Accelerating Python Data Science at NVIDIA



Episode Deep Dive
Guest introduction and background
Ben Zaitlen is a system software manager at NVIDIA and a long-time contributor in the Python and PyData ecosystem. Before NVIDIA, he worked at Continuum/Anaconda, helping advance core data science tooling. At NVIDIA he works on RAPIDS, the open source suite that brings GPU acceleration to familiar Python libraries like pandas, scikit-learn, NetworkX, and Polars, with a strong focus on practical performance and deep interoperability.
What to Know If You're New to Python
New to Python and want this episode to click? Here are quick primers aligned to what we discussed:
- rapids.ai: NVIDIA's open source toolkit that accelerates data workflows on GPUs. Think pandas, scikit-learn, and NetworkX at GPU speed.
- developers.google.com/machine-learning/frameworks/cudf/colab: Try RAPIDS in a hosted Colab notebook with a free GPU backend.
- www.dask.org: Scales Python across cores and machines. RAPIDS plugs into Dask to fan work out to multiple GPUs and nodes.
Key points and takeaways
Zero-code-change GPU acceleration for pandas, scikit-learn, and NetworkX
The episode’s core idea is you can speed up many existing CPU workflows without rewriting your code. Withcudf.pandas, you can%load_ext cudf.pandasin a notebook or run your script viapython -m cudf.pandasand keepimport pandas as pd. RAPIDS tries GPU execution first and automatically falls back to CPU when needed, aiming for correctness while surfacing acceleration where possible. Similar patterns exist for scikit-learn (via cuML) and for NetworkX via its backend dispatch setting to cuGraph. The team even runs upstream test suites to ensure expected behavior, with pandas tests reportedly passing at very high rates under the accelerator.- Links and tools:
- rapids.ai: rapids.ai
- cuDF pandas accelerator docs: docs.rapids.ai/api/cudf/stable/user_guide/cudf_pandas/
- NetworkX backend dispatch docs: networkx.org/documentation/stable/reference/algorithms/backends.html
- scikit-learn: scikit-learn.org
- pandas: pandas.pydata.org
- Links and tools:
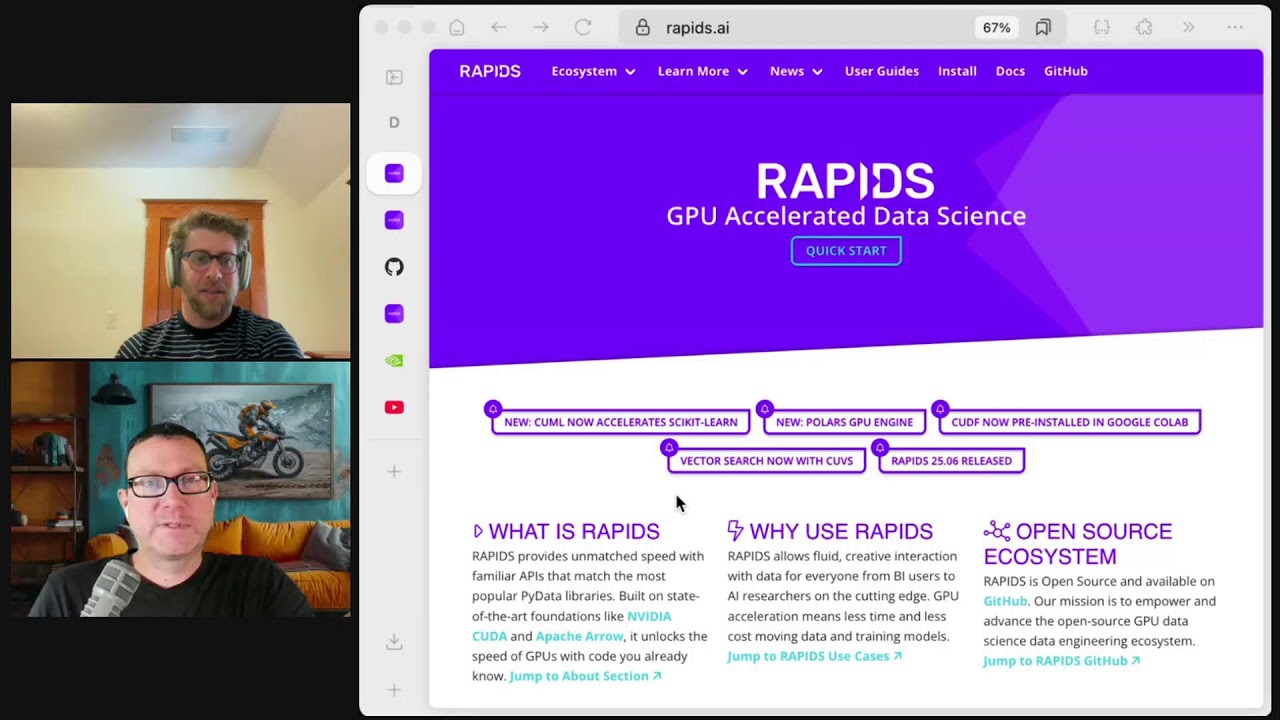
What RAPIDS is and why it’s open source
RAPIDS is a suite of GPU-accelerated libraries that feel familiar: cuDF for DataFrames, cuML for machine learning, cuGraph for graph analytics, plus specialized projects like cuSpatial, cuSignal, and cuXfilter. The rationale for building this in the open is deep interoperability with the broader PyData ecosystem and to meet users where they already are. RAPIDS leans on shared standards so data can move with minimal friction between libraries and runtimes. Many contributions come from NVIDIA engineers, but the projects welcome issues, feedback, and PRs from the community.- Links and tools:
- rapids.ai overview: rapids.ai
- cuDF: docs.rapids.ai/api/cudf/stable/
- cuML: docs.rapids.ai/api/cuml/stable/api.html
- cuGraph: docs.rapids.ai/api/cugraph/stable/
- cuSpatial: docs.rapids.ai/api/cuspatial/stable/
- cuSignal: github.com/rapidsai/cusignal
- cuXfilter: github.com/rapidsai/cuxfilter
- Links and tools:
Expected speedups and where they come from
Ben’s rule of thumb is to target 5–10x speedups versus typical CPU baselines, with outliers higher when replacing single-threaded Python code. Gains come from running vectorized, columnar operations on massively parallel GPU kernels and better exploiting modern hardware. The CPU world is improving too; for example, Polars brings strong multicore performance on CPUs, so GPU vs CPU gaps can narrow on some workloads. Still, many data pipelines see substantial wall-clock cuts when operations map cleanly onto GPU-friendly algorithms.- Links and tools:
- RAPIDS + Polars GPU engine post: rapids.ai/blog/polars-gpu-engine-turbocharge/
- scikit-learn: scikit-learn.org
- pandas: pandas.pydata.org
- Links and tools:
CSV parsing on the GPU is a real win
A concrete example:cudf.read_csvcan dramatically speed up large CSV ingest because parsing and type inference are parallelized across GPU threads. The work includes device-side string handling, numeric conversion, and format quirks, which tend to dominate ingest time at scale. When files reach multi-GB sizes, GPU parsing often outruns CPU readers while yielding a ready-to-use GPU DataFrame. This is a big unlock for ETL-heavy pipelines that start with messy, text-based data.- Links and tools:
- libcudf readers (CSV/JSON/Parquet): docs.rapids.ai/api/libcudf/stable/libcudf_io.html
- cuDF: docs.rapids.ai/api/cudf/stable/
- Links and tools:
Interop by design: Arrow, array API, DLPack, CUDA array interface
RAPIDS emphasizes zero-copy or low-copy handoffs across libraries using shared standards. Apache Arrow provides a columnar in-memory format that multiple tools understand. The Array API standard and NumPy’s array-function protocol help libraries dispatch to alternative array implementations. CUDA array interface and DLPack enable device memory exchange across frameworks like CuPy, PyTorch, and RAPIDS without bouncing through the CPU. This interoperability is what makes "mix and match" GPU workflows possible.- Links and tools:
- Apache Arrow: arrow.apache.org
- Array API standard: data-apis.org/array-api/latest/
- NumPy array-function protocol (NEP-18): numpy.org/neps/nep-0018-array-function-protocol.html
- CUDA array interface (Numba docs): numba.readthedocs.io/en/stable/cuda/cuda_array_interface.html
- DLPack spec: dmlc.github.io/dlpack/latest/
- Links and tools:
When your dataset is bigger than GPU memory
The team discussed two practical strategies. First is Unified Virtual Memory (UVM) where the CUDA driver transparently pages data between host and device; this can keep work going when data slightly exceeds the GPU, though you must watch for performance cliffs. Second is batching or lazy execution that streams data through the GPU in chunks, as seen in Polars’ lazy engine or in specific algorithms that accept external memory. In practice, many pipelines combine both approaches to unlock much larger-than-GPU datasets with acceptable throughput.- Links and tools:
- cuML API index (for GPU ML algorithms): docs.rapids.ai/api/cuml/stable/api.html
- RAPIDS + Polars GPU engine post: rapids.ai/blog/polars-gpu-engine-turbocharge/
- Links and tools:
Scaling out: multi-GPU with Dask and fast interconnects
Beyond a single GPU, Dask coordinates many workers across GPUs and nodes using familiar DataFrame and array APIs. RAPIDS integrates with Dask to shard cuDF DataFrames, schedule tasks, and minimize host-device copies. Hardware matters here: NVLink enables high-bandwidth GPU-to-GPU communication that reduces serialization overhead between devices. The result is a path from notebook-scale experiments to multi-GPU, multi-node clusters without changing your mental model much.- Links and tools:
- Dask: www.dask.org
- NVLink overview: www.nvidia.com/en-us/data-center/nvlink/
- cuGraph docs: docs.rapids.ai/api/cugraph/stable/
- Links and tools:
Hardware trends shaping software design
New platforms like NVIDIA Grace Hopper (GH200) introduce coherent CPU-GPU memory over NVLink-C2C with massive bandwidth. Ben notes teams think about the future as if "there is just memory," then decide how software and allocators should behave when host and device are this tightly coupled. Features like on-chip decompression and faster links don’t change your pandas API, but they let lower layers deliver bigger wins transparently. Expect more performance without user-visible complexity as these architectures land.- Links and tools:
- NVIDIA Grace Hopper (GH200): www.nvidia.com/en-us/data-center/grace-hopper-superchip/
- NVLink overview: www.nvidia.com/en-us/data-center/nvlink/
- Links and tools:
