library.
19:15 So there's a whole bunch of different examples as you go along.
19:18 A lot of the examples will start with, hey, here's a spreadsheet.
19:21 Here's a thing that you're doing in the spreadsheet.
19:23 Here is how you would do that with the Polars library and Python code instead.
19:29 And why you might do that instead of doing a spreadsheet.
19:33 Polars has this concept of expressions and filters.
19:38 And they're the ways of performing operations on your data and then looking at different columns or different rows.
19:44 So the course starts out there and then starts getting even deeper into real world examples.
19:51 The final lesson is actually a case study.
19:54 We took a bunch of the GDP data from the United Nations and showed you how to clean some of it, how to combine it.
20:05 whenever you've got data in the real world, even if it's from the same source,
20:09 you're going to go, oh, I want this information from this column and that information from that column,
20:13 but they aren't related.
20:14 So now we have to cross-reference.
20:16 So it covers how to sort of do all of that kind of stuff.
20:18 So it's sort of this journey of how do you take some of the more basic CSV
20:24 and Excel type stuff and change it into Python all the way along the line
20:28 to how do we actually create a report on data from the real world using Polars as your library for doing it.
20:36 Excellent.
20:37 Yeah, it's also very funny.
20:38 A very funny course.
20:39 I enjoyed it.
20:40 Okay.
20:41 Polars is pretty awesome, wouldn't you say?
20:42 Yes, that's a nice, you know, there you go.
20:46 How's that for a segue?
20:48 Pretty awesome.
20:49 In fact, let's reverse that.
20:51 We're going to talk about awesome Polars.
20:52 So there are so many of these awesome lists out there.
20:56 And, you know, if you are interested in something and you haven't looked yet for an awesome list for it,
21:01 go do that.
21:02 There's got to be an awesome Django.
21:04 I know there's got to be an awesome Flask.
21:06 There's an awesome Async.
21:07 There's an awesome Python.
21:09 And Ddata has gone and created awesome Polar.
21:12 So what we're going to do is we're going to go to this curated list and pull out 10-ish number of things that we think would be really interesting.
21:22 On the order of 10, yes.
21:22 We didn't count.
21:24 One of these days we'll start prepared.
21:26 Well, my tabs scroll off the screen, so I can't even count them.
21:30 So there we go.
21:31 But no, something on that scale.
21:32 We're going to go through a bunch of different little things that are great.
21:34 And for me, I just, like I said at the opening of the show, I really like these because it's
21:37 like, oh, it's not a big deal, but it just made all of my work way easier and is really
21:42 easy to adopt.
21:42 A lot of these things are actually not huge commitments.
21:46 It's not like redo your data stack in some other data frame library because you'll get
21:50 some benefit.
21:51 Like, no, you just plug this thing into your puller's work you're already doing and it's
21:54 really good.
21:55 So with that, let's start out on visualization.
22:00 What do you think?
22:01 Sure.
22:02 Yeah, and this one's almost independent of Polars.
22:05 I guess there's sort of this whole category of things that are already in the data science space.
22:12 And what is specific to Polars is the good news, which is Polars works with all those tools that you're used to working with.
22:19 So if you're already playing with Matplotlib or Seaborn or any of those, Polars will integrate with it just like Pandas does and most of the others.
22:27 Polars does have sort of specific integrations with Altair and HVplot.
22:33 So there's built-in calls on the data frame that essentially say, go plot this and they will use those tools.
22:38 But even if you don't want to use those, getting at a column, slicing a column out,
22:44 and then handing that column down to Matplotlib works more or less just like Bandus does.
22:49 So this integration works quite nicely.
22:52 Likewise, with tools like Jupyter or Marimo, again, this isn't really Polar specific,
22:57 but there's nothing in Polars that stops you from using these tools.
23:00 And so, you know, you're not, you know, if you're moving from pandas, this isn't a stopper.
23:09 All the other things, you don't have to learn everything else from scratch.
23:12 Everything you bring with you will continue to work without any problem.
23:16 Yeah, so on the Polars docs, we've got examples for HVPlot, MapPlotlib, Plot9, Seaborn, Plotly, all these things.
23:23 And yeah, they look great.
23:24 Have you played with Altair much?
23:25 You know, I've not played with Altair much. I think I've done mostly Plotly and Seaborn lately.
23:31 Okay. Yeah. I still, I have a love-hate relationship with Matt Plotlib. I'm usually too lazy to learn anything else and I grumble every time I use it because I can't remember how to set X underscore or set underscore X and it drives me crazy. But it gives you results and that's what's important.
23:50 For sure. So you mentioned it, Marimo. I recently covered, talked with Akshay from the Marimo team. I'm impressed. I am super impressed with the way that Marimo came out, the way it looks. It seems like a really nice, just a very nice modern Jupyter style. What do you think of it?
