Building GPT Actions with FastAPI and Pydantic



Episode Deep Dive
Guest: Ian Moyer and His Background
Ian Moyer is a seasoned Python developer working at Genome Oncology, building precision oncology software for medical professionals and researchers. He was previously on the podcast in 2018 discussing Python for genomics and biology. Ian began his career creating e-commerce sites in Java before switching to Python. He has since used Python, FastAPI, and other modern tools to solve problems in genomic data processing and, more recently, to experiment with custom GPT (Generative Pre-trained Transformer) applications.
1. Ian’s Ongoing Python Journey in Genomics
- Moving from Java to Python: Ian described how creating a quick prototype in Django drastically sped up development, convincing his team to adopt more Python.
- Current Work at Genome Oncology: He focuses on building tools for precision oncology, including natural language processing solutions that help interpret medical and genetic data.
2. LLMs (Large Language Models) and Their Place in Development
- Initial Exposure to LLMs: Ian originally used NLP libraries like spaCy for text processing, but the release of ChatGPT highlighted the power of large models for tasks like summarization and information extraction.
- Developer Workflow with ChatGPT: Rather than using “autocomplete” coding tools exclusively, Ian prefers to collaborate with ChatGPT 4 for step-by-step problem solving, especially around edge cases and testing strategies.
3. Integrating LLMs in Python Apps
- APIs and Providers: The episode surveyed several LLM APIs (OpenAI, Azure OpenAI, Google Gemini, Anthropic Claude) and highlighted Simon Willison’s LLM library for switching between providers.
- Abstraction and Optionality: Ian stressed coding to an abstraction layer so you can swap LLM backends easily—just as you might swap databases or services in other parts of your application.
4. Running LLMs Locally (Open Source and On-Device Models)
- Local Models vs. Cloud APIs: Ian and Michael discussed projects such as LM Studio and LlamaFile.ai, which provide OpenAI-like local servers running models like Llama 2, Mistral 7B, and more.
- Prompt Engineering & Context Windows: They covered techniques like few-shot prompting, chunking text for embeddings, and the inherent limits of a model’s “context window.”
5. Retrieval-Augmented Generation (RAG)
- Basic Concept: Store documents or data in a vector database, retrieve relevant chunks via embeddings, then feed them into an LLM prompt to synthesize an answer.
- Vector Databases: They discussed solutions like PG Vector (for PostgreSQL) and how indexing methods can trade off speed versus perfect recall.
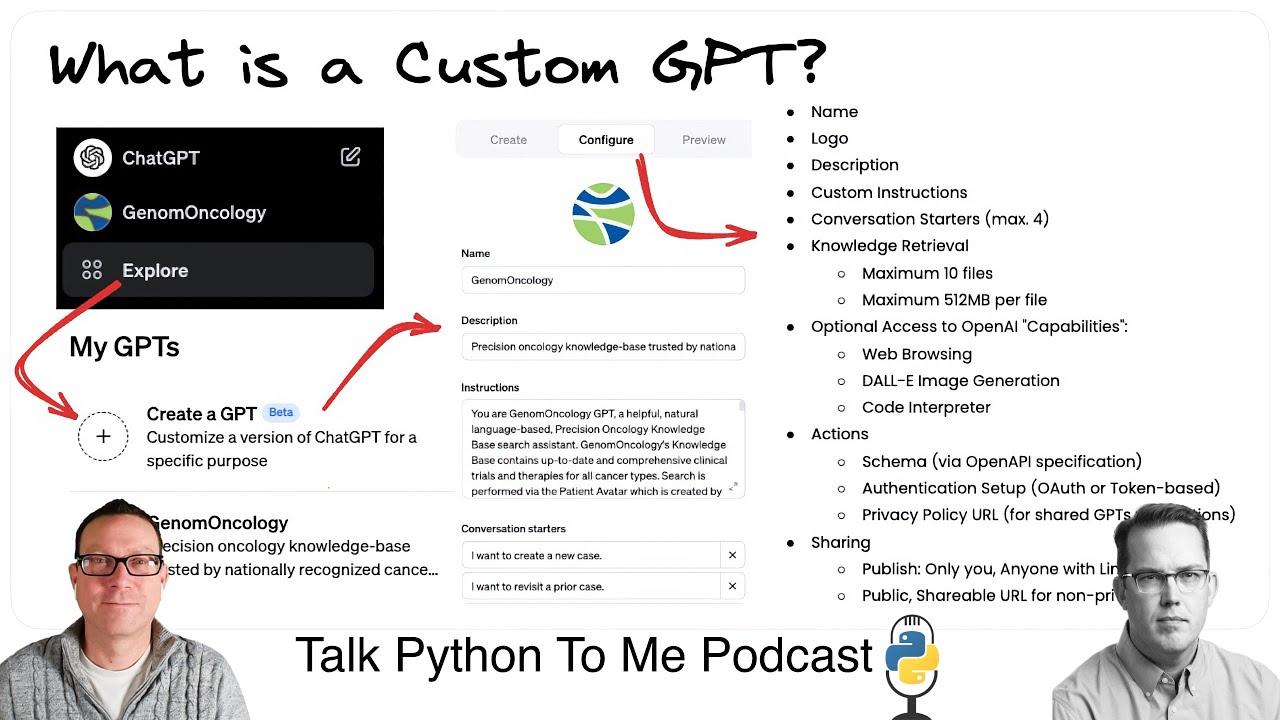
6. Custom GPTs from OpenAI
- Custom GPT Overview: A new feature from OpenAI that lets you name and brand a GPT, give it custom instructions, add PDF documents or knowledge sources, and share it with others.
- Actions and OpenAPI Specs: Formerly “plugins,” these GPT “actions” let your GPT call your custom API. Ian noted you can build that API with FastAPI plus an OpenAPI spec, effectively teaching the GPT how to interface with your code.
7. PyPI GPT Example
- FastAPI + Pydantic Demo: Ian’s example project (“PyPI GPT”) showcases how to serve an OpenAPI spec (via FastAPI) that a custom GPT can call. Although the demonstration is simple (fetching data about Python packages), it’s a working template for more advanced ideas.
- HTTPS & Hosting: If you want to replicate it, you’ll need a secure endpoint (e.g., via ngrok or Let’s Encrypt) so OpenAI can reach your API.
8. Tools, Libraries, and Projects Mentioned
Below are some references from the conversation, all of which Ian and Michael highlighted directly:
- LangChain: github.com/hwchase17/langchain
- LlamaIndex (formerly GPT Index): github.com/jerryjliu/gpt_index
- LM Studio: lmstudio.ai
- LlamaFile: llamafile.ai
- Simon Willison’s LLM: github.com/simonw/llm
- Sourcegraph Cody: about.sourcegraph.com/cody
- Marvin, Instructor, Outlines: Various open source Pydantic-based “extract-to-JSON” LLM libraries (mentioned for structured LLM outputs)
- VisiData: visidata.org – a CLI spreadsheet-like utility for CSVs and data
- btop: GitHub link – a colorful terminal-based system monitor
9. Medical Use Cases & Caution
- Leveraging GPTs in Oncology: Ian is actively experimenting with GPT solutions in genome interpretation, focusing on a “human-in-the-loop” approach where clinicians remain the final decision makers.
- Prompt Injection and Hallucination: They discussed the reality that LLMs can be tricked (prompt injection) or produce convincing but incorrect answers (hallucinations). Any serious medical or legal usage must account for these limitations.
Overall Takeaway
This episode takes a deep dive into building custom GPT apps using Python. It covers everything from best practices for LLM usage and prompt design to practical details on packaging a custom GPT with FastAPI and Pydantic. While GPTs can synthesize data and automate many tasks, Ian emphasizes the importance of safety, correctness, and a thoughtful integration approach—especially when reliability matters, such as in healthcare. By combining Python-based tooling with LLMs, developers can create targeted chat experiences that extend beyond the basic ChatGPT interface and potentially deliver high-impact solutions in specialized domains.
Links from the show
Mobile Navigation: openai.com
What is a Custom GPT?: imaurer.com
Mobile Navigation: openai.com
FuzzTypes: Pydantic library for auto-correcting types: github.com
pypi-gpt: github.com
marvin: github.com
instructor: github.com
outlines: github.com
llamafile: github.com
llama-cpp-python: github.com
LLM Dataset: llm.datasette.io
Plugin directory: llm.datasette.io
Data exploration at your fingertips.: visidata.org
hottest new programming language is English: twitter.com
OpenAI & other LLM API Pricing Calculator: docsbot.ai
Vector DB Comparison: vdbs.superlinked.com
bpytop: github.com
Source Graph: about.sourcegraph.com
Watch this episode on YouTube: youtube.com
Episode #456 deep-dive: talkpython.fm/456
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Do you know what custom GPTs are?
00:02 They're configurable and shareable chat experiences with the name, logo, custom instructions,
00:07 conversation starters, access to OpenAI tools, and custom API actions.
00:12 And you can build them with Python.
00:15 Ian Moyer has been doing just that and is here to share his experience building them.
00:20 This is Talk Python To Me, episode 456, recorded January 22nd, 2024.
00:26 Welcome to Talk Python To Me, a weekly podcast on Python.
00:43 This is your host, Michael Kennedy.
00:45 Follow me on Mastodon, where I'm @mkennedy, and follow the podcast using @talkpython,
00:50 both on fosstodon.org.
00:52 Keep up with the show and listen to over seven years of past episodes at talkpython.fm.
00:57 We've started streaming most of our episodes live on YouTube.
01:01 Subscribe to our YouTube channel over at talkpython.fm/youtube to get notified about upcoming shows
01:07 and be part of that episode.
01:09 This episode is sponsored by Sentry.
01:12 Don't let those errors go unnoticed.
01:14 Use Sentry.
01:14 Get started at talkpython.fm/sentry.
01:17 And it's also brought to you by Neo4j.
01:20 It's time to stop asking relational databases to do more than they were made for.
01:25 Check out the sample FastAPI project and see what Neo4j, a native graph database,
01:31 can do for you.
01:32 Find out more at talkpython.fm/Neo4j.
01:36 Ian, welcome to Talk Python To Me.
01:39 Hey, Michael.
01:40 Good to see you again.
