Do Excel things, get notebook Python code with Mito



Panelists


On this episode, we're talking about a tool called Mito. This is an add-in for Jupyter notebooks that injects an Excel-like interface into the notebook. You pass it data via a pandas dataframe (or some other source) and then you can explore it as if you're using Excel. The cool thing is though, just below that, it's writing the pandas code you'd need to do to actually accomplish that outcome in code.
I think this will make pandas and Python data exploration way more accessible to many more people. So if you've been intimidated by pandas, or know someone who has, this could be what you've been looking for.
Episode Deep Dive
Guests introduction and background
Aaron, Nate, and Jake are co-founders of Mito. Aaron and Jake are twin brothers who studied computer science and business at the University of Pennsylvania, where they first experienced the power of data analytics through Excel and Python side-by-side. Nate is their longtime friend (dating back to middle school) and also studied at Penn, bringing a blend of technical and business insights to the team. Together, they set out to make Python-driven data workflows simpler and more accessible by combining the best of Excel’s user experience with the power of pandas.
What to Know If You're New to Python
Many parts of this conversation highlight the bridge from Excel to Python, especially focusing on pandas and Jupyter notebooks. If you're getting started in Python and want to follow along:
- Know that pandas is a core data library for Python that allows data manipulation similar to Excel.
- Jupyter notebooks are a popular, interactive environment for data exploration, but can introduce some installation complexity.
- Understanding basic Python types (integers, strings, lists) and how to install packages with pip or conda is often enough to get you going with data analysis.
- Be aware that working in data science will likely involve reading CSV/Excel files, cleaning data, and creating visualizations—pandas plus a plotting library is usually the go-to combination.
Key points and takeaways
- Bridging Excel and Python with Mito
Mito offers a spreadsheet-like interface directly inside Jupyter notebooks, letting users manipulate data with familiar Excel operations. Under the hood, Mito auto-generates pandas code so you get both a visual workflow and full Python scripts you can revisit or modify later.
- Links and tools:
- Lowering the Barrier to Pandas Many newer Python data scientists or Excel power users find pandas syntax daunting when getting started. Mito’s interface helps them explore and transform data by pointing and clicking, rather than writing all the syntax manually. This helps beginners avoid frustration and more quickly gain confidence in the Python ecosystem.
- Code Generation Done Right
Every change made in the Mito spreadsheet is reflected as structured and documented Python code in the cell below. Rather than producing messy, unreadable blocks, Mito strives to optimize these generated scripts so they’re closer to best practices. Users can even refine or extend this code on their own, which fosters learning and deeper data science engagement.
- Links and tools:
- Plotly (used for graphs generated by Mito)
- Links and tools:
- Installation Challenges and Jupyter Ecosystem Getting Jupyter and related Python environments set up can be tricky, especially for non-developers. The conversation highlights JupyterLab Desktop, JupyterLite, and other emerging solutions that reduce environment hassles by shipping “batteries included” or leveraging WebAssembly in the browser. Mito’s team also invests energy in making installation more seamless for users who need a quick start.
- Interactive Data Exploration and EDA
Mito adds helpful features such as summary statistics, distribution plots, filtering by unique values, and cell-based formula logic reminiscent of Excel. This visual approach to Exploratory Data Analysis (EDA) complements Jupyter’s head(), describe(), or custom plotting code, and provides a quick way to pivot, merge, and clean data.
- Links and tools:
- Pivot Tables and Advanced Transformations A frequent need for Excel users is quickly grouping and summarizing data via pivot tables. Mito’s pivot table UI in the notebook accomplishes this and auto-generates the corresponding pandas “group by” or “pivot” code. Advanced transformations like joining multiple datasets are also streamlined.
- Performance and Larger Data Sets
While Mito does load data into an in-browser grid, it employs lazy loading (virtual scrolling) to handle more rows than can fit on-screen. Underneath, it’s still pandas, so if the dataset grows beyond local memory, using solutions like Dask could be the next step. The Mito team noted future possibilities for integrating with Dask to scale beyond a single machine.
- Links and tools:
- No-Code vs. Low-Code vs. Full-Code
Mito sits in a balanced spot between no-code dashboards and pure Python scripts. It doesn’t lock you into a proprietary platform. Instead, it writes real Python code that you own, so you can switch back and forth as needed. This approach helps maintain reproducibility and collaboration with full-time Python developers.
- Links and tools:
- Alteryx (mentioned as a higher-level tool comparison)
- Links and tools:
- Collaboration and Communication One of the big advantages of bridging Excel and Python is bringing more stakeholders into data-driven discussions. Teams where some members prefer code and others prefer a spreadsheet can meet in the middle with Mito. This also prevents issues like version conflicts or multiple “.xlsx” attachments flying around in email threads.
- Mito’s Future and Business Model Mito is free to use in many scenarios, especially for individuals. The team sustains its project by providing paid support and enterprise-ready features to larger organizations. They continue improving code optimization, advanced charting, and cross-platform support (like VS Code, Google Colab) to make Mito a lasting, polished tool for the data community.
Interesting quotes and stories
- Excel “Dark Ages”: A memorable comparison was how switching between a CS environment with code and the business school’s reliance on Excel felt like the “dark ages” of data tools. This contrast motivated them to merge the best of both worlds.
- Complex Excel Models: The Mito team encountered enormous 75-tab Excel files loaded with circular references. Their reaction was, “We probably even built worse ones ourselves, but we saw that bridging to Python was essential to handle complexity more sanely.”
- Hitting Scale Limits: Nate joked about telling users, “Grab a coffee or maybe even sleep overnight,” if they tried to process huge data in pure Excel. This scenario underlined why Mito and pandas are valuable for larger, more efficient analytics.
Key definitions and terms
- Jupyter Notebook: An interactive environment in which you can combine code, visualizations, and narrative text.
- pandas: A Python library for data manipulation, providing DataFrame objects and many convenient functions for data wrangling.
- Pivot Table: A feature for grouping and summarizing data across one or more dimensions.
- Lazy Loading: Loading data incrementally (often in slices) rather than all at once to manage memory efficiently.
- Low-Code / No-Code: Tools that let you build applications or perform data manipulations with minimal hand-written code.
Learning resources
Here are resources to help you deepen your Python and data analysis skills:
- Python for Absolute Beginners: A thorough introduction to programming with Python, perfect for folks new to coding.
- Move from Excel to Python with Pandas: A specialized course to help Excel users adopt Python-based data solutions.
Overall takeaway
Mito serves as a powerful gateway for both Excel enthusiasts and experienced Pythonistas to create repeatable, optimized data transformations. The conversation demonstrates how the future of data analysis will increasingly blur the lines between code and spreadsheets, with Mito striving to deliver the best of both worlds. By generating clean Python behind its intuitive UI, Mito empowers you to scale your analysis, learn better coding practices, and remain free to adapt or customize as you grow.
Links from the show
Mito summary stats: trymito.io
pandas-profiling package: github.com
Lux API: pypi.org
Hex notebooks: medium.com
Deepnote: deepnote.com
Papermill: papermill.readthedocs.io
JupterLite: jupyter.org
Jupyter Desktop App: github.com
Jut: github.com
Jupyter project: jupyter.org
Watch this episode on YouTube: youtube.com
Episode #343 deep-dive: talkpython.fm/343
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Here's a question. What's the most common way to explore data? Would you say Pandas and Matplotlib?
00:06 Maybe you went a little broader and more general and said Jupyter Notebooks. How about Excel or
00:13 Google Sheets or Numbers or some other spreadsheet app? Yeah, my bet is on Excel. And while it has
00:18 many drawbacks, it makes exploring tabular data very accessible to many people, most of whom
00:24 aren't even developers or data scientists. On this episode, we're talking about a tool called
00:30 Mido. This is an add-in for Jupyter Notebooks that injects an Excel-like interface right into the
00:36 notebook. You pass it data via a Pandas data frame or some other source, and then you can explore it
00:42 as if you're using Excel. The cool thing is, though, just below that, in another cell, it's writing the
00:48 Pandas code. You need to actually accomplish that outcome in code. I think this will make Pandas and
00:54 Python data exploration way more accessible to many more people. If you've been intimidated by
00:59 Pandas or know someone who has, this could be what you're looking for. This is Talk Python To Me,
01:04 episode 343, recorded November 8th, 2021. Welcome to Talk Python To Me, a weekly podcast
01:24 on Python. This is your host, Michael Kennedy. Follow me on Twitter where I'm @mkennedy,
01:28 and keep up with the show and listen to past episodes at talkpython.fm. And follow the show
01:33 on Twitter via at Talk Python. We've started streaming most of our episodes live on YouTube.
01:39 Subscribe to our YouTube channel over at talkpython.fm/youtube to get notified about upcoming shows
01:45 and be part of that episode. This episode is brought to you by Shortcut and Linode,
01:51 and the transcripts are sponsored by Assembly AI. Aaron, Nate, and Jake, welcome to Talk Python To Me.
01:58 Hey. Hey. Hey, y'all. Thanks, man. How's it going?
02:00 It's going really well. I'm excited to be on the data science side of the world today with you guys.
02:06 Cool. So are we.
02:07 Yeah, you built some really neat tools to help people get started and get up to speed and just be
02:11 more efficient than just solely writing Python code, but not, you know, excluding that either with your
02:18 product Mito. So that's super fun, and we're going to talk about that. But before we do, you know,
02:22 let's just kind of go around and how do you get interested in data science and working on this
02:27 Python tool? Aaron, you want to go first?
02:29 Yeah. So a little background. Jake and I, you can't tell just by the first names,
02:32 but we are twin brothers. So we've been working on projects together for a long time. Nate has been
02:38 our best friend since middle school. I think I didn't get invited to his eighth grade birthday.
02:43 So I think maybe starting in high school. And then he also went to college with us.
02:46 And I think like, yeah, we got our first like taste of data science at Penn. We all studied a mix of
02:53 computer science and business. And in the business classes, you do a lot of Excel based,
02:59 mostly, unfortunately, Excel based data analytics work and stat classes and finance classes and stuff
03:04 like that. So I think that's really where we got our first taste of data analytics or data science
03:09 work. And then we've each had some experiences through internships and jobs that we've had over
03:14 the past few years in the data science space as well. But really, I think it all goes back to the
03:20 beginnings of the courseworks that we did at Penn.
