Meet Beanie: A MongoDB ODM + Pydantic



You should be using an ODM. This time we're talking about Beanie which is one of the exciting, new MongoDB Object Document Mappers which is based on Pydantic and is async-native. Join me as I discuss this project with its creator: Roman Right.
Episode Deep Dive
Guest Introduction and Background
Roman Wright is a seasoned Python developer and creator of Beanie, an async-native ODM (Object Document Mapper) for MongoDB built on top of Pydantic. He has extensive experience with Django, FastAPI, and modern Python tooling. During this episode, Roman shares how he came to write Beanie—initially just to fill a need for an async ODM—and how working on production applications with Beanie helps him refine and evolve the library.
What to Know If You're New to Python
If you're newer to Python and want to follow along with the conversations about async, data modeling, and frameworks mentioned in the show, here are a few quick points:
- Make sure you have a basic grasp of Python classes and importing libraries.
- Know that “async” (asynchronous) code lets your program handle multiple tasks without waiting for them to finish in order.
- Understanding type hints (Python typing) can help when working with libraries like Pydantic.
- MongoDB interacts nicely with Python, but typically you’ll want an ODM (Object Document Mapper) like Beanie to handle data models and queries more cleanly.
Talk Python Runs on Beanie & MongoDB
Did you know that the very site you’re on—talkpython.fm—is powered by Beanie and MongoDB? We’ve found this stack to be both extremely performant and a joy to develop on, and it truly showcases how well Beanie integrates into a real-world production environment.
Key Points and Takeaways
- Beanie + Pydantic for MongoDB
Beanie stands out by combining Pydantic’s data validation and parsing with MongoDB’s async driver, Motor. This enables a well-structured, type-safe approach, rather than just sending raw Python dictionaries to the database. You still get powerful features from PyMongo and Motor but wrapped in a more Pythonic, validated model layer.
- Links and Tools:
- ODM vs. “Raw Dictionaries”
Relying on raw dictionaries exchanged with MongoDB can lead to chaos—less type safety and little structure. An ODM like Beanie automatically enforces consistency and validates data, preventing subtle bugs and data mismatches. This ensures your application’s data layer is far less fragile.
- Links and Tools:
- PyMongo
- MongoEngine (another ODM mentioned)
- Mongoose (JS) (for comparison in JavaScript)
- Links and Tools:
- Async and Await for High Performance Beanie builds directly on MongoDB’s official async driver, Motor, allowing truly non-blocking database operations in frameworks like FastAPI and async Flask. Async can significantly improve scalability, especially for I/O-bound tasks.
- Field Defaults and Event-Based Actions
Beanie allows you to set default values through Pydantic’s
default_factory, handy for timestamps and other fields. Beyond that, you can automate more complex logic (like updatingupdated_ator validating data) with Beanie’s event-based actions, which run before or after certain actions (e.g., insert, replace).- Links and Tools:
- Atomic Updates and Partial Saves
Rather than updating entire documents, Beanie supports MongoDB’s in-place operations (
$set,$inc,$addToSet, etc.). Additionally, “save changes” can track what was modified in memory and apply only those changes to the database. This approach is both more efficient and safer for concurrency.- Links and Tools:
- Relationships and Prefetching
Although MongoDB is document-oriented, Beanie 1.17+ has introduced a way to set up “links” that represent references (one-to-one or one-to-many) between documents. You can choose to fetch all related data in one shot with prefetch, avoiding the N+1 query problem. This is done under the hood with MongoDB’s aggregation “lookup” pipeline.
- Links and Tools:
- Indexing for Performance
MongoDB indexing is essential for speed, and Beanie allows you to declare indexes directly in your model definitions. You can specify ascending, descending, text, sparse, or unique constraints to match your application’s needs. Proper indexing can reduce query times dramatically.
- Links and Tools:
- Aggregation and Custom Output Models
Beanie supports MongoDB’s flexible Aggregation Framework. You can pass a pipeline or even specify an “output” Pydantic model for the aggregated result. This allows advanced data transformations (like grouping, summing, or averaging) directly in the database.
- Links and Tools:
- Caching Mechanisms
A newly added feature in Beanie is a caching layer that can store query results in memory, reducing redundant database hits. You can set expiration times on cached data, making it well-suited to data that rarely changes or to repeated queries within a short window.
- Tools:
- Local Python dictionary caching (built-in)
- Redis or other backends (planned for the future)
- Tools:
- Revisions and Optimistic Concurrency To handle concurrent writes gracefully, Beanie can track document revisions. If a document in memory is out of date when you try to save it, you’ll get an error rather than silently overwriting changes. This is known as optimistic concurrency control and helps avoid data conflicts.
- Concepts:
- Revision tokens stored with each document
- Conflict error if revision doesn’t match
- Beyond Pydantic: Future Plans While Pydantic is powerful, it can be heavy for certain large or performance-sensitive scenarios. Roman hinted at possible support for native Python data classes in the future, cutting down on overhead while preserving much of Beanie’s simplicity.
- PyCharm, YARL, and Other Tools Roman shared that he uses PyCharm (thanks to a JetBrains license for open source) and that he often relies on the YARL library for easy URL building (like a Pathlib for URLs). Many Python devs also toggle between editors like VS Code for quick scripts.
Interesting Quotes and Stories
- “If you're using PyMongo…you're doing it wrong. Basing your app on a foundation of exchanging raw dictionaries is a castle built on sand.”
- “I started with Django, so I wasn't a Python developer as much as a Django developer—later I learned Python too.”
- “We didn’t plan on relationships, but after seeing a demand, we built them—so much of Beanie’s evolution is driven by user requests.”
Key Definitions and Terms
- ODM (Object Document Mapper): A library that maps database documents (MongoDB) to Python objects, enforcing schema and providing query methods.
- Pydantic: A Python library for data validation using type hints, turning them into powerful conversion and validation rules.
- Motor: An official async Python driver for MongoDB, letting you use
asyncandawaitfor truly non-blocking database calls. - N+1 Query Problem: Common inefficiency where one parent record leads to many individual queries for child data, hurting performance.
- Event-Based Actions: Hooks in Beanie that run code before or after insert, update, or validation events.
- Optimistic Concurrency (Revisions): A way to avoid overwriting changes by having a version or revision on each record to detect out-of-date saves.
Learning Resources
Looking to dive deeper into MongoDB, Python, and async development? Check out these courses:
- Python for Absolute Beginners: A fun, foundational course if you’re just getting started with Python.
- MongoDB with Async Python: This course focuses on building apps with Beanie, Pydantic, FastAPI, and async—a perfect complement to this conversation.
Overall Takeaway
Beanie exemplifies how far modern Python has come for data-driven applications, blending async execution, Pydantic validation, and MongoDB’s non-relational freedom. By orchestrating advanced features like atomic updates, relationships, caching, and concurrency handling, Beanie takes you beyond raw dictionary chaos into a structured, efficient data model. Roman’s story underscores the power of community-driven, iterative open source development, and his experience proves that tight feedback loops in production lead to libraries that are both robust and developer-friendly.
Links from the show
Beanie ODM: github.com
Tutorial: roman-right.github.io
Beanie Relations, Cache, Actions and more!🎉🚀: dev.to/romanright
Unsync: asherman.io
ResponseModel: fastapi.tiangolo.com
Weather Talk Python API docs: weather.talkpython.fm
JetBrains fleet: jetbrains.com
yarl: github.com
Joke: twitter.com/stoltzmaniac
Loading Document Objects to Beanie Dynamically: dev.pythonbynight.com
Michael's YouTube videos
Parsing data with Pydantic: youtube.com
Counting the number of times items appear: youtube.com
Do you even need loops in Python?: youtube.com
Stream Deck + PyCharm - Enhancing Python Developer Productivity: youtube.com
Watch this episode on YouTube: youtube.com
Episode #349 deep-dive: talkpython.fm/349
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 This podcast episode that you're listening to right now was delivered to you in part by MongoDB and Python, powering our web apps and production processes.
00:09 But if you're using PyMongo, the native driver from MongoDB, to talk to the server, then you might be doing it wrong.
00:17 Basing your app on a foundation of exchanging raw dictionaries is a castle built on sand.
00:23 And by the way, see the joke at the end of the show about that.
00:26 You should be using an ODM, an object document mapper.
00:30 This time we're talking about Beanie, which is one of the exciting new MongoDB ODMs, which is based on Pydantic and is async native.
00:38 Join me as I discuss this project with its creator, Roman Wright.
00:41 This is Talk Python To Me, episode 349, recorded November 18th, 2021.
00:47 Welcome to Talk Python To Me, a weekly podcast on Python.
01:04 This is your host, Michael Kennedy.
01:05 Follow me on Twitter where I'm @mkennedy and keep up with the show and listen to past episodes at talkpython.fm.
01:12 And follow the show on Twitter via at Talk Python.
01:16 This episode is brought to you by Sentry and us over at Talk Python Training.
01:20 Please check out what we're both offering during our segments.
01:23 It really helps support the show.
01:25 Hey folks, it's great to have you listening as always.
01:28 A quick bit of news before we talk with Roman.
01:30 I've been looking for a way to explore ideas teaching Python, get some feedback, and then bring what I've learned back to the course content.
01:36 So I'm kicking off a new initiative over on YouTube.
01:39 It's called Python Shorts.
01:41 And the goal is to teach you one thing, both interesting and useful, as well as actionable, about Python.
01:47 I have three videos out so far.
01:49 The first, parsing data with Pydantic.
01:52 The second, counting the number of times an item appears in a list with counter.
01:56 And third, do you even need loops in Python?
01:58 I also published a fourth video about using the Stream Deck, that little button device that a lot of gamers use, to make Python developers more productive.
02:08 Check out all four of those videos on my personal YouTube channel, not the Talk Python one.
02:12 Links in the show notes.
02:13 Now, let's talk Beanie.
02:15 Roman, welcome to Talk Python To Me.
02:19 Hey, I'm happy to be here.
02:20 Yeah, it's great to have you here.
02:22 Oh, we get to talk about one of my favorite topics, MongoDB.
02:25 I'm so excited.
02:26 Yeah, my favorite topic, obviously too.
02:29 Oh, yeah, you definitely put a lot of time into it.
02:32 We're going to talk about your ODM.
02:34 People often hear about ORMs, Object Relational Mappers, but traditionally, MongoDB and other document databases and NoSQL databases haven't modeled things through relationships.
02:45 It's more through documents.
02:46 So the D instead of R, ODM.
02:49 Beanie, which is going to be super fun.
02:52 It brings together so many cool topics and even relationships.
02:56 So maybe if you really wanted, I guess you could put the R back in there as of recently.
03:00 Anyway, super fun topic on deck for us.
03:04 Before we get to that, let's just start with your story.
03:06 How did you get into programming in Python?
03:07 I started when I was a student, more than 10 years ago now.
03:12 But I started not with Python.
03:14 I started, it was 2008, I think, 2007 probably.
03:18 I started with Flash, and nobody knew that Flash will die soon.
03:22 Flash was such a big thing when it was new.
03:25 I remember people were just completely getting amazing consulting jobs and building websites with Flash.
03:32 I'm like, what is this?
03:33 I'm not sure I want to learn this, but do I have to learn this?
03:35 I hope not.
03:36 But yeah, anyway, yeah.
03:37 It did kind of get killed by HTML5.
03:39 And, you know, I think, honestly, maybe it got killed by Steve Jobs, really.
