Tips for ML / AI startups



Episode Deep Dive
Guests introduction and background
Dylan Fox is the founder of AssemblyAI, a speech-to-text and audio intelligence platform built with a deep focus on privacy, cutting-edge machine learning models, and developer-friendly APIs. Dylan started the company around 2017, leveraging his experience in natural language processing (NLP) and large-scale computing. Over time, he has led AssemblyAI to process millions of audio files daily and continually evolve their ML architecture to deliver more accurate transcription results and advanced audio analysis features. His passion for both fostering high-growth startups and delving into challenging ML / AI problems shines through in this conversation.
What to Know If You're New to Python
If you’re just starting out with Python and want to dive into ML or AI topics, here are some notes from this episode to help prepare you:
- Having a grasp of Python’s core syntax and package management (like
pip) is essential for exploring frameworks such as TensorFlow, PyTorch, or scikit-learn. - Building APIs in Python often involves asynchronous processing and frameworks such as Tornado, Flask, or FastAPI.
- Tools like huggingface.co provide pre-trained models you can fine-tune in Python without deep ML expertise.
- Even modest command-line skills (e.g. custom LS replacements like PLS) can speed up daily coding tasks in Python.
Key points and takeaways
- Core Challenge of AI Startups AI-focused startups demand balancing cutting-edge research with practical user-facing features. Dylan shares that while new ML architectures can yield breakthroughs, they must align with real user needs and be maintainable at scale.
- Links / Tools:
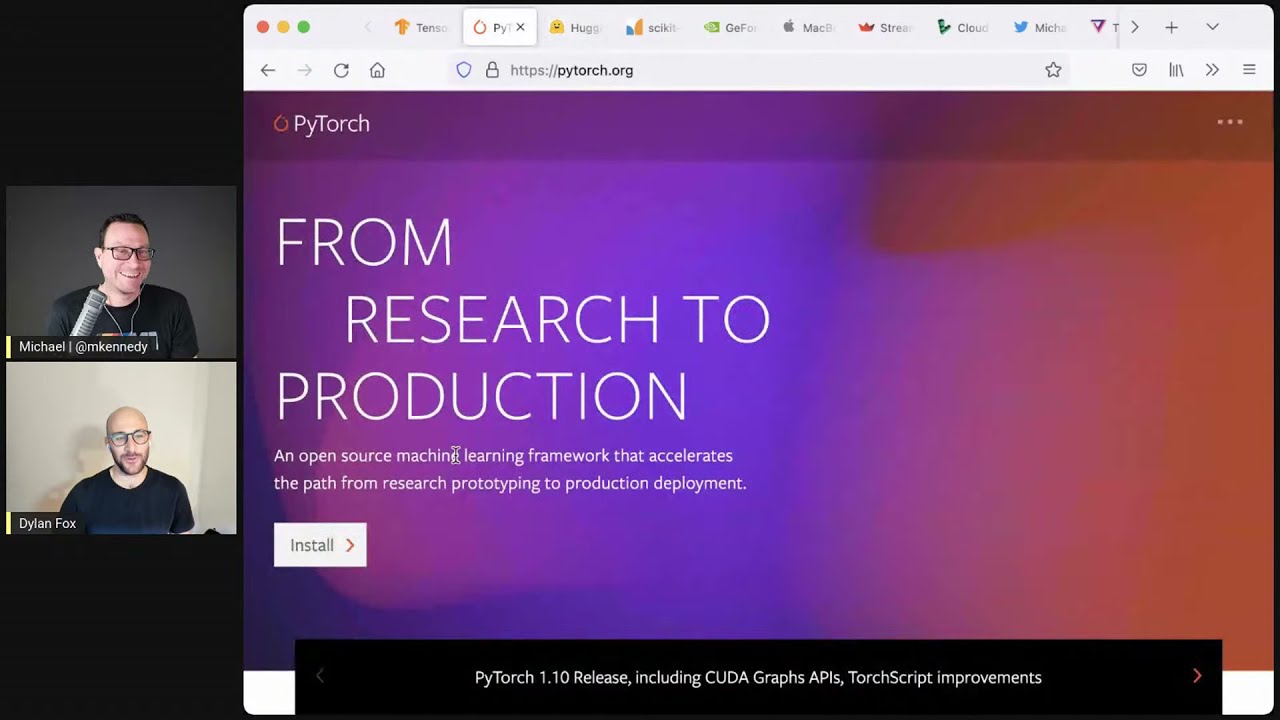
- Choosing between TensorFlow and PyTorch The episode highlights how PyTorch gained tremendous popularity because research advances, papers, and model examples often appear in PyTorch first. Although TensorFlow still has its place, PyTorch tends to simplify experimentation and transfer from research to production.
- Links / Tools:
- Starting Simple with scikit-learn Before jumping into deep learning, scikit-learn can efficiently handle many classification or regression tasks. Dylan notes that for something like predictive system monitoring or simpler use cases, classical ML approaches (e.g., SVMs) can be very effective and less resource-intensive than large neural networks.
- Links / Tools:
- Production Infrastructure and ML Ops Complexity Putting ML models into production is notably different from standard web apps. The conversation breaks down how new neural architectures require changes to container images, instance types, GPU/CPU usage, auto-scaling, and orchestration.
- Links / Tools:
- Datadog (mentioned for monitoring)
- AWS EC2 Instances
- Links / Tools:
- Cost Tradeoffs: Renting vs. Owning Compute AssemblyAI’s training infrastructure often uses dedicated GPU servers rather than on-demand cloud instances, saving significantly when training across dozens of GPUs for weeks at a time. Bootstrapped startups may rely on AWS, but once usage grows, purchasing or leasing dedicated hardware can dramatically reduce costs.
- Links / Tools:
- Privacy and Data Handling For privacy reasons, AssemblyAI does not permanently store user audio data. Instead, they hold audio only in memory during processing and then store transcripts (optionally, with user consent for model improvement). This approach reduces risk for both customers and the platform itself.
- Links / Tools:
- Otter.ai article reference (mentioned in conversation)
- Webhooks (used for asynchronous returns)
- Links / Tools:
- Real-time vs. Batch Processing Real-time APIs (like streaming voice over WebSocket) add an extra layer of complexity due to ultra-low latency requirements. Many ML startups must decide how to handle streaming data, whether to compress or batch it, and how to manage concurrency effectively.
- Links / Tools:
- Scaling Auto-scaling Dylan explains their team’s approach of overprovisioning compute to handle spikes while they refine auto-scaling policies. Although costlier in the short run, it prevents downtime. Once usage patterns stabilize, more precise autoscaling can balance performance and cost.
- Links / Tools:
- Data Moats and Large Language Models (LLMs) While some argue that possessing massive private datasets is a moat, Dylan suggests that public domain data plus advanced architectures (like GPT-3) can often match or surpass private data advantages. This democratizes ML innovation but also increases competition.
- Links / Tools:
- GPT-3 from OpenAI
- Links / Tools:
- Raising Capital vs. Bootstrapping Balancing heavy R&D costs and the speed needed for ML breakthroughs often leads AI startups to seek venture capital. However, Dylan acknowledges that many successful startups do bootstrap, focusing on a minimal workable model and scaling up profits to grow over time.
- Links / Tools:
- Y Combinator
- Pioneer.app (mentioned as an online accelerator)
Interesting quotes and stories
- Memorizing Al Gore’s TED Talk: Dylan mentioned testing early speech-recognition models so frequently on an Al Gore talk that parts of the transcript are now ingrained in his memory—a humorous testament to the iterative nature of ML model development.
- The Real-time vs. Batch Challenge: “For the asynchronous API, it’s basically like an orchestration problem—kicking off background jobs in parallel, collecting them, then returning the results,” illustrating how much custom plumbing is needed to handle large-scale ML data processing behind the scenes.
Key definitions and terms
- ML Ops: The practice of streamlining machine learning model development (R&D) and deployment to production systems, including auto-scaling, continuous integration, monitoring, and more.
- SVM (Support Vector Machine): A classical supervised learning algorithm used for classification and regression tasks, often effective with smaller datasets.
- PyTorch: A deep learning framework favored for rapid research and easier model deployment, developed primarily by Facebook’s AI Research lab.
- Ephemeral Storage: A method of handling data only in memory or temporary storage during processing, often used for heightened privacy.
- GPU (Graphics Processing Unit): Specialized hardware well-suited for parallel operations in machine learning tasks, often essential for training large neural networks.
Learning resources
If you want to gain deeper insights into Python and machine learning, here are a couple of helpful courses from Talk Python Training.
- Python for Absolute Beginners: Ideal for those totally new to Python, covering foundational concepts to help you become a confident Python developer.
- Build An Audio AI App: Get practical experience building a real-world audio-focused ML application, similar to the conversation around AssemblyAI.
Overall Takeaway
This conversation with Dylan Fox offers a behind-the-scenes look at what it takes to run a successful AI startup—from the day-to-day complexities of building production ML infrastructures to decisions around scaling costs and code frameworks. Whether you’re working on speech-to-text or any domain-specific AI, focusing on real-world customer needs, carefully evaluating your compute resources, and adopting iterative model improvements can set the stage for both cutting-edge innovation and consistent product delivery.
Links from the show
AssemblyAI: assemblyai.com
TensorFlow: tensorflow.org
PyTorch: pytorch.org
hugging face: huggingface.co
SciKit-Learn: scikit-learn.org
GeForce Card: nvidia.com
pLS: twitter.com
This journalist’s Otter.ai scare is a reminder that cloud transcription isn’t completely private: theverge.com
Programming language trends: insights.stackoverflow.com
Can My Water Cooled Raspberry Pi Cluster Beat My MacBook?: the-diy-life.com
PyTorch vs TensorFlow in 2022: assemblyai.com/blog/pytorch-vs-tensorflow
Watch this episode on YouTube: youtube.com
Episode #356 deep-dive: talkpython.fm/356
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Have you been considering launching a product or even a business based on Python's AI ML stack?
00:06 We have a great guest on this episode, Dylan Fox, who is the founder of Assembly AI and has been
00:12 building his startup successfully over the past few years. He has interesting stories of hundreds
00:18 of GPUs in the cloud, evolving ML models, and much more that I know you're going to enjoy hearing.
00:24 This is Talk Python To Me, episode 356, recorded February 17th, 2022.