24:09 So I've yet to play with it. I've done a bunch of reading on it. The theory behind it is something
24:15 that is beautiful to me. I actually don't use Jupyter. And the big thing, this big stopping
24:20 thing for Jupyter for me is it doesn't feel like it scales. And that's because the cells are stored
24:26 as JSON. So it's a great tool like a REPL where if you're experimenting with something, it's
24:31 fantastic. But as soon as you're trying to start doing that on a team, it can be problematic because
24:36 now you're trying to merge those JSON pieces. It doesn't work very well. And Marimo has essentially
24:42 tried to solve this from the ground up. Instead of creating JSON to store everything, it's actually
24:48 creating Python output, which means the documents that you're creating in Marimo actually can be
24:54 managed just like any other code. And although I haven't played with it myself, the theory behind
25:02 that to me is very, very beautiful. And the next time I dive into this space, this is definitely
25:06 going to be the one I'm going to be playing with. Yeah, it looks great to me too. I think even just
25:11 from a visual, like the way the UI works, I really, really like it. The other thing in addition to the
25:17 Python backing instead of the JSON backing in, as in file storage, is the reactive bits. Like one
25:25 of the things that always scares me about notebooks is like it can go one, five, two, seven. Yeah.
25:31 And you don't even know what happened into the like number six one, right?
25:35 But it affects the way the notebook runs.
25:38 Like it's kind of like go-to statements in it, but you get to pick randomly.
25:42 And this has a way to say these cells depend in this order.
25:44 And so there's a automatic refresh and stuff.
25:47 Anyway, bit of a diversion, but I think it's worth paying attention to.
25:51 Okay, where were we again?
25:52 Well, next thing we want to talk about is DataFramely.
25:58 Claritive, Polars native data frame validation library.
26:02 So the data science, the first 80% of your work is cleaning the data and getting it into the right shape.
26:09 And then the second 80% of your work is coding.
26:12 And then there's that last 80% of the work, which is output.
26:16 I think my math might be off there.
26:19 It feels like it's right, though.
26:20 It feels that the reality is true, though.
26:24 And what DataFramely helps you do is that first 80%.
26:29 So this is from a group of folks at a company called Quantco, and they're a data science consulting firm.
26:36 And it works a bit like Pedantic or DjangoRM.
26:40 See there, I brought it back.
26:42 There's a book on that.
26:44 So you can create a data class-like object here, which inherits from DataFramely's schema class.
26:50 And inside of that, you declare what your expected columns in a data framework.
26:55 So for example, you could specify a weight, something that is a weight, like heavier light is a float value
27:04 and an American zip code is a string.
27:06 And in addition to that declaration syntax, you can also write rule methods on the class
27:12 to give you more complex validation code, like this plus this have to be,
27:18 these two values have to work together or these two values have to be unique
27:21 or those kinds of validation pieces.
27:23 Now, once you've got one of these schema objects, you then call its validation method, passing in your data frame.
27:29 And if the results are clean, you get back your data frame.
27:31 And if they aren't, you get an exception that describes each validation, telling you what rule failed, what rows it failed upon.
27:39 And there's also a soft validation mechanism called filter, which returns a data frame with the rows that passed and a failure info object with the rows that went wrong.
27:50 So if you don't want to just sort of stop because it's too bad, you want to react to the parts that aren't, you can dig in and sort of go from there.
27:59 So this is a nice little piece and it can definitely help you.
28:04 It doesn't fix the dirty data, but helps you detect it, which of course is your sort of first step as you go along.
28:10 Yeah.
28:11 One of the real challenges you can run into is the data, it parses or something, right?
28:18 Yes.
28:18 And so then math works.
28:20 But at the same time, that's not necessarily giving the right answers.
28:24 And you've got to figure out, well, why is this not working?
28:27 Yeah.
28:28 In fact, in the course, one of the examples we use, which is what you've got up on the
28:31 screen here as well, is oftentimes people will put an American zip code, which for our
28:36 non-American friends is a five-digit number or could be a nine one, which that just makes
28:41 it messy.
28:42 But let's stick with the five digits for now.
28:44 Well, it could have a leading zero.
28:46 Well, if you've stored that in, say, Excel as a number, then that leading zero gets chopped.
28:52 And now all of a sudden you've got this four digit thing, which isn't a valid zip code.
28:56 And so as part of your data cleaning, you have to detect that or as part of loading the file.
29:01 And you might have to say, hey, wait a second.
29:03 This shouldn't be an integer.
29:05 Please load this as a string.
29:07 And so what these validation mechanisms allow for you is to help you sort of catch this.
29:12 And so, for example, if you were processing that failed info object and the only things that failed were zip codes, well, then you could have some code in there that went, okay, I'll just make sure that I fix the padding on this and maybe deal with it automatically as part of your data pipeline.
29:28 Yeah, you can do something like this to catch it potentially.
29:32 This portion of Talk Python To Me is brought to you by Agency.
29:35 The Agency, spelled A-G-N-T-C-Y, is an open source collective building the Internet of Agents.
29:42 We're all very familiar with AI and LLMs these days, but if you have not yet experienced the
29:48 massive leap that agentic AI brings, you're in for a treat. Agentic AI takes LLMs from the world's
29:54 smartest search engines to truly collaborative software. That's where agency comes in. Agency is
30:00 a collaboration layer where AI agents can discover, connect, and work across frameworks.
