Event Sourcing Design Pattern



Episode Deep Dive
Guest Introduction and Background
Chris May is a Python developer with about 20 years of experience and a longtime listener of Talk Python To Me. He learned to program as an adult after a friend suggested he try Python, and he came to programming from a graphic design background, which still shapes his obsession with great user experiences and fast page loads. Chris started and helps run PyRVA, the Python user group in Richmond, Virginia, which is over 10 years old and meets monthly. He has been quietly following event sourcing for over a decade, eventually leaning into it during a career break and now uses it as his default architecture in his day job. Outside of his work code, he writes and shares about event sourcing on his site Everyday Superpowers and recently published a free intro ebook on the topic. This is Chris's second appearance on the show, returning after the recent Datastar panel episode.
What to Know If You're New to Python
- This episode is architecture-heavy, so it helps to be comfortable with the basics of databases, CRUD operations (create, read, update, delete), and Python classes before listening.
- You don't need to know any specific framework, but a passing familiarity with an ORM (like Django's ORM or SQLAlchemy) will make the read-model and migration discussion click faster.
- Concepts like caching, JSON serialization, and "what is an API" come up casually; if those are still fuzzy, the episode will land much better after a beginner Python course.
- Chris and Michael also wander into AI-assisted coding with tools like Claude Code, so a basic mental model of "LLMs as a coding assistant" is helpful context.
Key Points and Takeaways
Event Sourcing: Your Database as an Append-Only History, Not a Single Mutating Row
The central idea of the episode is that event sourcing flips how you save data. Instead of a CRUD-style row that mutates over time (a shopping cart that ends up looking like every other "checked out" cart), you store every change as an immutable event: cart created, item added, item added, item removed, checked out. The current state is derived by replaying those events. Chris contrasts two users who both end up purchasing three items: in CRUD, their database rows are indistinguishable; in event sourcing, the full behavioral history is preserved. Michael frames it as "your database becomes an audit log" and notes the analogy to Git, where files are reconstructed from a base plus a series of diffs. That single shift is the foundation for everything else discussed in the episode.
The eventsourcing Library by John Bywater
When you actually want to build this in Python, Chris's recommendation is the eventsourcing package maintained by John Bywater. You write Python classes, decorate them or subclass from the framework's base classes, and the library handles the storage, replay, and orchestration. It supports SQLite, Postgres, and event-sourcing-specific databases, and there are companion packages for Django and SQLAlchemy that let your event store live next to your existing models with proper migrations. Chris notes that John has even opted the project into DeepWiki, which produces an AI-powered chat over the source and docs, an idea Michael found so useful he made it a side quest of his own. If you want a turnkey path into event sourcing in Python, this is the on-ramp.
- pypi.org/project/eventsourcing
- pypi.org/project/eventsourcing-django
- pypi.org/project/eventsourcing-sqlalchemy
- deepwiki.com
"Isn't It Slower?" Read Models, CQRS, and Why Computers Are Fast
The first instinct most developers have is that replaying events on every read must be expensive. Chris's answer, echoing his mentor Martin Dilger, is that for streams under roughly 2,000 events the event store itself is fast enough in milliseconds, and beyond that you reach for a read model: a separate, denormalized projection that subscribes to the events you care about and is incrementally updated. This is the CQRS pattern (Command Query Responsibility Segregation) that Chris uses alongside event sourcing. Michael adds that you can layer caches in front of the read model: a Valkey or Redis cache, or even a local on-disk cache like Python's diskcache library, with cache invalidation triggered by new events. The takeaway is that event sourcing does not force you to be slow; it gives you many places to optimize.
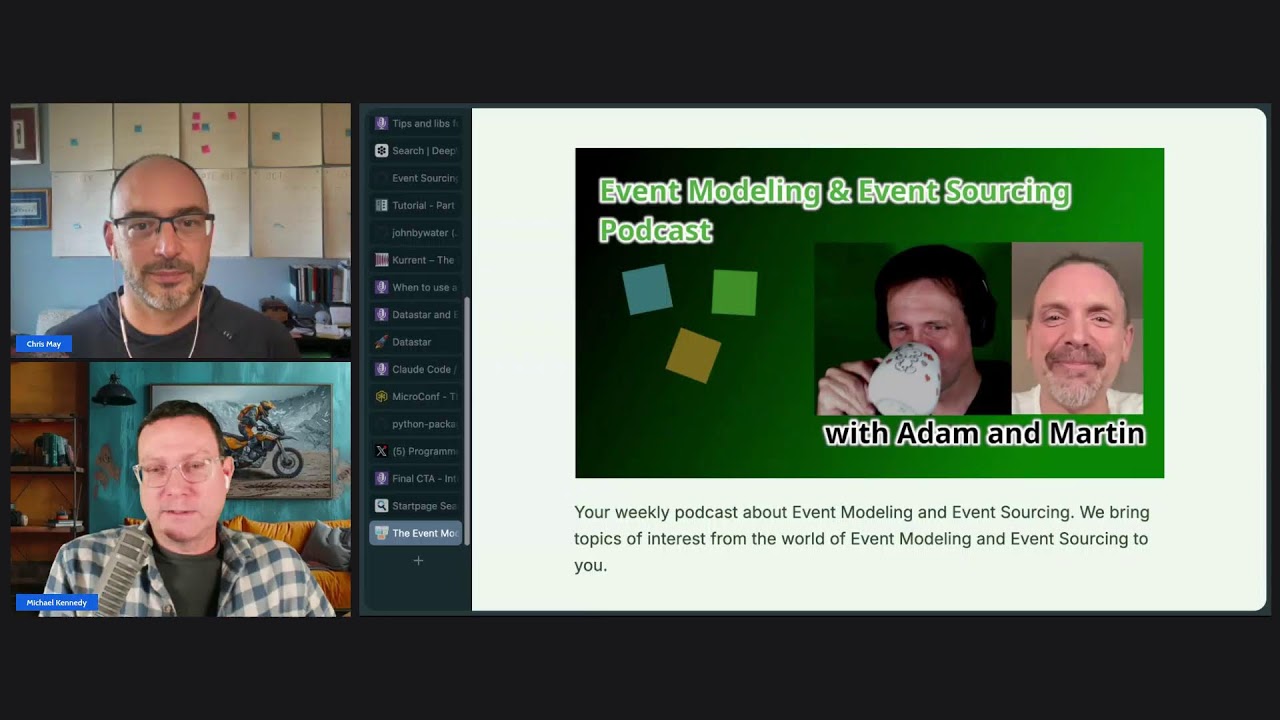
The North Stars: Martin Dilger and Adam Dymitruk
Chris credits two people as his event sourcing North Stars: Martin Dilger and Adam Dymitruk. Martin saw a gap in beginner-friendly material (event sourcing came out of the domain-driven design world and is heavy on jargon), and wrote the ebook "Understanding Event Sourcing" in roughly two months. The book is what moved Chris from "I built one event-sourced project" to "this is now my default architecture." Both Martin and Adam independently arrived at the same combination of patterns: event sourcing as the foundation, plus vertical slice architecture, CQRS, and a documentation technique called event modeling diagrams. They co-host a podcast literally named the "Event Modeling and Event Sourcing Podcast," which Chris recommends as his ongoing source of new ideas in the space.
Event Modeling Diagrams (and Why AI Loves Them)
Event modeling diagrams are a deliberately reduced visual language for describing the lifecycle of an application: a small set of shapes that show events, commands, and views over time. Chris finds them indispensable on event-driven teams because they keep everyone aligned on "what does what" without drowning in prose. The surprising follow-on is that LLMs read these diagrams really well. Chris cites research spikes by Martin and Adam where they recorded a client conversation, generated an event modeling diagram from it, then generated working code from the diagram, getting roughly 80-85% of the way to a solution in hours instead of weeks. The diagram becomes a compressed, AI-friendly contract for the system.
Why Event Sourcing Is a Great Fit for AI-Assisted Coding
Chris's company has mandated that every piece of code be written with AI, and he has noticed a striking pattern: Claude Code is dramatically more productive in his event-sourced service than in the neighboring CRUD services. The reason is structural. Vertical slice architecture means each feature lives in a small, self-contained group of files, which fits cleanly into a context window. The event names themselves describe the domain, so the model can reason about subscriptions and state transitions without scanning hundreds of files. In the older services, he has to feed the agent much more context to get the same quality. The lesson is that architectures that produce small, well-named, locally-coherent units of code are also the architectures AI codes well in.
The Storage and Replay Optimization Toolkit
Michael lays out a menu of optimization options and Chris confirms all are valid depending on use case. First, you can use the event store directly for short streams. Second, you can build a database-backed read model that subscribes to events and stays incrementally up to date. Third, you can push to a fast in-memory layer like Valkey or NATS for live UIs that need to stream changes to the browser. Fourth, you can use a local on-disk cache like diskcache when you don't want extra infrastructure. Michael also pitches storing the computed state and the embedded event list together inside a single document in MongoDB, which lets you atomically update both at once. The point is that flexibility is the feature: pick the projection that matches the query.
Event Versioning: Upcasters, Defaults, and the Nuclear Option
Schema change is the question Michael presses Chris on, since event sourcing can't just "run a migration to update the current state." Chris describes three strategies. The first is the document-database style: when you only add fields, most consumers ignore them and the few that care use a default fallback close to the domain logic that needs the new attribute. The second is upcasters, small functions that convert an old event version into a new one when read, kept local to the slice that needs the upgrade rather than as a global step. The third is the nuclear option: copy the entire event store into a new store while transforming each event in flight. Greg Young, who popularized event sourcing, wrote a whole book on this on LeanPub.
When to Use Event Sourcing (and When Not To)
Chris flips the usual question and asks when you should reach for it. Two heuristics: first, if your table has a "status" column, that's a strong signal, because a status column means one record can be in multiple states with different rules, which is no longer pure CRUD. Second, if you ever worry about losing data or being unable to answer a future question, event sourcing keeps the door open by default and lets you choose later when (or whether) to discard. The honest counterweights are real: pure "forms over data" applications like simple contact forms or admin tables don't need it; storage costs more (though storage is the cheapest commodity in modern infrastructure); and most importantly, it requires team buy-in, because a pattern that half the team works around is worse than not having the pattern at all. Chris also notes you can adopt it incrementally, mixing event-sourced and CRUD models in the same project.
Surprise Wins: Time Travel for Analytics, Debugging, and Compliance
Chris's favorite real-world payoff has been answering questions he didn't know he'd be asked. When a sister team asked his service to start sending data to their BigQuery instance, he was able to backfill months of history on day one because every event was already there. When his boss asked for a 30-day report table, he wrote it once and instantly had 30 days of populated history. The same property pays off for debugging: instead of staring at a row that is mysteriously null and asking "how did this happen?", you can see the specific event that produced the bad state. And for compliance frameworks like PCI, HIPAA, and GDPR, the event log is naturally the audit trail rather than a fragile parallel "history table" that teams forget to write to.
