Python in the Electrical Energy Sector



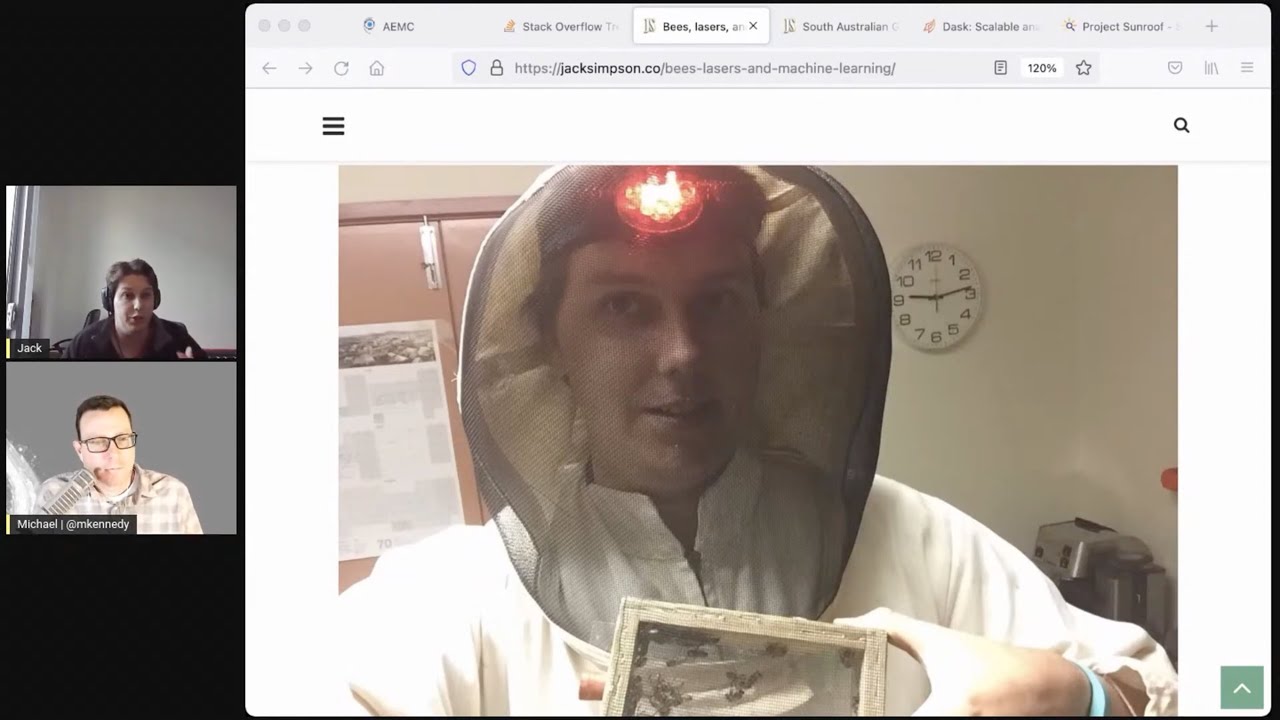
In addition to that, we also spend some time on how Jack used Python and Open CV (computer vision) to automate the study of massive bee colonies and behaviors. Spoiler alert: That involved gluing Wing Ding fonts to the backs of bees!
Episode Deep Dive
Guest introduction and background
Jack Simpson is a computational biologist turned data scientist working in the Australian electrical energy sector. Originally drawn to programming through his fascination with honeybees and biology, he discovered the power of Python for analyzing large datasets and automating research tasks. Today, Jack applies these deep data and code skills to help understand Australia’s electrical markets and grid, particularly around the massive adoption of solar energy and the implications for power generation and pricing.
What to Know If You're New to Python
- You’ll hear mentions of pandas for data analysis and NumPy for numerical operations — familiarity with these libraries will help you follow the episode’s discussion of large-scale data handling.
- Know that Python has special tools for big data, such as Dask (for parallel and distributed computing) and Numba (for just-in-time compilation).
- Handling huge CSV files can be simplified by Python’s built-in modules like
zipfileand techniques such as vectorization (applying operations over entire arrays rather than loops). - Python also has incredible community-supported libraries like OpenCV (computer vision) and NetworkX (graph analysis) mentioned in the episode, which open up highly specialized uses.
Key points and takeaways
Python’s Role in the Australian Energy Market
Jack uses Python to analyze real-time and historical power generation data across Australia. By pulling data on a five-minute or even four-second interval, he can identify trends in energy consumption and generation, including emergent behavior from solar, wind, and gas power stations.- Links and Tools:
Massive Rooftop Solar Adoption and Negative Energy Prices
Australia’s surge in rooftop solar installations has drastically changed midday energy supply and pricing. Jack’s analysis in Python shows that energy prices can go negative when there’s excess solar generation, causing fascinating market shifts.- Links and Tools:
- System Advisor Model (SAM) (via Python interface)
- NumPy
- Links and Tools:
Handling Large, Publicly Available Datasets
The Australian energy sector releases extensive, granular data—millions of rows per month. Python’s standard libraries (zipfile, CSV handling) and frameworks like pandas streamline data ingestion, cleaning, and transformation for Jack’s analyses.- Links and Tools:
Importance of Domain Knowledge in Data Science
Understanding the energy market’s physical and financial structures helps Jack interpret the data correctly (e.g., why a solar farm might keep output fixed vs. a gas generator’s rapid changes). Pure code skills alone aren’t enough for meaningful insights.- Links and Tools:
- NetworkX (for social or network-based data relationships)
- Links and Tools:
Speeding Up Python with Vectorization and JIT Compilation
Jack stressed the performance gains from vectorizing calculations (applying operations across entire arrays in pandas / NumPy) and using Numba for just-in-time compiling of Python loops that depend on prior states.- Links and Tools:
Parallelizing Work with Multiprocessing and Big Servers
For extremely large monthly data dumps (hundreds of millions of rows), Jack splits tasks into parallel processes. This approach, or using frameworks like Dask, helps harness multi-core servers (e.g., 60-core machines) efficiently.- Links and Tools:
- Dask
- Python’s
multiprocessingmodule
- Links and Tools:
Bee Research and Computer Vision with Python
Before shifting full-time to the energy sector, Jack’s PhD focused on tracking bees in a hive via tags and cameras. With OpenCV plus deep learning libraries like TensorFlow, he automated identifying bee behaviors, highlighting Python’s range of scientific uses.- Links and Tools:
Embracing Python’s Scientific Stack
From scanning images to analyzing time-series data, Python’s ecosystem (pandas, NumPy, SciPy, scikit-learn, etc.) provides a broad toolset. Jack also used specialized libraries like Cython for performance-critical code.Curiosity and Problem-Solving in Different Domains
Jack’s path shows how Pythonic problem-solving can jump from analyzing bee colonies to studying power grids. The core data manipulation and machine learning ideas transfer with minimal friction.- Links and Tools:
- Geopandas for spatial analysis and mapping
- Links and Tools:
Public Access to Energy Data
The transparency of Australia’s energy data enables hobbyists, researchers, and policymakers to dive deep. Jack underlines that the limiting factor is usually domain knowledge, not data availability.
- Links and Tools:
- AEMO Datasets for open energy data
Interesting quotes and stories
"I had a page of C++ code to convert between OpenCV and Caffe data structures, and I was terrified of breaking it. With Python, it’s all just NumPy arrays." — Jack Simpson
"I would put tiny patterns, even Wingdings, on the backs of bees. But the other bees didn’t like the smell of the glue and literally threw them out of the hive." — Jack Simpson
Key definitions and terms
- Vectorization: Performing an operation over an entire array or series instead of running explicit Python loops. This leverages fast, lower-level optimizations.
- Negative Electricity Prices: A market condition where power suppliers effectively pay others to take their electricity, usually due to excess generation.
- Numba: A just-in-time compiler for Python, especially suited for numeric calculations that can be parallelized or need speedups.
- System Advisor Model (SAM): A tool from NREL (U.S. National Renewable Energy Laboratory) for simulating energy system performance, including solar and wind.
- OpenCV: Open Source Computer Vision library for image processing and real-time computer vision tasks.
Learning resources
- Python for Absolute Beginners: Ideal if you're just starting out.
- Move from Excel to Python with Pandas: Great for those transitioning large spreadsheet workflows to pandas.
- Fundamentals of Dask: Learn how to scale your pandas workflows to large data.
Overall takeaway
Python’s flexibility and powerful libraries let developers move across scientific domains, from beekeeping research to high-stakes energy grid analysis. With effective tooling for large-scale data, performance optimizations, and transparency in the energy sector’s data, anyone with Python skills and a thirst for domain knowledge can make a tangible impact—no matter if it’s keeping the lights on for millions or decoding the secrets of a busy beehive.
Links from the show
Bees, lasers, and machine learning: jacksimpson.co
South Australian Gas Generator Interventions: jacksimpson.co
PySAM System Advisor Model: sam.nrel.gov
Visualizing the impact of Melbourne’s COVID-19 lockdown on Solar Panel Installations: jacksimpson.co
Stack Overflow Python graph: insights.stackoverflow.com
Watch this episode on YouTube: youtube.com
Episode #320 deep-dive: talkpython.fm/320
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 In this episode, we cover how Python is being used to understand the electrical markets and grid in
00:04 Australia. Our guest, Jack Simpson, has used Python to uncover a bunch of interesting developments
00:09 as the country has adopted more and more solar energy. We round out the episode looking at some
00:15 of the best practices for high-performance, large data processing in pandas and beyond.