30:06 For developers, this means standardized agent discovery tools, seamless protocols for interagent communication, and modular components to compose and scale multi-agent workflows.
30:18 Agency allows AI agents to discover each other and work together regardless of how they're built, who built them, or where they run.
30:25 And they just announced several key updates, including interoperability with Anthropics Model Context Protocol, MCP,
30:33 a new observability data schema enriched with concepts specific to multi-agent systems,
30:38 as well as new extensions to the OpenAgentic Schema Framework, OASF.
30:44 So are you ready to build the Internet of agents?
30:47 Get started with agency and join Crew AI, LangChain, Llama Index, BrowserBase, Cisco, and dozens more.
30:54 Visit talkpython.fm/agency to get started today.
30:57 That's talkpython.fm/agency.
31:00 The link is in your podcast player's show notes and on the episode page.
31:04 Thank you to the agency for supporting Talk Python.me.
31:08 It's weird the shadow that Excel casts, especially onto the data science world.
31:14 I'm thinking of how, or even science in general, there was some gene as in...
31:18 I was just about to mention the same example.
31:21 I think it was like MAR223 or something like that.
31:25 But if you put that to Excel, it's like, oh, March the 2nd?
31:28 You're like, no, no, no, no, no.
31:30 Yeah, yeah, yeah.
31:32 And in fact, even Polars to a certain extent has some of those kinds of problems.
31:40 The routine that you use to read in a CSV, because CSV files don't actually have data type information inside of them,
31:46 it essentially makes a guess.
31:48 And it uses, I think by default, it's like the first thousand rows of the file to make an educated guess as to what the data types are.
31:56 And what can happen is, let's say your data is consistent in the first thousand rows and then row 1001 has something else.
32:04 Well, then it's going to die because it'll say, well, this is an integer and now you're giving me a float.
32:10 And because it didn't detect that this was supposed to be a float in the first place.
32:14 Now, the difference between Polars and Excel is Excel will just keep chugging along and
32:20 you may not discover that you've caused yourself this problem, whereas Polars actually expects
32:25 those columns to be a data type.
32:26 So it'll scream.
32:28 And part of your data cleaning process would be to catch those kinds of things and fix
32:32 that.
32:32 Yeah.
32:33 I mean, spreadsheets are awesome.
32:35 They're really cool, but they get overused.
32:38 Like I was doing something where I had a bunch of dates in a column and I'd selected all
32:41 of them just to copy them.
32:43 But, you know, at the bottom it says, here's the sum of this or whatever.
32:46 It told me like the sum of these 20 dates was like March 12th of some.
32:52 I mean, nope, don't think it is.
32:53 But, you know, okay.
32:54 If you.
32:55 Well, the beauty of the spreadsheets is they're very, very flexible.
32:59 And the pain of a spreadsheet is they're very, very flexible.
33:03 And so, you know, it's, yeah, you could end up missing some toes depending on where you're pointing the gun.
33:09 So one of the challenges, for example, with your zip code example is maybe the first thousand rows are West Coast people.
33:15 So every number looks like a five digit proper number.
33:19 But after that, you get to East Coast people, which start with zeros because it goes old to new, I guess, is the way they came up with it.
33:27 And that could be a challenge, right?
33:28 Even just simple stuff like parsing that.
33:30 OK, what is up next?
33:32 So we go on the patio and have this conversation.
33:34 Yeah, so essentially, just as a quick aside, there are a couple different libraries that essentially do the same thing as what we just talked about.
33:41 Patio, Petito, I'm not sure how you're supposed to say this, which wasn't actually on the awesome pullers list, but it's one I've come across before.
33:50 This is by Jacob Gerard Martinson, and it's built on top of Pydantic.
33:55 Like with DataFramely, you declare a class inheriting from a model, then validate against it.
34:00 The twist on this one that I kind of liked is it also has a mechanism for generating data.
34:06 So if you're writing unit tests, once you've got this validator, you can go through and say, oh, give me some data to unit test with.
34:12 And it will give you data that complies with your model.
34:16 So I thought that was kind of an interesting little twist for helping you build your pipelines.
34:21 Yeah, it's super neat.
34:22 If you're a fan of Pydantic, this looks really, really cool.
34:25 You get basically the type of errors you would get parsing JSON with a Pydantic model.
34:31 It's the exact same error messages you get, but for data frame validation.
34:34 So I think that that's pretty cool.
34:36 Yeah, so it's nice and familiar.
34:37 Yeah, definitely.
34:38 If you're a FastAPI person or Pydantic for whatever reason.
34:42 Also, Patito, not patio, I suspect it probably is.
34:46 I want to start a trend.
34:47 I want to try to put something out there in the world for people.
34:50 If you've got something that could have multiple pronunciations, put just a little MP3 or something in your repo.
34:58 It sounds like this.
35:00 You know what?
35:01 I'm not sure that that's helpful because you remember the whole how do you pronounce Linux debate back in the 90s?