01:41 Yeah, great to see you again.
01:42 It has been a little while.
01:44 It seems like not so long ago.
01:46 And yet, when I pull up the episode that we did together, sure enough, it says March 7th, 2018.
01:54 Wow.
01:55 Years are short.
01:56 Years are short.
01:57 They go by really fast.
01:58 They sure do.
01:58 So back then, we were talking about Python and biology and genomics.
02:04 And it sounds like you're still doing genetic type things and still doing Python and all that kind of stuff.
02:11 For sure.
02:11 Yeah, definitely.
02:12 We work for a company called Genome Oncology.
02:14 We do precision oncology software, helping folks make sense of genomics and trying to help cancer patients.
02:20 That's awesome.
02:21 There's different levels of helping people with software.
02:24 On one level, we probably have ad retargeting.
02:28 On the other, we've got medical benefits and looking for helping people who are suffering socially or whatever.
02:38 So it's got to feel good to write software that is making a difference in people's lives.
02:43 That's right.
02:43 I did spend a lot of the 2000s making e-commerce websites and that wasn't exactly the most fulfilling thing.
02:48 I learned a lot, but it wasn't as exciting as what I'm doing now, or at least as fulfilling as what I'm doing now.
02:53 Were those earlier websites in Python?
02:55 I was all Java for the most part.
02:57 And finally with this company, I knocked out a prototype in Django a few years ago.
03:02 And my boss at the time was like, you did that so fast, you should do some more stuff in Python.
03:08 So that's kind of how it evolved.
03:10 And now basically most of our core backend is Python and we use a little bit of Svelte for the user interfaces.
03:17 Beautiful.
03:17 It's easy to forget, like five years ago, 10 years ago, people were questioning whether Python should be something you should use.
03:24 Is it a real language?
03:25 Should you really use it?
03:26 Is it safe to use?
03:27 Maybe you should use a Java or a C# or something like that because this is a real project.
03:33 It's interesting.
03:34 You don't hear that nearly as much anymore, do you?
03:35 I grew up with Boston sports fans and it was like being a Boston sports fan was terrible for the longest time.
03:40 And now it's like, okay, we don't want to hear about your problems right now.
03:43 And same thing with Python.
03:44 It's like, I like Python.
03:45 It's like, yeah, great.
03:46 So does everybody else in the world.
03:47 So yeah, it's really not the issue anymore.
03:50 It's now it's not the cool thing to play with.
03:51 So now you got to go to Rust or something else.
03:53 You know what?
03:54 Shiny.
03:54 LLMs are shiny.
03:56 LLMs are very shiny for sure.
03:58 Yeah.
03:58 We can talk about them today.
03:59 Yeah, that sounds great.
04:00 Let's do it.
04:01 First of all, we're going to talk about building applications that are basically powered by LLMs that you plug into, right?
04:08 Yep.
04:09 Before we get into creating LLMs, just for you, like what is, where do LLMs play a role for you in software development these days?
04:18 Sure.
04:18 So, you know, like everybody else, I mean, I had been playing with, so I do natural language processing as part of my job, right?
04:25 So using spaCy was a big, a big part of the information extraction stack that we use
04:29 because we have to deal with a lot of medical data and medical data is just unstructured and has to be cleaned up before it can be used.
04:35 That was my exposure.
04:37 I had seen GPTs and the idea of like generating text, just starting from that didn't really make much sense to me at the time.
04:44 But then obviously like everybody else, when ChatGPT came out, I was like,
04:47 oh, I get this now.
04:48 Like this thing does, you know, it can basically learn in the context and it can actually produce something that's interesting
04:53 and you can use it for things like information extraction.
04:56 So just like everybody else, I kind of woke up to them, you know, around that time that they got released and I use them all the time, right?
05:02 So ChatGPT 4 is really what I use.
05:04 I would recommend if you can afford the $20 a month, it's still the best model that there is as of January 2024.
05:10 And I use that for coding.
05:12 I don't really like the coding tools, the co-pilots, but there, you know, there's definitely folks that swear by them.
05:18 My workflow is more of, I have a problem, work with the chatbot to try to like, you know,
05:22 think through all the edge cases and then think through the test case, the tests.
05:27 And then I think through the code, right?
05:28 And then the actual typing of the code, yeah, I'll have it do a lot of the boilerplate stuff,
05:32 but then kind of shaping the APIs and things like that.
05:35 I kind of like to do that myself still.
05:37 I'm kind of old school, old school.
05:38 I guess I'm old school as well because I'm like right there with you.
05:41 But for me, I don't generally run co-pilot or those kinds of things in my editors.
05:47 I do have some features turned on, but primarily it's just really nice autocomplete.
05:53 You know what I mean?
05:54 Like it seems like it almost just knows what I want to type anyway.
05:58 And that's getting better.
05:59 I don't know if anyone's noticed recently.
06:01 One of the recent releases of PyCharm, it starts to autocomplete whole lines.
06:06 And I don't know where it's getting this from, and I think I have the AI features turned off.
06:10 At least it says I have no license.
06:11 I'm guessing that means they're turned off.
06:13 So it must be something more built into it.
06:15 That's pretty excellent.
06:16 But for me, I find I'm pretty content to just sit and write code.
06:20 However, the more specific the unknowns are, the more willing I'm like, oh, I need to go to ChatGPT for this.
06:27 Like, for example, like how do you use Pydantic?
06:30 Like, well, I'll probably just go look at a quick code sample and see that so I can understand it.
06:35 But if it's I have this time string with the date like this, the month like this,
06:41 and then it has the time zone like that, how do I parse that?
06:44 Or how do I generate another one like that in Python?
06:47 And here's the answer.
06:48 Or I have this giant weird string, and I want this part of it as extracted with a regular expression.
06:54 And I want to...
06:55 Regular expressions, I was just going to say that.
06:56 Oh, my gosh.
06:57 You don't have to write another one of those.
06:58 Yeah, it's great.
06:59 Yeah, it's pretty much like, do you need it to detect the end of a line straight to ChatGPT?
07:03 Not really.
07:03 But, you know, it's like almost any level of chat, a regular expression.
07:07 I'm like, well, I need some AI for this because this is not time well spent for me.
07:11 But yeah, it's interesting.
07:12 Yeah.
07:12 One big tip I would give people, though, is that these chatbots, they want to please you.
07:16 So you have to ask it to criticize you.
07:19 You have to say, here's some piece of code.
07:20 Tell me all the ways it's wrong.
07:21 And you have to also ask for lots of different examples because it just starts to get more creative, more things that it says.
07:28 It really thinks by talking, which is a really weird thing to consider.
07:31 But yeah, it's definitely some things to keep in mind when you're working with these things.
07:35 And they do have these really weird things.
07:37 Like if you compliment them or if you ask it, you sort of tell it, like, I really want you to tell me.
07:42 It actually makes a difference, right?
07:43 It's not just like a search engine.
07:45 Like, well, of course, what does it care?
07:46 You put these keywords in and they come out.
07:48 Like, no, you've kind of got to, like, know how to talk to it just a little bit.
07:51 I've seen people threatening them or, like, saying that someone's being held ransom or, you know, I like to say my boss is really mad at me.
07:58 Like, help me out here, right?
07:59 And, like, see if it'll generate some better code.
08:01 You're not being a good user.
08:02 You're trying to trick me.
08:04 I've been a good chatbot and you've been a bad user and I'm not going to help you anymore.
08:08 Yeah, right.
08:08 That was actually basically a conversation from Bing in the early days.
08:12 Yeah, the Sydney episode.
08:13 Yeah, that was crazy, right?
08:14 Super funny.
08:15 How funny.
08:16 All right.
08:17 Well, I'm sure a lot of people out there are using AI these days.
08:20 I think I saw a quote from, I think it was from GitHub saying over 50% of developers are using Copilot.
08:26 For sure.
08:26 Which is crazy, but, I mean, not that surprising.
08:29 50% of the people are using Autocomplete.
08:31 So, I guess it kind of, kind of like that, right?
08:33 They're great tools.
08:34 They're going to keep evolving.
08:35 There's some other ones I'm keeping an eye on.
08:36 There's one called Console, which just takes a different approach.
08:39 They use some stronger models.
08:41 And then there's a website called Find, P-H-I-N-D, that allows you to do some searching, that they've built their own custom model.
08:46 Really interesting companies that are doing some really cool things.
08:49 And then Perplexity is like the search replacement that a lot of folks are very excited about using instead of Google.
08:55 So, there's a lot of different tools out there.
08:57 You could spend all your day just kind of playing around and learning these things where you got to actually kind of get some stuff done, too.
09:02 Yeah, you got to pick something and go, right?
09:04 Because with all the churn and growth and experimentation we got, you probably could try a new tool every day and still not try them all, you know?
09:11 Just be falling farther behind.
09:13 So, you got to pick something and go.
09:15 And go, yep.
09:15 Let's talk about writing some code.
09:18 Yeah, the next thing you're going to do after you, you know, use a chatbot is to, you know, hit an API.
09:24 Like, if you're going to program an app and that app is going to have LLM inside of it, large language models inside of it, APIs are pretty much the next step, right?
09:32 So, OpenAI has different models that are available.
09:35 This is a web page that I just saw recently that will actually, you know, compare the different models that are out there.
09:39 So, there's obviously the big guy, which is OpenAI.
09:41 And you can get that through Azure as well if you have a Microsoft arrangement.
09:45 And there's some security reasons or HIPAA compliance and, you know, some other reasons that you might want to talk through Azure instead of going directly to OpenAI.
09:53 I'd defer to your IT department about that.
09:56 Google has Gemini, which they just released the Pro version, which I believe is as strong as 3.5, roughly.
10:03 That is interesting because if you don't care about them training on your data, if, like, whatever you're doing is just, like, not super proprietary or something you're trying to keep secret,
10:12 they're offering free API access, I believe 60 words per minute, right?
10:17 So, basically, one a second, you can call this thing and there's no charge.
10:20 So, I don't know how long that's going to last.
10:23 So, if you have an interesting project that you want to use in a large language model for, you might want to look at that.
10:27 Yeah, especially if it's already open data that you're playing with.
10:30 Exactly, right.
10:31 Or data you've somehow published to the web that has certainly been consumed by these things.