03:43 At least earlier than it would have been.
03:45 Definitely.
03:45 Yeah.
03:47 So, but that time I didn't know that.
03:49 And ActionScript, two and three.
03:51 Right on.
03:53 And then I decided to move to backend problem.
03:56 So Flash is a client technology, if anybody don't know.
03:59 There's no.
04:00 And then I moved to, I just wanted to build websites and wanted to move to backend.
04:06 And I chose Django.
04:09 Mm-hmm.
04:09 Not Python, but Django.
04:10 Because Django was super fancy at that time.
04:13 And now also, but that time, yes.
04:14 And I was a Django developer, not Python developer, but Django developer for a year, probably.
04:18 Because I knew a few tricks and tips about Django tools, models, views, and et cetera, templating.
04:25 And then somehow I learned Python also.
04:28 And now I'm always a good Python developer.
04:30 Yeah, fantastic.
04:32 I think I just realized as you were speaking, we might have to tell people what Flash is.
04:38 I feel like it's just one of these, you know, iconic things out of the tech industry.
04:42 But it might be like talking about AltaVista.
04:45 At some point, the kids, they won't know what Flash is.
04:48 They won't know there was this battle about getting this thing on people's computer.
04:52 And it was always like viruses are being found in them, but it could always do this magical stuff.
04:57 How interesting.
04:57 Yeah, yeah.
04:58 How old we are.
04:59 Exactly.
05:01 The other thing that is interesting is you said you chose Django.
05:05 You didn't choose Python.
05:08 Yeah.
05:09 Yeah, I think that that's, you know, now people are often choosing Python because of the data science and computational story.
05:16 But before 2012, there was not this massive influx of data science people.
05:21 And I think that the big influx was people becoming Django developers and like, well, I guess I'll learn Python.
05:28 Kind of like people becoming Ruby on Rails developers.
05:30 Like, I don't know Ruby, but I want to do Ruby on Rails.
05:33 So I guess I got to learn Ruby.
05:34 Django is kind of our version of that, right?
05:36 Right.
05:36 Yeah.
05:37 Then I think Flask appeared after a few years and everyone started to do microservices with Flask.
05:44 And after that, the game started.
05:48 That's right.
05:49 That's right.
05:50 Oh, my goodness.
05:50 Out in the live stream, we're getting some high fives from Pradvan on Django.
05:55 And Jeff says, he says Django the right way.
05:59 Fantastic.
05:59 So awesome.
06:01 Yeah.
06:01 And I think Django has been massively important for Python.
06:05 And very, very cool.
06:07 Yeah.
06:07 How about now?
06:07 What are you doing day to day?
06:08 So I'm principal Python developer now.
06:11 And this is interesting.
06:13 Actually, I changed my job three months ago.
06:17 And I didn't look for a new job.
06:19 But one day, Moot, my current manager, just texted me into Twitter that, hey, I saw your library, Bini.
06:28 And it's interesting.
06:30 And we need something like this in our project.
06:32 And probably you would like to participate in and integrate Bini into our project and develop Bini at the work time.
06:39 Oh, how cool.
06:39 And I decided, yeah.
06:41 Yeah.
06:42 That's amazing.
06:43 I mean, on one hand, it would just be cool to have a fun job doing cool MongoDB stuff, right?
06:49 On the other, it's like, oh, my gosh, I get to use my library and build up my library in a real production environment.
06:56 Like, that's awesome, right?
06:57 Yeah, yeah.
06:58 And so I decided the same day, I think.
07:01 Let me think about it.
07:04 Yes, okay.
07:04 We'll figure out how long it takes me to quit my current job.
07:08 Awesome.
07:09 Well, congratulations.
07:10 That's really cool.
07:10 Yeah, thank you.
07:12 That only means good things for Bini, right?
07:14 It only means more time and energy on it, I would suspect.
07:16 Yeah, yeah.
07:17 All this, the current release, the huge release is possible only because I can work a little bit time on work time, not only on weekend.
07:26 Yeah, absolutely.
07:27 It's easy to justify, like, the library needs this feature to work right for us.
07:32 So let me add that feature to the library as just part of the sprint or whatever, right?
07:36 And also probably it's even more important that when I can work on production with Bini, I can also see what does it mean.
07:44 Yeah.
07:44 Which feature and which improvement.
07:47 It's so true because there's just these little edge cases.
07:50 They don't show up under even a complicated little example you build for yourself.
07:56 You know, you've got to put it into production and live with it.
08:00 You know, some of that stuff might be migrations, right?
08:02 Like, I never need these migrations.
08:03 Oh, wait.
08:04 We have the zero downtime promise.
08:07 We kind of need migrations now or something, right?
08:09 Right.
08:09 Totally correct.
08:11 Yeah, yeah.
08:12 Cool.
08:12 Well, that's great to hear.
08:13 Congratulations.
08:14 Now, I wanted to start our chat off not talking about Bini precisely, but like a little lower in the tech stack here.
08:22 Let's just talk about MongoDB for a little bit.
08:27 I'm a huge fan of MongoDB, as I'm sure many of the listeners know out there.
08:32 I've been running Talk Python, Talk Python training those things on top of MongoDB for quite some time.
08:39 In the very, very early days, some of that was SQLAlchemy stuff, but then I switched over to Mongo and whatnot.
08:46 So I'm a huge fan of it.
08:47 I definitely think there's a lot of value.
08:49 And there's a lot of these architectures where people talk about, oh, we have a Redis middle tier cache because we got to have our website fast.
08:57 You know what?
08:59 We get 10 millisecond response time and there's no cache.
09:02 It's just talking to the database because, you know, everything is structured the right way.
09:06 I think it's, anyway, I'm kind of going on too much.
09:09 But what I wanted to start with was I want to hear your thoughts on just sort of why build on top of Mongo.
09:15 You know, so many people in the Python space build on Postgres, which is fine.
09:20 It's a good database and all is just a completely different modeling story.
09:24 So why are you interested in Mongo?
09:26 First of all, Mongo is super flexible database by design.
09:30 And I really like to do prototypes.
09:35 So when I just come up with new idea of new project, home project and et cetera, it's quite simple to work with MongoDB instead of Postgres when you have to change painfully schema of your data.
09:49 But with Mongo, you can just do what you want to.
09:53 That's been my experience as well that I remember almost every release of my code would involve some migration on the SQLAlchemy version.
10:01 I think I've done one, what you would consider a migration in like five years on MongoDB.
10:06 Whereas everything else is like, I'm going to add this equivalent of a table or I'm going to add a field to this document.
10:12 But it just goes in and it just, it adapts.
10:16 It's fantastic.
10:17 It's like plastic instead of something brittle.
10:20 Even in the indexes.
10:21 Yeah.
10:21 That's why it's great for me, I think.
10:23 Yeah, it's really easy for prototyping, right?
10:24 You just, instead of trying to keep the database in sync or whatever, you just work on your models and magic happens.
10:31 Yeah.
10:31 Yeah, you're right.
10:32 And then for sure for production, you have to understand your profile and your needs.
10:40 And then you can move to Postgres or you can move to something like timestamp database, ClickHouse, for example.
10:47 Yeah.
10:47 But in most cases, Mongo is enough.
10:49 And for some cases, Mongo is the best choice because of flexibility and because of many cool stuff like indexes and such.
10:57 Yeah, absolutely.
10:58 I think indexes.
11:00 I don't know.
11:01 This is maybe getting ahead of ourselves, but I think indexes are just so underappreciated in databases.
11:06 I mean, I know a lot of people out there make sure their queries have the right indexes and stuff in it.
11:12 But there's also so many websites I visit that take three seconds to load a page.
11:17 I'm like, there's no way there's an index on this query.
11:18 There's just no way.
11:20 I don't know what it's doing, but somebody has just not even thought about it.
11:24 And if it was a weird little, oh, here's like the reporting page.
11:27 Fine.
11:28 But it's like the homepage or something.
11:29 You know what I mean?
11:30 Like, how are they not making this faster even in like a Postgres story, right?
11:36 Like, I feel like there's one thing to have a database that does something.
11:41 There's another to like tune it to do the right thing, regardless of whether it's relational or NoSQL.
11:46 Yeah.
11:47 Totally correct.
11:47 Yeah.
11:48 You have a lot of experience with databases.
11:50 I mean, you must have that feeling as well.
11:52 You go to some website, you're like, what is it doing?
11:54 Why is this thing spinning?
11:55 What could it possibly be doing here?
11:57 Yeah, probably somebody's going, you know, to get data.
12:00 Exactly.
12:02 I mean, you're thinking through the ideas.
12:04 Okay.
12:04 Is it just not half an index?
12:06 Or is it an N plus one problem with some ORM?
12:09 Or where, why am I waiting here?
12:11 What mistake have they made?
12:12 Fantastic.
12:14 All right.
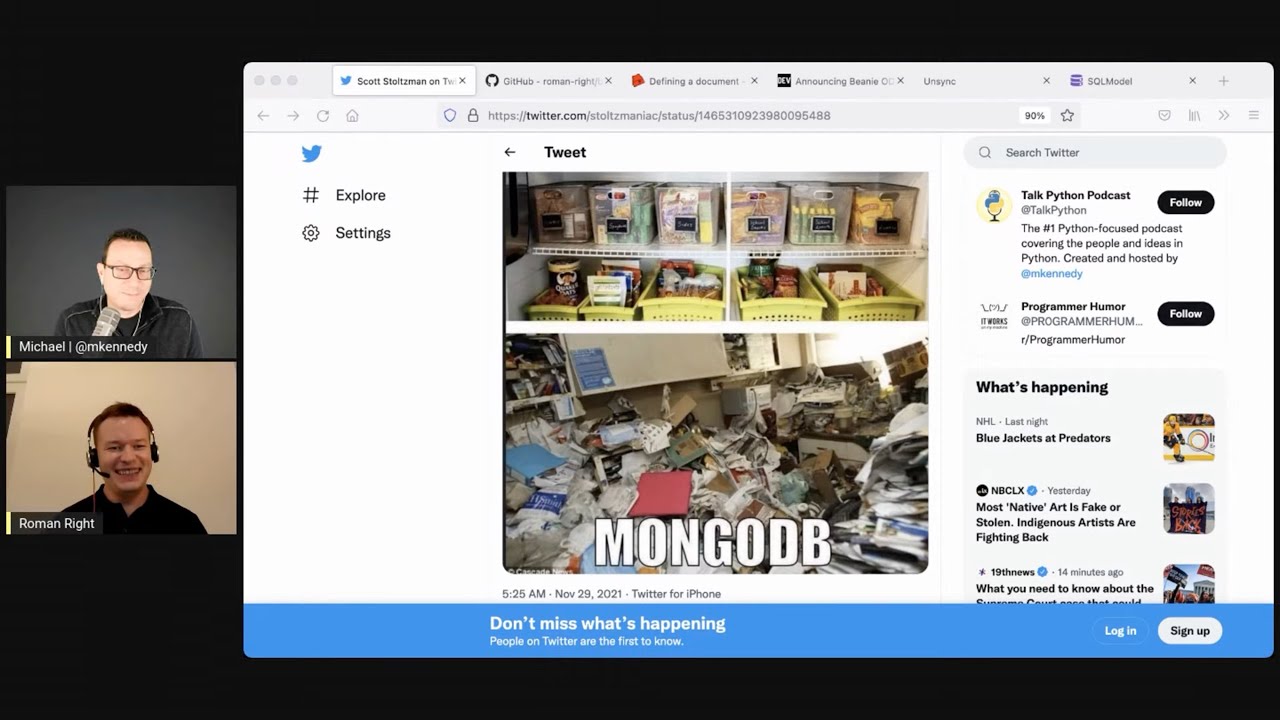
12:16 So the next thing I want to sort of touch on is this tweet from Scott Stoltzman sent this out yesterday.