00:19 In addition to that, we also spend some time on how Jack used Python and OpenCV,
00:24 computer vision, to automate the study of massive bee colonies and behaviors. Spoiler alert,
00:30 that involved gluing wingding fonts on the backs of bees. This is Talk Python To Me,
00:35 episode 320, recorded June 6th, 2021.
00:52 Welcome to Talk Python To Me, a weekly podcast on Python, the language, the libraries, the ecosystem,
00:57 and the personalities. This is your host, Michael Kennedy. Follow me on Twitter where I'm @mkennedy,
01:02 and keep up with the show and listen to past episodes at talkpython.fm, and follow the show on Twitter via at Talk Python. This episode is brought to you by Square and Linode,
01:12 and the transcripts are provided by Assembly AI. Please check out what all three of them are offering.
01:17 It really helps support the show. Jack, welcome to Talk Python To Me.
01:21 Thank you, Michael. It's great to meet you after hearing your voice for so many years.
01:24 It's so great to have you on the show. It's always fun to have people who are listeners,
01:29 but have interesting stories to tell. Come on the show, and you definitely have some
01:33 interesting stories about the energy grid and doing data science around really important stuff like
01:40 keeping the lights on in Australia.
01:42 Absolutely.
01:43 Yeah, I'm definitely looking forward to diving into that stuff. It's going to be a lot of fun,
01:46 I think.
01:46 Absolutely.
01:47 Before we get to it, though, let's start with your story. How did you get into programming,
01:50 and what brought you to Python?
01:51 Yeah. Well, I guess I have a very strange background. I actually started off at university
01:56 enrolling in journalism and politics right at the start of the GFC. I had never programmed before,
02:02 and I didn't even realize I was interested in it. And my lecturers kept telling me how many
02:07 journalists were losing their jobs during the financial crisis. And so I actually dropped out,
02:14 and I was trying to consider what I wanted to do. And I'd always had a passion for biology and science.
02:20 And my hobby was I was actually a beekeeper. I had six of my own hives at home. I really love that.
02:27 Amazing. Are these like honeybee type of bees or what kind of bees?
02:30 Honeybees. Yes, absolutely. The ones that stink. I actually also had a couple of Australian native bees,
02:38 tetragongula carbonaria, which I'm not sure if you've heard of them before, but they're actually,
02:43 they almost look like tiny little flies. They're stingless bees. And they will actually make their
02:49 hives out of the resin of trees. And they will build their brood in this beautiful kind of spiral
02:55 pattern going up through the hive. And so I was just really interested in, I guess, all things bee and
03:00 insects related at the time. And so I actually started blogging about bees and beekeeping. And
03:07 that was actually my introduction to code because I had, I think I had a website on blogger. And one
03:12 day I suddenly thought, well, I'd love to actually be able to make my own website. How do I do that?
03:18 And so I started learning HTML and JavaScript. And it was literally just so I could talk about my bees.
03:24 I had no interest in programming. Amazing. Well, I think so many people get into programming that way
03:29 who don't necessarily feel like my goal is to go be a programmer, but they just really have something
03:35 they're into. And programming is almost in the way, right? It's just like something you've got to figure
03:39 out so that you can actually get to the thing that you actually like. But then a lot of people find out,
03:43 well, hey, this is actually kind of cool. And what else can I do now that I know this, right?
03:47 Absolutely. That was really what made me change my degree. So initially I was going to do
03:51 a pure biology degree. And so I decided I would do biology and web development. And as I kind of went
03:57 along with the degree, I suddenly started realizing that the programming skills I was picking up during
04:04 my degree. So I learned, you know, PHP, Perl and Python. Suddenly I realized that these skills could
04:10 actually help me with working with scientific data. We kind of hit this point where there's just so much
04:16 genomic data. Really, most people at the time I was doing undergrad, but one of the things I've
04:21 really noticed is most people these days that enroll in a biology PhD, you join the lab and it's
04:27 almost like, right, you're learning Python or you're learning R. There's no other way you're working
04:32 with this data. And so suddenly I kind of hit this point where I was like, wow, these kind of technical
04:38 skills were letting me do things and be useful in ways that I never thought. And it let me answer
04:43 research questions that I was really fascinated by. And that was my motivation to actually, I guess,
04:49 go into and do a PhD and then try and take those skills further.
04:53 What was your PhD in?
04:55 So it was in computational biology. It was trying to develop software to automate the analysis of
05:01 honeybee behavior in the hive. So the thing that was interesting was it was both a physical setup and
05:08 the code as well. So the physical side was actually, how do we set up a beehive in a building with a kind
05:16 of like a glass window in so that I can film them with an infrared camera in the dark? And how do I
05:21 put little tags with patterns on them on the backs of the bees that I can then use Python and machine
05:27 learning to identify and track over the course of several weeks? And that kind of process ended up being
05:35 much harder than I had anticipated. Because when I started out, I read a couple of papers
05:39 by some computer scientists who mentioned that they'd printed out some card tags. And they said
05:45 that they filmed the bees for a couple of hours, got the data and did an analysis. And I thought,
05:49 great, I'm going to do that. Problem solved. It was only until later that I realized the reason that
05:54 they only filmed them for a couple of hours was because that was how long it took the bees to chew the
05:58 cardboard off each other in the hive.
06:01 I know. Oh, did they help each other? Like, hey, I've got this thing on my back, get it off me?
06:05 Yes. Yes, they actually did. They actually, and that was the thing I came, I would actually find time
06:10 and time again, I would come up with a material and I would try and stick it on the back of the bees.
06:13 And you would see their friends effectively come over and start trying to pry it off them in the hive.
06:19 And so it was actually a process to find something that didn't, I guess, trigger them, so to speak.
06:25 And one of the things, a really immensely frustrating experience I had when I was doing these experiments
06:30 was I thought I had found the perfect fabric and the perfect glue to put them on the bees.
06:36 And I'd spent hours tagging hundreds of them. I put them into the hive. And then I came back,
06:43 I would come back a few hours later and all my tags had disappeared. And I couldn't understand why. And I kept doing it.
06:48 And then at one point I thought, you know what, I'm going to put a bucket outside the hive entrance just to see what happens.
06:53 And I'm going to watch in the dark. And what actually happened was the bees didn't like the smell of the glue.
06:59 So they were actually physically grabbing bees that I'd tagged, dragging them to the entrance and flinging them out of the hive.
07:06 And because the hive, because these bees were juvenile bees, they were too young to fly yet.
07:14 The ants were actually dragging them away. So I thought my tags were dropping off or being pulled off.
07:19 But actually, my poor bees were getting eaten by the ants because they couldn't fly away.
07:24 Oh my goodness.
07:25 And so I guess it's another example as well. You know, when you've got missing data, understand the process.
07:30 Sometimes the process that made that data missing is significant in a way.
07:34 I would have never guessed. That's really pretty insane, actually.
07:37 And so the solution for dealing with this was I would actually go through the process of tagging the bees.
07:44 Then I would put them in this heated incubator on a frame of honey for several hours until all of the smell had kind of faded away.
07:53 And then I could introduce them to the hive and they would be accepted.
07:56 Oh, I see. Okay. Wait, basically wait till they dried and it was really on them.
07:59 Yeah. Yeah. Well, wait until all the fumes were gone and then they would be accepted and then it would work.
08:04 Because I think this was the real challenge of my project was we weren't interested in tracking, showing that we could write software that could track the bees.
08:13 We had a specific application was to look at the social development over several weeks of these bees.
08:19 So we needed a kind of experimental setup and the code to support it that would let us look at these extended periods of behavior.
08:27 Did they have different markings based on like their age or their role in the colony or something?
08:35 Like were they all tagged the same and you just said, well, they kind of move around like this or were they're like, did you group them or something?
08:40 What I would often do is I had use a laser engraver to burn patterns in the fabric that I would put on them.
08:46 And so each bee had a unique pattern that I could use to identify it.
08:50 Like a QR code on the bee?
08:51 Kind of like that, but not.
08:53 In fact, I think if you scroll through the website to the bottom of the page.
08:56 Yeah, there's some right there.
08:58 There's some little patterns.
08:59 This was some initial prototypes for the bottom.
09:01 Just if you scroll up a little bit more, the last image.
09:04 Yep, that one.
09:05 I was literally using a wingdings pod to try out different patterns.
09:10 Wingdings.
09:11 Okay.
09:11 On the bees.
09:12 Because I just had the idea was to have a relatively inexpensive 4K camera that could pick up the different patterns.
09:19 Of course, if you had a really expensive high resolution camera, then you could do more with QR codes, for instance.
09:25 And what I would do is I would do these experiments where I would, half of the bees would be that I would introduce.
09:31 They would all be juvenile, except I would also mark the queen so I could know how they were interacting with the queen.
09:37 But half the juvenile bees I would introduce into the hive would receive a label that I could reference later on.
09:44 And half would receive a different label that I knew about.
09:49 And the reason I did this was so I could actually do these, have these control and treatment groups in my experiment.
09:54 Because I would do these experiments where I would treat the bees with caffeine to see how it would actually affect their social development in the hive.
10:04 I guess to give a little bit more context to that, diving a little bit into the way that bees develop.
10:10 You could almost think of a worker bee in the hive like the pictures I have on my site.
10:14 The jobs that a bee does over its lifetime are influenced by how old it is.
10:19 So these juvenile bees I was first introducing to the colony.
10:23 They really would just have quite menial colonies.
10:25 They would do little cleaning tasks around the hive.
10:28 They wouldn't do much.
10:29 Then when they're a little bit older, they would start nursing other juvenile bees.
10:33 And then the eldest bees are the ones that you actually see out and about flying and collecting nectar and pollen.
10:40 So those are actually the eldest of the bees in the colony, typically.