Pandas + Arrow and the broader standardization push
The conversation touched on pandas’ growing support for Arrow-backed dtypes and how a shared columnar format improves cross-tool compatibility. This complements array-level standards so ecosystems can swap engines under familiar APIs. The net effect is less glue code and more time writing business logic while libraries and runtimes negotiate the fastest execution path. It also helps RAPIDS interoperate widely and preserve data layouts across boundaries.- Links and tools:
- Apache Arrow: arrow.apache.org
- pandas: pandas.pydata.org
- Links and tools:
Free-threaded Python (PEP 703) and data pipelines
We discussed Python’s free-threading work, which could reduce the need for heavyweight multiprocessing in I/O-heavy ML data loaders. In GPU workflows, better threading may help overlap staging, decode, and device transfer without forking many processes. It also raises new thread-safety concerns for extension modules, so C/C++ and Rust bindings will need careful updates. Overall, it is a promising direction for end-to-end throughput.- Links and tools:
- PEP 703: peps.python.org/pep-0703/
- Links and tools:
Getting started is easier than you think
The simplest on-ramp is a Colab notebook withcudf.pandas, then try a few pandas scripts with the accelerator enabled. From there, kick the tires on cuML models or NetworkX graphs via cuGraph’s backend to see what accelerates automatically. Once you hit bigger workloads, explore Dask for multi-GPU or multi-node scaling. You can also find community help on RAPIDS Slack and GitHub issues.- Links and tools:
- Using cuDF on Colab: developers.google.com/machine-learning/frameworks/cudf/colab
- RAPIDS community resources: rapids.ai/resources.html
- Dask: www.dask.org
- Links and tools:
Vector search for LLM and similarity workloads (cuVS)
When you step into LLM retrieval and high-dimensional similarity search, RAPIDS’ cuVS provides GPU-accelerated indexing and querying. It grew out of neighbors-and-embedding work common in ML tasks like UMAP and clustering, then adapted to modern vector databases and RAG pipelines. While it’s niche for general data analytics, it is increasingly central for AI-heavy applications. If vector search is on your roadmap, it’s worth a look.- Links and tools:
- cuVS: github.com/rapidsai/cuvs
- Links and tools:
Interesting quotes and stories
"Many of us, even still right now, think of GPUs as mostly being for drawing triangles or just linear algebra... but they're really still quite good computing platforms for doing a lot of processing around all kinds of data." -- Ben Zaitlen
"I want to write six lines of code in a notebook and have it do stuff that was previously impossible." -- Michael Kennedy
"We really try no code change, no import, no changes of imports." -- Ben Zaitlen
"It's all about the user at the end of the day." -- Ben Zaitlen
"Our success is building a wheel, building a conda package." -- Ben Zaitlen
"We typically see this like where you get these benefits... generally our metric for success here is like in the 5 to 10x range." -- Ben Zaitlen
"Go to Colab and just import cuDF.pandas." -- Ben Zaitlen
"Python is not just a niche language... It's found itself in every bit of computing up and down the stack." -- Michael Kennedy
key definitions and terms
- RAPIDS: An open source suite from NVIDIA that accelerates Python data science on GPUs using familiar APIs (cuDF, cuML, cuGraph, etc.).
- cuDF: A GPU DataFrame library with a pandas-compatible API and a pandas accelerator mode (
cudf.pandas). - cuML: GPU-accelerated machine learning library with scikit-learn-style estimators.
- cuGraph: GPU graph analytics that can serve as a backend for NetworkX.
- cudf.pandas: A zero-code-change accelerator that attempts to run pandas code on the GPU, with automatic CPU fallback.
- Unified Virtual Memory (UVM): CUDA feature that transparently pages memory between host and device, allowing workloads larger than GPU memory.
- NVLink / NVLink-C2C: High-bandwidth interconnect for fast GPU-to-GPU and CPU-GPU communication on newer systems.
- Apache Arrow: Columnar in-memory data format enabling zero or low-copy sharing between libraries and processes.
- Array API / NEP-18: Standards enabling libraries to dispatch array operations to different implementations.
- CUDA array interface / DLPack: Conventions for sharing device arrays across GPU libraries without copies.
- Dask: A Python framework for parallel and distributed computing; orchestrates multi-GPU RAPIDS workflows.
- cuVS: RAPIDS’ GPU-accelerated vector search library for embeddings and nearest neighbor search.
Learning resources
Here are solid, episode-aligned resources to go deeper:
- training.talkpython.fm/courses/fundamentals-of-dask-getting-up-to-speed?utm_source=talkpythondeepdive: Learn how to parallelize Python and scale out with Dask, the same engine RAPIDS uses for multi-GPU.
- training.talkpython.fm/courses/introduction-to-scaling-python-and-pandas-with-dask?utm_source=talkpythondeepdive: Convert pandas-style work to distributed DataFrames and clusters, locally and in the cloud.
- training.talkpython.fm/courses/python-data-visualization?utm_source=talkpythondeepdive: Build plots and dashboards that keep up with faster pipelines.
- training.talkpython.fm/courses/explore_beginners/python-for-absolute-beginners?utm_source=talkpythondeepdive: If you're early in your journey, start here so the GPU acceleration topics land cleanly.
Overall takeaway
GPUs are no longer just for triangles and tensors; they're a practical engine for everyday Python data work. RAPIDS lowers the barrier by meeting you at the pandas, scikit-learn, NetworkX, and Polars APIs you already know, often requiring little or no code change to see big wins. Start small in a Colab, flip on cudf.pandas, and let the tooling prove itself. As your needs grow, standards like Arrow and Array API keep everything interoperable while Dask and high-bandwidth interconnects carry you from a single GPU to many. The future is simple APIs, smarter runtimes, and faster answers.
Links from the show
Example notebooks showing drop-in accelerators: github.com
Benjamin Zaitlen - LinkedIn: linkedin.com
RAPIDS Deployment Guide (Stable): docs.rapids.ai
RAPIDS cuDF API Docs (Stable): docs.rapids.ai
Asianometry YouTube Video: youtube.com
cuDF pandas Accelerator (Stable): docs.rapids.ai
Watch this episode on YouTube: youtube.com
Episode #516 deep-dive: talkpython.fm/516
Episode transcripts: talkpython.fm
Theme Song: Developer Rap
🥁 Served in a Flask 🎸: talkpython.fm/flasksong
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Python's data stack is getting a serious GPU turbo boost.
00:03 In this episode, Ben Zaitlin from NVIDIA joins us to unpack Rapids, the open source toolkit that lets Pandas, scikit-learn, Spark, Polars, and even NetworkX execute on GPUs.
00:15 We trace the project's origins and why NVIDIA built it in the open, then dig into the pieces that matter in practice.
00:22 QDF for data frames, QML for machine learning, QGraph for graphs, QXFilter for dashboards, and friends like Qspatial and Qsignal.
00:31 We talk real speedups, how the Pandas accelerator works without a rewrite, and what becomes possible when jobs that used to take hours finish in minutes.
00:40 You'll hear strategies for datasets bigger than GPU memory, scaling out with Dask Array, Spark acceleration, and the growing role of vector search with QVS for AI workloads.
00:51 If you know the CPU tools, this is your on-ramp to the same APIs at GPU speed.
00:56 This is Talk Python To Me, episode 516, recorded July 1st, 2025.
01:16 Welcome to Talk Python To Me, a weekly podcast on Python.
01:20 This is your host, Michael Kennedy.