03:22 That's great that you all are able to stay together. I mean, obviously brothers,
03:25 continue to work together. And on this project, you know, business, business schools,
03:30 a whole business program just run on Excel, don't they?
03:33 It's kind of amazing the contrast because so Aaron and I specifically both got degrees in computer
03:39 science and in the business school. And so it was there was this transition where you'd be hanging out
03:43 in, you know, in class in the engineering school, and you'd be writing code. And then you would like
03:47 walk up campus into the business school, and it'd be like returning to the dark ages in some ways,
03:51 right? Yeah. And what's really cool, I think about Excel generally is that what we observed is that it
03:55 let, you know, our peers in school and us as well kind of complete really some amazing projects that we
04:01 might have not been able to do with code because our skills, you know, we were still learning at that
04:04 point. And so it's really kind of this really beginner friendly, amazingly powerful tool for what it is.
04:08 But then we would go back down to the engineering school and be like, Oh my God, there's all this
04:11 tooling here. We could have superpowers, but we don't know how to use this stuff. Right? So there was this
04:16 very direct contrast that we witnessed where there's very cool stuff happening all over the
04:20 place. But the tooling differential is pretty dramatic between between business school and
04:24 computer science world. And I think that's kind of what initially made us interested in this space.
04:27 Sure. You don't want to underestimate the power of just firing up Excel, selecting a section,
04:32 throwing up a graph or two. And that's incredible. And all of the functions and stuff. But you know,
04:38 it's if you think of bad programming practices, one of the worst ones has got to be like,
04:44 do these three things and then go to over here and then do a couple of things, then go over there and
04:48 then get that thing and then go back. You know, we've banished this type of programming from regular
04:53 programming long ago. And Excel is like that without even being able to see where the go to's point.
04:58 You know, it's really, it's really not very predictable, right?
05:01 Yeah. It's really amazing. And it's really, it's crazy, I think, because once you start thinking about
05:05 spreadsheets, you quickly realize, I mean, there's a couple of crazy things about spreadsheets that
05:08 people don't really acknowledge. We, you know, talk about them internally because we're
05:12 spreadsheet nerds at this point. And, you know, we like, you know, hyping up spreadsheets and stuff,
05:15 but it's like, you know, the original killer applications of computers were spreadsheets,
05:19 right? Oh yeah. And more than that, it's spreadsheets are the most successful programming
05:23 environment in the world. Hundreds of millions of people can program in Excel. The next leading
05:28 programming language has 10, 20 million. You know what I mean? So it's really, there's an order of
05:32 magnitude difference in how, you know, well adopted these things are, but you're totally right.
05:35 The number of foot guns in Excel and the amount of like 50 megabyte insane models that we've seen
05:40 where people are like, it's 75 tabs and they're all linked to each other in some crazy circular way.
05:45 It's really slow. I don't know why.
05:46 Well, I know why.
05:48 Not sure what's happening, but yeah. And we probably have built a couple of those ourselves,
05:51 probably even worse ones. But yeah, so, you know, we've seen that and it's definitely,
05:55 those are some of the problems of spreadsheets that we kind of initially,
05:58 we were like, hmm, maybe these are some things that we can, you know, try to help solve.
06:02 Yeah, absolutely. And Aaron and Nate, as you would go from business school back to the computer science
06:07 side, I guess specifically to the business school, did your business peers look at you like, oh,
06:13 these are the guys that have the power to make the thing happen. They can help us build the thing
06:17 that we can't quite automate or can't quite pull off.
06:20 I think in some ways it was like trying to work in a group in an Excel spreadsheet is a miserable
06:25 experience. I hope you haven't had to do it, but it's like you upload, you have a Google drive
06:29 and then you end up uploading new versions to the Google drive. And then it's usually a Google drive
06:34 paired with a text message group chat. And it's like, I just finished this sheet. Why don't you go up
06:39 and, you know, do download it again or something? Yeah, exactly. Make sure you're not doing it the same
06:44 time I'm doing it. And I think that I don't think Nate and I maybe solved, solve those collaboration
06:50 problems while we're at Penn, but I think it was those experiences and our thinking we've had,
06:55 our programming as a superpower made us want to start doing this. I don't know if it was
06:59 always recognized by everybody else though.
07:01 I think the big thing was maybe we weren't the best at attending class. So that was, it was hard to be a
07:05 good group member in the first place, but one day, one day will be helpful.
07:08 Yeah. Group work was always hard for me as well. Jake, how about you? How'd you get into this whole
07:12 project here?
07:13 Well, mostly by plug line. I'm Aaron's twin brother. So sort of like a, some sort of covenant,
07:18 I think comes through that. But no, we, so we, we started working really in this like Excel
07:23 collaboration space. My background, I worked at a software company during college, sort of on the
07:28 project management side of some data science projects. So I had, you know, not quite the business
07:33 side of it yet, but at least a little one separate from like the coding product side of it.
07:37 Yeah. And yeah, we started working on these collaboration issues and we built a few other
07:41 products before it had some, you know, modicums of success there, but really took a step back
07:45 at one point. We're looking at like, what are the biggest problems with spreadsheets? It's the speed,
07:50 it's the inability to play in the large data sizes, and it's the lack of repeatability though.
07:55 It just allows you to do, you know, repeatable processes in an efficient way. And so the place we
08:01 found that does all this really well is some kind of sort of very elite is, is Icon. So if the idea was to
08:06 stick a spreadsheet interface on top of Python, and that was sort of like a sentence we had written
08:12 down really, okay, now we need to backtrack and realize like, what does that mean? How do we do
08:15 that? How do we deal with that? And, opened the few thousand cans of worms doing so.
08:20 Yeah, I'm sure. But it's a super neat idea. You know, there's a lot of things that you can automate
08:25 with Python, but with what you guys built, we'll get to it in a little bit, but what you all built
08:29 lets you interact in this spreadsheet way, and then it writes the Python code. It doesn't
08:35 just sort of allow you to make changes. And then you got to stay in your tool, right? You
08:41 use the tool to write code that otherwise might be a little bit of a stretch for you.
08:45 Yeah, I think, and I can talk more high level, they can talk about exactly why and how we did
08:49 that. But like a lot of just from the business side, like a lot of other tools will try and
08:53 extract Python away. So we'll give you, we'll allow you to do the types of workflows that you
08:57 would do in Python, but in a DUI individual environment, we're much more tethered to the Python
09:03 or try to be more tethered to the Python and the notebook. It's really important to us that you're
09:06 staying in your Python environment, and you're not at any, now you're not at a disadvantage at
09:11 all because you don't have the code. The code is right there. It's being generated real time.
09:14 And that's important for yourself. If you're learning Python, if you're trying to use the code,
09:19 or if it's a communication layer, you want that code because you want to send that to a developer
09:23 who's working in Python as well. So really important for us to be tethered there.
09:27 Right. Yeah. It probably brings, allows you to bring more people into the actual project than
09:32 before.
09:32 Yeah. You're much less siloed by being in the environment.
09:35 Yeah, absolutely.
09:36 That kind of like mentality of when you're building tools for beginners or people that don't know,
09:41 like maybe the professional software, make it really point and click and kind of like hide a lot
09:46 of the complexity. I think that's something that we've experienced with tools that we've used.
09:50 For example, like we use Stripe and Stripe creates a bunch of dashboards for you. But the problem is
09:55 we have no idea what those dashboards, like what, what is the nitty gritty details of how those numbers
10:00 are calculated. And so we have all these metrics and we have really poor understanding of like,
10:04 what is this actually telling us? And so I think something interesting that we definitely try to do
10:09 is we give you, you know, people that are maybe less familiar with writing the syntax yourself,
10:14 the ability to, as you said, point and click and use the spreadsheet environment and then generate the
10:18 code. And then if you ever have questions about, oh, like what did this, what is this pivot table
10:22 that I created? What does it really mean? Then you can look at the generated code and see exactly
10:27 what's going on. And I think that kind of like understanding where users need help and where
10:31 users want the as professional as possible, you know, nitty gritty details is a stratification that
10:37 we've thought about and I think have a somewhat unique approach to when it comes to these like no code,
10:42 low code tools.
10:43 Yeah, absolutely. So I kind of want to set the stage by talking about some of the different
10:49 things people are doing with notebooks because notebooks have really taken over in the data
10:54 science space for a good reason. I think, you know, we had IPython notebooks and we had Jupyter and we
10:59 had JupyterLab, which is doing a little bit more than just Jupyter and people really love them,
11:05 I think. And while JupyterLab is great, I think there's even, there's a bunch of creative things
11:12 going on, trying to extend it and use it in different ways. And I feel like Mito falls in there. So I
11:17 wanted to throw out a couple and just see if you all have heard of these and if so, get your thoughts
11:20 on them. One of them is this thing called JUT, J-U-T, J-U-T, maybe something like that. And what it allows you
11:29 to do is it allows you to actually view notebooks in the browser. So have you guys, or not the
11:35 browser, in the terminal, have you guys seen this?
11:36 I haven't seen it, but I do have a lot of sympathy for the unknown pronunciation of JUT or JUT because
11:42 we get Mito and Mito a lot. So my heart goes out to the JUT for sure.
11:46 Yeah, I'm sure, I'm sure I'm messing it up, but yeah. Yeah. So here's a way to say like, well,
11:51 these notebooks are so popular. Let's see if we can show them in the terminal. Like if I'm SSH'd into a
11:57 remote machine and it has, you know, IPYNB files and I just want to see them, how do I look at them?
12:03 And so you just say JUT, I'm going to go with JUT. You just say JUT and then the file name and then
12:08 boom, it shows it right there using Rich, I think. Super cool. Yeah, I think that this is, and I'm sure
12:13 this comment will expand out on as we see more of these, but I think it really demonstrates something
12:18 that we've really observed, which is that notebooks are not like, they're just like Excel in many ways.
12:22 They're not a tool that's used by one person for one specific thing, right? So we use a tool called
12:27 Mixpanel, for example. It helps us tracks and metrics, for example. It's a product analytics
12:32 tool. Yeah. I've used it before. Yeah. It gives you insane amount of analytics of like, where did
12:36 these people come from? How did they find my product and stuff like that, right? Exactly. And you can
12:40 kind of imagine though, it's really in some ways, it's just for product analytics, right? In some ways.