35:08 One of the, I think it was Slackware distribution I had, came with an MP3 of Torvalds pronouncing it.
35:15 And of course, with his accent, it didn't solve the problem.
35:17 So I'm not sure that MP3 is actually the answer.
35:22 Maybe just a little hyphenated where you want to put the stress of it.
35:26 So yeah, I think I saw a GIF or was it a GIF about it?
35:30 I don't know.
35:30 Yeah, exactly.
35:31 That's right.
35:32 Just something to help us figure it out.
35:35 That gives us a fight about on the internet.
35:37 Yeah, that's right.
35:38 Let's make memes about it.
35:39 Okay.
35:40 So the next one is Polars IP tools.
35:42 Pretty sure that's how we'd say this for you.
35:44 Yeah, this one's less debating.
35:46 Yeah.
35:46 So this is a library by Eric Hutchins.
35:49 And if you're playing with IP addresses, this could be helpful to you.
35:53 It essentially provides a bunch of data frame methods for mucking around with IP addresses in a column.
35:59 One of the functions it provides is private.
36:03 This returns true if the address is a private network.
36:06 So if, you know, 192, 168 or one of those groupings that's private, then you get true or false based back from it.
36:12 Another method is in.
36:15 So you give it a list of addresses with masks, and then it'll give you true or false for every IP address as to whether or not it's in that specific group of ranges.
36:25 The library also integrates MaxMind's GeoIP address database, if you've got access to that, as well as the Spur VPN database, which contains information about what's a proxy, what's a VPN, that kind of stuff.
36:37 So if you're doing a whole bunch of log management and you're dealing with all those IP addresses
36:44 that are coming in your logs and you want to use pullers to muck around with that and create
36:48 reports, then IP tools might be helpful for some of that kind of stuff.
36:51 Yeah.
36:51 If you're doing online sales, you want to know where the sale is coming from or where's
36:55 the interest coming from, say for marketing, this would be super valuable.
36:59 Once a sale happens, often you can say, well, they put their address or zip code or credit
37:04 card information we can see that but there's way more traffic upstream from that that doesn't
37:08 necessarily buy things right you can see where the interest is and and so on i actually don't use this
37:13 library but i use the max mine stuff over at talk python because when you come to visit a course i
37:19 want to show it in your currency well what is your currency well it belongs to your country
37:23 what is your country you probably haven't told me but i know your ip address so let me see if i can
37:27 figure that out and at least get it right most of the time so yeah this is cool right fuzzy match
37:33 So this is great.
37:34 Who's geese?
37:35 Which is it?
37:35 Which am I finding?
37:37 Exactly.
37:37 So from moving from IP addresses, which are very specific strings to some more generic ones,
37:44 the Polars Fuzzy Match Library does kind of what you would expect from its name.
37:48 The GitHub user's name was bnmock3.
37:52 He didn't write it as his full name.
37:53 So that's what we're going to go with.
37:56 His avatar or their avatar is delightful.
37:59 iSquare symbol non-ASCII characters, which is funny. So if you're not familiar with fuzzy matching,
38:06 it's about approximate matches on a string. So this library comes with a function that returns
38:12 a score based on the thing that you're matching. So let's say I had a series of strings that I
38:16 wanted to match against the word car, and that list had care and card in it. Those are close,
38:23 so they might have a score of like 80 something. Well, frog, which has nothing in no relationship
38:29 shift a car that scores a null. So this allows you to sort of see how close you are. And the fuzzy
38:37 matching routine that they're using is based on an underlying Rust library called Nucleo,
38:43 which comes out of the Helix editor. So it's supported in a whole bunch of different ways.
38:48 This isn't just some random guy on the internet. And it also has a bunch of strength, a bunch of
38:54 ways of specifying patterns like submatches starts with suffix matches, inverted matches,
39:01 and more. I kind of like the suffix match feature. So it allows you to do fuzzy matching just on,
39:06 say, the suffix part of the extension part of a file name and ignore the rest. So you can,
39:11 you know, whether they mucked up MP3 or MP4 or whatever. So that's kind of a neat little piece.
39:17 And then along the same lines, the next one's Polars STR-SIM.
39:23 It is, so fuzzy matching is based on something called a distance calculation.
39:28 And this essentially takes two strings and then gives you a value for, typically it's between one and zero as to how close they match.
39:37 So if they're identical, it gives you a one.
39:39 And if they have nothing in column, it gives you a zero.
39:43 The most popular of these is Levenstein distances, but there are other ways out there.
39:49 The Jacquard, for example, or the Sorensen dice or whatever.
39:54 Yeah, I wasn't even going to attempt that.
39:56 So thank you.
39:59 These kinds of calculations get used in things like, say, spell checking software.
40:02 So if you've got something that isn't in the spelling dictionary and it wants to make a
40:07 suggestion, then what it does is it runs one of these kinds of distances on a bunch of
40:11 words in the dictionary and those values that are close are the suggestions that it'll give you.
