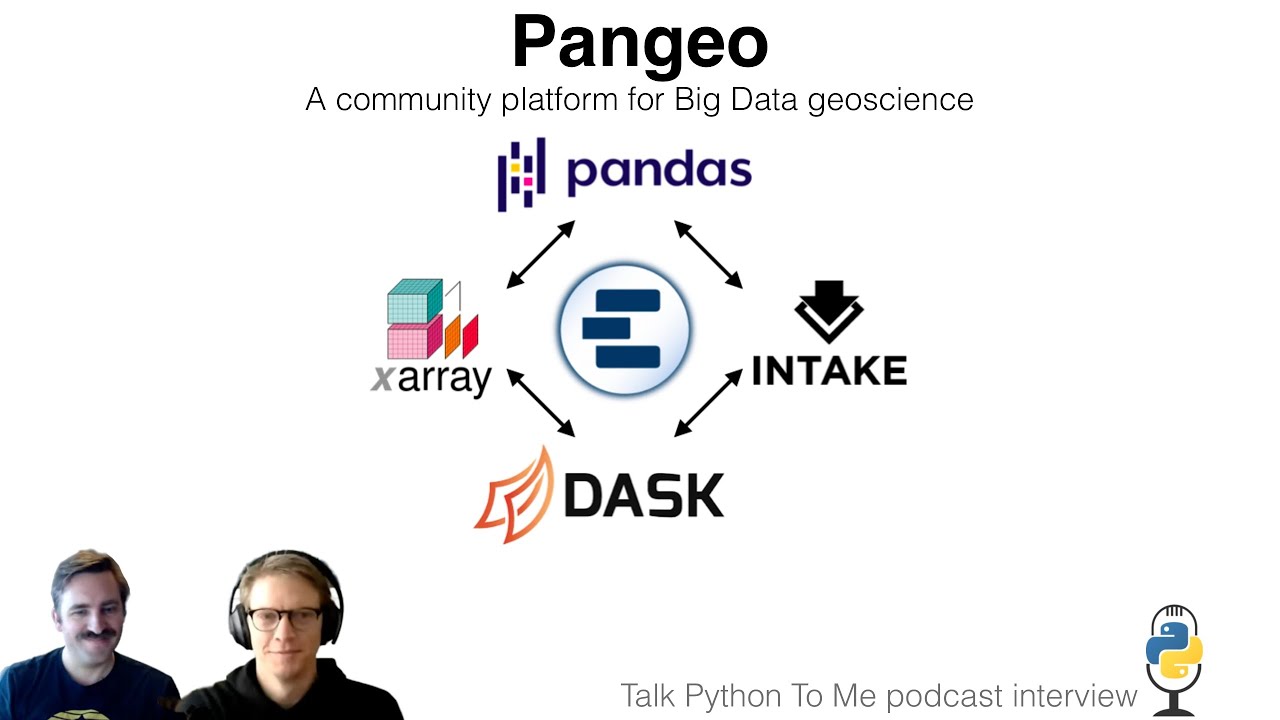
Pangeo Data Ecosystem



Panelists


Episode Deep Dive
Guests Introduction and Background
Joe Hamman is the Technology Director at CarbonPlan and also a scientist at the National Center for Atmospheric Research (NCAR). He comes from a civil engineering and computational hydrology background, where he transitioned from Perl, Fortran, and other older tools to Python. Joe has helped bring modern Python tools and open-source contributions into his research lab and broader scientific communities, with a special focus on hydrology, forest management, and climate data analysis.
Ryan Abernathey is a professor at Columbia University’s Lamont-Doherty Earth Observatory, where he leads a research lab specializing in computational oceanography. He has a longstanding background in programming, dating back to writing BASIC code at age seven. Today, Ryan uses Python for analyzing massive Earth science datasets (e.g., satellite data for ocean surface temperatures) and for open-source work, especially around Xarray and the broader Pangeo ecosystem.
What to Know If You're New to Python
Below are some quick points to help you get more out of this episode. These will prepare you to follow the discussion on powerful Python libraries and data-focused workflows:
- Make sure you understand basic Python scripting, functions, and data structures (lists, dicts, etc.).
- Experiment with data libraries like pandas to see how Python handles tabular data.
- Try out Jupyter notebooks for an interactive, iterative coding approach that many scientists use.
Key Points and Takeaways
Pangeo as a Community-Driven Ecosystem
This project started with a small workshop on scaling climate and weather data analytics with Python. The community has grown into a broad collaboration that brings scientists, software developers, and data providers together to solve the massive data challenges in Earth sciences. The Pangeo ecosystem centers on open-source projects (like Xarray and Dask) and focuses on reproducibility, big-data workflows, and cloud computing.- Links and Tools:
- Pangeo Project
- Pangeo Discourse Forum (the main place to ask questions and connect with the community)
- Pangeo Gallery (Jupyter notebooks demonstrating real-world use cases)
- Links and Tools:
Xarray: Multidimensional Arrays with Labels
Often dubbed “multi-dimensional Pandas,” Xarray allows you to handle large collections of netCDF or related scientific files as one coherent dataset. It supports labeled dimensions (e.g., time, latitude, longitude), understands metadata, and can open multiple files as if they were one big dataset. This eliminates repetitive code for reading files in loops and handling manual indexing, greatly simplifying research workflows.- Links and Tools:
Dask for Scalable Parallel Computing
Dask provides on-the-fly chunking and parallelization for Python data structures, including dataframes, arrays, and Xarray objects. This means you can write code almost identical to the single-machine version, but under the hood, Dask will handle distributing work across cores or even multiple servers. It’s not “pure magic”—understanding chunk sizes and data access patterns is still crucial—but it unlocks workflows for datasets far larger than RAM.- Links and Tools:
- Dask
- Coiled (commercial Dask hosting solution)
- Fundamentals of Dask (in-depth course on how to use Dask effectively)
- Links and Tools:
Cloud Object Storage as the New Data Portal
Traditional “data portals” often involved custom websites for file downloads. Pangeo encourages storing large scientific datasets (e.g., satellite or climate data) in object storage like Amazon S3, Google Cloud Storage, or other vendors. This approach decouples the storage from a single server and allows easy partial reads, integration with tools like Dask, and more flexible scaling for diverse users.- Links and Tools:
- Amazon S3
- Google Cloud Storage
- FSSpec (Python library for uniform file access across various backends)
- Links and Tools:
Open Science Requires More Than Uploading Code to GitHub
Both guests emphasized that open science is about collaborative workflows, reproducible data processing, and building on each other’s tools. Simply uploading code with a license is insufficient; you also need accessible data, environment details, documentation, and an active community to help others adopt and extend your work. This broader perspective drives projects like Pangeo, where packages like Xarray, Dask, and Jupyter are co-evolving to meet real research needs.- Links and Tools:
- GitHub (host your code but think beyond a simple repo)
- Pangeo Discourse Forum (active community for open-science questions)
- Links and Tools:
Transition from Spaghetti Scripts to Collaborative Frameworks
Many labs were using scattered scripts in Perl, C, Fortran, or shell. Shifting to Python with best practices like Xarray and conda environments has dramatically accelerated research. Researchers can prototype faster, share knowledge, and scale out to HPC or cloud-based clusters with fewer custom workflows.- Tools Mentioned:
- conda (environment management for scientific Python)
- [Fortran/Perl/C to Python migrations](various references in transcript, no official link)
- Tools Mentioned:
Jupyter Notebooks in the Cloud
An essential part of Pangeo is running Jupyter or JupyterLab on cloud platforms, close to large datasets. Instead of downloading massive data, you spin up notebooks on Google Cloud, AWS, or HPC systems, saving time and storage costs. Jupyter Lite is an interesting twist for small data or demos (running Python in the browser), but the real large-scale number crunching happens when you connect notebooks to Dask clusters running on remote infrastructure.- Links and Tools:
Pangeo Forge for ETL (Extract-Transform-Load) Pipelines
Many open-source ETL tools are geared toward business-style data rather than multi-dimensional science data. Pangeo Forge aims to address this gap by automating the conversion of diverse data sources into cloud-friendly, chunked, and metadata-rich formats that Xarray and Dask can easily load. This improves accessibility for large, disparate datasets like climate model outputs and satellite imagery.- Links and Tools:
- Pangeo Forge (GitHub organization)
- Pangeo Forge Recipes
- Links and Tools:
Big Data in Earth Sciences: Petabytes of Climate Data
Modern research in climate science, oceanography, and meteorology deals with massive data from satellites (SST—sea surface temperature), high-resolution climate models, and new NASA missions. The standard approach is to keep these data on HPC or cloud storage. Tools like Dask + Xarray let scientists handle these petabyte-scale datasets piecewise, retrieving only what they need without rewriting custom code for each study.- Examples:
- NASA’s upcoming surface water and ocean topography data
- CMIP6 (Coupled Model Intercomparison Project) datasets
- Examples:
Collaboration Between Academia and Industry
Researchers are noticing that businesses are increasingly adopting climate data for both adaptation (planning for changing climate) and mitigation (reducing emissions). Python, with Pangeo’s open-source ecosystem, helps unify these efforts. This cross-pollination has improved the tooling and driven new features like ephemeral Dask clusters and integrated data catalogs.