00:30 Welcome to Talk Python To Me, a weekly podcast on Python. This is your host, Michael Kennedy.
00:48 Follow me on Twitter where I'm @mkennedy and keep up with the show and listen to past episodes
00:53 at talkpython.fm and follow the show on Twitter via at Talk Python. We've started streaming most of our
01:00 episodes live on YouTube. Subscribe to our YouTube channel over at talkpython.fm/youtube to get
01:05 notified about upcoming shows and be part of that episode. This episode is brought to you by the
01:12 Stack Overflow podcast. Join them to hear about programming stories and about how software is made
01:18 in century. Find out about errors as soon as they happen. Transcripts for this and all of our episodes
01:25 are brought to you by Assembly AI. Do you need a great automatic speech to text API? Get human level
01:30 accuracy in just a few lines of code. Visit talkpython.fm/assembly AI. Dylan, welcome to Talk Python to
01:37 me. Yes. Thank you. I am a fan. I've listened to a lot of episodes and big podcast fan. So I'm happy
01:44 to be on here. Thanks. Yeah, I'm sure you are. Your specialty is in the realm of turning voice into
01:51 words. Yeah, that's right. I bet you do a lot of studying of media like podcasts or videos and so on,
01:58 right? Yeah, it's actually funny. So I started the company. I started Assembly like four years ago. And
02:04 there was this one audio file that I always used to test our speech recognition models on. It was this
02:08 Al Gore TED Talk from like 2007, I think. And I've almost memorized like parts of that TED Talk because
02:14 I've just tested it so many times. It's actually still part of our end-to-end test suite. It's in
02:19 there. It's like a legacy kind of founder thing that's like in the current still. Yeah, how cool.
02:24 Yeah, it is kind of funny, especially now that we're like 30 people at the company and I'll see
02:31 some of the newer engineers writing tests around like that Al Gore file still. And it makes me laugh
02:37 because there's no real reason I picked that. It was just something easy that came to me.
02:41 Yeah. Yeah. You can start. I just got to grab some audio. Here's something, right? Yeah, exactly. Exactly. So yeah, definitely. I've also listened to
02:48 like a ton of podcasts and I was with, we just started like releasing models for different
02:53 languages. And I was with someone from our team last week and I heard this like phone call and it's
02:58 like, it's like foreign language. People like screaming on this. I was like, what are you listening
03:02 to? And, it is, but it is an audio company. You get sometimes data from customers and it's like,
03:08 you have to like listen to it. Yeah. I bet there's some interesting stories in there.
03:11 Yeah. For sure. Yeah. Well, we're very privacy conscious. So not too, not too many, but yeah.
03:16 Yeah. There was just, on the verge, there was just a article about a different speech to text
03:23 company. I don't know. Have you seen this, that there was some suspicious stuff going on? Let me see
03:29 if I can find it. I think, what was it called? It was Otter. Interesting.
03:34 Otter.ai. I'm not asking you to speak on them, but this, a journalist, Otter.ai scares a reminder
03:41 that cloud transcription isn't completely private. Basically there was a conversation about Uyghurs
03:48 in China or something like that. Yeah. And then they unprompted reached out to the person who was
03:54 in the conversation and said, could you tell us the nature of why you had to speak about this?
03:59 No way. They're like, what?
04:01 That is crazy. That is crazy.
04:03 Yeah. They're like, we're a little concerned about why, you know, it's, it's kind of like
04:07 interested in the content of our conversation.
04:08 Yeah. There's a lot of that like suspicion around, you know, there's some like, like conspiracy
04:13 theories right around like, oh, does your phone like listen to you while you're around and does
04:17 it evidently listen to you and then use that data to remarket to you? And I was talking to someone
04:22 about this recently. I did nothing about the location-based advertising world, but sometimes I'll
04:27 be talking about something and then I'll see ads for it on my phone or if I'm on Instagram or something.
04:33 And someone told me it's probably more based on like the location that you're in and the other data
04:38 that they have about you.
04:39 Yeah. You were at your friend's house. Your friend just searched for that, then told you about it.
04:44 Yeah, exactly.
04:45 I think the reality of that is that it's actually more terrifying than if they were just listening to you.
04:51 Yeah, it is.
04:51 That they can piece together this shadow reality of you that matches reality so well.
04:56 Yeah. Like your friend just bought this thing and you went over and then, so maybe you're
05:00 interested in this thing because you're probably-
05:02 Yeah, they probably told you about it or something, right?
05:04 Yeah. It is really crazy. It is really crazy. I haven't paid too much attention to all the
05:08 changes that are happening around like, I listened to some podcast, I think on the Wall Street Journal
05:12 about like the big change that Google's making around that tracking and how a lot of people are up
05:17 in arms about that. And it's, it was saying something how like they're going to have,
05:20 and sorry if I'm derailing whatever plan we had for a conversation here.
05:24 You're derailing in a way that I'm like super passionate about because it's so crazy,
05:28 but yeah.
05:28 Yeah, yeah.
05:29 We'll go too deep, but yeah, it's so interesting.
05:31 They said that there's, I'm probably butchering this, but something how like for each user,
05:36 they're just going to have like six like categories about you. And then one of them is going to be
05:40 randomly inserted as to somehow anonymize your profile. And I just thought, yeah, it was super weird
05:46 to hear about how they're doing it.
05:48 Yeah.
05:48 And like what the meeting was internally that came up with that idea, you know? So I'm like,
05:52 well, let's just throw a random category on there. I don't know.
05:55 My thoughts are we're faced or we're presented with a false dichotomy. Either you can have horrible,
06:02 creepy, tracking, advertising, shadow things like we talked about. Or you can let the creators and
06:09 the sites that make the services you love die. There are more choices than two in this world,
06:15 right?
06:15 For example, you could have some kind of ad that is related to what is on the page rather than who
06:22 is coming to the page, right? You don't necessarily have to retarget me. Like for example, right here
06:26 on this podcast, I'm going to tell people about, I'm not sure without looking at the schedule, what the
06:31 advertisers are for this episode, but I am going to tell people about that. And it is exactly related
06:37 to the content of the show. It's not that I found out that, you know, Sarah from Illinois did this Google
06:45 search and visit this page. So now we're going to show it like, no, it's, there's so many sites like this,
06:50 this one here on the verge, you could have ads for assembly AI and it'll be, maybe you don't actually want
06:56 on this one, but you know, like things like this, it would be totally reasonable to put an ad for speech
07:02 to text companies on there that requires no targeting and no evil shadow companies. And there's,
07:09 you know, like we go on and on, but there are many ways like that, right? That don't require this false
07:14 dichotomy that is being presented to us. So hopefully we don't end up with either of those. Cause I don't
07:19 think those are the best options or the only options. Yeah. It's weird how that's kind of how
07:23 things developed, you know, to where we are now. Yeah. But I agree with you. There's probably a lot we
07:28 can everyone's looking for like, okay, well, if we do retargeting, we can get 2% better returns.
07:34 And like, you know, the, no one's worried about, well, what happens to society?
07:38 Yeah. That's actually what I was going to say. It's all about the kind of high growth,
07:42 like society that we have where we need to maximize growth and maximize returns. And I mean,
07:47 I understand this acutely. Like I'm, you know, the CEO of a startup, so I get it. But yeah,
07:52 it's when it's like growth over everything, you end up with things like what you said,
07:57 like, Oh, it proves it to our returns 2%. So let's do this. But you don't think about what
08:02 the trade-offs will be. Yeah, absolutely. All right. Well, thanks for that diversion.
08:06 That was great. Yeah. But let's, before we get beyond it, let me just, get your background
08:12 real quick. How do you get into programming? And I'm going to mix it up a little and machine
08:15 learning. Yeah. Yeah, definitely. Do you want the long, the long story or the short story?
08:19 How many minutes do I have? Intermediate. Intermediate.
08:22 So the intermediate story is that I started a company when I was in college, just like a
08:28 college startup thing. And at the time was very limited in my programming knowledge. I had done
08:35 some basic like HTML when I was a kid, I was really into like, like Counter-Strike and Call of Duty and,
08:41 Oh yeah. Yeah. I would like sell up like private servers. I don't, I don't know how I got into this,
08:48 but would, would, I like rented these servers and I would like windowed remote windows desktop into
08:53 them and set up like private Counter-Strike servers and then sell those and set up like a basic website
08:58 for it with HTML and CSS. And, and my brother was super into computers. So it was always kind of
09:04 into computers. And then in college, got into startups. And I think like programming and startups are like
09:09 really connected. So through that, learned how to code, learned how to program, started attending
09:15 Python meetups in Washington, DC, where I went to school. And that's how I met Matt Mackay, who we,
09:21 it was a mutual, mutual connection. Yeah.
09:23 So attended a bunch of meetups, learned how to program and then got really into it. But I think
09:29 what I found myself more interested in was the like more like meaty programming problems, more like,
09:35 I guess like algorithm type problems. And that kind of naturally led me to like machine learning and NLP.
09:42 And then kind of just like took off from there. Cause I found that I was really interested in,
09:46 in machine learning and, and like different NLP problems.
09:50 Those are obviously the really hard ones that, you know, it's, yeah.
09:54 Especially probably when was this that you were doing it or the, this is maybe like 2013, 2014.
10:02 Yeah. So, so kind of the early days of when that, that was becoming real. Right. I remember feeling like all this AI and text to speech
10:11 or speech to text rather type of stuff was very much like fusion, like 30 years out, always 30.
10:18 Like it's, it's going to come eventually, but you know, people are doing weird stuff in Lisp
10:22 and it doesn't seem to be doing much of anything at all.
10:24 Like some like Pearl script seat out. Yeah. Yeah.
10:28 And then all of a sudden we end up with like amazing speech attacks. We ended up with
10:32 self-driving cars, like something clicked and it all came, came to life.
10:36 Yeah. It's kind of crazy, especially over the last couple of years.
10:39 I think what's really interesting is that a lot of the advances in like self-driving cars and NLP
10:44 and speech to text, they're all based on similar machine learning algorithms. So,
10:49 you know, like the transformer, right. Which is like really popular type of neural network
10:54 that came out was initially applied towards like just NLP, like text language modeling related tasks.
11:01 Now that's shown to be super powerful for speech as well. Whereas classical machine learning,
11:06 there were still these underlying algorithms like support vector machines or, you know, other,
11:11 other types of underlying algorithms, but a lot of the work was around like the data.
