Pandas and Beyond with Wes McKinney



Episode Deep Dive
Guests Introduction and Background
Wes McKinney is a pioneering force in the Python data ecosystem, best known for creating or co-creating pandas, Apache Arrow, and Ibis. He has a deep background in quantitative finance and data infrastructure. Wes is also an entrepreneur, having co-founded Voltron Data, and he now holds a software architect role at Posit (formerly RStudio) to help shape the company’s Python strategy. Throughout his career, he has focused on improving Python-based data workflows and building new libraries and standards for data science at scale.
What to Know If You’re New to Python
If you’re just getting started, you’ll want to know that pandas is the de facto library for working with tabular data (think “spreadsheets” in Python). Many of the discussions below center around topics such as dataframe APIs, vectorized data operations, and integrations with broader ecosystems like Arrow, polars, and SQL.
Key Points and Takeaways
- Pandas as the Data Analysis Cornerstone
Pandas has become the standard library for Python data analysis, offering tabular data structures, built-in methods for filtering and grouping, and a powerful ecosystem around it. It’s widely adopted in industry and academia, partly because it’s a well-known entry point for data science and analytics in Python.
- Links / Tools:
- Apache Arrow: Modern Data Interchange and Performance
Wes and colleagues started Apache Arrow to create a language-agnostic, columnar memory format for high-performance analytics. Arrow takes advantage of cache-efficient operations and vectorization, enabling faster workloads on modern CPUs and even GPUs. It also serves as a bridge between different systems (like Python and Rust-based projects) without needing bespoke data conversions.
- Links / Tools:
- Ibis: One API, Many Backends
Ibis focuses on providing a dataframe-like API that can generate SQL or connect to various engines under the hood (DuckDB, Spark, polars, pandas, etc.). This portability lets you run similar code whether you’re on a local laptop dataset or a large cluster. It simplifies the big data story by giving you a uniform interface.
- Links / Tools:
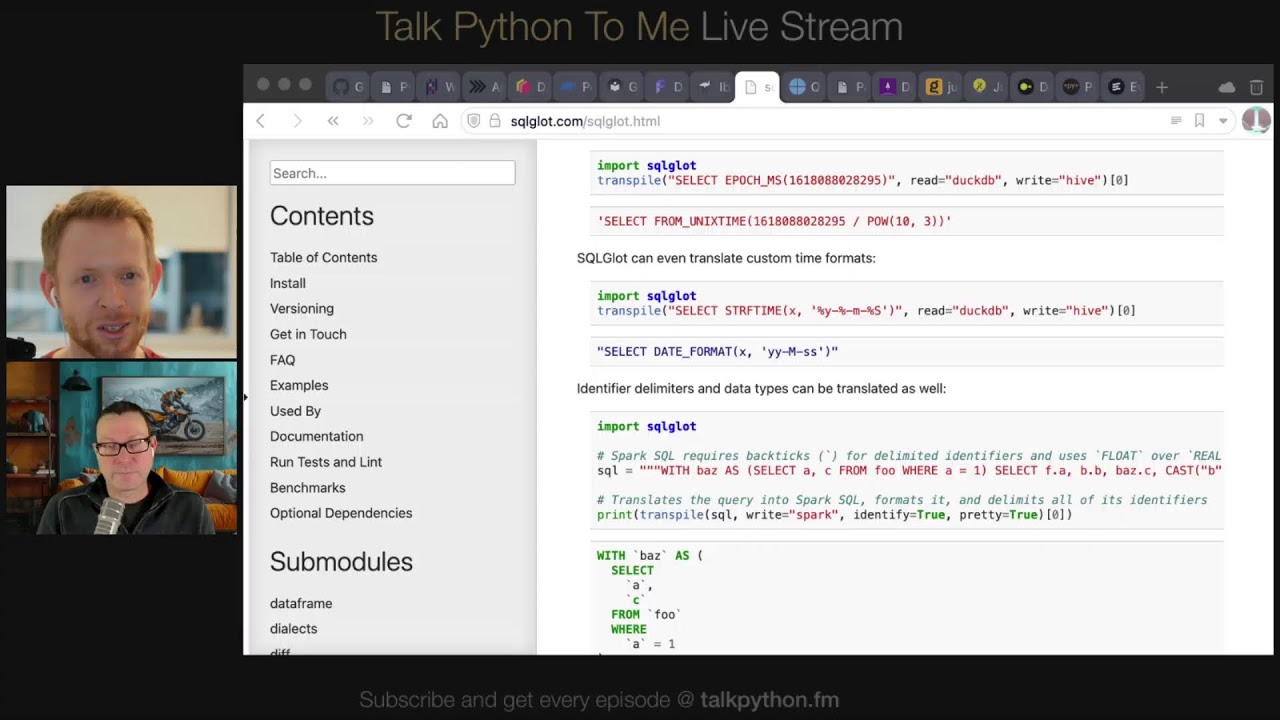
- SQLglot for Query Transpilation
SQLglot translates SQL queries across different database dialects—helpful if you’ve ever had to move queries from, say, Hive or Spark to DuckDB or ClickHouse. Ibis recently adopted SQLglot to handle SQL generation and dialect differences more seamlessly.
- Links / Tools:
- Rise of Polars and Rust-based Data Tools
Polars is a Rust-based dataframe library that’s Arrow-native under the hood, offering lazy execution and advanced optimizations. It’s a testament to the growing push for speed, parallelism, and more efficient data handling. This is a newer but notable addition to Python’s data stack.
- Links / Tools:
- Posit (formerly RStudio) and Shiny for Python
Although historically associated with R, Posit is increasingly investing in Python. Wes’s role there helps shape cross-language interoperability. Shiny for Python is a prominent example, focusing on a “reactive programming” model for building interactive dashboards without managing complex callback logic.
- Links / Tools:
- Big Data, Dask, and Parallel Python
While the episode didn’t go very deep on parallel Python frameworks, Wes touched on the importance of scaling computations beyond a single node. Tools like Dask can spread pandas-like workloads across CPU cores or clusters, supporting bigger-than-memory data processing.
- Links / Tools:
- WebAssembly & Browser-based Data Science A short but exciting point: projects like Pyodide and DuckDB compiled to WebAssembly open a future where Python and data workloads can run fully in the browser. This removes the need for specialized servers and can further simplify deploying interactive data applications.
Interesting Quotes and Stories
- Wes on unlocking capabilities for users: “One of the reasons I became passionate about Python was about giving people superpowers—making tasks easier so that you can focus on the interesting parts of your application.”
- On the mission of Posit: “It’s really refreshing to work with people who are truly mission focused and want to bring open-source data science tools to everyone, sustainably and for the long term.”
Key Definitions and Terms
- DataFrame: A tabular data structure, similar to a spreadsheet, commonly used in pandas and other libraries like polars.
- Vectorized Operations: Performing an operation on entire arrays or columns at once, rather than in Python-level loops.
- Columnar Format: A way of storing data column-by-column rather than row-by-row (e.g., Arrow, Parquet), usually more efficient for analytics.
- Transpilation: Converting code or queries from one form (or language) to another, e.g., from one SQL dialect to a different dialect.
Learning Resources
Here are some courses that align well with the topics covered:
- Move from Excel to Python with Pandas: Great for transitioning from spreadsheet-based workflows to Pythonic data analysis.
- Fundamentals of Dask: Excellent next step if you want to scale up your pandas-like operations across multiple cores or machines.
Overall Takeaway
This conversation with Wes McKinney highlights a broad ecosystem push toward simpler yet highly performant data workflows in Python. From the maturity and ubiquity of pandas to the high-speed innovations of Arrow, Ibis, and Rust-powered libraries, the Python data landscape continues to evolve rapidly. Underlying all these tools is a shared goal: making real-world data work more productive and accessible so developers can focus on the insights rather than the plumbing.