- Links and Tools:
- CarbonPlan (Joe’s organization working on open-data climate solutions)
- [Azure, AWS, GCP climate data marketplaces](various references)
Interesting Quotes and Stories
On the shift to Python in research:
Joe: “We were doing lots of computer things…my PhD advisor said, ‘We want to do Python stuff. You should be the guinea pig student to bring our group into the modern era.’”On open science in practice:
Ryan: “Just putting a repo up on GitHub has essentially no impact if no one can run it. We want to accelerate velocity of discovery, and that means documentation, data, everything.”On the power of Jupyter as a Trojan horse for cloud:
Ryan: “The hardest way to run Jupyter is probably on your own machine. Once you’re on the cloud, it’s easy—and the data is already there.”
Key Definitions and Terms
- Xarray: A Python library that brings labeled multi-dimensional arrays and datasets, making it simpler to handle netCDF files, satellite data, and other high-dimensional data.
- Dask: A parallel computing library for Python that scales from single-core to multi-node clusters, often used for big-data analysis in the Python ecosystem.
- Object Storage: A form of data storage (e.g., AWS S3, Google Cloud Storage) where data is stored as objects rather than in a traditional filesystem or database, enabling large-scale data sharing and partial retrieval.
- ETL (Extract, Transform, Load): A process for collecting data from various sources, transforming it into a usable format, and loading it into a destination system.
Learning Resources
Below are some resources to help you dive deeper into Python and data workflows discussed in this episode:
- Python for Absolute Beginners — A foundational course to help you learn Python from square one.
- Fundamentals of Dask — A detailed look at parallelizing workflows with Dask, which is central to Pangeo.
- Xarray Documentation — Official docs showing how to use Xarray.
- Pangeo Discourse Forum — The main community hub for discussing open science, big data, and climate analytics.
Overall Takeaway
The Pangeo ecosystem stands at the intersection of big-data analytics, cloud computing, and open science, empowering climate researchers and beyond. By leveraging Python tools like Xarray, Dask, and Jupyter, teams can seamlessly analyze massive datasets without reinventing the wheel or building unwieldy, one-off scripts. Pangeo’s core ethos—community collaboration, reproducibility, and a shared commitment to transparency—offers a scalable model for any data-intensive field, inspiring both scientists and developers to build tools that are robust, open, and truly impactful.
Links from the show
Joe Hamman: @HammanHydro
Pangeo: pangeo.io
xarray: xarray.dev
Pangeo Forge: pangeo-forge.org
fsspec: filesystem-spec.readthedocs.io
Step-by-Step Guide to Building a Big Data Portal: medium.com
Coiled: coiled.io
Pangeo Gallery: gallery.pangeo.io
Pangeo Quickstart: pangeo.io
JupyterLite: jupyterlite.readthedocs.io
Jupyter: jupyter.org
Pangeo Packages: pangeo.io
Pangeo Discourse: discourse.pangeo.io
Watch this episode on YouTube: youtube.com
Episode #361 deep-dive: talkpython.fm/361
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Python's place in climate research is an important one. In this episode, you'll meet
00:03 Joe Heyman and Ryan Abernathy, two researchers using powerful cloud computing systems and Python
00:09 to understand how the world around us is changing. They are both involved in the Pangeo project,
00:14 which brings a great set of tools for scaling complex compute in the cloud with Python.
00:19 This is Talk Python To Me, episode 361, recorded April 1st, 2022.
00:25 Welcome to Talk Python To Me, a weekly podcast on Python. This is your host, Michael Kennedy.
00:43 Follow me on Twitter where I'm @mkennedy and keep up with the show and listen to past episodes
00:48 at talkpython.fm and follow the show on Twitter via at talkpython. We've started streaming most
00:54 of our episodes live on YouTube. Subscribe to our YouTube channel over at talkpython.fm
00:59 slash YouTube to get notified about upcoming shows and be part of that episode. This episode is
01:06 sponsored by SignalWire and Sentry. Transcripts for this and all of our episodes are brought to you by
01:12 Assembly AI. Do you need a great automatic speech-to-text API? Get human-level accuracy in just a few lines
01:17 of code. Visit talkpython.fm/assemblyAI. Joe, Ryan, welcome to Talk Python To Me.
01:24 So much for having us. Hey, it's great to be here. It's fantastic to have you here. I'm really excited
01:28 to talk about earth science and all the cool large-scale computing stuff and cloud computing and
01:36 things like that with you. It'll be a lot of fun. So really looking forward to getting into that. Now,
01:41 before we dive into the topics, let's just start with your story. Joe, I guess you go first. How'd you
01:46 get into programming in Python? My path came through grad school. I was studying civil engineering and
01:51 climate modeling as a graduate student at the University of Washington. I was in a computational
01:56 hydrology group. So we were doing lots of computer things. And my PhD advisor at the time was like,
02:01 we want to do Python stuff. I don't know anything about it, or I don't know much about it. You should
02:06 be the kind of the guinea pig student to bring our group into the modern era. So it kind of threw me to
02:12 the wolves. And I ended up really kind of taking on a role that not just learned it, but then started
02:17 teaching other people and I ended up contributing to open source packages and the rest is history.
02:22 Oh, that's fantastic. What were you using before? You said you brought them into the modern era. Where were you
02:27 coming from? What was the dark ages?
02:29 Some terrible mix of like Perl and Seashell and C and Fortran and a bunch of other shell scripting
02:37 languages. So it was a total spaghetti land.
02:39 Wow. That is a spaghetti land. I would say Python and Jupyter and the PyStack probably sounds a little
02:45 simpler. Yeah. The connections are a little more natural for sure.
02:48 Indeed. How did people receive it?
02:49 It's been great. I think for me personally, it was like quite revolution in what was possible,
02:55 but then passing it around the lab and then around kind of the research community since then,
03:00 it's been overwhelmingly positively received and we're doing totally different things than we could
03:05 have done without it. And I think that's the big change. It's not just that it's like a little easier
03:09 to program, but that you can do things that you couldn't have done before.
03:13 Interesting. Yeah. Were people worried that, you know, coming from C and Fortran that Python wasn't
03:18 fast enough? They're like, we can't use this. This is one of these slow scripting languages.
03:21 Or was it, you'd already proven and it was fine.
03:24 No, I think, I mean, you hear that on occasion, but I think the developer velocity
03:28 outweighs that in 99% of the cases.
03:31 Yeah, I agree.
03:31 You can always optimize the 1% case further.
03:34 For sure. Ryan, how about you? How'd you get into programming in Python?
03:37 Kind of been a lifelong programmer. So I was actually just thinking back when you asked that,
03:40 I think I wrote my first basic code at age seven. My dad worked for IBM. And so I'm like,
03:45 really been like a kind of lifelong computer nerd. Drifted away from that a little bit in college,
03:51 where I majored in physics. But then, you know, in graduate school, I did a PhD in climate physics
03:56 and chemistry at MIT. And, you know, I had a huge need for scientific computing in that. So all of a sudden,
04:03 sort of my computer, you know, stuff started really coming back full and center of my world.