40:16 So the Polars STR sim library, which is from a fellow Canadian, Jeremy Foxcroft,
40:21 allows you to calculate these string distances on your data frames. As you mentioned, it supports a
40:28 whole bunch of mechanisms, which I'm not even going to pretend to pronounce. And each of the
40:34 calculators basically takes two column names and then calculates the distances between them,
40:39 which makes it really easy to include in something like a with_columns call
40:43 so that you can just sort of add this to your data frame and go along with your distance information.
40:47 So if you're trying to do partial matching, either of these two libraries could be helpful for you.
40:52 Yeah, they seem really great.
40:54 Just a little bit of a side note here.
40:55 I think this is an interesting pattern with this Nucleo Rust library that is actually kind of the foundation of the Polars Fuzzy Match, right?
41:04 I think this is something people should kind of keep their eye on out there.
41:08 like okay so this is not super popular but you might think well maybe it's not going to work that
41:14 well but if it's just kind of a wrapper around something that is super popular right an example
41:19 would be um granian i had giovanni on the show to talk about the granian python production worker
41:27 process thing and it's getting pretty popular 3.5k but you know you look at say uveacorn or something
41:33 like that but then really what it is kind of a wrapper around hypercrate well hypercrate is way
41:38 popular written in rust right used by 360 000 projects and 400 contributors like oh okay so
41:45 brand is kind of like an interface to hyper in a sense right and that's also a little bit what's
41:50 going on here and so when you're evaluating these libraries i think that's worth keeping in
41:55 mind what do you think yeah no for sure like it's um you know not that you can't not that you can't
42:00 create bugs in in a wrapper because you can create bugs in anything but uh you know the less code the
42:06 less likely there's a problem. And, you know, if it's built, if it, like you say,
42:10 if it's just a thin veneer on something that is big and popular and well-maintained, then,
42:15 you know, the fact that it's a thin veneer becomes less, less important.
42:18 Right. Right. Like, well, that veneer is not that popular. Like that veneer doesn't matter
42:21 that much. Okay. Maybe you should encrypt it though. If it had some sort of data,
42:25 you should encrypt it.
42:26 There you go. And this, this is another one actually that, you know, we'll pretend we
42:30 planned that. so this is another one, which is a thin veneer. so if you want to be sneaky
42:35 with your text here.
42:38 Niazi Garagashli, which I'm sure I'm butchering, has written Polars Encryption.
42:43 This library incorporates AES ciphers into Polars, providing encrypt and decrypt functions
42:48 as expressions.
42:50 So if you're mucking around with, say, personally identifiable information,
42:55 or you're just like sending other data scientists secret messages about your pointy-haired boss,
42:59 then this little veneer could actually be fairly useful to you.
43:02 Well, I'm thinking of maybe there's encryption at rest type of stuff you want to be having going on.
43:09 You know, there's a lot of different file formats that you can save in, right?
43:13 I mean, there's CSV or Excel, but you don't really want them necessarily.
43:16 You're doing like native folders, right?
43:18 We have Parquet, PyArrow, other better types, right?
43:23 So maybe you import some data and you then encrypt it.
43:26 So that file sitting on disk, somebody grabs it like, so what?
43:30 I mean, your app still has to know the encryption key and maybe decrypts it in a data frame and memory.
43:34 But it's a really nice sort of back and forth library for that, right?
43:37 Yeah, and data frames are a perfect place to do that kind of thing.
43:40 Prescription tends to be expensive, but data frames tend to be fairly fast about that kind of stuff.
43:48 So you're going to outperform using a mechanism like this that's built underneath as a Polaris plug-in
43:53 than, say, building a loop yourself and doing it.
43:57 So it tends to, like you said, it gives you that safety, but it gives you it in a way that's a little speedier than doing it yourself.
44:04 Yeah, I don't remember if I spoke to Richie about this.
44:06 Maybe I did, but I don't remember what he said if I did.
44:09 That's for sure.
44:11 Does Polars do parallelism automatically, or is there a way to ask it to do it easily, right?
44:17 Because this encryption per entry in a column is one of the embarrassingly parallelizable algorithms, right?
44:24 I know there are async pieces underneath.
44:26 I haven't played with them myself, so I'm not sure exactly how you trigger that.
44:32 I know, so Polars itself, although it's very much a Python library, the part of it underneath is still Rust.
44:40 And I believe that has been built so that you can get some of that concurrency.
44:44 I don't know how easy it is to just turn that on.
44:47 It hasn't been something, you know, one of the things with concurrency, it's actually what I did my master's degree in.
44:55 And the only thing I really remember is really, really don't do it unless you absolutely have to.
45:01 And, you know, I routinely ingest a million rows with Polars in a sub-second.
45:07 So I've yet to need concurrency because the size of the data stuff that I deal with isn't in that petabyte range where it actually would start to matter.
45:16 So there are mechanisms there, but I can't speak to them very well.
45:19 Yeah, I haven't done them either.
45:22 So time to move on?
45:24 Yes, time to move on.
45:24 Apparently, yeah, apparently there are ways to do it, but it's not worth going over in audio.