12:44 And the really interesting thing about a lot of our users is that we, you know, one thing as we're
12:49 trying to learn about our users and work with them to improve the tool, one thing we really realized is
12:52 there's people from all over the place and they're interested in notebooks for 472 different
12:57 reasons, right? And so some people using notebooks are people who've never written any Python code
13:01 before in their life. Some people have two weeks under of experience and some people are 75 year old
13:06 developers who only use the terminal. And if you show them anything else, they'll try and fight you,
13:09 right? So it's, you know, it's really, I think this demonstrates that there's really an appetite for a
13:13 wide range of kind of ways of consuming these things and presenting these things and editing these things
13:18 on these notebooks specifically. Yeah. That's a great, yeah. Yeah. Great analysis.
13:22 I totally agree. That's another cool thing about a tool like this or tools like this more generally
13:26 is that I think what they sort of have to do for a product perspective is condense down. What are the
13:30 really powerful things about notebooks? Cause they're taking a notebook and bringing it out of a notebook
13:34 environment. And I think kind of what we're trying to do with a spreadsheet is like, what are the values
13:38 of a spreadsheet? How can we bring a spreadsheet into other environments? So I think a tool like Jude is,
13:42 is just trying to do that. I think it's a, it's an interesting way to think about product. It's like,
13:47 sort of like, what is the essence? What is it? What are the essential parts of a notebook? What
13:51 are the essential parts of a spreadsheet? How do we translate those and bring that value to other
13:55 environments? So I always, I'm interested in tools like that. Yeah, for sure. This is an interesting
13:58 one. Another one is they just came out with JupyterLab desktop version. And I suspect that you guys
14:06 could even integrate with the JupyterLab desktop app, right? I hope so. Most likely. Yes. The answer is
14:12 probably yes. But, you know, I'll be honest with you, like candidly, if I spend one more minute
14:17 on installation problems, I might, you know, chop my arms off or something. I don't know,
14:20 but it's, it's really, I mean, I'm sure I don't have to preach to you. I'm sure you've heard this a
14:24 million times, but the Python installation ecosystem environment issues is a, it's a massive
14:30 blocker. I knew it was a massive blocker from like an individual level. Oh, I bet if you're trying to
14:35 reach people who are going through it, like I would just want to use Excel and like have a little bit of
14:39 code. Yeah. Conduit virtual environments, hip versions of Python. Yeah. You probably get a
14:46 couple of questions about that every now and then. Yeah. Yeah, exactly. I think that this is a really
14:54 cool example of, I guess, you know, the Jupyter devs realizing that distribution is one of the primary
14:59 problems here. And certainly with us, it's, it's like the primary bottleneck and users trying our product
15:04 is not, they can't figure out how to use it. It's that they can't even get the thing installed in the
15:07 first place. Yeah. You know, making that as easy as possible. I'm, you know, I'm sure there's still
15:11 work to do here, but, you know, really hats off to them and definitely something that we're
15:14 interested in and working with them in the future. If we don't already, there's probably some hack to do
15:18 it currently, but I have not, I've not done anything in earnest with Jupyter and lab desktop,
15:23 but I have installed it and run it. And I think it comes pre assembled with Python and Conda.
15:28 You don't have to have, it basically comes all set and it, then it just hosts Jupyter
15:33 lab locally inside of an electron app. So it might even be better for you guys.
15:38 Yeah. I'm not totally sure, but if you can make it work at all, I bet it's better.
15:41 I think what Nate is talking about is it's a trade-off that any tool or product building
15:45 as an extension to Python is going to face, especially if it's one that's trying to make
15:49 parts of data science more accessible to a newer audience. If you're building it in a
15:53 Jupyter environment, there's a lot of freebies you get. There's a lot of great nuggets,
15:56 valuable things to the user you get, but, you know, installation can be such a nightmare that you might
16:01 be casting away at certain part top of the funnel just by doing it.
16:05 One of the benefits, I guess, that you all will receive is people can go Google for help setting
16:11 up notebooks and getting the notebook started and all that. And you don't have to be part of that,
16:14 right? Like there's a whole ecosystem of, of people running notebooks, people writing articles
16:19 about using notebooks for beginners. And so you can just sort of level up on top of that and say,
16:24 once you go through all what they show you over here, here's how you go. Right. I mean,
16:28 obviously you want to help people succeed because if they can't get Jupyter going,
16:31 they can't use Mito. Yeah. I was creating documentation for getting set up with Mito and
16:35 I went to the JupyterLab documentation and first things like creating a new sheet,
16:39 I just grabbed the JupyterLab YouTube video and put it in our documentation free.
16:44 Well, that's one of the things I like about your documentation and your site is it's sprinkled
16:49 with screencasts, like little examples of how to do stuff or how to demonstrate stuff. And
16:54 I think more places should do that, right? There's so many places or so many projects that I just
17:00 don't understand though. It'll be a UI framework and there won't be a single picture of anything.
17:05 Like what it's about picture. The whole purpose is pictures. Give us a picture, at least it's like a
17:10 gallery or something. And similarly with how do you use things and just, yeah, you know, hats off to you
17:16 guys for putting those in there. Cause I think it makes a big difference.
17:19 Yeah. One of the reasons I think we've done that and had some, some good videos is just in terms of
17:23 just growing the tool, we've partnered with a lot of people in the YouTube data science community,
17:27 and they're all really good at making demos. I think we've learned a lot from them. People like
17:31 the data professor, Chris Nick, or two we work with a lot, but they've sort of, I think, I think at least
17:37 myself learned a lot from how to present a tool in a video. And that's obviously really valuable for,
17:42 for going to teach.
17:43 Yeah. I prefer to just fire up a two or three minute video and watch it instead of reading
17:47 through and see what I really got to pay attention to.
17:51 This portion of talk Python to me is brought to you by shortcut, formerly known as clubhouse.io.
17:56 Happy with your project management tool. Most tools are either too simple for a growing engineering team
18:01 to manage everything or way too complex for anyone to want to use them without constant prodding.
18:06 Shortcut is different though, because it's worse. No, wait, no, I mean, it's better.
18:10 Shortcut is project management built specifically for software teams. It's fast, intuitive, flexible,
18:16 powerful, and many other nice positive adjectives. Key features include team-based workflows.
18:22 Individual teams can use default workflows or customize them to match the way they work.
18:27 Org-wide goals and roadmaps. The work in these workflows is automatically tied into larger company
18:32 goals. It takes one click to move from a roadmap to a team's work to individual updates and back.
18:38 Type version control integration. Whether you use GitHub, GitLab, or Bitbucket,
18:43 Clubhouse ties directly into them so you can update progress from the command line.
18:47 Keyboard-friendly interface. The rest of Shortcut is just as friendly as their power bar,
18:52 allowing you to do virtually anything without touching your mouse. Throw that thing in the trash.
18:57 Iteration planning. Set weekly priorities and let Shortcut run the schedule for you with
19:03 accompanying burndown charts and other reporting. Give it a try over at talkpython.fm
19:08 slash shortcut. Again, that's talkpython.fm/shortcut. Choose shortcut because you shouldn't
19:16 have to project manage your project management.
19:18 JupyterLab Desktop is one of these sort of interesting things. Another one is JupyterLite,
19:25 which is Jupyter written in WebAssembly that runs just in the front end of the browser.
19:29 You guys check this thing out?
19:31 No, but this sounds amazing. I don't know if I saw the WebAssembly version, but I saw a Python
19:35 compiled to JS version of this, etc. But I mean, it would be very cool if everything could happen
19:41 in the browser because I feel like installation problems would evaporate, which is the goal.
19:46 It's the goal at the end of the day. So this is super interesting. We'll definitely check this out.
19:49 Yeah, this might also be relevant to you guys because it's basically Jupyter running and then they run
19:55 in-browser WebAssembly language kernels. So a limited set of CPython in WebAssembly in the browser and
20:03 probably also Julia and R and all those things.
20:04 Maybe partially non-technical audience like myself. What is the benefit here?
20:09 I'll take a shot. Yeah. So how I would describe this is that normally the way JupyterLab works is
20:14 that it's a client server model, right? So your client is effectively the thing that you as a user
20:19 interact with. You have a notebook that you see, you write code in the notebook, you press shift enter
20:23 to run a notebook cell. What actually happens when you press shift enter is that code gets sent to
20:28 the server. The server in this case is a Python kernel and the Python kernel actually runs that
20:33 code and then sends you back the results. So there's what you see on your web browser and then
20:37 there's a server running usually on your command line or something and you send code to it. It executes
20:42 the code and sends you the results. The benefit of this thing is that you can get rid of that backend.
20:45 So there's no more installation and instead you only need this kind of notebook that lives on the front
20:50 end, WebAssembly is a tool that allows us to run the code on the front end. And so instead of taking
20:56 code, sending it to the backend and getting it back, we can do that all in one location.
20:59 Right. And the challenges you've already been talking about are the challenge of setting up
21:02 that backend to get Python to run on your machine with the environments and the dependencies. And this
21:07 would theoretically in principle, at least avoid all that. It's just loaded up and it goes.
21:11 Yeah. It's super cool. No, we'll definitely, we'll definitely look into it because this is a,
21:14 I mean, this is an area of continual research for us is how to improve our installation process.
21:18 Yeah. Very cool. All right. What else have I pulled up here? A paper mill. So paper mill lets
21:22 you treat notebooks like almost like functions that you can execute a notebook and then get a value out
21:28 for all sorts of things. This is probably the least relevant to you guys, the things that I pulled up
21:33 here, because it's exactly about making it not interactive and, you know, kind of skipping that,
21:38 but just another interesting thing that people are doing to kind of add more or do more with these
21:43 notebooks. Yeah. It seems super cool. Now I was just going to say, I've seen people,
21:48 we've seen people who have notebooks where they like call functions in other notebooks and all of that
21:52 syntax, you know, the Panda syntax is confusing, but then like linking notebooks and all of that is
21:57 confusing as well. So I think it's all interesting. It's all interesting to see, you know, I think just
22:01 like spreadsheets have so many different use cases and Nate touched on this earlier. Notebooks have
22:05 an incredibly large number of different use cases with people from like top level data scientists to
22:10 people just getting started. So the tooling ecosystem that's being created and it already
22:15 existed really quite diverse and really powerful. Absolutely. All right. I think I've got one more
22:20 for you here. This might be the one that you heard of Nate called notebook JS. No, this one renders,
22:26 parses them and then renders it down to HTML, which is, I guess I don't have one to open, but that's
22:34 all right. So yeah, that's, that's pretty neat that it'll basically allow you to turn notebooks into
22:38 HTML. And I think just to kind of draw a categorization model over what we've kind of seen
22:43 before, I think there's, there's a couple areas of focus and these are things that we focus on
22:47 internally. And we, I think we'll deems that will come up throughout the rest of the conversation.
