asyncio all the things with Omnilib



On this episode, you'll meet John Reese. John is the creator of Omnilib, which includes packages such as aioitertools, aiomultiprocess, and aiosqlite. Join us as we async all the things.
Episode Deep Dive
Guest Introduction and Background
John Reese is a seasoned Python developer deeply involved in the Python community and interested in advanced performance techniques using asyncio. Professionally, he works at Facebook (Meta) on Python foundations and tooling. John is the creator of OmniLib, which houses Python libraries aimed at simplifying asynchronous workflows. These libraries include AIO SQLite, AIO Itertools, AIO Multiprocess, and AQL, each one designed to let developers “async all the things.”
What to Know If You're New to Python
Below are a few helpful points if you're just getting started with Python or asynchronous programming so you can follow along with this episode more easily:
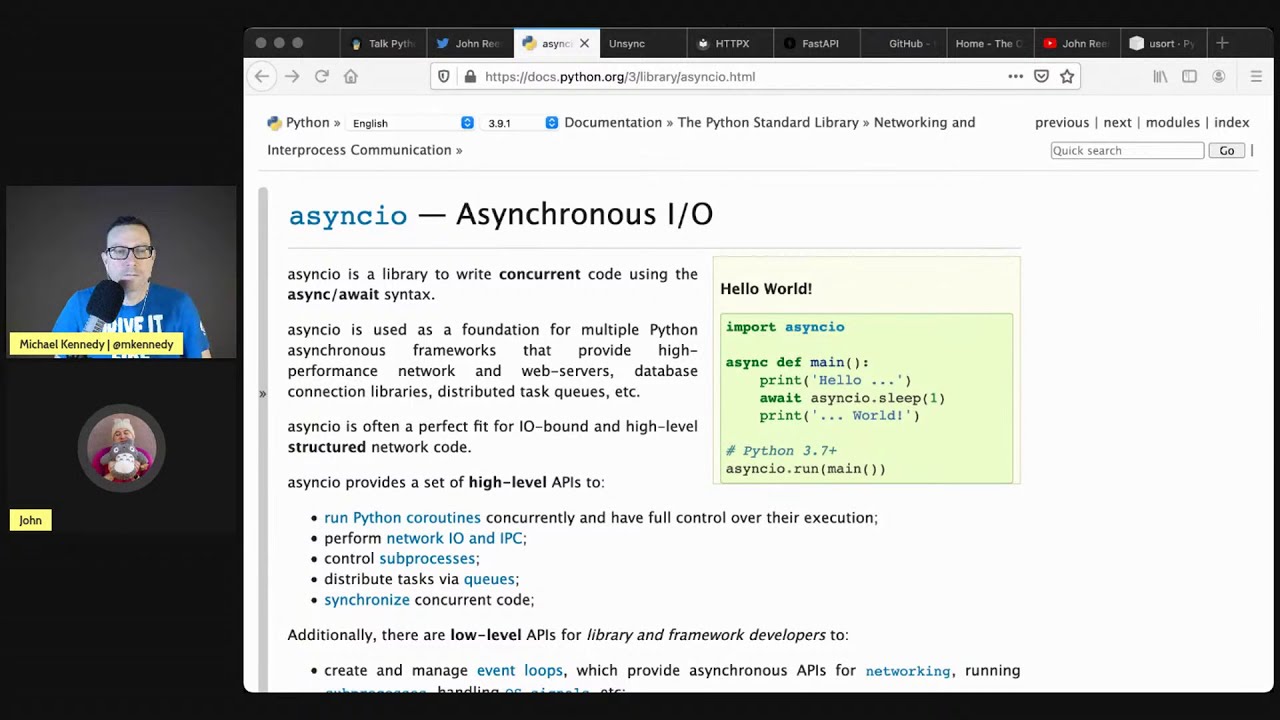
- Understanding that Python’s
asynciois a way to do concurrency without relying on multi-threading is key. - Knowing the difference between CPU-bound and I/O-bound tasks will help you decide which async or parallel approach is best.