10:44 And so I wanted to see how this caffeine would affect that kind of behavioral process in the juvenile bees.
10:53 How interesting.
10:54 Short, briefly, what did you find that caffeine does to bees?
10:56 One of the things I found was it effectively meant that bees sped up how quickly they adjusted to the rhythms of the colony.
11:06 So for a bit of context, if you're a juvenile bee in the hive, you don't really care about circadian rhythms, day-night cycles, because you're in a hive, it's completely dark all the time.
11:19 And so what we found was that we hadn't seen before was these juvenile bees, even though they weren't exposed to the light on the outside, they would actually pick up these circadian rhythms by interacting with the older bees that were coming back.
11:34 It was effectively like a socially acquired circadian rhythm.
11:37 And so what we found was that bees that were treated with caffeine effectively picked up this rhythm more quickly than bees that weren't and kind of progressed in their roles in the colony more quickly.
11:49 So there was that.
11:50 Okay.
11:50 Yeah.
11:51 So there was that.
11:52 And I had a few other areas, but yeah, to be honest, a lot of the work was really just making the software and the bees all play nice together.
12:01 Yeah.
12:02 Yeah.
12:03 Absolutely.
12:04 It was probably one of the most immensely, I will say one of the things that is quite nice about the energy sector is I don't have to deal with, I guess I can deal with machines, which are a little bit less frustrating at times.
12:14 More reliable, more predictable and certain, that's for sure.
12:17 This portion of Talk Python To Me is brought to you by Square.
12:22 Payment acceptance can be one of the most painful parts of building a web app for a business.
12:27 When implementing checkout, you want it to be simple to build, secure, and slick to use.
12:32 Square's new web payment SDK raises the bar in the payment acceptance developer experience
12:38 and provides a best-in-class interface for merchants and buyers.
12:41 With it, you can build a customized, branded payment experience and never miss a sale.
12:47 Deliver a highly responsive payments flow across web and mobile that integrates with
12:52 credit cards and debit cards, digital wallets like Apple Pay and Google,
12:55 ACH bank payments, and even gift cards.
12:58 For more complex transactions, follow-up actions by the customer can include
13:03 completing a payment authentication step, filling in a credit line application form,
13:07 or doing background risk checks on the buyer's device.
13:10 And developers don't even need to know if the payment method requires validation.
13:15 Square hides the complexity from the seller and guides the buyer through the necessary steps.
13:19 Getting started with a new web payment SDK is easy.
13:22 Simply include the web payment SDK JavaScript, flag an element on the page where you want the payment form to appear,
13:27 and then attach hooks for your custom behavior.
13:30 Learn more about integrating with Square's web payments SDK at talkpython.fm/square,
13:36 or just click the link in your podcast player's show notes.
13:39 Before we move on to the energy sectors, just give us a quick overview of the software that you use.
13:48 Was Python part of this role here?
13:50 Yes, absolutely.
13:52 So I used a mix of Python and OpenCV for a lot of the image processing.
13:58 And of course, TensorFlow and Keras for training my neural network to identify the different tags.
14:07 And that actually ended up being quite an interesting process, building up that data set and improving it over time.
14:13 Because one of the things I found when I started trying to train that data set was I thought,
14:19 okay, I can take my patterns, film them, add a little bit of noise and rotation,
14:24 and then that's my kind of starter, you know, machine learning model.
14:27 The problem was that when you put the tag on the bee, the way that they kind of walk around the hive,
14:34 you'll see different kind of angles of, they kind of have this bit of wobble walk as they go around.
14:41 So it kind of introduces this level of distortion to the tag.
14:45 And then other, and so then also you could have other situations where bees would walk over each other, the block occluded tags as well.
14:53 So one of the things I ended up having to do was I had to introduce a class to my,
14:59 a predictive class to my model that was literally just like the, I don't know what this is class.
15:04 And effectively, the idea was, I'm going to see this bee, I'm going to have multiple attempts to classify this bee as it's walking around.
15:13 So I want to only attempt a classification when I'm seeing enough of the tag
15:17 and I'm confident enough in that to attempt it.
15:20 And so that was one of the, one of the techniques I found that helped improve the classification.
15:24 And really it ended up just becoming a process where I would, I had a bit of a pipeline that would go through,
15:32 it would extract tags, it would use the model at the current iteration to label them.
15:37 I would then go in and manually review it and then figure out where it had stuffed up,
15:41 where it was doing well, and then use that corrected data set to retrain the model and then improve and see how well that
15:48 iteration did.
15:48 And it became kind of like a, almost like a semi-supervised problem to an extent when I was building it out.
15:54 And at a certain point, it became just as good as me at doing these classifications.
16:00 And then it was fully automated as well.
16:03 But I think I ended up labeling about seven or 800,000 images as part of doing this.
16:09 And my, my wife was actually, she was a PhD student in working in genetics at the time.
16:14 She was helping me in her spare time.
16:16 So she does not look favorably upon that, on that project.
16:22 She probably doesn't love wingding fonts.
16:25 Maybe in a bit of a surprise, she's like, oh, not you again.
16:28 Yeah, absolutely.
16:30 But I'd say, yeah, so Python and OpenCV were big ones.
16:33 And then the other tool I was using a lot of was Python Cython library, where I would,
16:39 for certain parts that I wanted to run really efficiently, I wrote those in C++ and then used Cython to expose some of those methods to it.
16:48 And that worked amazingly well.
16:50 It was so impressive how you could call, pass a list, a Python list to my,
16:56 my C++ class, and it would interpret that as a vector.
16:59 And then it would pass back the information as well.
17:02 I think this is the reason I'm such a fan of Python is just how well it lets me
17:06 do so many different things that I'm working on.
17:09 That's a really interesting point.
17:10 you know, a lot of people talk about, well, Python is slow for this or it's slow for that.
17:14 And yet here's all these really intensive computational things that Python seems to be
17:19 the preferred language for.
17:20 And I think this is one of the hidden secrets that's not apparent as people come into the
17:25 ecosystem, right?
17:25 Obviously people have been here for a long time and they, they kind of know that story,
17:29 but you know, as people come in, because there's, there's all sorts of people coming into the Python world drawn in a little bit like
17:36 you, you talked about how you started out in biology, not necessarily to be in software development specifically,
17:42 but then you kind of got sucked into it.
17:44 Right?
17:44 Absolutely.
17:45 Yeah.
17:45 I think all of the conversations around the performance of Python is super interesting.
17:49 It's like, oh, it's, it's really slow, except for in this time where it's like as fast as C++.
17:53 Wait a minute.
17:54 Is it, is it slower?
17:55 Is it fast as C++?
17:56 Well, it's both, right?
17:57 it varies, but you can bring in these extra like turbo boosts, right?
18:02 Like Cython and, or do your work in NumPy rather than in, in straight lists and stuff like that.
18:08 Absolutely.
18:09 And like one of the, initially when I started off my PhD, I actually wrote an initial prototype version of it all in C++ using open CV,
18:19 open C++ library and a machine learning, a deep learning library called cafe,
18:23 which was a bit of a thing back in the day.
18:26 And the pro that process for dealing with data and even just converting data
18:31 between like, I think the best thing about Python is the fact that NumPy arrays is just
18:36 understood by all the scientific libraries, whereas sometimes with other languages,
18:40 it can be painful moving data between different libraries and tools.
18:44 Oh, interesting.
18:45 Yeah, you're right about that.
18:46 Yeah.
18:47 And so like, I remembered at one point during my PhD with, with that initial C++ version,
18:51 I had like a page of code to convert between an open C, the matrix and a cafe,
18:57 I think blob.
18:58 And it was a page of code that I was terrified of breaking because I didn't understand how it
19:03 worked.
19:04 Whereas Python, it was like everything I can move between, you know, scikit-learn,
19:08 pandas, and all these other libraries.
19:11 And it's all kind of got that common foundation that makes me really efficient.
19:14 Yeah.
19:14 And that I understand really well.
19:16 That's a really interesting insight that there's this sort of common data structure across the
19:21 libraries, because you're right.
19:22 I remember in C++ and other languages like C# and whatnot, this one will take something like this and you've got to reorder the data and reformat it to pass it over.
19:31 And if you have to do that back and forth, it would completely slow things down.
19:35 All sorts of stuff.
19:36 Yeah.
19:36 Very interesting.
19:37 In a way as well.
19:38 I really loved that the Python stack has let me do things in during my PhD and then post PhD as well.
19:47 In just the skills that I developed in analytics here, I've gone on to be able to use that in so many different places.
19:53 For instance, one of the pieces of analysis I did was look, I used Python's network X library to look at the social interactions between the queen and worker bees.
20:03 And I would build out these network graphs that would explore the number of interactions and the length of time of those interactions between the queen and the worker bee.
20:14 And this actually recording independent interactions actually became important because sometimes the queen would literally fall asleep behind another worker.
20:23 And it would look like she loves that worker, but she just was resting for like over an hour or two.
20:28 What I've actually found is that those skills for working with data and with network analysis,
20:32 when I was working consulting, I would use network X to analyze the corporate structure of organizations that we're doing an org review for.
20:41 And then more recently I have done work in the energy sector, looking at building out networks of power stations as well.
20:47 And so it's, I think that's, that's one of the things I love about this area is that you have this kind of transferable skill set that you're more limited by what you can think of,
20:58 but using it by rather than what you can actually do with it, with it itself.
21:02 Yeah, absolutely.
21:03 And I think for a lot of people, if they're out there listening and they're doing,
21:06 you know, academic type stuff or working in one area, but maybe that's not the area they necessarily want to stay in.
21:14 A lot of these skills are super transferable.