04:09 It was a MATLAB shop, you know, MATLAB Fortran was the stack, you know, there.
04:15 After I sort of did my first project around 2006, 2007 in MATLAB, I decided, you know,
04:22 I just, I'd been doing open source hackery for in other languages for many years. And I was like,
04:27 I got it. I need an open source scientific computing solution. So I tried Python, got into Python around
04:33 2008. So that was when like, I've been at it long enough to have like compiled NumPy.
04:38 Yeah, that's like really when NumPy was basically coming out is right around that time.
04:42 Yeah.
04:43 Or Anaconda and the other one, you know, then just rolled with it ever since. And I,
04:48 so I was like the early adopter Python guy around there. I like helped get a lot of other people
04:52 into it, but it was still always just in my own projects, right? Like there was no community.
04:58 I really got into open source community development probably around 2014, 2015,
05:04 when I discovered X-Array. That is like the project that really like turned me from just
05:09 a user to a contributor.
05:11 Fantastic. Yeah. That's like multi-dimensional NumPy goodness, right? Yeah. We'll dig into it.
05:17 Yeah. Was that other distribution to Anaconda? Was that Canopy? I see out in the audience. Thank you,
05:24 Erie. Cool. The other one I was thinking of was ActiveState. So yeah, there's these,
05:28 these different distributions people can get for optimizing for different stuff. It's great.
05:32 Ryan, what are you doing day to day? It sounds like you both are still doing research university-like
05:37 things. Absolutely. So I'm a professor here at Columbia University in Lamont-Darody Earth
05:41 Observatory. And I sort of manage a medium-sized scientific research lab and teach at the university.
05:49 But then I like wear this total other hat as like open source developer and contributor.
05:53 That can be sometimes a little exhausting to try and wear both those hats at the same time.
05:58 But I really enjoy it. Our work in our lab is focused on computational oceanography,
06:03 trying to understand the role the ocean plays in the climate system, particularly the role that small
06:09 scale ocean processes, eddies, fronts, instabilities that are occurring at the say 10 to 100 kilometer
06:18 scale, how that sort of turbulence and variability influences a large scale ocean and the role it plays
06:25 in our changing climate. Right.
06:26 So the way we do that research is by working with large scale satellite data from NASA. So I'm involved
06:32 in the NASA surface water and ocean topography science team, a new satellite mission that's launching
06:38 this year. I do a ton of numerical modeling, simulating the ocean with computers. At the end of the day,
06:44 we're doing data analysis. Some of which was just sort of traditional statistics and visualization.
06:49 increasingly machine learning, AI, ML are part of our toolkit that we use to try and understand the ocean.
06:55 But the bottom line is, yeah, just working with a lot of data every day, diverse projects,
07:00 that has really forced me to center the rule of these tools in our work and recognize them as sort of
07:07 that is our, like a lot of my colleagues, you know, in other buildings at our lab, like they'll have
07:12 like a million dollar mass spectrometer. You know, they have like an instrument they use to do science.
07:18 Some crazy laser or something. Right. And they like turn the crate and like, we just,
07:22 we're like a data driven lab. And so I think a Pangino in a way is our instrument that we all
07:28 contribute to and maintain that then helps us to do all of the research projects that we want to pursue.
07:34 Yeah. How fascinating. You talked about running a research lab and then also doing this open source
07:40 thing, this dual hat thing. The world may has changed, but when I took a couple of computer science
07:45 classes at university, when I was my undergraduate degree, I didn't feel like a lot of the,
07:50 the instructors or professors there really had much real world experience in programming and stuff.
07:57 And I think things like this, like contributing to X-Array, it must give you this really grounded
08:02 sense of that. Not only these are the tools that you can use, but like, here's how it works. These are
08:07 the people doing it. Like you're in the trenches. Like, do you think that makes a big difference?
08:10 I think we have a major education problem around computational science. And I say this as someone,
08:16 like a university professor, like we have no curriculum to teach someone how to be like an
08:22 effective computational science. And particularly in the context of like open source community driven
08:28 software development, we have computer science classes that will teach you a lot of great things
08:32 about algorithms and data structures and even machine learning, but they won't teach you how to like
08:37 write effective software. And as you said, you have currently, we assume you have to learn that in
08:42 the trenches, just getting into a project. Maybe you work at a company for me, definitely. I upped my
08:48 software engineering team so much after I got involved in community open source, because there were people
08:53 like Stefan Hoyer, you know, you know, Google staff engineer who were like reviewing my PR.
08:58 Right. So that was huge. But I wish actually the university could teach this skill set because I
09:03 think it would help the world a lot. Yeah, I think it would as well. I think we can absolutely find space
09:09 in the curriculum for it. I think math might need to give up a little bit to allow for computational
09:16 math rather than symbolic math. If I could pick, I don't want to do realist too much. And I would do
09:21 want to let Joe get a chance to talk as well. But I think geometry and the going through proofs
09:26 and the thinking about how do I take axioms and using proofs to solve problems is exactly the same
09:32 mindset and the way of thinking as solving a computer program or solving a problem with a program.
09:37 And I haven't applied geometry that much, but I've sure applied a lot of computers. So anyway,
09:41 I just put that out there for people. You might be a little biased.
09:44 I may be a little biased, although I do have two math degrees for what it's worth,
09:48 but I'm still willing to put geometry out there. Anyway, Joe, how about you? What are you doing
09:53 these days? Yeah, so I wear a couple of hats as well. My main hat is I'm the technology director
09:57 at CarbonPlan, a nonprofit that's working on the climate problem. And our focus is really on
10:04 improving the transparency and the scientific integrity and quality of climate solutions.
10:09 We do that by building open source tools and open data and doing research into the various climate
10:16 solutions that are out there. So we use a lot of open source software to do that. And we build a lot
10:20 of open source tooling, including software to help tell stories about different climate solutions.
10:26 The other hat I wear, I'm a scientist at the National Center of Bramispheric Research,
10:29 where that part of my role looks a lot like Ryan's day to day. Yeah, we study different things, but
10:35 I work with big climate model data and do data analysis and all of that.
10:38 Yeah, sounds really fascinating. At CarbonPlan, what kind of data do you all use? Do you hook into electric grids?
10:45 Do you analyze the mixture of electric grids or transportation or what kind of problems and things
10:51 are you solving there? It's a bit of everything. We do big data, little data and everything in between.
10:56 But, you know, so like one of the areas we spend a lot of time working is in the area of forest offsets
11:01 and trying to ask questions about the quality and the potential of using forests as a climate solution.
11:07 And so there we're using everything from in situ observations where people go out and measure trees
11:13 with a tape measure. And they do that every five years. And that's like actually a fairly small data
11:17 set, even though there's a lot of trees out there. It's just there's only so many measurements you can make.
11:22 And then we also work with climate model data. We study climate risk to forests. And so there we're
11:28 building models of future forest fire risk and trying to understand how that's going to change in the
11:35 future. So that's like big data stuff. We're doing lots and lots of model building and machine learning
11:41 and that sort of thing on top of climate model data. Sounds fascinating. You and I are both in the
11:44 Pacific Northwest and last year was not too terrible for fire season, but recently we've had some pretty bad
11:51 forest fires up here and it's definitely concerning. So yeah, it definitely feels like I'm studying the
11:57 world around me more than ever when we're working on these fire problems and then also experiencing the
12:03 smoky weather that we've been having in the summers in the West Coast last few years.
12:07 Yeah, it's been pretty crazy. And I mean, I think that's a theme in climate science right now. It's gone
12:12 very quickly from this academic problem to something that so much of society and our economy is engaging with.
12:20 companies, you know, are just getting to work on adapting to climate change because they're feeling
12:27 it in their bottom line. And it's different than things were 10 years ago.