- Recognizing that Python code runs under the global interpreter lock (GIL) clarifies why libraries like
multiprocessingor distributed async tools can unlock true parallelism.
Key Points and Takeaways
- OmniLib’s Async Building Blocks
John Reese created OmniLib as an umbrella organization for several high-quality Python libraries focused on asynchronous workflows. It features a consistent coding style, strong documentation, and a welcoming code-of-conduct. The libraries under OmniLib address common async patterns such as database interaction, concurrency with multiple processes, and iterables. Their goal is to make async capabilities more straightforward, even for large-scale applications.
- Links and Tools:
- AIO Multiprocess: Combining AsyncIO with Multiple Processes
This library allows you to run Python code across multiple processes (one per CPU core), each hosting an event loop, giving you both concurrency and true parallelism. It’s especially valuable for high-scale tasks such as web scraping or network I/O to many servers. Because each process can handle multiple async tasks, you avoid the overhead of creating an enormous number of single-purpose processes.
- Links and Tools:
- Dealing with the Global Interpreter Lock (GIL)
Python’s GIL ensures only one thread modifies Python objects at a time, which simplifies development but can limit CPU-bound multithreading performance. John highlighted how async and multiprocessing can work around the GIL, especially when you are waiting on I/O or distributing CPU-intensive workloads across processes.
- Links and Tools:
- Guide to concurrency in Python (general reference)
- Links and Tools:
- AIO Itertools for Async Iteration
Modeled after Python’s built-in
itertools, this library handles async generators and iterables. It includes functions such as concurrency-limitedgatherto prevent overloading the event loop with thousands of tasks. Its chaining and batching features help handle streaming data efficiently, making it straightforward to build pipelines of async transformations.- Links and Tools:
- AIO SQLite for Asynchronous Database Access
SQLite is a light but powerful database engine included with Python.
AIO SQLitewraps standard SQLite calls in a background thread, exposing them via async/await. While SQLite isn’t inherently multi-thread-friendly, this library cleverly coordinates access so your async code never blocks while queries run on a separate thread.- Links and Tools:
- AQL: A DSL for ORM-like SQL
AQL aims to unify a typed approach to generating SQL queries, letting you write queries with method calls (e.g.,
table.select().where(...)). It can produce backend-specific SQL for different database engines. Although still evolving, its consistent interface across multiple databases is a big step in bridging ORM convenience and raw SQL performance.- Links and Tools:
- Benefits and Pitfalls of AsyncIO
AsyncIO is perfect for scaling I/O-bound tasks, such as network operations, web scraping, or reading many files concurrently. However, you can run into complexity if you try to adapt existing synchronous code by sprinkling in
asyncwithout proper design. Understandingasync with,async for, and how to manage an event loop is crucial for success.- Links and Tools:
- Combining Async and Distributed Systems If you need to go beyond your local machine’s limits, you can embed async code in distributed frameworks. AIO Multiprocess is just one example of parallelizing on a single system; you can also extend concurrency to clusters using more advanced tooling. The concept remains: quickly release control while waiting for I/O, enabling massive throughput.
- Adopting Open Source and Inclusivity John founded OmniLib with a welcoming code-of-conduct to encourage diverse contributors. He emphasizes that an inclusive environment helps open-source projects thrive. If you’re adopting any OmniLib library, you can contribute not just code but also ideas and reviews, even if you’re new to open source.
- Bowler and USort: Tools for Code Modernization Outside OmniLib, John has built tools like Bowler for code refactoring and USort for deterministic import sorting. These emerged from scaling Python within large organizations, ensuring code quality and consistency. They’re good examples of Python’s ecosystem supporting incremental improvement.
- Links and Tools:
Interesting Quotes and Stories
From TI-99 to Ansible “Hello World”: John recalled his earliest programming memory on a TI-99-4A, showing how simple personal projects eventually led to building open-source libraries used at scale.