"Closing the Books" Keeps Streams Short
A listener (Mike, in the chat) raised the obvious worry: storage requirements. Chris's answer is that well-designed event-sourced systems keep individual streams short, often a dozen events, sometimes two dozen. The technique borrowed from accounting is called "closing the books": at a natural boundary (end of day, end of period), you emit a summary event and start a fresh stream. Replays then read the summary plus today's events instead of every event since day one. Older events go to cold storage, or get deleted, depending on what your domain requires. This is the answer to "won't this grow forever?": no, because you design boundaries into the domain.
Document Databases as a Natural Event Store
Both Chris and Michael note that the shape of an event, a small ID-stamped envelope around a JSON payload, is essentially a document. Chris already uses Firestore as his event store. Michael pushes the idea further: you could keep computed values (cart total, item count) on the top level of a document and the event list as a nested array, then atomically update both in one operation, which a relational database can't easily do. The episode treats this as worth experimenting with, with the caveat that it pulls you back toward thinking in models, which the modern "model-less" event sourcing camp pushes against.
Git Worktrees, Planning Sessions, and Issues as Agent Memory
In the closing AI segment, Michael and Chris compare workflow notes. Chris uses Git worktrees to give Claude Code an isolated copy of the repo per feature, and has found a hard cap of two or three concurrent worktrees before he loses context himself ("now I know what the LLM is"). Michael's complementary practice is to run a planning session with the AI, then have it create a GitHub issue (via the gh CLI) capturing the plan, so subsequent sessions can be told "work on issue 127" and pick up where the last one left off. Both emphasize the intern metaphor: very smart, very fast, very confident, and in need of guidance. AI coding is an engineering skill, not a chat-and-pray habit.
The Domain-Driven Design Lineage
Event sourcing did not appear in a vacuum, and Michael makes a point of placing it in its lineage. He pulls up his own copy of Eric Evans's "Domain-Driven Design: Tackling Complexity in the Heart of Software," purchased in April 2005, as a reminder that this whole conversation grew out of the late-1990s and early-2000s refactoring and DDD movement led by people like Martin Fowler. Chris's closest read in the Python world is "Architecture Patterns with Python" (the Cosmic Python book) by Harry Percival and Bob Gregory, which covers many of these patterns in idiomatic Python.
Interesting Quotes and Stories
"Event sourcing has to do with how you save data to the database. The best way to contrast it is most apps are kind of CRUD based... Event sourcing, on the other hand, captures every change that happens within the system." -- Chris May
"Your database sort of becomes almost an audit log. It feels very source control-ish. It feels like Git, right? Like what you store is the file and then the diff, then the diff, then the diff." -- Michael Kennedy
"I don't know about you, but like when I first heard about this, I'm like, well, isn't it slower? ... And it turns out computers are fast." -- Chris May
"Three days after we did a go live, I created a meeting to circle back with them to make sure everything's working the way they wanted. And when they opened up the BigQuery database, they were shocked because they were expecting three days worth of data. I had sent every piece of data I had for months." -- Chris May
"And to be able to answer those questions with precision is intoxicating." -- Chris May, on querying the past with event sourcing
"It's a lot like a backup strategy. If you never test your backup strategy, you don't have backups." -- Chris May, on history tables that no one verifies
"If you have a database column called status, that means one item can be in multiple different statuses... and so event sourcing would be a great option for that." -- Chris May, on when to reach for event sourcing
"Friends outside of tech: lol, copilot is dumb. Friends in tech: I just bought iodine tablets, and I've made an offer in land upstate. My supplies of antibiotics and potable water are sufficient, but I need to set up for the hydroponics to make it through the first few years." -- Michael Kennedy, sharing a meme about how AI is received
"It's an engineering skill. It is not just, let's fire it up and ask for it." -- Michael Kennedy, on working with AI coding tools
Key Definitions and Terms
- Event Sourcing: A persistence pattern where every change to application state is captured as an immutable event, and current state is derived by replaying those events.
- CRUD: Create, Read, Update, Delete. The traditional pattern of mutating rows in place to reflect current state, optimized for data integrity but lossy about history.
- Aggregate (or Model): In domain-driven design, the boundary around a coherent set of data and the events that modify it (for example, a "shopping cart").
- Read Model / Projection: A separate, denormalized view of the data, built by subscribing to events and incrementally updating, optimized for fast queries.
- CQRS (Command Query Responsibility Segregation): Separating the write side (commands that produce events) from the read side (queries against read models).
- Vertical Slice Architecture: Organizing code by feature rather than by technical layer, so each feature has its own commands, events, handlers, and views together.
- Event Modeling Diagram: A reduced visual language for describing how events flow through a system over time, used both for team communication and as input for AI code generation.
- Upcaster: A small piece of code that transforms an older version of an event into the current version when it is read.
- Closing the Books: A practice borrowed from accounting where a periodic summary event is emitted, allowing future replays to start from the summary instead of from day one.
- Forms Over Data: Applications where the UI essentially mirrors a database table, with no meaningful state transitions, where event sourcing is usually overkill.
- Event Store: The append-only storage layer where events are written and read, optionally backed by SQLite, Postgres, a document database, or a purpose-built database like KurrentDB.
Learning Resources
If you want to go deeper after this episode, here are courses to keep building your foundation in Python, data, and the kinds of systems that benefit from event sourcing.
- Python for Absolute Beginners: The right place to start if Python itself is still new, before you take on architectural patterns.
- Just Enough Python for Data Scientists: The bridge from notebook scripting to production-quality, reproducible work, useful when your event-sourced system needs to feed real analytics.
- MongoDB with Async Python: Document databases are a natural fit for event payloads; this course covers Beanie, Pydantic, and async patterns end-to-end.
- Building Data-Driven Web Apps with Flask and SQLAlchemy: Useful background if you plan to use the eventsourcing-sqlalchemy companion package.
- Django: Getting Started: Pairs well with the eventsourcing-django package Chris uses on his side projects.
- Modern APIs with FastAPI and Python: For exposing your event-sourced services through clean, typed APIs.
- Async Techniques and Examples in Python: Helpful when you start streaming events to UIs over websockets or server-sent events.
- Getting started with pytest: Event-sourced systems are unusually testable because events are pure data; pytest will let you take advantage of that.
- Up and Running with Git: Chris and Michael both lean on Git worktrees for AI-assisted coding; this course gets you confident with the tool.
Overall Takeaway
Event sourcing is one of those patterns that quietly changes the questions you're allowed to ask. Once your system records every change instead of overwriting yesterday's truth, you stop arguing with your database about what happened and start asking what could happen next: new reports become a script away, debugging becomes a replay instead of a seance, compliance becomes a side effect, and AI coding agents have small, well-named seams to work inside. The trade-offs are real (more storage, more concepts, and a real need for team buy-in), but the upside is a codebase that is honest about its own history. Chris's advice is the right place to land: start small, pick one slice that has a "status" column or a question you wish you could answer about the past, try it there, and see if it gives you the same kind of joy it has given him.
Links from the show
Chris May: everydaysuperpowers.dev
Intro to event sourcing e-book: everydaysuperpowers.gumroad.com
Domain-Driven Design: The Power of CQRS and Event Sourcing: How CQRS/ES Redefine Building Scalable System: ricofritzsche.me
DDD: www.amazon.com
Understanding Eventsourcing (Martin Dilger): www.amazon.com
Event Sourcing Explained using Football Video: www.youtube.com
Why I finally embraced event sourcing and why you should too article: everydaysuperpowers.dev
valkey: valkey.io
diskcache: talkpython.fm
eventsourcing package: github.com
eventsourcing docs: eventsourcing.readthedocs.io
John Bywater: github.com
Datastar: data-star.dev
Microconf: microconf.com
Event Modeling & Event Sourcing Podcast: podcast.eventmodeling.org
Python Package Guides for AI Agents: github.com
Iodine tablets AI joke: x.com
KurrentDb: www.kurrent.io
Watch this episode on YouTube: youtube.com
Episode #548 deep-dive: talkpython.fm/548
Episode transcripts: talkpython.fm
Theme Song: Developer Rap
🥁 Served in a Flask 🎸: talkpython.fm/flasksong
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 What if your database worked more like Git?
00:02 Every change captured as an immutable event instead of a single mutating row that quietly forgets its own history.
00:09 That's event sourcing.
00:10 And Chris May is back on Talk Python, fresh off our Datastar panel, to walk us through what event sourcing actually looks like in Python.
00:18 We'll cover core patterns, the libraries to reach for, when not to use it, and why event sourcing turns out to be a surprisingly good fit for AI-assisted coding.
00:27 This is Talk Python To Me, episode 548.
00:29 Recorded May 5th, 2026.
00:47 Welcome to Talk Python To Me, the number one Python podcast for developers and data scientists.
00:54 This is your host, Michael Kennedy.
00:56 I'm a PSF fellow who's been coding for over 25 years.
01:01 Let's connect on social media.
01:02 You'll find me and Talk Python on Mastodon, Bluesky, and X.
01:05 The social links are all in your show notes.
01:08 You can find over 10 years of past episodes at talkpython.fm.
01:12 And if you want to be part of the show, you can join our recording live streams.
01:15 That's right.
01:16 We live stream the raw, uncut version of each episode on YouTube.
01:20 Just visit talkpython.fm/youtube to see the schedule of upcoming events.
01:24 Be sure to subscribe there and press the bell so you'll get notified anytime we're recording.
01:29 This episode is sponsored by Sentry's Seer.
01:32 If you're tired of debugging in the dark, give Seer a try.
01:35 There are plenty of AI tools that help you write code, but Sentry's Seer is built to help you fix it when it breaks.
01:40 Visit talkpython.fm/sentry and use the code Talk Python26, all one word, no spaces, for $100 in Sentry credits.
01:49 And it's brought to you by Temporal, durable workflows for Python.
01:53 Write your workflows as normal Python code and Temporal ensures they run reliably, even across crashes and restarts.
02:00 Get started at talkpython.fm/Temporal.
02:04 Hey, Chris.
02:05 Hey there.
02:05 How's it going?
02:06 I'm well.
02:07 How are you?
02:08 Oh, good.
02:08 Good to hear it.
02:09 I'm happy to have you back on the show.
02:11 Last time we had you on the show, you were part of the panel around Datastar, and that was cool.
02:16 Now we're going to talk about event sourcing, but we'll find a way to tie it back to Datastar just a bit, I think.
02:21 I see it on the horizon.
02:23 Or on the show notes.
02:25 Sounds good.
02:25 One of these.
02:26 Yeah.
02:26 Well, not everyone listens to every episode.
02:28 We've got new listeners coming all the time, so give us the quick intro.
02:32 Who are you, Chris?
02:33 Who am I?
02:33 Let's see.
02:34 I am a Python developer for about 20 years and a long-time listener to the show, so it's a very big privilege to be on, finally, my own self.
02:43 And by the way, great job continuing going, Michael.
02:46 You're constantly putting out great content, so I really appreciate all your work.
02:50 But as far as me, I learned the program as an adult.
02:53 Friend suggested I learn Python.
02:56 I hitched my wagon to this engine, and I've loved it ever since.
03:01 I was a technical coach for a little while.