12:31 Well, that's good to hear. I'm both pessimistic and optimistic about how things could go. You know,
12:37 I, there are so many full discoveries. Folks like you are using, you know, Python and computation
12:43 to really understand exactly what's happening and keep your finger on the pulse of where they're going.
12:48 And then also I see, you know, a mom and her one small kid in a Chevy Suburban next to me,
12:56 you know, idling in traffic. And it's like, I don't know. People do have to internalize it,
13:02 I think a little bit more, but it's, I wonder if it is maybe in business, they're starting to see,
13:07 starting to react a little bit sooner. Right. I think companies feel pressure of economics sooner
13:14 than people do a lot of the times. I know. I think that's true. I think there's also
13:17 social pressures that are pushing companies to act soon. And so I, you know, it's not just it,
13:23 sometimes it's altruistic, but also I think there's marketing involved in a range of other.
13:29 Right. Just don't want to look like the bad company. Yeah.
13:33 If they can put on a good image and it's, it's worth it, but whatever gets them to do it,
13:37 I don't care if it's.
13:37 Yeah. That's what I was just going to say. We don't have to shame that. I think that
13:41 there's a lot of action that needs to happen in a lot of sectors right now. And so to the extent
13:45 we can motivate that through one mechanism or another, that sounds like a good idea.
13:49 Yeah.
13:49 This portion of Talk Python To Me is brought to you by SignalWire. Let's kick this off with a question.
13:56 Do you need to add multi-party video calls to your website or app? I'm talking about live video
14:01 conference rooms that host 500 active participants, run in the browser and work within your existing stack,
14:06 and even support 1080p without devouring the bandwidth and CPU on your users devices. SignalWire
14:13 offers the APIs, the SDKs and edge networks around the world for building the realest of real time
14:18 voice and video communication apps with less than 50 milliseconds of latency. Their core products use
14:24 WebSockets to deliver 300% lower latency than APIs built on rest, making them ideal for apps where every
14:31 millisecond of responsiveness makes a difference. Now you may wonder how they get 500 active participants in
14:36 a browser-based app. Most current approaches use a limited but more economical approach called SFU or
14:42 Selective Forwarding Units, which leaves the work of mixing and decoding all those video and audio
14:46 streams of every participant to each user's device. Browser-based apps built on SFU struggle to support
14:53 more than 20 interactive participants. So SignalWire mixes all the video and audio feeds on the server and
14:59 distributes a single unified stream back to every participant. So you can build things like live
15:04 streaming fitness studios where instructors demonstrate every move from multiple angles,
15:08 or even live shopping apps that highlight the charisma of the presenter and the charisma of the products
15:14 they're pitching at the same time. SignalWire comes from the team behind Free Switch, the open source
15:19 telecom infrastructure toolkit used by Amazon, Zoom, and tens of thousands of more to build mass-scale
15:25 telecom products. So sign up for your free account at talkpython.fm/signalwire and be sure to mention
15:31 Talk Python To Me to receive an extra 5,000 video minutes. That's talkpython.fm/signalwire and mention
15:37 Talk Python To Me for all those credits.
15:39 We're getting like maybe down this climate rabbit hole, but this is the probably the most important
15:45 issue of our time. So let's go down it. I mean, you got to distinguish between the terms we use are
15:50 mitigation versus adaptation, right? So mitigating climate is doing things like burning less fossil
15:57 fuels that are going to reduce the potential impacts of climate change. Adaptation is just accepting that
16:04 climate change is happening and it's going to happen and changing our behavior like infrastructure.
16:09 And so when I say to see a lot of companies taking action, I see especially a lot of companies taking
16:14 action from where I sit on adaptation using earth system data, using our projections from our climate
16:20 models to make business decisions under this changing climate. Mitigation is what we've been calling
16:26 for for decades. And that's where like the Chevy Suburban comes in. I guess I really push back against
16:32 the idea that like personal choices are like an important part of mitigation. This is, I think,
16:38 this narrative has actually been counterproductive. Like, don't think we need to rely on personal,
16:42 like ethical choices about like which type of like bags to bring to the grocery store. I mean,
16:47 like it's important, but like this is a very, very large scale.
16:50 It's solving the problem. I think very, very much on the edges when you're just going like,
16:54 but there's this huge middle part. What do we need?
16:56 Global scale regulation around carbon emissions in order to mitigate climate. And that's a political
17:02 problem.
17:02 It is. Well, the renewable energy story seems to be coming on faster than people thought recently. So
17:08 there is a lot of hope in that space. Now let's talk, you know, you both mentioned a little bit of
17:13 this sort of blend of like open source side of things, and then the science side of things. Let's just
17:20 talk for a moment about just some general best practices with open source and science and stuff
17:27 like that. One of the things I guess is Ryan, you talked about having people like these high-end
17:34 software engineers reviewing your code and stuff. And I suspect there's a lot of lessons you've learned
17:38 that you can kind of bring back to the science world from that open source experience.
17:43 I think there's this whole spectrum of open science, right? And open source activities,
17:49 right? So right now it's pretty common in scientific fields to encourage projects,
17:54 research projects to publish their research code under an open license or put it on GitHub or
18:01 something like that. And I see that it's just like a very, very first step towards a much more
18:06 transformative way we do science as a community. As you well know, like just putting a repo up on
18:13 GitHub has essentially no impact, right? Like if no one uses it, like if someone pushes their commit in a
18:23 forest and no one hears it land, like, okay, great. Like you checked a box. The real goal of open science
18:30 is to encourage more reuse, more collaboration, and accelerate the velocity of scientific discovery.
18:37 And that takes more than just putting your code out there. And of course, putting your code out there
18:41 is the first step, but it actually takes making sure people can run it. Like they have the environment for
18:46 it. Like they can access the data that it needs to run, that they understand what it can do, that it's
18:51 coded in a way that is extensible and modular. And all of those things are a lot more than a license.
18:57 They're about actually writing good scientific code. And so I do think that just the process of getting
19:03 involved in open source is a huge form of education for scientists about how collaboration can work,
19:11 not just even in code, but in general, the way the collaboration process works in a
19:16 well-functioning open source project is kind of miraculous.
19:20 Yeah, it absolutely is. And you know, there's a lot of barometers people use when they go and
19:25 look at an open source project to decide, can I trust this thing? The obvious ones are like,
19:31 how many stars and forks? Like, is it a popular thing that people seem to care about? But others are,
19:35 does it have tests or, you know, does it seem to be operated in a way that is going to lead to
19:41 contributors being able to contribute and, you know, the software evolving over time in a way that
19:46 that they could depend upon? Right?
19:48 Yeah. I think another thing here that's really important to think about is what the incentive
19:52 structures are for a researcher working on a scientific programming problem. And for, you know,
19:58 for most graduate students or researchers at institutions that Ryan and I work at, the goal
20:02 is to write a paper or to produce a dataset. And the software has been kind of thought of as like
20:08 a tool you use to get there, but it's not necessarily a tool that you fix up or improve along the way.
20:13 And I think one of the things that we've been trying to do is kind of break that pattern
20:17 a little bit and think of that, like the whole ecosystem of tools that we're working with is
20:23 improvable so that we don't have to reinvent the wheel. And individual researchers have,
20:28 I actually, and I just, maybe just speaking for myself, being able to say, okay, I'm going to take a,
20:33 rather than take the like shortcut path to get to my, the end of the paper, I'm going to like,
20:37 improve the ecosystem so that later on I can reuse this improvement, but also so Ryan and others in
20:43 the community can reuse it. And that's like a fundamentally different way of thinking about
20:47 the tools you're using.
20:48 That's interesting. It sure is. I've only spent a couple of years in that space, but my experience was
20:54 so much of the code, at least traditionally had been written just to solve a very focused problem and
21:01 not in a way that could be adapted to future problems, right? It'd be like, well, we're changing
21:06 the algorithm or we're, it's slightly different data. So we'll make a copy of this script and we'll
21:10 copy it over there. And we'll just like, you know, maybe there's not a single function in the whole
21:13 thing. It's just top to bottom. And I suspect adopting some of these techniques to sort of produce
21:19 more of a library out of it. Even if you put it on GitHub and nobody comes, it still would benefit
21:25 you and your research over time, I would imagine.