10:36 And these models are going to train on it, right?
10:37 That's the trade, right?
10:38 They're trying to get more tokens, is what they call it, right?
10:41 The tokens are what they need to actually make these models smarter.
10:44 So, everyone's just hunting for more tokens.
10:47 And I think this is part of their strategy for that.
10:48 And then there's also a Claude by Anthropic.
10:51 And then after that, you get into the, you know, kind of the open source APIs as well.
10:55 There's some really powerful open source ones out there.
10:57 Yeah, so this website, yeah, this is DocsBot for people listening.
11:02 DocsBot.ai.
11:02 And is it sole purpose just to tell you price comparisons and stuff like that?
11:07 Or does it have more than it?
11:08 I assume this company's got some product.
11:10 Unfortunately, I don't know what it is.
11:11 I saw this link that they put out there.
11:13 And it's a calculator.
11:14 So, you basically can put your tokens, how many tokens.
11:17 There's input tokens and there's output tokens, right?
11:19 So, they're going to charge more on the output tokens.
11:22 That's for the most part.
11:23 Some of the models are, you know, more equal.
11:26 And then what they do is, if you can figure out, like, roughly how big a message is going
11:30 to be, both the input and the output, how many calls you're going to make, you can use
11:33 that to then calculate basically the cost.
11:36 And the cost is always at, like, tokens per thousand, you know, or dollars or pennies, really.
11:41 Pennies per thousand tokens.
11:43 And then it's just a math equation at that point.
11:45 And what you'll find is calling GPT-4 is going to be super expensive.
11:48 And then calling, you know, a small 7, what's called the 7B model from Mistral is going to
11:53 be the cheapest.
11:55 And you're just going to look for these different providers.
11:57 Well, the prices really are different.
11:58 Like, for example, OpenAI Azure GPT-4 is a little over three cents per call, whereas GPT-3.5
12:07 Turbo is one-tenth of one cent.
12:11 It's a big difference there.
12:13 It's 11 cents versus $3 to have a conversation with it.
12:16 Yes, it's a very, very wide difference.
12:18 And it's all based on, you know, how much compute do these models take, right?
12:21 Because the bigger the model, the more accurate it is, but also the more expensive it is for
12:26 them to run it.
12:26 So that's why there's such a cost difference.
12:30 This portion of Talk Python To Me is brought to you by Sentry.
12:33 In the last episode, I told you about how we use Sentry to solve a tricky problem.
12:37 This time, I want to talk about making your front-end and back-end code work more tightly together.
12:43 If you're having a hard time getting a complete picture of how your app is working and how
12:48 requests flow from the front-end JavaScript app back to your Python services down into
12:53 database calls for errors and performance, you should definitely check out Sentry's distributed
12:58 tracing.
12:58 With distributed tracing, you'll be able to track your software's performance, measure metrics
13:03 like throughput and latency, and display the impact of errors across multiple systems.
13:09 Distributed tracing makes Sentry a more complete performance monitoring solution, helping you
13:14 diagnose problems and measure your application's overall health more quickly.
13:18 Tracing in Sentry provides insights such as what occurred for a specific event or issue, the
13:24 conditions that cause bottlenecks or latency issues, and the endpoints and operations that
13:29 consume the most time.
13:30 Help your front-end and back-end teams work seamlessly together.
13:33 Check out Sentry's distributed tracing at talkpython.fm/sentry-trace.
13:39 That's talkpython.fm/sentry-trace.
13:43 And when you sign up, please use our code TALKPYTHON, all caps, no spaces, to get more features and
13:50 let them know that you came from us.
13:51 Thank you to Sentry for supporting the show.
13:55 Yeah, I recently interviewed, just released a while ago, interviewed because of time shifting
14:00 on podcasts, Mark Rosinovich, CTO of Azure, and we talked about all the crazy stuff that
14:05 they're doing for coming up with just running these computers that handle all of this compute,
14:10 and it's really a lot.
14:12 There was a GPU shortage for a while.
14:13 I don't know if that's still going on.
14:14 And obviously, you know, the big companies are buying hundreds of thousands of these GPUs
14:19 to get the scale they need.
14:21 And so once you figure out which API you want to use, then you want to talk about the
14:25 library.
14:25 So now, you know, most of these providers, they have, you know, a Python library that they
14:30 offer.
14:30 I know OpenAI does and Google with Gemini does, but there's also open source ones, right?
14:35 Because they're not very complicated to talk to.
14:38 It's just basically HTTP requests.
14:40 So it's just really a matter of like, what's the ergonomics you're looking for as a developer
14:44 to interact with these things?
14:46 And most importantly, make sure you're maintaining optionality, right?
14:49 Like, it's great to do a prototype with one of these models or recognize you might want
14:54 to switch either for cost reasons or performance reasons or what have you.
14:58 And, you know, LangChain, for instance, has a ton of the providers as part of you basically
15:03 are just switching a few arguments when you're switching between them.
15:07 And then Simon Willison has, you know, of Python fame, has an LLM project where he's defined,
15:13 you know, basically a set of, and it's really clean just the way he's organized it, because
15:18 you can just add plugins as you need them, right?
15:20 So you don't have to install all the different libraries that are out there.
15:22 And I think LangChain is kind of following a similar approach.
15:25 I think they're coming up with a LangChain core capability where you can just kind of bring
15:29 in things as you need them.
15:30 And so the idea is you're now coding against these libraries and you're trying to bring
15:36 together, you know, the text you need to have analyzed or whatever your use case is.
15:40 And then it'll come back with the generation.
15:42 And you can also not just use them on the cloud.
15:45 You can use open source ones as well and run them locally on your local computer.
15:48 I'd never really thought about my architectural considerations, I guess, of these sorts of things.
15:54 But of course, you want to set up some kind of abstraction layer.
15:58 So you're not completely tied into some provider.
16:01 I mean, it could be that it becomes too expensive.
16:03 It could be that it becomes too slow.
16:05 But it also might just be something that's better.
16:07 It could be something else that comes along that's better.
16:09 And you're like, we could switch.
16:11 It's 25% better.
16:12 But it's like a week to pull all the details of this one LLM out and put the new ones in.
16:18 And so it's not worth it.
16:19 Right.
16:19 So you like having being tied to a particular database rather than more general.
16:24 It's a similar idea.
16:25 And especially at this moment in time, right?
16:27 Every couple of months, something.
16:28 So something from the bottom up is getting better and better.
16:31 Meaning, you know, Llama came out a year ago and then Llama 2 and Mistral and Mixtral.
16:36 And, you know, Llama 3 is going to be coming out later this year, we believe.
16:40 And so those models, which are smaller and cheaper and easier to use, are not easier to use, but they're just cheaper, is those things are happening all the time.
16:48 So being able to be flexible and nimble and kind of change where you are is going to be crucial, at least for the next couple of years.
16:54 Yeah.
16:54 The example that I gave was databases, right?
16:56 And databases have been kind of a known commodity since the 80s or what, 1980s?
17:02 And of course, there's new ones that come along, but they're kind of all the same.
17:05 And, you know, we've got, there was MySQL, now there's Postgres that people love and, right?
17:10 So that is changing way, way slower than this.
17:13 And people are like, well, we got to think about those kinds of like, don't get tied into that.
17:17 Well, sure.
17:18 It's way less stable.
17:19 Right.
17:19 And people, you know, create layers of abstraction there, too, is right.
17:23 You got SQLAlchemy and then, you know, Sebastian from FastAPI has SQL model.
17:28 That's a layer on top of SQLAlchemy, you know, and then there's also, you know, folks that just like writing clean NC SQL.
17:34 And you can, you know, hopefully be able to port that from database to database as well.
17:37 So it's the same principles, separation of concerns.
17:40 So you can kind of be flexible.
17:42 All right.
17:42 So you talked about LangChain.
17:44 Just give us a sense real quick of what LangChain is.
17:46 This was a great project from a timing perspective.
17:49 I believe they kind of invented it and released it right around the time ChatGPT came out.
17:53 It's a very comprehensive library with lots of, I mean, the best part about LangChain to me is the documentation and the code samples.
18:00 Right.
18:00 Because if you want to learn how to interact with a different large language model or work with a vector database, there's another library called Lama Index that does a really good job at this as well.
18:09 They have tons and tons of documentation and examples.
18:12 So you can kind of look at those and try to understand it.
18:15 The chaining part really came from the idea of like, okay, prompt the large language model gives a response.
18:20 Now I'm going to take that response and prompt and prompt and, you know, again, with a new prompt using that output.
18:25 The challenge with that is the reliability of these models, right?
18:28 They're not going to get close.
18:30 They're not close to 100% accurate on these types of tasks.
18:33 You know, the idea of agents as well as another thing that you might build with a LangChain.
18:38 And the idea there is basically the agent is, you know, getting a task, coming up with a plan of that for that task and then kind of, you know, stepping through those tasks to get the job done.
18:47 Once again, we're just not there yet as far as those technologies just because of the reliability.
18:53 And then there's also a bunch of security concerns that, you know, that are out there too that you should definitely be aware of.
18:59 Like one term to Google and make sure you understand is prompt injection.
19:03 And so Simon, once again, he's got a great blog.
19:05 He's got a great blog article and, or just even that tag on his blog is, you know, tons of articles around prompt injection.
19:11 And, and prompt injection is basically the idea.
19:14 You have an app, a user says something in the app or like types into the, to the, whatever the input is and whatever text that they're sending through, just like with SQL injection, they kind of hijacks the conversation and causes the large language model to kind of do a different thing.
19:27 Little Bobby Llama, we call him instead of little Bobby tables.
19:31 And then the other wild one is like, you know, people are putting stuff up on the internet so that when the large language model browses for web pages and brings back text, it's, you know, reading the HTML or reading the text in the HTML.
19:42 And it's causing the large language model to behave in some unexpected way.
19:45 So there's lots of, lots of crazy challenges out there.
19:49 I'm sure there's a lot of adversarial stuff happening to these things as they're both trying to gather data and then trying to run.
19:55 Right.
19:56 I saw the most insane, I guess it was an article, I saw it in RSS somewhere.