21:16 One of the things that's blown my mind as I've spent more and more time in the software industry was,
21:22 I remember I was doing professional training and I spent one week at a stock brokerage in New York City teaching programming.
21:30 And then I spent two weeks later, I was like at an air force base working with some of the engineers there.
21:36 The stuff that those two groups need to know, it sounds like it's entirely different worlds,
21:40 right?
21:40 It's like 90% identically the same.
21:43 It's just a little bit of what do you do with that once you know it?
21:46 Like what's the secret sauce on top of it that puts it together?
21:49 But yeah.
21:49 And it sounds like you kind of got that skill in your research.
21:52 Absolutely.
21:53 And I think this is one of the things I've noticed is that some PhDs can struggle to transition into industry.
22:00 And often it's because there's people on the industry side that don't really understand how those skills can help them.
22:08 But at the same time, I think it's actually a skill to be able to explain how you can link what you already know,
22:15 what you're capable of and solve their kind of business problem.
22:18 And in fact, I think when I went into management consulting and I would do some work for some of the partners,
22:23 eventually it took me a little while to figure out that they weren't that interested in,
22:28 you know, the code I was doing or even some of the raw data.
22:31 But if I could figure out a way to link that to the business problem they were trying to solve,
22:35 then they were interested.
22:36 Yeah, absolutely.
22:37 Being able to kind of communicate and act as like a bridge between those was something I didn't realize was a skill,
22:43 but it is hugely valuable in organizations.
22:46 I've really noticed.
22:47 Yeah, absolutely.
22:48 All right.
22:49 One final question about your research before we get into the energy sector.
22:52 That what year did you do that?
22:54 Oh, so 2014 to 2017.
22:57 Yeah.
22:57 And that's not that long ago.
22:59 And yet the machine learning story has probably progressed really quite a bit with deep learning,
23:06 transfer learning, all sorts of stuff going on, the different use of GPUs and tensor compute units and whatnot.
23:13 What would it look like now if you're doing it versus then?
23:16 What would be different?
23:17 I think now one of the big differences was really that TensorFlow only came out towards the second half of my PhD.
23:25 So I think a lot of the, so I think that was a difference.
23:29 Having more accessible machine learning libraries and tools really made a big difference.
23:34 The other one was, I think when I started my project, I actually spent a lot of time playing around with,
23:40 you know, now if you started your PhD, you would go image analysis, it's going to be deep learning.
23:45 Whereas when I started, I was actually pointed in the direction of, oh, go check out,
23:51 you know, support vector machines, try out a random forest, try out a whole bunch of different feature engineering and machine learning techniques.
23:58 And so I spent a lot of time kind of moving around between those before I literally had a,
24:03 I got in touch with a researcher in the computer science department because I was in the biology department doing this work.
24:09 And he literally, I had a chat with him and he literally looked at what I was doing and he said,
24:14 use deep learning.
24:15 And he said, go check out, check out these libraries, but this is what you need to do it.
24:19 And I think, yeah, in a way like that type of, the libraries and the understanding about how you would solve this problem now is,
24:26 is a lot further along and probably would have shortcut a lot of my initial frustration compared to previous.
24:33 Yeah, probably.
24:33 But think of all the lessons you've learned with those late nights of it not working and,
24:37 and whatnot.
24:38 Right.
24:39 One other thing really quickly is I love to look at this graph here, this,
24:44 the stack overflow trends, and I'll link to this in the show notes.
24:47 There was, back in 2017 article by stack overflow, their data science team set called the incredible growth of Python.
24:55 And they predicted, Oh, Python's going to overtake some of these languages.
24:59 And you're not going to believe it.
25:00 It's going to be more popular than JavaScript, more popular than Java.
25:04 And people are like, no way.
25:05 This has got to be something wrong with the data.
25:07 And obviously, here we are, you know, in 2021, where I think they underestimated.
25:13 Honestly, I don't want to have the exact picture in my mind, but I'm pretty sure they underestimated the last couple of years,
25:19 which is pretty interesting.
25:20 But that's not what I want to talk about.
25:21 What I want to talk about is that 2012, you know, Python had been around for at that time,
25:27 25 years or something.
25:28 It was well known.
25:29 It was a fairly popular language, but it was kind of just steady state.
25:33 And then it's like somebody just lit the afterburner on that language.
25:37 And it just, you know, it just started going up and up right around that time.
25:41 And this is the time that you got into Python as well, more or less, right?
25:45 Absolutely.
25:45 I feel like so many people came from these not traditional programming spaces.
25:52 I mean, still interested in programming, but not like a CS degree type of programming in.
25:57 And it just brought so much diversity in terms of the problems being solved.
26:01 And I think this graph is exactly what's happening here.
26:04 It sounds like you're part of that, making that curve go up there.
26:06 Yes.
26:06 Yeah, I guess so.
26:07 And I think for me as well, when Pandas came out, I think around in 2012 for working with,
26:12 you know, data frames as objects, I've used R.
26:15 I really liked that kind of data frame feature in R initially.
26:18 And it was a little bit frustrating before Pandas was a thing, being able to,
26:23 having to deal with, you know, CSV files and having to treat them as lists and indexing.
26:28 So when Pandas became a thing, that was almost one of the big reasons I pushed into using Python for so much.
26:34 And I still feel like I've been using Pandas for, yeah, I guess eight or nine years.
26:39 And I'm pretty sure the project I'm on currently, I'm pretty sure I've learned a few extra things about the library just in the last couple of weeks.
26:46 Yeah.
26:46 It's crazy how that works, right?
26:47 You're like, I've been doing this forever.
26:48 How did I not know about this part of it?
26:51 Right?
26:51 Absolutely.
26:52 Amazing.
26:52 Amazing.
26:53 All right.
26:54 Well, super cool project you had there.
26:55 Let's talk about energy.
26:57 So you work for the Australian Energy Market Commission?
27:01 Yes.
27:01 Yeah.
27:01 What's this?
27:02 What do you do there?
27:02 You can almost think of them as the rulemaker for the energy market.
27:06 We don't run the energy market.
27:08 That's the Australian Energy Market Operator.
27:10 But they effectively pass the legislation that determines how people have to act within the
27:17 energy market.
27:17 The reason I really joined the organization was because when I was working in consulting,
27:23 I started doing work in the energy sector.
27:24 And I do work for energy retailers, the people that you pay for your electricity.
27:30 I just work for some industrial companies.
27:33 And one of the things I found was when I bumped into the wholesale energy data, it was almost
27:38 like this, what was it?
27:40 The, you know, the city of gold in some way.
27:43 It was immense amounts of reasonably well-structured and cleansed data where the limitation wasn't,
27:51 you know, the data or cleaning it.
27:53 The limitation was understanding the domain well enough to do interesting things with it.
27:58 Right.
27:58 Okay.
27:58 And so that's really became my obsession was to learn as much as I could.
28:03 So I could actually do more and more interesting things with the data.
28:06 And so the reason I joined the AAMC was because it's one of the most amazing workplaces in terms
28:13 of the capability of everyone there is so passionate and incredible at what they do.
28:19 And so just being around these people and learning from them is just an experience in itself.
28:25 Yeah.
28:25 Fantastic.
28:25 That sounds super interesting.
28:27 And it sounds like things like your network experience, you know, there's probably a lot
28:30 of networks and energy and suppliers and whatnot.
28:33 There might go together.
28:35 Absolutely.
28:35 Yeah.
28:36 Basically there's, it's kind of a market that they set the price energy and then generators
28:42 like private companies that are, you know, have power plants and solar forms and whatnot.
28:47 They can decide whether or not they want to participate at that very moment in the grid or how does
28:52 it work?
28:52 Yeah, absolutely.
28:53 So yeah, this is one of the fascinating things about the wholesale energy market.
28:57 You can almost think that every five minutes, the market operator is effectively running
29:02 an auction where all power stations around on the East Coast of Australia are bidding in
29:08 bids for how much they were willing to sell different volumes of electricity at.
29:12 So for instance, a wind farm might say that they will sell this volume of power quite cheaply,
29:19 whereas a gas generator that has quite a high cost of fuel will set a higher price.
29:25 And the market operator will take all of these bids and it knows the locations of these generators.
29:31 It knows the capabilities of the transmission lines and the network.
29:35 And it will run this linear optimization to figure out, okay, what is the cheapest mix of
29:42 generators that I should dispatch to satisfy demand while still making sure the network is secure?
29:48 Okay.
29:48 So it's like trying to optimize certain goals.
29:51 Like we are going to need however much energy in the grid at this very moment.
29:55 And these people are willing to supply it at this, like, you know, who do we take however
30:00 much energy from until we get like both enough people that are willing to participate from a
30:05 financial perspective and then what people also need, huh?
30:08 Yes, absolutely.
30:09 And that's the thing that's so fascinating about this market is that at all times, supply
30:14 and demand have to be matched.
30:16 Very, very carefully because it'll break the grid if there's, well, too much is probably
30:20 worse than too little because you just get a brownout, right?
30:23 But too much could destroy things, right?
30:25 Yeah.
30:25 You don't want too much.
30:26 If you have too much, then you need generators to start to try and reduce the output.
30:31 And at the same time, if you have too little, then it can also create problems.
30:36 And in fact, the grid has to be kept at this such a precise level of balance that if it
30:43 actually you have too much or too little for too long, it will damage the machines that are
30:47 connected to it.
30:48 And in fact, to protect themselves, you will actually see them start to disconnect and it
30:53 can actually create these kind of cascading problems.
30:55 So unless you, we actually had a fascinating example recently in Queensland where a turbine,
31:05 a coal turbine blew up and it then tripped a whole bunch of other coal power stations that
31:12 then couldn't, that then stopped creating load.