12:21 I don't think he knew that we were coming up with this conversation, actually.
12:26 So there was this programming humor joke.
12:29 It says, it has like two, I guess one of them is like a kitchen.
12:35 The other is an office, but it doesn't really matter.
12:38 Like the kitchen is super organized and it says MySQL.
12:41 Everything's little buckets and put away nice.
12:44 And then there's a desk area that's just, it looks like a hoarder house or like a, you know, earthquake hit and destroyed this area.
12:53 And it says MongoDB.
12:55 And it's actually true.
12:57 It is.
12:58 It can be true.
13:00 And the reason I bring this up is Scott said, you know, I know a guy who made this course that saved me from this chaos with MongoEngine.
13:07 Because it can happen with, it can happen in about 15 seconds without a strong plan.
13:11 And so out of the box, the way MongoDB, the dev folks there suggest that you, or at least provide, let's put it that way.
13:22 The tools they provide for you to work with MongoDB are dictionaries.
13:27 Like you can give us dictionaries and put them somewhere and then you can get dictionaries back.
13:32 And Python dictionaries are just whatever, right?
13:35 There's zero structure.
13:37 There's zero discoverability.
13:38 There's zero type safety, right?
13:40 Sometimes it's a string that looks like a number.
13:43 Other times it's a number.
13:44 Good luck.
13:44 Those don't match in a query.
13:46 You know, like it's horrible.
13:47 And so for me, I feel like what you need to do when you're working with databases that have less structure in the thing itself, like this is MySQL, say Postgres.
14:00 Like Postgres says the table looks like this.
14:02 This column is that size of a string.
14:05 This is a number and that's it.
14:07 You know, like the structure is in the database where in these document databases, the structure is in the code.
14:15 And so you should have some kind of code that helps you not end up in a situation like this, right?
14:21 Yeah.
14:21 Honestly, Postgres also came up with JSONB fields now.
14:25 Yeah.
14:26 So they're kind of, maybe they fall into that bottom bucket like in a small little area.
14:30 Yeah.
14:30 This portion of Talk Python To Me is brought to you by Sentry.
14:36 How would you like to remove a little stress from your life?
14:38 Do you worry that users may be encountering errors, slowdowns, or crashes with your app right now?
14:44 Would you even know it until they sent you that support email?
14:47 How much better would it be to have the error or performance details immediately sent to you,
14:52 including the call stack and values of local variables and the active user recorded in the report?
14:58 With Sentry, this is not only possible, it's simple.
15:01 In fact, we use Sentry on all the Talk Python web properties.
15:05 We've actually fixed a bug triggered by a user and had the upgrade ready to roll out as we got the support email.
15:11 That was a great email to write back.
15:13 Hey, we already saw your error and have already rolled out the fix.
15:17 Imagine their surprise.
15:18 Surprise and delight your users.
15:20 Create your Sentry account at talkpython.fm/sentry.
15:25 It's also one of the things.
15:49 Why schemas about structure?
15:53 So the thing I think saves you from, you know, Scott mentioned MongoVidgin, which is pretty good.
15:59 But I think the thing that saves you from this are these ODMs.
16:01 Like you have a lot more structure in your classes and your Python layer, right?
16:07 Yeah, yeah, correct.
16:08 And also, so, yeah.
16:10 Beanie is ODM based on Pydantic.
16:13 Pydantic is Python library, the data and stuff.
16:17 Yeah, let me read the little introduction bit here.
16:20 Because I think there's so much in this first sentence.
16:23 So Beanie is an asynchronous Python object document mapper, ODM, for MongoDB.
16:30 So ODM we talked about, Mongo we talked about, asynchronous, and also I didn't finish the sentence,
16:37 based on motor, which comes from MongoDB, and Pydantic.
16:40 So it's also asynchronous, right?
16:43 Which is pretty awesome, as in async and await.
16:46 And so often, the models that we build for the databases are their own special thing.
16:55 And then you've got to build maybe an API, and you might use Pydantic or something like that.
16:59 But Pydantic's been really coming on strong as a super cool way to build object trees and object graphs and stuff.
17:07 And so Pydantic is a perfect thing to say, well, let's just use that.
17:12 Everyone already knows how to use that.
17:13 And things like APIs can already exchange those on the wire.
17:17 Yeah, yeah.
17:19 And that's why I chose this.
17:23 It's just such a neat combination of bringing the async and await stuff together, along with Pydantic,
17:30 and saying, let's see if we can use those ideas for the basically for the ODM.
17:35 So there's other ones.
17:36 You know, Scott mentioned MongoEngine.
17:38 That's actually what I'm using right now for my MongoDB stuff in Python.
17:41 It's MongoEngine's pretty good.
17:43 I feel like it's kind of wherever it's going to be.
17:48 There's not a ton of excitement in terms of like new features and pushing stuff forward.
17:52 For example, there's, to my knowledge, there's no async and await stuff happening in there.
17:58 There's, I think it's synchronous.
18:01 Possibly there's something that's happened that's changed up.
18:03 But the last time I looked, it was synchronous still.
18:05 Weeks ago, it was synchronous, yeah.
18:07 Yeah, okay.
18:07 That's much more recent than I've looked.
18:09 And what are some of the other ones?
18:11 I'm trying to think of some of the other MongoDB ODMs out there.
18:15 I know in another language is probably like Mongoose in JavaScript.
18:20 Yeah.
18:20 Active record stuff for Ruby and things like that.
18:24 Yeah, yeah.
18:24 So a lot of these systems were based on the Django ORM model.
18:29 So for example, like MongoEngine is basically Django ORM, but adapted for documents in Mongo, right?
18:36 Like the terminology and everything is quite similar.
18:39 Being based on Pydantic, yours is a little bit different, right?
18:43 I feel like there's a lot of interesting things you've, choices you've made.
18:47 One, to be based on Pydantic and how that works.
18:51 But two, we'll get into the API and stuff.
18:54 But when you look at the API, I feel like you've chosen to be very near MongoDB's native query syntax or query language.
19:00 So for example, instead of doing a select, you would do like a find or find one or the updates.
19:08 And like a set operator is one of the things you can do, like a set a value on there.
19:13 Was that conscious?
19:14 Did it say, like, I'm going to try to be really close to MongoDB or what was the thinking there?
19:18 When I started to work on Beanie, it was not Beanie.
19:22 It was just a side project because, so yeah.
19:26 On the very beginning, I started to play with FastAPI.
19:29 It was a very modern web framework at that time.
19:33 Now it's still modern and great web framework.
19:36 But at that time, it was quite new around a few years ago.
19:39 And this is a synchronous also and uses Pydantic under the hood.
19:43 And there were no ODM, no sync ODM for Python and MongoDB.
19:49 I had the same experience.
19:51 Like, I wanted to use MongoDB with some FastAPI stuff.
19:54 I'm like, there's not a great library that I can pick here.
19:57 So I guess I'll just use SQLAlchemy or something, right?
20:00 And what I did, I just started with Pydantic.
20:05 I've got Motor.
20:07 It is PyMongo.
20:10 So yeah, this is an engine over PyMongo.
20:13 And it is a synchronous engine.
20:16 Yeah, yeah.
20:16 Let's talk about Motor a little bit because I suspect that most people who work with MongoDB work with PyMongo.
20:24 Right?
20:25 When I opened the conversation, I said, the tools they give you are just, here's a dictionary to put in.
20:31 And then I get dictionaries back out.
20:32 I was exactly thinking of the PyMongo library.
20:36 Right?
20:37 And so what's this Motor thing?
20:39 This is also from MongoDB.
20:41 This is also from MongoDB, right?
20:43 And it also reflects each method and function from PyMongo.
20:48 But it's converted, let's say, into a synchronous method and function.
20:54 So it uses the same, mostly the same syntax as MongoDB itself and as PyMongo also.
21:01 Okay.
21:02 Yeah.
21:02 So it's a lot like PyMongo.
21:03 It says Motor supports nearly every method PyMongo does, but Motor methods that do network I.O.
21:12 are coroutines.
21:13 So async and await type of things, right?
21:16 Yeah.
21:17 Yeah.
21:17 Yeah.
21:18 Yeah.
21:18 And what I did, I just combined together Pydantic and Motor without any query builder stuff and other ODM fancy stuff.
21:29 Just querying, using dictionaries, the same dictionaries as Motor does.
21:33 And PyMongo for models and nothing more.
21:37 Small library.
21:38 It wasn't Bini at that time.
21:40 It was an internal project just to play with FastAPI.
21:43 And then after a few months of working, I decided probably I can make it open source.
21:50 I came up with the name Bini.
21:53 And mostly that's why I'm following MongoDB naming, not select, not join, et cetera.
22:00 Just find the many, find one, update, et cetera.
22:04 Because I'm using, I started to use directly Motor functions inside of Pydantic stuff.
22:11 And only after that, I just started to update Bini stuff with more fancy stuff.
22:18 Yeah.
22:19 So it was a pretty close match to like, how do I take Motor and just make it send and receive Pydantic instead of send and receiving straight dictionaries, right?
22:28 Yeah.
22:28 So the first project was just a parser from Motor to Pydantic and back.
22:33 Cool.
22:34 Well, I think it's really neat.
22:35 And I, you know, however you got there, I think it's really nice that you have the API that matches that.
22:40 Because then I can go to the MongoDB documentation and, or I can find some other example that somebody has on, well, here's how you do it with PyMongo.
22:50 And you're like, well, that looks really close to the same thing over here.
22:54 So we can talk about that.
22:56 Now, I want to dig into some of the other features and stuff there.
23:01 For example, data and schema migrations and support and whatnot.
23:04 That's pretty cool.
23:05 Yeah.
23:05 But let's talk about modeling data here.
23:08 That's, you know, the first letter in ODM, the object bit.
23:14 So what does it look like?
23:16 I know, well, maybe not everyone listening knows what it looks like to model something with Pydantic.
23:21 So maybe we could give us a Pydantic example, and then we could talk about how to turn that into something that can be stored in MongoDB.
23:27 Yeah.
23:28 Yeah.
23:28 Pydantic is base model.
23:29 The main class of Pydantic is base model.
23:32 And you inherit everything from base model.
23:35 And it looks like data classes of Python.
23:37 But it also supports validation and parsing, which data classes does.
23:43 Yeah.
23:44 And the conversions and stuff, it's really cool.
23:46 That's one of the things I think Pydantic is so good about.
23:49 Yeah.
23:49 If you look at their example, the way you define these classes is you have a class and you just as a class level, not instance level, you'd say name, colon, or variable, colon, type, variable, colon, type.
24:02 So in this example, you've got a category, say name, colon, str, description, colon, str.
24:08 And this just means this thing has two fields.
24:11 They're both strings.
24:12 But the Pydantic example on their website has got some kind of model where it's got multiple fields.
24:19 And one of them is a list of things that are supposed to be numbers.
24:22 And if you pass it a data and that list happens to have a list of strings that can be parsed to numbers, it'll just convert it straight to numbers as part of loading it.
24:33 It's really, really nice, right?