21:27 And I would say that that is a big part of Python and why Python is a good tool for science, because
21:34 it is easy to build higher level abstraction. Like coming from the MATLAB world, you basically got
21:40 MATLAB and its toolboxes, and then you got like your scripts. And like, there's like this hard divide
21:46 between like the platform and the tool and like your own work. You're used to thinking, well, these are
21:51 like the primitives provided by like the tool and here's what I have to do. But Python allows you to
21:57 build very flexibly and has this great ecosystem. I mean, I think this segues naturally into X-Ray.
22:02 Yeah.
22:03 Like many of us in say in 2014 had our own sort of private version of a code that did what X-Ray did,
22:10 thinking like that's code that needs to live in users. That's not a package provided by the ecosystem.
22:16 But then once sort of X-Ray started to catch on and we realized how powerful and how cool it was and how
22:21 well it was, what a solid foundation it had, many of us immediately stopped working on our own sort of
22:26 private X-Ray like thing and started contributing to X-Ray. And we've seen over say the past, you know,
22:33 five or six years, this really steady growth in like the capabilities, both in terms of features and
22:38 robustness like of X-Ray that we never would have done if there hadn't been that coalescence around
22:44 like, okay, we're all going to work together on this.
22:47 Yeah. And then you have these knock on effects, right? There's now other libraries and other systems
22:53 that use X-Ray. And so if you're programming against it, it's super easy to plug into it, kind of like
22:58 what Pandas and Dask are doing. Like if you program against Pandas, you kind of automatically get like
23:03 the scale up version because Dask is just Pandas, but more.
23:07 Right. And you don't have to write code to like read CSVs.
23:10 Yes, exactly. So I gave the elevator pitch for X-Ray, but let's go ahead and dive into that. And some of,
23:17 maybe, maybe give us the story for Pangeo where X-Ray is one of the sort of umbrella,
23:23 is covered under that umbrella. Yeah. So whoever wants to take it.
23:26 Yeah. I'll start, but I think, you know, just to take maybe a slight step back and say what X-Ray is
23:31 one more time, I think. So X-Ray is a package, a Python package for working with multidimensional
23:36 labeled arrays and datasets. And it integrates with NumPy and Pandas. And in many ways, you can think
23:42 of it as a multidimensional Pandas. Yeah.
23:44 And it's used really widely in the climate science community and the geosciences, but it's also used
23:50 in fields outside of the geosciences. Right. It could be finance or all sorts of things.
23:55 Yeah. So finance and biomedical and bioimaging, et cetera.
24:00 Give us a sense of like the data that you might load up off of some oceanography.
24:03 Something I think that our go-to data set for oceanography is like ocean sea surface temperature.
24:08 Satellites observe the ocean from space, infrared or microwave observations can tell how warm the water
24:15 is. That gets processed by NASA. They distribute essentially a bunch of net CDF files that are up
24:22 on like basically an HTTP or FTP server, one file per day for the past 30 years, quarter degree resolution.
24:30 Each file is a couple of, you know, 10, 10, 20 megabytes or something like that. We want to do an analysis on that data.
24:36 And so X-Ray can open that individual file, but it can also open that collection of thousands of files as one coherent data set object.
24:44 Interesting. So do you give it something like a directory and a file pattern and it just somehow does a sort and then loads them up?
24:52 Yeah.
24:54 It can do globbing, you know, it can X-Piles pass it a list. That is one of the killer features of X-Ray that I think brought a lot of people into it.
24:59 Because like, you know, we were all kind of used to like writing code around files. Like, okay, I've gone to this analysis.
25:05 Here's like a hundred files for like each file in my list of files, you know, do this. Right. And instead, the workflow changes with X-Ray. It's like, okay, open multi-file data set. Mean. Done. Right. Like, right.
25:18 And so it's just like this cognitive load that's lifted.
25:22 That's cool. Yeah. There's, especially in the data science space, I see a lot of these things and it's almost about learning about the packages and the way that you can use them.
25:32 You know, like an example that really quickly comes to mind for me is like, if I wanted to get a table out of an HTML page, out of a website, and then pull that in and like process it, I could do, go get the page with requests.
25:45 I could do some beautiful soup thing to find the table. And then I could, I don't know, try to parse it or something and then convert the elements.
25:51 If they were really supposed to be numbers, you got to parse them as numbers and then get that into some data structure.
25:57 Or you go to pandas and you say, read HTML tables bracket two or something like that. Like those kinds of things seem to appear so much in these data science libraries. Like, oh, you could do this big, long computer science thing. You could call this function over here and you got the same outcome. And it's really about knowing about that those exist. Right.
26:15 Yeah, totally.
26:45 So, you know, the workshop was Pi AOS atmosphere, ocean sciences or something like that. It was, it was a name that got dropped pretty quickly.
26:52 But the idea was that we were like 20, it was probably 20 of us that worked on X-ray and Dask mostly. And it was kind of a mix of software developers and scientists. We got together and like just kind of shared out the use cases that we were wrestling with and the problems. And out of that grew the Pangea project and a few ideas. So the, like the mission that you read on the website today is like what we wrote that weekend, which is, you know, to try to tackle a few key problems that we're facing our community.
27:19 We're facing our community, mostly big data, reproducibility and really aiming at supporting the software ecosystem that connected all those dots. And since then, the Pangea project is, has grown into a wider community project that has a lot of software packages involved, not just X-ray and Dask. That's the origin story. It really started with X-ray as the, like the beginnings. And then from there.
27:43 Okay. Interesting. Yeah. Yeah. Very cool. Maybe we could talk a little bit about the other packages, but X-ray and then there's a list of packages on the website. Iris, I know y'all don't do too much with Iris, but maybe just tell us really quick with that.
27:55 So it's at the same level of the stack as X-ray. So you're probably using either X-ray or Iris. Iris is, I would say like, it's maybe a little bit more opinionated than X-ray in the sense that it's scoped to like geo data or like data, you know, or that has things built into it that are like more specific to that domain.
28:16 Like some of the specific file formats, which I'm not familiar with, but like GRIB and those kinds of things.
28:22 No, actually X-ray gets all of those file formats.
28:24 Okay.
28:25 I think it's more about the API, like, you know, an understanding that like what latitude and longitude actually mean and like supporting things like re-gridding directly rather than say through third party packages, like we would use with X-ray.
28:38 It's a great project and it is in many ways very complimentary to X-ray and highly interoperable as well.
28:44 You can like X-ray to Iris dataset, you know, Iris dataset to X-ray.
28:50 You can think of them all as wrappers, higher level data structures around arrays, right?
28:55 So many of us have probably coded, written, if you work with NumPy at any level, you probably had a dictionary with NumPy arrays in it, like multiple different arrays you want to keep together.
29:07 And at that point, I would say like, just use X-ray whenever you're starting programming that pattern.
29:12 Yeah, because that's basically what X-ray is, right?
29:14 As how do you label it?
29:16 That's the keys.
29:17 And then multidimensional is multiple arrays, right?
29:21 Yes.
29:21 And then understanding relationships between these and then metadata, another huge part of this, right?
29:26 Like so X-ray, both X-ray and Iris and anything in the space is going to really understand metadata that comes with those things.
29:32 So things like units or, you know, conventions that tell you how the variables are related to each other.
29:38 And then it can do things with that metadata computationally, not just like drag it around, you know, for posterity, but actually leverage it to make certain syntax or certain computation.
29:51 You filter by all the ones that are tagged by state or whatever.
29:54 Interesting.
29:55 Okay.
29:56 Then the next one in the overall banner of Pangeo is Dask.
30:01 Yep.
30:01 I've had Matthew Rocklin on the show before to talk about Dask, but it's been a while.
30:05 So maybe tell folks about Dask.
30:07 Yeah.
30:07 So Dask is a, it's a library for doing parallel computing in Python and it, and it has a bunch of different containers.