01:22 Follow me on Mastodon where I'm @mkennedy and follow the podcast using @talkpython, both accounts over at fosstodon.org and keep up with the show and listen to over nine years of episodes at talkpython.fm. If you want to be part of our live episodes, you can find the live streams over on YouTube. Subscribe to our YouTube channel over at talkpython.fm/youtube and get notified about upcoming shows. This episode is sponsored by Posit and Posit Workbench.
01:51 Posit Workbench allows data scientists to code in Python within their preferred environment without any additional strain on IT.
01:59 It gives data scientists access to all the development environments they love, including Jupyter Notebooks, JupyterLab, Positron, and VS Code, and helps ensure reproducibility and consistency.
02:09 If you work on a data science team where consistency matters, check out Posit Workbench.
02:13 Visit talkpython.fm/workbench for details.
02:17 Ben, welcome to Talk Python To Me.
02:19 So excited to be talking data science with you.
02:20 Yeah, thanks so much for having me. I'm really excited to talk to you as well.
02:24 Yes, data science, hardware acceleration, graphics, but not really. So it should be super fun.
02:31 Yeah, let's dive into it. Before we really get into using GPUs for data science, which I think is going to be super interesting, just tell us a bit about yourself. Who's Ben?
02:44 Yeah, my name is Ben Zaitlin. I am a system software manager, I think is my title, at NVIDIA.
02:50 I've been working in the Python ecosystem since I left graduate school in 2006, 2005.
02:58 It's actually, unlike other people, this is only my second job.
03:02 I moved from graduate school to working at Continuum or Anaconda, and then I came to NVIDIA.
03:09 I've always been in the space of doing some kind of science with computers.
03:14 Yeah, Anaconda or Continuum at the time, as it was known, been renamed.
03:20 what a launchpad for this kind of stuff, right?
03:23 Yeah, it's been crazy.
03:25 I mean, I feel like I'm a little bit older now than obviously I was when I first joined things, but it's nice to be able to reflect and look back at how much was built over the last decade and a half or so.
03:36 It really is.
03:37 People use Conda.
03:39 People use Conda.
03:40 A bunch of things in the hip were fixed.
03:42 More things need to be fixed.
03:44 More things are being built.
03:45 It's really great.
03:46 Yeah, and not to go too far afield, But Anaconda Inc. is doing interesting stuff to push on different boundaries of Python.
03:54 In addition to the data science and ML side, you know, they're funding a lot of work on PyScript, which I think is really important for the Python in the browser.
04:04 Yeah, I think one, like many conversations I've had when I was at Anaconda about like how deploying Python can be so challenging.
04:11 It wouldn't be great if we had this deployment vehicle like JavaScript, if everything just ran.
04:16 You didn't need anything set up.
04:17 It's just all on the browser.
04:19 And seeing those ideas actually mature into an existing product is really exciting.
04:23 I think there's some people that are really even pushing quite hard to see how do you connect WebGL to getting other parts of your local machine, like obviously the GPU in this case, accessible through the browser.
04:35 But it's really exciting to see that work.
04:37 All right.
04:38 Now you're just blowing my mind.
04:39 I didn't connect the WebGL, the OpenGL of the browser to GPU acceleration, but of course.
04:46 You can see a few people in PyScript, like if you go to the issue tracker, like, oh, I want to, how do I use PyTorch or how do I use TensorFlow inside of this, inside of my browser?
04:54 Occasionally you'll see some people will talk about it later.
04:56 Like, how do I use Rapids or other things like that?
04:58 But once you open the doors, everybody just wants everything there.
05:02 It's like, oh, yes, I understand.
05:04 I see.
05:04 Okay.
05:05 Yeah.
05:05 Yeah.
05:05 And, you know, I said multiple areas, not just PyScript, but also they're doing a lot of work to support Russell Keith-Magee.
05:13 And it's Malcolm.
05:15 I'm sorry if it's not Malcolm, the guy working with him on that, to bring Python to mobile as well.
05:21 So those are really important initiatives.
05:23 Yeah.
05:24 Python is not just a niche language.
05:28 It's found itself in every bit of computing up and down the stack from mobile to workstation, HPC, everywhere.
05:36 So I want to start this conversation and jumping into Rapids with a few comments.
05:42 First of all, I recently did an episode on just GPU programming.
05:50 So that was really fun.
05:52 And a quick, where was it?
05:55 Oh, yeah.
05:56 That was with Bryce Aldeis-Lolbach.
06:02 Sorry, Bryce.
06:02 I didn't remember the whole name.
06:04 I'm like, I'm going to screw this up.
06:05 I got to look it up.
06:06 So we talked a little bit about GPUs and stuff, and not so much about Rapids and the side of things.
06:12 that you're working on, although we definitely did touch on it a little bit. So that's another resource for people that really want to go deep into this area. But the thing that I want to go and actually talk about is I want to introduce this with a story from when I was in college in the 90s and a question that really surprised me. I was working doing this like applied math project using Silicon Graphics mainframes in complex analysis, if people know what that is.
06:41 And I was programming with OpenGL to do some visualizations and stuff.
06:46 And people, I was trying to get some help and someone's like, Hey, Hey, are you using the GPU for the math calculations?
06:53 Because I want to hear about that.
06:54 I'm like, I don't even, that doesn't even make sense to me.
06:56 Like, why would you even ask me that?
06:57 GPUs are for pictures and graphics.
07:00 I like write loops and stuff for the math part.
07:02 Right.
07:03 But we've come so far and now GPUs really are a huge part of computation.
07:09 Right.
07:09 And Bryce said, hey, I've worked at NVIDIA for a long, long time, and I know nothing about graphics and 3D programming.
07:16 Yeah, everybody's journey into this has been somewhat rejecting some popular notions about what GPUs are and are not for and to really testing those ideas.
07:26 I think many of us, even still right now, think of GPUs as mostly being for drawing triangles or just linear algebra.
07:34 And those are best in class of what GPUs are for, but it turns out that they're actually not terrible for doing string processing, or they're not as fast as they are for doing dense linear algebra, but they're really still quite good computing platforms for doing a lot of bulk processing around all kinds of data that are not typically what you think of for GPU processing.
07:57 But like in data science, so much of what we're seeing now is actually still string based.
08:02 So how do we get, we don't, we can't just, we can't always just isolate parts of the code to be just for strings or just for compute.
08:09 We have to do all of it together and exploring how we can do that all on the device has been really quite, quite revelatory that it's actually pushing us to tell maybe how to inform how hardware maybe should be built or where we can actually do some software tricks to make some of these non-standard processing still quite performant.
08:28 I'm sorry, I think I cut you off a little bit.
08:30 Oh, no, no, it's great.
08:32 If people haven't physically handled some of these GPUs lately, they might not appreciate just how intense they are, right?
08:40 Like, you know, you think, oh, I've got a little laptop and it's got a GPU in there and it must do a thing.
08:44 But like the desktop high-end ones, like I couldn't put a higher GeForce card into my gaming computer because the power supply was only something like 800 watts or something insane.
08:57 Can I even plug that into the wall without melting it, even if I got a bigger power supply?
09:02 These things are crazy.
09:03 And that's not even touching on the H100, H200 type of server things, right?
09:08 Which is just next level.
09:10 Yeah, there's a lot of power consumption for these accelerators.
09:14 I think what she touched on as well is something that I've seen change over the last 10 years that we thought about GPUs as mostly being for just graphics as these niche computing devices. And they're still not exactly, at least in my mind, not exactly commodity hardware, but they're a lot more commonplace where it's not so revolutionary to think of, oh, what else can I do with the hardware that's in my laptop or in my workstation? And GPUs are definitely part of that narrative. We're becoming very common to think of what are other things that I can do with this just sitting around not doing something.
09:50 Yeah, absolutely.
09:51 And I think just coincidentally, or just the way it works out, data science type of work, and really most significantly, the data science libraries, the way that they're built and the way they execute, line up perfectly with the way GPUs do their work.
10:07 And what I'm thinking of is pandas, Polars, all the vector type of stuff.
10:12 So instead of saying, I'm going to loop over and do one thing at a time, you just say, here's a million rows apply this operation to all million and then either update it in place or give me a new data frame or whatever and that is perfect for like let me load that into a gpu and turn it loose in parallel on all these pieces because as a programmer a data scientist i don't i don't write the imperative bits of it right i just let it go and it's easy for things like rapids to grab that and parallelize
10:43 without me having to know about parallelism, right? Yeah, I think the same is also true in the CPU world as well. I don't know a lot about BLAS or LEPAC or these linear algebra libraries that have been in existence for 30 or 40 years. Those have been tuned to the gills to work on CPU, but I'm just the inheritor of all of that academic research. I don't need to know about caching algorithms or tiling algorithms. I just write my numpy or my pandas or my pullers, and generally, I'm pretty happy. Year after year after year, things generally get better for me without having to go very deep into computer science or even computer hardware design. I can still focus on boring business things or exciting business things or whatever particular vertical I'm in, whether it's genomics or selling ads or whatever it may be.