45:29 Okay, let's move on.
45:32 xdt so sorry yeah i was i wasn't being snarky there i was no no i know of course this is a date time functionality library uh and it actually comes from the
45:47 polars folks so i think what they're kind of doing here is kind of like that contrib thing
45:51 inside of django which is yeah we don't really need this we'll keep it separate but if you need
45:56 it's there it essentially is a collection i think it's like a 10 or 12 uh functions that essentially
46:02 are extra date stuff for example last one was um last commit was by marco corelli who's been on the
46:08 show before yeah there you go uh so for example the date range function returns a series of dates
46:14 and can be used to populate a column in data frame so it takes a start and end date as arguments and
46:19 then will work with a variety of intervals and allows you to ignore weekends and holidays so
46:24 if you want to generate like a time series kind of thing, this will do that. The day name function
46:30 returns the name of the day of the week, supporting localization. Similarly, there's format localized,
46:36 and I think there's other stuff for months and things like that in here as well. The one I kind
46:40 of liked, I've done a couple courses on astronomy because a colleague of mine is working on his
46:47 degree in this space. And so it always fascinates me when you move sort of sideways in a science and
46:54 you're doing what? So this library supports calculating a Julian date, which is kind of
47:00 like a Unix epoch, except day one is in 4713 BCE. And although this is fun for history buffs,
47:09 it gets used in astronomy so that they can do time lapse calculations as simple addition and
47:14 subtraction. And so it's like Julian one versus whatever we're in now, which is Julian 6000
47:20 in something. And so if you're as strange as this may seem, if you happen to be working in that space,
47:27 this plugin allows you to switch between Julian and back and forth. And then of course, Julian
47:33 dates also mean something completely different. So that gets confusing as well, but you know,
47:37 welcome to software. And welcome to date times and software for sure. Yes. We have double so in
47:43 date time. Yeah. So there's some interesting things here and I have some real time follow
47:46 up here in a second. So it says blazing fast written in Rust convert to and from multiple
47:50 time zones, which is great, format date time zones and different locales, dueling dates. And then
47:56 there's a couple of things that are crossed off and say they've been upstream to polars, which is
48:00 really cool. It's like, actually, this turns out to be important enough. It should just be in polars.
48:05 So there's this cool interplay here for sure. Yeah, I'm pretty sure this is somebody's playground.
48:10 So I think they're maintaining it separately. And I think if it's something that's popular enough,
48:14 it'll move up but uh and it is in the GitHub sorry it is in the GitHub uh polars repos not
48:21 the organization not just some yeah yeah and that was kind of what i was about to say right back to
48:25 your question about sort of a trust thing well the people who write the library when they write
48:29 another library to go with it you're probably okay absolutely um marco garelli this my real
48:35 time follow-up says hey some of these didn't fit into polars because they would have increased the
48:40 size of the binary too much due to extra dependencies right so that's great like too
48:45 heavy weight but let's make it an extra so yeah pretty cool that's a good reason to do it yeah
48:50 yeah indeed all right let's go and talk statistics a bit yeah what's the chances of that huh so so
48:57 from making that from from simple math to harder math yeah uh so let's say you're doing some audio
49:05 signal processing and you need to pull some of the frequencies out or you want to try and remove some
49:11 noise this process is called filtering one way of doing this is to use something called a least mean
49:17 square filter which is a special calculation that tries to minimize the mean square of the error
49:23 between the signal and the desired result you too can sound like you know what you're talking about
49:28 by reading a wikipedia entry into a microphone so uh if most of what i said was meaningful to you
49:34 then the Polars OLS library might be your thing.
49:38 This is by Azmi Rajab and performs least mean squares calculations using a variety of different mechanisms.
49:45 Allows you to do this on at, it allows you to do this as a Polars expression.
49:49 And of course the underlying code, like a lot of these are as Rust based.
49:53 So it's nice and snappy performance wise.
49:55 The expression even includes different ways of dealing with nulls, which is one of those things
49:59 that gets in the way with real world data.
50:02 So this library strikes me as one of those things will save someone a whole lot of time so if you happen to be that someone there you go yeah it's
50:10 excellent i you know i think in data science there's a lot of this tension of do i actually
50:16 need to know the algorithm and the details of this or do i just need to know that i can call
50:20 this function and when i should and when i should call it and i think that's a valid tension right
50:26 because if something you call it on the wrong data and you get the wrong answer but you're like
50:29 look i've discovered life on another planet oh no i discovered dust or whatever right you know it's
50:36 um i was uh doing a bit of tutoring for a friend of mine's daughter a few years back and uh one of
50:43 the things i ran into is you know you're allowed to use calculators now which when i was a kid
50:48 calculators basically didn't exist and you weren't allowed to touch them but now this is part of the
50:52 math program um and one of the things we were talking about a lot is well if you don't know
50:56 what answer you're expecting, then when it says a thousand and it was supposed to be
51:01 C10, you're not going to know you hit the wrong button.
51:03 So I think that's kind of that.
51:04 This is exactly what you're talking about.