11:15 And so how can you extract better features for this type of data? And you had to be like,
11:19 I remember when I was getting into speech recognition, I bought this speech recognition,
11:24 like textbook. And this is, yeah, a while ago. And it was around like really understanding like
11:29 phonemes and how different things are spoken and how the human speech is spoken. And now you don't
11:35 need to know about that. You just get a bunch of audio data and you train these like big neural
11:38 networks. They figure that out. Right. You wanted to understand British accents and American
11:42 accents. You just give it a bunch of more data. Yeah, yeah, exactly. So, but it is,
11:47 it is crazy to see where things have gotten over the last couple of years in particular. Yeah. So
11:52 when I was starting out, neural networks were there, but they're a lot more basic and you didn't have,
11:58 like, there's a lot more compute resources down, more mature libraries like TensorFlow and
12:02 PyTorch. I think I went to like one of the first TensorFlow meetups that they had,
12:07 or not meetups, like developer days or whatever down at the Google conference. So it's,
12:12 it's like so new still. Yeah. It's so new. Yeah. It's easy to forget. It is a while ago.
12:16 It is. Yeah. That all the stuff didn't even exist, right? Yeah, absolutely.
12:19 So you mentioned assembly, assembly AI. Yes. That's what you're doing these days, right?
12:24 Yeah. So I am the founder of a company called assembly AI. We create APIs that can automatically
12:31 transcribe and understand audio data. So we had APIs for automatic speech to text of audio files,
12:39 live audio streams, live audio streams, and then APIs that can also summarize audio content,
12:44 do content moderation on top of audio content, detect topics, what we call like audio intelligence
12:50 APIs. And so we have a lot of startups and enterprises using our APIs to build the way we call it like
12:57 applications on top of audio data, whether it's like content moderation of a social platform or
13:03 speeding up workflows like I'm sure you have where you take a podcast recording and transcribe it so
13:09 you can make it more shareable or extract pieces of it to make it more shareable. Yeah, exactly. Yeah.
13:14 Basically for me, it's a CLI command that runs Python against your API, against a remote MP3 file. And then,
13:24 you know, magic. That's the great thing about podcast hosts that are also programmers. Like I've talked
13:30 to a few and they're all like, there's a bunch that are non-programmers and they use these different
13:34 services. But every podcast host that I've talked to that's a programmer, they have their own like
13:38 CLIs and Python scripts that they're running. Yeah.
13:42 Yeah. Yeah. Yeah. There's a whole series of just, you know, CLIs and other commands to do the workflow.
13:48 Yeah. I do want to just give a quick statement, disclaimer. Yes. So if you go over to the transcripts
13:53 or possibly, I suspect if you've listened to the beginning of this episode, it'll say that it's
13:57 sponsored by Assembly AI. This episode is not part of that sponsorship. This is just, you and I got to
14:04 know each other. You're doing interesting stuff. You've been on some other shows that I've heard that
14:08 the conversation was interesting. So invited you on. Thank you for sponsoring the show. But just to
14:13 point out, this is not actually part of that. But with the transcripts that we do have on the show,
14:18 the last year or so are basically generated from you guys, which is pretty cool.
14:23 Yep. Yep. And we don't even need to talk about Assembly that much on this podcast. We can talk
14:27 about other things. Yeah. So one of the things I want to talk about, and maybe what's on the screen
14:34 here gives a little bit of a hint of being TensorFlow, is why do you think Python is popular
14:39 for machine learning startups in general? I feel that I'm not as deep in that space as you, but
14:44 looking in from the outside, I guess I would say it feels very much like Python is the primary way
14:50 which a lot of this machine learning stuff is done.
14:52 Yeah. Yeah. That's a good point. So why that is, outside of machine learning even, I think Python's
14:57 just such a popular language because it's so easy to build with compared to PHP or C# and even
15:05 JavaScript. When I learned to code, I started with Python because the syntax was easy to understand.
15:11 There were a lot of good resources. And then there's this snowball effect where more people know Python,
15:16 so there's more tutorials about Python. There's more libraries about Python. And
15:19 it's just more popular of a language. Yeah. This insights to be pulling this up.
15:23 Yeah. If people have talked about this a lot, right? But if you pull up the Stack Overflow
15:28 trends for the most popular programming languages, there's only one that is going dramatically up out
15:35 of 10 languages or something. It's just so much more popular. Yeah.
15:38 It is. It's so interesting how it's really sort of taken off. And it wasn't back in when you got
15:46 started and when I got started back in this general area in 2012. Interesting. What was the number one
15:50 language then? The number one then was, what is that? C#.
15:54 C#. But you got to keep in mind, this is a little bit of a historical bias of Stack Overflow.
16:00 Stack Overflow was started by Jeff Atwood and Joel Spolsky, who came out of the .NET space.
16:05 So when they created it, its initial traction was in C# and VB. But over time, clearly,
16:11 it's become where programmers go, obviously. So take that a bit with a grain of salt. But that was the
16:16 number one back in the early days. Another founder legacy decision.
16:19 Yeah. Exactly. Yeah. Yeah. So I agree that it's absolutely generally popular. And I think there's
16:25 some interesting reasons for that. Yeah. It's just so approachable, but it's not a toy, right? A lot
16:30 of approachable languages are toy languages and a lot of non-toy languages are hard to approach.
16:35 So I'll see you next time.
16:49 For a dozen years, the Stack Overflow podcast has been exploring what it means to be a developer
16:53 and how the art and practice of software programming is changing our world. Are you wondering which skills
17:00 you need to break into the world of technology or level up as a developer? Curious how the tools
17:04 and frameworks you use every day were created? The Stack Overflow podcast is your resource for tough
17:10 coding questions and your home for candid conversations with guests from leading tech companies about the
17:16 art and practice of programming. From Rails to React, from Java to Python, the Stack Overflow podcast will
17:22 help you understand how technology is made and where it's headed.
17:25 Hosted by Ben Popper, Cassidy Williams, Matt Kierninder, and Sierra Ford, the Stack Overflow
17:31 podcast is your home for all things code. You'll find new episodes twice a week, wherever you get
17:36 your podcasts. Just visit talkpython.fm/stackoverflow and click your podcast player icon to subscribe.
17:43 And one more thing. I know you're a podcast veteran and you could just open up your favorite podcast app
17:48 and search for the Stack Overflow podcast and subscribe there. But our sponsors continue to support us when
17:53 they see results and they'll only know you're interested from Talk Python if you use our link.
17:57 So if you plan on listening, do use our link, talkpython.fm/stackoverflow to get started.
18:03 Thank you to Stack Overflow for sponsoring the show.
18:05 Yeah, like for me, it was very easy to get started with Python. And I actually had,
18:12 so I taught myself how to program. I went to college, I studied economics. So I did not study
18:19 programming in college computer science. And the first language I started to try to learn was PHP.
18:24 And I bought this huge PHP textbook and made it halfway through. And I was like, what is going on?
18:29 I gave up and then tried again with Python later and it was so much easier.
18:33 And then I also wonder how much of this is for the machine learning libraries in specific.
18:38 Like you have these macro trends where a lot of the data science boot camps that have been so popular.
18:43 There's scikit-learn. I know we have a tab up there. There's NumPy and I dream of what NLTK is one of the
18:50 popular NLP libraries. So there are a lot of libraries in Python in the early, like when I was getting into NLP,
18:56 I worked a lot with NLTK and like SciPy and scikit-learn and NumPy. And I think a lot of
19:02 work was done around there. And so people that were doing data science or doing some type of machine
19:07 learning were already in Python. And then now you have like PyTorch and TensorFlow and it's just like
19:12 kind of cemented, like, okay, the machine learning libraries today, the popular ones that you work
19:17 with them in Python.
19:17 Yeah. You want to give us your thoughts on those? We've got TensorFlow and PyTorch and
19:22 you know, probably scikit-learn as well. Those are the traditional ones. We've got some newer ones like
19:26 Hugging Face.
19:27 Yeah. Yeah. They're a cool company.
19:28 Yeah. Maybe give us a survey of how you see the...
19:32 The different libraries.
19:33 The different libraries.
19:33 The different libraries.
19:33 The libraries that people might choose from.
19:35 So when we started the company, everything was in TensorFlow.
19:38 When was that?
19:39 Back in like late 2017.
19:41 Okay.
19:41 Yeah. Late 2017. Everything was in TensorFlow. And actually, I don't know what year
19:47 PyTorch came out. I don't even know if it was out back then. Or maybe it was like just internally at Facebook.
19:52 Yeah. It's pretty new. Yeah.
19:53 Yeah. So TensorFlow was definitely, they got started early. I think their docs and
19:58 the framework just got complicated over the years. And then they sort of rebooted with like TensorFlow 2.0.
20:05 And then there was like Keras that was popular. It kind of got pulled in. Now, I think,
20:11 so we switched everything over to PyTorch in the last year or two. A big reason for that was that,
20:16 and we actually put out this article on our blog comparing like PyTorch and TensorFlow. And we have
20:21 this chart where we show like the percentage of papers that are released where the code for the
20:27 paper is in PyTorch versus TensorFlow. And it's a huge, huge difference. Like most of the latest
20:34 research gets implemented. Yeah, here it is. If you go down to one of, so this is, yeah,
20:39 hugging face. Can you go keep going? Yeah, research papers. Yeah. Go up to that one. Yeah. Okay.
20:44 So it shows like the fraction of papers. And so what we're showing here for the people that are
20:48 listening is like a graph that shows the percentage of papers that are used, built using PyTorch
20:55 versus TensorFlow over time. Yeah. When you started, it was, what is this? Six, seven percent?
21:00 Yeah, probably 10 percent. And the balance being TensorFlow, Right. When you started your company. Right.
21:05 And now it's 75 percent PyTorch. That's a huge, very large change.
21:10 It's a dramatic change. You know, if PyTorch was a company, it'd be like
21:13 probably raising a lot of money. I think one of the reasons we picked PyTorch is because a lot of the
21:19 newer research was being implemented in PyTorch first. There were examples in PyTorch. And so it's
21:23 easier to get, they have it on their, it's their tagline, but to quote them, like from research to
21:28 production, right? Like it was easier to get more exotic, advanced neural networks into production and
21:35 like actually start training models with those different types of layers or operations or loss
21:39 functions that were released in these different papers. So we started using PyTorch and we kind of
21:44 haven't looked back. Yeah.