11:33 There's a lot of layers to that, right? We've got the layers of like, you're talking about the libraries or like the CPU operations, but just the pip install or conda install type of layers that you can add on. They honestly don't need to know too much about what even they're doing, right?
11:48 Yeah. I think that the demands of the user have definitely gone up and really pushed, I think all of the library developers to meet those demands. But when I, when I was first starting in computing, you know, you'd read a two or three pages worth of, you know, change this little bit of XML, compile this thing, do something else. Now the expectation really is like single button, if not single button data science, single button deployment of whatever it is I'm trying to
12:13 work on. Yeah. Yeah. I want to write six lines of code in a notebook and have it do stuff that was
12:19 previously impossible, basically. Right. Or I just want to express like math and then have it work.
12:24 Or I mean, even now in some AI systems, I just want to express text and some agent takes care of everything for me.
12:32 Yeah, it's absolutely.
12:33 The AI stuff is absolutely crazy.
12:34 And we'll come back to some of the integrations with like vector embeddings and vector search and all that kind of stuff at the end.
12:43 But for now, let's maybe, I want to talk a bit about open source at NVIDIA and why you all decided to open source Rapids.
12:54 And then we could maybe talk about how it came to be as well.
12:57 So people probably think of NVIDIA mostly, Obviously, there's a lot of audience bias by listening to this show.
13:04 But a lot of people think of NVIDIA as the gaming company or maybe just the GPU company.
13:10 What's the software story and the open source story there?
13:14 I think software is very important to NVIDIA.
13:18 Obviously, CUDA is one of its primary vehicles to interact with the GPU.
13:24 But NVIDIA has been exploring software in a more concentrated way over the last, I don't know, five, six years, at least since I've been there, probably it predates.
13:34 I can't speak for all of NVIDIA in this way.
13:36 But software becomes quite critical that if you want to deliver a full platform to people and have them use it, you need the software to be as good, if not better, than just the hardware.
13:49 Everything, probably everything needs to work.
13:51 I don't need to disparage any group or elevate any one group over another.
13:56 And Rapids kicks off probably in late 2018, but it predates my time there.
14:04 With a thesis of, well, we see a lot of, there's a lot of signal out in the world of whatever it is that I'm doing right now, how do I make it go 10x faster?
14:13 And I think that's a very natural response to any timeframe, whether it's the 60s or 70s and having them search for whatever the hardware was doing back then, faster cores or multi, I don't know, as they approached, I think the first multi-core thing comes out in the early 80s. But we have this desire to do whatever it is that's happening right now, it can always be faster. There's actually this really great Grace Hopper quote that I like, where she's reflecting on some things from the 70s, that not only is data going to increase, but the demand for access to that data is going to increase. And I've heard a lot about data, beta size is increasing, but it was the first time I really saw somebody even back then saying like, oh, the demand for access was going to increase. So it's really, it's like innate for us to just always go faster. And then Rapid's approach to this problem was, well, these libraries have really become like canon for how you do data science in the Python world. The NumPy, Pandas, NetworkX, Matplotlib become the underlying pillars for this huge explosion of Python and PyData libraries.
15:23 And we want to join that effort.
15:25 How do we take a bunch of knowledge around writing very fast GPU kernels and bring it to this very large community?
15:33 And there's a whole bunch of strategies that we try to employ to make it attractive, to make it possible, and to actually deliver something that ultimately will benefit what
15:43 today versus what didn't happen yesterday. Yeah. You know, you're talking about the Grace Hopper quote. I know way back in the early mainframe days before they had many computers or whatever that were still huge, but every one of the, like the early history of Cray and the places that gave birth to that company, every one of those computers, those big computers had its own programming style, its own basically assembly language and the way that it worked. And if you got a new computer, you'd have to rewrite your software to run on this new computer.
16:17 We've come a long ways.
16:18 So we have these nice building blocks like pandas and numpy and pullers and so on.
16:21 Yeah.
16:22 So I love that period of time just because it seemed like so bonkers where, you know, like I think in like the later 2000s when LVM really kind of becomes popular, there's a lot of languages.
16:33 I think in like the 60s and 70s, that time period was also this like Cambrian explosion of languages that very niche things, many of them with the defense department, but also business things like the rise of COBOL comes around, so does FORTRAN, but wonderful languages like the stepped Reckoner, like a harking back to Leibniz things. There's a bunch of really cool... If you have a minute, you can look up this cool image from Gene Samet, who built this Tower of Babel-like image showing all these languages stacked on top of each other and highlighting that problem that you were just describing that if you moved between the IBM 360 to the Omdahl 720 or something like you had to rewrite your whole stack even though the map didn't didn't change or what you were
17:18 working like the problem that you were actually trying to solve didn't really change. Yeah what what an insane time that was but so interesting there's actually a really good YouTube video if people want to check it out called Cray it was the rise and fall of the Cray supercomputer by Asianometry. I'll put a link to that. That goes a lot into it. It's really neat.
17:37 Cool.
17:37 Yeah, absolutely. So let's talk about Rapids. There's a bunch of cool stuff right on the homepage that are like little announcements that I think are going to be really fun to dive into.
17:47 But the H2 here is GPU accelerated data science. And if, you know, Rapids is a Python package that you can install, but it's not just, it's kind of a, I guess you call it a meta package, right?
18:00 Like when you install it, you get a bunch of things that work together.
18:03 So tell us what is Rapids.
18:06 Yeah, so Rapids is a suite of very popular data science libraries that have been GPU accelerated.
18:12 So we've been exploring the space of how you do, again, those libraries that I was describing before that make the pillars of the PyData stack, NumPy, Pandas, Polars.
18:22 Like it keeps, it's grown since we first started and have GPU equivalents of them.
18:28 So, but maybe I can like wax on for a little bit longer.
18:33 That's okay.
18:33 Because the world has changed since we first started these things.
18:36 So when Rapids first kicks off, we say, we'll take, I think many people actually, not just Rapids, says, well, I want, how do I make pandas go faster?
18:46 How do I make Syketlin go faster?
18:48 And there's a lot of products that are built that are import foo as PD or import X as SKLARM.
18:59 And that's where we start off as well. So we build QDF, which is as close to a one-to-one mapping of the Pandas API and build QML that's a similar strategy. It's as close as possible to a one-to-one mapping and same thing with QGraph and NetworkX. And what you have here on the screen is QSPATIAL and parts of SciPySignal. And QSIM is also related to scikit image.
19:26 But when you, I don't know, your experience may differ, but when you go to actually import Foo as PD or import Kupai as NP, it doesn't work out as well as you might want it to.
19:40 There's still enough edge cases there.
19:42 There's enough sharp edges that it actually prevents you from having it just magically work as much as you might want it to.
19:49 And that can be very frustrating.
19:50 So you just move on.
19:51 Right.
19:52 So what you're saying is a lot of times people say things like import pandas as PD.
19:58 A trick somebody might want to try or a technique would be like, well, if it's kind of a one-to-one mapping, could we just say import QDF as PD and see if it just keeps going?
20:09 It's a really great first starting point, but there are some subtle differences.
20:14 And if you go to the QDF documentation page, you can see a lot of these, a lot of that we've tried to highlight where things differ.
20:21 So like on joins or value counts or group buys, pandas guarantees some ordering that Kudf by default doesn't.
20:31 And we care deeply about performance.
20:33 So we could probably meet those API expectations, but we're trying to balance both ergonomics and performance.
20:40 I think even in the case of like Kudf and NumPy, there's going to be differences on indexing behavior.
20:46 There's going to be some behavior where it won't allow you to do an implicit device-to-host calls.
20:53 It will prevent you from doing things in a way that, again, it's a good starting point, but it's not enough to actually deliver on the magic of what I have of this one-to-one mapping that perfectly works.
21:07 This portion of Talk Python To Me is brought to you by the folks at Posit.
21:11 Posit has made a huge investment in the Python community lately, known originally for our they've been building out a suite of tools and services for Team Python.
21:21 Have you ever thought of all the things that go into a Python data science project?
21:25 You need your notebook or IDE, sure.
21:27 Also a server or cloud environment to run it, a version of Python, packages, access to your databases, and internal APIs.
21:35 That's a lot of setup.
21:37 And if you change any of these things, when you return to your projects a month down the road, you might get different results.
21:43 Wouldn't it be nice to have all of this set up for you in one easy-to-access place whenever you want to get work done?
21:49 That's the goal of Posit Workbench.
21:52 Posit Workbench allows data scientists to code in Python within their preferred environment without an additional strain on IT.
21:59 It gives data scientists access to all the development environments they love, including Jupyter Notebooks, JupyterLab, Positron, and VS Code.
22:07 And yet, it helps ensure reproducibility.
22:10 Here's how it works.
22:11 You or your IT team set up Posit Workbench on a powerful, dedicated server within your organization or on the same cloud service that is hosting your most important data sources, such as AWS, SageMaker, Azure, GCP, Kubernetes, or pretty much anywhere.
22:27 There, you create dedicated pre-configured environments to run your code and notebooks, and importantly, you also configure access to proprietary databases and internal APIs.