03:04 I started the Python group here in Richmond, Virginia, PyRVA.
03:09 So if you're local, come out.
03:10 In fact, we're just two weeks away from the next meeting.
03:14 Awesome.
03:14 How frequently do you have meetings?
03:15 Once a month now.
03:16 In fact, if you look behind me, you can see all these blue dots are the meetings.
03:20 Okay, excellent.
03:22 Keep planning.
03:22 What are some of the kind of topics you all have?
03:24 Oh, man.
03:24 We range pretty much whatever we can figure out that people are interested in.
03:29 We've had a number of AI discussions.
03:32 In fact, those have been really powerful.
03:34 We've kind of lined up the chairs in a big circle and just have a discussion.
03:38 And it's really incredible.
03:40 You know, you have people on the whole spectrum of opinions about AI.
03:47 So, yeah, it was very, very...
03:49 That was one of my favorite...
03:50 I was going to say episodes.
03:52 One of my favorite meetings.
03:54 I think we might bookend this podcast episode with a little AI at the start, a little AI at the end.
04:00 Sounds good.
04:01 Cool.
04:01 So, yeah, people will just go attend that.
04:04 And I guess probably a meetup.com is where they find you.
04:07 It is, yeah.
04:08 And you can go to pyrva.org to get to the meetup page either way.
04:12 Yeah, easiest way.
04:13 Because you can find a lot of crazy stuff.
04:14 You'll probably find people with pet pythons that want to meet up in Virginia as well.
04:18 And it's not the same thing.
04:20 Indeed, yeah.
04:21 Thankfully, and we are, gosh, over 10 years old.
04:24 So we are one of the first ones to pop up just because of age, I think, sometimes.
04:28 Although, honestly, some of the newer ones pop up ahead of us sometimes, too.
04:32 So, you know.
04:32 It's such a contentious topic, this AI stuff.
04:36 You know, talking about your meetup.
04:37 How did that go?
04:38 Were people frustrated?
04:39 People excited?
04:40 Yeah, it was kind of the whole spectrum.
04:42 You know, I felt like it was great because everybody respected each other.
04:45 And there were, I'd say, two people anchored on each of the sides.
04:51 You know, two people who, actually, maybe there were three people who, you know, have bought their own hardware and are really going deep into AI and, you know, encouraging people to, like, really dig into it.
05:01 And we had two people who were very AI skeptic and very, you know, worried about the environment, you know, all sorts of different things.
05:10 And so, I thought it was a very healthy, very good discussion.
05:14 You know, I walked away with, you know, a healthier respect for both sides.
05:20 Some ideas that I incorporated into my work, especially now that the company I work for gives us a mandate to use AI to write every piece of code.
05:28 So, that's been a very fascinating transition for me.
05:32 But it also gives me, you know, a little bit of agency or a little bit of permission to experiment and see what to do, you know, how to actually function in this new paradigm.
05:44 It is engineering.
05:45 And we'll talk about it more later, but it's quite wild that your company's, that is the position.
05:50 I don't necessarily think it's the wrong position.
05:52 I think it might be the right one, but it's, I think it's got to be brought on from a, from a, this is a skill you need to learn, not just throw stuff at the chat bot and now that's your job.
06:03 Like, these are not the same things, you know?
06:04 But I think a lot of people do, especially when they're getting started, treat them as the same thing and then say it doesn't work and then they're frustrated.
06:10 Yeah, totally.
06:11 Yeah.
06:11 Yeah.
06:12 Yeah.
06:13 All right.
06:14 More of that.
06:15 We'll speak further about certain things, but yes, I agree.
06:19 Absolutely.
06:19 Absolutely.
06:20 All right.
06:20 Well, we'll, we'll come back to that and, and get there, but let's talk about a little bit of this event sourcing thing.
06:27 Yeah.
06:28 What exactly is event sourcing?
06:30 That's a question.
06:30 Okay, cool.
06:31 I wasn't sure if you had more.
06:32 I saw your.
06:33 No, no.
06:33 I think I, when you, when you reached out and said, Hey, let's talk about this.
06:36 I'm like, I, so let's take a step back.
06:38 Okay.
06:39 Design patterns, refactoring ideas, like all of these architecture.
06:44 I love to talk about this stuff.
06:45 I love to think about this stuff.
06:47 I think also, maybe that's a why, one of the reasons I'm not super frustrated with the AI things because I will tell it, I want you to use, like you could say like, I want to build a system with event sourcing and it's going to work this way.
06:57 Like for me, the fun is like, Oh, I got to build some of the event source and it clicks together with this and it does that.
07:02 And like, yeah, I didn't have to do all the little checks and details and like the file IO, but whatever.
07:07 Like I can skip that and build just like, think a little bit bigger and a little more, more big building blocks.
07:12 So I'm a big fan of design patterns and paying attention to what you're doing, I can tell that you are too.
07:18 Yes.
07:19 Especially event sourcing, I would say.
07:22 So I have been following the topic of event sourcing for over a decade.
07:27 I listened to a podcast in with a couple of developers in the PHP realm and they were talking about event sourcing and it just inspired me.
07:36 specifically the things that I really loved.
07:39 Before I was a programmer, I was a graphic designer.
07:42 And so creating websites with exceptional user experiences is something that just makes me excited.
07:48 And at the time, I was working at a creative agency building websites that would just slow, get slower and slower and slower, the more data we put into it or, you know, the more we configure the routing or the navigation and whatnot.
08:01 And so the thought of never having a slow page load again was intoxicating to me.
08:08 However, that was in a portion of my career where I was, had so much imposter syndrome, having learned to program in as an adult and I just felt like I couldn't suggest to my lead developer we should lean into this.
08:23 And even when I was a lead developer, I just didn't feel confident that I could lead a whole team into like a redesign of the code.
08:32 But a couple years ago, I got laid off and I was like, you know what?
08:35 I've been wanting to explore event sourcing for 10 years.
08:39 I'm going to do it.
08:40 And it turns out it's a lot easier than I thought.
08:43 But anyway, all this to say, let me define event sourcing since I've kind of danced around it.
08:47 Event sourcing is how, has to do with how you save data to the database.
08:52 The best way to contrast it is most apps are kind of CRUD based, right?
08:56 So you create a table, like let's say you're a shopping cart application.
09:00 You have a table called carts and you have a bunch of columns and one of the columns has data for the product IDs that are in the cart.
09:10 And so if you have that kind of situation and you have one user who adds five items to the cart, then removes two and then checks out.
09:20 And then you have another user who adds just three items to the cart and checks out.
09:23 Well, if they check out at the same time and you look at the two database rows, they are very similar.
09:28 They're the same user, basically.
09:30 They get put in the same cohort from your marketing side, right?
09:34 Yeah.
09:35 Both of them checked out exactly the same products.
09:39 And if you look at the database, you'd have no idea that one of them removed two items from their shopping cart.
09:44 So event sourcing, so the reason that is because CRUD based applications will mutate state in the database to ensure it's always up to date with the current state and optimize for data integrity.
09:58 Event sourcing, on the other hand, captures every change that happens within the system.
10:04 So you would have an event of like cart created, item added to cart, item added to cart.
10:10 You'd have five item added to cart events and two removals.
10:14 And so you could have the whole history of how each user interacts with your system in the database.
10:19 That is essentially the core of event sourcing.
10:22 Everything else is actually adding more design patterns onto event sourcing, which is really wonderful.
10:27 But that is what event sourcing is.
10:29 Right.
10:29 So your database sort of becomes almost an audit log.
10:33 It feels very source control-ish.
10:35 It feels like Git, right?
10:36 Like what you store is the file and then the diff, then the diff, then the diff.
10:41 You get back to the file by running all the operations on it, potentially.
10:45 Yeah, exactly.
10:46 Yeah, that's exactly what it is.
10:47 And it's funny because like, I don't know about you, but like when I first heard about this, I'm like, well, isn't it slower?
10:52 Because it just seems like you're doing so much more work.
10:54 Every time you're updating the cart, you're pulling out all the events from the event store and building up the state of where it's at right now and saying, okay, you know, does that cart exist in the, does that item exist in the cart?
11:06 Can I remove it?
11:07 Okay, let's remove it.
11:08 You know, and it turns out computers are fast.
11:12 And so it's negligibly slower depending on the query.
11:17 Yeah.
11:17 So I saw you and Bob Belderbos talking about this on YouTube and that was one of my first thoughts too.
11:22 It was like, this is super cool, but it's kind of sounds a lot slower to answer questions.
11:27 Yeah.
11:28 And I think, but then I thought about it and I thought, I think there's actually a decent amount of stuff that you can do to make it quite a bit faster.
11:36 Right.
11:36 So let me throw some ideas out to you and then you tell me how they land as somebody who's actually done this stuff.
11:43 First of all, back to your comment on computers are fast.
11:46 Computers are so fast.
11:47 They're so much faster than people realize how fast they are and databases are fast too.
11:51 If you put indexes on them, then they're so much faster.
11:55 I just don't understand how websites are slow.
11:58 It's just, it's not just, oh, I'm a little frustrated.
12:01 It's like, how is it possible that somebody built this and accepted that it takes three seconds to load this page and yet they do and you just know that it's most likely that there's not a database index somewhere or maybe on an extreme situation there should be better caching,
12:16 but it's just like, ah.
12:18 So like when done right, you're right, it's absolutely blazes, right?
12:21 Yeah, absolutely.
12:22 But how, you could make it faster.
12:25 So a couple of thoughts that came to mind.
12:26 One was, I have three.
12:29 The one is you could have a operational database which has, for a particular user, it might have the five ads, two removals and that's their shopping cart and the way you get that is either you query it and then code you add it up or you do some kind of aggregation thing
12:43 that says get all these things and then somehow plus minus them together, right?
12:48 Yeah.
12:49 Probably in the shopping cart it feels like you probably need to actually pull them back.
12:53 But still, you could do that super quick and then just run that bit of code and every time you make a change you could also write that to a second table, second database that doesn't have the, it just has the current state.
13:04 I just have three for that user shopping cart.
13:06 That sounds okay to me but it's, I mean databases hate duplication.
13:10 That's like kind of their third normal form job.
13:13 Do databases hate duplication or is it people that don't like it?
13:18 Yeah, that's fair.
13:19 That's fair.
13:19 I mean they were built to avoid duplication, right?
13:21 So in that sense.
13:22 So, but another, you know, another possibility would just be something like Valkey.
13:27 You could, I could have said Redis but I'm a fan of Valkey over Redis.
13:31 I find this is like a little bit nicer project.
13:33 Are you familiar with Valkey?
13:35 I am not and I'm taking notes mentally right now.
13:37 Yeah, here we go.
13:38 So Valkey, or if I find its repository which is hiding down here, it describes itself.
13:45 Where does it describe itself?
13:47 So a fork of the open source Redis project right before the transition to their new source available but not open source models.
13:54 So if you have say the Redis Python library, you just tell it that it talks to this thing, this endpoint, this IP address and port and it thinks it's Redis, right?
14:03 But it's like more open source friendly.
14:05 I'm going to star it for the world.
14:06 So, and it's got 26,000 stars, right?