21:46 Well, if you're tracking all the research and trying to build a cutting edge startup around ML,
21:52 you don't want to wait for this to make its way to other frameworks. You want to just grab it and go.
21:57 So that's where the research is being done. That helps a lot, right?
22:00 Right. Exactly. Yeah. You can get, just get up and running a lot faster with the newer research. And so
22:05 most companies that I talk to now, they're all using PyTorch. I think PyTorch is definitely like
22:11 the more popular framework. There's some new ones coming out that have people excited, but still,
22:15 like from what I can sense, PyTorch is, if someone was going to get started today, I would tell them
22:21 to start with PyTorch. Yeah.
22:22 And I think TensorFlow is also- Who runs PyTorch? I think it's-
22:26 Sorry, who runs PyTorch? It's released by Facebook, right?
22:28 Yeah. And then TensorFlow, that's Google, right?
22:30 Google, yeah. Yeah. And I think Google's tried to tie TensorFlow into their cloud ML products,
22:35 so train your models on Google Cloud and use their TPUs in the cloud. And there's probably some business
22:41 in this cases behind that, but I feel like it may have made the developer experience worse because
22:46 it's trying to get back to Google. Whereas PyTorch isn't trying to get you to train your models on
22:51 Facebook Cloud or something. Yeah. What's the story with hugging face?
22:54 This is how- People probably wouldn't use Facebook Cloud if that existed nowadays.
22:58 Yeah. I don't know if you'd want to host your data interface. Meta Cloud. I mean, Meta Cloud now.
23:04 Yeah. Meta Cloud. You can only do it in VR. Yeah.
23:06 What's the story with Hugging Face? So Hugging Face is a cool- So this is a company, actually.
23:10 And they have, it's kind of hard to even explain. It's like, you can basically get access to a bunch
23:16 of different pre-trained models really quickly through Hugging Face. And so if you want to,
23:20 a lot of work around NLP now is like how familiar you are with like self-supervised learning or
23:26 base models for NLP. I'm familiar with that. Somewhat. So the idea is to have a,
23:31 like a general model and then apply some sort of transfer learning to build up a more specialized
23:37 one without training from scratch. Is that- Exactly. Yeah. And then that general model is,
23:41 is really just trained to like learn representations of the data. It's not even really trained like with us,
23:47 our particular like NLP task. It's just like trained to learn representations of data. And then
23:52 with those representations that it learns, you can then say like, okay, you know, I'm going to train you towards this specific task with some labeled data in a
24:01 supervised manner. And so there are some really popular open source, like base models, foundation
24:07 models, like BERT is one, there's a bunch of others, but you can easily get like, like load up BERT basically,
24:13 and fine tune it on your data with Hugging Face. So if you're trying to get a model, the model up and
24:19 running quickly in like the NLP, like the text domain, you can do that pretty easily with Hugging
24:24 Face. And- Okay.
24:25 Yeah. So it's less like, if you want to like build your own neural network from scratch,
24:29 like inputs to outputs, implement your own loss function, all that, you would do that in PyTorch.
24:35 If you want to try to just like quickly fine tune BERT for a specific task that you're trying to solve,
24:40 you could still go like the PyTorch out, but it would just be faster to go with Hugging Face. So they've seen a lot of adoption there. And then scikit-learn is kind of like the old school library that's been around forever with like-
24:52 The OG, yeah.
24:54 The OG, yeah. Like if you want to do stuff with like support vector machines or random forest or like KDR's neighbors, you know, this scikit-learn is probably still really popular in that for those different use cases.
25:05 I do think that I hear scikit-learn being used quite a bit still.
25:09 Yeah.
25:09 Maybe in the research, the academic, if you go take a course on it, you know, probably there's a lot of stuff on this, I would guess.
25:17 Yeah. Like there's a lot of times where, I mean, you don't really need to build a neural network. I mean, there's parts of our stack that are really important.
25:22 Like basic machine learning, like statistical models. And if you can get away with it, it's a lot easier to train and you don't need as much data and it's easier to deploy. So like a lot of like recommendation type models or, and sometimes SVMs are just like good enough. SVMs, support vector machines are just good enough for, for a task that you might want to have.
25:41 So for a lightweight Netflix recommendation or YouTube recommendation, not like the high end stuff that I'm sure they're actually doing.
25:49 Yeah.
25:49 Something like that.
25:50 Yeah. Yeah, exactly.
25:51 That kind of recommendation engine. Yeah.
25:52 Something, yeah. Something basic. Yeah. Although I actually am kind of underwhelmed with like the Netflix and YouTube recommendations are very good.
25:59 Netflix recommendations and like prime recommendations are kind of underwhelmed by. You would think that you watch.
26:04 I agree.
26:05 Yeah. Yeah. It's still so hard to find things to watch sometimes on those platforms.
26:09 It is. And YouTube interestingly seems to have an end. So if you scroll down through YouTube, like 10 pages, it'll start showing you like, well, it seems like we're out of options. Here, we'll show you 10 from this one channel. And then we'll just kind of stop.
26:22 I know you got a lot of videos. You could just keep recommending stuff. I'm pretty sure if you would keep recommending it. There's stuff down here. But yeah, I agree. It's interesting.
26:30 I feel like it's gotten better too. Like my YouTube consumption has really picked up over the last year, I would say. The recommendation algorithms, and I don't know if it's just more content being created or maybe it's just like a personal thing for me. And there was some thing on Hacker News too about like YouTube comments that like one of the founders of Stripe posted are like generally very positive. And like there's really good comments on YouTube too. So they've definitely also come up with ways to classify comments as being high value or not.
26:58 And then put those up top. And nowadays, those models are definitely used with something like for some big neural networks and transformer.
27:07 Yeah.
27:07 Because those neural networks, they're so much better at understanding context. And like SVMs, you have to still, for a lot of these classical machine learning approaches, like feed it, hand-labeled data. But the neural networks, yeah, they're really good for those language tasks now.
27:24 Yeah, absolutely. Christopher out in the audience has a question. That's kind of interesting. Does it make sense to start with scikit-learn if, for example, you're trying to predict when a production machine is not out of tolerance yet is trending to be?
27:37 Is that like, God...
27:38 Like if you were like monitoring like a data center for maybe VMs, I'm guessing.
27:42 Like your RAM or like memory is going high or some statistic is like predictive that this VM will probably go down.
27:50 Failure is coming.
27:51 Failure is coming. Yeah.
27:53 And the question was, is it SBM or scikit-learn good to start with? Yeah, I would actually probably say that's where you want to go with something like scikit-learn.
28:00 Because there's probably very clear-cut patterns.
28:03 I would say if you're unsure of what the pattern is, then a neural network is good because a neural network can, in theory, like you're feeding it raw data and it's learning the pattern.
28:12 But if you know what the pattern is, like, okay, like there's probably like these signals that if a human was just sitting there looking at it all day, would be able to tell this system is probably going to go down.
28:23 Then you just can train an SVM or some type of classical machine learning model with scikit-learn to be able to do those predictions with pretty high accuracy.
28:31 And then you've got a super lightweight model.
28:33 You don't need much training data to train it because you're not trying to build something that's like super generalizable to like all systems or like all AWS instances.
28:41 It's probably something unique to your system.
28:43 But I would say that's kind of where the difference is.
28:45 And then it's a lot easier too because if you're trying to build like a neural net, it's like, well, what type, how many layers, what, you know, kind of like optimization schedule, like learning rate.
28:56 There's all these hyper parameters and things you have to figure out.
28:59 You still have to do that too for classical machine learning to a degree.
29:02 But if your problem is not that difficult, it's not as, you know, like fancy nowadays, but it gets the job done.
29:10 Yeah.
29:10 I suspect you could come up with some predictors and then like monitor them for in this model, whereas opposed to here's an image that is a breast scan.
29:18 Does it have cancer or not?
29:20 Right.
29:20 Like exactly.
29:21 We don't even really know what we're looking for, but there probably is a pattern that could be pulled out by a neural network.
29:26 Exactly.
29:27 Yeah.
29:27 That's a great point.
29:28 And, you know, like we're trying to build some predictive scaling for our API right now, because, you know, one of the problems with the challenges of a startup that's doing machine learning in production is, you know, we deploy like hundreds of GPUs and thousands of CPU cores into production every day at peak load.
29:45 And then there's just huge costs that come from a scale.
29:50 And then there's huge costs that come with that.
29:52 And so we've done a ton of work around like auto scaling and trying to optimize models and production and things like that.
30:01 And now we're trying to do some predictive scaling.
30:04 And for that, for example, we'd probably do something super simple with like scikit-learn.
30:08 We wouldn't do a neural net for that.
30:10 Yeah.
30:10 The scaling sounds like solving a basically a similar issue.
30:13 Yeah.
30:14 Yeah.
30:14 As understanding failure, right?
30:15 Yeah, exactly.
30:16 Exactly.
30:17 The lack of scaling sometimes is kind of the result is failure.
30:20 So yeah, they're somewhat related together.
30:23 Yeah.
30:24 You talked about like running stuff in production.
30:26 And there's obviously two aspects for machine learning companies and startups and teams and products that are very different than say the kind of stuff I do, right?
30:36 Like I've got APIs that are running.
30:38 We've got mobile apps.
30:39 We've got people taking the courses.
30:40 But all of that stuff, there is like one.
30:43 It's always the same, right?
30:45 We put stuff up and people will use it and consume it and so on.
30:48 But for you all, you've got the training and almost the R&D side of things that you've got to worry about working on and scaling.
30:55 Right.
30:55 And then you've got the productionizing.
30:57 So maybe tell us a little bit about how you, what do you guys use for-
31:02 For both parts.
31:02 For training.
31:03 Yeah.
31:03 Maybe start with the training side.
31:05 Yeah, the training side, it's basically like impossible to use the big clouds for that because it would just be prohibitively expensive, at least for what we do.
31:13 So we train like these huge neural nets for speech recognition and different NLP tasks.
31:19 And, you know, we're training them across like 48, 64 GPUs, like really powerful GPUs.
31:24 I've got the GeForce 3090, which is a beast up here.
31:28 Do you know what kind you're using?