31:15 And so you suddenly had this situation where you had all this demand for electricity and
31:21 suddenly they just lost all of this generation ability.
31:24 And what actually happened is the system just started disconnecting.
31:28 Well, it caused a blackout.
31:30 But there was this automated system in a fraction of a second that just started disconnecting
31:34 load or demand to try and balance it as quickly as possible to try and arrest the problem.
31:39 So, and one of the things I've actually been doing has been looking at this at like a, on a four second basis, the events that happened on this day and how different units responded to these events.
31:50 It's amazing.
31:51 Like there's, there's almost like the energy sector and the market.
31:54 It's almost like there's the physical infrastructure of make and making everything work and all that amazing engineering.
31:59 And then there's the financial market and the bids and everything like that, that's built on top of it.
32:04 And the market and the bids are fascinating, but at the end of the day, everything has to bow to the engineering.
32:10 It has to work.
32:11 Right.
32:11 It has to work.
32:12 Yeah.
32:12 Yeah.
32:13 Or it's all just going to come apart.
32:14 Interesting.
32:15 Yeah.
32:15 AR out in the live stream says, is AEMC doing anything with energy web?
32:20 I'm not sure if I've come across that before, but I'd be interested in looking into it.
32:24 Yeah.
32:25 And then also, it sounds like DERMS, what you're describing or D-E-R-E-M-S.
32:29 I'm not sure whether, how you pronounce it.
32:31 That might be something, an acronym from the, from the U.S. energy markets.
32:36 Everyone has their own kind of different acronyms.
32:38 Oh yeah.
32:40 That makes it easy, right?
32:41 To not even be consistent.
32:42 If you go to the market operators website, they have a glossary page where you can just
32:47 scroll for, for all those days on all the acronyms that are used in the sector.
32:52 Probably like an acronym thesaurus.
32:53 We call it this, what do they call it?
32:55 Exactly.
32:56 Exactly.
32:56 This portion of Talk Python To Me is sponsored by Linode.
33:01 Visit talkpython.fm/Linode to see why Linode has been voted the top infrastructure
33:06 as a service provider by both G2 and TrustRadius.
33:09 From their award-winning support, which is offered 24, 7, 365 to every level of user, to the ease
33:16 of use and setup, it's clear why developers have been trusting Linode for projects both
33:20 big and small since 2003.
33:22 Deploy your entire application stack with Linode's one-click app marketplace, or build
33:27 it all from scratch and manage everything yourself with supported centralized tools like Terraform.
33:32 Linode offers the best price-to-performance value for all compute instances, including GPUs,
33:38 as well as block storage, Kubernetes, and their upcoming bare metal release.
33:43 Linode makes cloud computing fast, simple, and affordable, allowing you to focus on your
33:48 projects, not your infrastructure.
33:50 Visit talkpython.fm/Linode and sign up with your Google account, your GitHub account,
33:55 or your email address, and you'll get $100 in credit.
33:59 That's talkpython.fm/Linode, or just click the link in your podcast player's show notes.
34:04 And thank them for supporting Talk Python.
34:06 So we have on the graph here, this picture on the screen, where energy went negative, actually.
34:13 And so this is where people are willing to pay to take energy that you've generated?
34:18 Like, that sounds completely insane.
34:20 Yeah, I know.
34:21 It sounds weird.
34:21 So yeah, to explain this figure, what's been happening this year in South Australia, the
34:27 wholesale price of electricity has been around, averaged around negative $20 during the middle
34:34 of the day, pretty much consistently.
34:36 And so the way this works is because the generators submit bids for how much they're willing to
34:42 sell their electricity for, because they'll effectively, when they run the optimization,
34:47 the price of the bid that satisfies demand is the price that everyone gets paid.
34:52 So what a lot of generators will do is they'll bid in quite cheaply at negative prices so that
34:58 they're sure that they will get dispatched.
35:00 But if everyone bids in a negative prices, then everyone gets the negative price.
35:04 And so what we've actually been seeing is because there's now so much generation in the middle
35:09 of the day, you're ending up with these really fascinating market events.
35:13 Like, yeah, these negative prices where literally you can get paid to consume electricity.
35:18 As a consumer, that sounds pretty good.
35:20 You know, get it nice and chilly and we'll all be fine.
35:22 True.
35:23 Yeah, that's true.
35:23 One of the drivers of this, it sounds to me like, is solar energy in Australia, right?
35:28 Yes.
35:29 Yes.
35:29 We now have so much rooftop solar.
35:31 I can't remember the exact percentage, but a significant percentage of Australian households
35:35 now have solar panels because the cost has come down so much.
35:39 And so a lot of our work has involved looking at how that is impacting the grid.
35:44 Because if you imagine historically the energy market, it was a process where, you know, the
35:50 market operator could instruct generators to turn on or turn off.
35:54 And now we're in a world where there's so much of these kind of small scale solars that
35:58 solar that you can't tell what to do.
36:01 How do you factor that into balancing supply and demand in the grid?
36:05 Yeah.
36:05 Well, it definitely sounds like some interesting Python must be at play there.
36:09 So give us an overview of sort of the kind of tools you're using, the types of problems
36:13 you're solving.
36:14 Yeah, sure.
36:14 In the solar place, we've been using a Python, a software package called SAM, which is a system
36:21 advisor model, which is actually released by the National Renewable Energy Laboratory
36:26 in the States.
36:27 And so what it lets you do is if you provide solar irradiance data and data from weather
36:32 stations, you can use it to simulate the generation of rooftop in different areas around the country
36:40 on a granular, on a half hourly basis over the course of the year.
36:43 And so what this lets us do is I can use, they've got a Python library that lets me kind of call
36:49 and run this tool.
36:51 And I can simulate different PV system sizes and different locations and angles and all
36:57 for setups all around the country.
36:59 So I can effectively simulate hundreds and hundreds of different PV systems.
37:03 And if I combine that with how much the household is consuming and what the actual cost of electricity
37:11 was and those half hourly intervals, you can suddenly build up a picture for the economic
37:17 effect of different PV panels for different households around the country.
37:22 Yeah, how interesting.
37:23 Is this the right thing I pulled up here?
37:24 This Pi Sam?
37:25 Yes.
37:25 And I will say that for your US listeners, the laboratory release all of the data for
37:32 the US mainland in a format that's ready for you guys to go.
37:35 I had to, a big part of my project was actually trying to turn the Australian data into a format
37:41 that this program could understand.
37:43 And that in itself was an interesting exercise in data cleaning and manipulation because, for
37:50 instance, all of the data on the irradiance for the country came as tens of thousands of
37:56 these text files that were just these kind of grids, which pretty much they said, each value
38:01 represents a five by five kilometer grid on the Australian mainland.
38:05 It starts at this coordinate.
38:07 So I had to pretty much try and convert this text file into a map and then convert that into
38:12 format so I could know where the house fell in that as well.
38:16 Oh, wow.
38:17 How interesting.
38:17 Yeah, you're normally taking a bunch of text files and piecing those together in a map,
38:23 but I guess you do.
38:25 Eugene, who was on the show a little while ago about the life lessons from machine learning,
38:29 brought an interesting quote.
38:32 It was something to the effect of the data cleaning is not the grunt work.
38:36 It is the work of so much of this, right?
38:39 Like it's getting everything right, making sure it's correct, converting it, formatting it,
38:44 and then you feed it off to the magic library and get the answer, right?
38:46 Yep.
38:47 Absolutely.
38:48 And I think, yeah, the lessons that you learn from working with and cleaning the data often
38:54 help inform your analysis later on.
38:57 For instance, one of the things I was doing recently was I've been trying to correct for
39:01 errors in this really large data set measuring output from these power stations.
39:05 And so one of the pieces of advice I received was that if I see a data where the generation
39:14 value from the power station does not change, it effectively says this power station is generating
39:19 100 megawatts and that value doesn't change for more than a minute, for at least a minute,
39:25 that means there's an error in the data collection.
39:28 And so as I was cleaning up the data and I implemented that and I started looking for outliers,
39:34 and I actually discovered that you could see for some solar farms that it looks like if I
39:41 used this metric that I'd implemented to pick out the bad data, it was actually removing
39:46 cases where the power station, the solar farm was deliberately keeping their output perfectly
39:54 level to match this instruction from the market operator.
39:57 And so I think this is a case where they were actually foregoing additional generation to be
40:03 more predictable.
40:04 And I would have missed this whole interesting power station behavior if I just, you know,
40:09 if I wasn't thinking about what the implications were of these different, you know, cleaning
40:14 techniques that I was doing.
40:15 Okay.
40:16 Yeah.
40:16 Because maybe that advice comes from, I don't know, a gas power plant or a coal plant where
40:22 they have to fluctuate because, you know, whatever reason, right?
40:25 And this new world, the assumptions changed or the situation changed and the assumptions didn't,
40:31 right?
40:31 Absolutely.
40:32 Absolutely.
40:32 And I think, yeah, like in a way, like part of the reason I think I've always gravitated towards
40:39 being passionate about combining the programming and the analytics with like deep domain expertise
40:44 is that I really love when I'm working with the data set, when I see something weird, I
40:50 love that I can go, that's wrong.
40:52 I can remove that or that looks weird.
40:55 I'm going to investigate this because I think that's interesting.
40:57 And one of the things I found in consulting was the projects where I didn't understand
41:02 the data or the industry as well were always a bit, and I was brought into the team to provide,
41:09 you know, the analytics capability, but I was effectively, you know, turning the understanding
41:14 of others into code.