14:08 So it's pretty popular.
14:09 Not that it's totally really relevant exactly which version this is but just having a cache that has that information of what is, you know, shopping cart is three, period.
14:20 Yeah.
14:20 And put something, just put two pieces in place.
14:23 One, when you do a query, first you check the cache.
14:25 If it's not there, you get the playback, you compute it and you put it in the cache.
14:30 And if you make any change to that thing, then you invalidate the cache, right?
14:33 Those two things would give you basically seamless ephemeral answers to the questions that if you ask them very often, you get super quick responses, right?
14:42 Absolutely.
14:43 Yeah.
14:43 And then the other one is, if you, you know, I always find like these extra caching servers are honestly not necessary.
14:49 You know, we already talked about FAST.
14:50 So I'm a big fan of disk cache, which I had Vincent Warmerdom on to talk about and disk cache is awesome.
14:57 So you could just have like a local file store on your Docker image or volume or whatever.
15:02 Then you get the same thing, but you don't have to have the infrastructure, right?
15:05 There's, there's different options.
15:06 So basically, I guess to sum this up, I'll throw it to you now.
15:09 Operational database that is also has the answers or some kind of caching story.
15:14 It could be in memory, it could be a server like Valkey.
15:17 It could be the disk cache, whatever.
15:19 What do you think about those?
15:20 Are you guys all exploring them?
15:22 I am exploring two, essentially, yeah, I guess you could say all three in a way.
15:27 I'm, I'm experimenting with NATS to do kind of the, I guess, Redis kind of side of it.
15:31 But all that to say is all three are viable options depending on your use case.
15:36 The first thing is like just the event store itself.
15:39 Like you, getting the current state of any individual item should not take, you know, essentially should take milliseconds if, if that long.
15:48 One of the, so there are two people that I kind of, who are my North star for all of my event sourcing knowledge.
15:54 they are Martin Dilger and Adam Dymitruk.
15:57 And Martin wrote a book called Understanding Event Sourcing, which was huge to helping me go from somebody who created an event sourcing project to adopting event sourcing as my kind of default strategy.
16:12 And in, in the book, he mentioned that he will tend to use the event store for essentially, like, if you start hitting 2000 events in a stream, then he'll think about optimizing it, you know, changing, going to one of the alternate
16:26 approaches that we just mentioned.
16:28 So, like, that's really impressive.
16:30 I, he uses Java or one of the Java derivative languages.
16:34 So, chances are, it's slower in Python.
16:36 And so you need, you know, that we need to adjust that number for Python.
16:41 But honestly, we should have shorter event streams anyway.
16:44 2000 seems like a lot.
16:46 It does.
16:48 Seems like a lot.
16:48 This portion of Talk Python To Me is brought to you by Sentry and Seer AI.
16:54 There are plenty of AI tools that help you write code, but Sentry Seer is built to help you fix it when it breaks.
17:01 The difference is context.
17:02 Seer isn't just guessing based on syntax.
17:05 It's analyzing your actual Sentry data, your stack traces, logs, and failure patterns.
17:10 Because it has the full context, it can, A, spot buggy code in review and help prevent issues before they happen, and B, identify the root cause of production errors.
17:20 It can even draft a fix and hand the work off to an agent-like cursor to open a PR for you.
17:26 Seer turns Sentry into a complete loop.
17:28 You have your traces, errors, logs, and replays to see the problem and now AI to help solve it.
17:33 Join millions of devs at companies like Claude, Disney+, and even Talk Python who use Sentry to move faster.
17:39 Check them out at talkpython.fm/sentry and use code talkpython26, all one word, for $100 in Sentry credits.
17:49 Thank you to Sentry for supporting Talk Python.
17:52 Kind of the first fallback for me would be what Martin and Adam call the read model, which is essentially one way you can make a read model would be the database-backed read model where you have code that subscribes
18:05 to only the events it cares about.
18:08 And so whenever an event comes in, it'll incrementally update that database cache or your file cache or Redis cache or whatever.
18:14 And then I guess the third thing that I appreciate is using Redis or in my case, NATS, is when you have a front-end, a very high-frequency, high-updating web UI or something
18:28 that you want to really make sure that the user has up-to-date information, I would lean towards that having ways to push down to the client.
18:36 Yeah, anytime you've got a live stream, it seems perfect, right?
18:39 Yeah, absolutely.
18:40 Yeah, I mean, hook up some JavaScript or hook in some textual or whatever it is you're trying to do and just say, or just write, you know, arbitrary web sockets or server-sent events and just say, when this changes, send me the Delta and then we'll adjust.
18:53 Yeah.
18:54 Which is pretty, pretty nice.
18:55 Yeah.
18:55 So there's a book that you recommended by one of the guys you mentioned, Martin Dilger.
19:00 Yeah.
19:01 Tell people about that real quick.
19:02 Yeah, this is incredible to me.
19:05 He realized he needs, there's a gap.
19:08 One of the biggest problems with event sourcing is that the material is sometimes there's gaps in where there's good material and because event sourcing came out of the domain driven design community, there's a lot of jargon that you have to kind of get through.
19:22 And they do like their jargon in the DDC space.
19:25 They really do.
19:27 And it, once you understand it, it makes perfect sense.
19:29 But yeah, yeah.
19:30 Getting onboarded does, does take.
19:32 Gets your bounded context working and then off the races.
19:35 Yeah, exactly.
19:36 And so Martin essentially saw this gap in knowledge and was like, I need to fill this with an e-book.
19:44 And I can't remember, I want to say in like two months he wrote this thing.
19:47 And it's so amazing because it introduces the way that the two of them work.
19:52 Like they both independently kind of came to similar conclusions, which is to use event sourcing as your base, but to also leverage two other or one main other, whatever, a couple of other patterns, vertical slice architecture, CQRS, which is kind of that idea
20:07 of like having those read models ready to, you know, optimized for you to download and use.
20:14 And then using a documentation technique called event modeling diagrams.
20:18 And that, that is a huge key too because as someone who has been on a couple teams to do the event-driven transition to try to really help, you know, do more asynchronously, you need to have a good communication pattern
20:33 to keep everybody up to date on what does what.
20:35 And I find that all three, especially event modeling diagram, they have refined this to make it simpler and simpler and simpler to the point where there's really just a few elements put together and you can understand the whole life cycle of a, of an application.
20:49 Yeah, cool.
20:49 I'll link to the book on, over on Amazon.
20:52 You know, another, before we carry on, I thought of another more optimized scenario.
20:57 What about a document database like Mongo?
20:59 Yeah.
21:00 Your top level elements are just like the computed fields like total lifetime value or, you know, cart value or cart count, item count, but then have like maybe a cart item events, which could be a, a nested list
21:14 of acts of like rich, you know, many documents that are like item added, item added, timestamp, value, like category, all, and actually storing them in the same record.
21:24 Yeah.
21:24 I haven't tried that, but I think it's a really interesting approach.
21:27 You know, I actually use a document database as my fire store, as my, as my event store.
21:34 And I haven't really kind of dug into like kind of the optimizations I could do.
21:38 But I find it curious because like the, I mean, what you're suggesting is slightly different than how I think about it because it sounds like you have like a, like a better word, a model that you're storing all of its events in as well.
21:50 And some of the neat, some of the, it's kind of inside out of what the real design pattern is, right?
21:55 Well, it's not so much that as much as, one thing that I have found interesting is, you know, since this came out of the domain driven design group, everything is about an aggregate, what they call aggregate.
22:07 Many people call it a model.
22:08 And so you, you know, set up boundaries of this is your shopping cart and these are the events that modify the shopping cart.
22:15 What has been a new movement in event sourcing is to, essentially be model less is to like focus on the events themselves because they are so flexible and so many times we as developers can kind of create
22:29 boundaries around what we think are the models that, but the models change.
22:35 Yeah.
22:35 Yeah.
22:36 And coupling is like the hardest thing.
22:38 The bounded context, as I would say, actually changes because the problem you're solving might change and the models don't match.
22:44 Exactly.
22:44 Yeah.
22:45 Yeah.
22:45 So all that to say is I don't, not that I want to especially say like, I don't think that that's a bad idea.
22:50 I think it could be really fascinating.
22:52 especially as like a secondary approach because, you know, well, whatever, you know, like I, one of the things I really find fascinating about this is this is such a flexible pattern that people, I mean, they've done so many different ways of optimizing
23:05 for their event store or anything like this.
23:08 So I think that's a very much a valid approach.
23:11 It's, it's, the reason it came to mind is you can atomically update documents and therefore you could atomically update both the computed value and the series of events as a single action, which is interesting, you know?
23:25 Yeah, absolutely.
23:26 Very interesting.
23:27 And they kind of, that, that one thing becomes the source of truth for what you're tracking.
23:30 I don't, there might be something there.
23:32 I don't, but it does sound a little bit too focused on the model.
23:35 I do think.
23:36 It's worth experimenting with for sure.
23:38 So just, to throw out a little street cred there, look at this, purchased April 18th, 20, 2005, the domain driven design by Eric Evans.
23:47 So this is kind of the greater space, right?
23:50 Maybe the book is called domain driven design, tackling the complexity in the heart of software.
23:54 It's pretty interesting.
23:55 I think it's kind of the follow-on of the refactoring movement that Martin Fowler and all those folks were working on, like in the late 90s, early 2000s.
24:05 Yeah.
24:05 Kind of in that space, right?
24:06 Yeah.
24:07 I must say, I haven't bought that book.
24:08 The closest I've come is the Cosmic Python book or the architecture patterns in Python book that Harvey and, oh, I always forget the other guy's name, but that's such an amazing book.
24:19 So that's the closest I've come to DDD.
24:21 There's a video.
24:24 I think, I think you gave me this video, right?
24:25 Events, we're seeing explain football.
24:27 Yeah.
24:27 And this looks like foosball type football, not American football.
24:31 Indeed.
24:32 I love American football, but I do believe it's slightly misnamed.
24:36 Like, you don't use your feet that much, other than the red card.
24:38 Yeah.
24:40 True that.
24:41 I mean, it's like calling Formula One, like, foot car, because you make the car go with your foot, but it's not really the main thing of the sport anyway.
24:49 Yeah.
24:50 But yeah, I love this video.
24:51 Yeah.
24:52 Okay.
24:52 Tell me about it.
24:53 I'll put it in the show notes.
24:54 Yeah.
24:54 This is, you know, I feel like event sourcing, it's like one of those things where it's hard to explain until you get it.
25:00 And then I feel like it's like a good board game.
25:02 You know, if you have a board game fan in your life, they're like, oh, this is such a great board game.
25:06 It's so simple.
25:07 And then they start explaining it and like half an hour later, you're like, are we ever going to actually play this?
25:11 I don't know that I want to anymore.
25:12 But I felt like the, this person has done a really good job of kind of really distilling it down and showing like why it matters.
25:19 And it's a 10 minute video, you know, five minutes at 2X.
25:22 And it's, it's really kind of charming.
25:24 Really good.
25:25 Really well done.
25:25 Okay, cool.
25:25 Yeah, yeah.