22:37 When it's time to onboard a new data scientist or start a new project, you just fire it up in Workbench, and it's fully configured and ready to go, including on the infrastructure side of things. All of this is securely administered by your organization. If you work on a data science team where consistency matters, you owe it to you and your org to check out Posit Workbench.
22:56 Visit talkpython.fm/workbench today and get a three-month free trial to see if it's a good fit.
23:01 That's talkpython.fm/workbench. The link is in your podcast player's show notes. Thank you deposit for supporting talk python to me so what should you yeah yeah well what's the likelihood it works if i have a simple problem if i'm say a biology student and i've i've written 20 lines of panda related code and it's kind of slow but could i just get away with it or is it like where are
23:26 these rough edges yeah i think the rough edges come when you again with like some of the assumptions that we've made are usually around some of these ordering problems that i described before I think probably 20 lines of code, yeah, you're probably safe doing it. It's not that big. But as you get into enterprise code, things that are maybe using pandas as a library where you have a lot of all the different kinds of ways that pandas is delightful and sometimes complex, that makes all these guarantees hard. It makes it more and more challenging to make sure that we have met that we've delivered with what we say on the tin. It's harder to meet those things.
24:08 Yeah, whatever that's.
24:09 Yeah, I can. Well, the farther into the edge cases you go, the more that's true, right?
24:13 Yeah. So this is where we start and that's not where we finished. So maybe I can also back up and say part of how Rapids has been interacting with this broader open source ecosystem is, Well, this is what we've done.
24:28 But the ecosystem also wants to do these things.
24:31 They are interested.
24:32 The community, the much broader community is interested in exploring how to use these APIs that people have grown to love and depend on and have them dispatch or be used by other kinds of engines.
24:43 So it's not just Rapids pushing something out into the world.
24:47 It's also working with this broader community.
24:49 So you see this in like the array API standard of how scikit-learn or how NumPy can dispatch to not just Kupy and NumPy, but also to Jax or to Desk or Xarray.
25:01 And same thing with scikit-learn as they explore the space of how to do GP things.
25:06 Yeah, super interesting.
25:08 One thing that I think as I look through this list here, as you see, okay, here's all the ways in which, all the different aspects, all the different libraries that you're compatible with, right?
25:20 Handis, scikit-learn, NetworkX, Scikit-Image, and so on.
25:26 Those things are moving targets, right?
25:29 Yeah.
25:29 So how much of your job is to chase changes to those libraries to keep up what it says on the 10 that you're compatible with them?
25:38 Yeah, it's a lot of work. So we try to adhere to NumPy deprecation cycles of making sure that we're within some kind of range of which version of NumPy we're supporting. But we do spend a lot of time trying to go back in time as much as possible to the older versions that we support, but also still keep up with the bleeding edge of the newest release.
26:03 The way that we have tried to also solve this problem has been in a set of newer developments where we have these zero code change experiences.
26:12 So while QDF and QML and QGraph provide as close to possible one-to-one mappings, we've been pushing on, I think the marketing term that we have for this is truly zero code change.
26:26 So for QDF, for example, we have QDF.pandas.
26:30 And this is a different product on top of Kudia, where we really try no code change, no import, no changes of imports.
26:41 And it's a bunch of really amazing code that has gone into what might be kind of considered a giant try except.
26:48 So you try and we'll take whatever code you have.
26:52 We'll do some, you know, Python lets you kind of muck around with all sorts of fun things under the hood.
26:56 We do that.
26:58 And we'll try and run that on the GPU.
26:59 if it doesn't work, we'll fall back to the CPU library. And that has been really fun and exciting to see that work for lots of reasons. One is because the engineering to make that happen has
27:10 been really fun to get. You have to go into the depths of Python because it's not just using
27:16 pandas directly, but using pandas as a library. How do you make sure that you actually have a pandas object or when a third-party library is using pandas, we don't do something crazy or we to do something wrong.
27:28 Somebody says, is instance or especially a third-party library is doing something, right?
27:35 And there's a lot of that.
27:36 A lot of these Matplotlib and Xray and Seaborn and a whole bunch of other folks, or all these other libraries, do a bunch of instance checking.
27:44 We need to make sure that that's guaranteed.
27:46 So we built this for QDF Pandas.
27:49 We did something similar for QML and scikit-learn.
27:53 But each community is actually different.
27:55 The NetworkX community instead has built a dispatching mechanism.
27:58 So it's an environment variable that you can set to, instead of using NetworkX, it will dispatch to Kugrath.
28:07 And I think the NetworkX community did that as part of, like they have other ideas of different accelerated NetworkX experiences, like NX parallel.
28:16 So let's talk about this, just maybe talk through a little bit of code with QDF.pandas.
28:22 So if I'm in a notebook, I can say percent load ext qdf.pandas.
28:28 And then you just import pandas as PD.
28:30 But you must be overriding the import hooks to actually change what that means.
28:36 First of all, let me take a step back.
28:37 And what if I'm writing a Python script?
28:39 I don't have like these percent magic things.
28:42 Yeah.
28:42 So you can use a module.
28:44 So you can say python-m load qdf.pandas as well.
28:49 I think there's some instructions.
28:50 Yeah.
28:51 I see.
28:51 And then like execute, give it an argument of your script or something like that.
28:55 Okay.
28:55 So, all right.
28:56 That's interesting.
28:56 The other part here is it's a, there's a, you know, comment, Pandas APIs now at GPU Accelerate.
29:02 Great.
29:02 The first thing you've got here is pd.readcsv and it says hash uses the GPU.
29:09 How can you read a CSV faster using the GPU?
29:13 Like, help me understand this.
29:15 Yeah.
29:15 So actually the QDF CSV reader was one of the first things that we, one of the earlier things that we tackled and it forced, it's a very, actually very broad problem because you immediately need to tackle, you don't have to tackle compression and decompression, but you do have to tackle string parsing on the, on, on the device and, and formatting issues and, and a whole bunch of other fun IO tasks.
29:40 And it turns out that as like you can get an op reading CSV is depending, as they get much larger, typically in the like multiple gigabytes to tens of gigabytes, is a lot faster on GPU compared to the Panda CSV reader, because you're doing so much of that, so much of that parsing can be parallelized as you convert a one to an int.
30:02 Yeah, because like the quote one to the 0, 0, 0, 0, 0, 1 in binary, right? That sort of thing.
30:08 Yeah. Okay. Yeah, I guess I didn't really think of it, but especially with Pandas and pullers as Well, it'll potentially try to guess the data type and then do like conversion to date times or conversions to numbers.
30:21 And then that could actually be the slow part, right?
30:23 That's right, yeah.
30:24 Okay.
30:25 Well, I guess using the GPU for that makes sense.
30:27 You just jam a bunch of text in there and you tell it to go wild on it and see what it can do.
30:32 Yeah, that's right.
30:33 Kudief, I should also say, sorry, I forgot to mention it, that Kudief Polar is also a relatively new offering.
30:40 And that we've been working very closely with the Polarist community to not have...
30:44 We're not...
30:45 This mechanism, working closely with the Polarist community allowed us to just say instead of...
30:50 On your collect call, you can define a particular engine type.
30:54 So whether it's streaming or whether it's GPU, now we have a similar kind of very easy button for these worlds.
31:01 So it's not like we're trying to dogmatically dictate what each experience has to be, but work with all these, the community at large or each individual library communities and what best
31:13 works for them. Yeah, super neat. One of the things that I saw, where did I see it? Somewhere.
31:19 One of these levels here. I saw that with, here we go, on the QDF top level bit, it says that it's built on Apache Arrow, a columnar memory format. Polars is also built on Apache Arrow. And Pandas now supports that as a possible backend instead of NumPy.
31:40 But as Pandas 3 is coming out, it's going to be the default as well.
31:44 So something I've heard a lot when I was reading about Rapids and stuff is zero copy interop with other parts of the ecosystem.
31:53 And I asked you about the staying API compliant, but staying in-memory shape compliant.
32:00 So you can take one thing and just go, here, have this.
32:03 you don't have to transform it or marshal it over to a different format. You can just pass it over.
32:08 Like that's pretty neat, right? Yeah. That's been, it's, yeah, we, we are definitely big.
32:14 Many of us in Rapids have wear open source badges very proudly and want, and push these, push ourselves to do these kinds of things because it only works if you get interop, like throughout the much broader community. So it's not just that we built a very fast merge that doesn't work with anybody else or that we have a GPU accelerated library that you have to stop what you're doing in order to do some viz. It works everywhere. And that means relying on Arrow as an in-memory data format, or even things like array function dispatching from NumPy, or the CUDA array interface, things like DLPack. All these things have to actually work in some amount of harmony to actually help the end user do what they're trying to do. It's all about the
32:58 user at the end of the day. Yeah. It's a pretty wild initiative to say, let's try to replicate the most important data science libraries into a cohesive whole that does a lot of what, you know, Pandas and scikit-learn and stuff do, but like just on GPUs, that's a big undertaking.