24:34 Yeah.
24:34 Yeah.
24:35 This is a great feature.
24:36 Yeah.
24:36 This exchange across, especially across either files or API boundaries, right?
24:40 Somebody writes some code and they send you some data.
24:45 Well, if they didn't really use the native data type, but it could be turned into it, then, you know, that's really nice.
24:51 And you also can add your own parser, like your own validation step.
24:56 And then it will convert this here rule, like from string to number, to date.
25:02 So, yeah.
25:04 And the Bini uses the same schema.
25:07 The same.
25:07 So, document is a main class of Bini.
25:09 And it's inherited from Pydantic base model and inherits all the methods, all the aspects of base model of Pydantic.
25:19 So, it can use the same validation stuff, the same parsing stuff, and et cetera.
25:24 Right.
25:24 So, whatever people know and think about Pydantic, that's what the modeling looks like here.
25:29 I guess the one difference is when you talk about, when you model the top-level documents that are going to be stored and queried in MongoDB, you don't derive from base model, right?
25:43 Drive from something else?
25:44 Yeah.
25:44 From document.
25:45 Right.
25:46 And document, it comes from Bini.
25:48 But that document itself is derived from base model, ultimately, right?
25:53 So, even though you got to do this little more specialized class, it's still a Pydantic model in its behavior, right?
25:59 Yeah.
25:59 Yeah, correct.
25:59 That's why you can use it as a response model, for example, in FastAPI, if you're familiar with.
26:06 Yes.
26:06 Because it uses identity base models and submodels of base models.
26:12 Yeah, if people haven't seen that, let me, here's an example.
26:15 One of the things you can do with FastAPI that's super, super neat is you can go and say, as part of returning the values out of the API, one of the things you can do in the decorator is you can just say,
26:28 the response model is some Pydantic class.
26:30 And if you just add that one line and that class happens to be a Pydantic model, you get all sorts of live documentation and API definition stuff.
26:41 And there's even code that will consume that.
26:43 So, I built this little weather thing in FastAPI for one of my classes over at weather.talkpython.fm.
26:51 And you just go to slash docs.
26:52 It pulls up, oh, here's all the APIs you can call.
26:57 And here's like the return value with, you know, exactly what the schema is.
27:01 And all of that's just from that one line of code.
27:04 So, what you're saying is you could do that with these database models.
27:07 You could just say, I'm going to return this directly from my API back to you.
27:11 And if you just say response model equals your data entity model, you get all this for free, right?
27:17 Yeah, it's also invalidated based on this model.
27:20 If you're, for example, using some external source of data and they changed schema and you received it and responded back.
27:28 And if the format is not correct, it just will erase an error and you can gracefully handle this.
27:34 Yeah.
27:35 Nice.
27:35 Yeah, the error that it returns is also meaningful.
27:38 Like, the third entry in this list cannot be parsed to an integer rather than, you know, 400 invalid data.
27:45 Good luck.
27:46 Okay, so we've modeled these objects in here.
27:51 And I guess one more thing to throw in while we're talking about modeling.
27:54 In your example, right at the bottom of the GitHub page, you have a category which has the name and description.
27:59 And you have a product that has its own name and description.
28:02 And then a price.
28:04 And the product has a category.
28:07 And here you just say colon category, right?
28:10 And that would make, I guess, would make this, in this case, an embedded document inside of the product document, right?
28:18 Yeah, totally correct.
28:19 It will just create embedded documents.
28:21 Yeah, so the way that you model.
28:23 This is why Pydantic's a really good match because Pydantic allows you to compose these Pydantic models in this, like, hierarchy.
28:29 You can have, like, lists of other Pydantic models within a Pydantic model, which is exactly the same modeling you get with document databases like Mongo, right?
28:37 Yeah, yeah.
28:38 So you don't have to do anything.
28:39 It's like, it just, it keeps modeling the things I wanted to model.
28:42 Cool.
28:42 So, in other database systems, like SQLAlchemy or something, you would be able to say, this field is nullable.
28:52 Or not, or it's required, or something like that.
28:56 So how do you say that in this model?
28:59 If it's nullable, yeah, I can just use Python type in optional.
29:04 It's not a class, but optional, optional.
29:08 Yeah.
29:09 Mark it as optional.
29:10 Like optional bracket str versus just str, right?
29:14 Yeah.
29:14 And I guess for a default value, you just set it equal to its default value, right?
29:18 You're right.
29:19 But if it's optional, so it's explicitly marked here, but Pydantic allows you to use optional without default value, and default would be none in that case.
29:28 Because Pydantic is...
29:30 I'm thinking, like, false or none or something like that.
29:34 In this case, you probably wouldn't make it optional.
29:35 You would just give it a default value, right?
29:37 Yeah.
29:37 Correct.
29:38 Now, one of the things that I can do in, say, MongoEngine, is I can say the default is a function.
29:44 Because maybe this is incredibly common in my world, is I want to know when something was created.
29:51 You know, when did this user create an account?
29:53 When was this purchase made?
29:54 When did this person watch this video or whatever?
29:57 And so almost all of my models have some kind of created date type of thing.
30:01 And the default value is datetime.datetime.now without parentheses.
30:07 You know, like, I want you to call the now function when you do an insert.
30:11 How would I model that in Beanie?
30:13 Again, you can use Pydantic stuff here.
30:15 So I really like Pydantic.
30:17 They did half a fork.
30:19 You can use field class, equal field.
30:22 And inside of that, you can use default factory parameter, where you can just provide function you want to.
30:29 Okay.
30:29 Oh, that's right.
30:31 So you can, instead of setting it, like, you could say it's a string, but its value is, what is it?
30:36 You say field factory or something?
30:38 You said it to be one of these things that Pydantic knows about.
30:41 Didn't get you.
30:42 Sorry.
30:42 Is that thing that I'm setting it to equal to?
30:44 Does that come out of Pydantic?
30:46 Like, that's not a Beanie thing?
30:47 This is Pydantic stuff.
30:48 Yeah.
30:49 Default factory stuff.
30:51 But there is interesting Beanie feature about this.
30:55 I can show you in another code example here.
30:57 For example, if you want to use not create at, field but updated at.
31:03 So, and each time when you update, you want to update time.
31:07 And for that case, default factory will not work.
31:10 Because default factory...
31:11 It's already got a value.
31:12 Yeah.
31:12 It's only on create.
31:13 Yeah.
31:13 Yeah.
31:14 And Beanie allows you to use event-based actions for this.
31:19 And you can just create a method of the class.
31:22 And there, mark it like run before event.
31:27 Before event decorator.
31:28 Yeah.
31:28 Before event.
31:30 And inside of this, you can just write your logic.
31:33 Self updated at field equals current time.
31:37 And it will work.
31:38 For events, you will choose like insert, replace, and anything else.
31:43 Yeah.
31:43 This is one of the new features.
31:44 We're going to talk about some of the new things.
31:46 But one of them are these event actions.
31:49 So, you can say before the insert event or before the save event happens or after the
31:56 thing's been replaced or any of those types of things, you can sort of put a decorator and
32:01 say run this function when that happens on this type or in this collection effectively.
32:06 Right?
32:06 Yeah.
32:06 Very, very cool.
32:07 All right.
32:07 We're going to dive back into that because that's good.
32:10 And so, that would be actually a pretty good way, wouldn't it?
32:12 Just do an event on insert.
32:14 And when on insert happens, set my created date to be datetime.now.
32:19 Yeah.
32:19 Okay.
32:19 Good.
32:20 Good.
32:20 And then, I guess, the other part that's interesting now is doing queries and inserts on this.
32:25 So, you would create your objects just exactly the same as you would Pydantic, right?
32:30 Just class name, key value, key value, key value.
32:33 Like that?
32:34 Yeah.
32:35 Or even parse object like category dot parse object and dictionary with values.
32:40 And yeah.
32:41 If you want to parse more than one object.
32:43 Right.
32:44 If it's coming.
32:44 Okay.
32:44 Or if it's coming out of an API or something like that, right?
32:47 And then you would say, here's where it gets interesting.
32:49 You say await object dot insert or await class dot find one, right?
32:56 Or await set some value there.
32:58 Yeah.
32:59 Because this is, I think, await library.
33:02 So, that's why you have to use await here based on the asynchronous nature of the library.
33:07 Sure.
33:07 And that's the whole point, right?
33:09 Is that it's built around that.
33:11 I think, I mean, there's ways in which you could use it in asynchronous situations, right?
33:15 You could always create your own event loop and just run the function and just block right that way.
33:20 Or use something like unsync, which maybe we'll touch on a little bit later.
33:23 But yeah.
33:25 So, but if you're doing something like Flask or FastAPI, where the functions themselves,
33:32 the thing being called by the framework is already handling it, it's basically no work, right?
33:38 You just make an async method and then you just await things and you get this,
33:42 you unlock this scalability right there.
33:44 Yeah.
33:45 Yeah.
33:45 I think modern Python world is pretty everywhere asynchronous already.
33:50 I don't know if I think framework development now, like most of them are asynchronous.
33:56 Yeah, exactly.
33:58 I think with Flask, there's limited support for async.
34:02 And then if you want full async, you have to use court for the moment, but maybe stuff's happening.
34:07 I know Django is working on an async story as well.
34:11 Yeah.
34:11 I think the big holdup for like full on async and Django has actually been the Django ORM.
34:15 So this would fix that.
34:17 Although, does it make any sense to use Beanie or another ODM or something like that out with Django?
34:24 Or I mean, it's so tied into its ORM itself, right?
34:28 I think for Django, it's a little bit tricky.
34:31 Yeah.
34:31 Probably things changed, but Django works with relative databases, yeah, with SQL databases,
34:38 and also the Django model stuff.
34:41 Yeah.
34:41 It's possible.
34:45 Definitely it's possible.
34:46 It's Python.
34:47 Everything is possible.
34:48 Yeah.
34:49 It's just, you know, if you're fighting against the system, then you maybe should just choose a different framework rather than try to fight the way that it works, right?
34:59 Like if you're going to choose something like Django that gives you a lot of opinionated workflow, but a lot of benefit if you stay in that workflow, then just, I'd say, follow that.
35:08 But the other frameworks are pretty wide open, right?
35:11 You could easily use this with Flask.
35:13 You could use this with pretty much anything.
35:16 It's better if it supports async, right?
35:18 There's not a synchronous version, is there?
35:21 Yeah, there is no synchronous version of this, unless it uses a motor insight, as we said.
35:26 I'm thinking about by Mongo support without motor.
35:30 In that case, it would be just synchronous.
35:33 I would think that would be great, honestly.
35:35 I'm very excited that this is async first.
35:38 I think that's really good.
35:40 But let me give you an example.
35:41 So for my website, I would love to be able to make all the view methods be async, right?
35:48 That would give it a little bit more scalability.
35:50 It's pretty quick, like I said, but it would still be way more scalable if it could do more while it's waiting on the server.
35:56 But at the same time, I have all these little scripts that I run.
36:00 And here's how I want to go and just show me all of the podcast episodes who is sponsoring them to make sure that if I had to reorder things, I don't mess up some sponsorship detail.
36:15 Or show me all the people who have signed up for this class this month and whatnot.
36:21 Those little scripts, right?
36:23 It would be nice if I could just say these little things are going to be synchronous because it's the easier programming model.
36:28 I don't have to do that.
36:35 I don't have to do that.
36:36 What do you think of that?
36:37 I do agree totally.