25:26 I'll put it on there.
25:26 Can you watch videos at 2X?
25:28 Oh yeah, all the time.
25:29 Yeah.
25:29 My daughter does that.
25:30 I'm like, how do you actually take it in?
25:33 I just, I'm a 1X sort of person.
25:34 I do slow it down or rewind to, to pull in things, but yeah.
25:38 Let's see.
25:39 It's like a, like a seek and then focus sort of deal.
25:42 Exactly.
25:42 Exactly.
25:43 Not that one.
25:44 This one.
25:45 I also heard there's this ebook I can get.
25:47 What's up with this?
25:48 Yeah.
25:49 So scheduling this podcast episode, I didn't know, you know, what we're going to talk about.
25:55 And I know like, there's going to be things I forget.
25:57 And I feel like part of the reason I am so excited about this is I know that there's someone like me, the 10 year ago version of me who has heard about these things and is curious, but just needs more information.
26:08 And so I've spent the last couple of weeks creating this ebook and I put the first version up and I'm going to continue to improve it as time goes on.
26:18 So if anything in this conversation is interesting to you and you just need a little bit more and you want to understand a little bit more what's going on, absolutely download it.
26:25 And, you know, it's free.
26:26 So why not?
26:27 Cool.
26:27 And then we'll have to make you do a, an audio version, put that on audible or something like that.
26:32 Sounds good.
26:33 Yeah, sure.
26:34 I always want to do audio books for stuff that I'm working on, but just the concept of trying to speak code or config file, I just like, I got to stop.
26:42 You know, it's, it's tough.
26:43 It's a tough balance to do with audio books and tech, like developer stuff, but still.
26:47 For sure.
26:48 Yeah.
26:48 Cool.
26:49 All right.
26:49 So people can check that out.
26:50 It's for free.
26:50 We'll put that in the show notes.
26:51 Now, I think that this both has really positive or really big possibilities for data science, but also potential challenges.
27:02 Let me throw it out to you and then you, you take us through it.
27:04 Super benefits, incredibly obvious.
27:06 You have an event stream that tells you over time what times the things happened.
27:11 You have, both the additions and subtractions or the permutations that it goes through until it ends up in its final state.
27:17 Not just show me all the customers from California who bought this month, but like show me all the Californians who abandoned the cart, but then came back and then did the, you know what I mean?
27:26 Like you can just answer way more interesting questions.
27:29 You got time series.
27:30 On the other hand, maybe I would just want to load up a pandas data frame with the answers of what's the average cart size during checkout.
27:38 And that, that becomes like a big computation out of an event source based database.
27:44 If you don't have one of things.
27:45 Okay.
27:45 Well, let's hear it.
27:46 Let's hear it.
27:47 I'm going to say it.
27:47 Like if you, if you don't do one of those caching or multi-database things or the QRS, I don't remember the patterns.
27:56 Anyway, that looks like it maybe is a little bit of a challenge.
27:59 You could do it.
27:59 I think you could do it more easily in pandas, but like maybe I just, you know, some people do data science just through SQL and they just, I'm just going to write queries against a warehouse database, you know?
28:09 Yeah, absolutely.
28:10 Why not have it both ways?
28:11 For example, on my, okay, so let's start the, for the hardcore data scientist, actually, you know, I don't even think the event store is the right format for them.
28:21 You know, I would definitely have some kind of script that would run on some kind of loop that, you know, maybe every day or every couple hours or whatever would transform the raw events into some format that would be great for.
28:34 Sure.
28:35 And you hear about all these like OLAP cubes and all these other like super BI type of systems.
28:40 None of those, no, no, I can't say none of those.
28:42 Many of those are not running out of the operational database.
28:45 They're like a, some kind of like warehouse data lake.
28:49 We've transformed this so you answer questions.
28:51 So it's not necessarily just event sourcing.
28:52 Like we just want to avoid five joins so we can just ask the question directly, right?
28:57 Yeah.
28:57 Yeah.
28:57 And in fact, my current project that I have in production at work, it is a service that multiple other services use to process items.
29:07 And the project manager of one of these services reached out to me and said that they have a BigQuery table that has all this analytical information and they wanted to add the information we have to theirs.
29:19 And so, you know, we set up a conversation.
29:22 I created the code and every day I'm sending information to their BigQuery instance.
29:26 And three days after we did a go live, you know, I created a meeting to like kind of circle back with them to make sure everything's working the way they wanted.
29:34 And when they opened up the BigQuery database, they were shocked because they were expecting three days worth of data.
29:40 I had, I set every piece of data I had for months, which was how long they've been sending things to my service.
29:48 And so, like, I was just, I just, you know, this person was elated because they were like, they knew their data scientists wanted this information and they, now they have all this information going back to day one, so to speak.
29:59 And also just recently, my boss asked me, like, I have a reports view that's just a webpage that has like how, stats on how my service is doing.
30:07 And he's like, it'd be nice to have like, some, like a table of some of these, you know, last few days or whatever.
30:12 And I was like, okay, how many, how many days would you like?
30:15 And he's like, 30 days.
30:16 So I created, the HTML was pretty easy and I just created a script to like pull the events out of the event store and populate this table, you know, as exactly as we needed.
30:25 It went into production live and we were immediately there with 30 days of history.
30:28 It was, it was so exciting.
30:29 And, and like, this is what I get to experience every week is like, you know, having the ability to like, go back into history and answer questions that we've had that we didn't even think we knew.
30:38 We didn't have any idea that we would want to know, you know, a month ago.
30:42 And to be able to answer those questions with precision is, is intoxicating.
30:46 Yeah.
30:46 I certainly see the value.
30:47 Like you don't necessarily know the questions you're going to ask.
30:50 And if you don't have enough data or you don't store it in the right way, you literally can't answer them.
30:56 Yeah.
30:56 Right.
30:57 But with, it sounds like with, events or so, you can go back and like, well, what if we ask this over time instead of by region?
31:02 Like, okay, slightly different query, no problem.
31:04 Exactly.
31:05 Yeah.
31:05 Yeah.
31:05 It's, it's really quite something.
31:07 I had no idea.
31:09 Like my, I kind of mentioned earlier, my biggest thing was, I was, I can't wait to have fast UI.
31:15 And now that I realized that I feel like our applications obviously serve the primary purpose of whatever it is that the business needs, but I didn't realize how much there was a secondary need of understanding how it works and enabling the business to make decisions
31:29 based on how customers are actually using the application.
31:32 We're going to talk about the AI side later, but I do just want to throw out as different constituents who might care to answer these questions.
31:38 Like I was just thinking, you've got, you've got the operational side of say the website or app or, you know, driving an API for the app or something like that.
31:46 That's one view.
31:47 That's kind of the traditional view, but now you have this much more increasingly popular view of like data scientists and BI tools and the CEO wants a dashboard that updates live type, you know, so events are a clear trigger for those kinds of things, right?
32:01 Absolutely.
32:01 But then also you might ask your AI Opus or Codex or whatever, hey, find me some trends or let's look at this and, you know, it has more to work with as well, right?
32:11 Yeah.
32:12 Just thinking of the different constituencies, yeah?
32:14 Totally.
32:14 In fact, just today I was looking into a bug that was happening in production and I asked Claude, hey, can you query the GCP logs?
32:23 Can you query the event store and help me understand what's going on?
32:26 And it was like, sure enough, here you go and made fixing the bug much easier.
32:32 This portion of Talk Python is sponsored by Temporal.
32:36 Ever since I had Mason Egger on the podcast for episode 515, I've been fascinated with durable workflows in Python.
32:43 That's why I'm thrilled that Temporal has decided to become a podcast sponsor since that episode.
32:48 If you've built background jobs or multi-step workflows, you know how messy things get with retries, timeouts, partial failures, and keeping state consistent.
32:56 I'm sure many of you have written brutal code to keep the workflow moving and to track when you run into problems, but it's trickier than that.
33:03 What if you have a long-running workflow and you need to redeploy the app or restart the server while it's running?
33:09 This is where Temporal's open-source framework is a game-changer.
33:13 You write workflows as normal Python code and Temporal ensures that they execute reliably, even across crashes, restarts, or long-running processes while handling retries, states, and orchestrations for you so you don't have to build and maintain that logic yourself.
33:27 You may be familiar with writing asynchronous code using the async and await keywords in Python.
33:33 Temporal's brilliant programming model leverages the exact same programming model that you are familiar with but uses it for durability, not just concurrency.
33:42 Imagine writing awaitworkflow.sleep timedelta 30 days.
33:47 Yes, seriously, sleep for 30 days.
33:49 Restart the server, deploy new versions of the app.
33:51 That's it.
33:52 Temporal takes care of the rest.
33:53 Temporal is used by teams at Netflix, Snap, and NVIDIA for critical production systems.
33:58 Get started with the open-source Python SDK today.
34:01 Learn more at talkpython.fm/Temporal.
34:04 The link is in your podcast player's show notes.
34:07 Thank you to Temporal for supporting the show.
34:09 Yeah, I guess you know why.
34:11 You have more granularity on what, if the thing in the database doesn't look like you expected, you much, have a much more granular way of knowing like it was this step that made it look like that because I've had problems before where I completely
34:26 upgraded, swapped out the data access layer for Talk Python training for the courses.
34:32 Yeah.
34:32 And for the website, it was perfect.
34:33 Everything was great.
34:34 But under certain circumstances on Android, the app was resulting in something, it was sending in something that would make the data not right, right?
34:43 Like there was some field that was null instead of just taking on the default value.
34:47 Oh, man.
34:48 Which is fine.
34:49 But then when the person logged in on the website, the website didn't assume that that thing could be null because it was, at a minimum, had a non-nullable default value.
34:57 I'm like, why do we need to check this for null?
34:59 How did it get to be null?
35:01 It makes no sense.
35:01 It took forever to figure that out.
35:04 Oh, wow.
35:04 But with event sourcing, you could see this was the event that made it null.
35:08 Not just, it is null.
35:09 What in the world is going on?
35:11 Why could it, how could it possibly be null?
35:13 Yeah, absolutely.
35:14 So I think it's got some interesting debugging.
35:17 And one more thing, like I know this is quite the data science side, but another constituency could be PCI, HIPAA, GDPR, like all the compliance frameworks you got to deal with for auditing or sort of audit trail
35:32 or something that happens.
35:33 I mean, a lot of times logs serve that value, but that might be a, they updated the record like, oh, what?
35:38 Yeah, totally.
35:39 Yeah.
35:40 And that, you know, I, even though I've been in insurance and I've been in healthcare, I haven't had anything where I have to certify these things, but like you've, the audit log is the way you interact with everything.
35:51 It is the source of truth.
35:53 And so, but what's funny is I have worked on teams that created history tables to try to essentially do that work.
36:00 and it was like two or three months after I started working there before I learned that that table existed.
36:06 And so, there were two or three months of work I should have been putting in the history table that I didn't.
36:12 And from what I hear among other developers, a lot of teams work that way.
36:17 Like, only a few people really know and understand how to maintain that history table.
36:22 And a lot of times, like when they try to replay it, it just doesn't work.