22:50 So there's things that we'll call, let's say presentation, right? And presentation is this
22:55 looking at the outputs here in the terminal or looking at the outputs easily on a webpage without
22:59 running a server, right? And presentation is something that we encounter. How do we present data?
23:03 how do we present conclusions from analysis, et cetera. Then there's another thing, which I think
23:07 this paper mill thing that we looked at last is super relevant on, which is this idea of repeatability,
23:13 right? As anyone who's worked in notebooks knows, there are really great areas for being a scratch pad.
23:18 It can get pretty confusing sometimes when you've got like all these cells flying around,
23:22 you're executing things out of order.
23:23 That's the thing, you know, we have sort of solved the Excel, this cell refers to that cell.
23:29 And then, but you have this human aspect of notebooks, right? I can go, I want to try this,
23:33 try this, try this, go back and change this and then run this and the stuff below it, you know,
23:38 you can run them in different orders and even change them and then have some of the invisible
23:42 changes stuck in another unrun cell. Yeah. That's yeah. That can be a problem.
23:47 I mean, Aaron and I spend all day in notebooks and the amount of times where I'll go up to Aaron and be
23:51 like, Aaron, dude, look at this, this code makes no sense. What is this bug? I don't understand it.
23:54 And Aaron's like, you fool. You've been one, three, four, not one, two, three. What were you thinking?
23:58 You know, like just the amount of times that even we as people use notebooks all day,
24:01 that is really, you know, it's dramatic. And so I think that, it's, you know, that area of
24:06 reproducibility and repeatability is something that we spend a lot of time thinking about mostly
24:10 because a lot of our users are really interested in it and it's problems that they struggle with.
24:13 And, it's something I think we'll definitely get into, you know, as we kind of, you know,
24:17 what we actually ended up building. Yeah. Awesome. So speaking, get into it. Let's,
24:20 let's talk about Mido. So I think Mido lives in this realm of these interesting ways to do more
24:27 with notebooks. And as we've already hinted at, you basically take an Excel user interface,
24:32 stick it into a notebook, and then allow people to interact with the data within the notebook
24:37 in Excel style way. Right. But what's your elevator pitch?
24:42 Oh, I can do elevator pitch. Elevator pitch. Essentially, it's a spreadsheet interface for Python.
24:47 So everything you do in the spreadsheet is going to generate the equivalent code for you in the code.
24:51 So below, if you're watching the video right now, you're seeing a little demo happen, but we have
24:55 features for exploratory data analysis. We have features for data wrangling, data munching. I've
25:00 heard lots of different words for that type of process. So yeah, there, and then graphing as well.
25:06 And also we have the ability to save and replay analysis sort of like a macro. And in terms of
25:11 users, you know, we have people who are newer to Python using it to sort of introduce themselves to
25:15 the Python world. They're learning as they go. But the nice thing is that they're not held back by the
25:19 syntax at any point. So you're not Googling syntax, not going to stack row of flow. You're in your
25:23 notebook the entire time, sort of staying in a state of flow. And then we also have more advanced Python
25:28 users and people intermediate in the middle using it just to get their analysis done more quickly.
25:32 It's really fast to do something usually, especially like the code for graphing or pivot tables or
25:37 merging. Take a lot of time to type it out and get the syntax right. So in our tool, you just do it
25:41 in an Excel interface that you're used to and it spits out the correct code for you.
25:45 Yeah, it's cool. People definitely need to see the little video. So if you haven't checked it out,
25:49 you know, obviously I'll put a couple of videos in the show notes, but yeah, that's the idea is you
25:54 come in and you just basically inside the notebook as part of the cell, you know, you might be familiar
26:00 with having an interactive widget for like some kind of graph, right? Where it's got like some
26:04 sliders and stuff. It's like that, but it's Excel ish. Right? Yeah, exactly. Was this your first idea or
26:10 where did this whole idea start? We've worked on a lot of different like spreadsheet related tools
26:15 over, I guess, a year and a half ago or two years, a long time ago at this point, we started building
26:22 like a GitHub for Excel. We're building essentially like, you know, difference detection,
26:27 allowing you to merge, going back to those original problems that we talked about that we experienced
26:32 at school. So we were building kind of this GitHub for Excel platform. We were primarily talking to
26:38 investment bankers and people in private equity and these like really Excel power users. We built the
26:44 tool. We've interacted with a lot of them, eventually realized that wasn't maybe the most
26:48 helpful space that we could be working in and ended up finding our way to this where it was more
26:54 Python based Jupyter notebooks and just making them more accessible. And as Jake said, you know,
26:58 helping people across the spectrum from beginners to more advanced data analysts, get their analysis
27:04 done faster. Sure. I think there's two angles here. One is just, you could be really fast, right?
27:08 You could say, okay, I want to do, I see the data. I want to sort by this. Now I want to drop these
27:13 three columns and then I want to, you know, compute a, do a computer column of sort of thing,
27:18 or maybe join two pieces of data, like two data frames and create like a larger one out of that
27:25 and so on. You could be really quick with that. But I think maybe even more important to that is
27:30 helping people who are just stepping into the data science side of the world, right? They've,
27:35 they've been working in some other tools or no tools whatsoever, really. And then they just,
27:39 they hear, oh, I should go do Python and I should do notebooks. And then they're confronted
27:43 with pandas, which pandas is great and it's not that hard to use, but there's a zillion things
27:48 you can do with pandas and it's not super discoverable. What it is you should choose.
27:53 And also the notebooks don't really help as much as they could. I think it presenting
27:57 the features of an API, right? Like if I'm working in PyCharm or VS Code and I say dot,
28:04 like, boom, there's a bunch of descriptions. And if I get the mouse near it, it'll give me like
28:07 examples and documentation. And here it just lets you type unless you hit, you know, dot tab,
28:12 and you explicitly asked for it. And a lot of people don't, I suspect if they're coming from
28:16 economics, they don't know that, oh, like tab has this magic to show me what I can do and stuff like
28:21 that. Right.
28:21 Those people making the transition to the notebook environment are doing so at a, along a spectrum
28:27 of willingness as well. Some people are doing it because they're really excited about, you know,
28:31 up-leveling their skills, learning Python, making their analysis faster. And then some people are doing
28:37 it because, you know, upper level management wants me to do that. And I think those people are,
28:42 really grateful for having a tool that will help them, you know, meet the workflow requirements that
28:46 they're working in, but not necessarily having to, you know, I'm sure you've read at some point the
28:52 Pandas documentation. And it's, it's one of those that it has lots of great examples in fairness,
28:56 but no pictures. Yeah. It's not the most intuitive.
28:59 Probably not a lot of tutorial videos in there.
29:01 Yeah. So, I would add a sort of a third category to what Aaron was saying, which is like, it's, it's people not
29:07 forced by management, but it's not sort of out of their own interest in Python. It's more so they're just sort of
29:12 forced to, based on what they're trying to accomplish. If they have a certain data set of a certain size, you simply can't do it
29:18 in Excel or Google sheets. So there, I need a medium that's going to allow me to facilitate data analysis on this scale.
29:23 And it'd be really frustrating if you're thrown into pandas to do that and you have to spend all your time.
29:28 So it's kind of doing simple things that you're so used to doing in Excel, like adding columns, doing pivot tables,
29:32 whatever it is, using formulas. And now you're spending a new set of your time going through syntax and making sure that you're
29:37 typing out and capitalizing the right letters in a, in a, in a white code. That can be really frustrating. So our tools really
29:42 trying to allow you to stay focused on the actual analysis the entire time and less about getting your code.
29:48 And many people are Excel literate. Right. And so it kind of leverage that a little bit.
29:52 Yeah. And then for, you know, people who aren't even coming from Excel, but are just data scientists, they're a word. It's not, not Excel
29:58 literate, but they're sort of like visual literate. That's a horrible phrase, but what it means essentially is that they
30:03 understand how to do this. They understand, okay, these are the things I need to do it. Here are the butts. Do it here.
30:07 The options I could use. So it's still a really valuable environment for everyone, Excel or Python.
30:12 Nice. So question from the audience out there's phone says, hello, what are the limitations of Mito?
30:18 That's a great question. I think the honest answer is that Mito is certainly a work in progress and
30:23 there's a large portion of pandas functionality that we don't currently support. So kind of, I think a
30:29 helpful context here is how we're actually developing this tool. So Mito is very much, I would say a
30:34 collaboration with our users. And what that practically means is that join our discord,
30:37 there's a feature request channel and anyone has the ability to show up and essentially say, Hey,
30:41 this is missing from my workflow. And we'll say, Oh, that's on a roadmap or, Oh, that wasn't on a
30:46 roadmap. We'll add that or help us engage with your workflow and understand where that's coming from.
30:49 But essentially what's happening is over the past six to eight to nine months or so, we've been working
30:54 really heavily with our users to kind of build out the core pieces of pandas functionality that most of
30:58 our users work with one by one and kind of investing their workflows back into the tool.
31:03 Yeah. Which way do you take it? Do you go and say, all right, these are the things people need
31:07 to do in Pandas. How do we surface that in our interface? Or do you say, these are the Excel type
31:12 things people are happy with? How do I make that happen? And it's like, which direction do you find
31:17 yourself going?
31:18 It's a really great question. And Aaron, you can definitely speak to this more because this is
31:21 kind of part of our process internally that's been evolving, but really kind of what we try and do
31:26 at this point is we try and, we try and work very heavily with our users to understand, you know,
31:30 at the highest of levels, what are they trying to accomplish? Right? Someone really isn't usually
31:34 trying to make a pivot table. Usually what they're trying to do is conclude, should I tell a salesperson
31:40 to do X or Y?
31:40 What state are we spending, getting the most sales in? And all I have is zip codes or something
31:45 like that.