Links from the show
Pandas: pandas.pydata.org
Apache Arrow: arrow.apache.org
Ibis: ibis-project.org
Python for Data Analysis - Groupby Summary: wesmckinney.com/book
Polars: pola.rs
Dask: dask.org
Sqlglot: sqlglot.com
Pandoc: pandoc.org
Quarto: quarto.org
Evidence framework: evidence.dev
pyscript: pyscript.net
duckdb: duckdb.org
Jupyterlite: jupyter.org
Djangonauts: djangonaut.space
Watch this episode on YouTube: youtube.com
Episode #462 deep-dive: talkpython.fm/462
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 This episode dives into some of the most important data science libraries from the Python space
00:04 with one of its pioneers, Wes McKinney.
00:07 He's the creator or co-creator of the Pandas, Apache Arrow, and Evis projects,
00:12 as well as an entrepreneur in this space.
00:14 This is Talk Python To Me, episode 462, recorded April 11th, 2024.
00:21 Are you ready for your host?
00:23 You're listening to Michael Kennedy on Talk Python To Me.
00:27 Live from Portland, Oregon, and this segment was made with Python.
00:31 Welcome to Talk Python To Me, a weekly podcast on Python.
00:38 This is your host, Michael Kennedy.
00:39 Follow me on Mastodon, where I'm @mkennedy, and follow the podcast using @talkpython,
00:45 both on fosstodon.org.
00:47 Keep up with the show and listen to over seven years of past episodes at talkpython.fm.
00:52 We've started streaming most of our episodes live on YouTube.
00:56 Subscribe to our YouTube channel over at talkpython.fm/youtube to get notified about upcoming shows and be part of that episode.
01:03 This episode is sponsored by Neo4j.
01:07 It's time to stop asking relational databases to do more than they were made for and simplify complex data models with graphs.
01:14 Check out the sample FastAPI project and see what Neo4j, a native graph database, can do for you.
01:21 Find out more at talkpython.fm/Neo4j.
01:26 And it's brought to you by Mailtrap, an email delivery platform that developers love.
01:32 Try for free at mailtrap.io.
01:35 Hey, Wes.
01:36 Welcome to Talk Python To Me.
01:37 Thanks for having me.
01:38 You know, honestly, I feel like it's been a long time coming having you on the show.
01:42 You've had such a big impact in the Python space, especially the data science side of that space.
01:46 And it's high time to have you on the show.
01:48 So welcome.
01:49 Good to have you.
01:49 Yeah, it's great to be here.
01:51 I've had my been heads down a lot the last, you know, and last N years.
01:56 And, you know, I actually haven't been because I think a lot of my work has been more like data infrastructure and and work working at even a lower level than than Python.
02:05 So I haven't been I haven't been as engaging as much directly with the with the Python community.
02:10 But it's it's been great to kind of get back more involved and start catching up on all the things that people have been building.
02:16 And and being at Posit gives me the ability to, yeah, sort of have more exposure to what's going on and people that are using Python in the real world.
02:24 There's a ton of stuff going on at Posit that's super interesting.
02:27 And we'll talk about some of that.
02:28 And, you know, it's sometimes it's just really fun to build, you know, and work with people building things.
02:32 And I'm sure you're enjoying that aspect of it.
02:34 For sure.
02:35 Nice.
02:35 Well, before we dive into Pandas and all the things that you've been working on after that, you know, let's just hear a quick bit about yourself for folks who don't know you.
02:44 Sure. Yeah.
02:45 My name is Wes McKinney.
02:46 I grew up in Akron, Ohio, mostly.
02:49 And I got involved, started getting involved in Python development around 2007, 2008.
02:55 And built I was working in quant finance at the time.
02:58 I started building a personal data analysis toolkit that turned into the Pandas project.
03:03 And then open source that in 2009, started getting involved in the Python community.
03:08 And, you know, I spent several years like writing my book, Python for data analysis, and then working with the broader scientific Python, Python data science community to help enable Python to become a mainstream programming language for doing data analysis and data science.
03:23 In the meantime, I've become an entrepreneur.
03:26 I've started some companies and I've been working to innovate and improve the computing infrastructure that powers data science tools and libraries like Pandas.
03:38 So that's led to some other projects like Apache Arrow and Ibis and some other things.
03:43 Since recent years, I've been working on a startup, Voltron data, which is still very much going strong and has a big team and is off to the races.
03:54 And I've had a long relationship with Posit, formerly RStudio.
03:58 And they were, you know, my home for doing aero development from 2018 to 2020.
04:04 They helped me incubate the startup that became Voltron data.
04:08 And so I've gone back to work full time there as a software architect to help them with their Python strategy to make sort of their data science platform a delight to use for the Python user base.
04:21 I'm pretty impressed with what they're doing.
04:22 I didn't realize the connection between Voltron and Posit, but I have had Joe Chung on the show before to talk about Shiny for Python.
04:31 And I've seen him demo a few really interesting things, how it integrates to notebooks these days.
04:37 Some of the stuff that y'all are doing.
04:40 And yeah, it's just it's fascinating.
04:41 Maybe give people a quick elevator pitch on that while we're on that subject.
04:45 On Shiny or on Posit in general?
04:47 Yeah, whichever you feel like.
04:48 Yeah.
04:49 So Posit started out 2009 as RStudio.
04:54 And so it didn't start out intending to be a company.
04:57 JJ Lair and Joe Chang built a new IDE, Integrated Development Environment, for R, because what was available at the time wasn't great.
05:06 And so they made that into, you know, I think probably one of the best data science IDs that's ever been built.
05:11 It's really an amazing piece of tech.
05:13 So I started becoming a company with customers and revenue in the 2013 timeframe.
05:20 And they've built a whole suite of tools to support enterprise data science teams to make open source data science work in the real world.
05:26 But the company itself, it's a certified B Corporation, has no plans to go public or IPO.
05:31 It is dedicated to the mission of open source software for data science and technical communication and is basically building itself to be a hundred year company that has a revenue generating enterprise product side and an open source side so that we the open source feeds the kind of enterprise enterprise part of the business.
05:49 It's the enterprise part of the business generates revenue to support the open source development.
05:53 And the goal is to be able to sustainably support the mission of open source data science, you know, for, you know, hopefully the rest of our hopefully the rest of our lives.
06:01 And it's an amazing company.
06:02 It's been one of the most successful companies that dedicates a large fraction of its engineering time to open source software development.
06:09 So it's very impressed with the company and, you know, JJ Lair, its founder.
06:13 And, you know, I'm excited to be, you know, helping it, helping it grow and, and become a sustainable long-term fixture in the, in the ecosystem.
06:22 Yes.
06:23 Yeah.
06:23 It's definitely doing cool stuff.
06:25 Incentives are aligned well, right?
06:27 It's not private equity or IPO.
06:29 Yeah.
06:30 Many people know JJ Lair created cold fusion, which is like the original dynamic web development framework in the 1990s.
06:39 And so, so he and his brother, he and his brother, Jeremy and some others built a layer corp to commercialize cold fusion.
06:45 And they built a successful software business that was acquired by macro media, which was eventually acquired by Adobe.
06:51 But they did go public as a layer corp.
06:54 And during the.com bubble, then JJ went on to found a couple of other successful startups.
06:58 And so he found himself in his late thirties in the 15 years ago or around, around age 40 is around, around the age I am now having been very successful as an entrepreneur, like no need to, to make money and looking for like a mission to spend the rest of his career on.
07:14 And that identifying data science and statistical computing as an open source in particular, like making open source for data science work, you know, was the mission that he aligned with and something that he had been interested in earlier in his career, but he had gotten busy with other things.
07:30 So it's really refreshing to work with people who are really mission focused and focused on making impact in the world, creating great software, empowering people, increasing accessibility and making most of it available for free on the internet and not being so focused on empire building and producing great profits for venture investors and things like that.
07:50 So I think, yeah, I think the, I think the goal of the company and, is to, you know, provide like a, you know, an amazing home for top tier software developers to work on this software, to, you know, spend their careers and to, to build families and, to be a happy, happy and healthy culture for working on this type of software.
08:08 That sounds excellent.
08:09 Very cool.
08:09 I didn't realize the history all the way back to cold fusion.