33:14 And still also interoperate with them, yeah.
33:16 Yeah, it's really big.
33:18 It's a bit grand, more than a bit grand.
33:24 But I think we've seen like a lot of success.
33:26 I mean, there's definitely like some trials and tribulations along the way, But I think we're ultimately pushing something and exploring the space in a way that gives users something that they can try out right this minute and actually get some benefit right now.
33:39 So we have a lot of actually paying customers that want to use these libraries or that are deriving a lot of value from it and helping them accelerate what they were doing yesterday, today.
33:49 There is what I really like about this world, though, is that it's still a bit of research.
33:54 I mean, sorry, maybe more than grand thing to say is that there's not a whole lot of people that explore this space.
34:00 And not only are we exploring it, but we're also putting it into production or we're not writing a white paper.
34:08 Like our success is building a wheel or building a conda package.
34:11 Yeah, yeah, that's super neat.
34:14 So building this stuff as an open source library, which is pretty cool.
34:17 So for example, QDF is a Apache 2 license.
34:21 It's great doing it on GitHub, really nice.
34:24 it allows people who are using this to say, not just go, please, please add a feature, but maybe they can look and suggest how to add the feature or they can do a PR or whatever.
34:33 So what's the breakdown of NVIDIA people contributing versus other contributors?
34:40 You know, like what's the story there?
34:41 I said there's 12,000 closed PRs for QDF.
34:46 The far majority of PRs that are being committed are by people that work at NVIDIA or work closely with LibQDF.
34:54 We've seen other companies that have gotten involved in some niche cases.
35:00 We've also seen a number of academics from other, usually from a GPU CS oriented lab that will get involved here.
35:10 But what we see actually more open source interactions, it's the best thing in the world for any library.
35:15 It's when somebody says, oh, I have a problem.
35:17 That's so wonderful.
35:18 We see a lot of issues from our users, which is so great.
35:22 these when we were doing things as like import library as PD or scikit-learn, the users would probably not say anything. But now that we've built these zero-code change experiences and thought more about profiling and how to actually inform the user whether something is or is not happening, when something doesn't meet their expectations, they now have this opportunity to tell us something didn't go quite right or not getting the acceleration that I want, please help me. And that happens on GitHub issues and that happens on the GoAI Slack channel. It's really great to see. But for day-to-day contributions, yeah, the majority of them are happening at NVIDIA. But suggestions can... It's open source, so you can please come commit if you want to learn about GPU data science. Or if you have a feature request, please, we try to stay as responsive as possible to all the community interactions that are community vectors that we're a part of.
36:19 Yeah, super neat. It's really cool that it's out there like that. So let's talk about sort of the effect of choosing something like Rapids over NumPy-backed pandas.
36:33 I've read a bunch of stuff about that used to take a week and now it takes minutes. That's an insane that's an insane sort of speed up and you know i was talking about the power just kind of like yeah these things are crazy like the power consumption and stuff but the other angle that you know people say like oh this uses so much energy one consideration though is it might use a ton of energy for this compute but it might do it for minutes instead of for a week on a cluster of cpus right so it's not yeah yeah it's not as insanely far out as you think but there's a lot of stuff that makes sort of like scaling up, scaling down, I think pretty interesting that I want to talk to you about. But first of all, just maybe give us some examples of what are data scientists and people doing computational stuff seeing by adopting this or what's become
37:21 possible that used to be unreasonable? Yeah. So an internal goal, at least for many of the people that I work with, is usually we're trying to get to like five to 10x performance speed up of versus what already exists out there, whether that's, yeah, for typically comparing against some CPU equivalent. There are definitely cases where we're trying to push into that area. There are definitely cases where it's not as performed, where you're getting like one and a half or two.
37:49 Generally, our metric for success here is like in the five to 10X range. You will definitely come across these absolutely bonkers speed upsets, a thousand X faster. And they're not fabricating those speedups. Usually that's because they're doing some single threaded Python thing. And now the GPU has just unlocked this unreal performance that they were doing before.
38:13 Go and find a bunch of NVIDIA blog posts that make those claims. I think there's been some on climate science and writing some Numba GPU kernels. But we typically see this where you get these benefits. If you're comparing QDF to pandas, you're comparing this incredibly parallel powerful GPU machine to what might mostly be a single core, in some cases, a little bit of multi-core interactions on CPU. And you can get, it's very easy to get these very, very large speedups where I think the same is also true. The same can be true for scikit-learn as well, where we're model training and just running, especially like hyperparameter searching, where you're just doing the training over and over and over again with different parameters.
39:01 You can get very powerful, very large speedups comparing scikit-learn to QML or just CPU to GPU.
39:11 But I think what I also find exciting is that the CPU world and the Python world is not sitting on their hands.
39:17 There's all these other scikit-learn developers are pushing into doing more multi-core things.
39:23 And Polars has actually come out with a bunch of very, very powerful multi-core native tooling that's very exciting.
39:32 So when you compare Kudiev to Pandas, you can see these very powerful speedups.
39:36 You compare GPU Polars to CPU Polars, the speedups are definitely still there, but they're somewhat diminished because CPU Polars itself is quite powerful.
39:47 Yeah, just to give people a sense, I'm speaking to you all right now on my Mac Mini M2 Pro, which has 10 CPUs or CP cores.
39:56 And if I go and run Python, computational Python code, it's single-threaded, so it's one-tenth of my machine, right?
40:05 But if there's nothing stopping people like Richie Vink from adding internal parallelism to certain important operations inside pullers, right?
40:14 And just by that virtue, it's 10 times faster on my machine.
40:18 So, well, ish, right?
40:21 It's on the scale of 10 times more compute resources anyway.
40:25 So if you said, you know, the rapid stuff was 100 times faster before, well, now maybe it's 10 times faster.
40:31 And that might sound not as impressive, but that's just progress in other areas, right?
40:35 Yeah, I think it's great all around.
40:38 Yeah, it's fun to see.
40:40 I mean, even though I'm here talking about GPU data science, I think it's just like really great to see more of the Python data science ecosystem really leveraging and understanding more about the hardware.
40:51 whether that's like the multi-core nature of all the machines that we have now, or even I think like, you know, a decade ago, people were like, oh, there's these L1, L2, L3 caches that we can take advantage of. We should target that. How do I do that? How do I make that? How do I expose that in Python? Where it's not already baked in, your work isn't baked into BLOS or these vector code
41:14 bases that have existed for a long time. Yeah. I hadn't even thought about like specifically trying to address the L1, L2, L3 cache sort of deals.
41:22 Like those caches are hundreds of times faster than main memory.
41:26 There really is a big, big difference.
41:29 And if you structure, it's like, well, what if we aligned our data structures that are allocated them this way in memory, then maybe we would like be able to hit the cache a lot more, you know, the L2 cache or whatever.
41:40 It's crazy.
41:41 Yeah.
41:42 Working at NVIDIA, we think about, or when we think about Rapids, we think about that entire pipeline as well.
41:46 How do we move data?
41:48 as efficiently as possible from disk to memory to GPU memory, do some compute and try and take advantage of all of the bits of hardware in between them. Yeah. What do you think about
42:00 Python T as in free threaded Python? The big news is just a week or two ago, it was officially accepted, you know, like was that PEP 703? I think it was that got accepted in Python 313 as sort of experimentally accepted. And I've never heard of something being added to Python as like, well we'll give it a try but we might take it out but that's how that was added and it is it kind of got the all right you're going to the next stage you're you're more likely to not be kicked out or i'm not sure if it's 100 guarantee but that's going to have a lot of knock-on effects as well right it especially affects the data science space because if you're writing extensions through the c apis or rust right you've got to think more about thread safety because python all of a sudden can become concurrent like it didn't used to be able to?
42:46 Yeah, it opens up a big door.
42:50 I think in the initial PEP, one of their highlighted use cases was actually the problem that we were just talking about of how do you pipeline efficiently across multiple devices?
43:01 So in the PyTorch case, you need to maybe spin up a bunch of different, at the moment, you need to spin up a bunch of Python processes in order to efficiently load data from disk into your PyTorch or your deep learning pipeline.
43:16 Doing that with multiprocessing is not a wonderful world.
43:20 And we could probably be a lot better.
43:22 Free threading maybe opens up that door.
43:25 Yeah.
43:25 I also see it adding possible challenges, not just benefits.
43:29 Like, for example, if I go and write a bunch of multi-threaded code that's truly multi-threaded, like C and C# and other languages have been for a while, pretty much forever, and I start interacting with it, Like, does that, you know, we talked about L2 cache and keeping it active.
43:45 Like, what about the GPU?
43:46 Like, does that potentially open up a case where the GPU gets loaded up with, you know, tons of data and gets dropped because a thread contact switch happened and like just it thrashes?
43:57 It's possible that that could happen.
43:59 Sorry, this line of questioning also opens the door for me to just briefly talk about like these larger systems that NVIDIA,
44:06 but other folks have been building as well, like where you have coherent memory.