31:30 Yeah, so we use a lot of V100s, like A100s.
31:34 And we rent, basically what we do is we rent dedicated machines from provider.
31:40 And each machine, we're able to like pick the specs that we want.
31:44 Like how many GPUs, what cards, how much RAM, what kind of CPU we want on there.
31:48 So we're able to pick the specs that we want.
31:51 And we found that that's been the best way to do it because the big clouds, yeah, if you're running like a dozen, dozens of GPU, like of the most expensive types of GPUs for like weeks on end, you could do that if you had like one training run you wanted to do.
32:06 But a lot of times you have to train a model halfway through.
32:09 It doesn't work well.
32:10 You have to restart or finish this training and the results are not that good.
32:14 And you learn something.
32:15 So you have to go back and start over.
32:16 And now what we're doing is buying a bunch of our own compute.
32:19 Like my dream is to have some closet somewhere with just like, you know, tons of GPUs and like our own like mini data center for the R&D.
32:26 Because if things go down, you know, like when you're training a model, you checkpoint it as you go.
32:31 So if your program crashes or your server crashes, like you can resume training.
32:35 Whereas like for production workloads, we use AWS for that because things can't go down.
32:40 And I don't think we'd want to take on our own competency of like hosting our own production infrastructure.
32:45 But for the R&D stuff, you know, we are looking into just buying a ton versus renting because it'd be a lot more cost efficient.
32:53 And you can, instead of basically like paying each year for the same compute, you just like buy it once.
32:58 And then you just pay for the electricity and server hosting costs and maintenance costs that come with that.
33:03 Yeah.
33:04 Maybe find a big office building and offer to heat it for free in the winter by just running on the inside.
33:09 There's this like, you know, you can run like NVIDIA SMI.
33:11 I don't even play around with GPUs at all.
33:13 But like, you can see what the temperature is of the GPU.
33:16 And like sometimes, you know, if I'm, I remember a while ago when I was training some of these models, I would just like look at what the temperature is during training.
33:24 And yeah, they get so hot.
33:25 And these data centers have to have all this, all these special cooling infrastructure to keep the machines down.
33:30 It's pretty environmentally unfriendly.
33:32 Yeah.
33:32 To the extent that some of them, yeah, to the extent that people are creating underwater data center, like nodes and putting them down there and just letting the ocean be the heat sink.
33:44 Yeah.
33:45 That's crazy.
33:45 You can buy some land and like, you know, in Arctica and put our stuff there.
33:50 That's where like the GitHub, like the Arctic code thing.
33:53 I forget what it's called.
33:54 Yeah.
33:54 Yeah.
33:55 The Arctic code vault.
33:58 Yeah.
33:58 Yes.
33:58 Yeah.
33:58 So we could do something like that for our GPUs.
34:00 When we get bigger, that's, that's the dream.
34:02 That's where it might nerd out.
34:03 There you go.
34:03 So, yeah, so we train, I think we have like, I think somewhere like maybe like 200 like GPUs that we use just for R&D and training.
34:13 And we're getting a lot more because you don't want to be, a lot of times there's like scheduling bottlenecks.
34:18 So two researchers want to run a model and need a bunch of compute to be able to do that.
34:22 And they're both good ideas.
34:23 You don't want to have to like wait four weeks for someone to run their, their model because compute is taken.
34:30 So we're trying to unblock those scheduling conflicts by just getting more compute.
34:34 Yeah.
34:34 And for the production side, yeah, we deploy everything in AWS right now and onto like smaller GPUs.
34:41 Because a lot of our models do inference on GPU still.
34:44 Some of our models do inference on CPU.
34:47 Oh, interesting.
34:47 Yeah.
34:48 To, to evaluate the stuff, it still uses GPUs.
34:51 Yeah.
34:51 Correct.
34:52 Even after the models are created.
34:52 Correct.
34:53 Yeah.
34:53 I mean, there's, we could run it on CPU, but it's just not as parallelizable as running
34:58 it on GPUs.
34:58 There's a lot of work that we could probably do to get it really efficient so that, you know,
35:04 we're running it on like as few CPU cores as possible.
35:06 But one of the problems is like almost like every like three to four months, we're like throwing
35:11 out the current neural network architecture and using a different one that is giving us better
35:15 results.
35:15 Like sometimes we'll make the model bigger or there'll be a small tweak in the model
35:19 architecture that yields better results.
35:21 But a lot of times it's like, okay, we've kind of iterated within this architecture as
35:25 much as we can.
35:26 And now to get the next accuracy bump, we have to go to a new architecture.
35:29 We're undergoing that right now.
35:31 We've released our, one of our like newer speech recognition models we released, I think
35:36 like three months ago and the results are really good, but now we have one that is looking
35:40 a lot better and it'd be like a completely different architecture.
35:43 And so it's just that trade off of, do you spend a bunch of time optimizing the current
35:48 model that you have and trying to like prune the neural network and do all these optimizations
35:54 to get it really small?
35:55 Or do you just spend that research effort and that energy focused on finding the next accuracy
36:00 game?
36:01 And because we're trying to win customers and grow our revenue, it's just, all right, let's
36:06 just focus on the next model.
36:07 And when we have a big enough team or when we can focus on it, we'll work on making the
36:11 models smaller and more compute efficient and less costly to run.
36:16 But right now, yeah.
36:17 Like our speech recognition model that does inference on a GPU.
36:21 There's a couple of our like NLP related models, like our content moderation model that does
36:26 inference on a GPU.
36:28 And then there's like our automatic punctuation and casing restoration model.
36:31 Like that runs on a CPU because that's not as compute intense.
36:35 And so it really varies.
36:37 Yeah.
36:37 Yeah.
36:37 Yeah.
36:37 As you say, it's pretty interesting to think about how you're optimizing the software
36:41 stack and the algorithms and the libraries and whatnot.
36:44 You know, when you're not doing something that's changing so quickly, you know, if it's working,
36:51 you can kind of just leave it alone.
36:53 Right.
36:53 Like, right.
36:54 I've got some APIs, I think they're built either in Pyramid or Flask.
36:58 Sure.
36:58 It'd be nicer to rebuild them in FastAPI, but they're working fine.
37:02 I'm just like, I have no reason to touch them.
37:04 Right.
37:04 So there's not a, like a huge step jump I'm going to take.
37:08 They're not under extreme load or anything.
37:11 Right.
37:13 This portion of Talk Python To Me is brought to you by Sentry.
37:17 How would you like to remove a little stress from your life?
37:19 Do you worry that users may be encountering errors, slowdowns, or crashes with your app right
37:25 now?
37:25 Would you even know it until they sent you that support email?
37:28 How much better would it be to have the error or performance details immediately sent to you,
37:33 including the call stack and values of local variables and the active user recorded in the
37:39 report?
37:39 With Sentry, this is not only possible, it's simple.
37:42 In fact, we use Sentry on all the Talk Python web properties.
37:46 We've actually fixed a bug triggered by a user and had the upgrade ready to roll out as we
37:51 got the support email.
37:52 That was a great email to write back.
37:54 Hey, we already saw your error and have already rolled out the fix.
37:58 Imagine their surprise.
37:59 Surprise and delight your users.
38:01 Create your Sentry account at talkpython.fm/sentry.
38:05 And if you sign up with the code talkpython, all one word, it's good for two free months of
38:11 Sentry's business plan, which will give you up to 20 times as many monthly events as well
38:16 as other features.
38:17 Create better software, delight your users, and support the podcast.
38:22 Visit talkpython.fm/sentry and use the coupon code talkpython.
38:29 But in your world, there's so much innovation happening around the models that you do have
38:36 to think about that.
38:37 So how do you work that tradeoff?
38:38 How do you like, well, could we get more out of what we've got or should we abandon it and
38:42 start over?
38:43 Right?
38:43 Because it is nice to have a very polished and well-known thing as well.
38:47 Definitely.
38:48 And every time you throw out our architecture to implement a new architecture, you've now
38:52 got to figure out how to run that architecture at scale.
38:54 And you don't want to have any hiccups for your current customers or users of your API, which
38:59 sometimes happens because these models are so big that you can't just write this model
39:03 that service that sits on a GPU and does everything.
39:06 You have to break it up into a bunch of component parts so that you can run it efficiently at
39:10 scale.
39:11 So there's like eight, nine microservices for a single model because you break out all
39:17 these different parts and try to get it running really efficiently in parallel.
39:20 But it does beg the question of how do you build good CI/CD workflows and good DevOps workflows
39:25 to get models into production quickly?
39:26 And this is something that we're working on right now and trying to solve.
39:31 Because a lot of times we have better models and we sit on them for like two, three weeks
39:34 because to get them into staging, we have to do low testing, see does anything with scaling
39:39 have to change because the model profile is different?
39:42 Are there any weird edge cases that we didn't check or see during testing?
39:46 So it slows down the rate of development because you have, it's hard to do CI/CD.
39:53 It's not like you just, okay, run these tests, the code works, go.
39:57 There's like compute profile changes that happen.
39:59 So maybe you need a different instance type or you need to...
40:02 Right.
40:03 Uses less CPU, but way more RAM.
40:05 So if you actually deploy, it's going to crash or something.
40:07 Okay.
40:07 Exactly.
40:08 And then doing that at scale, you have to profile out and do low testing.
40:12 And so really, we're trying to figure out how to get these models into production faster.
40:15 And I think the whole ML ops world is so in its infancy around things like that.
40:21 And it's a lot of work.
40:23 Yeah.
40:23 It's a lot of work.
40:24 So for us, the trade-off though is always like, you know, our customers and developers,
40:28 they just want better results and always more accurate results.
40:31 And so we just always are working on pushing our models, making them more accurate.
40:36 If we can iterate within a current architecture, great.
40:39 Like sometimes you can just make the model bigger or make a small change and then you get
40:43 a lot of accuracy improvements.
40:44 And it's just like what we call it a drop-in update where no code changes.
40:48 It's just literally like the model that you're loading is just different.
40:51 And then it's just more accurate.
40:53 Right.
40:53 That's easy.
40:53 Yeah.
40:54 That's the dream.
40:54 You know, it's just a drop-in, but that's maybe like 30% of updates.
40:59 Like the other 70% are, okay, you've got a new architecture or it's got a pretty different
41:03 compute profile.
41:04 So it uses a lot more RAM or it's a lot slower to load in the beginning.