36:38 But I have limited time.
36:39 That's why.
36:42 Yes, of course you do.
36:43 And I guess that pull requests are accepted or contributions are accepted if there's meaningful good work, right?
36:51 Yeah, sure.
36:52 Sure.
36:53 Yeah, cool.
36:53 I'm not suggesting that it's like a super shortcoming, right?
36:56 It's not that hard to create an async method and just call async io.run on it.
37:00 But having this ability to say this situation is really a synchronous one, don't need to go through the hoops to make that happen.
37:09 Even I had this situation in the past, you know, and I had to create a loop inside of synchronous function.
37:16 Yeah, exactly.
37:17 Exactly.
37:18 I think that's worth touching on a little bit because people say that async and await is like a virus or something.
37:26 Like once one part of your code base gets async, like it sort of expands upward so that anything that might touch that function itself has to become async and then its colors have to become async and so on.
37:37 In the most naive, straightforward way, that's totally true.
37:41 But it's not true if you don't want it to be, right?
37:46 Like halfway through that function, that call stack, you could say on this part, I'm going to create an async io event loop and just run it and just block.
37:54 Right?
37:54 And anyone who calls that function doesn't have to know it's async io, right?
37:57 Yeah.
37:58 You can sort of stop that async propagation.
38:01 And that sounds like that's what you're talking about, like creating a loop and running it inside of a synchronous function.
38:05 Yeah.
38:06 But this looks really super ugly.
38:08 Yeah.
38:10 You even don't have any chance to await this.
38:14 You're creating a task.
38:16 Yeah.
38:17 Yeah.
38:18 It is a little bit weird if you haven't seen it.
38:20 I, okay.
38:21 So it's time for my requisites required.
38:24 Shout out to the unsync library, which I think is just so neat in the way that it simplifies async and await in Python.
38:32 We're talking about this just a little bit before I hit record, but it has basically two things that are frustrations that make this kind of stuff.
38:41 We're talking about a little bit harder.
38:42 Like one, wouldn't it be nice if you could just call an async function and it just runs?
38:47 Like I want to write this to the log, but let's do that asynchronously and just go, go right to the log.
38:52 I don't want to see from you again.
38:53 I want to hear from you again.
38:54 Go put it in the log.
38:56 I'm going to keep on working, right?
38:57 You can't do that with Python's async.
38:58 You've got to like put it in a loop and make sure the loop is running.
39:01 So this fire and forget model doesn't work.
39:04 And the other is you can't block.
39:05 You can't call dot result to make it block.
39:09 If it's not done, it's going to throw an exception, right?
39:11 So this unsync thing lets you put an at unsync decorator on an async method.
39:17 And then if you need to stop the async propagation, you just call dot result and it'll block and then give you the answer.
39:23 Builds done.
39:24 And there's all sorts of cool integration with like threads plus asyncio plus multiprocessing.
39:30 It's, I think this fixes a lot of those like little weird edge cases.
39:34 I think I will try this after this podcast and will create a page on documentation.
39:40 So if you need to try it out and see if it's a good idea.
39:43 It might not be a good fit, but I think it is actually.
39:46 I think it would be.
39:47 I will try.
39:47 So if it will not work, I will not.
39:49 So basically the way it works is it creates, when it starts up, it creates a background thread.
39:55 That its only job is to run an asyncio event loop.
39:59 And then when you do stuff, when you call functions on this, instead of running the main thread, it just runs on that background thread.
40:04 And when you block, it just waits for that background thread to finish its work and stuff like that.
40:08 So it's, that's sort of the trick around it, but super big fan of unsync.
40:12 I think it's, it does a lot of good for these situations that we're talking about where you're like, okay, almost all the time.
40:17 And definitely in production, I want it async, but every now and then I want it to just stop.
40:22 Talk Python To Me is partially supported by our training courses.
40:29 We have a new course over at Talk Python.
40:32 HTMX plus Flask.
40:33 Modern Python web apps hold the JavaScript.
40:36 HTMX is one of the hottest properties in web development today.
40:40 And for good reason.
40:41 You might even remember all the stuff we talked about with Carson Gross back on episode 321.
40:46 HTMX, along with the libraries and techniques we introduced in our new course, will have you writing the best Python web apps you've ever written.
40:53 Clean, fast, and interactive, all without that front-end overhead.
40:57 If you're a Python web developer that has wanted to build more dynamic, interactive apps, but don't want to or can't write a significant portion of your app in rich front-end JavaScript frameworks, you'll absolutely love HTMX.
41:10 Check it out over at talkpython.fm/HTMX or just click the link in your podcast player show notes.
41:18 So let's talk about some of the other features.
41:20 Back to this example here, there's one thing I wanted to highlight that I think was really neat that I saw.
41:26 So you've got the standard.
41:29 I've created an object that goes in the database, and I call insert, and I await that.
41:34 That puts it in the database, right?
41:35 Yeah.
41:36 So I don't see a return value here.
41:38 Does that actually set the ID on this thing that's being inserted after that function call?
41:42 It updates.
41:44 Okay.
41:44 Perfect.
41:45 Yeah.
41:46 So .id is good to go after that, right?
41:48 Yeah.
41:48 Yeah.
41:49 Okay, cool.
41:49 And then the other one, you've got your await find one.
41:53 The filter syntax is the first thing I wanted to talk about, which I think is really nice.
41:57 Thank you.
41:58 So even though these things are, does it have to be one of these indexed ones, or can you do these queries of the style on any of these?
42:08 Could I do a category or a description equals something or a name equals something?
42:12 Yeah.
42:13 Yeah, sure.
42:13 You can do it with everything.
42:14 And you can do it even in the same line, in find one, price less than 10, comma, and name equals, I don't know, your name.
42:25 So it will work.
42:27 Nice.
42:27 So the way that you would say, I want to find the product, or all the products, that has a price less than 10, is you just say, in this case, a product is a class with a price field.
42:39 You just say product.price less than 10, right?
42:42 Just like you would in an if statement or a while loop or something like that.
42:45 Yeah.
42:45 This is really nice because the alternative is something like what you have in MongoEngine, where what you would say is you would say price underscore underscore LLT equals 10.
42:58 Yeah.
42:58 Right?
42:59 You would say, like, separate the operators on the field with double underscores.
43:03 And so LT means less than, and then you equal the value you want it to be less than.
43:07 And that is entirely not natural.
43:10 It's not horrible.
43:11 You can get used to it, but it sure isn't the same as price less than 10.
43:15 Right?
43:16 Yeah.
43:17 That is really nice.
43:17 On the very beginning, when I told that I was Django developer, not Python developer, it was about this.
43:22 Because I knew how to do this stuff about Django, but it's not Python syntax, honestly.
43:29 It's Django syntax, which moved to.
43:32 Exactly.
43:32 So you can do these natural queries.
43:35 You got, like, less than, greater than, equal, not equal to, and so on.
43:38 Yeah, yeah.
43:39 For if it was none, I mean, thing is none is the most natural way, but you would just say equal, equal none.
43:45 Is that how you would test this?
43:46 Yeah.
43:47 You cannot hear.
43:48 So it's not supported to use is.
43:51 That's fine.
43:51 You can use only equal.
43:53 It's better than underscore, you know, price equals 10 or equals none, just as an assignment.
44:00 That's even weirder.
44:01 So that's cool.
44:03 Then the other thing that I thought was neat is so often in these ORMs, and it is worse in the Mongo story because each record that comes back represents more of the data, right?
44:16 In this case, you've got a product, and the product has a category, whereas those might be two separate tables in a relational database.
44:24 So the problem is I get one of these objects back from the database.
44:28 I make a small change to it, like I want to change the name, and then I call save, and it's going to completely write everything back to the database, right?
44:36 It's going to override everything, which can be a big problem.
44:39 There's a couple of solutions you have for that, and one is you have the in-place update operators, like set, and I'm guessing do you have like increment and decrement and add to set and those kinds of things?
44:52 Yeah, literally everything from which MongoDB supports.
44:55 Yeah.
44:56 Right.
44:56 So in this case, you can say product.set, and then product name is gold bar, right?
45:04 Rather than what was it before?
45:05 It was Tony's or something like that, right?
45:08 Yeah.
45:08 And that'll do a MongoDB dollar set operation, which is an atomic operation.
45:14 So somebody else could be updating, say, the category at the same time and sort of transactionally safe.
45:20 And so this way you're both way more efficient.
45:23 And it's also safer that you're not possibly overriding other changes.
45:27 Yeah.
45:28 And also in current version, it's possible to, so Beanie tracks all the changes of the object.
45:37 And when you call instead of set, you can call a safe changes.
45:42 And it will call set inside for all the changes which was happened with this object.
45:48 Yeah.
45:49 This was the other way that I was hinting at.
45:51 And it's super cool.
45:52 Where is this?
45:53 Save changes.
45:54 There we go.
45:55 On all of these documents, you can optionally have a class, an inner class called settings.
46:00 And then you can do things like use state management equals true.
46:04 And you don't have to figure out how to write those set operations or increment operations or whatever.
46:10 You can just make changes and call save changes and off it goes, right?
46:14 Yeah.
46:14 Yeah.
46:15 So it's quite simple.
46:17 Yeah.
46:17 This is really, really cool.
46:18 I like that about this, that it gives you that option to sort of use the most natural way of making very small changes to the data, right?
46:27 Because so often ORMs and ODMs are, give me the object back and make a change to it.
46:32 Put the whole thing back wherever it came from, you know?
46:35 Yeah.
46:35 Yeah.
46:36 I agree.
46:36 And also, if you don't want to fetch object at all and you want to set something to object, you can use update query here, right?
46:44 Yeah.
46:45 And you will not even fetch object into your application.
46:49 That's a really good point because so often with ORMs and ODMs, the set-based behaviors are super hard to do, right?
46:57 Like, let's suppose I've got 100,000 users.
47:00 I want to go and, you know, set some field to like a default value that didn't previously exist in the database.
47:06 Or I want to compute something that's a computed field that wasn't previously there.
47:11 So I've got to go to each one, make a change or something.
47:14 I mean, if it's always the same value, you still would need to go in the ORM stories, like, do a query, get the 100,000 records back, loop over them, set the little one value on the class and call save.
47:28 But what you're saying is you could just do, like, product, or in my case, users.update, value equals what you want it to, and just update all of them, right?
47:38 Update many, you might have to call or something like that.
47:40 Or you can even find something and then .update.
47:42 And it will update on only...
47:45 Oh, really?
47:46 So you could do like a find all, then a .update?
47:49 Yeah.
47:49 And it wouldn't actually pull them back from the database?
47:51 It will not fetch them, yeah.
47:52 Oh, my goodness.
47:53 Okay.
47:54 It's a bit magical.
47:54 That's very magical.
47:56 That's awesome, actually.
47:57 Then, again, the other things you have on here that are really just simple is, like, you can do a find and then just a to list on it.
48:04 You know, like, I don't want to loop over it or whatever.
48:07 Just give me the list back.
48:08 That's also nice.
48:09 Yeah.
48:10 Yeah.
48:10 Let's see.
48:10 How are we doing on time?
48:12 We're getting a little short on time.
48:14 Let me...
48:14 Let's talk through a little bit of some...
48:16 There's a really nice tutorial here that starts out with defining documents, setting up the code, which is pretty much just standard MongoDB, right?
48:26 Like, you have to create one of these clients, but what you're really creating is just a motor client.