20:00 And it was saying that on Amazon, there's all these knockoff brands that are trying to, you know, instead of Gucci, you have a Gucci or I don't know, whatever.
20:10 Right.
20:10 And they're getting so lazy.
20:13 I don't know what the right word is that they're using LLMs to try to write a description that is sort of a, in the style of Gucci, let's say.
20:20 Right.
20:20 And it'll come back and say, I'm sorry, I'm a large language model.
20:24 I'm not, my, my rules forbid me from doing brand trademark violation.
20:30 Right.
20:31 That's what the Amazon listing says on Amazon.
20:33 They just take it and they just straight pump it straight.
20:35 Whatever it says, it just goes straight into Amazon.
20:37 Yeah.
20:37 You have to like Google, like, sorry, I'm not, sorry as a large language model or sorry as a whatever.
20:41 Yeah.
20:41 Exactly.
20:42 And there's like the product listings are full of that.
20:44 It's amazing.
20:45 It's amazing.
20:46 It's crazy.
20:46 Certainly the reliability of that is, you know, they could probably use some testing and those kinds of things.
20:52 For sure.
20:52 Oh, and out there asked, like, I wonder if the, for local LLM models, there's a similar site as DocSpot that show you like what you need to run it locally.
21:00 So that's an interesting question.
21:01 Also segue to maybe talk about like some local stuff.
21:04 LLM studio.
21:04 This is a new, a new product.
21:06 I honestly haven't had a chance to like really dig in and understand who created this and, you know, make sure that the privacy stuff is up to snuff.
21:12 But I've played around with it locally.
21:14 It seems to work great.
21:15 It's really slick, really nice user interface.
21:17 So if you're just wanting to get your feet wet and try to understand some of these models, I download that and check it out.
21:22 There's a ton of models up on Hugging Face.
21:24 This product seems to just basically link right into the Hugging Face interface.
21:29 And grabs models.
21:30 And so some of the models you want to look for are right now as in January, right?
21:34 There's Mistral 7B, you know, M-I-S-T-R-A-L.
21:38 There's another one called Phi 2.
21:40 Those are two of the smaller models that should run pretty well on, you know, like a commercial grade GPU or an M1 or an M2 Mac, if that's what you have.
21:50 And start playing with them.
21:51 And they're quantized, which means they're just kind of made a little, take a little bit less space, which is good from like a virtual RAM with regards to these GPUs.
21:59 And, you know, there's a account on Hugging Face called The Bloke.
22:04 If you look for him, you'll see all his different fine tunes and things like that.
22:09 And there's a group called Noose, I think is how you pronounce it, N-O-U-S.
22:12 And they've got some of the fine tunes that are basically the highest performing ones that are out there.
22:18 So if you're really looking for a high performing local model that can actually, you know, help you with code or reasoning, those are definitely the way to get started.
22:26 Yeah, this one seems pretty nice.
22:28 I also haven't played with it.
22:29 I just learned about it.
22:30 But it's looking really good.
22:32 I had played with, what was it, GPT for All, I think is what it was.
22:36 Yep, yep.
22:36 It was the one that I played with.
22:38 Somehow this looks like, it looks a little bit nicer than that for some, I don't know how different it really is.
22:42 But I mean, it's all the idea of like downloading these files and running them locally.
22:47 And these are just user interfaces that make it a little easier.
22:49 The original project that made this stuff kind of possible was a project called Llama CPP.
22:54 There's a Python library that can work with that directly.
22:57 There's another project called Llama File, where if you download the whole thing, it actually runs no matter where you are.
23:04 I think it runs on Mac and Linux and Windows and BSD or whatever it is.
23:08 And it's, I mean, it's an amazing technology that this one put together.
23:12 It's really impressive.
23:13 And then, you know, you can actually just use Google Colab too, right?
23:17 So Google Colab has some GPUs with it.
23:19 If you, I think if you upgrade it to the $10 a month version, I think you get some better GPUs access.
23:25 So if you actually want to get a hand of like running.
23:27 And so this is a little bit different, right?
23:29 So instead of calling an API, when you're using Google Colab, you can actually use a library called Hugging Face.
23:34 And then you can actually load these things directly into your memory and then into your actual Python environment.
23:40 And then you're working with it directly.
23:41 So it just takes a little bit of work to make sure you're running it on the GPU.
23:45 Because if you're running it on the CPU, it's going to be a lot slower.
23:48 Yeah, it definitely makes a big difference.
23:49 There's a tool that I use that for a long time right on the CPU and they rewrote it to run on the GPU.
23:55 Even on my M2 Pro, it was like three times faster or something.
23:59 Yeah.
23:59 For sure.
24:00 It makes a big difference.
24:01 So with the LM Studio, let's you run the LLMs offline and use models through an OpenAI.
24:08 That's what I was looking for.
24:09 The OpenAI compatible local server.
24:11 Right.
24:12 You could basically get an API for any of these and then start programming against it, right?
24:16 Exactly right.
24:17 And it's basically the same interface, right?
24:19 So same APIs for posting in response of the JSON schema that's going back and forth.
24:25 So you're programming against that interface and then you basically port it and move it to another, to the OpenAI models if you wanted to as well.
24:32 So everyone's kind of coalescing around OpenAI as kind of like the quote unquote standard.
24:36 But there's nothing, you know, there's really no, there's no mode around that standard as well, right?
24:41 Because anybody can kind of adopt it and use it.
24:44 There's not like a W3C committee choosing.
24:46 Correct.
24:48 The market will choose for us.
24:49 Let's go.
24:50 It seems to be working out well.
24:52 And that's another benefit of Simon's LLM project, right?
24:55 He's got the ability to kind of switch back and forth between these different libraries and APIs as well.
25:00 This LM Studio says, this app does not collect data nor monitor your actions.
25:05 Your data stays local on your machine.
25:07 Free for personal use.
25:08 All that sounds great.
25:09 For business use, please get in touch.
25:11 I always just like these, like, if you got to ask, it's too much type of thing.
25:14 Probably.
25:15 Yeah.
25:16 I'm using it for personal use just so if anybody's watching, yes.
25:18 Yeah.
25:19 Just playing around.
25:19 Either they just haven't thought it through and they just don't want to talk about it yet.
25:22 Or it's really expensive.
25:24 I just probably imagine it's price.
25:25 Like, ah, we haven't figured out a business model.
25:27 Just, I don't know.
25:28 Shoot us a note.
25:28 Nope.
25:29 They're concentrating on the product, which makes sense.
25:31 Yeah.
25:31 So then the other one is Llamafile.ai that you mentioned.
25:35 And this packages it up.
25:36 I guess going back to the LM Studio real quick.
25:40 One of the things that's cool about this is if it's the OpenAI API, right?
25:45 With this little local server that you can play with.
25:47 But then you can pick LLM such as Llama, Falcon, Repl, Replit.
25:52 Replit.
25:52 Replit.
25:53 All the different ones, right?
25:54 Star Coder and so on.
25:56 It would let you write an app as if it was going to OpenAI and then just start swapping in models
26:01 and go like, oh, we switch to this model.
26:03 How'd that work?
26:04 But you don't even have to change any code, right?
26:05 Just probably maybe a string that says which model to initialize.
26:09 One of the tricks, though, is then the prompts themselves.
26:11 All right.
26:12 Let's talk about it.
26:13 Yeah.
26:13 The models themselves act differently.
26:15 And part of this whole world is what they call prompt engineering, right?
26:19 So prompt engineering is really just exploring how to interact with these models, how to make
26:25 sure that they're kind of in the right mind space to tackle your problem.
26:28 A lot of the times that people get when they struggle with these things, it's really just
26:32 they've really got to think more like a psychiatrist when they work with a model.
26:36 They're basically getting them kind of prepared.
26:38 One of the tricks people did figured out early was you're a genius at software development,
26:44 like compliment the thing, make it feel like, oh, I'm going to behave like I'm a world rock
26:50 star programmer, right?
26:51 Well, it's going to give you average.
26:52 But if you tell them I'm genius, then let's start.
26:54 We'll do that.
26:55 Yeah.
26:55 And there was also a theory like that in December that the large language models were getting
26:59 dumber because it was the holidays and people don't work as hard, right?
27:02 Like it's really hard to know like which of these things are true or not.
27:06 But it's definitely true that each model is a little bit different.
27:09 And if you write a prompt that works really well on one model, even if it's a stronger
27:13 model or a weaker model, and then you port it to another model and it's, you know, that
27:18 then the stronger model works worse, right?
27:20 It can be very counterintuitive at times.
27:22 And you just got to you've got to test things out.
27:24 And that really gets to the idea of evals, right?
27:27 So evaluation is really a key problem, right?
27:30 Making sure that if you're going to be writing prompts and you're going to be building, you
27:34 know, different retrieval augmented generation solutions, you need to know about prompt injection
27:39 and you need to know about prompt engineering and you need to know what these things can
27:43 and can't do.
27:44 One trick is what they call few shot prompting, which is, you know, if you wanted to do data
27:49 extraction, you can say, OK, I want you to extract data from text that I give you in JSON.
27:54 If you give it a few examples, like wildly different examples, because the giving it a
27:59 bunch of similar stuff, it might kind of cause it to just coalesce around those similar examples.
28:02 But you can give it a wildly different set of examples.
28:05 That's called in context learning or few shot prompting.
28:08 And it will do a better job at that specific task for you.
28:11 That's super neat.
28:12 When you're creating your apps, you do things like here's the input from the program or from
28:18 the user or wherever it came from.
28:20 But maybe before that, you give it like three or four prompts.
28:23 And then let let it have the question.
28:25 Right.
28:25 Instead of just taking the text, like I'm going to ask you questions about biology and genetics,
28:30 and it's going to be under this context.
28:32 And I want you to favor these data sources.
28:34 Now ask your question.
28:35 Something like this.
28:36 For sure.
28:37 All those types of strategies are worth experimenting with.
28:39 Right.
28:40 Like what actually will work for your scenario?
28:42 I can't tell you.
28:43 Right.
28:43 You got to dig in.
28:44 You got to figure it out.
28:45 And you got to try different different things.
28:47 You're about to win the Nobel Prize in genetics for your work.
28:50 Now I need to ask you some questions.
28:52 For sure.
28:52 That will definitely work.