44:09 Yeah, so in this new architecture, Grace Hopper or Grace Blackwell, there's a specific communication channel between device and host.
44:20 It can, I think it's called chip-to-chip technology or NBLink C2C, and you can move data back and forth between device and host at around 900 gigabytes per second.
44:30 That's basically free, right?
44:33 Or sometimes it's fun to think about it.
44:35 I'm pretty sure it's faster than my RAM on my Apple Silicon.
44:38 Yeah.
44:39 So thrashing is not good, but if you're for whatever reason in that scenario for a pipeline, you might not feel it in these new coherent memory systems.
44:52 Yeah, that's wild.
44:54 I also think you probably just, you know, it might be one of those things where it's like, doctor, my leg hurts when I bend it this way.
45:00 And they said, well, don't bend it that way.
45:02 You know what I mean?
45:03 It hurts when I try to run like 10 concurrent jobs on the GPU on the same computer.
45:08 well don't do that you know what i mean sure that that might be that might be the way like use a
45:13 use a lock and don't let that stuff run then right yeah the answer for for probably these things is probably don't do it you shouldn't you shouldn't just absorb that problem dr hitters like no don't
45:23 do that um but there are ways to scale up and i got all this comfort this is kind of what i was leaning towards is like there's interesting ways to scale up um across like multi gpu i know that Dask has an interesting interop story and Dask has super interesting grid computing ways to scale. So like Dask can kind of do pandas, but larger than memory on your machine. And it can take advantage of the multiple CPUs cores, and it can even scale out and across clusters. Right. And so there's some integration with Dask and other things. Do you want to talk about that side of the
45:58 story? Yeah. Yeah. So maybe very briefly, Dask is trying to scale Python data science as well.
46:06 So I think actually, if I can just get into a little bit of the history,
46:09 there's lots of people, I think just before a bunch of people are importing library as PD,
46:16 there's a lot of people, I think even historical people that have been exploring, how do I do distributed NumPy or distributed memory array applications, like both in the HPC world and also in the enterprise world. And they're rewriting a library from scratch. And Dask comes along with the idea of, well, I'll just take the... I'll build some block, I'll build some distributed version of NumPy, but still keep NumPy or still keep pandas as the central compute engine for what's happening. And I'll build orchestration mechanisms around that and build distributed algorithms around pandas or around NumPy. And there's a way for you to both scale out horizontally and also scale up because you could get pandas now as a multi-core thing and you could get numpy as this distributed scale out solution and much of the dask world actually evolved with with rapids as well in the last like five five years is last five years where because we were building a pandas like library in rapids like qdf we could get dasks to also do our scale out scale-out mechanisms. So we built some hooks for Desk to, or we tried to generalize what is a data frame. If it meets these things, I can use pandas, I can use QDF, I can use the next data frame library after that. We also built some specific hooks inside of Desk to take advantage of accelerated networking and making sure that GPU buffers got shipped around to all the different
47:45 workers. That's pretty wild. So could I have, I guess I could probably have multiple GPUs on workstation, right? When I say that, I know you can have multiple GPUs and you can link them in hardware, but could I just literally plug in multiple GPUs and take advantage of them as well?
48:03 Yeah. You can have, underneath my desk, I have a two GPU workstation that does have an NVLink bridge between the two, but you could also just have them work at many, many, many workstations,
48:17 just have two GPUs plugged into the PCIe board. And things will work there as well.
48:21 Yeah. There are some performance considerations there where if you want to move, if you're communicating data between those two devices, you pay a bit of a cost. You have to move data from device to host. You then have to serialize it across the network and then move data from host to device. This is why having that NVLink bridge is so powerful if you have it in your system.
48:45 Okay. So if people are already using Dask, how easy is it to adopt the setup? Or do you even have to think about it? Is this Dask storage just underneath the covers of the API?
48:57 If you're already using Dask, you can already use DaskQDF or DaskKupai. Those things work.
49:06 I've done some experiments and I've not had as much success, but people are still pushing quite hard as using Dask as a third-party library.
49:13 So how do I make a GPU version of X-Ray?
49:17 Well, that actually takes a bit more work.
49:19 And there are people that are pushing quite hard, as I was saying before.
49:21 But X-Ray, at least when I attempted it like three or four years ago, has a lot of mixture of DESK, of Pandas calls, of NumPy calls.
49:30 And it was hard, at least in my attempt, to perfectly articulate all the GPU mechanisms that needed to be satisfied to make it work seamlessly or get any performance benefit.
49:41 But I'm not as up to date on it.
49:43 Maybe there's been some recent developments there.
49:45 Yeah, there's a lot of moving parts.
49:48 And they're all moving.
49:49 And what used to be impossible and now is no problem.
49:53 But you haven't tested that combination, right?
49:56 Yeah.
49:57 I'm very encouraging of anybody who wants to work on that problem or explore that space.
50:02 I think geospatial, geoscience things definitely need all the attention they can get in an ever-changing climate world, climate science kind of problems that we are all experiencing as humans.
50:13 Yeah, absolutely.
50:14 So we talked earlier about the challenge of staying in touch with all these different APIs and staying consistent with them.
50:23 Do you have really interesting test cases?
50:25 Do you have some mother-of-all-py test execution sort of thing where do you maybe take the pandas unit tests and try to run them on QDF and similarly with scikit-learn and so on?
50:39 Yeah, that should have been my first answer now that I think about it. That's exactly what we do do. For Kudyat Pandas, we run the... So for the Kudyat Pandas product, we do run the Pandas unit test. And we see... That's the goal, to have this run perfectly across it. It's not necessarily to accelerate all the APIs, but making sure that we never fail.
51:02 They fall back to CPU if they have to.
51:04 They fall back to CPU if they have to, exactly.
51:07 We're also recording where we aren't using the GPU.
51:10 So it gives us some directional information about the kinds of things that aren't accelerated.
51:15 So maybe there's some niche datetime features or some niche extension D-type things that we aren't handling or can't be handled.
51:24 And the same thing is also true for scikit-learn and QML.
51:28 I think there are some known, actually at the moment, there are some known failures for for QML and SecondLearn. But we do, that is like the easiest thing that we could do. And we,
51:35 we do that. Yeah. And are they, they're pretty much all running. I know you talked a little bit about QML and stuff, but how much pytest.ignore is in there? There's not as much as you,
51:47 I think for KUDIF pandas, we are at like 99.x% passing for, for it. For QML, I have to look it up. But I think we still have like pretty, pretty good coverage of, of the entire scikit-learn code base in terms of not a falling back correctly, not necessarily accelerating it. There's a lot of,
52:07 there's a lot of classifiers there. Okay. Yeah. I'm sure there are.
52:11 That might be interesting. I don't know if this is like documented somewhere or whatever, but that might be interesting as a way for people who are considering adopting it to go like, well, let's see what the failing or ignored tests are like, no, these don't seem to apply to me.
52:23 we're probably okay i think actually on the kumel documentation page there's a known limitation section that outlines the kinds of estimators that are not are not accelerated on some edge cases that are not supported at the moment but they're working again the team is quite motivated to like keep on as you've mentioned before it's an ever-changing world we're not we're
52:44 going to keep on working on these problems my now admittedly pretty old geforce card in my gaming computer I got in 2020. I don't know how much RAM it has, four gigs, eight gigs, something like that.
52:56 But I know there are data problems that are certainly bigger than four or eight gigs of data.
53:01 What happens if I try to read CSV and the CSV is 12 gigs and I've got eight gigs of available?
53:07 I love that you asked this question because it's been a focus of our group for like the last year and a half. A lot of very fun engineering problems have to be solved when you want to do of core processing and there's a lot of tools that we can deploy to solve this problem.
53:25 So for single GPU, there already is a solution that was available to us that we needed to improve upon, but still could largely just deploy.
53:35 And that's a CUDA memory type.
53:38 CUDA has a bunch of different kinds of memory that you can use.
53:41 So there's not just CUDA malloc, but there's an asynchronous malloc.
53:46 And there's also a larger pool that you can build and then pull memory from this larger pool to help speed things up.
53:53 There's also something called UVM or Unified Virtual Memory.
53:58 And in this case, the driver, the CUDA driver itself, is going to try and allocate some memory on the GPU.
54:05 And if it can't, it will spill.
54:07 It will page data from the GPU onto the CPU.
54:11 And the driver just takes care of all of that for me.
54:13 So if you have a 12 gigabyte data set and you're trying to read it into a car that only has eight gigabytes, you could probably get by with just UVM.
54:26 A question that you still should ask yourself is whether you received any performance benefit.
54:30 I really want to be very clear.
54:32 If you're trying to do something on CPU, and it's faster and everything just works, you should stay there.
54:37 You shouldn't bend over backwards.
54:38 We're really working hard to make sure that you get a benefit from using these devices.
54:42 The other thing that you can do is batch.
54:45 So there's this exotic memory type that is like the default.
54:49 Most users don't ever have to think about it or worry about it, especially in the case of QDF pandas.
54:56 But the other thing that you can do is sip data out.