48:30 So I'm guessing you can send as, like, complex of a MongoDB configuration as you need to, and it doesn't affect Beanie.
48:36 Yeah, and also now it's not documented yet because I'm lazy, but Anthony Shaw, you know him, I think?
48:44 Anthony Shaw makes common appearances here, yes.
48:47 Yeah.
48:47 He suggested me to add optional, so you can pass a connection string instead of all this stuff with database, just init, Beanie, and connection string, and it will work.
48:59 Nice.
48:59 But I have to add documentation about this because...
49:02 Sure, so in the documentation, you create a motor client, and then you pass the client over to Beanie init, or you just create the client first, right?
49:11 But if you just call init Beanie with the right connection string, it'll do that behind the scenes for you.
49:17 Yeah, thanks, Anthony.
49:18 That's really good.
49:19 So, but if you're working with, like, sharded clusters and replica sets and all the kind of stuff that is, like, on the outer edge of these use cases, that should be supported, right?
49:30 Yeah.
49:30 It's just under, behind the scenes, you don't have to know about it.
49:33 The other thing that's interesting is when you initialize it, you pass it all the document classes, like product or user or whatever, right, as a list?
49:43 Yeah, yeah, because you have to, so under the hood, document must know to which database it's picked because, so for some use cases, you can use different databases in the same application.
49:55 And in that case, you have to init Beanie for different databases with different set of models.
49:59 So, yeah, you have to pass models there, in that case.
50:04 Yeah, I do that in mine.
50:05 I have multiple databases, like logging and analytics and all that kind of stuff goes to one database that gets managed and backed up less frequently because it's, like, gigs and gigs of data.
50:18 But, you know, if you lost it, the only person who would care in the world is me, like, I lost my history of stuff, right?
50:24 As opposed to the thing the website needs to run or user accounts or whatever.
50:29 Like, those need to be backed up frequently and treated really specially.
50:34 So, I actually have those as two separate databases based on classes.
50:38 So, I guess what you're saying here is you can also call init Beanie on multiple times with different databases and different lists of documents.
50:46 Yeah.
50:46 And it will work.
50:47 Nice.
50:48 Yeah, that's really cool.
50:50 Can you give it, like, a star type of thing?
50:52 Like, everything in this folder, in this module or this sub package?
50:58 Not yet, unfortunately.
51:00 But it's a nice feature, I think.
51:03 Yeah.
51:03 Sounds like a feature request, yeah?
51:05 Okay, sounds like a feature request.
51:06 Yeah, so if you could give it something like, all my models live in this sub package of my project or in this folder.
51:13 Like, there you go.
51:14 That might be nice.
51:15 Because, you know, one of the things that happens to me often is I'll add, like, a view to some part of my site and I'll forget to register it somewhere.
51:26 Like, why is this a 404?
51:28 Oh, yeah, yeah, yeah.
51:29 I got to go and make sure the thing can see this file.
51:31 It will erase an error, an exception, errorless, and then you will call an endpoint.
51:38 Nice.
51:39 If you will try to touch any document without initialization, it will erase an error.
51:43 Yeah, cool.
51:43 So, let's see.
51:45 Let's talk indexes.
51:46 I started our conversation with my utter disbelief that there are websites that take five seconds to load.
51:52 And I'm like, I know they don't have more data than I have.
51:56 I just know they've done something wrong.
51:58 There's no way this has more data.
52:00 So, indexes are critical, right?
52:03 What is the index story?
52:04 How do you create them over here?
52:06 It's an interesting story about indexes, honestly.
52:08 Like, I published my first version of Beanie and one guy texted me that probably it's possible to add indexes there.
52:17 I don't see if it's supported or not.
52:20 And in a few days, I added them.
52:24 Yeah, that's right.
52:25 We covered Beanie when it first came out on Python Bytes.
52:28 I'm like, this is awesome, but where are the indexes?
52:30 A bit of a stickler for those.
52:32 That's awesome.
52:33 So, yeah, the way you do it is instead of saying when you define a class, say the type is, say, a str or an int, you would say it's an index of int.
52:43 And that just creates the index.
52:45 And it looks like, you know, in Mongo, you have all these parameters and control.
52:49 Is it a sparse index?
52:52 Is it a uniqueness constraint as well?
52:54 Is it ascending?
52:55 Is it descending?
52:56 And whatnot.
52:57 And so, you can pass additional information like that it's a text index or something like that, right?
53:02 Yeah.
53:03 Yeah, it supports all the parameters.
53:04 And uniqueness.
53:05 This isn't super important, right?
53:07 Like, your email on your user account had better be unique.
53:11 Otherwise, a reset password is going to get really weird.
53:13 You support multi-field indexes, which is something that's pretty common, like a composite index.
53:20 If I'm going to do a query where the product is in this category and it's on sale, you want to have the index take both of those into account to be super fast, right?
53:29 So, you have support for that?
53:30 Yeah, it supports also.
53:31 But it's not that neat, let's say.
53:34 It's not that beautiful.
53:35 But it supports it.
53:36 Yeah.
53:37 The payoff is worth it.
53:40 It's also in this class called collection, right?
53:43 So, it's kind of in its own special inner class of the model, in which case, you know, a lot of the IDs have a little chevron.
53:51 You can just collapse that thing and not look at it anymore.
53:53 So, it's easy to hide the complexity, I guess, there.
53:58 Yeah.
53:58 Cool.
53:58 All right.
53:59 What else?
54:00 Aggregation.
54:01 It sounds like that when we talk about, I'll have to get to it pretty quick.
54:05 When we talk about relationships and stuff, you said that this is super efficient because it's using the aggregation framework.
54:13 So, MongoDB has like two ways to query stuff, right?
54:16 It's like the straight query style.
54:18 And then it has something that's honestly harder to use but more flexible called aggregations.
54:24 And so, you guys support, your library supports aggregation queries as well, right?
54:29 Yeah.
54:29 Yeah.
54:30 And also, as before, with updates, it also supports find queries together with aggregations.
54:36 Like an example, for example, there are some presets of aggregations, average here.
54:41 And you can use this average with find queries together and you will see the result.
54:46 And also, for sure, you can pass a list pipeline in MongoDB terms.
54:50 You can pass pipeline of your aggregation steps there and it will work.
54:55 Yeah.
54:56 It's not super easy to write if you haven't done it before, but yes, it will work.
55:00 Yeah.
55:01 And also, the thing is, with aggregations, you have to set up what schema of the result
55:07 would be because with find, everybody knows it would be the same schema of the document,
55:11 of the original document.
55:12 But with aggregations, it definitely can be any schema of results.
55:16 Right.
55:17 Because the whole point of aggregation and other people might know something similar with
55:21 MapReduce is I want to take, say, a collection of sales and I want to get a result of show
55:28 me the sales by country and the total sales for that country.
55:32 Right.
55:32 So you're not going to get a list of sales back.
55:34 You're going to get a thing, a list of things that has a country and a total sales.
55:38 Right.
55:39 Yeah.
55:39 For sure.
55:40 It's optional and you cannot pass output model.
55:44 And in that case, it will return dictionaries, but it's not that fancy.
55:48 So it would be better to.
55:50 Yeah.
55:51 This is super cool.
55:51 I love this projection model idea.
55:53 Mario in the audience says, I created a model loader.
55:56 Speaking of the passing the documents to Beanie and init, I created a model loader as a utility
56:03 function that pulls dot separated pass and then passes it to document models.
56:08 Works really well.
56:09 Great.
56:10 There you go.
56:11 Right on.
56:13 So let's talk about relationships.
56:16 Because I started out talking about, you don't use the R, you use the D because you model documents,
56:21 not relationships.
56:22 And yet Beanie supports relationships.
56:25 I'm super excited about this.
56:28 Yeah.
56:28 Tell us about this.
56:29 Yeah.
56:29 So it took around three months to come up how to do relations.
56:34 MongoDB doesn't support relations.
56:37 But relations is very popular feature in Orium and ODIMs.
56:45 And I had to implement it finally.
56:47 And I did it.
56:49 For now, it's supported limited version of relations, like only top level fields are supported and
56:56 only two kinds of relations, direct relation and list of relations.
57:02 Right.
57:02 A one-to-one or a one-to-many, I guess.
57:05 One-to-one, one-to-many.
57:06 Yeah.
57:06 Uh-huh.
57:07 And so the syntax is by tonic, I'd say.
57:11 It uses generic class link inside of bracket, of square brackets, pass your document.
57:18 Right.
57:19 So maybe you would specify, normally you would say an optional int.
57:23 Here you would say like link int.
57:25 And that might, int doesn't make sense.
57:27 But, you know, that type thing would be the relationship, right?
57:29 It's like the same syntax as optional basically here.
57:31 Yeah.
57:32 It's a little bit tricky and with a black magic under the hood.
57:36 But as long as I don't have to know about it.
57:39 Thanks for creating the black magic.
57:40 So you could say here your model is there's a door and a house.
57:44 And then the door is of type link of door.
57:47 And then you have another one.
57:49 You have windows where the house has many windows.
57:52 And you would say the windows is a list of link of window, which is, it's a little bit
57:58 intense on the nesting there, but it's not bad, right?
58:02 It's just, it's a list of relationships.
58:04 Yeah.
58:04 Yeah.
58:05 Yeah.
58:05 And for sure it's possible.
58:06 And I think later it would be implemented.
58:09 I will, you know, shorten this list of link to another.
58:13 Links.
58:15 Links.
58:16 No, just kidding.
58:17 Don't do that.
58:17 Although it would be kind of awesome.
58:20 As a syntax, I think it would be less discoverable.
58:25 Yeah.
58:26 Yeah.
58:26 And it works.
58:27 You can insert data inside of this linked documents to linked collections.
58:34 And you can fetch data from linked collections.
58:35 Yeah.
58:35 And you can even have it cascade things.
58:39 So for example, you could have created a house object and say dot windows is this list of window
58:45 objects.
58:46 And then you would say house dot save.
58:47 And if you pass the link rule, then that says write the cascade the changes.
58:54 It'll also go and insert all those windows and associate them.
58:57 Right?
58:58 Yeah.
58:58 Correct.
58:59 And I didn't use cascade term because it's not SQL database and a little bit different
59:06 things.
59:07 Sure.
59:07 With relations, it would be a little different.
59:10 Yeah.
59:10 How does this look in the database itself?
59:13 So if I go to MongoDB and I pull up the house, what is in its windows?
59:19 Is that a list of the IDs of the window objects or what is that?
59:23 In MongoDB, there is a special data type called ref ID.
59:28 Okay.
59:28 It's combined under the hood.
59:30 It's binary and data type, but under the hood, it's a combination of ID of the document,
59:36 name of the collection and name of the database.
59:39 So it's a two point.
59:40 Oh, interesting.
59:41 Okay.
59:42 So that's what I, in the document, what I end up with is a list of those things.
59:46 Yeah.
59:47 Yeah.
59:47 Okay.
59:48 And you will see a few collections like here, house, window and door, three collections
59:54 with objects, separated objects.
59:57 Okay.
59:58 Cool.
59:58 You can also tell it that you don't want to propagate those changes, right?
01:00:02 As you save the house, which is interesting.
01:00:04 Let's talk about refetch.
01:00:07 So I told you one of the, when I see those websites that are just dragging super slow, I go through
01:00:13 my thing.
01:00:13 All right.
01:00:14 Did they forget the index?
01:00:15 Are they doing some terrible seven way join?