28:53 And then threatening it that your boss is mad at you is also going to help you too.
28:57 Right.
28:57 For sure.
28:57 If I don't solve this problem, I'm going to get fired.
29:00 As a large language model, I can't tell you, but I'm going to be fired.
29:03 All right.
29:03 Well, then the answer is.
29:04 Exactly right.
29:05 So for these, they run, like you said, they run pretty much locally.
29:09 These, these different models on LM studio and others like the llama file and so on.
29:14 If I had a laptop, I don't need a cluster.
29:16 Llama CPP is really the project that should get all the credit for, for, for making this
29:20 work on your, on your laptops.
29:21 And then llama file and llama CPP all, all have servers.
29:25 So I'm guessing LM studio is just exposing that server.
29:28 Yeah.
29:28 And that's in the base llama CPP project.
29:31 That's really what it is.
29:32 It's really just about now, now you can post your requests.
29:36 It's handling all of the work with regards to the token generation on the backend using
29:41 llama CPP.
29:41 And then it's returning it to using the HTTP, you know, kind of processes.
29:45 Is llama originally from meta?
29:47 Is that where that came from?
29:47 I think there were people that were kind of using that LLM, right?
29:51 I think people were kind of keying off the llama thing at one point.
29:55 I think a llama index, for instance, I think that project was originally called GPT index.
29:59 And they decided, oh, I don't want to be like, I don't want to confuse myself with open
30:02 AI or confuse my project with OpenAI.
30:04 So they switched the llama index and then of course, meta released llama.
30:07 So you can't, you kind of, and then everything from there is kind of evolved too, right?
30:11 There's been alpacas and a bunch of other stuff as well.
30:14 I didn't know your animals.
30:14 Yeah.
30:15 If you don't know your animals, you can't figure out the heritage of these, these projects.
30:18 Correct.
30:19 Llama from meta was the first open source, I'd say large language model of note, I guess,
30:25 since ChatGPT, there were, there were certainly other, you know, I'm not a re so one,
30:29 one thing, the caveat, I am not a researcher, right?
30:32 So there's lots of folks in the ML research community that know way more
30:34 than I do, but because there was like bloom and T5 and a few other large, you know, quote
30:39 unquote, large language models.
30:40 But Llama after ChatGPT, Llama was the big release that came from meta and I think March.
30:45 And then, and that was from meta.
30:47 And then they, they had it released under just like research use terms.
30:51 And then only certain people could access to it.
30:53 And then someone put a, I guess, put like a BitTorrent link or something on, on, on GitHub.
30:58 And then basically the world had it.
31:00 And then they did end up releasing Llama 2 a few months later with more friendly terms.
31:04 So that, and that, and it was a much, a much stronger model as well.
31:07 Nice.
31:08 It's kind of the realization like, well, if it's going to be out there anyway, let's at least
31:11 get credit for it.
31:12 Then for sure.
31:12 And I did read something where like basically Facebook approached OpenAI for access to
31:17 their models to help them write code.
31:18 But the cost was so high that they decided to just go build their own.
31:21 Right.
31:21 So it's kind of interesting how this stuff has evolved.
31:24 Like, you know, we got a big cluster of computers too.
31:26 Metaverse thing doesn't seem to be working yet.
31:29 So let's go ahead and train a bunch of large language models.
31:32 Yeah, exactly.
31:33 We've got some spare capacity over in the metaverse data center.
31:36 All right.
31:36 So one of the things that people will maybe talk about in this space is RAG or retrieval augmented
31:42 generation.
31:42 What's this?
31:43 One thing to recognize is that large language models, if it's not in the training set and
31:48 it's not in the prompt, it really doesn't know about it.
31:51 And the question of like, what's reasoning and what's, you know, generalizing and things
31:56 like that.
31:56 Those are big debates that people are having.
31:58 What's intelligence?
31:58 What have you.
31:59 Recognizing the fact that you have this prompt and things you put in the prompt, the large
32:03 language model can understand and extrapolate from is really powerful.
32:06 So, and that's called in context learning.
32:08 So retrieval augmented generation is the idea of, okay, I'm going to go.
32:12 I'm going to maybe ask a, allow a person to ask a question.
32:15 This is kind of like the common use case that I see.
32:18 User ask a question.
32:20 We're going to take that question, find the relevant content, put that content in the prompt
32:24 and then do something with it.
32:26 Right.
32:26 So it might be something like summer, you know, ask a question about, you know, what,
32:30 you know, how tall is the leaning tower of Pisa?
32:31 Right.
32:32 And so now it's going to go off and, and find that piece of content from Wikipedia or what
32:36 have you, and then put that information in the prompt.
32:38 And, and then, and then now that the model can then respond to that question based on that
32:43 text.
32:44 Obviously that's a pretty simple example, but you can get more complicated and it's going
32:47 out and bringing back lots of different content, slicing it up, putting in the prompt and asking
32:51 a question.
32:52 So now the trick is, okay, how do you actually get that content and how do you do that?
32:56 Well, you know, information retrieval, search engines and things like that.
33:00 That's obviously the technique, but one of the key techniques that people have been, you
33:04 know, kind of discovering, rediscovering, I guess, is this idea of word embeddings or vectors.
33:09 And so word to VEC was this project that came out, I think 11 years ago or so.
33:13 And, you know, there was a big, the big meme around that was you could take the embedding
33:18 for the word King.
33:19 You could then subtract the embedding for the word man, add the word embedding for woman.
33:24 And then the end math result would actually be close to the embedding for the word queen.
33:28 And so what is an embedding?
33:30 What's a vector?
33:30 It's basically this large floating point number that has semantic meaning inferred into it.
33:37 And it's, and it's built just by training a model.
33:39 So just like you train a large language model, they can trade these embedding models to basically
33:43 take a word and then take a sentence and then take a, you know, a document is what, you know,
33:48 OpenAI can do and turn that into this big giant 200, 800, 1500, you know, depending on the size
33:55 of the embedding floating point numbers, and then use that as a, what's called, you know,
34:01 semantic similarity search.
34:02 So you're basically going off and asking for similar documents.
34:05 And so you get those documents and then you make your prompt.
34:08 It's really wild.
34:09 So, you know, we're going to make an 800 dimensional space and each concept gets a location in that
34:15 space.
34:15 And then you're going to get another concept as a prompt and you say, what other things in
34:19 this space are near it?
34:20 The hard problems that remain are, well, first you got to figure out what you're trying to
34:24 solve.
34:24 So once you figure out what you're actually trying to solve, then you can start asking yourself
34:27 questions like, okay, well, how do I chunk up the documents that I have?
34:31 Right.
34:31 And there's all these different, and there's another great place for Lama Index and LangChain.
34:35 They have chunking strategies where they'll take a big giant document and break it down
34:39 into sections.
34:40 And then you chunk each section and then you're, and then you do the embedding on just that small
34:45 section.
34:45 Because the idea being, can you get, you know, finer and finer sets of text that you can then,
34:51 when you're doing your retrieval, you get the right information back.
34:54 And then the other challenge is really like the question answer problem, right?
34:58 If a person's asking a question, how do you turn that question into the same kind of embedding
35:02 space as the answer?
35:03 And so there's lots of different strategies that are out there for that.
35:06 And, and then another, you know, another problem is if you're looking at the Wikipedia page for
35:10 the Tower of Pisa, it might actually have like a sentence in here that says it is X number
35:15 of meters tall or feet tall, but it won't actually have the word, you know, Tower of Pisa in it.
35:19 So, so there's another chunking strategy where they're, they call propositional chunking, where
35:23 they basically use a large language model to actually redefine each word, each sentence so that
35:29 it actually has those proper nouns baked into it so that when you do the embedding, it doesn't lose
35:34 some of the detail with propositions.
35:36 It's this tall, but it's something that replaces this tall with its actual height and things like
35:42 that.
35:42 Correct.
35:42 Crazy.
35:43 But fundamentally, you're working with unstructured data and it's kind of messy and it's not always
35:47 going to work the way you want.
35:48 And there's a lot of challenges and people are trying lots of different things to make it better.
35:52 That's cool.
35:52 It's not always deterministic or exactly the same.
35:55 So that can be tricky as well.
35:58 This portion of Talk Python To Me is brought to you by Neo4j.
36:01 Do you know Neo4j?
36:03 Neo4j is a native graph database.
36:06 And if the slowest part of your data access patterns involves computing relationships, why
36:12 not use a database that stores those relationships directly in the database, unlike your typical
36:17 relational one?
36:18 A graph database lets you model the data the way it looks in the real world, instead of forcing
36:23 it into rows and columns.
36:25 It's time to stop asking a relational database to do more than they were made for and simplify
36:30 complex data models with graphs.
36:32 If you haven't used a graph database before, you might be wondering about common use cases.
36:37 What's it for?
36:38 Here are just a few.
36:40 Detecting fraud.
36:41 Enhancing AI.
36:43 Managing supply chains.
36:44 Gaining a 360 degree view of your data.
36:47 And anywhere else you have highly connected data.
36:50 To use Neo4j from Python, it's a simple pip install Neo4j.
36:56 And to help you get started, their docs include a sample web app demonstrating how to use it
37:01 both from Flask and FastAPI.
37:03 Find it in their docs or search GitHub for Neo4j movies application quick start.
37:09 Developers are solving some of the world's biggest problems with graphs.
37:12 Now it's your turn.
37:13 Visit talkpython.fm/Neo4j to get started.
37:18 That's talkpython.fm/Neo4j.
37:23 Thank you to Neo4j for supporting Talk Python To Me.
37:26 One of the big parts of at least this embedding stuff you're talking about are vector databases.
37:32 And they used to be really rare and kind of their own specialized thing.
37:36 Now they're starting to show up in lots of places.
37:38 And you shared with us this link of vector DB comparison.
37:41 I just saw that MongoDB added it.
37:43 I'm like, I didn't know that had anything to do with that.
37:45 And I'm probably not going to mess with it.
37:47 But it's interesting that it's just like finding its way in all these different spaces, you know?
37:51 It was weird there for a couple of years where people were basically like talking about vector
37:54 databases like they're their own separate thing.
37:56 The vector databases are now becoming their own fully fledged, either relational database
38:01 or a graph database or a search engine, right?