36:25 And it's, it's unfortunate.
36:26 Yeah, it's like, well, there is history in the history table.
36:30 When we run it again, we don't get the same output as the final database.
36:34 What's going on?
36:34 Yeah, true.
36:36 Yeah, but with the event sourcing, it reverses it.
36:38 Basically, the events are the source of truth and the other one is some kind of dynamically generated sort of deal, yeah?
36:44 Yeah, yeah.
36:45 And it's a lot like, you know, a backup strategy.
36:49 You know, if you never test your backup strategy, you don't really.
36:52 Exactly.
36:52 And I feel like it's the same thing with the history table.
36:54 And honestly, to be totally honest, event sourcing is similar in that it's easy to accidentally migrate event versions.
37:01 You know, like for myself, I was working on a new event to kind of, you know, on my app and I introduced a new attribute or actually, I guess it was a full, whatever the point being is, at some point I decided I wanted to change
37:16 the name of the attribute because it would reflect better what it meant in the domain and not realizing that I had already published that event to production.
37:24 And so at one point I was, I don't know, I don't remember what I was doing, looking up issues or honestly, it might have been a view that it was rendering that was supposed to be for with throwing errors and I couldn't understand why and I looked at it and sure enough, it was because I accidentally created a different version
37:39 of the same event.
37:40 Thankfully, all I had to do was change the code to say, well, if this attribute doesn't exist, look for this attribute and everything was fixed.
37:47 But, you know, you can honestly fall into some of those things with event sourcing too if you're not careful.
37:51 But the nice thing is because the events are still there, you have the ability to recover from them.
37:56 Let's talk about versioning for a little bit.
37:58 Sure.
37:59 On a sort of operational third normal form type of database, you know, you might run a migration.
38:04 One of the reasons I really like using MongoDBs because I almost never have to run migrations, but that's a different, it's a different debate.
38:11 However, you might run the migration to say like, okay, we're going to add a column or we're going to split this data apart and move this stuff over here and that over there and then create a foreign key relationship or whatever.
38:23 Yeah.
38:23 But I can see if you've got this kind of history of things.
38:26 Like, let's say, I don't know, how do you deal with versioning, right?
38:29 Like, I've got these old events and the way you're not storing the current state.
38:34 So with the migration or something like that, you're like, well, let's just transform the current state into the new state.
38:38 With these, you've got like old events and new events and they might be in a real way incompatible.
38:45 Yeah.
38:45 Yeah, sure.
38:46 What do you think about with that?
38:47 You have so many strategies.
38:50 You just have to choose which one works for your situation.
38:52 So the first one is kind of what I mentioned just a minute ago, kind of like the MongoDB or I should say document database way of working with things where if you're adding things to an event, adding fields, then if, you know, if the code, you know, most code will be blissfully ignorant
39:07 that you're adding new attributes to it.
39:09 So it doesn't really matter.
39:11 And then those that do care can kind of have fallbacks.
39:14 And the way that Adam and Martin suggest, you essentially have like upcasters or some kind of code that essentially says like, okay, the previous version, actually, that's two different things.
39:25 I'm sorry.
39:25 The code that does care about the new attribute, if it encounters an older event that doesn't have that attribute, then you can have a default fallback.
39:32 And it's best to have those close to, you know, the domain logic that you want to update.
39:37 This is a vertical slice architecture approach as opposed to having like a global upcaster.
39:41 Again, I realized that I want to keep going to the upcasting, which is the second option that I've been trying to get to.
39:47 But so essentially one is, you know, have a default fallback.
39:50 Second one is to have an upcaster that says, okay, you know, especially if they're two different versions, like truly different versions of the event, you know, you have add to shopping or item added and item added version two.
40:02 You know, you might have completely different fields.
40:03 It's good to have a piece of code that can, you know, upcast to the second one.
40:08 You put that in your, like your data access layer.
40:11 It might write a thing and say, give me all the items of the cart and it looks at the type or the version flag and then does a little processing or would you rewrite the database?
40:20 Oh, well, that's, I was going to say that's your third option.
40:22 So let me take a step back and ask your first, your last question, which was like, at least to me, the tent, what you're doing with your events is essentially rebuilding state.
40:30 And so wherever you're in that loop to rebuild the state, you would probably say like, oh, is it this event or is it this event or whatever behave this way?
40:37 Right there.
40:38 Like in my story of using one of the data caches, you do a request, it's not in the cache.
40:44 So you've got to run your build it up code and put it in the cache.
40:46 And that just, I mean, that part right there would be the part that goes, okay, we're going to transform it differently now and then we'll still store the answer in the cache and the next time they ask, it's just fast.
40:55 Yeah.
40:56 So yeah, you would have, the way I would code it is you'd have a piece of code that's listening into the events.
41:02 So you have, it knows about the old version of the event and the new version of the event.
41:06 And it knows what format that data needs to be in in that Redis cache or whatever it was that you suggested.
41:13 Yeah, Valkey.
41:13 Come on, Valkey.
41:14 Valkey.
41:14 Let's go, Valkey.
41:15 I'm going to remember this by the end of the conversation.
41:18 So yeah, so what it does is it will be able to say like, okay, this event is an old one, but I can upcast it to a new one and convert it into the format or however we need to save it to Valkey.
41:28 And then if it's a new one, it also knows, okay, I'm going to convert it this way to save to Valkey.
41:33 So it's nice that it's kind of localized to, you know, the process that you need to update, upcast.
41:39 And then we've touched on like kind of the quote unquote nuclear option, which is to apply a transform to your entire event store.
41:46 And so you would, by doing that, you would create a new database from your database table, which would be your new event store.
41:50 And you, for each event, you just copy it over, do some kind of map or transform to upcast the entire, your entire history.
41:58 Yeah.
41:59 I see values, value in all of them.
42:01 You know, if you're doing a lot of direct SQL data science-y stuff, you probably want to transform the database.
42:06 If it's primarily coming out of an API, like just let that thing handle it as it reads them, you know, computers are fast.
42:12 Keep it in mind.
42:13 Indeed.
42:13 And I forgot to mention that, oh, his name escapes me right now.
42:16 The guy who popularized event sourcing back in the 2000s wrote a book on this topic specifically.
42:22 So he kind of listed out all of your strategies and when you would want to choose them and why.
42:27 Are we talking Martin Dilger?
42:29 No.
42:30 Greg Young.
42:31 Greg Young.
42:32 Okay.
42:32 I think it's on LeanPub.
42:34 Yeah, that sounds about right.
42:35 In fact, Martin Dilger's book is cheaper on LeanPub as well and you git additional content there too.
42:39 Okay.
42:40 Yeah, very interesting.
42:42 Let's, let's make this a little bit concrete for people.
42:46 Sure.
42:46 We talked about how you might, in theory, architect some software, could be Python or something else to follow these patterns, but there is a Python library, right?
42:55 Yeah, absolutely.
42:56 Do you recommend it?
42:57 I do.
42:58 You know, I, it's funny, I don't have any production code with it, but I have used it a lot over the years.
43:04 John Bywater has done an incredible job maintaining this, this repo and, you know, all his, all the people who have contributed as well.
43:12 He has shepherded this through and is, has been really making it such an incredible application.
43:18 When I wrote my applications, you know, I, the first one I did, I was like, I want to do it myself so I can understand it.
43:26 And so I can really understand and respect what he's done.
43:29 But also, you know, there's a part of me that really, like a lot of the, you know, essentially I feel like it depends on who you are.
43:35 If you're somebody who wants to grab a framework and run with it, this is an exceptional one to do it with.
43:40 It, essentially, you just write Python classes and you decorate them or subclass from some of his classes and all the magic of event sourcing happens for you.
43:50 And it just make, leaves you with really readable, understandable code.
43:54 And then you'll have other people who, you know, a lot of people in the event sourcing space says it's actually not that complicated.
44:00 You can write your own code to do it.
44:02 And I did.
44:03 And I recommend it for the right type of person.
44:06 For me, it was hard because there's so many decisions that you need to make.
44:09 And I am not the best Python programmer.
44:11 I do not know all the concurrency issues and all these things.
44:15 I'm getting to learn them more.
44:17 But, you know, I have software that's running in production that's, that's doing well.
44:20 So all that to say is, yeah, I highly recommend this package, especially if you're new to it.
44:25 It can really show you, you know, how you, one option of, of things can work.
44:30 And I love that it, by default, it uses, well, you can, you can use SQLite, Postgres, or one of the, a couple of the doc, databases that are optimized for event sourcing.
44:42 And so you can kind of see how it's, you know, some of the many ways you can pattern things to make it easy for you.
44:48 Interesting.
44:49 So I probably need to file a PR or something here.
44:52 It says, the way you get it is pip install event sourcing.
44:56 I feel like it should be pip install event sourcing.
44:58 No, just kidding.
44:59 But that's cool.
45:00 However, I am, you know, so it's, you know, you can get it off PyPI, but I'm having a hard time resisting pressing this.
45:07 Ask DeepWiki.
45:08 Have you ever gone, what is DeepWiki?
45:10 Yeah.
45:11 It's a AI powered document thing that he opted into, which I thought was very fascinating.
45:16 I was following, I was at the time he did it.
45:19 I was, I think I was writing my own code.
45:21 And so I had Slack open.
45:22 He has a good Slack channel and was like showing all the things that he was able to, to all the insights that was able to be gleaned from it.
45:30 This is epic.
45:31 I love it.
45:31 So it had, the DeepWiki apparently is like, and knows the source and the docs.
45:37 And then it's just a chat.
45:38 And even on fast, I asked, I said, give me an example of using this library.
45:41 So sure.
45:42 Here's a complete example of dog school application, all the code using event source, the light, the package.
45:48 This is nuts.
45:50 Yeah.
45:51 Side quest unlocked.
45:53 Must figure out how to get my packages into DeepWiki.
45:55 This is nice.
45:57 And I also want to add, he has other companion packages that for example, connect into Django and I believe Flask and some other ones too.
46:05 So one of my side projects, I'm leveraging this with Django and it's really cool because one of the things that enables you to do is configure your events table to be similar to your,
46:19 I guess in the same database as your Django table or at least configurable from the way Django would do it.
46:24 And yeah, so getting all these read models are very easy with all the migrations.
46:28 You just say, this is what I want my data to look like with Django and of course apply migrations and there it is in production.
46:34 So that's really nice.
46:35 Yeah, cool.
46:36 It also has extension projects.
46:38 What are these?
46:39 The Django one, the KurrentDB, K-U-R-R-E-N-T.
46:43 I imagine KurrentDB is probably a...
46:45 I believe that is, yeah, it's one of the first event sourcing specific databases.
46:51 I think it was called...
46:51 Oh, it's for intelligent and responsive systems.
46:55 I don't know, Chris, I just got to rant a little bit.
46:57 Like there's all these projects that are cool and they do neat stuff and now I feel when I go to them that it's like, this is the AI compute data frame or this is the AI, the intelligent AI.
47:06 It's like, it's just a database or just a data frame that AIs can use.
47:10 That doesn't make it an AI data frame, you know, it's like, but they all want to capture the excitement.