01:00:18 Probably without indexes.
01:00:20 Or the third thing.
01:00:21 Is it an N plus one ORM problem where they get one thing, but then they've got to go back
01:00:25 and back and back because they're touching this related field, which you could potentially run
01:00:31 into that problem as well.
01:00:32 So you have this prefetch idea, which is kind of like a joined load or something like that,
01:00:37 right?
01:00:37 Yeah.
01:00:38 Yeah.
01:00:38 It uses lookup aggregation in terms of MongoDB.
01:00:42 it's not just find query, but aggregation and it avoids this N plus one problem.
01:00:48 Yeah.
01:00:49 As you said.
01:00:49 Right.
01:00:50 So you just do, and you're fine.
01:00:51 You just say fetch links equals true.
01:00:53 And that'll just go get the doors, the windows, everything in your house example, right?
01:00:57 Yeah.
01:00:58 And I like the speed of this.
01:01:00 Like it's much faster than do it, you know, one by one, especially for list of objects.
01:01:05 Yeah, absolutely.
01:01:06 So you also have the ability to say fetch all links retroactively.
01:01:10 If you've been like, oh, I should have, I should have done this join, but I didn't.
01:01:14 Yeah.
01:01:15 That might sound silly, right?
01:01:16 Well, why not just always do the join, right?
01:01:18 That's one, probably slower than not doing it, I would guess.
01:01:22 And two, this happens to me all the time.
01:01:25 Like for example, on the courses website, I want to show, I want to be able to get the
01:01:30 courses, but the courses have like chapter information and other stuff inside of them.
01:01:35 And then those have like links effectively over to say like all the details about each chapter,
01:01:41 like the lectures and videos and all that.
01:01:44 On say the page that lists the courses, I do not want those things.
01:01:49 But on the course details page where it shows you like, here's all the stuff in the course
01:01:53 and how long it is, like I definitely do want those things.
01:01:56 So in my data access layer, I have a thing that says, should you get all the data or just
01:02:01 the top level data?
01:02:02 Basically.
01:02:03 And this would be exactly the code you'd write.
01:02:05 Like, well, if you want all the data, you'd say fetch all links on it, right?
01:02:09 Yeah.
01:02:09 Yeah, correct.
01:02:10 This is cool.
01:02:11 Is there a way to do that on a set?
01:02:13 Like this is on one record.
01:02:15 Is there a way to say I got 20 houses back, fetch all of their links?
01:02:19 Or do I have to do it?
01:02:21 Is that 20 calls?
01:02:22 So it would be 20 calls, unfortunately.
01:02:23 That's okay.
01:02:25 I think in my example, it's also 20 calls or however many.
01:02:29 The same setup is exactly the same.
01:02:31 But I will improve it.
01:02:33 I hope.
01:02:34 Yeah.
01:02:35 This is worth pointing out.
01:02:36 This is a brand new feature, right?
01:02:37 You announced this as one of the new features just two days ago.
01:02:42 On Monday, yeah.
01:02:43 Yeah.
01:02:43 And for the people listening, we're recording on Wednesday morning.
01:02:47 So yeah, this is not, this is like your first pass.
01:02:50 But I really like how this looks with the relationships and the querying and whatnot.
01:02:54 It would be nice, I think, if you could have some way to kind of globally configure to save.
01:03:00 In general, if I call save, the rule to write the relationships is to not, to do nothing or to always write them or something and then only have to override it potentially.
01:03:10 Yeah.
01:03:11 Yeah.
01:03:11 Sounds like default, default rule.
01:03:12 Yeah, exactly.
01:03:13 Exactly.
01:03:14 That'd be pretty cool.
01:03:14 So let's see a few other things we could talk about.
01:03:19 We talked a little bit about the event-based actions, but you want to just kind of talk about them directly because it was like a quick, well, how do I add my default value?
01:03:28 What's the overall picture with these default, with these event actions?
01:03:31 Yeah.
01:03:32 A lot of, somehow a lot of people wanted this.
01:03:35 And I didn't know about this pattern before.
01:03:41 Like it's implemented something like this, implemented in ActiveRap record pattern of Rails.
01:03:47 And so finally I was inspired by this.
01:03:50 I like this word inspired by.
01:03:53 Not stolen, but inspired by.
01:03:56 Exactly.
01:03:57 Yeah.
01:03:57 And we met this, yeah.
01:03:59 And now it's supported only four types of events.
01:04:04 There are events on each insert, replace, save, changes, and validate on save.
01:04:09 It creates an event and two events before it called and after it called.
01:04:16 And based on these events, actions already registered to the document would be called also.
01:04:23 It supports and asynchronous and asynchronous methods for this.
01:04:28 And you can do a lot of stuff with this.
01:04:30 Yeah, that's cool.
01:04:31 Yeah, that's cool.
01:04:31 You can put the decorator on just an async version or a non-async version and being able to just call it correctly, right?
01:04:37 Yeah.
01:04:38 Yeah.
01:04:38 Yeah, that's cool.
01:04:39 I'm guessing if you're not doing any awaits, it'd be better if it was not asynchronous, but it doesn't matter that much, right?
01:04:46 It's one and a half faster if it's not asynchronous.
01:04:49 Yeah.
01:04:50 So probably it's critical for something.
01:04:52 Yeah, if it's doing something where it's waiting on something else, then maybe it should be.
01:04:55 Yeah.
01:04:55 Okay.
01:04:56 Another feature that just came out is cache.
01:04:59 Yeah, cache.
01:05:00 Tell us about this.
01:05:01 It's also an interesting feature.
01:05:04 Like, so yeah, it's cache.
01:05:06 I don't know if I have to explain what is cache.
01:05:09 It's when you save data somewhere locally and use a copy of data for some time.
01:05:16 Yeah, and what you're talking about is not using MongoDB as a caching backend, but caching the queries that would run through Beanie to not hit the database again if it knows the answer.
01:05:27 Yeah.
01:05:27 Yeah, and somehow it's a really important feature even for my projects.
01:05:32 For example, if you have to validate stuff with user and you already asked for a user in this application with this ID, but you don't know the place where you did it and you don't want to provide this.
01:05:45 It's an object through the whole pipeline because probably it will not be used in the end of this pipeline.
01:05:50 But user is already cached in Beanie.
01:05:53 And if you just will ask in the end of the pipeline again about the same user data, so it would be there.
01:06:00 And with a bigger field of find queries, it works the same way.
01:06:05 Yeah, the more complicated the query, the better.
01:06:07 This makes a lot of sense, I think, for data that doesn't change much.
01:06:11 Like if you've got a bookstore, you might have categories and books.
01:06:14 And maybe the books change often.
01:06:17 The reviews of the books change often.
01:06:19 The books that are in different categories change.
01:06:21 But the categories themselves very rarely change, right?
01:06:25 So that could be something like the category query could just be like, you know what?
01:06:28 This is cached.
01:06:29 Yeah, definitely.
01:06:30 So for now, it supports only local cache like dictionaries of Python.
01:06:36 But I plan to add another cache backends like Redis and things like this.
01:06:41 Yeah, that's cool.
01:06:42 Or even possibly you could put, it might even make sense to use MongoDB itself as a cache.
01:06:47 Yeah.
01:06:48 Because it's more native.
01:06:49 I mean, it'd be weird to kind of store the same thing back into it.
01:06:53 But at the same time, if you've got a complicated query, what you're storing is like, these are the three things that came back from running that query against possibly hundreds of millions of records.
01:07:03 Right?
01:07:03 So in that case, it might make sense to just put it back in Mongo so it's just a straight, you know, table scan read.
01:07:09 Something like Lambda architecture inside of the single database.
01:07:12 Yeah.
01:07:12 So I wanted to ask you, your example says, okay, what we're going to do is say sample.find num greater than 10 to list.
01:07:20 And then if you call it again with the caching on, then you get the same thing.
01:07:25 Well, it looks at the actual query, right?
01:07:28 So if I said num greater than 11, I would get, that would be a separate result and a separate cached thing, right?
01:07:34 Yeah.
01:07:35 Yeah, totally.
01:07:36 Cool.
01:07:36 The other thing I guess that's worth noting is you can set an expiration date on the cache, right?
01:07:41 Like I want this to live for 10 minutes or whatever to get the answer back.
01:07:46 Yeah.
01:07:47 Yeah.
01:07:47 Yeah.
01:07:47 Cool.
01:07:48 All right.
01:07:49 Let's talk about revisions.
01:07:50 And then I'm going to propose one more idea that I think I could build out of revisions and events.
01:07:56 So what are revisions?
01:07:58 So it's not my idea again.
01:08:01 It's neither one user asked me for this.
01:08:03 And I really like users of Winnie because I have not that many ideas.
01:08:10 And yeah, what is this?
01:08:12 You, sometimes you have to protect document inside of the database of changes.
01:08:18 So yeah, sometimes you have old version of the data in your backend and you do some updates.
01:08:24 And if you update your document with this old data, you will lose data updated by another
01:08:31 backend for the same document.
01:08:33 So let me, let me give people some examples because I think understanding the context is
01:08:38 really important.
01:08:38 Like it could be even the same function basically.
01:08:41 Right.
01:08:42 So I could have a function that do complicated things.
01:08:45 I could say, get me my user object for the current user who wants to make some changes.
01:08:49 I could call, do a bunch of work, call a function with the past, say like the user ID over.
01:08:55 Maybe that gets the user back, makes some changes, saves it to the database.
01:08:59 And then I go to the end, I make some more changes, not realizing that to my in-memory version.
01:09:04 And I call save and it overwrote what that intermediate function might have, whatever was there is gone
01:09:09 now.
01:09:10 You know what I mean?
01:09:11 So you would want to know, is there, is the thing that I got back, if I'm going to replace
01:09:18 it in the database, is it still the same thing or somebody somewhere behind the scenes changed
01:09:24 it?
01:09:24 You know, often I think that people think about very complicated.
01:09:27 Well, some other process did some other thing, but it could just be some other part of your
01:09:32 code that you didn't realize called save after a query.
01:09:35 Yeah.
01:09:35 Yeah.
01:09:36 And for this case, I'm using a revision ID, a special token, which generates each time when data saves into the database.
01:09:45 And when you save again, it will check if this ID is the same or it's already updated.
01:09:53 If it's updated, it will raise an error, like you have all data in memory, but if it's the
01:09:58 same, it will allow you to.
01:09:59 Nice.
01:09:59 That's really cool.
01:10:00 I think it's a great feature.
01:10:02 It's good.
01:10:02 It definitely is.
01:10:03 Because the alternative of this pattern is to do a blocking transaction.
01:10:08 Yeah.
01:10:08 Right.
01:10:09 And that's also potentially possible.
01:10:11 I think MongoDB does have transactions now, but I still haven't used them.
01:10:14 I don't really have a use for that.
01:10:16 But the alternative model in databases is to say, we're going to do a transaction that blocks
01:10:23 and anyone else who tries to do a database thing whatsoever, they just wait until we're
01:10:27 done.
01:10:28 And that way, there's no chance of them seeing it in this intermediate state.
01:10:32 A lot of the scalable systems don't end up doing that even in relational databases because
01:10:39 this blocking model can really kill the concurrency.
01:10:41 Yeah.
01:10:42 Right.
01:10:42 And so they end up doing optimistic concurrency with these types of revisions.
01:10:45 Anyway, it's just so I think it's a really cool pattern.
01:10:49 I love it.
01:10:50 Yeah.