41:16 I've always found them a little bit less satisfying from a personal perspective because I didn't
41:21 feel like I was the one who was really, you know, getting, I felt like I was a vehicle other
41:27 people turn their thoughts into code.
41:28 Whereas I really like that if I understand the domain, then suddenly I can investigate and
41:33 understand the area that I'm working in.
41:35 Yeah.
41:36 It becomes a puzzle, not just, I don't know, just more, get information from these people,
41:41 apply it to the data, see what comes out.
41:43 Yeah, for sure.
41:44 You know, someone asked me recently, they were looking to hire somebody.
41:47 It was, I don't know if it was exactly in the data science world, but it's close enough.
41:51 They were asking something to the effect of, should I go and try to find a computer science
41:56 type of background person who I can then teach the subject matter to and kind of get them
42:03 up to speed there because we need good programmers.
42:05 Or should I find some people who really understand what we're doing and then try to teach them
42:10 Python?
42:10 Yeah.
42:10 What would you say to that?
42:12 I had a thought on it, but I'd love to hear yours.
42:14 I think to a certain extent, the experience, you want to have, I guess, the passion for learning
42:21 about the domain.
42:22 And obviously, if they understand the domain, that's really valuable, but you probably want
42:27 them to be exposed at least a little bit to some programming concepts for them to know
42:31 that they like it.
42:32 In fact, I remember when I had a chat with my former boss who hired me into my current
42:38 role.
42:38 And he said that he's hiring philosophy is he looks for people with interesting backgrounds.
42:44 You know, my background, he saw computational biology.
42:47 And, you know, a lot of people would be like, oh, how does that apply to the energy sector?
42:52 Yeah.
42:52 That does.
42:52 That's not for us.
42:53 That's something totally different, right?
42:55 Exactly.
42:56 But he said, you know, for him, that's an interesting story.
42:59 And he could see how those skills can generalize to different areas.
43:02 And then it's more about, are you passionate about the thing you're working on as well?
43:06 So like, I think people can learn, you know, people with domain expertise.
43:09 I think learning Python can be like adding a bit of a superpower to your, you know, your
43:14 skills and domain skills as well.
43:16 But I also think that you wouldn't want to say, for instance, you wouldn't want to hire
43:21 someone who had good domain expertise into the team to be a programmer who'd never programmed
43:26 before and discovered they hated programming as well.
43:29 Yeah.
43:29 I think the assumption was that they had a little bit of programming experience or they were super
43:33 interested in it, but maybe not all the way there.
43:35 I think the subject matter expertise is really valuable.
43:39 It's, I think these days there's so many amazing libraries and Python so accessible that it's
43:46 really important to understand like deeply what's happening.
43:49 But you should probably also have one or two people who have like a true software engineer
43:53 experience like, hey, has anybody told anyone around here about Git?
43:57 We need to be using source control.
43:58 And what about continuous integration?
43:59 And have you heard of testing, right?
44:01 Like those kinds of things matter.
44:03 But I think also having this like deep understanding of it really matters.
44:06 Absolutely.
44:07 Cool.
44:08 Cool.
44:08 Cool.
44:08 Cool.
44:09 All right.
44:09 So are there, I mean, you talked about this system advisor model.
44:13 Are there other things like in say the astronomy space, there's AstroPy, like all the astronomers
44:18 talk about, this is the library.
44:20 These are the things you talked about pandas and numpy and whatnot already, but is there something
44:26 like that or a couple of libraries like that in the energy space?
44:29 The closest I would probably say is the Pyomo optimization library.
44:32 So that I think Clark mentioned in a previous interview.
44:36 Yeah, yeah.
44:37 We had Clark come on to talk about that.
44:39 And he was doing really cool stuff.
44:41 Clark, yeah.
44:41 I'm trying to, I'm going to set up a chat with our team with Clark.
44:46 And that's the plan at a later date.
44:47 Because, yeah, it was very interesting that what he was able to do during his masters with
44:53 linear optimization.
44:54 And so I think, yeah, like really, there may be libraries out there that I haven't come
45:00 across yet at this point.
45:01 But I've really found that the whole, yeah, the Python stack of your pandas, Pyomo for
45:07 optimizations, and even things like, have you come across a library called Geopandas at all?
45:13 Yes.
45:14 Which adds spatial elements to data frames.
45:16 I use that for a lot of analysis.
45:18 Yeah.
45:18 Geopandas sounds cool.
45:19 I haven't done anything with it, but I would love an opportunity to do something fun with
45:23 Geopandas.
45:23 I did that when I was working in consulting.
45:26 I used that library once for looking at data from the Australian Bureau of Statistics.
45:30 And then suddenly, I was in demand for every proposal to be making these heat maps of the
45:35 country.
45:36 I suddenly was just making, I had heat maps coming out everywhere.
45:40 Yeah, they're like, if Jack knows how to make these graphs, give it to Jack.
45:44 He'll build a flag.
45:45 Exactly.
45:47 But Geopandas, if you know a bit about using, you know, pandas and data frames for working
45:51 with data sets, it's pretty much like using a pandas data frame, but it just adds a whole
45:56 bunch of capability for working with spatial data sets and creating beautiful figures as
46:01 well.
46:01 It's amazing.
46:03 Yeah.
46:03 Oh, it sounds super cool.
46:04 Super cool.
46:05 Yeah.
46:05 It works with Shapely.
46:06 It sounds like it would work really well with your 10,000 text files almost even.
46:10 Yeah.
46:11 Some of those things linking it up.
46:13 Yeah.
46:14 Yeah.
46:14 Yeah.
46:14 Alexander out in the live streams coming back.
46:17 Just one quick thought says, I wish people learned at least some programming.
46:20 Making customs software to cover simple cases is definitely tiring.
46:23 And most of the time, it's just a simple script.
46:25 Yeah.
46:26 I mean, kind of the automate the boring stuff could take a lot of people a long ways for sure.
46:30 Yeah.
46:30 At that level.
46:31 Absolutely.
46:32 In a way, a lot of the little things that I would go around and be useful for when I
46:36 was working in consulting, if people had a little bit of programming background, then
46:41 yeah, they almost wouldn't need my input because they understood the area better than me.
46:46 And if they had a little bit of Python and knew how to link up some data sets, then it would
46:52 be like they could just automate so much of some tedious things in their lives.
46:56 One thing I heard a lot in that sort of realm was, if you automate all these things, you're
47:01 going to take our jobs away.
47:02 What are we going to do?
47:03 Like this painful, tedious manual stuff that should be automated.
47:07 Like that's our job because that's what a lot of the people that I had worked with for
47:12 a while.
47:12 That's what they did.
47:13 And they were legitimately a little concerned that if we wrote software that would do those
47:18 things automatically, well, then what would they do?
47:20 And I saw year after year, we would write that software.
47:23 They would say, thank goodness, we don't have to do this again.
47:26 And they would just solve more problems, take on more data.
47:29 Like they would just do more and almost never did it result in, well, we don't need these
47:33 people anymore.
47:33 It just meant they got to do more interesting stuff in a bigger scale.
47:36 Absolutely.
47:37 Like this is what I find that when I work with new data sets or problems, and once you've
47:42 kind of, you know, solved the problem, you understand that data, you fix the issues with
47:45 it.
47:46 Suddenly having that kind of foundation and curated data set lets you actually build on it and do
47:52 more interesting things going forward.
47:54 It's not like, you know, you've done that.
47:55 You can, you know, you never need to do that again.
47:58 Yeah.
47:58 And that's what drew me to the energy sector because it was like, the more I worked with
48:01 these data sets, the more I understood and the more interesting questions I could answer,
48:05 which is really satisfying.
48:07 Yeah.
48:07 Yeah.
48:07 And the more things that are batch processes can become almost real time and really change
48:13 things.
48:13 So speaking of data, it sounds like you guys work with a ton of data over there.
48:17 Give us a sense for the scale.
48:19 Yeah.
48:19 So I guess the more standard data set is there's a database that has pretty much everything
48:26 going on in terms of dispatch on a five minute basis.
48:29 And so for most of your users, if you just want to see what the power station is doing,
48:32 what it's bidding, you can use that data.
48:34 It's large, like pulling out some of these data sets in, it's in, you know, a hundred or
48:39 200 million rows looking at certain parts of it.
48:42 But the thing I'm working on at the moment, it almost makes this kind of look small.
48:46 And this is kind of that same data from that same database, but it's on a four second basis.
48:50 So a single month of data is about 750 million rows.
48:55 And it gets all released as thousands of zip holders containing CSVs.
49:00 One CSV for every half hour.
49:02 Oh my goodness.
49:04 And so is there like a big process that just goes along, unzips it, grabs it, inserts it
49:08 into some database or something along those lines?
49:10 I think that was how it gets shared in some format.
49:13 So what I actually, so this is how I was given the data on my current project.
49:16 And so it's so big, I can't actually unzip it on the machine.
49:20 So I have to use Python to kind of spin up a number of separate processes that will kind
49:25 of work through the different zip folders.
49:28 It will then use, I think Python has a library called zip file.
49:31 So it will unzip the folder in memory, read in the CSVs, process them, and then it will
49:37 eventually concatenate it all back into a cleaned data frame that I can work with going forward.
49:44 And so, and so then I'm trying to use those sets of tools to try and then turn this into
49:49 a more compressed, cleaned data set that I can work with going forward.
49:53 So does that fit in memory or do you have to like only pull out slices sort of dynamically
49:58 with the zip file processing?
49:59 Yeah.
50:00 So I can fit about a month in memory on my machine.
50:03 We do have some large servers.
50:05 And so I will transition to processing this in parallel on the servers, which should get
50:10 an even better speed up.