31:45 Exactly. Exactly. Right. There's really a lot of people that we work with and this isn't the only
31:49 thing, but one of the things, for example, is they're operating the level of, I'm looking to
31:52 predict this feature or understand what affects this, this piece of my data. And so what we do is we kind
31:57 of work with them to understand their workflow. And then we use that to internally figure out,
32:01 you know, what features drive this, what does Pandas support and how can we provide an interface
32:06 on that that really lets people, you know, get this done as quickly as possible in a way that gives
32:09 them as much flexibility at the end of the day, if they need to take this from Mito and
32:13 and go run with the code somewhere else.
32:14 Yeah.
32:14 Yeah.
32:14 And Eric, go for it.
32:16 Eric, go for it.
32:17 I was going to say, I feel like in the beginning, kind of when they were saying, we were very focused
32:22 on let's put Excel into Python. And it was like more about the Excel functionality. But I think over
32:27 time we've come to think more about the questions more, what is the best visual interface for Python,
32:33 for data science? And it's less so. And so some of those things are from Excel. Some of those things are
32:37 our own creations. It's still a spreadsheet interface, but the goal is certainly not to take
32:43 Microsoft Excel and give you all of that Python.
32:45 Interesting. Yeah. Cool. All right. I think maybe a good way to understand this, how this workflow
32:51 works and get a peek inside of the features is over here somewhere, I think in the documentation side of
32:59 things you've got, yeah, right at the beginning here, quick tutorial here, you've got this sort of,
33:04 I don't know, I'm not bouncing around, I'm not finding it quite where it was to tell you, but
33:08 there's this example where you go and load up a couple of CSV files and then like join them to
33:13 create a pivot table and stuff on that, like that. Maybe give us a talk through what working with that
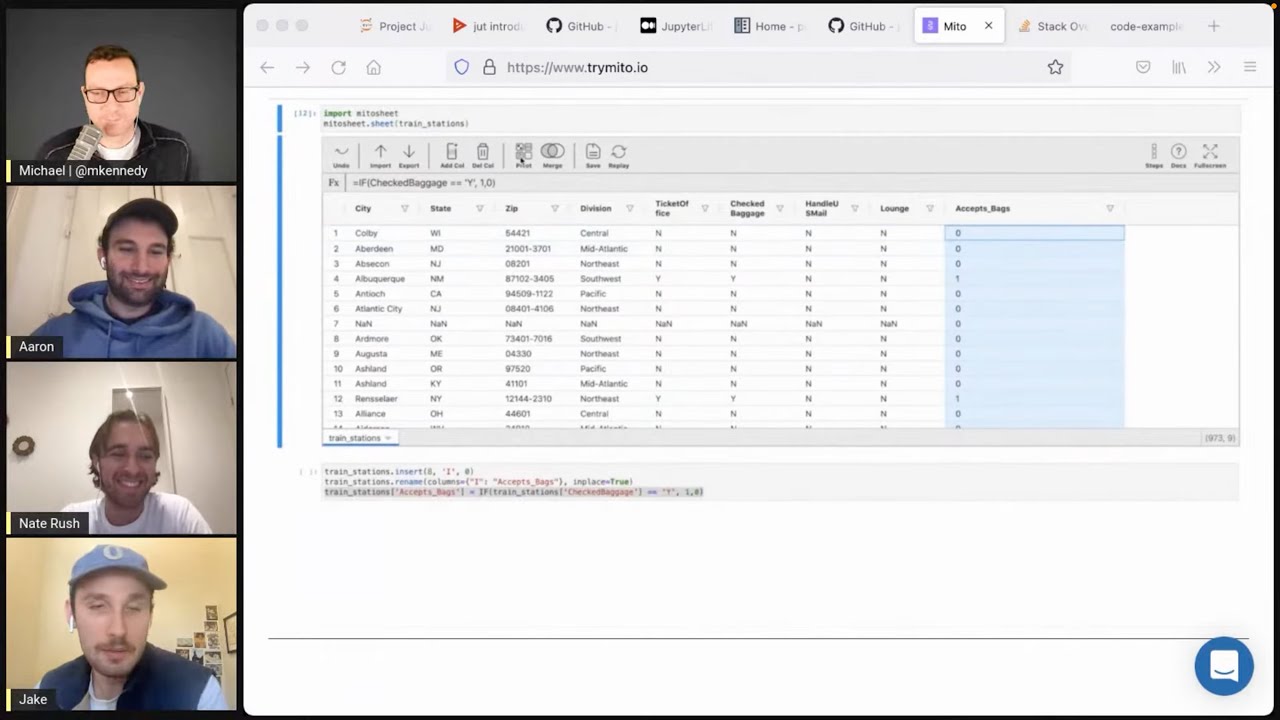
33:18 data flow kind of looks like. You know, I talked about this idea of like turning zip codes into states
33:23 and that kind of stuff. What does work with Mito feel like? Give us a sense.
33:27 I can talk a little about that. So I think working with Mito feels hopefully very fast and very
33:32 intuitive, or I think two of the things and maybe robust or maybe like the three kind of things we
33:37 strive for. I think in terms of workflows that we see people doing, a lot of people kind of fit this
33:43 like feature creator and automator use case that we think about. So it's people that have some business
33:50 sort of question like where are all my sales coming from when I just have these zip codes.
33:54 And they're probably trying to do that in Python because they've been doing it in Excel over and
34:00 over again each month and they're looking for a more robust and more automatic way of doing that.
34:05 So I think a lot of, a lot of how, a lot of the ways that we see these workflows play out is people
34:11 either have a CSV file or they have like a snowflake connection to get some data. And then they start by
34:18 doing some simple EDA and trying to get a better sense of what their data actually looks like.
34:23 Right. Without Mito, it might be something like df.head or df.sample and just like kind of get a
34:29 visual look of a grid of data, right?
34:30 Exactly. Or even some people are, they want the more visual interface. So they're downloading it to
34:36 Excel initially and doing some manipulations or something like that there. But then that workflow is
34:42 very separate from their more automatic script that they're creating. And then they have to kind of
34:47 reconcile any changes that they've made back into the Python workflow. But yeah, so Mito has a bunch of
34:53 features. There's some here, you know, if you scroll down in the documentation on this left-hand side,
34:57 you might see some stuff that might be helpful. So there's things like summary stats right there,
35:02 which will show you like a graph, a distribution of the data in each column, a lot of those dot
35:08 describe functions and has a really intuitive filtering. So things like filter by value. So you
35:12 can see all the, all the unique values in your column, and then you can toggle them in and out of your data
35:18 set, or you can add more, you know, customized filters, whichever you would like. But then once you
35:23 move past this kind of like initial data cleaning, some people do write spreadsheet formulas. So we
35:28 have a bunch of Excel's most popular formulas, things like date manipulation and date parsing.
35:34 Here's a bunch of, here's a few of them. Once you kind of get a sense of what your data looks like,
35:39 you can do some of these transformations. And then ultimately you'll end up with this script that you can
35:44 use to run over and over again and never have to go back into the Excel world to and fight through the
35:49 manual process again. This portion of Talk Python To Me is sponsored by Linode. Cut your cloud bills in
35:57 half with Linode's Linux virtual machines. Develop, deploy, and scale your modern applications faster
36:03 and easier. Whether you're developing a personal project or managing larger workloads, you deserve
36:08 simple, affordable, and accessible cloud computing solutions. Get started on Linode today with $100 in
36:14 free credit for listeners of Talk Python. You can find all the details over at talkpython.fm,
36:19 slash Linode. Linode has data centers around the world with the same simple and consistent pricing,
36:26 regardless of location. Choose the data center that's nearest to you. You also receive 24/7/365
36:34 human support with no tiers or handoffs, regardless of your plan size. Imagine that real human support
36:39 for everyone. You can choose shared or dedicated compute instances, or you can use your $100 in credit on
36:46 S3 compatible object storage, managed Kubernetes clusters, and more. If it runs on Linux, it runs
36:52 on Linode. Visit talkpython.fm and click the create free account button to get started. You can also
36:58 find the link right in your podcast player show notes. Thank you to Linode for supporting Talk Python.
37:04 "The DataFrame" to get data into this spreadsheet-like front-end that is Mido.
37:10 You basically just have to have a data frame. If you have a data frame, there's a ton of flexibility for
37:16 doing that. You could load a file, you could get it from the internet, you could do even read HTML off of
37:24 a URL and then go grab a table and then there's your data frame, work with that. There are simplifications,
37:31 things like when you're in Mido, you can hit file load equivalent and browse to the files and then it'll
37:37 write the pandas code, say like pd.readcsv, whatever you selected, right?
37:42 Yeah, exactly. One of the things I think would be really interesting to talk with you about is
37:47 generally in your survey of the Python ecosystem, it's interesting because Python is code, right?
37:53 And so in some ways we're on this boundary, this flexible border between pure code and low-code,
38:01 no-code tool. And there's been a hundred million low-code, no-code tools that have existed over the
38:05 past 25, 30 years, whatever. And some of them are around and some of them aren't. And really the
38:09 question for us that we kind of ask ourselves is, what unique do we bring to the table here? And as a
38:14 local tool, how do we differentiate ourselves? And it's that exact idea that you can also just pass a
38:19 data frame. We're not necessarily interested in, we don't want to stop you from writing Python code,
38:23 we want to enable you to write Python code as easily as you possibly can. And really that's
38:26 how we see ourselves, you know, manning that spectrum.
38:29 I think it's a really good place to be because my hesitation with all these low-code, no-code tools
38:35 is they usually, one, lock you into their thing, which is often a SaaS thing, right? So you're locked
38:42 into having your data there and continuing to subscribe to a thing, which don't get me started
38:47 on subscribing to so many things. I was suggested that I subscribe to my internet speed checker,
38:53 app, not pay for it.
38:55 You need to know, but like...
38:56 Once an hour, you need to check, right?