41:08 So we need to scale earlier because instances come online later and become healthy later.
41:14 So there's all these like things you have to think about.
41:17 Yeah.
41:17 The whole DevOps side of this sounds way more interesting and involved than I first thought.
41:22 Yeah.
41:22 It's painful too.
41:23 I mean, we're like, I can't explain how many like graphs we have in Datadog, just like monitoring
41:27 things all day.
41:28 Luckily, I don't have to work on that anymore.
41:31 That was very stressful.
41:33 And I was like owning the infrastructure.
41:35 Now we have people that are better at it than me.
41:37 We had like two DevOps people start on Monday, but yeah, like DevOps is a huge, huge piece
41:41 of this.
41:42 Yeah.
41:42 That's quite interesting.
41:43 Yeah.
41:43 I do want to just circle back to one real quick thing.
41:45 You talked about buying your own GPUs for training and people might out there be thinking
41:48 like, who would want to go and get their own hardware in the day of AWS, Node, whatever,
41:54 right?
41:55 Like it just seems crazy.
41:56 But there's certainly circumstances.
41:58 Like here's an example that I recently thought about.
42:00 So there's a place called Mac Stadium where you can get Macs in the cloud.
42:03 Hey, how cool, right?
42:04 So maybe you want to have like something you could do with extra things.
42:07 And well, what does it cost?
42:08 Well, for a Mac mini M1, it's $132 a month.
42:14 You think that's, is that high or low?
42:15 Well, the whole device, if you were to buy it costs $700.
42:19 Yeah.
42:20 You know, that's, and I suspect that even though the GPUs are expensive, there's probably something
42:26 where like, if you really utilize it extensively, it actually makes.
42:29 To buy it.
42:30 It stops making sense in ways that people might not expect.
42:33 Yeah.
42:33 That it's a buy it, you mean, right?
42:35 Like it stops making sense to rent it.
42:36 Yeah.
42:36 That's what we're facing.
42:37 It stops making sense to rent it in the cloud.
42:38 Yeah.
42:38 Yeah.
42:39 I mean, we spent a crazy amount of money renting GPUs in the cloud and it's like, okay, you
42:45 know, if we had a bunch of money to make a, you know, CapEx purchase, right?
42:49 Like just shell out a bunch of money to buy a bunch of hardware up front, it'd be so much
42:53 better in the long run.
42:54 Cause it is similar to the example you made about like, if you don't have a lot of cash, then you're
42:59 only going to use a Mac for a couple months.
43:01 Right.
43:01 You need it for two weeks.
43:02 Then it doesn't make sense to buy it.
43:03 Great.
43:04 You just, you pay the a hundred dollars and you're good.
43:05 Right.
43:06 Right.
43:06 Or if you don't have like 2k and you know, then, then you just rent in and it's like,
43:11 you know, if you don't have the money to buy a house, you rent an apartment, right?
43:14 Like things like that.
43:15 So there are definitely benefits.
43:17 And I think for a lot of, I think for most models, you don't need crazy compute.
43:22 Like you could get away with, like, you could buy a desktop device that has like two GPUs
43:28 or you could rent a dedicated machine or still do it on AWS if you're using like one or two
43:32 GPUs.
43:32 And it wouldn't be insane.
43:34 So if you're just starting out, all those options are fine.
43:37 But if you're trying to do like big models and, or train a bunch of parallel, you need
43:42 more compute.
43:43 And definitely doesn't make sense to use the big clouds for that.
43:47 There's a bunch of dedicated providers that you can rent, like dedicated machines from
43:51 and just pay a monthly fee regardless of how much you use it.
43:55 And, it's a lot more, it's a lot more efficient for like companies to do that.
43:59 Give me your thoughts on sort of CapEx versus OpEx for ML startups rather than, I don't know,
44:06 it's some other SaaS service that doesn't have such computational stuff, you know, being
44:11 CapEx being, you got to buy a whole bunch of machines and GPUs and stuff versus OpEx.
44:16 Like, well, it's going to cost this much to rent in the cloud.
44:18 Like I feel like things are more possible because you can get the stuff in the cloud,
44:24 prove an idea and then get investors without going, well, you know, let's go to friends
44:29 and family and get 250,000 for GPUs.
44:31 And if it doesn't work, we'll just do Bitcoin.
44:32 Yeah.
44:33 Yeah, yeah, yeah.
44:34 Definitely.
44:34 I mean, we started in the cloud, right?
44:36 So like first models we trained were K80s on K80s and AWS took like a month to train.
44:43 Wow.
44:43 Yeah, it was terrible.
44:44 So we started in the cloud and then now that we're fortunate to have like more investment
44:49 in the company, we can make these CapEx purchases.
44:51 But yeah, I mean, the operating expenses of running an ML startup are also like crazy, like
44:56 payroll and GP and payroll and like AWS are our biggest expenses because you run so much
45:02 compute and it's super expensive.
45:04 And what I talk about and what we talk about is like, there's nothing fundamental about what
45:09 we're doing that makes that the case.
45:11 It's just goes back to that point of like, do you spend a couple months optimizing your models,
45:16 bringing compute costs down?
45:18 Or do you just focus on the new architecture and kind of pay your way to get to the future?
45:23 Like this growth versus, yeah.
45:26 And then we're like a venture-backed company.
45:28 So like there's expectations around our growth and, you know, all that.
45:31 So we just focus on like, okay, let's just get to the next milestone and not focus too much
45:36 on like bringing those costs down because there's the opportunity cost of doing that.
45:40 But eventually we'll have to.
45:42 Yeah.
45:43 It's a little bit of the ML equivalent of sort of the growth.
45:48 You can lose money to just gather users.
45:51 Yeah.
45:52 But this is the sort of gain capabilities, right?
45:55 It is.
45:55 Yeah, it is 100%.
45:56 And then you'll figure out how to do it efficiently once you kind of find your way.
46:00 Okay.
46:00 And I'll give you like a tangible example.
46:02 I mean, like we've been adding a lot of customers and developers on the API and there's always like
46:08 new scaling problems that come up.
46:09 And sometimes we're just like, look, let's just scale the whole system up.
46:13 It's going to be inefficient.
46:14 There's going to be waste, but like let's scale it up and then we'll like fine tune the auto
46:18 scaling to bring it down over time versus like having to step into like a more perfect auto
46:26 scaling scenario that wouldn't cost as much, but there'd be bumps along the way.
46:30 And so we just like scaled everything up recently to buy us time to go work on figuring out how
46:35 to improve some of these like auto scaling.
46:37 Yeah.
46:38 Yeah.
46:38 You could spend two weeks trying to figure out the right way to go to production or you
46:42 could spend just more money.
46:44 Exactly.
46:45 And then, cause you, you might not be sure with the, like the multiple month life cycle,
46:51 some of these things.
46:52 Right.
46:53 Is this actually going to be the way we want to stick with?
46:55 So let's not spend two weeks optimizing it first.
46:57 Right.
46:57 Very interesting.
46:58 And I mean, like, look, not every company can make that decision.
47:01 Like if you are bootstrapped or you're trying to get off the ground, which like a lot of companies
47:05 are, you do have to make those, you can't just pay your way to the future.
47:09 Yeah.
47:09 And I'm a big fan of bootstrapped companies and finding your way.
47:14 I don't think that necessarily just, you know, set a ton of money on fire.
47:17 Right.
47:18 It's the only way forward.
47:19 But if you have backers already, then they would prefer you to move faster.
47:24 I suspect.
47:25 Correct.
47:25 Yeah.
47:26 Correct.
47:26 Correct.
47:27 Like I always was self-conscious about our, you know, operating costs as an ML company,
47:31 cause they're high compared to other SaaS companies where you don't have heavy compute,
47:36 but you know, the investors we work with, they get that like, okay, this isn't, there's
47:41 nothing like that fundamental about this that requires those costs to be high.
47:45 You just have to spend time on bringing them down and it's, there's like a clear path.
47:49 It's not like Uber where it's like the path to bring costs down or like self-driving cars
47:54 because it's expensive to employ humans.
47:56 That's like, you know, so far down the road.
47:59 Yeah.
47:59 But for us, it's like, okay, we need to just spend three months making these models more
48:03 efficient and they'll run a lot cheaper, but it's that trade-off.
48:08 But I love bootstrap companies too.
48:10 I mean, it's just a different way to do it.
48:11 Something special about like, you're actually making a profit and you're actually, you have
48:16 customers and people paying for stuff.
48:18 Yeah.
48:19 Yeah.
48:19 Yeah.
48:20 And the, and the freedom for sure.
48:21 Yeah.
48:21 So you probably saw me messing around with the screen here to pull up this Raspberry Pi
48:25 thing.
48:25 There's a question out in the audience says, could you do this kind of stuff on a Raspberry
48:29 Pi?
48:30 And like a standard Raspberry Pi, I suspect absolutely no.
48:33 Yeah.
48:34 Have you ever seen that there are water-cooled Raspberry Pi clusters?
48:37 Whoa.
48:37 I have not seen that.
48:39 That is crazy.
48:40 Is that insane?
48:40 That's insane.
48:41 So what kind of computer are they getting on that?
48:44 It's pretty comparable to a MacBook Pro on this.
48:47 That's crazy.
48:48 They've got what, eight water-cooled Raspberry Pis in a cluster.
48:51 And it's really an amazing device.
48:53 But if you look back at a, you know, you sort of consider it like a single PC with a, you
49:00 know, a basic Nvidia card or a MacBook Pro or something like that.
49:04 Like that's still pretty far from what you guys need.
49:06 Like how many GPUs did you say you were using to train your models?
49:09 It's like 64 for the bigger ones.
49:12 Yeah.
49:12 In parallel.
49:13 Yeah.
49:14 Yeah.
49:14 These are not small GPUs.
49:16 So I suspect I'm going to maybe throw it out there for you and say probably no, maybe
49:21 for the scikit learn type stuff, but not for what you're doing.
49:23 Not the TensorFlow PyTorch.
49:25 Yeah.
49:25 Not for, not for training, but you could do inference on a Raspberry Pi.
49:30 Like you could squeeze a model down super tiny, like what they do to get some models
49:34 onto your phones.
49:35 And you're on that on a Raspberry Pi.
49:37 You get the models small enough.
49:39 The accuracy might not be great, but like you could do it.