47:14 It drives me crazy.
47:15 Yeah.
47:16 And what's worse is when they don't even say exactly what they do.
47:18 It is, it is your answer for AI-ing the thing that we're not going to tell you.
47:22 I hate it.
47:23 Yeah.
47:24 Yeah, exactly.
47:24 And it just obscures what the heck it is, but it's the H1 and the H2.
47:27 You're like, oh my gosh.
47:29 Yeah.
47:29 Yeah.
47:30 Okay.
47:30 But that does look pretty interesting.
47:32 Like, yeah, look, it's example is create a client, new event data, new UUID, et cetera, order place, serialize.
47:39 So right here, this example is basically it's got primary key, a category or type of event, like a, just an event, I guess is the way you would call it.
47:48 But then it has JSON serialized, like a JSON blob.
47:53 That is the details of the event.
47:55 Is this how you typically do it?
47:56 I would say so.
47:57 Or is it more column oriented where like this one has an order ID and a total.
48:01 So you might have an order ID and a total in the data structure or is it in a blob level?
48:06 Yeah.
48:06 The implementations I've seen generally will have some kind of blob or JSON serialized or bytecode serialized optimization of it.
48:17 You know, because each event, you know, when you're saving things to the database, you know, you're going to save an event.
48:22 It's going to have an event stream.
48:23 It's going to have generally speaking, there's probably an event version.
48:26 Like there's all these specific things, but the actual payload of the event.
48:29 If there's not an event version, you're going to wish there was an event version at some point probably.
48:33 Exactly.
48:34 Yes.
48:34 And so the payload is usually some kind of blob or JSON body or something like that.
48:39 It sounds very good to be a document database.
48:41 Indeed.
48:42 Yeah.
48:43 Yeah.
48:43 Because you can put indexes on like the sub items and then if they're not in that event, it just doesn't use the index for those particular ones.
48:50 I mean, it's a lot of things.
48:52 Yeah.
48:52 Yeah, exactly.
48:53 It's pretty sweet.
48:54 Yeah.
48:54 And again, well, I haven't said it quite, but like one of the things I have been thinking about for a decade is the more I kind of thought about it, the event sourcing and the patterns and unlocks really gives you so much flexibility.
49:07 You know, you can use document data stores and like really take those, the power of that.
49:13 You know, if you have, and part of this is too is just data, you know, vertical slicing or whatever, it's both multiple patterns put together.
49:19 But like, you know, if you have a view that would be so much better served by having a graph query, a graph database, then use it.
49:28 You know, it's, I remember at one time it took me a while, but like somebody told me that they were using, I can't remember their, their open query.
49:39 Is that what it's called?
49:40 The, I forgot the old name of what I'm trying to think of, but essentially it's, you know, like a database that optimizes for saving text.
49:47 So you can like search for it.
49:49 You know, they use that as just for one, you know, to serve the purpose of one item.
49:55 And honestly, this isn't unique to event sourcing.
49:57 You can do this with event-driven architecture as well.
50:00 But what I love about event sourcing is like you have the benefits of event-driven architecture and the benefits of a monolith in one if you choose to go that way.
50:08 And yeah, it's just, it's, I guess really what it comes down to is what I love about it and was surprised by is how flexible it gives you the ability.
50:16 Yeah, in the book, it reminds me, one of my users was complaining about the status screen that I show for the users and he had all these great ideas and I was like, you know what?
50:27 I want to take advantage of that.
50:29 So I actually cloned my, the vertical slice for that view and created a new database column or collection for that, to power that view.
50:39 and we iterated and iterated to make this thing better and with each iteration, sometimes I needed to change how the read model reacted to events and so I could just blow away the read model, regenerate it from events and we ended up with something really great so that when it
50:54 was time to go live, I just changed which, where the URL went, pointed to the new one and was able to delete the old code and delete the database table and it was wonderful.
51:03 Yeah, it just gives you so much flexibility to do whatever you need.
51:08 So, a couple more, one more, I guess one more really relevant thing, two more things to give a shout out with this event sourcing.
51:14 There's event sourcing Django which is Python package for it with Django.
51:18 Imagine that probably somehow it upgrades with the ORM, don't know.
51:20 But also event sourcing SQLAlchemy which is kind of cool.
51:23 So if you use SQLAlchemy, yeah, very nice.
51:25 All right, so this stuff is great but I imagine that it has times you should use it maybe more and times you should go, well, square peg round hole maybe not this time.
51:36 Sure, yeah.
51:37 What do you think?
51:38 For me, I feel like it's usually the way I think about it first is because most people are very comfortable with not using event sourcing, right?
51:45 And so I usually answer it the opposite way which is when should you?
51:48 Sure, exactly.
51:49 The two biggest, the best piece of advice that I heard over the last decade was number one, use it, a good opportunity to use it is if you have a database column called status because if you have a columnated status then that means that
52:03 one item can be in multiple different statuses, right?
52:07 Different states and if you're having different states each states behave different in some way or form and so you are definitely not dealing with true CRUD create, read, update, delete patterns and so event sourcing would be a great option for that.
52:20 The second piece of advice is do you ever, are you ever concerned about losing data?
52:25 Because by default event sourcing does not and what it enables you to do is choose when to lose data, right?
52:30 Because you don't have to keep every event around forever.
52:32 You can just say like after 90 days let's just put it to cold storage or just delete it, you know, it depends.
52:37 Yeah, exactly.
52:38 Out in the audience Mike says, I'm scared of the physical storage requirements of this potentially.
52:42 I guess it depends how many data, how many events make up a final state in your system.
52:47 Like a cart checkout, big deal?
52:49 No, probably not.
52:50 Like if used as an app log, that might be a problem.
52:54 Yeah, yeah.
52:54 Most, I'll say models, will have maybe a dozen events, maybe two, depends on your, obviously depends on your domain.
53:03 But ideally, you will keep your events short and they have practices called closing the books where you will use events in your domain to kind of keep it short.
53:12 So like, for example, a store will want to know their revenue across the entire year, but every night they shut down, they get their cash registers or if they still have cash registers and they kind of reconcile how much money they made that day.
53:25 And so, you know, kind of keeping your event stream short really helps.
53:29 If you're going to go back, you would just say, well, we'll just read the daily summary and then add today's events or something like to get the final output, something like that.
53:37 Yeah.
53:38 Unless you want to go all the way back to day one, in which case you can, you know, read and say like, okay, the, you know, it all depends on how you want to do it, right?
53:46 This is again, the flexibility side of it because you could just like, say, start from today and read forward or you can start from today and say, okay, what was the event stream before this and read that and keep going back to the originating?
53:57 And I think you put up Mike's comment that said, I'm afraid of the physical storage requirements.
54:02 And it's like, that is the trade-off.
54:04 There is, it will take more space, but thankfully, storage space is the cheapest commodity in all of online or, you know, in today's world.
54:15 And it's, and most expensive is memory and then compute and then storage and then bandwidth and then storage.
54:20 I think that's probably the breakdown, right?
54:22 Yeah, I think so.
54:24 And why things like disc cache are awesome versus like another thing that's just in a memory cache, but another process, right?
54:29 Like, exactly.
54:30 Yeah.
54:31 And having the ability to say like, you know, we, you know, like my current application, I have not yet deleted any events, but truly like the only reason we have events older than even a week are just for analytical purposes and, and just me understanding how our system works.
54:45 And so I'm planning to make a way to offload that event or those events.
54:49 And a lot of people just put them straight to cold storage, you know, just so that they always have a backup just in case, but, you know, chances are they rarely ever use it.
54:57 Interesting.
54:58 And one other thing I did want to add is to go answer your question when not to use event sourcing.
55:02 exactly.
55:03 Would be essentially like, you know, so let's say you don't care about losing data.
55:08 There are just a number of just simple applications that are truly crud, right?
55:12 Like I've worked on a number of these where they're just forms over data.
55:16 It's exactly the term I was thinking, forms over data.
55:18 Defining that for people if they don't know.
55:20 Yeah, it's essentially something where like in my case, one of the first ones I worked on is like you have a web page that almost exactly mirrors the database table that you're saving the data to.
55:30 You know, maybe it's a contact form.
55:32 Who knows what it could be?
55:33 You know, the idea is like there is so the web UI or whatever you're building is just an easy way to get data into the database.
55:41 And chances are you don't have status field.
55:44 You don't have all these different ways of different rules for how things behave.
55:49 And in fact, in my event source application, I have a model that is not event sourced.
55:54 It is truly a crud model.
55:56 And so just by saying, you know, adopting event sourcing doesn't mean you have to do it for everything.
56:00 You can use it for even just a small bit of your project, especially if you want to try it out and see how it could be.
56:05 That's a really good point.
56:06 It's not an all or nothing sort of thing.
56:07 Because you have a properly factored data access layer and you're not doing that inside of your Jinja template, are you?
56:15 No?
56:16 Right.
56:17 Not even in your view, but like you've got just an opaque layer of actions.
56:22 Some of those actions can be driven by events.
56:25 Some of those actions can just be straight crud.
56:27 Create, read, update, delete for those who don't know.
56:29 One of the people who inspired me to really dig into event sourcing, he has a line of business that, well, he'll go to a company who is struggling because their database schema is holding them back.
56:42 You know, for whatever decision they made, they cannot, they're having such a hard problem, hard time creating a new feature because of their database schema.
56:50 So he goes in, teaches them event sourcing and uses the event sourcing event store to publish both the dream schema that they wish they would have and the old schema.
57:01 And they live side by side and the event, you know, once the features are complete, they'll, you know, put it up and they'll start slowly migrating traffic over to the new event source version and, you know, eventually they can delete the old database table or schema, you know, database.
57:15 And most of the teams he's worked with have kept with the event source version and gone on from there.
57:21 Yeah.
57:21 Oh, and then finally, one other thing I want to mention too is when not to use is it's up to your teammates because, you know, I am sold.
57:30 I think this is such an incredible pattern.
57:33 It is just unlocking so much joy again and so much flexibility as I've said before that I cannot imagine having to go back.
57:41 That said, if I join a new team and my team members are like, I don't know, I'm going to go with them, you know.
57:48 Yeah.
57:49 One thing is to not use an optimal pattern.
57:52 What's worse is to try to use an optimal pattern but have nobody else want to do it and then they work around it and you, you know, it sounds a little similar to like people who don't want to do unit testing.
58:02 Yeah.
58:02 So some of the people write the unit test and they set up CI/CD that'll fail if the unit test failed but then the other people will check and work without running the test at all and then they break it and you're like, what are you doing?
58:11 Like, well, I don't want to run these crappy tests.
58:13 You're like, well, now the whole CI/CD is not just not helpful.
58:16 It's inhibiting me working because you won't even, you know what I mean?
58:19 It's just like, and it seems like you do need a certain level of buy-in for this to make sense.
58:24 Absolutely.
58:24 Yeah.
58:25 And maybe they should listen to this podcast and they can see it.
58:28 And maybe you create an example of one feature in an event sourced way so they can see some of the benefits.
58:36 But, you know.
58:37 Yeah, yeah, yeah.