38:57 Yeah, yearly, I can subscribe to it. If I pay yearly for my speed checker, like,
39:02 what are you doing? Too many things that are subscribed to. Anyway, not that subscriptions
39:07 don't make sense for a lot of tools. But what I like about this is, like you said, you bring the
39:12 data from wherever and you could do this out of a Postgres database and you build up a data frame,
39:17 and then you could throw into this visual place that speeds you up. And then what comes out the
39:21 other end are more data frames, right? So you could even do multiple, I mean, maybe tell me this is
39:26 true. It seems like you could. You could do some regular Python code, some Mito that generates a
39:32 really interesting transformation, some more Python code, and then maybe another Mito block that takes
39:37 another bit of output and then brings in more data, does other stuff, right? You can kind of mix and match
39:41 throughout these, right? Throughout the notebook? Yeah, exactly. And actually, the other day, we
39:45 went into GitHub and we searched Mito sheet to see how people are using it. And you see people using
39:50 it in that exact way where they're importing data, they then generate some code using Mito. And then
39:55 they'll, you know, one of the things, admittedly, that the tool is maybe not the best that right now
39:59 is graphing. We have, you know, we support creating basic graphs, but not changing the colors,
40:05 changing the titles, all of that. What UI frameworks do you support? Map, Plotlib?
40:10 We use Plotlib. We use Plotlib. Okay. Yeah. We generate Plotlib code, which has great documentation. It's really, you know, you can go in there, we give you a link,
40:18 and you can go in and make your edits. But this is one of those places where generating Python code,
40:22 and you know, in this case, Plotlib code is super helpful for everybody involved. For us,
40:27 it's helpful because, you know, we didn't have to recreate the Plotlib library, which is massive.
40:31 But for everybody else, it's also helpful because, you know, because we didn't generate the Plotlib,
40:36 we didn't recreate the Plotlib library. You are able to use, you know, the entire Plotlib ecosystem,
40:41 and you're not locked in at all. So for something like Alteryx, you know, where you can use their
40:47 graphing features, and if, you know, they don't have the graphs that you want to create, then you're kind
40:51 of out of luck because you're locked in, and there's not really an easy customizability path.
40:56 But you own your Python code that Mito generates. So it's up to you to do whatever you want.
41:00 Yeah, I suspect you guys don't recommend this. But you technically could delete out,
41:05 in a lot of cases, the Mito bits after you generate your Python code and keep going like,
41:10 okay, this was really helpful, but we actually don't need this anymore. There are cases where some of the
41:15 Excel-like functions really come from you guys, right? But a lot of it is what it's writing is pandas,
41:20 and NumPy and Plotly code, right? Just speaking to the lock-in or not the lock-in side of the story,
41:27 right? Yeah, I think we definitely support that. In Mito, actually, we have a button clear.
41:32 Data analysis is all about, it's very iterative, building your understanding of what is useful and
41:38 where you want to go. So one of the, actually, the most kindly done things in the tool is actually
41:43 clearing all of the edits that you've made to your analysis. And getting rid of Mito now that you have
41:47 that understanding and wanting to take it in another direction, I think we're huge supporters,
41:51 well, we're big supporters in our own development process of cleaning your workspace. Nate is proud
41:56 of how clean our code is. And, you know, if Mito isn't helpful for you right now, definitely get rid
42:01 of it so you have an easy notebook to clean up and debug. Yeah, I think that's a big contrast going to
42:07 some other no-code SaaS system. There is no, I don't want to use this exactly anymore, just let me carry
42:13 on with my analysis. There's none of that in most of these tools. And with yours, I think it's there to
42:18 support you and I can see it being incredibly valuable. But at the same time, it's not the
42:22 essence of what you're doing. It's the UI on top of Python, as Jake likes to say. Yeah, I was just going to
42:27 say to the point of deleting out the Mito sheets, we have a society of secret Mito users who are trying to
42:33 convince their bosses that they're really good at Python to get pay raises. So we support that workflow very,
42:39 very well. Exactly. So one of the challenges that you can have when you have a machine write code
42:44 is that it writes bad code that's hard to understand. And Nate, it sounds like you might have had some
42:50 input on this, that when you interact with Mito, you do certain operations. Like I do a filter,
42:57 I create a pivot table, or I filter out certain things. It'll actually write step one, you did this,
43:02 step two, you did that. And it writes what looks like pretty well formatted Python code with little
43:07 bits of documentation, like pivot the table, reset the column name and indexes and stuff like it'll
43:11 even comment your code that it writes. You want to speak to that a little?
43:14 Yeah, absolutely. I mean, this is a really interesting area that we've put a bunch of
43:19 research time in, if you can call it that. So there's a couple things that I want to,
43:22 I think, highlight here. And I'd love to also hear your thoughts on as well. So you're totally right.
43:26 Machines writing code, it's all the rage these days, in some ways, with these fancy,
43:30 you know, machine learning systems where you can, you know, write a little prompt and everything will get
43:34 written for you. Mito takes a little bit of a different approach where exactly as you say,
43:37 when you, for example, add a filter, it'll generate the line of code that corresponds to that filter.
43:41 Of course, immediately, the question becomes, this is not exactly how I want the code to be.
43:46 I didn't mean to do that. I meant to do something else. And so really, the way we think about it is
43:51 giving the user that code in the cleanest way that we possibly can. So just as an example of this,
43:56 if the user adds a column, and then immediately after renames that column, a feature that we're actually
44:00 releasing this week is that is going to get collapsed into just the adding of the column with the new name.
44:03 Right? Nice. Yeah.
44:04 That's ultimately what the user was intending to do. There's other more fancy things that you can do.
44:08 You can start getting into kind of code optimization, where it's like, you made a pivot table, then you
44:13 overwrote the pivot table. And those are all things that we're definitely interested in, and kind of are
44:17 on the roadmap for improving. But generally, you're totally right. If we want users to be able to learn
44:22 from this code, to be able to use this code, we need to generate clean semantic Python that really
44:27 works in the wild and is actually editable by the users. Otherwise, it's just a blob,
44:31 a mass that you can actually interact with.
44:33 Yeah, well, you get it, but at least from the examples I've seen, I would be happy to take that
44:37 and then start writing directly on that. Even though you don't see it on the screen,
44:41 it's like right above, I scrolled it right a little bit off there. But it says, don't edit this section.
44:45 This is Mido code. I guess that's if you still want to be able to use Mido on it.
44:49 Right. You know, exactly. Don't mess it up, right?
44:51 We're actually, that's a feature we're working on this week is improving that communication. You can
44:56 take Mido code and edit it and change it however you want. The only problem is Mido might have
45:00 trouble reinterpreting that if you try and then later replay an analysis. But that's also a work
45:04 in progress. And ideally, you know, the kind of perfect version of what we, you know, envision
45:09 long term, and maybe we'll get there. Maybe this is impossible. But one really cool thing that
45:13 we're kind of thinking about is edit a spreadsheet to generate Python.
45:17 Yeah, I was thinking if this could be a bi directional, that'd be fantastic.
45:21 Yeah, really cool. So really, it's this world where you're you're really fluidly writing code
45:25 and editing a spreadsheet. And if something's easier in code, go write the code. If something's easier
45:29 in the spreadsheet, go write the spreadsheet. And that's definitely a vision that we've seen
45:31 ourselves kind of realizing over time currently. And something that, as you mentioned, you can go
45:35 Mido Python, Mido Python and do that currently. But making that easier for our users to really use the
45:41 code in a dynamic and real way, as you would any other Python code that you write is definitely
45:45 something that we're actively investing in right now and really trying to improve.
45:48 Nice. Yeah, I like the idea of being able to have it do some optimizations rather than create a
45:53 variable and then overwrite the variable with some other thing and just do it all at once. I'm sure
45:58 there's a ton of stuff in pandas that could be done better rather than like a really naive,
46:03 straightforward, like multi step stage.
46:05 Yeah. And yet the other thing I will say is the one benefit actually to generating this code is that
46:11 and not to insult anyone because I'm the biggest offender of this, but most data science scripts you
46:15 see in the wild are not the like pinnacle of clean, well-kept code. It's usually out of order notebooks
46:21 where, you know, because it's such a dynamic process, it's just very hard in practice to keep
46:25 these things well organized. And so actually what we can do in practice is generate some documentation
46:30 for what's happening and help users save and manage these scripts in a more linear and organized way,
46:35 et cetera, and help users kind of adopt these best practices. And that's sort of the stuff that we've,
46:39 you know, we've been exploring recently and Aaron was actually working on some of this today,
46:43 improving some of this code generation stuff, but it's not the highest of bars to meet. And we
46:47 definitely think that we can, you know, continue to improve and surpass that and make sure that the
46:50 code we're generating is really great, great stuff and stuff you'd be happy to edit.
46:53 One thing that while I'm looking at this, I'll just throw this out of here as a piece of feedback with very
46:57 little actual experience. So take it with a grain of salt is you've got like step one,
47:02 step two, step three. It'd be cool if those were actually separate cells.
47:05 So like at the end of say step three, I could do like a pivot table dot head or something just to
47:09 like sort of touch on it and explore it a little bit along there.
47:13 Yeah, no, definitely. And a similar thing that we've also certainly thought of that that
47:17 multi-cell approach would enable is, you know, changing the order of steps, switching things
47:21 around and saying, oh, I actually want to filter first and then pivot versus pivoting and then
47:24 filtering. Yeah, certainly on the roadmap, but definitely, definitely something we
47:27 want to do, giving users more options on how they actually export this code and what they
47:31 do with it at the end.
47:32 Yeah, super neat. I've got a question out here that kind of leads into where I was going to
47:35 go with this anyway, and I'm going to switch the order so I don't cover your head, Jake.
47:39 Spawn also asked, does Mito support switching or you switching from or to or using Dask?
47:47 So, gotcha.
47:48 Yeah, not currently. No. So the one really cool thing is because of the Mito, the way Mito works
47:53 internally, which is something we can definitely get into depending on, you know, if you're,
47:56 you think your audience would be interested in it, what the appetite is. But we really have the
47:59 ability to kind of switch out, let's say, what the backends is of Mito, the kind of what code
48:06 do we actually end up generating is something that can we can leave up in the air. And really,
48:09 our interface can be a more general thing than just Python code or just pandas in Python code.
48:14 Yeah, especially for these frameworks that are near compatible, API compatible with pandas,
48:19 like Dask.
48:20 Like I think Dask is almost exactly, and many, for most of the basic operations,
48:24 it's, they've aligned on the pandas UI just, or the pandas, the pandas API just for, you know,
48:29 how to kind of handle things. So it's definitely something that in the future we could, you know,
48:33 we could support. And if we have users who are working with huge data sets and need Dask,
48:37 that it's definitely something we'd be interested in learning about and exploring.