08:11 Speaking of history, let's jump in.
08:14 There's a, Wes, there's a possibility that people out there listening don't know what pandas is.
08:19 You would think it's pretty ubiquitous.
08:21 And I certainly would say that it is, especially in the data science space, but I got a bunch of listeners who listen and they say really surprising things.
08:29 They'll say stuff to me like, Michael, I've been listening for six weeks now and I'm starting to understand some of the stuff y'all are talking about.
08:36 I'm like, why did you list for six weeks?
08:37 You didn't know what I was talking about.
08:39 Like, that's crazy.
08:40 And a lot of people use it as like language immersion to get into the Python space.
08:45 So I'm sure there's plenty of people out there who are, you know, immersing themselves, but are pretty new.
08:49 So maybe for that crew, we could introduce what pandas is to them.
08:53 Absolutely.
08:53 It's a data manipulation and analysis toolkit for Python.
08:59 So it's a Python library that you install that enables you to read data files.
09:03 So read many different types of data files off of disk or off of remote storage or read data out of a database or some other remote data storage system.
09:12 This is tabular data.
09:14 So it's structured data like with columns.
09:16 You can think of it like a spreadsheet or some other tabular data set.
09:20 And then it provides you with this data frame object, which is kind of pandas dot data frame.
09:26 That is the main tabular data object.
09:29 And it has a ton of methods for accessing, slicing, grabbing subsets of the data, applying functions on it that do filtering and subsetting and selection, as well as like more analytical operations, like things that you might do with a database system or SQL.
09:46 So joins and lookups, as well as analytical functions, like summary statistics, you know, grouping by some key and producing summary statistics.
09:56 So it's basically a Swiss army knife for doing data manipulation, data cleaning and supporting the data analysis workflow.
10:05 But it doesn't actually include very much as far as actual statistics or models or, you know, if you're doing something with LLMs or linear regression or some type of machine learning, you have to use another library.
10:17 But pandas is the on ramp for all of the data into your environment in Python.
10:22 So when people are building some kind of application that touches data in Python, pandas is often like the initial like on ramp for how data gets into Python, where you clean up the data, you regularize, regularize it, you get it ready for analysis, and then you feed the clean data into the downstream, you know, statistical library or data analysis library that you're using.
10:45 That whole data wrinkling side of things, right?
10:48 Yeah, that's right.
10:49 That's right.
10:50 And so, you know, in some history, Python had arrays, like matrices and what we call tensors now, multidimensional arrays going back all the way to 1995, which is pretty, pretty early history for, for Python, like the Python programming language has only been around since like 1990 or 1991, if my memory serves.
11:10 But the numpy, what became numpy in 2005, 2006 started out as numeric in 1995.
11:17 And it provided numerical computing, multidimensional arrays, matrices, the kind of stuff that you might do might do in MATLAB.
11:24 But it was mainly focused on numerical computing, and not with the type of business data sets that you find in database systems, which contain a lot of strings or dates or non numeric data.
11:35 And so my initial interest was I found Python to be a really productive programming language, I really liked writing code in it, writing simple scripts, like, you know, doing random things, you know, for my for my job.
11:47 But then you had this numerical computing library, NumPy, which enabled you to work with large numeric arrays and large, you know, data sets with a single data type.
11:56 But working with this more tabular type data stuff that you would do in Excel or stuff that you do in a database, it wasn't very easy to do that with with NumPy or it wasn't really designed for that.
12:06 And so that's what led to building this like higher level library that deals with these tabular data sets in the pandas library, which was originally focused on, you know, building really with a really close relationship with NumPy.
12:19 So pandas itself was like a thin layer on top of NumPy originally.
12:23 This portion of Talk Python To Me is brought to you by Neo4j.
12:26 I have told you about Neo4j, the native graph database on previous ad spots.
12:31 This time, I want to tell you about their relatively new podcast, Graph Stuff.
12:36 If you care about graph databases and modeling with graphs, you should definitely give it a listen.
12:41 On their season finale last year, they talked about the intersection of LLMs and knowledge graphs.
12:47 Remember when ChatGPT launched?
12:49 It felt like the LLM was a magical tool out of the toolbox.
12:53 However, the more you use it, the more you realize that's not the case.
12:57 The technology is brilliant, but it's prone to issues such as hallucinations.
13:01 But there's hope.
13:03 If you feed the LLM reliable current data, grounded in the right data and context, then it can make the right connections and give the right answers.
13:12 On the episode, the team at Neo4j explores how to get the results by pairing LLMs with knowledge graphs and vector search.
13:20 Check out their podcast episode on Graph Stuff.
13:23 They share tips for retrieval methods, prompt engineering, and more.
13:27 So just visit talkpython.fm/neo4j dash graph stuff to listen to an episode.
13:34 That's talkpython.fm/neo4j dash graph stuff.
13:39 The link is in your podcast player's show notes.
13:41 Thank you to Neo4j for supporting Talk Python To Me.
13:46 One thing I find interesting about pandas is it's almost its own programming environment these days in the sense that, you know, traditional Python, we do a lot of loops.
13:58 We do a lot of attribute dereferencing, function calling.
14:02 And a lot of what happens in pandas is more functional.
14:06 It's more applied to us.
14:09 It's almost like set operations, right?
14:11 Yeah, lots of vector operations and so on.
14:14 Yeah, that was behavior that was inherited from NumPy.
14:16 So NumPy is very array-oriented, vector-oriented.
14:20 So you, rather than write a for loop, you would write an array expression, which would operate on whole batches of data in a single function call, which is a lot faster because you can drop down into C code and get good performance that way.
14:36 And so pandas adopted the, you know, the NumPy way of like the NumPy-like array expression or vector operations.
14:43 But it's true that that's extended to the types of like non-numeric data operations that you can do in pandas, like, you know, vectorized set lookups where you can say like, you would say like, oh, like this, I have this array of strings and I have this subset of strings.
14:58 And I want to compute a Boolean array, which says whether or not each string is contained in this set of strings.
15:04 And so in pandas, that's the isin function.
15:06 So you would say like column A, like isin some set of substrings and that produces that single function call produces a whole Boolean array that you can use for subsetting later on.
15:17 Yeah, there's a ton of things that are really interesting in there.
15:20 One of the challenges, maybe you could speak to this a little bit, then I want to come back to your performance comment.
15:24 One of the challenges, I think, is that some of these operations are not super obvious that they exist or that they're discoverable, right?
15:32 Like instead of just indexing into, say, a column, you can index on an expression that might filter out the columns or project them or things like that.
15:40 How do you recommend people kind of discover a little bigger breadth of what they can do?
15:45 There's plenty of great books written about pandas.
15:48 So there's my book, Python for Data Analysis.
15:51 I think Matt Harrison has written an excellent book, Effective Pandas.
15:54 The pandas documentation, I think, provides really nitty gritty detail about how all the different things work.
16:01 But when I was writing this book, Python for Data Analysis, my goal was to provide a primer, like a tutorial on how to solve data problems with pandas.
16:11 And so for that, I had to introduce some basics of how NumPy works so people could understand array-oriented computing, basics of Python, so you know enough Python to be able to understand what things that pandas is doing.
16:25 It builds incrementally, and so like as you go through the book, the content gets more and more advanced.
16:30 It introduces, you learn, you master an initial set of techniques, and then you can start learning about more advanced techniques.
16:37 So it's definitely a pedagogical resource.
16:40 And it is now freely, as you're showing there on the screen, it is freely available on the internet.
16:45 So JJ Allaire helped me port the book to use Quarto, which is a new technical publishing system for writing books and blogs and website, you know, Quarto.org.
16:56 And yeah, so that's how I was able to publish my book on the internet, as, you know, essentially, you can use Quarto to write books using Jupyter Notebooks, which is cool.
17:06 My book was written a long time ago in O'Reilly's Docbook XML, so not particularly fun to edit.
17:11 But yeah, because Quarto is built on Pandoc, which is a sort of markup language transpilation system.
17:19 So you can use Pandoc to convert from one, you know, you can to convert documents from one format to another.