38:03 Those are kind of the three categories where all, I mean, I guess Redis is its own thing
38:07 too.
38:07 But for the most part, those new databases, quote unquote, are now kind of trying to be more
38:11 fully fledged.
38:12 And vectors and semantic search is really just one feature.
38:16 I was just thinking that is, is this thing that you're talking about?
38:18 Is it a product or is it a feature of a bigger product, right?
38:22 Correct.
38:22 If you already got a database, it's already doing a bunch of things.
38:25 Could it just answer the vector question?
38:26 Maybe, maybe not.
38:27 I don't know.
38:28 Exactly right.
38:28 And the one thing to recognize is that, and then the other thing people do is they just
38:32 take NumPy or what have you and just load them all into memory.
38:34 And if you don't have that much data, that's actually probably going to be the fastest and
38:38 simplest way to work.
38:39 But the thing you got to recognize is the fact that there is precision and recall and
38:44 cost trade-off that happens as well.
38:47 So they have to index these vectors and there's different algorithms that are used and different
38:53 algorithms do better than others.
38:54 So you got to make sure you understand that as well.
38:56 So, and one thing you can do is, for instance, pgvector, which comes as an extension for Postgres,
39:02 you can start off by not indexing at all.
39:04 And you should get, I believe, hopefully I'm not misspeaking, you should get perfect recall,
39:08 meaning you'll get the right answer.
39:10 You'll get the, if you ask for the five closest vectors to the, to your query, you'll get the
39:15 five closest, but it'll be slower than you probably want.
39:17 So then you have to index it.
39:18 And then what ends up happening is, you know, the next time you might only get four of those
39:22 five, you'll get something else that snuck into that list.
39:24 If you got time, you're willing to spend unlimited time, then you can get the right answer.
39:29 The exact answer.
39:31 But I guess that's all sorts of heuristics, right?
39:33 You're like, I could, I could spend three days or I could do a Monte Carlo thing and
39:37 I can give you an answer in a fraction of a second.
39:39 Right.
39:39 But it's not, it's not deterministic.
39:41 All right.
39:42 So then we'll walk with my camera.
39:43 So I turn it off.
39:44 I don't know what's up with it, but we'll, yeah.
39:46 So you wrote a cool blog post called, what is a custom GPT?
39:51 And we'll want to talk some about building custom GPTs and with SAPI and so on.
39:56 So let's talk about this.
39:57 Like one of the, I think one of the challenges in why it takes so much compute for these systems
40:02 is like they're open-ended.
40:03 They're like, you can ask me any question about any knowledge in the world, in the humankind,
40:08 right?
40:08 You can, you can ask about that.
40:10 Let's, let's start talking.
40:11 Or it could be, you can ask me about genetics.
40:14 Right.
40:15 Right.
40:15 That seems like you could both get better answers if you actually only care about genetic
40:19 responses.
40:20 You know, how tall is the landing tower and probably make it smaller.
40:24 Right.
40:25 So that's, is that kind of the idea of these custom GPTs or what is it?
40:28 No.
40:28 So custom GPTs are new capability from OpenAI.
40:32 And basically they are a wrapper around a very small subset, but it's still using the open
40:38 AI ecosystem.
40:39 Okay.
40:39 And so what you do is you give it a name, you give it a logo, you give it a prompt.
40:43 And then from there, you can also give it knowledge.
40:47 You can upload PDF documents to it and it will actually slice and dice those PDF documents
40:51 using some sort of vector search.
40:53 We don't know how it actually works.
40:54 The GPT, the cool thing is the GPT will work on your phone, right?
40:57 So I have my phone.
40:58 I can have a conversation with my phone.
40:59 I can, I can take a picture, upload a picture and it will do vision, vision analysis on it.
41:03 So I get all the capabilities of OpenAI GPT-4, but a custom GPT is one that I can
41:09 construct and give a custom prompt to, which basically then says, okay, now you're into your
41:13 point.
41:14 I think maybe this is where you're going with it.
41:15 Like, Hey, now you're an expert in genomics or you're an expert in something and you're
41:18 basically coaching the language model and what it can and can't do.
41:22 And so it's a targeted experience within the large language within the ChatGPT, you know,
41:29 ecosystem.
41:30 It has access to also the OpenAI tools.
41:32 Like, so opening AI has the ability to do code interpreter and Dolly, and it can also hit
41:36 the web browser.
41:37 So you have access to everything.
41:39 But the interesting thing to me is the fact that you can actually tie this thing to what
41:43 are called actions.
41:43 So March, I think of last year, they actually had this capability called plugins that they
41:48 announced and plugins have kind of faded to the background.
41:51 I don't know if they're going to deprecate them officially, but the basic gist with plugins
41:55 is what was you could turn that on.
41:56 It can then call your API.
41:57 And the cool thing about it was that it read your open API spec, right?
42:01 So you, you know, you write an open API spec, which is Swagger, if you're familiar with Swagger,
42:05 and it basically defines what all the endpoints are, what the path is, what the inputs and outputs
42:10 are, including classes or field level information and any constraints or what have you.
42:15 So you can define, fully define your open API spec.
42:18 It can then call that open API spec.
42:20 And it's basically giving it tools.
42:22 So like the example that they say in the documentation is get the weather, right?
42:25 So if you say, what's the weather in Boston?
42:26 Well, ChatGPT doesn't know the weather in Boston.
42:29 All it knows how to do is call it, but you can call an API and figures out how to call the
42:33 API, get that information, and then it can use that to redisplay.
42:36 And that's a very basic example.
42:38 You can do way more complicated things than that.
42:41 It's pretty powerful.
42:41 Okay.
42:42 That sounds really pretty awesome.
42:44 I thought a lot about different things that I might build.
42:46 On your blog post here, you've got some key benefits and you've got some risks.
42:50 You maybe want to talk a bit about that?
42:52 Yeah.
42:53 So the first part with plugins that didn't work as well is that there was no kind of overarching
42:58 custom instruction that could actually teach it how to work with your plugin.
43:01 So if you couldn't put it in the API spec, then you couldn't integrate it with a bunch of
43:05 other stuff or other capabilities, right?
43:08 So the custom instruction is really a key thing for making these custom APIs strong.
43:12 But one warning about the custom instruction, whatever you put in there, anybody can download,
43:16 right?
43:17 Not just the folks at OpenAI, anybody.
43:18 Like basically there's GitHub projects where like thousands of these custom prompts that
43:23 people have put into their GPT.
43:25 So, and there are now knockoffs on GPT.
43:28 So it's all kind of a mess right now in the OpenAI store.
43:31 I'm sure they'll clean it up, but just recognize the custom instruction is not protected and neither
43:35 is the knowledge.
43:36 So if you upload a PDF, there have been people that have been figuring out how to like download
43:40 those PDFs.
43:41 And I think that that might be a solved problem now or they're working on it, but something
43:45 to know.
43:46 The other problem with plugins was I can get a plugin working, but if they didn't approve
43:50 my plugin and put it in their plugin store, I couldn't share it with other people.
43:55 The way it works now is I can actually make a GPT and I can give it to you and you can use
44:00 it directly, even if it's not in the OpenAI store or OpenAI store.
44:03 You know, it is super easy to get started.
44:05 They have like a tool to like help you generate your dolly picture and actually you don't
44:09 even have to figure out how to do the custom instructions yourself.
44:11 You can just kind of chat that into existence.
44:13 But the thing that I'm really excited about is that this is like free playing.
44:17 Like you could do, so the hosting cost is basically all on the client side.
44:22 You have to be a ChatGPT plus user right now to create these and use these.
44:26 But the cool thing as a developer, I don't have to pay those API fees that we were talking
44:30 about, right?
44:30 And if I need to use GPT for, which I kind of do for my business right now, just because
44:35 of how complicated it is, I don't have to pay those token fees for folks using my custom
44:40 GPT at this moment.
44:41 Where's like the billing or whatever you call it for the custom GPT live?
44:45 Is that in the person who's using it?
44:47 Does it have to, it goes onto their account and whatever their account can do or afford?
44:50 Yeah, right now, OpenAI, ChatGPT plus is $20 a month.
44:55 And then there's a Teams version, which I think is either 25 or 30, depending on the number
45:00 of users or how you pay for it.
45:01 That's the cost.
45:02 So right now, if you want to use custom GPTs, everyone needs to be a ChatGPT plus user.
45:07 There's no extra cost based on usage or anything like that.
45:11 In fact, there's talk about revenue sharing between OpenAI and developers of custom GPTs.
45:17 But that has not come out yet as far as like what those details are.
45:20 It does have an app store feel to it, doesn't it?
45:23 There's risks too, right?
45:24 Obviously, anybody can, there's already been like tons of copies up there.
45:28 OpenAI, they're looking for their business model too, right?
45:30 So they could, if someone has a very successful custom GPT, it's well within their right to
45:35 kind of add that to the base product as well.
45:37 Injection is still a thing.
45:39 So if you're doing anything in your actions that actually changes something that is consequential
45:44 is what they call it.
45:45 You better think very carefully, like what's the worst thing that could happen, right?
45:49 Because whatever the worst thing that could happen is, that's what's going to happen.
45:52 Because people can figure this stuff out and they can confuse the large language models into calling them.
45:58 And the more valuable it is that they can make that thing happen, the more effort they're going to put into it as well.
46:03 Yeah.
46:03 Yeah, yeah.
46:04 For sure.
46:05 I just ask, is you think it's easy to solve SQL injection and other forms of injection, at least in principle, right?
46:13 There's an education problem.
46:15 There's millions of people coming along as developers and they see some demo that says the query is like this plus the name.
46:22 Wait a minute, wait a minute.
46:24 So it kind of recreates itself through not total awareness.
46:28 But there is a very clear thing you do solve that.
46:32 You use parameters.
46:32 You don't concatenate strings with user input.
46:34 Problem solved.
46:35 What about prompt injection, though?
46:36 It's so vague how these AIs know what to do in the first place.
46:42 And so then how do you completely block that off?
46:45 Unsolved problem.
46:46 I'm definitely stealing from Simon on this because I've heard him say it on a few podcasts.
46:49 It's just basically there's no solution as far as we know.