48:40 You know, Dask, when I first think of Dask, I think large clusters, massively scaled out data.
48:46 But then at the same time, right over here, I have my MacBook Pro Max, which has, you know,
48:52 10 cores on it. And when I run Python code, I get 10% of that CPU, right? And Dask will allow you to
48:59 scale across your CPUs, even on your local machine, right, or scale larger than your memory and stuff.
49:04 And so I feel like it's Dask, even for just making your local work go better, is actually
49:09 probably under realized or under utilized. That's super cool. It's interesting that the range of
49:14 data set sizes that we actually see in practice, it's very, I would say, at least from my observations,
49:19 and Aaron, Jake, feel free to hop on this, but it's like very bimodal and that there's a lot of people
49:22 hanging out with 100,000 rows. And then there's some people are like, hey, I have, you know,
49:26 a hundred million records I'm looking to analyze. And we're like, well, you know,
49:29 good luck on your 2000 fall MacBook. You know what I got? It's going to take a bit.
49:34 Get a coffee.
49:36 Chill out, go to sleep, wake up tomorrow, hope it hasn't crashed, I think is the general strategy.
49:40 Yeah. So that does lead me towards my final two little areas I want to speak about before
49:45 we run out of time here. Now, on one hand, this is just writing Python code. So its performance and
49:51 its limitations are what effectively pandas can deal with. On the other, it is showing that stuff and
49:57 allowing you to sort it visually. So there might be some constraints on like amount of data you can
50:01 work with. What's the data size story?
50:04 It's a great question. We have a release coming out within the next two weeks. Generally,
50:09 but here's our, here's our motto. We obviously we're providing a visual interface. There's going
50:13 to be a little bit of overhead, but the way we like to think about what we do is that it's a tiny
50:18 little bit of flat overhead, no matter how big your data is.
50:21 Okay. For example, you won't try to show the entire hundred million rows in a grid or like
50:25 you'll do some sort of like virtual lazy load list or something like that.
50:29 Exactly. A lazy load list. And we actually have a lazy load of the entire data set. That's a
50:33 feature coming out within the next two weeks or so. It's all written. We just got to test it a bit
50:37 better in the wild. But yeah, effectively, it's, we're a very thin wrapper on top of pandas
50:42 functionality. And in practice, what that means, what that means is anything you can do in pandas,
50:46 you should be able to do in Mito from a data set size perspective. It's something that was
50:50 very important to us, especially because a lot of our users are in Python because of data set
50:53 size limitations in the first place. As I think Jake mentioned. Yeah. Yeah. Yeah. That's a good
50:57 point. This is something that we'd spent a lot of time. We were previously using AG grid as our
51:01 actual display unit. And it just wasn't made in combination of probably us not implementing it 100%
51:08 how they might implement it. And you know, them not optimizing for these ginormous data sense,
51:13 data sets. Nate in particular just spent a huge amount of time recreating the entire grid from
51:19 scratch. So we could have complete customizability over it and show as much as much data as possible.
51:24 Nice. I mean, sometimes you got to do that, right? You're like this, this control is amazing,
51:28 but we've outgrown it and bite the bullet and just do it right. Exactly. Yeah. Now,
51:33 interesting question from Samir out there. Hey Samir, can I use Mito and VS Code and I'll sort of
51:39 expand to that just a little bit. Can I use it in, in some of these other tools that are not exactly
51:44 notebooks. So we've got VS Code has its kind of own way of presenting and showing notebooks. We've got
51:50 PyCharm and we've got data spell, which is JetBrains new data science IDE thing. What's the story with
51:57 these environments? So unfortunately right now, Mito only works in future lab, but this question is
52:04 something that comes up all the time. We, I think the places we hear the most interest are VS Code and
52:08 Google Colab. And we're definitely excited and really going to support those environments as well. And I
52:14 think we've, we've done a lot of work internally on how we design, how we design Mito to make it
52:18 extendable. It's now, you know, we have a lot of these like functionality that we're trying to pack
52:23 into the tool and then handling these new environments as, you know, a decent amount of development work as
52:28 well. So it's all a prioritization game at this point. Yeah, of course. Yeah. So short answer is we
52:33 don't support them now, but in the future we definitely will. Cool. All right. Two other areas quickly I want to
52:38 touch on. One, tell us a little bit about how this is implemented internally. I think it, I don't know
52:43 how it's implemented, but I'm, I'm guessing that it's somewhat like a lot of Jupyter stuff. Like I
52:48 want to do Jupyter things for Python, but I got to write them in JavaScript. Is that the story here as
52:52 well? You know, actually your earlier comment of, I imagine it's just like a slidey widget that you can
52:58 use in a graph in JupyterLab was spot on. The IPy interactive widget or whatever it's called?
53:02 We are actually just a very fancy IPy interactive widget. Okay. And practice how that actually works
53:07 for your audience. If they're interested is there's kind of two pieces to your code base. There's a
53:11 JavaScript front end and there's a Python backend. The JavaScript front end is the sheet that you see.
53:16 It's the buttons that you click. And what that actually does is it just, it's a very thin wrapper
53:20 that just then sends a message to this Mito sheet Python package in the back and says, Hey, I just
53:25 clicked this add column button. You should add a column, excuse me, to this data frame. And then that
53:30 Python processes that message and then responds to the front end and says, okay, great. Display the new data
53:34 frame and also write this code to the cell below. And that's kind of the high level of what happens
53:39 there. It gets, you know, as you can say, more complex than the nitty gritty. We're in practice.
53:43 We're a react code base. We use TypeScript because we like strong typing and we kind of hate Python's
53:47 weak typing. But do you use type annotations on your Python side? We are gradually adding them to our
53:53 code base. We don't currently type check. Actually, we mostly use them as like IDE support to make
53:57 things easier. That's the main thing I use them for as well, because a lot of times the
54:00 IDEs will show you the errors if you make them anyway, right?
54:04 Yeah. Yeah. No, you definitely, you get some support, but pandas, I'll say pandas typing
54:08 support. Obviously pandas is the main library we interact with. It's not perfect in all cases. It's
54:12 a very complex library, so for sure. But effectively in those cases, things kind of break down and the
54:17 errors that you get are maybe sometimes false positives, sometimes false negatives, and you can
54:21 shoot yourself in the foot sometimes. Yeah. Interesting. Okay. So it's a blend. It's
54:24 it's the JavaScript, React, TypeScript, front end, and then Python back end. Yep. Yeah, exactly.
54:29 That question of that, let's say that stratification in that architecture is that's exactly what's going
54:34 to have to evolve as we kind of move into other places like Google Colab, VS Code, etc. They all
54:39 have slightly different extension architectures. And so architecting our code bases, so these things are
54:43 separatable and reconfigurable and in the ways that other data science environments expect is something
54:50 that we've kind of been trying to do. But you know, a plea to everyone who's developing data
54:54 science IDEs, settle on one extension environment, please. I know it's never going to happen, but it'd
54:59 be really nice for us extension developers. We'd love it for sure. Right. Or making it an adapter.
55:03 Yeah. Right. If somebody created things that if you have a Jupyter UI and you want to put in
55:08 Google Colab, you just insert this thing and talk to it and then magic happens. Yeah. Shims when they work
55:14 are great. So if someone's done that, let us know. Please reach out and we'd really appreciate it.
55:17 Yeah. Yeah. Super cool. All right. Another thing I do want to make sure that we touch on a little bit
55:22 is up here at the top, I see plans. And so this is not for every possible use case of free tool,
55:30 right? You have a free version and you have a higher order paid version for teams, if I'm
55:35 understanding that correctly. Right. So we have, my tool is a free 3D tool. We have free users,
55:40 90 whatever percent of our users are for free to an end user. Please download it. You know,
55:44 you can, you can pivot solve and it's free. We work with some larger organizations in sort of more
55:50 of a scope manner doing cost of development, cost integration. And those are the payment happening
55:56 there. Sometimes it's some of those larger enterprises. What we're building out now is
55:59 sort of that middle piece where we, you know, we want to have sort of a plan for teams, maybe with better
56:03 security, some free development hours, things like that. And that business model is evolving, but we'll
56:09 probably be, what we want is a SaaS model there where you're paying, you know, 10 bucks a month
56:13 or something. It does seem like some kind of online system. I mean, you go to Jupyter through a browser
56:20 anyway, some kind of system that's like really already configured because you're helping people come into
56:24 Python who probably don't totally want to pip install and manage their path and activate virtual
56:30 environments and all those kinds of things. Yeah. Yeah. It's kind of like really helped them there.
56:34 Right? Totally. And that's one of the things we do when we work with some of these larger enterprises is
56:37 help them with the setup of their Drupal Hub environment, help them get the package they
56:40 need, help them get my to install, obviously. But I was going to say to your viewers, you know,
56:44 we're definitely looking to partner with more organizations or teams. If anyone wants to reach
56:47 out and make my email or something, we'll be in a link somewhere. Yeah. Yeah. We'll put your
56:52 contact information in the show notes. Sounds good. But yeah, we're definitely, you know,
56:55 we're looking to work with teams right now as we have a really good, really strong user base.
56:58 Yeah. Cool. Cool. So I'm glad that you guys have some kind of business model because a lot of
57:02 these things, they come and then people kind of lose interest and then they go. And there's a
57:07 real big difference of this is my job and my investment. So I'm really going to work on it
57:11 versus this is a thing I'm kind of excited about for a few months. So it's cool. You got a free plan
57:16 for people to use that. That's awesome. It's also cool that there's a path to support to just make it
57:21 better. Yeah. Yeah. We're here for the long haul and works out. The other thing I'll add here is it's,
57:25 and I know I mean this on a knock on the like hundreds of amazing data tools that are out there, but
57:30 there's, I think like this level of polish that we really feel a desire to reach with our tool.