17:24 And so that's the kind of the root framework that Quarto is built on for, you know, generating, starting with one document format and generating many different types of output formats.
17:34 That's cool. I didn't realize your book was available just to read on the internet.
17:38 Yeah.
17:39 Navigate around.
17:40 In the third edition, I was able to negotiate with O'Reilly and add a, you know, add an append and make an amendment to my very old book contract from 2011 to let me release the book for free on my website.
17:54 So it's, yeah, it's just available there at westmckinney.com slash book.
17:58 I find that like a lot of people really like the print book.
18:02 And so I think that having the online book just available, like whenever you are somewhere and you want to look something up is great.
18:08 Print books are hard to search.
18:09 Yeah, that's true. That's true. Yeah.
18:11 And like, if you go to the search bar and if you go back to the book and just look at the search bar, you know, look at just search for like group by like, you know, all one word or, you know, yeah, it's like it comes up really fast.
18:21 You can go to that section and it's pretty cool.
18:25 I thought that releasing the book for free online would would affect sales, but no, people just really like having paper books.
18:31 It seems even in 2024.
18:32 Yeah. Even digital books are nice. You got them with you all the time.
18:36 You can I think it's about taking the notes.
18:37 Where do I put my highlights and how do I remember it?
18:40 And that's right.
18:41 Yeah. Yeah. Stuff like that.
18:42 This quarter thing looks super interesting.
18:45 If you look at Pandoc, if people haven't looked at this before, the conversion matrix, I don't know how you would, how would you describe this, Wes?
18:55 Busy? Complete? What is this? This is crazy.
18:58 It's very busy. Yeah.
18:59 It can convert from looks like about, you know, 30 or 40 input formats to, you know, 50 or 60 output formats, maybe, maybe more than that.
19:09 Kind of like just my just eyeballing it. But yeah, it's like a pretty, pretty impressive.
19:12 And then if you took the combinatorial of like how many different ways could you combine the 30 to the 50?
19:17 It's kind of what it looks like. It's right.
19:19 It's truly amazing. So if you've got Markdown, you want to turn it into a PDF or you've got a, a Doku wiki and you want to turn it into an EPUB or whatever.
19:28 Right. Or even like reveal JS probably to PowerPoint, I would imagine. I don't know.
19:34 Yeah.
19:34 Yeah.
19:34 As history, like backstory about, about Quarto.
19:38 So, you know, it helps to keep in mind that, that JJ created ColdFusion, which was this, you know, essentially publishing system, early publishing system for the internet, similar to CGI and, and PHP and, and other dynamic web publishing systems.
19:53 And so at early on at RStudio, they created R Markdown, which is a, basically a extensions to Markdown that allow you to have code cells written in, in R. And then eventually they added support for some other languages where it's kind of like a Jupyter notebook in the sense that you could have some Markdown and some code and some plots and output.
20:13 And you would run the R Markdown renderer and it would, it would, it would, you know, generate all the output and insert it into the document.
20:20 And so you could use that to write blogs and websites and everything.
20:24 But, but R Markdown was written in R. And so that limited, in a sense, like it made it harder to install because you would have to install R to use it.
20:32 And also people, it had an association with R that perhaps was like, like unmerited.
20:37 And so in the meantime, you know, with, with all, all, everything that's happened with web technology, it's now very easy to put a complete JavaScript engine in a stall footprint, you know, on a machine with no dependencies and to be able to run a system that is, you know, written in a system that's written in JavaScript.
20:55 And so Quarto is completely language agnostic. It's written in TypeScript and it uses Pandoc as an, as an underlying engine.
21:02 And it's very easy to install. And so it addresses some of the portability and extensibility issues that were, that were present in R Markdown.
21:11 But, but as a result, you know, I think our, the Posit team had a lot of just has more than a, you know, a decade, or if you include ColdFusion, you know, more than 25 years of experience in, in building really developer friendly technical publishing tools.
21:25 And so I think that, that it's not data science, but it's something that is an important part of the data science workflow, which is how do you present your, make your analysis and your work available for consumption in different formats.
21:38 And so having this, this system that can, you know, publish outputs in, in many different places is, is super valuable.
21:45 So a lot of people start out in Jupyter notebooks, but, but there's many different, you know, many different possible input formats.
21:51 And so to be able to, you know, use the same source to publish to a website or to a Confluence page or to a PDF is like, yeah, it's super valuable.
21:59 Yeah. It's super interesting. Okay.
22:00 So then I got to explore some more. All right, let's go back to Pandas for a minute.
22:05 First, how about some kind words from the audience for you?
22:08 Ravid says, Wes, your work has changed my life. It's very, very nice.
22:12 I'm happy to hear it. But yeah, yeah, I'm more than happy to talk, let's talk in depth about Pandas.
22:17 And I think history of the project is, is interesting.
22:20 And I think also how the project has, has developed in the intervening 15, 16 years is, is pretty interesting as well.
22:28 Yeah. Let's talk derivatives for a minute.
22:30 So growth and speed of adoption and all those things.
22:33 When you first started working on this and you first put it out, did you foresee a world where this was so popular and so important?
22:41 Did you think of, yeah, pretty soon black holes. I'm pretty sure I'll be part of that somehow.
22:45 It was always the aspiration of making Python this mainstream language for statistical computing and data analysis.
22:54 Like I didn't, it didn't occur to me that it would become this popular or that it would become like the, one of the main tools that people use for working with data in a business, in a business setting.
23:05 Like that would have been, if that was the aspiration or if that was, you know, what I needed to achieve to be satisfied, that that would have been completely unreasonable.
23:13 And I also don't think that in a certain sense, like I don't know that, that it's popularity, it is deserved and it's not deserved.
23:19 Like I think there's, there's many other worthy efforts that have been created over the years that have been really great work that, that others have, have done in this, in this domain.
23:28 And so the fact that, that pandas caught on and became as popular as it is, I think it's a combination of timing.
23:34 And, you know, there was like a developer relations aspect that there was content available.
23:39 And like I wrote my book and that made it easier for people to learn how to use the project.
23:43 But also like we, we had a serendipitous open source developer community that, that came together that allowed the project to grow and expand like really rapidly in the early 2010s.
23:56 And I definitely spent a lot of work like recruiting people to work on the project and encouraging, you know, others to work on it.
24:03 Because sometimes people create open source projects and then it's hard for, hard for others to get involved and get a seat at the table, so to speak.
24:09 But I was very keen to bring on others and to give them responsibility and, you know, ultimately, you know, hand over the reins to the project to others.
24:19 And I've spoken a lot about that, you know, over the years, how important that is to, you know, for open source project creators to, to make room for others in, you know, steering and growing the project so that they can become owners of it as well.
24:32 It's tough to make space and tough to, to bring on folks.
24:35 Have you heard of the Djangonauts?
24:37 The Djangonauts, I think it's Djangonauts dot space.
24:40 They have an awesome domain, but it's basically like kind of like a bootcamp, but it's for taking people who just like Django and turn them into actually contributors or core contributors.
24:49 What's your onboarding story for people who do want to participate?
24:53 I'm embarrassed to say that I'm not, I don't have a comprehensive view of like all of the different, you know, community outreach channels that the Pandas project has done to help grow new contributors.
25:04 So one of the core team members, Mark Garcia has done an amazing job organizing documentation sprints and other like contributor sourcing events, essentially creating very friendly, accessible events where people who are interested in getting involved in Pandas can meet each other and then assist each other in making their first pull request.
25:27 And it could be something as simple as, you know, making a small improvement to the, to the Pandas documentation because it's such a large project.
25:34 The documentation is like, you know, either adding more, adding more examples or documenting things that aren't documented or making, yeah, just, just making the documentation better.
25:46 And so it's something that for new contributors is, is more accessible than working on the internals of like one of the algorithms or something.
25:54 And, and, or like we working on some significant performance improvement might be a bit intimidating if you've never worked on the Pandas code base.
26:02 And it's a pretty large code base because it's been, it's been worked on continuously for, you know, for like going on 20 years.