51:06 You need to understand it enough to sort of go, am I getting something back that makes
51:10 sense?
51:11 But if you just call the function blindly, you know, garbage in, garbage out.
51:16 But if you, you know, there's a lot of depth to some of these things and you could spend
51:21 an entire career trying to understand it all and that's not going to help you solve the
51:24 problem you're trying to solve, right?
51:26 So yeah, like you said, balance.
51:28 Indeed.
51:28 What about pairing?
51:30 Okay, so this one's off the charts.
51:37 So a pairing function is one that takes two natural numbers and maps that to a single natural number.
51:45 This process can also be undone.
51:47 So you can take a single natural number and find out what pairs could be used to create it.
51:51 This is related to set theory and gets into that funky domain where you can start to talk about some kinds of infinity
51:57 are bigger than other kinds of infinity.
52:00 The Polars Pairing Library by Antonio Camargo provides three different pairing functions.
52:06 I'm not even going to try.
52:07 One of which is Cantor, that one I can pronounce, which allows you to pair columns in a data frame
52:13 or unpair results.
52:15 I've got the Sudzik and Hagen as well.
52:18 Got them all.
52:18 There you go.
52:19 If you Google around, you can find all sorts of articles on what this is and how it gets used in set theory.
52:25 how you'd use it in your code is a mystery to me but maybe i just didn't dig enough
52:31 uh but if uh if you're mucking around and trying to understand canter pairing why not uh if on the
52:38 other hand one of the things i saw come up a couple times with that some of these libraries are often
52:43 used as examples for how to write a polars library uh so if you there are certain things you need to
52:49 do if you're writing a plugin and so some of these small libraries as much as this might not apply to
52:54 your day-to-day, because they're a small library, they can actually be helpful for you to kind of
52:59 understand the structure of things because you don't need to understand the math underneath this.
53:03 That's just a function call, but you can see the structure of things out there. So sometimes
53:07 something like this that is, why would I do that, could actually be a good lesson.
53:12 Yeah. Okay. Well, it seems like maybe encryption. I don't know. But yeah,
53:17 if you're doing set theory. In theory, this has to do with hashing in practice i think there are better ways of hashing so um yeah yeah you read it how about
53:26 that yeah all right so as a complete aside um there's a several list items on the polar's
53:33 package list use the little bear emoji in their docs and i'm not sure if this is just my font
53:38 but it looks like a panda and it looks like a panda to me too yeah so so to be clear if polar
53:43 bears and panda bears lived in the same place panda bears would be appetizers and they even
53:47 come with their own little bamboo garnish. So funnily enough, I'm not sure if this is a strong
53:53 signal, but not one of the ones that used the barren emoji was one I could get working on my
53:58 system. So I don't know, or whatever that's worth. Anyways, so we kind of got into the weeds there.
54:05 So now we'll like step back a little bit and talk about a few things that are a little more higher
54:10 level. The Polars List Utils, a good name, kind of describes what it does. This is by Travis
54:17 Hammond and it gives you a series of functions that operate on columns that have lists within
54:22 the column. So for example, one of the stronger uses here is something called aggregate list
54:28 column element wise, which is a long function name, but it does aggregation operations on the values
54:34 inside the list data, supporting the same kind of aggregation that regular Polars does. So you
54:39 can do a mean account or some or whatever on those things that are in the column. So the library seems
54:46 to be coming out of the signal processing space, I suspect, because it supports a whole bunch of
54:52 fast Fourier transform mechanisms, including applying them, getting frequency bins, linear
54:59 spacing, and all that kind of stuff. The library also has some decent examples in its repo. This
55:04 was obviously written by somebody doing something with audio, because there's a whole bunch of sample
55:09 data and graph pictures and things like that on it. As a quick aside, this project explicitly
55:16 required Python 3.10 through 3.12, but I was able to get it working using the ignore requires Python
55:22 flag to pip. So I don't think there's anything, I was using 3.13 and there wasn't anything that
55:27 was actually 3.12 specific. So if you bump into that, if you're playing with it, don't worry about
55:32 that too much. Interesting. Yeah, probably they just over-constrained their requirements when
55:37 specifying the package, right? I ran into it with a couple of the other libraries that I tried out
55:41 and they actually didn't work uh this wasn't that case though so this worked fine okay yeah very
55:47 interesting and then i hardly believe it i hardly believe it uh i love the image with this one
55:52 the nice biker going thing here uh so this is harley this is by tom burge and although the docs
56:00 explicitly say it isn't associated with the bikes or the comic there's a nice picture of a motorcycle
56:05 in acknowledgement uh and an acknowledgement that this is a port of a pie spark library called quinn
56:11 where it comes from. This is a catch-all library. It's got a bunch of different things. So for
56:19 example, anti-trim, remove all white space, and single space are all functions that deal with
56:25 leading, trailing, multi-white space inside of strings. Approximate equal compares two columns
56:32 for equality within a given threshold. So that's kind of useful if you've got a couple floats and
56:36 And, you know, if it's within 10% of each other, then that's good enough.