30:14 And so there's Dask array, which is what X-ray uses, but there's also a Dask data frame, which does kind of parallel chunked operations on pandas data frames.
30:24 And then there's the like catch all the Dask bag, which does graph style parallel computing.
30:30 So where this comes in for X-ray is that, I mean, actually for Iris as well, since we were just talking about Iris, but the arrays in an X-ray data set can be backed by a Dask array instead of a NumPy array.
30:43 And by just kind of swapping that out, it's almost a behind the scenes swap out.
30:48 You do a dot chunk on your X-ray data set, and then your operations are going to be handled by Dask, which means they're going to be streamed through the Dask scheduler.
30:58 You'll be able to scale out to a cluster of workers and do, instead of say gigabyte style operations, you can do terabyte scale or even petabyte scales at someday data analysis.
31:11 So Dask is the thing that gives X-ray its horizontal scalability.
31:15 Yeah, very cool.
31:16 So scaling across machines.
31:18 Now, when I learned about Dask, I saw it as it's like the local pandas or the other types of things that models, but you set up a cluster and it runs there.
31:30 And then when I spoke to Matthew about it, I realized he pointed out that it's useful even on a single machine.
31:37 Some of the times, right?
31:38 If you've got a ton of data, but not enough RAM to hold it, or you even have like a pretty simple computer here as eight cores.
31:46 If I run something on pandas, I get one core worth of processing power, right?
31:51 So maybe, Joe, you're shaking your head.
31:52 Like, tell people about that use case.
31:55 Yeah, so Dask has a bunch of schedulers.
31:57 And some of those are local schedulers that run on a single machine.
32:00 And they can either use Python's multi-processing module or threading multiple threads to do computation.
32:06 It also has distributed schedulers that might live on Kubernetes or on an HPC machine.
32:12 There's now companies like Matt Rocklin has gone on to start Coiled, which has managed Dask clusters for you.
32:19 But the idea is that like at a small scale, when you're using the threaded scheduler, it's going to stream computation.
32:26 So when you say taking the average of a terabyte size array, it's going to like use its chunks and process those chunks one at a time and then aggregate those process chunks to the final result.
32:36 Yeah.
32:37 A lot of times, if it's the simple path of you go find some tutorial or example code or something on Stack Overflow, it's just like, well, first you just load this up.
32:46 You read the CSV or you load the JSON file and then you go over it like this.
32:50 And you're like, well, I have a terabyte of data and, you know, 16 gigs of RAM.
32:55 And so you need this sort of iterative streaming style to get there.
32:59 The brilliance of Dask, the game changing flavor of Dask is that for many cases, the user doesn't really have to rewrite their code at all to scale out.
33:09 And so typically with X-Ray, like we, when we teach it and we really want to like get people the sense of the power, we like start by downloading like a 10 megabyte file and opening it with X-Ray and doing some analysis.
33:21 And then they like learn the API and, you know, they use it and then, and then, and then we point it, then we sort of point people to like a massive, you know, a hundred gigabyte data set in the cloud and a Dask cluster.
33:34 And we say like, write the same code and it like just works and it's pretty fast and it is able to scale out without much, really any expertise on the user's side about distributed computing.
33:45 I love that feature.
33:46 On the other hand, I've also come around to the feeling that it can sometimes it's a double-edged sword because some things actually just fail.
33:53 If you don't think hard about the parallelization strategy, it's not magic.
33:58 It depends on the operation that you want to do.
34:00 And so the flip side of that ease of parallelization is that sometimes users will think it is Dask is smarter or more capability than it really could ever be and expect it to just automatically parallelize anything.
34:14 Even say just IO patterns that are just not parallelizable, not scalable, right?
34:20 Or other operations that are just can't be accelerated.
34:23 Yeah, it seems like it just automatically fixes the problem.
34:27 It just makes it faster with magic programming dust.
34:30 And then like, obviously some points that comes undone, right?
34:35 This portion of Talk Python To Me is brought to you by Sentry.
34:38 How would you like to remove a little stress from your life?
34:41 Do you worry that users may be encountering errors, slowdowns, or crashes with your app right now?
34:47 Would you even know it until they sent you that support email?
34:50 How much better would it be to have the error or performance details immediately sent to you,
34:55 including the call stack and values of local variables and the active user recorded in the report?
35:00 With Sentry, this is not only possible, it's simple.
35:04 In fact, we use Sentry on all the Talk Python web properties.
35:07 We've actually fixed a bug triggered by a user and had the upgrade ready to roll out as we got the support email.
35:14 That was a great email to write back.
35:16 Hey, we already saw your error and have already rolled out the fix.
35:19 Imagine their surprise.
35:21 Surprise and delight your users.
35:23 Create your Sentry account at talkpython.fm/sentry.
35:27 And if you sign up with the code talkpython, all one word, it's good for two free months of Sentry's business plan,
35:34 which will give you up to 20 times as many monthly events as well as other features.
35:39 Create better software, delight your users, and support the podcast.
35:43 Visit talkpython.fm/sentry and use the coupon code talkpython.
35:50 Hoiled, Matthew Rocklin's company that he started with some other folks, I believe.
35:55 And this is a really interesting story.
35:58 Like we talked about how you've got your X-array like code or you got your pandas like code that you just wrote for yourself.
36:07 And then by sort of adopting one of these libraries and maybe even contributing it and like building it up, you get these knock-on effects, right?
36:14 So I gave the pandas to Dask example.
36:17 And like, here's the next step in that chain, right?
36:19 Like now you have, oh, I can just spin up a cluster on the cloud automatically through coiled with like one or two lines of code because I built on Dask because I built on pandas.
36:30 You know, like that chain just keeps going of like how it all sort of this synergy between all of them.
36:35 Absolutely.
36:36 And I mean, I would say like it's not just like coincidental.
36:40 Like Matt Rocklin was at that Pangeo meeting at Columbia like in 2016 or whatever.
36:46 And actually we've watched this evolution.
36:48 So a big part of what we have been doing in Pangeo is experimenting with cloud computing.
36:53 I think a little bit earlier and more sort of in a different way than a lot of the other scientific community was.
37:00 I think we can thank Matt for that to some degree because the story with Pangeo and cloud
37:05 is that we after that workshop, we brought our first proposal to the NSF and we got a grant to like develop some of these stuff and develop Pangeo and support scientific use cases.
37:17 And what we had put into that original grant were like we had a bunch of servers that we wanted to buy to like host data and run.
37:23 That's what you do.
37:24 Like when you write a scientific grant and NSF asked us to trim our budget and we decided, OK, we will cut out these servers.
37:30 But why don't you give us some credits on the cloud?
37:32 Because at the time NSF was running this pilot program called Big Data where they were granting those like a partnership with Google and Amazon stuff.
37:39 And so we got like $100,000 worth of Google cloud credits.
37:43 And we just started playing around to see how well we could make this stack work in the cloud.
37:48 And Matt was instrumental actually at that time.
37:51 He was really involved and was helping us figure out like how to deploy stuff on the cloud.
37:56 And we learned all about Kubernetes and object storage and like all of this stuff.
38:00 And it was incredibly fortunate for us to have that because I think we really figured out a lot of stuff early on about how science, scientific research can interact with cloud computing.
38:11 And that's where a lot of our focus and energy is today.
38:15 That's cool.
38:15 Yeah, there's a lot of interesting things about large data sets, right?
38:18 You can put them, as you said, in object storage and then people can come into that cloud and like use the data without trying to download it or move it around.
38:27 Or like some of these data sets are terabytes, right?
38:30 What are you going to do to get those shared, right?
38:31 Yeah, I know some of them are petabytes at this point.
38:34 Which that's terabytes you can do.
38:35 Petabytes, that might be like a little bit beyond what your ISP is going to let you do to download.
38:40 That's right.
38:41 Yeah.
38:41 Where are you going to put it?
38:42 Or you can get a hard drive for it, right?
38:43 Where are you going to put it?
38:44 Yeah, exactly.