26:07 So it's, yeah, it can be, takes a while to really get to a place where you can be productive and that can be discouraging for new contributors, especially those who don't have a lot of open source experience.
26:19 That's one of the ironies of challenges of these big projects is they're just so finely polished.
26:24 So many people are using them.
26:26 Every edge case matters to somebody, right?
26:29 And so to become a contributor and make changes to that, it takes a while, I'm sure.
26:33 Yeah. Yeah.
26:34 I mean, I think it's definitely a big thing that helped is allowing people to get paid to work on Pandas or to be able to contribute to Pandas as, as a part of their job description.
26:46 Like as, you know, maybe part of their job is maintaining, maintaining Pandas.
26:50 So Anaconda, you know, was like, you know, one of the earliest companies who had engineers on staff, you know, like, you know, Brock Mendel, you know, Tom Augsberger, Jeff Reback, who part of their job was maintaining and developing, developing Pandas.
27:03 And that was, that was huge because prior to that, the project was purely based on volunteers.
27:08 Like I was a volunteer and everyone was working on the project as a, as a passion project in their, in their free time.
27:15 And then, Travis Oliphant, one of the founders, he and Peter Wang founded Anaconda.
27:20 Travis spun out from Anaconda to create Quonsight and has continued to sponsor development in and around Pandas.
27:26 And that's enabled people like Mark to do these community building events and, and for it to not be, you know, something that's, you know, totally uncompensated.
27:35 Yeah, that's a lot of, a lot of stuff going on.
27:37 And I think the commercial interest is awesome, right?
27:40 I mean, if there's just a different level of problems, I feel like we could take on, you know, you know what, I got this entire week and someone, that's my job is to make this work rather than I've, I've got two hours and can't really take on a huge project.
27:53 And so I'll work on the smaller improvements or whatever.
27:56 Yeah.
27:56 Many people know, but I haven't been involved day to day in Pandas since 2013.
28:01 So that's, that's getting on.
28:02 That's a lot of years.
28:03 You know, I still talk to the Pandas contributors.
28:05 we had a, we had a Pandas meetup core, core developer meetup here in Nashville pre COVID.
28:10 I think it was in 2019 maybe.
28:12 So, you know, I'm still in active contact with the Pandas developers, but, it's been a different team of people leading the project.
28:20 It's taken on a life of its own, which is, which is amazing.
28:22 That's exactly.
28:23 Yeah.
28:24 As a project creator, that's exactly what you want is to not be beholden to the project that you created and forced and, you know, kind of.
28:31 Have to be, be responsible for it and take care of it for the rest of your life.
28:35 But if you look at like a lot of the community, a lot of the most kind of intensive community development has happened since, like, since I moved on to work on, on other projects.
28:43 And so now the project is, I don't know the exact count, but it's had thousands of contributors.
28:48 And so, you know, to have thousands of different unique individuals contributing to an open source project is, it's a big deal.
28:55 So I think even, I don't know what it says on the bottom of, on the bottom of GitHub, it says, you know, 30,
29:01 30, 200 contributors, but that's maybe not even the full story because sometimes, you know, people, they don't have their email address associated with their GitHub profile and, you know, how GitHub counts contributors.
29:12 You know, I would say probably the true number is closer to 4,000.
29:15 That's a testament, you know, to the, to the core team and all the outreach that they've done and work making, making the project accessible and easy to contribute to.
29:25 Because if people, if you go and try to make a pull request to a project and there's many different ways that, that you can fail.
29:31 So like either the project is technically like there's issues with the build system or the developer tooling.
29:38 And so you struggle with the developer tooling.
29:40 And so if you aren't working on it every day and every night, you can't make heads or tails of how the developer tools work.
29:45 But then there's also like the level of accessibility of the core development team.
29:50 Like if they don't, if they aren't there to support you in getting involved in the project and learning how it works and creating documentation about how to contribute and what's expected of you, that can also be, you know, a source of frustration where people churn out of the project, you know, because it's just, it's too hard to find their sea legs.
30:08 And maybe also, you know, sometimes development teams are unfriendly or unhelpful or, you know, they make, they make others feel like they make others feel like they're annoyed with them or like they're wasting their time or something.
30:20 It's like, I don't want to look at your, you know, this pull request and give you feedback because, you know, I could do it more quickly by myself or something.
30:27 Like sometimes you see that at open source projects.
30:29 Yeah.
30:30 But they've created a very welcoming environment.
30:32 And yeah, I think the contribution numbers speak for themselves.
30:37 They definitely do.
30:38 Maybe the last thing before we move on to the other stuff you're working on, but the other interesting GitHub statistic here is the used by 1.6 million projects.
30:47 That's, I don't know if I've ever seen it used by that high.
30:50 There's probably some that are higher, but not many.
30:52 Yeah.
30:52 It's a lot of projects.
30:53 I think it's, it's interesting.
30:55 I think like many projects, it's reached a point where it's, it's an essential and assumed part of the, of many people's toolkit.
31:02 Like they, like the first thing that they write at the top of a file that they're working on is important.
31:07 Import pandas as PD or import numpy as PD, you know, to create, I think in a sense, like, I think one of the reasons why, you know, pandas has gotten so popular is that it is beneficial to the community, to the Python community to have fewer solutions.
31:20 Kind of the zen of Python.
31:21 There should be one and preferably only one obvious, obvious way to do things.
31:26 And so if there were 10 different pandas like projects, you know, that creates skill portability problems.
31:32 And it's just easier if everyone says, oh, we just pandas is the thing that we use and you change jobs and you can take all your skills, like how to use pandas with you.
31:41 And I think that's also one of the reasons why Python has become so successful in the business world is because you can teach somebody even without a lot of programming experience, how to use Python, how to use pandas and become productive doing basic work very, very quickly.
31:56 And so one of the solutions I remember back in the early 2010s, there were a lot of articles and talks about how to address the data science shortage.
32:06 And my belief and I gave a I gave a I gave a talk at Web Summit in Dublin in 2000.
32:12 Gosh, maybe 2017, 2000.
32:16 I have to look exactly.
32:17 But basically, it was the data scientist shortage.
32:20 And my thesis was always it's we should make it easier to be a data scientist or like lower the bar for like what sort of skills you have to master before you can you can do productive work in a business setting.
32:32 And so I think the fact that that there is just pandas and that's like the one thing that people have to have to learn how to how to use is like their essential like starting point for doing any data work has also led to this piling on of like people being motivated to make this one thing better because it you know, you make improvements to pandas and they benefit millions of projects and millions of people around the world.
32:53 And that's yeah.
32:54 So it's like a, you know, steady snowballing effect.
32:58 This portion of Talk Python To Me is brought to you by Mailtrap, an email delivery platform that developers love.
33:05 An email sending solution with industry best analytics, SMTP and email API SDKs for major programming languages and 24 seven human support.
33:17 Try for free at mailtrap.io.
33:22 I think doing data science is getting easier.
33:24 We've got a lot of interesting frameworks and tools.
33:27 Yeah.
33:27 For Python, one of them, right?
33:29 That makes it easier to share and run, run your code, you know?
33:33 Yeah.
33:33 Shiny, Shiny for Python, Streamlit, you know, Dash, like these different interactive data application publishing frameworks.
33:39 So you can go from, you know, a few lines of pandas code, loading some data and doing some analysis and visualization to publishing that as an interactive website without having to know how to use any web development frameworks or Node.js or anything like that.
33:55 And so to be able to, you know, get up and running and build a working, you know, interactive web application that's powered by Python is, yeah, it's a game changer in terms of, you know, shortening end-to-end development life cycles.
34:08 What do you think about JupyterLite and these PyOxidide and basically Jupyter, Jupyter in a browser type of things?
34:18 Yeah.
34:18 WebAssembly and all that?
34:19 Yeah.
34:20 So definitely very excited about it.
34:22 I've been following WebAssembly in general.
34:24 And so I guess some people listening will know about WebAssembly, but basically it's a portable machine code that can be compiled and executed within your browser in a sandbox environment.