55:00 You can batch it.
55:01 So for pandas, that's a lot of work to write a lazy framework on top of it.
55:06 But for polars, that already exists.
55:08 I was thinking that's the default of kind of how polars works.
55:12 Right.
55:12 So we already have this mechanism to push to higher than memory, larger than memory limits, or do this out of core kind of processing because it's native to the Polars experience.
55:22 I think we've also been seeing that more with some of our machine learning algorithms.
55:29 So if you look at the 3.0 release of XGBoost has this external memory allocator where you can use host memory to batch data in before you start processing on GPU. And the same thing is also true for UMAP as well, where you can use host memory to store data temporarily as you start processing it on GPU. And it allows you to really push much higher than what this resource-constrained
55:59 GPU environment is. If I want to run this stuff in the cloud, what are some good options? Do I go to DigitalOcean and just pick a GPU-enabled droplet? Or is there like super heavy-duty things I can get? Or maybe you're like me and you have a Mac Mini, but you want to play with stuff and you don't have an NVIDIA GPU on this computer. Yeah. Unfortunately for the Mac Mini,
56:22 there aren't a lot of options. While all this is open source and the code can be read and can be contributed from anybody, these only work on NVIDIA hardware. So yeah, you can go get a a Droplet, spin up a Docker image.
56:39 I think we not only have pip and kind of packages, but also have Docker containers.
56:45 You can get AWS.
56:46 You can get, I think, on this page, maybe not the page that you're on, but there's a deploy page where we have a lot of recommendations about how to deploy rapids in a variety of environments.
56:59 Some things like some of the MLOps tools like SageMaker.
57:03 Yeah, that's the page.
57:04 I probably could do something like Google CoLab or something like that in my MacBan, right?
57:10 Actually, that's the best place to get started.
57:13 That's where we direct a lot of our users.
57:16 Google CoLab has a free tier offering where you can just select a different backend.
57:20 I think for Kaggle users, there's now even like L4s or multi-GPU L4s that they can get access to.
57:26 Nice.
57:27 Okay.
57:28 And then one other thing before we wrap it up is, let's see, I just go to Rapids.
57:34 I know at the beginning here, it says you got the new Polars GPU engine, what we talked about, and it's pre-installed on Google Colab and things like that.
57:44 But you also have vector search now with QVS, which is what I'm going with unless I'm told otherwise.
57:49 But if you're not using AI, you're not using LLMs, but you're literally building LLMs or you're augmenting LLMs, this vector search stuff and embeddings and whatnot is what you need. So I know you're not a super expert in vector embeddings and stuff, and neither am I, but maybe tell people quick about this
58:08 library, this aspect. Yeah, this actually grows out of the QVS, or QD Accelerated Vector Search, grows out of the ML world that you have. In the ML world, for UMAP or clustering algorithms, You need neighborhood algorithms to help you do regular data science.
58:30 And it turns out that taking a bunch of strings and doing math on them, which is what a vector, which is what an embedding is, I have some text, I need to do some math on it, and then I need to understand how that text relates to other things with even more math.
58:44 It'd be something like cosine distance or Jaccard similarity or minhash, whatever it is.
58:50 And I need to do that across a very large corpus of text.
58:54 So vector search and vector rag become this go-to tool for the LLM space, which is, as I was just saying, a lot of math on text.
59:03 How do I make that go faster?
59:05 How do I build an index?
59:06 How do I re-index faster and faster and faster as the corpus changes or it has an update?
59:11 Yeah, you think geospatial is an interesting query.
59:14 Like the number of dimensions of this kind of stuff is unimaginable, right?
59:19 That's right.
59:19 I don't know that as many day-to-day, like if you're in the LLM space, LLM building space or in the retrieval space, QVS is definitely going to be something you should take a look at.
59:31 For the rest of the broader data science community, I don't think QVS is as relevant to that
59:35 just as a small clarification.
59:37 Right, like how many people are using vector databases that are not using LLMs?
59:43 Probably not too many.
59:44 Right, probably not too many.
59:45 Yeah.
59:46 All right, let's wrap this up with one final question.
59:49 where do you go from here? What's next?
59:51 What's next for Rapids?
59:53 Yeah, Rapids and basically Python plus NVIDIA.
59:57 I think what's next for Rapids is it's always going to be some bit of maintenance of what we currently have pushing more and more performance and then trying to always encourage people to try out what we have and actually deliver something that is ultimately providing value for them.
01:00:18 I think that there's a lot of really cool things that are happening on the hardware side, as I mentioned before.
01:00:23 Like Blackwell has some pretty cool things that I don't know that the users will feel, but I don't know that they're going to have to interact with.
01:00:31 So there's this very fancy decompression inside of Blackwell.
01:00:36 There's also, again, as I mentioned before, in this coherent memory world where there's just memory or can I treat the system as just memory, how does software look?
01:00:45 If I want to, like, we're posing these questions to ourselves, but if there was just malloc in the world and that happened seamlessly between host and device in it, what kind of software would I be running? How would I try and architect that code? I think those pose a lot of, like, very interesting computer science and also computer engineering questions. I think for, like, NVIDIA and Python, as the guest that you had on before, Bryce Ledback was describing, I think exposing all these ideas to Python developers is really exciting. They might not maybe move into the C++ world, but I think a lot of Python developers want to understand how this device works and how they can manipulate it through their language of choice. We've seen that as we were actually just describing earlier, like I want to get access to the different cache levels, but we see Python core developers made that available to us. That's really wonderful. The whole world isn't just vector computing. I want to take advantage of the entire system. So I think a lot of it is going to be exposure, education,
01:01:46 and more and more performance. Awesome. Any concrete releases coming up that
01:01:51 people should know about? Rapins does releases every two months. So you can see some announcements of what we're planning in the next release. I think that we're coming up 2508 should be baking right now. And then we'll have 2510 and 2512, where we just announced a few months ago a multi-GP Polarist experience. You can scale, not just have scale up, but scale out with the Polarist front end. We're doing a lot of good work around Kuml XL, as I was mentioning before, getting more algorithms, trying to push to higher and higher data sets that UMAP works with. And we're also looking at, we're trying to spend some time looking at particular verticals, I think, especially in like the bioinformatic space as well. But, you know, really excited to hear from anybody if they have a problem that they need, that they need more power, more performance, you know, please,
01:02:44 please raise your hand and come talk to us. Awesome. Yeah, I'll put your, some link to you somehow in the show notes that people can reach out. But you mentioned Slack earlier, is there Slack Discord? What are the ways? Yeah, there's a couple Slack channels. One of them is
01:03:00 called GoAI. There's a CUDA Slack channel.
01:03:05 And then there's also a community-based GPU mode Slack channel that's a little bit more deep learning oriented. But the GoAI Slack channel is something that is specific to
01:03:15 Rapids. Yeah. Awesome.
01:03:16 Ben, this has been really fun.
01:03:19 People out there listening, maybe they want to get started.
01:03:21 What do you tell them? What do they do to try out Rapids? Go to CoLab and just import CUDA Pandas. Import Kumel XL. Import NXCUDRAF.
01:03:31 Everything is baked in.
01:03:32 We worked really hard with Google to make sure that that environment was set up from the get-go.
01:03:36 Awesome.
01:03:37 All right.
01:03:37 Well, it's been great to chat GPUs and data science with you.
01:03:41 Thanks for being on the show.
01:03:41 Thanks so much for having me.
01:03:42 I really appreciate it.
01:03:43 Yeah, you bet.
01:03:44 Bye-bye.
01:03:45 This has been another episode of Talk Python To Me.
01:03:48 Thank you to our sponsors.
01:03:50 Be sure to check out what they're offering.
01:03:51 It really helps support the show.
01:03:53 This episode is sponsored by Posit and Posit Workbench.
01:03:57 Posit Workbench allows data scientists to code in Python within their preferred environment without any additional strain on IT.
01:04:05 It gives data scientists access to all the development environments they love, including Jupyter Notebooks, JupyterLab, Positron, and VS Code, and helps ensure reproducibility and consistency.
01:04:14 If you work on a data science team where consistency matters, check out Posit Workbench.
01:04:19 Visit talkpython.fm/workbench for details.
01:04:22 Want to level up your Python?
01:04:23 We have one of the largest catalogs of Python video courses over at Talk Python.
01:04:28 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:04:33 And best of all, there's not a subscription in sight.
01:04:35 Check it out for yourself at training.talkpython.fm.
01:04:39 Be sure to subscribe to the show, open your favorite podcast app, and search for Python.
01:04:43 We should be right at the top.
01:04:45 You can also find the iTunes feed at /itunes, the Google Play feed at /play, and the direct RSS feed at /rss on talkpython.fm.
01:04:54 We're live streaming most of our recordings these days.
01:04:57 If you want to be part of the show and have your comments featured on the air, be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:05:05 This is your host, Michael Kennedy.
01:05:07 Thanks so much for listening.
01:05:08 I really appreciate it.
01:05:09 Now get out there and write some Python code.
01:05:28 *music*