49:41 Yeah.
49:41 Oh, there's a lot of stuff happening around the edge.
49:43 Like I think a lot of that Siri.
49:45 Yeah.
49:45 The edge compute, the sort of ML on device type stuff.
49:48 Like a lot of the speech recognition on your phone now happens on device.
49:52 Yeah.
49:52 Yeah.
49:52 And not in the cloud.
49:53 Yeah.
49:53 Sort of related to this, like the new M1 chips and even the chips in the Apple phones before
50:00 then come with like neural engines built in, like multi-core neural engines.
50:04 Right.
50:04 Interesting for edge stuff again, but not really going to, not really going to let you do like
50:09 the training and stuff like that.
50:11 Right.
50:11 I haven't done much iOS development, but I know there's like SDKs now to kind of like get your
50:16 neural networks like on device and make use of these, like the hardware on the phone.
50:20 And definitely if you're trying to deploy your stuff on the edge, there's a lot more
50:24 resources available to you.
50:26 Yeah.
50:26 Yeah.
50:26 And it's a really good experience because having, you know, you speak to your assistant
50:31 or you do something and it says thinking, thinking like, okay, well that I don't want
50:35 that.
50:35 Like, I'll just go do it if I got to wait 10 seconds.
50:37 Right.
50:37 Yeah.
50:38 But it happens immediately.
50:38 And there's the privacy aspect too.
50:40 Yeah, absolutely.
50:41 The privacy is great.
50:42 Yeah.
50:43 Like the wake word on the, like, I don't know if you know this, but like the wake
50:46 words, like on the Alexa device, like they happen local, that runs locally.
50:49 Although I've heard, I've heard that when you say Alexa, they verify it in the cloud
50:55 with a more powerful model.
50:56 Interesting.
50:57 Because sometimes it'll trigger and then shut off.
50:58 I don't know if you've ever seen that happen.
51:00 Yeah.
51:00 It's, it'll spin around and go, ah, no, that wasn't right.
51:03 Yeah, exactly.
51:04 I think what's happening is that they're sending what they're sending like the wake
51:07 word to the cloud to verify.
51:08 Like, did you actually say Alexa?
51:09 Probably the local models below some certain confidence level, it sends it up to the cloud and then
51:15 the cloud verifies like, yeah, start, start processing.
51:17 But it is much faster from a latency perspective.
51:20 Although with, with 5G, I don't know, like mobile internet is so much, it's faster now.
51:25 It's getting pretty crazy.
51:26 Yeah.
51:26 Yeah, absolutely.
51:27 Yeah.
51:27 Sometimes I'll be somewhere my wifi is slow and I'll just tether my phone and it's like
51:32 faster.
51:32 Yeah.
51:32 Yeah.
51:33 If I'm not at my house, I usually do that.
51:35 If I go to a coffee shop or an airport, I'm like, there's a very low chance that the wifi
51:39 here is better than my 5G tethered.
51:41 Yeah.
51:41 Yeah.
51:41 Exactly.
51:42 Exactly.
51:42 Exactly.
51:45 Jack Woody out in the audience has a real interesting question.
51:47 I think that you can speak to because you're in this space right now, living it.
51:54 What do investors look at when considering an AI startup or maybe AI startup, not just specifically
51:59 speech to text?
52:01 Yeah.
52:01 It's a good question.
52:02 I think it really depends on like, are you building like a vertical application that makes
52:07 use of the AI?
52:07 So you're building some like call center optimization software where there's like AI under the hood,
52:13 but you're, you're using it to power this like business use case versus are you building
52:18 some like, like infrastructure AI company?
52:20 Like we're us, like we're building APIs for speech to text, or if you're building a company
52:25 that's exposing like APIs for NLP or different types of tasks, I think it varies what they
52:30 look at.
52:31 I am not an expert in like fundraising or AI startups.
52:35 I want to make that very clear.
52:36 Like, so, so maybe don't take my advice too, too seriously.
52:39 Yeah, but you've done it successfully, which is, I mean, there are people who claim to
52:44 be experts, but are not currently running, you know, a successful backed company.
52:48 So I wouldn't put too much of a caveat there.
52:51 Yeah.
52:51 I think we just got lucky with, you know, meeting some of the right people that have helped us.
52:55 But I think it's like, yeah, you know, are you, are you doing something innovative on the
52:59 model side?
53:00 Do you have some innovation on the architecture side?
53:03 I actually don't really think the whole like data vote is that strong of an argument personally,
53:08 because there's just so much data on the internet now.
53:10 And did a moat being like, we run Gmail so we can scan everybody's email.
53:14 That gives us a competitive advantage.
53:16 Yeah.
53:16 Yeah.
53:17 Something like that.
53:18 Exactly.
53:18 Yeah.
53:18 I don't know.
53:19 Like you might get like a slight advantage, but there's so much data on the internet and
53:23 there's so many, there's so many innovations happening around.
53:26 Like, look at, look at GPT-3 that OpenAI put out, right?
53:29 That was just trained on like crazy amount, a huge model trained on crazy amounts of public
53:34 domain data on the internet.
53:36 That works so well across so many different tasks.
53:38 So even if you had a data mode for a specific task, like it's arguable that GPT-3 could beat
53:45 you at that task.
53:46 So I think it depends what you're doing, but I don't personally buy into the whole data mode
53:51 thing that much.
53:52 You know, cause like even for us, we're able to build some of the best speech to text models
53:56 in the world.
53:57 And we don't have this like secret source of data.
54:01 You know, we, we just have a lot of innovation on the model side and there's tons of domain
54:05 data in a public domain that you can access now.
54:08 So I think it's really about like, are you building some type of application that is making
54:13 the lives of like a customer developer, some startup, like easier leveraging AI?
54:19 Right.
54:19 Are you solving a problem that people will pay money to solve?
54:22 Yeah.
54:23 Yeah, exactly.
54:23 Exactly.
54:24 Cause I actually think it's more about like the distribution of the tech you're building
54:28 versus the tech itself.
54:29 So like, are you packaging it up in an easy to use API or is like the, imagine you're
54:36 selling something to like podcast hosts that uses AI.
54:39 I mean, AI could be amazing, but if like the user interface sucks, you know, like you're,
54:44 you're not going to use it.
54:45 Here's what you do.
54:45 You're going to make a post request over to this and you put this header in and like, it's
54:49 going to like, here's how you do paging and you're like, no, no, here's the library
54:53 in your language.
54:53 You call the one function, things happen, right?
54:55 Like how presentable or straightforward do you make it right?
54:58 Right.
54:59 Cause I actually think that's a huge piece of it.
55:01 Are you, are you making it easier?
55:02 Are you making, is the distribution around the technology you're creating like really powerful
55:06 and, and like, do you have good ideas around that?
55:09 So I think it's a combination of those things, but to be honest, I think really depends on
55:13 what you're building and what the product is or what you're doing.
55:16 Cause it varies, like really it varies a lot.
55:18 Yeah.
55:18 There's also the part that we as developers don't love to think about, but the marketing
55:25 and awareness and growth and traction, right?
55:28 Yeah.
55:29 It's, you could say, look, here's the most amazing model we have.
55:32 Well, we haven't actually got any users yet, but that is a really hard sell for investors
55:36 unless they absolutely see, you know, this has huge potential.
55:40 Right.
55:40 But if you're like, look, we've got this much monthly number of users and here's the
55:46 way we're going to start to up, you know, create a premium offering.
55:49 And yeah.
55:49 Yeah.
55:50 Right.
55:50 That that's something we're not particularly skilled at as developers, but that's a non-trivial
55:56 part of any tech startup.
55:57 Right.
55:57 Oh yeah.
55:58 And I think as a developer too, you kind of like shy away from wanting to work on that
56:01 because it's so much easier to just write code or build a new feature versus like go solve
56:05 this hard marketing problem or go like.
56:08 Marketing sales.
56:09 Like you gotta have them, even if you're bad at them and you don't like it.
56:12 Yeah.
56:12 And we're fortunate that we get to market it to developers.
56:14 So like I enjoy it, you know, and cause you get like to talk to developers all the time,
56:20 but yeah, that's a huge piece of it too.
56:22 Definitely.
56:22 Definitely.
56:23 It's, it's kind of all come together.
56:24 Yeah.
56:25 This up a little bit, we're getting sort of near the end, but let's talk about,
56:28 you've got this idea of you've got your models, you've got your libraries, you've trained them
56:32 up using your GPUs.
56:33 Now you want to offer it as an API.
56:36 Like how do you go to production with a machine learning model and do something interesting?
56:41 You want to talk about how that's where I know you talked a little bit about running
56:44 the cloud and whatnot, but yeah.
56:46 You know, do you offer as an API over Flask or run it in a cloud?
56:50 Like what are you doing there?
56:51 Are they Lambda functions?
56:52 Yeah, that's a good, that's a good question.
56:53 What's your world look like?
56:54 So we have asynchronous APIs where you send in an audio file and then we send you a
57:00 webhook when it's done processing.
57:01 And then we have real-time APIs over WebSocket where you're streaming audio and you're getting
57:05 stuff back over a WebSocket in real time.
57:07 The real-time stuff's a lot more challenging to build.
57:10 I'm sure it is.
57:11 Yeah.
57:11 Yeah.
57:12 The async stuff.
57:13 Really what happens is we have like, so one of our main APIs was built in Tornado.
57:18 I don't know if you, yeah.
57:19 Legacy.
57:20 The early, early async enabled Python web framework before asyncio was officially a thing.
57:26 Yep.
57:27 So I built the first version of the API in Tornado.
57:30 So it's kind of like still in Tornado for that reason.
57:33 A lot of the newer things or newer microservices are built by FastAPI or Flask.
57:38 And so for the asynchronous API, what happens is like you're making a post request.
57:43 The API is really just like a CRUD app.
57:44 It's storing a record of the request that you made with all the parameters that you turned
57:49 on or turn off.
57:50 And then that goes into a database.
57:52 Some worker that's like the orchestrator is constantly looking at that database and it's
57:57 like, okay, there's some new work to be done.
57:59 And then kicks off all these different jobs to all these different microservices, some over
58:04 queues, some over HTTP, collects everything back, orchestrates like what could be done in
58:09 parallel, what depends on what to be done first.