34:35 So it protects against security issues and allows, prevents, like the person who wrote the WebAssembly code from doing something malicious on your machine, which is very important.
34:45 Won't necessarily stop them from like, you know, mining cryptocurrency while you have the browser tab open.
34:50 That's a whole separate problem.
34:51 But it's enabled us to, you know, run the whole scientific Python stack, including Jupyter and NumPy and Pandas totally in the browser without, you know, having a client and server and needing to, you know, run a container someplace in the cloud.
35:05 And so I think in terms of creating application deployment, so like being able to deploy an interactive data application, like with Shiny, for example, without needing to have a server, that's actually pretty amazing.
35:17 And so I think that, you know, simplifies, opens up new use cases, like new application architectures and makes things a lot easier for, because setting up and running a server creates brittleness, like it has cost.
35:29 And so if the browser is doubling as your server process, like that's, I think that's really cool.
35:35 You also have like other projects like DuckDB, which is a high performance, embeddable analytic SQL engine.
35:43 And so, you know, now with DuckDB compiled to WASM, you can get a, you know, high performance database running in your browser.
35:49 And so you can get low latency interactive queries and interactive dashboards.
35:54 And so it's, yeah, there's, WebAssembly has opened up this whole kind of new world of possibilities.
36:01 And it's transformative, I think.
36:03 For Python in particular, you mentioned Pyodide, which is kind of a whole package stack.
36:08 So it's like a framework for build and build and packaging and, you know, basically building an application and managing its dependencies.
36:16 So you could create a WebAssembly version of your application to be deployed like this.
36:21 But yeah, so I think one of the Pyodide, either the Pyodide main creator or maintainer went to Anaconda.
36:26 They created PyScript, which made, which is another attempt to make it even easier to use Python to, to make it even easier to use Python to create web applications, interactive web applications.
36:37 There's so many cool things here.
36:38 Like in the R community, they have WebR, which is, you know, similar to PyScript and Pyodide in some ways, like compiling the whole R stack to WebAssembly.
36:46 There was just an article I saw on Hacker News where they worked on, you know, figuring out how to get, how to trick LLVM into compiling Fortran code, like legacy Fortran code to WebAssembly.
36:56 Because when you're talking about all of this scientific computing stack, you need the linear algebra and all of the 40 years of Fortran code that have been built to support scientific applications.
37:05 Like you need all that to compile to and run in the browser.
37:08 So yeah, that's pretty wild to think of putting that in there, but very useful.
37:11 I didn't realize that you could use DuckDB as a WebAssembly component.
37:16 That's pretty cool.
37:17 Yeah, there's a company, I'm not an investor or plugging them or anything, but it's called evidence.dev.
37:22 It's like a whole like business intelligence, open source business intelligence application that's powered by, powered by DuckDB.
37:29 And so if you have data that fits in the browser, you know, to have a whole like interactive dashboard or be able to do business intelligence, like fully, like fully in the browser with no need of a, no need of a server.
37:41 It's, yeah, it's, it's very, very cool.
37:43 So I've been following DuckDB since the, you know, since the early days and, you know, my company Voltron Data, like we became members of the DuckDB Foundation and build, actively build a relationship with, with DuckDB Labs.
37:56 So we could help accelerate progress in this space because I think the impact, the impact is so, is so immense.
38:04 And we just, it's hard to predict like what, you know, what people are going to build, build with all this stuff.
38:09 Yeah.
38:09 And so that was all, you know, with, I guess, going back, you know, 15 years ago to Python, like one of the reasons I became so passionate about building stuff for Python was about in, I think the way that Peter Wang puts that, it puts it as, you know, giving people superpowers.
38:24 So we want to enable people to build things with much less code and much less time.
38:29 And so by making it things that much more accessible, that much easier to do, like the mantra in Pandas was like, how do we make things one line of code or like this, that must be easy.
38:39 It's like one line of code, one line of code.
38:41 It must be like, like make this as terse and simple and easy to do as possible so that you can move on and focus on building the more interesting parts of your application rather than struggling with how to read a CSV file or, you know, how to do whichever data munging technique that you need for your, for your data set.
38:58 Maybe an interesting mental model for DuckDB is kind of an equivalent to SQLite, but more analytics database for folks, you know, in process and that kind of things, right?
39:07 What do you think?
39:07 Yeah.
39:07 So yeah, DuckDB is like SQLite.
39:10 And in fact, it can run the whole SQLite test suite, I believe.
39:13 So it's a full database, but it's for analytic processing.
39:17 So it's optimized for analytic processing.
39:19 And as compared, you know, with SQLite, which is not for data processing.
39:23 Yeah.
39:23 Cool.
39:24 All right.
39:24 Well, let's talk about some things that you're working on beyond Pandas.
39:29 You talked about Apache Arrow earlier.
39:31 What are you doing with Arrow and how's it fit in your world?
39:34 The backstory there was, I don't know if you can hear the sirens in downtown Nashville, but...
39:39 No, actually, it's...
39:40 It's good.
39:41 It's filled.
39:41 The microphone filters it out, filters it out pretty well.
39:43 Yay for dynamic microphones.
39:46 They're amazing.
39:46 Yeah.
39:47 So in like around the mid, like the mid 2010s, 2015, I started working at Cloudera, like in
39:53 the...
39:54 Which is a company that was like one of the pioneers in the big data ecosystem.
39:57 And I had been spent several years working on five, five years, five, six years working on
40:03 Pandas.
40:04 And so I had gone through the experience of building Pandas from top to bottom.
40:08 And it was this full stack system that had its own, you know, mini query engine, all of
40:15 its own algorithms and data structures and all the stuff that we had to build from scratch.
40:19 And I started thinking about, you know, what if it was possible to build some of the underlying
40:24 computing technology, like data readers, like file readers, all the algorithms that power
40:30 the core components of Pandas, like group operations, aggregations, filtering, selection, all those
40:37 things.
40:38 Like what if it were possible to have a general purpose library that isn't specific to Python,
40:43 isn't specific to Pandas, but is really, really fast, really efficient.
40:46 It has a large community building, building it so that you could take that code with you
40:51 and use it to build many different types of libraries, not just data frame libraries, but
40:55 also database engines and stream processing engines and all kinds of things.
41:00 That was kind of what was in my mind when I started getting interested in what turned into
41:04 Arrow.
41:05 And one of the problems we realized we needed to solve, this was like a group of other open
41:10 source developers and me, was that we needed to create a way to represent data that was not
41:16 tied to a specific programming language.
41:18 And that could be used for a very efficient interchange between components.
41:23 And the idea is that you would have this immutable, this kind of constant data structure, which is
41:29 like it's the same in every programming language.
41:31 And then you can use that as the basis for writing all of your algorithms.
41:35 So as long as it's Arrow, you have these reusable algorithms that process Arrow data.
41:40 So we started with building the Arrow format and standardizing it.
41:44 And then we've built a whole ecosystem of components like library components and different programming
41:50 languages for building applications that use the Arrow format.
41:54 So that includes not only tools for building and interacting with the data, but also file
42:00 readers.
42:00 So you can read CSV files and JSON data and Parquet files, read data out of database systems.
42:07 Wherever the data comes from, we want to have an efficient way to get it into the Arrow format.
42:11 And then we moved on to building data processing engines that are native to the Arrow format so
42:18 that Arrow goes in, the data is processed, Arrow goes out.
42:21 So DuckDB, for example, supports Arrow as a preferred input format.
42:26 And DuckDB is more or less Arrow-like in its internals.
42:30 It has kind of Arrow format plus a number of extensions that are DuckDB specific for better
42:36 performance within the context of DuckDB.
42:39 So in numerous communities, so there's the Rust community, which has built Data Fusion, which
42:44 is an execution engine for Arrow, SQL engine for Arrow.
42:47 And so, yeah, we've kind of like looked at the different layers of the stack, like data
42:51 access, computing, data transport, everything under the sun.
42:55 And then we've built libraries that are across many different programming languages so that
42:59 are, you can pick and choose the pieces that you need to build your system.