01:10:50 This is great.
01:10:51 It's great.
01:10:52 It's not my idea, but it's great.
01:10:54 It's really good.
01:10:55 It's also, I guess, worth discussing set and increment and those types of things.
01:11:01 So if I say I want to add a category to a product, I could do add to set on that thing
01:11:08 and just put this thing in its category list.
01:11:12 Will that also increment the revision?
01:11:15 So only set, I think, yeah.
01:11:18 Because if you will use internal methods of MongoDB, it will not understand that it needs
01:11:24 to update another field.
01:11:25 Got it.
01:11:26 Okay.
01:11:26 Interesting.
01:11:27 But yeah, that's a good feature.
01:11:29 I like it.
01:11:29 This is a big release.
01:11:30 It's a huge one.
01:11:31 Cool.
01:11:32 Well, we've been talking for a long time.
01:11:35 As you can tell, I'm very excited about it.
01:11:37 What else?
01:11:38 What's coming next?
01:11:39 So next, I have a big plan sales.
01:11:42 I really like Pydantic.
01:11:44 I'm a huge fan of Pydantic.
01:11:46 You can see it.
01:11:47 But for some cases, Pydantic is a heavy tool.
01:11:52 And probably, I don't know how I will implement it, but I want to add support of native Python
01:11:59 data classes here or here or to separate it smaller project like Bini data classes.
01:12:06 I don't know yet.
01:12:07 But anyway, I have planned to add native classes without Pydantic.
01:12:11 Just with not, let's say, fancy parsing stuff without that great validation stuff.
01:12:18 But somewhere in between, I just want to, you're just getting dictionaries back.
01:12:24 Good luck.
01:12:24 And you're getting Pydantic.
01:12:26 Somewhere in the middle is you're getting classes back, but they don't necessarily, they're not
01:12:30 as precise as, say, Pydantic.
01:12:32 Yeah.
01:12:33 There are cases.
01:12:35 And people use Bini with these cases also.
01:12:39 When you have a lot of huge JSONs as a document, and when you parse it on a fetching, it keeps
01:12:46 a lot of time.
01:12:48 Yeah.
01:12:49 So it takes a lot of time just for parsing.
01:12:51 And then for encoding back to dictionary to store this dictionary.
01:12:56 Yeah.
01:12:57 It's not Pydantic fault, definitely, because Pydantic is, again, it's great.
01:13:01 But I need to avoid this step somehow.
01:13:06 And probably, probably I will use data classes for this.
01:13:11 Sure.
01:13:11 They look very similar.
01:13:12 Yeah.
01:13:12 Another scenario where I find that Pydantic is not a good fit is where I might be getting
01:13:17 bad data, but I don't want it just to be an exception.
01:13:20 I want to be able to get all the bad data and say, here's the three errors that you made
01:13:25 passing me this data.
01:13:27 And I'm not going to accept it, but here's what you gave me.
01:13:31 If you're doing like form exchange, right?
01:13:34 Like from an HTML form.
01:13:37 What you need to do is put the old value back in and say, that value right there, that's wrong.
01:13:42 But with Pydantic, if you get the value from the form and you try to read it, it's just
01:13:49 going to know it's wrong.
01:13:49 And you're like, wait, but I need to give it back to them.
01:13:51 Just don't run away.
01:13:52 Come back.
01:13:53 Where'd you go?
01:13:54 And so there's situations like that where you need to kind of keep that exchange going,
01:13:58 but you still want some sort of, you just got to do the validation yourself.
01:14:03 But anyway, there's certainly times where Pydantic is as cool as it is, it's not the right fit
01:14:07 for that situation.
01:14:08 Yeah.
01:14:08 Yeah.
01:14:09 I agree.
01:14:09 Totally.
01:14:10 Good example.
01:14:11 Thanks.
01:14:12 All right.
01:14:13 Well, this is a very cool project.
01:14:16 I've, as you hinted at earlier, I've seen it from the beginning, at least when you open
01:14:21 sourced it and it's really come a long ways.
01:14:24 It's super compelling.
01:14:25 It looks like something that I could possibly use on my next project.
01:14:30 I constantly, as many people out there are, I'm sure as you are, I'm constantly resisting
01:14:35 the urge to go, you know, I should rewrite that.
01:14:37 I should rewrite that in FastAPI or I should rewrite that in this.
01:14:42 I should rewrite my MongoEngine stuff with Beanie, but you know, maybe one day I'll break
01:14:47 down and do it.
01:14:48 It'd be fun.
01:14:48 Yeah.
01:14:48 Thank you.
01:14:49 Thank you.
01:14:50 Yeah.
01:14:51 Very cool.
01:14:52 So nice work on this project.
01:14:54 You're looking for contributors and PR.
01:14:56 Would you be, PRs, would you be happy to have people make contributions?
01:15:00 I make a bunch of issues now.
01:15:02 A lot of people found some, something doesn't fit to different use cases.
01:15:09 And so, yes, it would be great to have other contributors here.
01:15:13 I already have 15 contributors.
01:15:17 Yeah.
01:15:18 Yeah.
01:15:18 That's why I saw there's quite a few people in the sidebar there.
01:15:22 Yeah.
01:15:22 That's awesome.
01:15:25 Yeah.
01:15:25 But I need more, more and more.
01:15:27 And especially for documentation, because I don't know, I really much better in Python
01:15:34 than in English.
01:15:35 And documentation is my weak point.
01:15:40 Yeah.
01:15:40 Okay.
01:15:41 Cool.
01:15:41 Well, definitely a neat project.
01:15:43 So thank you for building it.
01:15:45 Now, before you get out of here, you have to answer the final two questions.
01:15:49 If you're going to write some Python code, what editor are you using these days?
01:15:53 What did you use to create Beanie with, for example?
01:15:55 I'm using Pesharm.
01:15:56 JetBrains also gave me ProVersion for Beanie as support program, I think.
01:16:03 Yeah.
01:16:03 Yeah.
01:16:04 Fantastic.
01:16:05 It's really great tool.
01:16:07 I'm expecting a new one I don't remember the name of, but so they have a new idea.
01:16:15 I don't remember the name.
01:16:16 Fleet.
01:16:16 Yeah.
01:16:17 Yeah.
01:16:17 I was about to mention Fleet.
01:16:18 Fleet is interesting.
01:16:20 Fleet is like JetBrains' response to VS Code.
01:16:23 Yeah.
01:16:24 I'm pretty excited about it.
01:16:27 You know, I really love PyCharm.
01:16:29 Nobody's going to be surprised that I say that.
01:16:31 But if I've got just one file, like I'm going to open that in VS Code because all the JetBrains
01:16:38 IDE tools, they expect like a project and they're going to create all these things.
01:16:42 I'm like, I just want to look at the files.
01:16:43 Just the files, please.
01:16:45 Like just not too much.
01:16:46 And this is kind of like that where you can later turn on some of the IDE features, right?
01:16:51 It looks pretty cool.
01:16:52 You're going to try it out?
01:16:53 Not yet.
01:16:53 I asked for it, but so JetBrains, if you hear me, please.
01:16:58 Yes, exactly.
01:16:59 JetBrains.
01:16:59 I'm already on the early access list too.
01:17:01 And I have an email.
01:17:03 Maybe I haven't checked it this morning.
01:17:04 Maybe it's there.
01:17:05 Fantastic.
01:17:08 Yeah.
01:17:09 All right.
01:17:10 So PyCharm, maybe Fleet in the future, potentially.
01:17:12 Cool.
01:17:13 And then notable PyPI package.
01:17:15 I mean, we've talked about a bunch of libraries already.
01:17:18 Yeah.
01:17:19 So I really like one.
01:17:20 It's not about Pydanticum or FastAPI stuff, but it's a great package called YARL.
01:17:27 Y-A-R-L.
01:17:30 Yeah.
01:17:30 It's like a pass library, but for URLs.
01:17:34 And it's great.
01:17:36 You can combine strings with this URL stuff together and you can parse it.
01:17:42 You can...
01:17:42 Oh, that's cool.
01:17:43 Yeah.
01:17:44 So you can pass it a URL as a string, just like whatever you'd expect.
01:17:47 But then you can say, give me the scheme, which is like HTTP, HTTPS, the host, the path,
01:17:53 the query string.
01:17:53 Yeah.
01:17:55 I really like how they use this divide operator.
01:17:57 You probably see it in the bottom of your page now.
01:18:01 Like URL, divide full, divide bar.
01:18:04 Oh, interesting.
01:18:04 It's like Pathlib style.
01:18:07 It's like Pathlib, yeah.
01:18:08 It's like Pathlib for URLs.
01:18:10 Cool.
01:18:11 It's super great.
01:18:12 All right.
01:18:12 This is totally new to me.
01:18:14 Awesome.
01:18:14 Good recommendation.
01:18:15 Good recommendation.
01:18:16 Yeah.
01:18:16 I use it in each project now.
01:18:18 I don't know how to live without this.
01:18:20 All right.
01:18:21 Well, I'm going to check it out for sure.
01:18:23 One quick follow from the audience here.
01:18:26 Mario says, thank you for this project.
01:18:28 I'm about to launch my FastAPI Beanie blog soon.
01:18:31 Couldn't have done it without it.
01:18:32 Thank you.
01:18:33 Yeah.
01:18:33 And Ollie's on it.
01:18:35 He says, Pathlibs for URLs.
01:18:37 Indeed, it's Pathlib for URLs.
01:18:39 Cool.
01:18:40 That's a great one.
01:18:41 All right.
01:18:42 Final call to action.
01:18:43 People want to get started with Beanie.
01:18:44 What do you say?
01:18:45 I would say, have fun.
01:18:47 Awesome.
01:18:49 I would recommend that people go and check out the, if you go to the documentation, there's
01:18:55 a tutorial that walks you through this pretty well right there on the left.
01:18:59 It just starts by defining a document and then initialization and so on.
01:19:03 Yeah.
01:19:03 Yeah.
01:19:03 We try to do this as much simple to understand as possible.
01:19:08 Fantastic.
01:19:08 All right.
01:19:09 Roman, thank you for being here.
01:19:11 Thank you very much for being here.
01:19:14 This has been another episode of Talk Python To Me.
01:19:17 Thank you to our sponsors.
01:19:19 Be sure to check out what they're offering.
01:19:20 It really helps support the show.
01:19:22 Take some stress out of your life.
01:19:24 Get notified immediately about errors and performance issues in your web or mobile applications with
01:19:30 Sentry.
01:19:30 Just visit talkpython.fm/sentry and get started for free.
01:19:35 And be sure to use the promo code talkpython, all one word.
01:19:39 Want to level up your Python?
01:19:40 We have one of the largest catalogs of Python video courses over at Talk Python.
01:19:44 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:19:50 And best of all, there's not a subscription in sight.
01:19:52 Check it out for yourself at training.talkpython.fm.
01:19:55 Be sure to subscribe to the show.
01:19:57 Open your favorite podcast app and search for Python.
01:20:00 We should be right at the top.
01:20:01 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:20:06 and the direct RSS feed at /rss on talkpython.fm.
01:20:11 We're live streaming most of our recordings these days.
01:20:14 If you want to be part of the show and have your comments featured on the air,
01:20:17 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:20:22 This is your host, Michael Kennedy.
01:20:24 Thanks so much for listening.
01:20:25 I really appreciate it.
01:20:26 Now get out there and write some Python code.
01:20:28 I'll see you next time.