57:36 It's like that, that kind of when you're delivering a tool to a paying customer, there's often a
57:40 different expectation that comes from the paying customer. And we do our very best to hold ourselves
57:44 to the highest standard possible. But when someone who's paying you reaches out and says, Hey, this
57:48 button doesn't look the way it should. That extra level of polish really kind of kicks the tool over
57:52 the edge. And all of those, all of that feature development ends up getting, you know,
57:55 pushbacks to the individual users. And so really the free users I'll say, and you know, most of the
58:00 people who use our tool. And so really, you know, we're trying to build the best tool that we can here
58:03 and making sure that we can do that sustainably long-term and really invest in, you know, what
58:08 we're doing and build a team around it is something that, you know, really is necessary if we're going to
58:11 deliver on what we think we can and the promise. Yeah. Cool. Another nice thing about the paying users
58:17 is just that we get to, we need to work in a much more close relationship with them. So there's a lot,
58:21 that's where we get to zone in on like specific use cases around financial services or around
58:27 bio research. So we've come to work on specific features and specific workloads that we definitely
58:31 wouldn't otherwise that I think made inspire going to really benefit everyone uses the tool.
58:35 Yeah. Yeah. Very cool. I'm fascinated with the different ways people are working and operating in
58:40 open source space or building on top of open source tools to create businesses. You know,
58:44 we've got the Anacondas, we've got the MongoDBs and stuff out there. So yeah, good,
58:49 good luck to you guys. I'd like to see you succeed here.
58:51 Yeah. Thanks so much. And then the last thing I'll say is, you know, we do our best to give back to
58:56 open source tools as well, especially the ones that we work on. So you'll see me sometimes being
59:01 annoying opening issues on GitHub. And I think that's another big piece of this is as we build
59:04 on open source tools, making sure we contribute back to them in ways that are meaningful and actually
59:08 helpful is, you know, certainly really important as well. And definitely something to say something.
59:12 Yeah. Fantastic.
59:13 All right. Well, I think that's about it for the time that we have to talk about extending notebooks and
59:19 Mido and all this really cool stuff that you all built. Before I let you out of here,
59:22 there's the final two questions, however many in what order and whatnot, you want to take this,
59:26 just jump on in notable PI PI package out there, something you've come across like,
59:30 oh, this library is awesome. It doesn't get enough attention. Anything come to mind?
59:34 Mido and Mido: Yes. Honestly, something that a lot of our users use and Jake,
59:37 actually feel free to hop in after me, but I would say a pandas profiling. It's a tool that does somewhat
59:41 similar stuff to us, but it's a super great tool for many of our users. And I don't think a ton of
59:45 people know about it. And it works right in JupyterLab as well. So it's called Lux, which is cool. I don't
59:49 even know if it's actually still being supported and developed at all, but I really love it.
59:53 LogTrestles. You look up Lux Python. It's cool. It does like automatic graph suggestions. So you
01:00:00 can pass in a data frame and it'll suggest sort of give you options of visualization to just click
01:00:04 on and use, which I think is a really quick thing. It's not the most like, why fully fledged package,
01:00:09 but for what it does, I think it's really good.
01:00:10 Mido and Mido: Now these little things that people don't know about, they're like,
01:00:12 oh, that's cool. I'm going to go check this out. It might help.
01:00:14 Mido and Mido: Yeah.
01:00:15 Mido and Mido: A Python API for intelligent visual discovery.
01:00:17 Mido and Mido: I may not could be exact more, but we're really close and we love the DeepNote
01:00:22 product. It's like, it's pushing notebooks forward. So trying to add collaboration,
01:00:28 like collaboration, like Google sheets and Google docs, it has a lot more, potentially a more friendly
01:00:33 interface than sending out the rest Jupyter notebooks that are a little bit bare gains at times.
01:00:38 Mido and Mido: Okay.
01:00:38 Mido and Mido: There's also another notebook.
01:00:40 Mido and Mido: Yeah, really cool. I've spoken to the DeepNote people just a little bit and
01:00:43 they're doing cool stuff for sure. Mido and Mido: Yeah, he's cool. Obviously,
01:00:45 there's another notebook called Hex. We had to talk to their founders recently
01:00:47 about some potential collaboration, but they're doing cool stuff as well.
01:00:51 Mido and Mido: Okay, fantastic. All right. And then if you're going to write some Python code,
01:00:55 on notebooks, obviously, if anything else, what editor do you use?
01:00:59 Mido and Mido: We're big VS Code users.
01:01:00 Mido and Mido: Okay. All three of you guys?
01:01:01 Mido and Mido: Jake when he dabbles. Mido and Mido: Yeah.
01:01:03 Mido and Mido: Yeah. Mido and Mido: Yeah.
01:01:04 Mido and Mido: Yeah. No, VS Code.
01:01:05 Mido and Mido: I'm in notebooks.
01:01:06 Mido and Mido: I was thinking about this yesterday recently. It's like, I wish at school someone taught a class called actually doing software development in the real
01:01:12 world because I feel like I lived my whole school life writing Java code in Eclipse and
01:01:17 Mido and Mido and Mido and Mido and Mido and Mido and Mido and Mido and Mido and Mido and Mido. And I'm in the real world. And then I started using VS Code and it was like this transcendent moment of bliss where I was like, oh, programming can actually be fun. And it turns out the tools I was using just made my computer heat up to a thousand degrees and burn my lap.
01:01:29 Mido and Mido: Yeah, I really agree with that statement that that there's a bit of a mismatch of what is taught in sort of computer science and then what is expected of people when they get out in the real world. And it might not be as academically highly valued, but really good, like working with tools like VS Code and and PyCharm and these other tools that help you write code better quicker. And some of the software engineering science, I think that's really could be valuable.
01:01:54 Mido and Mido: No, totally. And also the other thing I'll say is for developers like us, maybe who came out of school and moved into a startup and, and, you know, didn't have a ton of experience, let's say writing Python in production in the wild. The other thing I would highly recommend is continuous integration. You can set it up through GitHub or GitLab. I'm sure if you use that as well, testing your code automatically on a server, huge productivity gains for us and really is increased our confidence that we're able to deliver like the best possible product and not something ever anyone ever told us about, you know, when we're in school. So.
01:02:23 Mido and Mido: No, go implement a database in Lisp. Okay. All right. And it's John out in the audience has a quick funny comment about the editors, Neo Vim, of course, that's starting to get some attention lately as well. Very cool.
01:02:36 Mido and Mido: I'm scared of anything with the word Vim and it scares me, but I'm sure you're a superhuman for using it. But,
01:02:41 Mido and Mido: You know how you generate a proper random number or character set is you get a first year computer science student into Vim and then you ask them to quit.
01:02:51 Mido and Mido: Yeah. I mean, you've seen the most, the most like Stack Overflow questions like I'm trapped in Vim. How the hell do I get out of here?
01:02:57 Mido and Mido: Yes, exactly. Mido: It's so funny. It's like half of what Stack Overflow does is answering just that question specifically.
01:03:01 Mido and Mido: Exactly. For sure. That's great.
01:03:04 Mido and Mido: All right. So final call to action. You guys, people are excited about this. How do they get started? Where do they go from here?
01:03:09 Mido and Mido: Dot Trimido.io, which is our documentation website. And if you're an organization enterprise,
01:03:14 just reach out to me at my email, cheek@sagacollab.com, which will have all links here. Or here, the planes page is a link there. But yeah, the documentation,
01:03:22 Mido and Mido: Yeah. Right on. Also, I'll throw out there while you're on the docs, watch the videos. That's a quick and easy way to really see what it's about. And before we wrap it up here, Mr. Hypermagnetic has a little comment like that Vim is the eighth. It's like deadly sins.
01:03:38 Mido and Mido: It's weird though, because it's not just the eighth of the deadly sins. It's the eighth of the deadly sins that also like 10% of the population swears is the greatest thing since sliced bread. And so it's like half the population, like me, I'm terrified of the damn thing. But my father is like, son, like my dad's dad from the eighties is like, son, have you heard of this? I'm like that, please. I can't take this right now.
01:03:56 Mido and Mido: Yeah, it's amazing. Yeah. My co-host in Python bites, Brian, he's all about Vim. Everything's Vim. It's great. But I did some Emacs and then I kind of did some other more UI oriented things. Awesome. All right. Well,
01:04:08 Jake, Aaron, Nate, it's been fun to have you here. Congratulations on this project. I think it's going to help a lot of people get into Python and data science quicker, more easy.
01:04:16 Mido and Mido: Awesome. Yeah. Thanks for having us. Great chatting.
01:04:18 Mido and Mido: Talk soon. Bye bye. Mido and Mido: Yep. Bye.
01:04:20 Mido and Mido: This has been another episode of Talk Python To Me. Thank you to our sponsors. Be sure to check out what they're offering. It really helps support the show. Choose Shortcut, formerly Clubhouse.io, for tracking all of your projects work, because you shouldn't have to project manage your project management.
01:04:37 Visit talkpython.fm/shortcut. Simplify your infrastructure and cut your cloud bills in half with Linode's Linux virtual machines. Develop, deploy and scale your modern applications faster and easier. Visit talkpython.fm/linode and click the create free account button to get started.
01:04:53 Do you need a great automatic speech to text API? Get human level accuracy in just a few lines of code. Visit talkpython.fm/assemblyai.
01:05:03 Want to level up your Python? We have one of the largest catalogs of Python video courses over at Talk Python. Our content ranges from true beginners to deeply advanced topics like memory and async. And best of all, there's not a subscription in sight. Check it out for yourself at training.talkpython.fm. Be sure to subscribe to the show. Open your favorite podcast app. And start with your podcast.
01:05:15 a subscription in sight, check it out for yourself at training.talkpython.fm. Be sure to subscribe to
01:05:21 the show, open your favorite podcast app, and search for Python. We should be right at the top.
01:05:25 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:05:31 and the direct RSS feed at /rss on talkpython.fm. We're live streaming most of our
01:05:37 recordings these days. If you want to be part of the show and have your comments featured on the air,
01:05:42 be sure to subscribe to our YouTube channel at talkpython.fm/youtube. This is your host,
01:05:47 Michael Kennedy. Thanks so much for listening. I really appreciate it. Now get out there and write
01:05:51 some Python code.
01:05:52 Bye.
01:05:53 Bye.
01:05:54 Bye.
01:05:55 Bye.
01:05:56 Bye.
01:05:57 Bye.
01:05:58 Bye.
01:05:59 Bye.
01:06:00 Bye.
01:06:01 Bye.
01:06:02 Bye.
01:06:03 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:04 Bye.
01:06:05 Bye.
01:06:06 Bye.
01:06:06 Bye.
01:06:06 Bye.
01:06:06 Bye.
01:06:07 Bye.
01:06:08 Bye.
01:06:08 Bye.
01:06:09 you you Thank you.
01:06:12 Thank you.