58:37 Like your partial example, indeed.
58:39 Yeah.
58:39 All right.
58:40 We're getting short on time here, Chris, but let's talk this AI flow.
58:45 First of all, let's circle back to your comment of your company having a mandate to use AI.
58:52 What the heck is going on here?
58:54 How is this received and how are you receiving it?
58:56 And also tell us, are you actually writing, you know, make, shipping more features and be more productive or not?
59:03 Like what, give us your assessment as much as you're willing to share.
59:06 Like you don't have to like.
59:08 Yeah, yeah.
59:09 I will, I will hide certain things, but to say.
59:13 Names and places have been changed to protect the parties.
59:16 Yes, and emotions and conversations with multiple other people.
59:20 I would say at times I am so much more productive.
59:23 At times it has brought down the production, you know.
59:30 So it is a mixed case.
59:33 I see that Mike in the chat said it's an overconfident intern and I'm like 110%.
59:39 Like this is exactly what it is.
59:40 But very smart intern.
59:41 It is.
59:41 Oh, absolutely.
59:42 Very confident.
59:43 Oh, well, he said that.
59:43 Yeah, overconfident.
59:44 And I find this fascinating because my production app is actually three services in one monorepo and I'm responsible for one and, you know, a couple other people are responsible for the other ones, but, you know, we're all interacting.
59:59 And so my, when I need to change something on my code, you know, and I'm required to use Claude Code, I say this is what I need to do and generally it does a really great job.
01:00:08 And I think a lot of this has to do with the vertical slice architecture because vertical slices only hold code that is responsible for one feature.
01:00:15 And so that really fits very nice into a context window.
01:00:18 Yeah.
01:00:19 It doesn't have to scan 200,000 lines and 100 files.
01:00:23 It looks at five.
01:00:24 Yeah.
01:00:24 And it knows event sourcing.
01:00:26 So it knows, okay, I'm subscribing to events.
01:00:28 These are the events.
01:00:29 I know where they are, you know, all these different things.
01:00:31 When I work on one of the other services, it takes a lot more context to understand the state of the code.
01:00:38 And I really have to work harder to do, to do what I need to do in those, in those parts of the code base.
01:00:46 Yeah.
01:00:46 So it's been a very interesting experiment.
01:00:48 And additionally, kind of when I am, I had to curb this, but when I have been more productive is creating get work trees.
01:00:56 So it's like, I have a kind of main repo that I work out of.
01:00:59 And then I, if I have a feature that I, you know, I'm like looking at the code base and like, oh, or the web app or the logs.
01:01:04 And I'm like, oh, it'd be good to like optimize this.
01:01:07 Then I create a new work tree and set cloud up in there and get it working on a thing.
01:01:11 And so I have found that I can only, I need to limit myself to two or three work trees because any more than that, I start losing context.
01:01:18 And now I know what the LLM is.
01:01:20 Yeah, exactly.
01:01:21 If you over, overdo it, it's, you just send off five agents and don't look like that's how you end up like, oh, we have kind of like bugs in our code about architecture.
01:01:28 Well, you never look at it.
01:01:30 It's like, we got the super energetic, super smart intern and we kicked him off and said, go on that feature.
01:01:35 But you know, they need guidance, right?
01:01:38 All the tests are passing because I changed all the tests to pass.
01:01:40 I know.
01:01:41 The problematic data has been removed from the database.
01:01:43 It works now.
01:01:45 Why is it empty?
01:01:46 Yeah.
01:01:48 Back to your backup comments.
01:01:50 Honestly, I'm having like an insane amount of productivity with Claude Code and with AI and stuff.
01:01:55 But it's an engineering skill.
01:01:57 It is not just, let's fire it up and ask for it.
01:01:59 Like one of the things I'm doing lately that I'm really appreciating is going through like a planning session, which I know a lot of people do that and like talk about it.
01:02:07 But, and now, if you have the GitHub CLI installed, just the GH thing, you can tell it, hey, create, you know, instead of just running this plan, create a GitHub issue of this plan, write all the details in GitHub and then your next comment
01:02:22 can be, let's work on issue 127 and it'll go work on it when it gets done.
01:02:26 Like, let's make a retrospective comment on the issue.
01:02:29 Let's create a PR that closes that issue.
01:02:32 That's, you're like, there's some really interesting team dynamics that you can put in there that, you know, talking to a chat box is not covered, but if you know what, you know what to ask for.
01:02:41 Yeah, I'm really inspired by Martin and Adam because both of them in one way or another have, let me take a step back.
01:02:48 They, I mentioned the event modeling diagram.
01:02:51 It is a visual diagram that really has a reduced visual language and what was mind-blowing to us a couple years ago was that AI understands it.
01:03:01 And so, the fact that you can essentially say like, here's the diagram, can you implement the slice and it can get you from, well, let me take a step back.
01:03:08 Martin and Adam have both had successful research spikes where they took an event modeling diagram.
01:03:16 Actually, no, they even did, what they did even worse was they started with a conversation with a client and recorded it, created the transfer.
01:03:23 They generated the diagram.
01:03:24 Generated the diagram and then generated code from the diagram that didn't solve everything but got it, I think, 80 or 85% the way they're in hours from, you know, like cutting months of work down to weeks is impressive.
01:03:38 And I've had some similar, you know, I'm still working on my personal one because like, I just, you know, after work, I just tend to shut down my computers and I'm not like dedicated to like really going at it but like, I found some really incredible benefits
01:03:52 of doing something like that.
01:03:53 that's awesome.
01:03:54 I created this open source project.
01:03:56 I mean, it's more source open, whatever, it's not really a project but I called it Python Package Guides for Agents and all the projects that I work on, I'll go and download the source and the documentation.
01:04:05 So like, if I'm working on disk cache, I'll like literally clone it, clone the documentation and then make Claude write a super detailed, like, not use their documentation or its old version but like, have it like legit, write down examples, study the source code, study the documentation,
01:04:20 source code like trumps documentation because if the docs are out of date and so on and then I'll drop, you know, if I'm using like two of these like maybe data classes and disk cache, I'll drop those things into my project and tell Claude about them and that's been a pretty neat thing to do as well.
01:04:34 Yeah.
01:04:34 But I want to leave this portion of our conversation with an incredible joke.
01:04:38 Okay.
01:04:39 Okay.
01:04:40 Just because I feel like this has to be said right now.
01:04:42 It's just so, the joke, this is the word copilot, it could be Claude, it could be Codex, it could be Chat, whatever, like just AI, right?
01:04:48 Friends outside of tech.
01:04:50 Lol, copilot is dumb.
01:04:51 Friends in tech.
01:04:52 In tech.
01:04:52 I just bought iodine tablets and I've made an offer in land of state.
01:04:55 My supplies of antibiotics and potable water are sufficient but I need to set up for the hydroponics to make it through the first few years.
01:05:01 Like I feel like that's where we are, you know?
01:05:03 Yeah, yeah, totally, totally.
01:05:06 And that maybe also sums up your meetup as well.
01:05:10 Yeah, yeah, yeah.
01:05:11 Yeah, absolutely.
01:05:12 It's quite a spectrum both of Friends outside tech and inside tech.
01:05:17 Yeah, exactly.
01:05:17 Like it's more like believers and non-believers.
01:05:19 I'm not really sure.
01:05:20 All right.
01:05:21 Final Call to Action.
01:05:22 What do we got here?
01:05:24 People are interested.
01:05:24 They want to get started.
01:05:25 What do you tell them?
01:05:26 Get your ebook, your free ebook that you put up?
01:05:28 That's right.
01:05:29 Yeah, so my website is everydaysuperpowers.dev.
01:05:32 If you want an ebook that kind of introduces you into event sourcing and kind of gives you kind of this kind of fundamental background and a couple other things, go to everydaysuperpowers.dev slash es intro and it'll take you right there.
01:05:46 I'm on Mastodon mostly, but I'm also watchbluesky and sometimes x underscore chrismay on all of those.
01:05:55 With Mastodon, I think I'm on fosstodon.org.
01:05:57 What else?
01:05:59 I mentioned everydaysuperpowers, so that's...
01:06:01 I also have a Discord from there too, so if you go through my website, you can see how you can join that.
01:06:07 Sweet.
01:06:07 Maybe check out the event sourcing library.
01:06:09 100%.
01:06:09 For them people.
01:06:10 Yeah.
01:06:10 Yeah.
01:06:11 And if you...
01:06:12 Oh, oh, the...
01:06:13 Martin and Adam have a podcast called the Event Modeling and Event Sourcing Podcast, which is verbosely named, but it also is really great.
01:06:21 You know, this is how I learn just from these great people, you know.
01:06:25 There you go.
01:06:26 Just kind of every...
01:06:27 Almost every week talking about patterns they do and stuff like that.
01:06:30 They also talk about a bunch of other stuff that isn't relevant, but I've learned so much from listening to them and they also have Discords.
01:06:37 So go ahead.
01:06:37 Cool.
01:06:37 I'm honestly impressed.
01:06:39 Like an entire podcast on a single design pattern.
01:06:41 Let's go.
01:06:42 That's commitment to it.
01:06:43 Yeah.
01:06:44 Yeah.
01:06:44 And it's incredible.
01:06:45 I mean, as someone who has played the board game and really enjoys it, it's amazing.
01:06:51 Well, Chris, I really appreciate you coming on here and sharing all your experience and excitement and all the things.
01:06:56 Great to talk to you.
01:06:57 Likewise.
01:06:58 Thanks for having me.
01:06:59 This has been another episode of Talk Python To Me.
01:07:02 Thank you to our sponsors.
01:07:03 Be sure to check out what they're offering.
01:07:04 It really helps support the show.
01:07:06 This episode is sponsored by Sentry's Seer.
01:07:09 If you're tired of debugging in the dark, give Seer a try.
01:07:12 There are plenty of AI tools that help you write code, but Sentry's Seer is built to help you fix it when it breaks.
01:07:18 Visit talkpython.fm/sentry and use the code talkpython26, all one word, no spaces, for $100 in Sentry credits.
01:07:27 And it's brought to you by Temporal, durable workflows for Python.
01:07:31 Write your workflows as normal Python code and Temporal ensures they run reliably, even across crashes and restarts.
01:07:38 Get started at talkpython.fm/Temporal.
01:07:41 If you or your team needs to learn Python, we have over 270 hours of beginner and advanced courses on topics ranging from complete beginners to async code, Flask, Django, HTMX, and even LLMs.
01:07:54 Best of all, there's no subscription in sight.
01:07:57 Browse the catalog at talkpython.fm.
01:07:59 And if you're not already subscribed to the show on your favorite podcast player, what are you waiting for?
01:08:04 Just search for Python in your podcast player.
01:08:06 We should be right at the top.
01:08:08 If you enjoyed that geeky rap song, you can download the full track.
01:08:11 The link is actually in your podcast blur show notes.
01:08:13 This is your host, Michael Kennedy.
01:08:15 Thank you so much for listening.
01:08:16 I really appreciate it.
01:08:18 I'll see you next time.
01:08:18 to the show
01:08:48 Thank you.