43:02 And the goal ultimately was that we, in the future, which is now, we don't want people to
43:08 have to reinvent the wheel whenever they're building something like Pandas, that they could just
43:12 pick up these off-the-shelf components.
43:13 They can design the developer experience, the user experience that they want to create,
43:18 and they can get built.
43:20 You know, so if you were building Pandas now, you could build a Pandas-like library based on
43:25 the Arrow components in much less time.
43:27 And it would be fast and efficient and interoperable with the whole ecosystem of other projects that
43:32 use Arrow.
43:33 It's very cool.
43:34 It's, I mean, it was really ambitious in some ways, obvious to people.
43:38 They would hear about Arrow and they say, that sounds obvious.
43:40 Like, clearly we should have a universal way of transporting data between systems and processing
43:46 it in memory.
43:47 Why hasn't this been done in the past?
43:49 And it turns out that, as is true with many open source software problems, that many of these
43:54 problems are, the social problems are harder than the technical problems.
43:58 And so if you can solve the people coordination and consensus problems, solving the technical
44:03 issues is much, much easier by comparison.
44:05 So I think we were lucky in that we found like the right group of people, the right personalities
44:11 where we were able to, as soon as I met, I met Jacques Nadeau, who had been at MapR and
44:16 we was working on his startup, Dremio.
44:19 Like I knew instantly when I met Jacques Nadeau, I was like, I can work.
44:22 He's like, it's like him.
44:23 Like, he's going to help me make this happen.
44:25 And when I met Julien Ledem, who had also co-created Parquet, I was like, yes, like we are
44:31 going to make, like, I found the right people.
44:32 Like we are, we are going to make this happen.
44:34 It's been a labor of love and much, much work and stress and everything.
44:38 But I've been working on things circling, you know, with Arrow as the sun, you know, I've
44:43 been building kind of satellites and moons and planets circling the Arrow sun over the last
44:48 eight years or so.
44:49 And that's kept me pretty busy.
44:50 Yeah.
44:50 It's only getting more exciting and interesting.
44:52 Over here, it says it uses efficient analytic operations on modern hardware like CPUs and
44:59 GPUs.
44:59 One of the big challenges of Python has been the GIL.
45:03 Also one of its big benefits, but one of its challenges when you get to multi-core computational
45:08 stuff has been the GIL.
45:09 What's the story here?
45:10 Yeah.
45:10 So in Arrowland, when we're talking about analytic efficiency, it mainly has to do with the underlying,
45:18 like how the, how a modern CPU works or how a GPU works.
45:24 And so when the data is arranged in column oriented format that enables the data to be
45:30 moved efficiently through the CPU cache pipelines.
45:34 So the data is made, made available efficiently to the, to the CPU cores.
45:39 And so we spent a lot of energy in Arrow making decisions firstly to enable very cache of like
45:45 CPU cache or GPU cache efficient analytics on the data.
45:49 So we were kind of always, when we were deciding we would break ties and make decisions based
45:53 on like what's going to be more efficient for the, for the computer chip.
45:56 The other thing is that modern, and this is true with GPUs, which have a different parallelism
46:02 model than, or different kind of multi-core parallelism model than CPUs.
46:08 But in CPUs, they've focused on adding what are called single instruction, multiple data intrinsic,
46:14 like a built-in operations in the processor where, you know, now you can process up to 512
46:21 bytes of data in a single CPU instruction.
46:24 And so that's like, my brain's doing the math, right?
46:28 Like 16 32-bit floats or, you know, eight 64-bit integers in a single CPU cycle.
46:34 There's like intrinsic operations.
46:35 So multiply this number by that one, multiply that number to these eight things all at once,
46:41 something like that.
46:41 That's right.
46:42 Yeah.
46:42 Or you might say like, oh, I have a bit mask and I want to select, I want to gather
46:47 like the one bits that are set in this bit mask from this array of integers.
46:52 And so there's like a gather instruction, which allows you to select a subset sort of SIMD vector
46:59 of integers, you know, using a bit mask.
47:01 And so that turns out to be like a pretty critical operation in certain data analytic workloads.
47:05 So yeah, we were really, we wanted to have a data format that was essentially, you know,
47:10 future-proofed in the sense that it's, it's ideal for the coming wave, like current, current
47:16 generation of CPUs, but also given that a lot of processing is moving to GPUs and to FPGAs
47:22 and, and to custom silicon, like we wanted Arrow to be usable there as well.
47:27 And it's, Arrow has been successfully, you know, used as the foundation of GPU computing libraries.
47:33 Like we kind of at Voltron Data, we built, we've built a whole accelerator native GPU native,
47:39 you know, scalable execution engine that's, that's Arrow based.
47:42 And so I think the fact that we, that was our aspiration and we've been able to prove that out
47:46 in, in real world workloads and show the kinds of efficiency gains that you can get with using
47:51 modern computing hardware correctly, or at least as well as it's intended to be used.
47:56 That's a big deal in terms of like making applications faster, reducing the carbon footprint of large scale data workloads, things like that.
48:04 Yeah. Amazing. All right. Let's see. What else have I got on deck here to talk
48:07 to you about? You want to talk IBIS or which one do you want to, we got a little time left. We got
48:11 a couple of things to cover.
48:13 Yeah. Let's, we can talk about IBIS. Yeah. We could, we could probably spend another hour talking.
48:17 Yes. Easy.
48:18 I think one of the more interesting areas in recent years has been new data frame libraries
48:23 and data frame APIs that transpile or compile to different execute on different backends. And so
48:30 around the time that I was helping start Arrow, I created this project called IBIS, which is basically
48:35 a portable data frame API that knows how to generate SQL queries and compile to pandas and polars and
48:43 different data frame, data frame backends. And the goal is to provide a really productive data frame
48:50 API that gives you portability across different execution backends with the goal of enabling what
48:56 we call the multi-engine data stack. So you aren't stuck with using one particular system because all of
49:02 the code that you've written is specialized to that system. You have this tool, which,
49:06 so maybe you could work with, you know, DuckDB on your laptop or pandas or polars with IBIS on your
49:12 laptop. But if you have, if you need to run that workload someplace else, maybe with, you know,
49:17 ClickHouse or BigQuery, or maybe it's a large big data workload that's too big to fit on your laptop
49:22 and you need to use Spark SQL or something that you can just ask IBIS, say, Hey, I want to do the same
49:28 thing on this larger data set over here. And it has all the logic to generate the correct query
49:34 representation and run that workload for you. So it's super useful, but there's a whole wave of like,
49:38 you know, work right now to help enable people to work in a pandas like way, but get work with big
49:44 data or, you know, get better performance than pandas because pandas is a Swiss army knife, but is,
49:50 isn't a chainsaw. So it, if you were rebuilding pandas from scratch, it would end up a lot.
49:55 There's areas of the project that are more bloated or have performance overhead. That's hard to get
50:00 rid of. And so that's why you have Richie Fink started the Polars project, which is kind of a
50:05 re-imagining of, of pandas, pandas dataframes written in Rust and exposed in Python. And Polars,
50:12 of course, is built on Apache Arrow at its core. So building an Arrow native dataframe library in Rust and,
50:18 you know, all the benefits that come with building Python extensions in Rust, you know,
50:23 you avoid the GIL and you can manage the multi-threading in a systems language, all that,
50:27 all that fun stuff.
50:28 Yeah. When you're talking about Arrow and supporting different ways of using it and things being built
50:32 on it, it's certainly Polars came to mind for me. You know, when you talk about IBIS, I think it's
50:36 interesting that a lot of these dataframe libraries, they try to base their API to be
50:43 pandas-like, but not identical potentially, you know, thinking of Dask and others.
50:48 But this IBIS sort of has the ability to configure it and extend it and make it different,
50:54 kind of like, for example, Dask, which is one of the backends here.
50:57 Yeah.
50:57 But the API doesn't change, right? It just, it talks to the different backends.