38:44 The thing that our work on cloud computing really unlocked for us was this idea that we could federate access, not only to compute, like everyone kind of knew, yeah, you can spin up a VM, but federating access to the data in a way that was infinitely.
39:00 That's a totally scalable, both in terms of access, but also in storage is a totally, like is a total game changer.
39:05 And so, you know, as we've gone down this rabbit hole and we've gone fairly deep at this point, the idea of putting data in object store and letting anyone in the research community access that has kind of revolutionized the way we think about what scientific computing platforms should look like going forward.
39:22 Yeah.
39:22 Yeah, absolutely.
39:23 It solves like half of the problem.
39:25 One is the computational time and power, but the other is just the storage and the data and the memory and all those kinds of things, right?
39:30 Absolutely.
39:31 And, you know, I think data providers are really reckoning now with what the cloud means, right?
39:37 Because what we had seen in geosciences and climate sciences is there were a lot of data portals out there.
39:44 An agency or a group would decide, we have a data set we want to share.
39:48 We have this data we want to share.
39:49 Let's make a portal, which was almost always sort of a highly customized website with a browser.
39:54 And maybe you had to click through to do some JavaScript and like do it like you had to interact with the browser to get data files.
40:00 And then you would like get some data files.
40:02 And maybe it seemed like a good idea.
40:04 There was reasons why they wanted to have a portal.
40:06 But like from a user point of view, especially like an expert user point of view, they're just incredibly frustrating to interact with data that way.
40:13 With cloud object storage, I linked in the chat this blog post I wrote about this, my fantasy about how if this facetious post about how to create a big data portal, there's like one step.
40:24 It's like upload your data to S3.
40:26 Right.
40:27 Exactly.
40:29 I think it's provocative.
40:30 But like I think the fact is there's a lot of vested energy expertise within the scientific community about how to build and maintain these really bespoke data access solutions.
40:40 When I think really we should be moving to a very, we should just really be using object storage and the scalability of cloud style computing to distribute scientific data.
40:51 It doesn't mean we need to just like go all in on AWS.
40:54 Although actually that's exactly what NASA has done.
40:57 You know, there's a lot of cloud storage like things that provide a really scalable base layer of storage for internet enabled computing.
41:05 There's like Wasabi alternative to Amazon.
41:08 There's like Cloudflare now is launching a data storage service, which I'm super excited about.
41:15 Interesting.
41:15 Yeah.
41:16 And you might end up with a copy of that data.
41:18 Maybe you have a copy in AWS, a copy in Azure, maybe even like Linode, DigitalOcean, places like that.
41:24 Right.
41:25 But that's only four or five copies.
41:27 Not every researcher trying to figure out how they're going to deal with it.
41:31 Right.
41:31 Exactly.
41:32 Or you outsource that sort of mirroring to, you know, a service that knows how to scale that sort of thing.
41:38 Yeah.
41:38 Another really interesting player in this space is IPFS and the, you know, distributed web.
41:44 And, you know, where we're at now is like people are very excited about in science or like about S3 and, you know, cloud computing.
41:51 But on the other hand, the scientific community is wary of being too dependent on the big tech giants.
41:56 And it always has sort of a do-it-yourself sort of distributed approach to infrastructure.
42:00 So I'm really excited about IPFS Interplanetary File System, which is a distributed yet highly performant way of sharing petabyte scale data on the internet.
42:12 Oh, that sounds really interesting.
42:14 Really quick, James out in the audience is asking, are there any Pangeo specific resources to help with that transition,
42:20 that jump from the workstation to cloud computing?
42:22 Yeah.
42:23 I think this is a good opportunity to show off and talk about the list of tutorials and examples that we have.
42:29 So I think, you know, Pangeo has a collection of Jupyter notebooks that show how to use.
42:36 Yeah.
42:36 So this is gallery.pangeo.io.
42:39 There's a list of Jupyter notebooks here that walk through kind of real world examples of working with large geoscientific data in the cloud.
42:49 And so I'd encourage people that are listening to pull this site up and take a look.
42:53 And I'll put a link in the show notes if you can find it as well.
42:55 Yeah.
42:55 Yeah.
42:56 So I think this is a good example of like one of the best resources we can point folks to.
43:01 Okay.
43:01 But I mean, to get a little bit more specific, the idea is actually you don't have to change very much at all about your workflow when moving to the cloud.
43:07 Right.
43:08 That's what we're aiming for with Pangeo.
43:10 And a key part of this and sort of that another pillar of Pangeo we haven't discussed yet is Jupyter.
43:14 So Jupyter is a key part of our effort.
43:16 We work very closely with the Jupyter developers and also the team at 2i2c, who I know you've talked to recently.
43:22 And Jupyter has been, I think, an amazing sort of Trojan horse for like cloud computing because the way when you use Jupyter for the first time, it launches up a notebook in your browser.
43:34 And honestly, the hardest way to use Jupyter is to try to use it locally because you've got to install it and configure it and run it and get.
43:40 Exactly.
43:40 The cloud story is just even easier.
43:42 Exactly.
43:42 So we now have the scientific community who like scientists, you know, huge number of scientists in many different languages are all just used to the idea that we're going to do our science in our browser through this type of, you know, IDE, essentially.
43:53 And JupyterLab especially has so many more features than classic notebook that make for a really rich, interactive scientific computing environment.
44:03 So then moving the work to the cloud is trivial.
44:05 I mean, for the user, you know, and so in Pangeo, we operate some cloud-based Jupyter hubs.
44:11 And also we have an operating binder.
44:13 And those Jupyter hubs, basically, you just log on like and anyone out there can actually sign up for the Pangeo hubs or apply to be to get access to these hubs.
44:22 And then you just have a notebook environment in the cloud.
44:25 Of course, just having your notebook in the cloud is not that cool.
44:29 But what we can augment it with are some capabilities to run DAS.
44:33 So we use DAS Gateway in those hubs as a DAS deployment solution.
44:37 But, you know, Coiled is another example of a DAS deployment solution.
44:40 And then the key, though, what is going to bring scientists to the cloud is that data, right?
44:46 So that is what makes this appealing and game-changing.
44:51 The fact that now you log into this hub.
44:52 Okay, you're in Google Cloud US Central 1.
44:55 We got a petabyte of data from the World Climate Research Program coupled model enter comparison program project sitting there.
45:03 Organized, analysis ready that you can start doing science with.
45:06 So when before you know that, if a grad student, say, would decide, okay, I'm going to work with these cloud models and do this research project, they would literally spend months downloading, organizing, and sorting that data on a computer before they can get started.
45:20 Now you can start it in five minutes and be processing data.
45:24 And that's amazing.
45:25 That's what gets me excited and motivates me to devote energy to this project.
45:31 Maybe that also involved writing a grant so that you could get enough compute to locally hold and work on that.
45:37 And you got to wait.
45:38 Okay, I'm going to order our Silicon Graphics or a Cray or whatever it is you're getting, you know, whatever the supercomputers are these days.
45:45 And they'll wait for some big thing to show up.
45:47 Or you fire up a notebook in AWS.
45:50 Take your pick, right?
45:52 I suspect this is also democratized computing somewhat as well, right?
45:57 You don't need as much compute to set up something like this and access that existing cloud database.
46:04 That's true.
46:04 And I think part of that is we've separated in the cloud model of separation of concerns.
46:10 The storage is not necessarily directly attached to compute.
46:13 Whereas like in a supercomputing center, it's all one warehouse, right?
46:17 Yeah.
46:17 Yeah.
46:17 And so, yeah, like if you're just, if you're doing a small problem, you get a small VM or you get a small cluster.
46:22 A small DAS cluster.
46:23 If you're doing a big problem, you scale out.
46:25 Right.
46:26 And so you can sort your, or you can arrange your compute infrastructure appropriate to the problem you're working on.
46:33 And the other thing is the way we're storing the data allows for partial queries of these large array.
46:40 You know, so the data that Ryan was talking about, the CMIP 6 data is a petabyte in scale, but you don't have to open the whole thing and you don't have to load the whole thing.