46:53 So you have to design and there's no solution to the hallucination problem either because that's, you know, that's a feature, right?
46:59 That's actually what the thing is supposed to do.
47:01 So when you're building these systems, you have to recognize those those two facts along with some other facts that really limit what you can build with these things.
47:09 So you shouldn't use it for like legal briefs.
47:11 Is that what you're saying?
47:11 I think these things are great collaborative tools, right?
47:15 Yeah.
47:15 The human in the loop.
47:16 And that's everything that I'm building, right?
47:17 So all the stuff that I'm building is assuming that the humans in the loop and that the and what I'm trying to do is augment and amplify expertise, right?
47:25 I'm building tools for people that know about genomics and cancer and how to help cancer patients.
47:30 I'm not designing it for cancer patients who are going to go operate on themselves, right?
47:34 That's not that's not the goal.
47:36 The idea is there's a lot of information.
47:38 There's these tools are super valuable from like synthesizing a variety of info.
47:44 But you still need to look at the underlying citations and ChatGPT by itself can't give you citations like it'll make some up.
47:51 It'll say, oh, I think there's probably a Wikipedia page with this link.
47:54 But you actually have to you definitely have to have an outside tool either the web, you know, being which is I would say subpar for a lot of use cases.
48:02 Or you have to have actions that can actually bring back references and give you those links.
48:07 And then the expert will then say, oh, OK, great.
48:08 Thanks for synthesizing this, giving me this info.
48:11 Let me go validate this myself, right?
48:13 Go click on the link and and go validate it.
48:15 And that's really I think that's really the sweet spot for these things, at least for the near future.
48:19 Yeah.
48:19 Don't ask it for the answer.
48:20 Ask it to help you come up with the answer.
48:23 Right.
48:23 Exactly right.
48:24 All right.
48:24 And then have you criticize you when you do have something because then it'll do a great job of telling you everything you've done wrong.
48:29 I'm feeling too good about myself.
48:31 I need you to insult me a lot.
48:32 Let's get going.
48:33 All right.
48:34 Speaking to talk about ourselves, you've got this project called PyPI GPT.
48:38 What's this about?
48:39 I really wanted to tell people that FastAPI and Pydantic because Python, like we were saying earlier, I don't know if it was on the call or not.
48:46 But Python is the winning language.
48:48 Right.
48:48 And I think FastAPI and Pydantic are the winning libraries in their respective fields.
48:53 And they're great.
48:53 And they're perfect for this space because you need an open API spec.
48:57 English is the new programming language.
48:59 Right.
48:59 So Andre Caparthe, who used to work at Tesla and now works at OpenAI, has this pinned tweet where he's basically like, English is like the hottest programming language or something like that.
49:08 And that's really the truth.
49:09 Because even in this space where I'm building an open API spec, 99% of the work is like thinking about the description of the endpoints or the description of the fields or codifying the constraints on different fields.
49:23 Like you can use these greater thans and less thans and regexes, right, to describe it.
49:27 And so what I did was I said, okay, let's build this thing in FastAPI.
49:31 It's just to get an example out for folks.
49:33 And then I turned it on.
49:35 I actually use ngrok as my service layer because you have to have HTTPS to make this thing work.
49:40 Ngrok is so good.
49:41 Yep.
49:41 Yeah.
49:42 I turned that on with an Nginx thing in front of it.
49:44 So this library, to actually use it, you'll have to actually set that stuff up yourself.
49:49 You have to download it.
49:50 You have to run it.
49:50 You have to get, you know, either get it on a server with HTTPS with Let's Encrypt or something.
49:55 Once you've turned it on, then you can actually see how it generates the OpenAPI spec, how to configure the GPT.
50:01 You know, I didn't do much work with regards to like the custom instructions that I came up with.
50:05 I just said, hey, call my API, figure it out.
50:07 And it does.
50:08 And so what this GPT does is it basically says, OK, given a package name and a version number, it's going to go and grab this data from the SQLite database that I found that has this information and then bring it back to you.
50:17 It's the least interesting GPT I could come up with, I guess.
50:19 But it shows kind of the mechanics, right?
50:21 The mechanics of setting up the servers and the application within FastAPI, the kind of the little, you know, things, the little bits that you have to flip to make sure that OpenAPIs or OpenAI can understand your OpenAPI spec,
50:36 bumble through OpenAI and OpenAPI all the time, and make sure that they can talk to each other.
50:40 And then it will then do the right thing and call your server and bring the answers back.
50:45 And there's, you know, there's a bunch of little flags and information you need to know about actions that are, you know, on the OpenAPI documentation.
50:53 And so I tried to try to pull that all together into, you know, one simple little project for people to look at.
50:58 It's cool.
50:58 So you can ask it questions like, tell me about FastAPI, this version, and it'll come back.
51:03 I was hoping to do something a little better, like, hey, here's my requirements file and go, you know, tell me, like, am I on the latest version of everything or whatever, like something more interesting.
51:12 I just didn't have time.
51:13 Can you ask it questions such as what's the difference between this version and that version?
51:17 You could, if that information is in the database, I actually don't know if it is.
51:20 And then obviously you could also hit the PyPI server.
51:23 And I didn't do that.
51:24 I just wanted to, I don't want to be, you know, hitting anybody's server indiscriminately at this point.
51:29 But the, but that would be a great use case, right?
51:32 So like someone could take this and certainly add some, add some capabilities.
51:36 The thing that is valuable that I'm trying to showcase is the fact that ChatGPT and large language models, while they do have the world's information kind of compressed, you know, at a point in time, they are still not a database, right?
51:49 They don't do well when you're basically trying to make sure you have a comprehensive query and you've brought back all the information.
51:55 And they're also not good from like a up-to-date perspective, right?
51:58 There's a cutoff date.
51:59 Thankfully, they finally updated that recently.
52:01 I think it's now April of 2023.
52:03 But at some point, it just doesn't know about newer things.
52:06 And so a GPT is a really interesting way of doing that.
52:09 I'm going to put it out in the universe and hopefully someone will do it.
52:11 Make me a modern Python GPT, which is basically like get the new version of Pydantic and Polars and a few other libraries that ChatGPT does a bad job at just because they, you know, they're in under active development during the time that ChatGPT was getting trained.
52:26 So that's the perfect use case for these types of, you know, custom GPTs with knowledge in a PDF file or an API backing it up.
52:35 I think there's a ton of value in being able to feed a little bit of your information, some of your documents or your code repository or something to a GPT and then be able to ask it questions about it, right?
52:47 Yeah.
52:47 Yeah.
52:47 Like, you know, tell me about the security vulnerabilities that you see in the code.
52:51 Like, is there anywhere where I'm, I'm missing some test or I'm calling a function in a way that's known to be bad.
52:58 And, you know, like that kind of stuff is really tricky, but it's also tricky because it doesn't, even if you paste in a little bit of code, it's not the whole project.
53:06 Right.
53:07 So, you know, to put a little bit more in there, it's pretty awesome.
53:10 Yeah.
53:10 Being able to give it all the code from some of these code repositories, right.
53:14 Like, and bringing back the relevant information.
53:16 So I think there is a kind of this race.
53:18 There's going to be other, you know, cool, there's another cool project called Sourcegraph and Codi that we can talk about that will, you know, run on your local server and basically indexes your code base and will bring back relevant snippets from your code base and answer questions kind of in context.
53:33 And, you know, long-term and then the new project around new Codeium, they had a new paper where they talked about flow engineering and flow engineering is just basically that I, that same concept of the human in the loop with the LLM with the code.
53:47 That's the magic combination of kind of those people, those entities kind of iterating with each other.
53:52 I think these, you know, these tools are definitely going to evolve and you really want to, you really want to have the ability to have access to your specific information to answer your specific questions.
54:02 Codi is new to me.
54:03 Codi.dev and it's a little subtitle or whatever is Codi as a coding assistant that uses AI, understand your code base, right.
54:12 It was saying it was about your entire code base, APIs, implementations and idioms.
54:16 Like that's, it's kind of what I was suggesting, at least for code, right.
54:19 Yeah. And source graph, those folks really understand code indexing and searching.
54:24 Like that's what the first product was.
54:26 They were kind of just teed up ready for this large language model moment.
54:28 And then they said, oh, let's just put Codi on top of that.
54:31 So this thing will run, it will understand your code and it will kind of bring things together for you.
54:36 So these folks do, do podcasts all the time.
54:38 I'd, I'd reach out to them.
54:39 Yeah. Interesting. It's, it's quite neat looking.
54:41 I think I'm going to give it a try.
54:42 It both plugs into a charm and VS Code.
54:45 That's pretty neat.
54:46 Very cool.
54:46 We're starting to get a little bit short on time here, but for people who want to play with the PyPI GPT, maybe as an example, to just cut the readme and it's easy to get from there.
54:55 What do you need to tell them?
54:56 I put a make file in there.
54:57 So, you know, exactly like the steps to kind of make the environment, download the files and just ping, ping me, follow me on Twitter.
55:03 I'm more and ping me if you need anything there.
55:06 I'm also on LinkedIn and, and get up.
55:08 Right.
55:08 So you can certainly reach out if you, if you have any challenges.
55:11 Excellent.
55:12 The last thing that folks that are actually in the medical space, right?
55:15 So the thing that I'm working on right now actively is how to integrate this thing with our knowledge base.
55:21 Right.
55:21 So I have a knowledge base of hand curated trials and curated therapies and other information built it so that my custom GPT can actually work with that.
55:30 Come up with some, I'd say novel.
55:32 At least I haven't seen anybody else and I haven't seen any research approaching things the same way I am that handles some of the other challenges that are out there.
55:40 Right.
55:40 So for instance, the context window is a challenge.
55:43 So the context window is the amount of text that's in there and, and how, and how it gets processed.
55:48 If you're making decisions and you're changing course, the chat bot will lose track of, of those changes.
55:56 Right.
55:56 So if you're, you know, experimenting or, or going down one path of inquiry and then you switch to another path, it can get confused and forget that you switch paths.
56:05 Or just run out of space to hold all that information.
56:08 Like, well.
56:08 For sure.
56:08 It forgot the last three things, the first three things you told it.
56:11 It only knows four and you think it knows seven and it's working incomplete.
56:14 Right.