51:01 Yeah. There's different schools of thought on this. So there's another project called Moden,
51:05 which is similar to IBIS in many ways in the sense of like transpilation and sort of dynamically
51:10 supporting different backends, but sought to closely emulate exact details of like the API call,
51:17 the function name, the function arguments must be exactly the same as pandas to with the goal of
51:23 being a drop-in replacement for people's pandas code. And that's one approach, kind of the pandas
51:28 emulation route. And there's a library called Koalas for Spark, which is like a PySpark
51:33 emulation layer for the pandas API. And then there's other projects like Polars and IBIS,
51:38 Das DataFrame that take like design cues from pandas in the sense of like the general way in
51:45 which the API works, but has made meaningful departures in the interest of doing things
51:50 better in many ways than pandas did in certain parts of the API and making things simpler and not
51:56 being beholden to decisions that were made in pandas, you know, 15 years ago.
52:00 Not to say there's anything bad about the pandas API, but like with any API, it's large,
52:04 like it's, it's very large as evidenced by, you know, the 2000 page pages of documentation.
52:09 And so I understand the desire to make things simpler while also refining certain things,
52:14 making certain types of workloads easier to easier to express. And so Polars, for example,
52:19 is very expression based. And so everything is column expressions and is lazy and not eagerly
52:25 computed. Whereas pandas is eager execution, just like NumPy is, which is how pandas became eagerly
52:32 executed in the first place. And so I think the mantra with Polars was we don't want to support the
52:39 eager execution by default that pandas provides. We want to be able to build expressions so that we can
52:44 do query optimization and take inefficient code and under the hood, rewrite it to be more efficient,
52:50 which is, you know, what you can do with a query optimizer.
52:52 And so ultimately like that matters a lot when you're executing code remotely or in like a big
52:58 data system, you want to have the freedom to be able to take like a lazy analytic expression and
53:04 rewrite it based on, it might be like, you need to seriously rewrite the expression in the case of
53:09 like Dask, for example, like Dask has to do planning across a distributed cluster. And so, you know,
53:15 Dask data frame is very pandas like, but it also includes some explicit details of being able to
53:21 control how the data is partitioned and being able to have some knobs to turn in terms of like
53:25 having more control over what's happening on a distributed cluster. And I think the goal there
53:30 is like to give the developer more control as opposed to like trying to be intelligent, you know,
53:34 make all of the decisions on behalf of the developer. So, you know, if you know about how,
53:39 you know, know a lot about your data set, then you can make more, you can make, you know,
53:43 decisions about how to schedule and execute it. Of course, Dask is building, you know,
53:48 query optimization to start making more of those decisions on behalf of the user. But,
53:51 you know, Dask has become very popular and impactful and making distributed computing easier in Python.
53:57 So they've gotten, I think, gotten a long way without turning into a database. And I think Dask
54:01 never aspired to be a, to be a database engine, which is a lot of distributed computing is, you know,
54:06 not database like it's could be distributed array computing or distributed model training and
54:10 just being able to easily run distributed Python functions on a cluster, do distributed computing
54:16 that way. It was amazing. Like how many people were using PySpark in the early days, just for the
54:21 convenience of being able to run Python functions in parallel on a cluster.
54:25 Yeah. And that's pretty interesting. Not exactly what it's designed for.
54:29 Right.
54:29 You know, you probably come across situations where you do a sequence of operations. They're kind of
54:36 commutative in the end and practice, but from a computational perspective, like how do I distribute
54:40 this amongst different servers? Maybe one order matters a lot more than the other performance,
54:46 you know?
54:46 Yeah.
54:46 Yeah. Interesting. All right. One final thing. SQLglot.
54:50 Yeah. So SQLglot project started by Toby Mao. So he's a Netflix alum and, you know, really,
54:58 really talented, talented developer who's created this SQL query transpilation framework library for Python.
55:05 And, you know, kind of underlying core library. And so the problem that's being solved there is that
55:10 SQL, despite being a quote unquote standard, is not at all standardized across different database
55:16 systems. And so if you want to take your SQL queries written for one engine and use them someplace else,
55:21 without something like SQLglot, you would have to manually rewrite and make sure you get the
55:26 typecasting and coalescing rules correct. And so SQLglot has, understands the intricacies and the
55:34 quirks of every database dialect, SQL dialect, and knows how to correctly translate from one dialect
55:40 to another. And so IBIS now uses SQLglot as its underlying engine for query transpilation and
55:46 generating SQL outputs. So originally IBIS had its own kind of bad version of SQLglot, kind of a query
55:53 transpile, like SQL transpilation that was powered by, I think, powered by SQLAlchemy and some,
56:00 a bunch of custom code. And so I think they've been able to delete a lot of code in IBIS by moving to
56:05 SQLglot. And I know that, you know, SQLglot is also, you know, being used to power kind of a new,
56:11 yeah, being used in people building new products that are Python powered and things like that.
56:15 So, and Toby, like his, his company, Tobiko data, they, yeah, they're, they're building a product
56:21 called SQL mesh that's powered by SQLglot. So very cool project and maybe a bit in the weeds,
56:26 but if you've ever needed to convert a SQL query from one dialect to another, it's a, yeah,
56:30 SQLglot is here to save the day.
56:32 I would say, you know, even simple things is how do you specify a parameter variable,
56:37 you know, for a parameterized query, right? And Microsoft SQL server, it's like at the very,
56:42 the parameter name and Oracle, it's like question mark or SQLite. I think it's also,
56:47 you know, just that, even those simple things.
56:49 It's a pain, yeah.
56:50 And without it, you end up with little Bobby tables, which is also not good. So.
56:53 That's true. That's true.
56:54 Nobody wants to talk to him. Yeah, this is really cool. SQLglot, like polyglot,
56:59 but all the languages of SQL. Nice. And you do things like, you can say,
57:05 read DuckDB and write to Hive or read DuckDB and then write to Spark or,
57:10 or whatever. It's pretty cool. Yeah. All right, Wes, I think we're getting short on time,
57:14 but you know, I know everybody appreciated hearing from you and hearing what you're up to these days.
57:20 Anything you want to add before we wrap up?
57:22 I don't think so. Yeah. I enjoyed the conversation and yeah, there's a lot of stuff going on and
57:29 still plenty of things to get, get excited about. So I think often people feel like all the exciting
57:34 problems in the Python ecosystem have been solved, but there's still a lot to do. And yeah, we've made
57:40 a lot of progress in the last 15 plus years, but in some ways feels like we're just getting started.
57:46 So we are just excited to see where things go next.
57:49 Yeah. Every time I think all the problems are solved, then you discover all these new things
57:53 that are so creative and you're like, oh, well, that was a big problem. I didn't even know it was a
57:56 problem. It's great. All right. Thank you for being here and taking the time and keep us updated on what
58:01 you're up to. All right. Thanks for joining us. Bye-bye. Bye-bye.
58:04 This has been another episode of Talk Python To Me. Thank you to our sponsors. Be sure to check
58:11 out what they're offering. It really helps support the show. It's time to stop asking relational
58:16 databases to do more than they were made for and simplify complex data models with graphs.
58:21 Check out the sample FastAPI project and see what Neo4j, a native graph database, can do for you.
58:28 Find out more at talkpython.fm/Neo4j. Mailtrap, an email delivery platform that developers love.
58:36 Try for free at mailtrap.io. Want to level up your Python? We have one of the largest catalogs of Python
58:44 video courses over at Talk Python. Our content ranges from true beginners to deeply advanced topics like
58:49 memory and async. And best of all, there's not a subscription in sight. Check it out for yourself
58:54 at training.talkpython.fm. Be sure to subscribe to the show. Open your favorite podcast app and search
59:00 for Python. We should be right at the top. You can also find the iTunes feed at /itunes,
59:05 the Google Play feed at /play, and the direct RSS feed at /rss on talkpython.fm.
59:12 We're live streaming most of our recordings these days. If you want to be part of the show and have
59:16 your comments featured on the air, be sure to subscribe to our YouTube channel at talkpython.fm
59:21 slash YouTube. This is your host, Michael Kennedy. Thanks so much for listening. I really appreciate
59:27 it. Now get out there and write some Python code.
59:29 Thank you.