46:49 We're able to slice into that and grab out just the parts that are interesting for the research project that's being done.
46:54 Right.
46:55 Exactly.
46:55 That's, that's awesome.
46:56 One thing I did want to ask you to about real quick, or we're getting short on time here, but do projects like JupyterLite, which is Jupyter, but running on WebAssembly in the browser or the Python stack a little bit running on the browser or PyIoDied.
47:12 Do these projects offer any benefits to you all or are you tracking them?
47:16 Are you interested?
47:16 It's super cool.
47:17 JupyterLite and PyIoDied, it really lowers the bar to providing just like getting something up and running.
47:24 The motivations for getting into Pangeo, for starting Pangeo, a big part of it was big data.
47:30 We have large data sets, right?
47:32 And so we want to do data approximate computing.
47:34 So by putting a hub in the cloud, we're putting our compute next to the data.
47:38 PyIoDied actually takes it back to the laptop.
47:40 Yeah, yeah.
47:41 This doesn't solve the data problem.
47:42 This kind of wrecks that, but it does give computational capabilities without.
47:48 And if you couple that with something like Coiled or any Dask solution where you can actually then call out to a data processing layer that isn't.
47:57 Interesting.
47:57 It's, it will, it would make the need for us to operate those Jupyter hubs potentially go away or reduce or go away.
48:03 Oh, that's interesting.
48:04 So you've got the Dask cluster or whatever next to the data in the cloud.
48:08 And this is just handling the results of all that.
48:11 Okay.
48:12 I hadn't thought about combining those in that way.
48:14 Very cool.
48:14 If you want to process like many terabytes of data, you're not going to do it in your browser.
48:18 You're not going to do it in your laptop at all.
48:20 You do need a big computer, right?
48:22 Yeah.
48:22 But still, like it, it certainly expands what's possible larger than like maybe the first impressions.
48:27 Oh, I was going to say a quick shout out.
48:29 Recently added a JupyterLite example tutorial to the X-Ray homepage at xray.dev.
48:36 So if folks want to go try out xray really quick without having to start up a Jupyter lab server or something, it's there and you can run through.
48:44 Oh, that's fantastic.
48:45 Yeah.
48:46 We've got binder, which sort of creates a cloud instance to run all these examples, but a lot of them could actually just run like this, which is great.
48:54 Yeah.
48:54 It makes it a lot simpler.
48:54 Yeah.
48:55 All right.
48:55 We could talk for much longer, but we also know that we don't have too much time left.
49:01 So let me ask you both real quickly the final two questions.
49:04 Joe, you can go first.
49:06 You're going to write some code.
49:06 What Python code, what editor do you use?
49:08 VS Code.
49:09 VS Code.
49:09 All right.
49:10 Or Vim if I can't.
49:11 Okay.
49:12 I use Atom and I feel like I'm behind the times, but like that's what I use.
49:16 That's like OG VS Code.
49:18 It gets what I need to do done, but I feel like I'm missing out on things.
49:21 So I probably need to upgrade.
49:23 I do feel like my development environment is increasingly owned by Microsoft.
49:27 And so I have like some mild reluctance to switch to VS Code.
49:32 Sure.
49:32 I hear you.
49:33 Awesome.
49:33 And then notable PyPI package, some library you've come across lately that you thought was awesome.
49:38 I mean, obviously, shout out to Pangio and all of it.
49:41 But it's not a package.
49:42 You can't pick.
49:43 No, I know.
49:44 Yeah, I know.
49:44 I'm going to go with one of my favorites, which is not something I came across recently, but I think everybody should know about it.
49:50 Yeah, that works as well.
49:51 It's FSSpec.
49:52 And it's a library for accessing data across a bunch of different file storage systems.
49:57 And it is a game changer for working with remote data.
50:00 Everyone should know about it.
50:01 Yeah, absolutely.
50:02 That's a super interesting one.
50:04 Basically, you can connect it to all these different backends and stuff, right?
50:08 I don't remember where to find them.
50:09 But yeah, like you could connect S3 like it was a file and stuff like that, right?
50:13 Yep, exactly.
50:14 Yeah, fantastic.
50:15 All right, Ryan.
50:16 Well, mine is a shameless self-promotion, but it's for a new project we have called Pangio Forge, which is basically an ETL tool for this X-ray scientific data space.
50:27 Right.
50:28 So what we found is that a lot of the ETL tools that exist for business style data analytics don't necessarily play well with our multidimensional data model that we use in geosciences and sciences more broadly.
50:41 And so we're building this open source Python package called Pangio Forge recipes that is designed to help us with all this data movement, data transformation that needs to happen as we're migrating so many sort of legacy data sets into this cloud native format.
50:57 That looks fantastic.
50:58 All right.
50:58 Yeah.
50:58 Good shout out.
51:00 And we'll put a link to that so people can check it out.
51:02 All right.
51:03 Joe, Ryan, it's been a lot of fun.
51:04 A quick final call to action.
51:06 People want to get started with Pangio.
51:08 What do you say?
51:09 Come to our forum.
51:10 Yeah, you mentioned before we hit record, you mentioned that the discuss page is like really where the action is at right now.
51:15 The discuss forum, right?
51:16 Discourse.
51:17 Discourse, sorry, not discuss.
51:18 Yeah, discourse.
51:19 The tools and the stuff is self-documenting on the website.
51:22 But what we really emphasize about Pangio is the community aspect of it.
51:26 We are not just trying to build a tool and like put it out there.
51:28 You know, we're really trying to build a community where scientists are talking to software developers, are talking to infrastructure maintainers, are talking to data providers,
51:38 and are collectively sort of trying to keep this flywheel spinning of innovation and development, ultimately with the goal of empowering more scientific discoveries.
51:46 And so if you have questions, if you have, if you stop breaks, if you don't know if it's the right tool for you, this forum is where we can welcome you.
51:55 We don't have a Slack.
51:56 We try to be more open than as a community than a Slack.
52:00 So this is where I should have.
52:03 I can second that.
52:04 It's a good idea.
52:05 Awesome.
52:05 And then, Joe, you also wanted to throw out xray.dev, right?
52:09 Yeah.
52:09 So there's, yeah, exactly.
52:10 This is a relatively new site that sits on top of our documentation site.
52:14 But there's the JupyterLite interface is down below the fold.
52:17 And it's a great starting point.
52:19 Thank you both for being here.
52:21 This has been really interesting.
52:22 And thanks for all the hard work.
52:23 Thanks for having us.
52:24 Thank you for creating this.
52:25 Yep.
52:25 You bet.
52:25 Bye.
52:25 This has been another episode of Talk Python To Me.
52:29 Thank you to our sponsors.
52:31 Be sure to check out what they're offering.
52:33 It really helps support the show.
52:34 Add high-performance, multi-party video calls to any app or website with SignalWire.
52:39 Visit talkpython.fm/SignalWire and mention that you came from Talk Python To Me to get started and grab those free credits.
52:46 Take some stress out of your life.
52:49 Get notified immediately about errors and performance issues in your web or mobile applications with Sentry.
52:55 Just visit talkpython.fm/sentry and get started for free.
53:00 And be sure to use the promo code talkpython, all one word.
53:04 Want to level up your Python?
53:06 We have one of the largest catalogs of Python video courses over at Talk Python.
53:10 Our content ranges from true beginners to deeply advanced topics like memory and async.
53:15 And best of all, there's not a subscription in sight.
53:18 Check it out for yourself at training.talkpython.fm.
53:21 Be sure to subscribe to the show.
53:22 Open your favorite podcast app and search for Python.
53:25 We should be right at the top.
53:27 You can also find the iTunes feed at /itunes, the Google Play feed at /play, and the direct RSS feed at /rss on talkpython.fm.
53:36 We're live streaming most of our recordings these days.
53:39 If you want to be part of the show and have your comments featured on the air, be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
53:48 This is your host, Michael Kennedy.
53:49 Thanks so much for listening.
53:50 I really appreciate it.
53:51 Now get out there and write some Python code.
53:53 We'll talk to you soon.