56:40 Multi equals checks if multiple columns have a specified value.
56:44 So, you know, again, different comparison things.
56:47 Div or else divides one column by another, but allows for a default value if the divisor is zero.
56:53 So that's useful when you're not supposed to be dividing by zero.
56:56 I'm told that's not allowed.
56:59 And then there's some validation tools.
57:00 It's just a good recommendation.
57:02 Yeah.
57:03 And there's also some validation tools, Boolean tools, and a few things in here that can help you get information about your schema.
57:10 So nice little all told collection.
57:13 And I love these kinds of things.
57:16 There's a couple of ones in the Django world that there's one I wrote and there's the extensions one as well.
57:22 These collections are often I find these are the ones that often save me the most amount of time because there's usually something in them that I'm going to use again.
57:30 because this is, you know, it's written by somebody who was trying to solve some problem
57:34 and just didn't want to do it twice.
57:36 Yeah, very cool.
57:37 Yeah, I think, yeah, I think that might be all over.
57:39 That's our list.
57:41 That's the valid list, yep.
57:42 And I was thinking after we went through them, I might know if it were 10 or not,
57:46 but I'm even more confused because we went down so many tangents.
57:49 I don't even know whether some of them count.
57:51 But I can tell you that those are a lot of helpful tools and libraries for people.
57:56 So make sure you're putting that list together and doing all the research, Chris.
57:59 Yeah, for sure.
57:59 And, you know, we only really covered a few of the plugins.
58:03 The Awesome Polars list also has links to articles, links to blog posts, things on different interfaces for Polars on other languages that you can use to interact with it.
58:18 So even over and above the libraries we talked about there, there's a fair amount of decent content there.
58:24 Yeah, absolutely.
58:25 All right.
58:26 A couple of final calls to action.
58:27 I'll let you have the final word but I'll do a few for you check out your Django book very cool
58:33 even has some HTMX in it check out your Polars course which I'll link to in the show notes and
58:38 is very germane to this conversation and with that people want to do some Polars maybe want to
58:45 level up a little bit with some of these things we talked about what do you tell them um you know
58:49 it's a very approachable library I think it's uh it's one of those things you can dig in fairly
58:53 easily to um not to say hey you know the course is very helpful but the guides that come with
59:01 pullers are also very very readable as well um so if you're not if you if you're saving up to take
59:07 the course later hit the guides up as well they can be helpful uh and the community seems to be
59:12 pretty good i've seen a fair amount of your typical python help each other out kind of space as well
59:17 so yeah it's a fun little library and uh very very useful for solving some of your data science
59:23 Thanks.
59:24 Awesome.
59:25 Thank you.
59:25 Let me do one more quick little shout out now that I'm thinking about it at the end here.
59:29 Speaking of Marco Garelli, I had him on recently to talk about Narwhals,
59:33 which is a library that will help you bridge code between working with pandas
59:37 and working with Polars and other data frame libraries.
59:40 So if you've got some code and you want to try out Polars on it, but it's mostly in pandas
59:44 or some other data frame library, like, I don't know, Dask or something,
59:48 you can check out Narwhals as well.
59:51 And the episode is 480.
59:53 so not too long ago.
59:54 Anyway, one more thing, people to help them get started.
59:57 All right, Christopher, thanks for being on the show.
59:59 Always fun to catch up with you.
01:00:01 Yeah, great.
01:00:02 Thanks for having me.
01:00:02 Yeah, bye.
01:00:04 This has been another episode of Talk Python To Me.
01:00:07 Thank you to our sponsors.
01:00:09 Be sure to check out what they're offering.
01:00:10 It really helps support the show.
01:00:12 Take some stress out of your life.
01:00:14 Get notified immediately about errors and performance issues in your web or mobile applications
01:00:19 with Sentry.
01:00:20 Just visit talkpython.fm/sentry and get started for free. And be sure to use the promo code Talk Python, all one word.
01:00:29 And it's brought to you by Agency. Discover agentic AI with Agency. Their layer lets agents find,
01:00:35 connect, and work together, any stack, anywhere. Start building the internet of agents at
01:00:40 talkpython.fm/agency, spelled A-G-N-T-C-Y. Want to level up your Python? We have one of the
01:00:47 largest catalogs of Python video courses over at Talk Python. Our content ranges from true
01:00:52 to deeply advanced topics like memory and async.
01:00:55 And best of all, there's not a subscription in sight.
01:00:58 Check it out for yourself at training.talkpython.fm.
01:01:01 Be sure to subscribe to the show, open your favorite podcast app, and search for Python.
01:01:06 We should be right at the top.
01:01:07 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:01:12 and the direct RSS feed at /rss on talkpython.fm.
01:01:16 We're live streaming most of our recordings these days.
01:01:19 If you want to be part of the show and have your comments featured on the air,
01:01:22 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:01:28 This is your host, Michael Kennedy.
01:01:29 Thanks so much for listening.
01:01:30 I really appreciate it.
01:01:31 Now get out there and write some Python code.
01:01:58 I think is the norm.