50:12 But yeah, at the moment, I really just kind of look at things on a monthly basis.
50:15 And so what I can actually do is, and then there's a ton of processing I have to do with
50:20 this four second interval data, because what I can see is I will break the data up then into
50:26 five minute intervals.
50:27 And I, what I can do is I can see what the generator was doing on a four second basis.
50:31 And then I can see what its target was.
50:34 So when they run their optimization, they will say, we know you're sitting at this point here,
50:38 you have to ramp up to hit this target here at the end of this five minute period.
50:43 And so I can use this data to tell how well the generators are actually hitting their targets
50:48 and how well they're following instructions.
50:51 But the funny thing is, even though, you know, you think of four second data as being, you know,
50:55 very, very, such a short interval of time.
50:58 But if you look at some of the big batteries in the grid, that data is actually too slow for
51:04 some of the batteries, because batteries can actually turn on, inject power into the grid.
51:08 turn off again, and I can miss it in the four second data.
51:11 It's amazing.
51:12 Some of these big grid scale batteries are like the big Tesla battery in South Australia at
51:19 Hornsdale.
51:19 They're amazing feats of engineering that you really appreciate when you realize you're
51:23 missing things at a four second interval.
51:24 They break your sensors and things like that.
51:27 Yeah, Australia is really well known for having some of these big batteries in the energy sector.
51:32 I think for some reason, Tesla seemed to have partnered up with you guys to build these.
51:36 Yeah, the plan is to roll out a bunch more of these batteries around the grid as well.
51:42 And they're just really impressive.
51:44 You know how I mentioned the whole challenge of constantly balancing supply and demand?
51:50 And really, that's what batteries are so good at doing.
51:52 Right.
51:53 Their response time is almost instant.
51:55 Yeah.
51:55 So you could just, they could take it in.
51:57 Exactly.
51:58 They could eat the energy or they could initially fill, like immediately fill the gap, right?
52:02 For a while.
52:03 Exactly.
52:03 And sometimes with some of this data, you can actually see the battery will receive an
52:08 instruction.
52:08 It will quickly turn on.
52:10 It will discharge some power.
52:11 And then a couple of seconds later, it will actually then, because there's too much power
52:16 in the grid, the battery will actually then suck up some of that power and recharge and
52:20 do the opposite effect.
52:20 It's just amazing.
52:22 Yeah.
52:22 Fantastic.
52:23 I would love to dive into that, but let's say I'm super fascinated with batteries and
52:27 their potential.
52:28 Talk Python To Me is partially supported by our training courses.
52:34 When you need to learn something new, whether it's foundational Python, advanced topics like
52:39 async or web apps and web APIs, be sure to check out our over 200 hours of courses at Talk Python.
52:46 And if your company's considering how they'll get up to speed on Python, please recommend they
52:51 give our content a look.
52:52 Thanks.
52:52 With all of this data, you said that you had basically learned some good advice, like certain
52:59 things you can just easily do in Pandas and NumPy on small data sets, maybe not so much on
53:05 large data sets like that.
53:07 Give us some of the things that you found to be useful and some of the tips and tricks.
53:10 Absolutely.
53:10 So there's a concept called vectorization.
53:13 I'm not sure if you've come across it, but it's effectively, how can you apply an operation
53:17 to a whole column?
53:18 So you're not writing a manual loop or using conditionals.
53:22 For instance, if I try to multiply a column with millions of rows by a number, it's really,
53:28 really fast because that's all kind of optimized to see under the hood.
53:32 And so with a lot of this, when I'm working with smaller data sets, you can get away with
53:37 doing some manual loops yourself or using Pandas to group by a column.
53:42 For instance, I would often say, this is the identifier for a power station.
53:46 I want you to group by this column identifier and then sum up.
53:52 And even those things start to become too slow once your data is kind of at this scale.
53:57 And so the real trick I find is, yeah, it's how do you find ways where you can apply some
54:03 operation, a calculation to the whole column?
54:06 And, but the tricky part with that starts to be what happens if you want to do conditional
54:10 calculations?
54:10 And so one of the things I find is sometimes I want to see how much the output of, on a four
54:17 second basis, how much is the generation of a power station changing?
54:21 And so you can imagine that Pandas has a calculation that lets you effectively calculate the difference
54:27 between the previous value that came before really, really efficiently.
54:31 But because, you know, I've got all these different generators and intervals, like kind of all
54:36 in the same, you know, data frame, I don't want to consider the first value in a five minute
54:41 interval, because that's affected by, you know, a different time interval as well.
54:46 So what you can do is NumPy has these great functionality called where or select, where you can pretty much
54:55 pass it a column that turns out to be true or false for the whole data set.
55:00 And it will then replace the value with something else really efficiently.
55:04 So what I can do is I can, I can run my calculation for the whole column.
55:08 And then I can use a NumPy where to replace the first value in each five minute interval with a
55:14 missing value.
55:15 And that pretty much does things in, you know, a few seconds that would have taken, I don't
55:21 even know how long with the other way hours, at least.
55:23 Wow.
55:24 It's amazing.
55:25 Yeah, I think that the whole computational space with pandas and with NumPy's, there's,
55:30 you know, like in Python, we speak about Pythonic code, right?
55:33 You would use a foreign loop instead of trying to index into things and so on.
55:37 And then there's a whole special flavor of that in the pandas world, right?
55:41 And a lot of it almost has the guidance of if you're doing a for loop, you're doing it
55:47 wrong, right?
55:47 Like there should be some sort of vector operation or something passed into pandas or something
55:53 along those lines, right?
55:54 Absolutely.
55:55 Like, yeah, it's almost like its own kind of type of problem solving in a way, because it's
55:59 like, how can I apply this calculation to everything in a column, but also in these cases, do something
56:08 else.
56:08 That's really the problem solving in a lot of ways.
56:10 Yeah.
56:11 Yeah.
56:11 It's a lot more set-based thinking, almost like databases.
56:14 Yeah.
56:14 What about things like threading or multiprocessing or stuff like that?
56:18 Like, have you tried to scale out some of the things that you're doing in that way?
56:22 So yeah, so we have a server that has about 60 cores and about 700 gig of RAM on it.
56:28 So that's the plan is I can shift my things over there once this project-
56:31 60 cores?
56:32 That's pretty awesome, actually.
56:34 Yeah.
56:34 We've got a couple of them, which is very useful for all of the energy modeling that we do.
56:38 And usually what I'm doing is kind of a mix of, yes, using Python's multiprocessing library
56:46 to try and, yeah, just split.
56:49 Usually what I'm doing is I'm just processing a whole heap of data frames in parallel and then
56:56 concatenating them back into a single data frame once they're kind of processed.
57:00 That workflow seems to work pretty well for a lot of the requirements that I have on projects.
57:06 Yeah.
57:06 Because you can get each subset data frame bit to do its own computation in parallel, right?
57:12 Yes.
57:12 Yeah, exactly.
57:13 And the other thing too that can also benefit is that usually as part of the cleaning process,
57:19 I'm kind of subsetting the data as well.
57:20 So while the data is starting off at an immense size as well, I'm figuring out which parts of
57:27 it I need and cleaning it.
57:29 And then so then the data frame I end up concatenating back together can be a more manageable size as
57:35 well.
57:35 Right, right, right.
57:36 Interesting.
57:36 Have you looked at Dask for any of this?
57:39 Yes.
57:39 We've had, I did some work on the server for a different project looking at it.
57:44 And I think Dask might be, once I've kind of built up a more curated version of this four
57:50 second interval data, I think Dask will probably be what I'll use on the server for working with
57:55 the whole data set in the future.
57:57 Yeah.
57:58 It sounds like it might really be, I mean, I haven't actually tried to apply to that much
58:02 data that you got there, but it's sort of its functionality.
58:05 It sounds like it really might be the thing to do because it'll take, it basically, your
58:10 description of breaking into the many data frames, having them run and then bringing it back
58:13 together.
58:13 That sounds to me like what Dask is built for, right?
58:16 Yeah.
58:16 And the brilliance as well, I think of the Dask project is how they were able to kind of
58:20 emulate the Python, sorry, the Pandas way of doing things as well, which is great because,
58:25 you know, it's nice not to have to relearn too many things and be efficient from the beginning.
58:30 Also, I should probably just flag as well that these data sets that I'm working with, the four
58:36 second interval, and then the actual database on the five minute basis, one of the things
58:40 that got me so into the energy sector, and that's, I think, unique in a way about the Australian
58:45 energy market, although I stand to be corrected, is that this is all public data.
58:48 If you want, you can go and download all of this data from the market operators website, which
58:53 is, you know, an amazing amount of kind of openness to be able to go in and look at what
58:58 these power stations are doing and what prices that we're getting on such a granular basis
59:02 as well.
59:03 That's been really what fascinated me.
59:05 Yeah, that's super cool.
59:06 You know, if people are out there trying to do research, working on a thesis or something
59:11 like that, they could just grab this data.
59:12 And it's like you said, it's real.
59:14 And a lot of people have both physical machine reasons and financial reasons.
59:18 Keep it accurate, right?
59:19 Yes, absolutely.
59:20 And really, I guess I come back to that original point where the limitation for this data isn't
59:26 how clean it is or the amount of data.
59:29 It's just understanding the processes well enough to know what you can do with it.
59:33 Right.
59:33 A little bit like that example you had about the solar farms versus coal generation, right?
59:40 Exactly.
59:40 Exactly.
59:41 Yeah.
59:41 Know that I mean different things.
59:42 Yeah.
59:43 Yeah.
59:43 Very cool.
59:44 All right.
59:44 Other advice or interesting things going on before we're getting short on time, but
59:49 anything else you want to throw out there?