58:12 When that's all done, all the kind of asynchronous like background jobs, the orchestrator pushes
58:18 the final result back into our primary database.
58:21 And then that triggers you getting a webhook with the final result.
58:25 So that's like in a nutshell, kind of what the architecture looks like for the asynchronous
58:29 workloads.
58:30 There's like tons of different microservices, all with different instance types.
58:34 different like compute requirements, some GPU, some CPU, some, you know, like all different
58:40 scaling policies.
58:41 And that's really where the hard part is.
58:43 That's kind of like the basic overview of how the asynchronous stuff works in production.
58:47 Yeah.
58:48 Yeah.
58:48 Very cool.
58:48 Yeah.
58:49 Are you seeing Postgres or MySQL or something like that?
58:52 Postgres for the primary DB.
58:54 Because we're on AWS, we use DynamoDB for a couple of things like ephemeral records we need
58:59 to keep around for when you send something in, it goes to DynamoDB.
59:02 And that's where we like keep track of basically like your request and what parameters you add
59:08 on and off.
59:08 And that kicks off a bunch of things.
59:10 But the primary DB is Postgres.
59:11 Yeah.
59:12 I think there's like, at this point, like it's getting pretty large.
59:15 There's like a few billion records in there.
59:18 Because we process like a couple million audio files a day with the API.
59:22 Sometimes I'll read on Hacker News like these, I think like GitHub went down at one point
59:27 because they couldn't increment the primary key values any higher.
59:31 It's, int 64 is overflowing.
59:34 We're done.
59:34 Yeah, yeah.
59:35 Something like that.
59:36 Yeah.
59:36 I mean, in the back of my mind, like I hope we're thinking about something like that because
59:39 that would be really bad if we came up against something like that.
59:42 Do you store the audio content in the database or are they going like some kind of bucket,
59:48 some object storage thing?
59:49 So we're unique in that we don't store a copy of your audio data.
59:52 Okay.
59:53 For privacy reasons for you.
59:55 So you send something in, it's stored ephemerally like in the memory of the machine that's processing
01:00:01 your file.
01:00:01 And then what's stored is the transcription text encrypted at rest because you need to be able
01:00:05 to make a GET request for the API to fetch it.
01:00:07 But then you can follow up with a delete request to permanently delete the transcription text from
01:00:12 our database.
01:00:12 So we try to like keep no record of the data that you're processing because like we want
01:00:18 to be really privacy focused and sensitive.
01:00:22 You can, like some customers will toggle on that.
01:00:25 We keep some of their data to continuously improve the models, but by default, we don't store anything.
01:00:31 Yeah, that's really cool.
01:00:32 Yeah.
01:00:32 That's good for privacy.
01:00:34 It's also good for you all because there's just less stuff that you have to be nervous about
01:00:38 when you're trying to fall asleep.
01:00:40 You're like, what if somebody broke in and got all the audio?
01:00:42 Oh wait, we don't have the audio.
01:00:43 Okay.
01:00:43 So that's not a thing they could get.
01:00:44 Yeah.
01:00:45 Like things like that, right?
01:00:46 Yeah.
01:00:46 Yeah.
01:00:47 It's definitely, definitely.
01:00:50 I hadn't thought about that before, but I'm imagining now what that would be like.
01:00:53 Well, now I'm making, now you're going to be nervous because there's probably other stuff,
01:00:56 but that's all right.
01:00:56 Yeah.
01:00:56 Now you got me thinking about in that space.
01:01:00 Like what are those things we need to lock up?
01:01:02 No, we have like, we're mostly a team of engineers.
01:01:05 So I think of the 30 people, like 70% are engineers with a lot more experience than me.
01:01:11 So we're doing everything like by the book, especially with the business that we're in.
01:01:15 Yeah.
01:01:15 Yeah.
01:01:15 Of course.
01:01:16 Yeah.
01:01:16 All right, Dylan, I think we're out of time, if not out of topic.
01:01:19 So let's maybe wrap this up a little bit with the final two questions and some packages and
01:01:25 stuff.
01:01:25 So if you're going to work on some Python code, what editor are you using these days?
01:01:29 I'm still using Sublime.
01:01:31 Right on.
01:01:31 What do you use?
01:01:32 The OG easy ones.
01:01:34 I'm mostly PyCharm.
01:01:35 If I want to just open a single file and look at it, I'll probably use VS Code for that.
01:01:40 That's probably just, you know, I want to open that thing.
01:01:42 Not have all the project ideas around it, but I'm doing proper work.
01:01:46 Probably PyCharm these days.
01:01:47 Yeah.
01:01:47 Yeah.
01:01:48 That makes sense.
01:01:48 Yeah.
01:01:49 And then a notable PyPI project, some library out there.
01:01:52 I mean, you've already talked about it, like TensorFlow and some others, but anything out
01:01:56 there you're like, oh, we should, you should definitely check this out.
01:01:58 I would check out Hugging Face if you haven't yet.
01:02:00 It's a pretty cool library.
01:02:01 Yeah.
01:02:02 A pretty cool library.
01:02:03 Yeah.
01:02:03 Hugging Face seems like a really interesting idea.
01:02:05 Yeah.
01:02:05 I want to give a quick shout out to one as well that I don't know if you've seen this.
01:02:09 Have you seen TLS, please, as an LS replacement?
01:02:13 No.
01:02:14 Chris May told me about this yesterday.
01:02:16 Told me and Brian for Python Bytes.
01:02:18 Check this out.
01:02:19 So it's a new LS that has like icons and it's all developer focused.
01:02:24 So like if you've got a virtual environment, it'll show that separately.
01:02:27 If you've got a Python file, it has a Python icon.
01:02:30 The things that appear in the list are controlled somewhat by the git ignore file and other things
01:02:34 like that.
01:02:35 And you can even do like a more detailed listing where it'll show like the git status of the
01:02:40 various files.
01:02:41 Isn't that crazy?
01:02:41 That's really cool.
01:02:42 Yeah.
01:02:42 That's really cool.
01:02:43 That's a Python library, PLS.
01:02:44 PLS.
01:02:45 That's awesome.
01:02:46 I'll check that one out.
01:02:46 Yeah.
01:02:47 Yeah.
01:02:47 People can check that out.
01:02:48 Yeah.
01:02:48 All right.
01:02:49 Dylan, thank you so much for being on the show.
01:02:51 It's really cool to get this look into running ML stuff.
01:02:55 Yeah.
01:02:55 And production and whatnot.
01:02:57 Thanks for having me on.
01:02:58 Yeah.
01:02:59 You bet.
01:02:59 You want to give us a final call to action?
01:03:00 People interested in sort of maybe doing an ML startup or even if they want to do things
01:03:06 with Assembly AI?
01:03:07 If you want to check out our APIs for automatic speech and text, you can go to our website,
01:03:11 assemblyai.com.
01:03:13 Get a free API token.
01:03:14 You don't have to talk to anyone.
01:03:15 You can start playing around.
01:03:17 There's a lot of Python code samples that you can grab to get up and running pretty quickly.
01:03:20 And then, yeah, if you're interested in ML startups, I think that one of the things that
01:03:25 I always recommend is if you want to go the funding route, definitely check out Y Combinator
01:03:31 as a place to apply because that really helped us get off the ground.
01:03:35 They help you out with a lot of credits around GPUs and resources.
01:03:39 And it helps a lot.
01:03:40 That helped us a lot.
01:03:41 Were you in the 2017 cohort?
01:03:43 Yeah.
01:03:43 Something like that.
01:03:44 Yeah.
01:03:45 2017.
01:03:45 So it was super helpful.
01:03:47 And I would highly recommend that.
01:03:48 There's also just a big community of other ML people that you can get access to through
01:03:53 that.
01:03:53 So that really helped.
01:03:55 And I would recommend people check that out.
01:03:57 How about if I don't want to go PC funded?
01:04:00 Yeah.
01:04:00 Go ahead.
01:04:01 Yeah.
01:04:01 So one more is there's also an online accelerator called Pioneer.
01:04:05 I don't know if you've heard of this, but that's also a good one to check out too.
01:04:09 If you don't want to go the accelerator route, then I would say like, yeah, really it's just
01:04:15 about getting a model working good enough to like close your first customer and then just
01:04:19 like keep iterating, you know?
01:04:20 So like don't get caught up in like reaching state of the art or yeah.
01:04:23 Like in the research, just like kind of think of like the MVP model that you need to build.
01:04:27 They go win your first customer and they kind of keep going from there.
01:04:30 Yeah.
01:04:31 Awesome.
01:04:31 All right.
01:04:32 Well, thanks for sharing all your experience and for being here.
01:04:34 Yeah.
01:04:35 Yeah.
01:04:35 Thanks for having me on.
01:04:36 This was fun.
01:04:36 Yeah, you bet it was.
01:04:37 All right.
01:04:37 Bye.
01:04:38 This has been another episode of Talk Python To Me.
01:04:41 Thank you to our sponsors.
01:04:43 Be sure to check out what they're offering.
01:04:45 It really helps support the show.
01:04:46 For over a dozen years, the Stack Overflow podcast has been exploring what it means to
01:04:51 be a developer and how the art and practice of software programming is changing the world.
01:04:55 Join them on that adventure at talkpython.fm/stack overflow.
01:04:59 Take some stress out of your life.
01:05:02 Get notified immediately about errors and performance issues in your web or mobile applications with
01:05:07 Sentry.
01:05:07 Just visit talkpython.fm/sentry and get started for free.
01:05:12 And be sure to use the promo code talkpython, all one word.
01:05:16 Want to level up your Python?
01:05:17 We have one of the largest catalogs of Python video courses over at Talk Python.
01:05:21 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:05:26 And best of all, there's not a subscription in sight.
01:05:29 Check it out for yourself at training.talkpython.fm.
01:05:32 Be sure to subscribe to the show.
01:05:34 Open your favorite podcast app and search for Python.
01:05:37 We should be right at the top.
01:05:38 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:05:43 and the direct RSS feed at /rss on talkpython.fm.
01:05:47 We're live streaming most of our recordings these days.
01:05:51 If you want to be part of the show and have your comments featured on the air,
01:05:54 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:05:59 This is your host, Michael Kennedy.
01:06:00 Thanks so much for listening.
01:06:02 I really appreciate it.
01:06:03 Now get out there and write some Python code.
01:06:05 Thank you.