56:15 Yep.
56:15 And, and, you know, one of the key things is you actually want it to forget some things as well.
56:20 Right.
56:20 So those are, that's, those are all interesting challenges.
56:22 And I'm actually working with these custom GPTs to kind of change the way that the collaboration works between the human, the expert, the large language model or the assistant and my backend, my actual, the retrieval model.
56:37 The, the API that's actually doing stuff.
56:39 So are researchers and MDs and PhDs at your company talking with this thing and making use of it?
56:46 Yeah.
56:46 I mean, we're in active development right now.
56:47 We have a few key opinion leaders that are, that are working with us and collaborating with us, but we're always looking for more folks that, that are in the field that actually.
56:55 And right now you need kind of the cutting edge people.
56:58 This stuff's not ready for prime time.
56:59 Clinical decision support is a really hard problem.
57:02 And we, but we need the folks that are, that want to get ahead of it because, because we know that there are doctors and there are patients that are asking ChatGPT questions right now.
57:11 And even if it says I'm not a medical expert, blah, blah, blah.
57:13 And at the end of the day, we actually don't have enough doctors, right?
57:16 That's the other scary thing is we don't have enough doctors.
57:19 Patients want answers.
57:20 How do we build solutions that can allow this expertise to get more democratized and more, you know, more into folks' hands?
57:27 And, and I'm hoping, hoping our tool along with these large language models can help, help relieve some of that burden.
57:33 It might not be as a hundred percent accurate, a hundred percent precise, but neither are doctors, right?
57:38 They get stuff wrong.
57:39 You just need to be in the realm of as good as a doctor.
57:43 You don't need to be, you know, completely without making a mistake.
57:47 And that's a, I think a challenge that we're just going to have to get used to in general.
57:52 I joked about the legal brief thing because someone got in trouble for submitting a brief that had hallucinations in it.
57:59 And there's certain circumstances where maybe it's just not acceptable, but AI, self-driven cars, people crash, but that's a, like a human mistake.
58:07 But when a machine makes it, it's a pre-programmed, pre-determined mistake.
58:12 You know, something like that, like it doesn't feel the same as if the machine made a mistake.
58:15 So if a machine makes a recommendation, like you need this cancer treatment or you're fine, you don't need it.
58:21 And it was wrong.
58:22 People are not going to be as forgiving, but it doesn't mean there's not value to be gained from systems that can help you.
58:29 Right.
58:29 I always appreciate those, those machine learning papers that I'll like, you know, there'll be show the tracking of over time of like how the models have gotten better and better.
58:36 And they put the human in there and you can see that the human has already gotten eclipsed by the, by the models.
58:41 And that specific problem, right?
58:42 Because it's not also recognizing that a lot of this stuff, these models that are doing tasks are doing one specific task.
58:48 They're not doing a whole job.
58:49 They're not, they're not doing an end to end process.
58:51 They're answering a medical question or they're, you know, looking at an image and finding all the cats or whatever it's supposed to do.
58:57 So, and to your point though, you know, humans aren't perfect at these tasks either.
59:02 I think mostly people are going to be using this kind of stuff to help them come up with these answers.
59:06 Right.
59:06 The, my weird Amazon description example is going to be the edge case, not the go-to like.
59:12 Agreed.
59:12 Yeah.
59:13 You came in, you spoke to the chat bot.
59:15 Here's your diagnosis.
59:16 Have a good day.
59:16 Right.
59:17 Not so much more like, I need some help thinking through this.
59:20 What are some of historic, what are some studies that have like addressed this?
59:24 Right.
59:24 And like those kinds of questions.
59:25 And I hesitate to say it's just a better search engine because that's, I actually think it's got way more potential than that.
59:30 I agree.
59:31 It's a conversation.
59:32 It can iterate back and forth.
59:34 And what I'm actually trying to do is build some state into it.
59:37 Right.
59:37 Some, some structured way of kind of remembering what the conversation was and using a lot of the techniques that these large language models are good at to actually, to make that actually happen.
59:47 And so that you can actually build a system so that the human and the assistant and the backend all kind of know what the other party is thinking about and that they all work together.
59:56 Nice.
59:57 For your genomics custom GPT thing that you're making internally, is that going to become a product eventually?
01:00:03 If other people are interested, is there some way they can keep tabs on it or is it just internal only?
01:00:08 Definitely reach out to me.
01:00:09 So we're building different versions of GPTs.
01:00:11 Like we're going to have a GPT for our curation team that curates knowledge and we're building a GPT that, you know, my hope is that it'll go to physicians, to oncologists and genomic counselors and other providers that could actually use this thing.
01:00:23 Eventually, if it becomes robust enough and stable enough, and I don't feel like we're doing a disservice, we could certainly make a version of that available for cancer patients as well.
01:00:32 I would, you know, I'd love to have that.
01:00:34 I just want to make sure that it's done in a responsible way.
01:00:36 Yeah, absolutely.
01:00:37 Well, I honestly hope that you actually do such a good job that we don't have to have cancer research anymore, but that's a long, long term goal, right?
01:00:46 That is definitely the end goal.
01:00:48 And that's really exciting too.
01:00:49 So is that the new drugs that are coming out, new treatments that are coming out, it's really just about making sure people are aware of it, making sure that they're getting the genetic testing that they need, right?
01:00:59 So if you have a loved one that has, unfortunately has cancer, make sure that they're at least asking their doctor the question about genomic testing to make sure that they're getting the best possible treatment.
01:01:08 Sounds good.
01:01:09 All right.
01:01:09 Well, quickly, before we get out of here, recommendation on some libraries, some project that maybe we haven't talked about yet.
01:01:16 Something came across, people were like, oh, this would be awesome.
01:01:18 We ran out of time.
01:01:19 I was going to talk about some of these Pydantic projects.
01:01:21 So there's Marvin, Instructor, and Outlines.
01:01:24 So folks should definitely look at those.
01:01:27 So basically what you do is you can describe stuff as Pydantic, and then it'll actually just extract it right into that Pydantic model for you.
01:01:34 And that's some Marvin and Outlines and Instructor.
01:01:36 So check those guys out.
01:01:37 They're awesome.
01:01:38 And then the other one that I actually had teed up was VisiCalc.
01:01:41 So VisiCalc is like this crazy command line tool.
01:01:45 It's awesome.
01:01:45 You can basically look at giant CSV files all on the command line.
01:01:49 It has these hotkeys that you can do.
01:01:51 And it's, sorry, not VisiCalc, VisiData.
01:01:54 VisiData, okay.
01:01:54 And so basically it's just, it's basically Excel inside your terminal.
01:01:58 And this was before Rich and Textual Project.
01:02:02 And it was just like, it was kind of mind-blowing all the stuff that this person was able to figure out how to make work.
01:02:07 That's super amazing.
01:02:07 I just wanted to give a shout out one more thing because your VisiData reminded me of something I just came across called BTOP.
01:02:14 I don't know if you have servers out there and they need to know what's going on with their server.
01:02:18 Where's mine?
01:02:19 I need a picture for this.
01:02:20 But yeah, it's like a nice visualization.
01:02:23 There's also B-HITOP.
01:02:26 It's pretty amazing what people can do in the terminal, right?
01:02:28 Oh, there they are.
01:02:29 They're just responsive design themselves out.
01:02:31 But yeah, if you want a bunch of live graphs.
01:02:33 Every time I see stuff like this, the VisiData or this or what textual folks are working on, it's just like, I can't believe they built this, right?
01:02:41 Like, I'm working at the level of colorama.
01:02:43 This string is red right here.
01:02:45 They're like, oh, yeah, we rebuilt it.
01:02:47 I got an emoji to show up, right?
01:02:49 I'm excited.
01:02:49 Yes, exactly.
01:02:49 Yes.
01:02:50 A rocket ship is there, not just tech.
01:02:53 Yeah.
01:02:54 Pretty excellent.
01:02:55 All right.
01:02:55 Well, Ian, thank you for being here.
01:02:58 And keep up the good work.
01:03:00 I know so many people are using LLMs, but not that many people are creating LLMs.
01:03:05 And as developers, you know, we love to create things.
01:03:08 We already have the tools to do it.
01:03:09 People can check out your GitHub repo on the PyPI and GPT and use it as a starting place, right?
01:03:15 Sounds great.
01:03:16 Yeah.
01:03:16 And definitely reach out if you have any questions.
01:03:19 Excellent.
01:03:19 Well, thanks for coming back on the show.
01:03:21 See you later.
01:03:21 Great.
01:03:22 Good to talk to you.
01:03:22 Bye-bye.
01:03:23 Yeah, you bet.
01:03:23 Bye.
01:03:24 This has been another episode of Talk Python To Me.
01:03:27 Thank you to our sponsors.
01:03:29 Be sure to check out what they're offering.
01:03:31 It really helps support the show.
01:03:32 Take some stress out of your life.
01:03:34 Get notified immediately about errors and performance issues in your web or mobile applications with Sentry.
01:03:40 Just visit talkpython.fm/sentry and get started for free.
01:03:45 And be sure to use the promo code TALKPYTHON, all one word.
01:03:49 It's time to stop asking relational databases to do more than they were made for and simplify complex data models with graphs.
01:03:57 Check out the sample FastAPI project and see what Neo4j, a native graph database, can do for you.
01:04:04 Find out more at talkpython.fm/Neo4j.
01:04:09 Want to level up your Python?
01:04:10 Want to level up your Python?
01:04:10 We have one of the largest catalogs of Python video courses over at Talk Python.
01:04:14 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:04:19 And best of all, there's not a subscription in sight.
01:04:22 Check it out for yourself at training.talkpython.fm.
01:04:25 Be sure to subscribe to the show.
01:04:27 Open your favorite podcast app and search for Python.
01:04:30 We should be right at the top.
01:04:31 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:04:36 and the direct RSS feed at /rss on talkpython.fm.
01:04:41 We're live streaming most of our recordings these days.
01:04:43 If you want to be part of the show and have your comments featured on the air,
01:04:47 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:04:51 This is your host, Michael Kennedy.
01:04:53 Thanks so much for listening.
01:04:55 I really appreciate it.
01:04:56 Now get out there and write some Python code.
01:04:58 I'll see you next time.