59:50 Work with all this data?
59:51 One of the areas I'm quite interested in at the moment is Python's number library.
59:55 N-U-M-V-A.
59:57 Yeah.
59:57 I think it uses the able to kind of compile Python code under the hood to get really high
01:00:03 performance.
01:00:03 And it can be perfect for my use.
01:00:06 And the reason I'm rather interested in it is that if I can vectorize a calculation,
01:00:11 you know how I'm applying it to the whole column.
01:00:13 But for instance, if I'm trying to do some calculation where I want to loop through it
01:00:20 because my current calculation depends on the state of a previous calculation, then that can
01:00:25 be a limitation of this kind of vectorization approach.
01:00:29 Whereas...
01:00:29 Right, right.
01:00:29 You can't just apply it to the set and go, hey, every row here, just look back at yourself
01:00:35 a little bit in that place and then do the thing.
01:00:38 It's got some dependencies on what happened before, right?
01:00:42 And that, I have no idea how you would fix that.
01:00:44 Maybe it's possible, but it's very tricky, right?
01:00:46 And so number does that, okay?
01:00:47 So number is effectively a way to write Python loops that run as fast as C, but within for
01:00:54 numeric calculations.
01:00:55 So this is why I'm very interested in this for some of the areas that are a little bit
01:01:00 trickier for me to vectorize using data frames.
01:01:04 I'm very interested in the number library as a solution for some of those challenges.
01:01:08 Yeah.
01:01:08 So number makes Python code fast.
01:01:10 It says it's an open source JIT compiler that translates a subset of Python and NumPy
01:01:15 code into fast machine code.
01:01:17 So I haven't used it, but it sounds like it really knows about NumPy in addition, right?
01:01:22 Because you could use Cython, but Cython doesn't necessarily know anything about NumPy, for
01:01:25 example, right?
01:01:26 Yes.
01:01:26 Yeah, you're exactly right.
01:01:28 Like in a way, number has kind of replaced what I would have used Cython for in the past,
01:01:33 but for my application.
01:01:34 What I could do, say for instance, if I have a NumPy array and I want to loop through it
01:01:40 and there's some calculation I want to do and then my next calculation depends on that previous
01:01:44 calculation going forward.
01:01:45 This lets me do that.
01:01:47 Yeah, in a way, and I'm writing Python code.
01:01:49 I don't have to write C or C++.
01:01:51 You can see it.
01:01:52 You're literally adding decorators, just like how Flask has that lovely kind of decorator
01:01:58 syntax.
01:01:59 It's almost like that to an extent.
01:02:01 Yeah, exactly.
01:02:01 You say at number.jit and then do you want this to run in parallel or not?
01:02:06 Yeah, sure.
01:02:07 Why not?
01:02:07 Exactly.
01:02:08 And also it even lets you run your calculations in parallel as well.
01:02:12 You can see that little parallelism true.
01:02:14 And it's actually true parallelism without the GIL as well, which is amazing.
01:02:19 Yeah, this is super interesting.
01:02:20 I knew that it was a compiler along the lines of Cython, but I didn't realize that it had
01:02:25 this special integration with NumPy.
01:02:26 That's very neat.
01:02:27 Yeah, I really recommend, like, I think for most people, Pandas is probably what you need.
01:02:33 But if you're running into these kinds of, yeah, these types of problems, then I think
01:02:37 NumPy would be a solution before you would have to look to, necessarily have to look to
01:02:43 a different programming language.
01:02:44 Yeah, absolutely.
01:02:45 And like, this is how I started off our conversation together.
01:02:48 The performance side of Python is super interesting because it's like, oh, well, it's not really
01:02:53 fast enough.
01:02:54 Until you apply this decorator, then all of a sudden it's just as fast and it's amazing.
01:02:57 There's just all these little edge cases that are super neat.
01:03:00 Yeah.
01:03:00 Very, very cool.
01:03:01 I look back to some of the code I wrote during my PhD and I cringe at some of the bad performance
01:03:07 practices I probably had for working with them.
01:03:09 And I think this comes back to your point about having people in the team who are a bit more
01:03:14 experienced in this area.
01:03:15 Because if you can have people who understand this and point team members to these tools
01:03:20 for optimizing their code, then I think that can deal with a lot of the issues for people
01:03:23 who may not be as experienced with writing Python themselves.
01:03:27 Yeah, that's super advice.
01:03:28 And then if you've got data that maybe is like the other side of your story, it's like
01:03:32 too big to fit in RAM or you want more sort of automatic, rather, parallelism across, say,
01:03:39 a large data frame, then Dask is definitely a good thing to look at.
01:03:42 Absolutely.
01:03:43 All right, Jack.
01:03:44 This has been super interesting.
01:03:45 I think we're getting a little long on time.
01:03:47 I don't want to take up your entire day.
01:03:49 So I will have to call it a show on that bit.
01:03:52 No problem.
01:03:52 But before we get out of here, of course, you have to answer the two final questions,
01:03:56 as always.
01:03:56 So if you're going to write some code, work on some of these projects, what editor do you
01:04:02 use?
01:04:02 VS Code.
01:04:02 Especially since they added Jupyter Notebooks into the editor as well.
01:04:07 Yeah, it's really interesting to see both what VS Code and PyCharm are doing to try to bring
01:04:12 either just bring notebooks into the space or try to come up with a more native alternative,
01:04:18 right?
01:04:19 Like, well, here's a cell and it's separated by like this special comment, but you can still
01:04:23 run it in notebook style.
01:04:25 But it's like feels like a text file you're working with.
01:04:27 And yeah, it's an exciting time for that stuff.
01:04:29 Absolutely.
01:04:30 Yeah.
01:04:30 And then you've already given a shout out to a couple of different projects.
01:04:34 But any notable PyPI packages you want to tell people about?
01:04:38 Yeah, I mean, Numbers is the one I'm fascinated with in terms of learning more about at the
01:04:43 moment.
01:04:43 But I think for in terms of getting things done, just Pandas and Geopandas and the kind
01:04:49 of scientific stack, it's just, it's amazing what people, the code that people have done
01:04:54 that makes me so effective just by understanding, just being able to use their libraries.
01:04:58 It's phenomenal.
01:04:59 It's phenomenal.
01:05:00 Yeah.
01:05:00 Are you a Jupyter or a JupyterLab person or something else?
01:05:04 I use mainly Jupyter, mainly because at least at the time when I tried out JupyterLab, I couldn't
01:05:09 collapse some of the outputs from the cells as well.
01:05:11 They may have fixed that, but I'll take a peek at JupyterLab every couple of months or so
01:05:16 and see what's new.
01:05:18 All right.
01:05:18 Fantastic.
01:05:19 All right.
01:05:20 Well, final call to action.
01:05:21 People are interested in, maybe they work in energy somewhere else in the world or they're
01:05:26 trying to do research with it.
01:05:27 What do you tell them?
01:05:28 If you're interested in getting in touch with me, we run a few meetups for energy modelers
01:05:32 in Sydney.
01:05:32 So if you're ever interested in getting in touch to chat about some of the data in Australia
01:05:36 or some of the work we're doing, feel free.
01:05:38 Is that Zoomable these days or is it in person?
01:05:41 The plan is for the meetup to be up as a Zoom one.
01:05:44 So that's the plan.
01:05:46 Yeah.
01:05:46 All right.
01:05:46 Fantastic.
01:05:47 Well, Jack, it's been great to have you here.
01:05:49 Thanks so much for sharing what you're up to.
01:05:51 Thanks so much, Michael.
01:05:52 It was great meeting you.
01:05:53 Thanks for having me.
01:05:53 Yeah.
01:05:54 Keep the lights on down under.
01:05:55 Thank you.
01:05:56 I will.
01:05:56 Bye.
01:05:58 Bye.
01:05:58 Have a good night.
01:05:59 This has been another episode of Talk Python To Me.
01:06:02 Our guest on this episode was Jack Simpson, and it's been brought to you by Square, Linode,
01:06:07 and Assembly AI.
01:06:08 With Square, your web app can easily take payments, seamlessly accept debit and credit cards, as
01:06:13 well as digital wallet payments.
01:06:15 Get started building your own online payment form in three steps with Square's Python SDK
01:06:20 at talkpython.fm/square.
01:06:23 Simplify your infrastructure and cut your cloud bills in half with Linode's Linux virtual machines.
01:06:29 Develop, deploy, and scale your modern applications faster and easier.
01:06:32 Visit talkpython.fm/linode and click the Create Free Account button to get started.
01:06:37 Transcripts for this and all of our episodes are brought to you by Assembly AI.
01:06:41 Do you need a great automatic speech-to-text API?
01:06:44 Get human-level accuracy in just a few lines of code.
01:06:46 Visit talkpython.fm/assembly AI.
01:06:49 Want to level up your Python?
01:06:51 We have one of the largest catalogs of Python video courses over at Talk Python.
01:06:55 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:07:00 And best of all, there's not a subscription in sight.
01:07:03 Check it out for yourself at training.talkpython.fm.
01:07:06 Be sure to subscribe to the show, open your favorite podcast app, and search for Python.
01:07:10 We should be right at the top.
01:07:12 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:07:17 and the direct RSS feed at /rss on talkpython.fm.
01:07:21 We're live streaming most of our recordings these days.
01:07:25 If you want to be part of the show and have your comments featured on the air,
01:07:28 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:07:32 This is your host, Michael Kennedy.
01:07:34 Thanks so much for listening.
01:07:36 I really appreciate it.
01:07:37 Now get out there and write some Python code.
01:07:39 I'll see you next time.
01:07:59 Thank you.