On Overthreading: One memorable story highlighted the trap of thinking “more threads solves everything,” only to discover that thousands of threads can slow an application. Instead, concurrency-limited gather in
asyncioor using processes more wisely can be far more efficient.
Key Definitions and Terms
- GIL (Global Interpreter Lock): A lock in CPython ensuring only one thread runs Python code at a time, simplifying memory management but limiting multithreading performance.
- AsyncIO: A Python framework for asynchronous programming that uses an event loop and cooperative multitasking (via
async/await), well suited for I/O-bound operations. - Event Loop: The engine that schedules and runs
asynctasks. It continuously checks if any tasks are ready to proceed. - AIO: Often a shorthand prefix meaning “Asynchronous I/O.”
- Multiprocessing: The technique of running code across multiple CPU cores or processes to bypass the GIL for CPU-intensive work.
Learning Resources
Here are a few curated courses and references that dive deeper into Python and async topics:
- Python for Absolute Beginners: Perfect for anyone brand new to coding in Python.
- Async Techniques and Examples in Python: Understand how to use
asyncio, threads, multiprocessing, and more for parallelism in Python. - Modern APIs with FastAPI and Python: If async web frameworks interest you, check out FastAPI’s powerful async features.
Overall Takeaway
This episode highlights how to push Python’s concurrency and parallelism to the next level by blending asyncio with carefully managed processes. John’s OmniLib suite provides practical frameworks for async iteration, database access, and bridging the gap between CPU-intensive and I/O-heavy workloads. Whether you’re scaling to hundreds of network calls or wanting a more elegant approach to concurrency, OmniLib demonstrates that Python can “async all the things” with performance and clean design in mind.
Links from the show
awesome-asyncio: github.com
unsync: asherman.io
Live Youtube Stream: youtube.com
Charities
Power On: poweronlgbt.org
The Trevor Project: thetrevorproject.org
Episode #304 deep-dive: talkpython.fm/304
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 The relatively recent introduction of async and await as keywords in Python have spawned a whole
00:04 area of high-performance, highly scalable frameworks and supporting libraries.
00:08 One such library that has great async building blocks is OmniLib. On this episode, you'll meet
00:14 John Reese. John is the creator of OmniLib, which includes packages such as aioitertools,
00:19 aiomultiprocess, and aiosqlite. Join us as we async all the things. This is Talk Python To Me,
00:26 episode 304, recorded February 16th, 2021.
00:31 Welcome to Talk Python To Me, a weekly podcast on Python, the language, the libraries, the ecosystem,
00:49 and the personalities. This is your host, Michael Kennedy. Follow me on Twitter where I'm at
00:54 mkennedy and keep up with the show and listen to past episodes at talkpython.fm and follow the
00:59 show on Twitter via at Talk Python. This episode is brought to you by Linode and Talk Python training.
01:05 Please check out the offers during their segments. It really helps support the show.
01:09 John, welcome to Talk Python To Me.
01:11 Howdy. It's good to be here.
01:13 Yeah, it's great to have you here as well. It's going to be a lot of fun to talk to you about
01:17 async stuff. I think we both share a lot of admiration and love for asyncioing all the
01:23 things.
01:23 I definitely do. It's one of those cases where the things that it enables is so different,
01:29 and you have to think about everything so differently when you're using asyncio,
01:32 that it's a nice challenge, but also has potentially really high payoff if it's done well.
01:39 Yeah, it has a huge payoff. And I think that it's been a little bit of a mixed bag in the terms of
01:44 the reception that people have had. I know there have been a couple of folks who've written articles
01:48 like, well, I tried it. It wasn't that great. But there's also, you know, I've had examples where I'm
01:53 doing something like web scraping or actually got a message from somebody who listened. Maybe they were
01:57 listening to Python Bytes, my other podcast. But anyway, I got a message from a listener after we
02:01 covered some cool asyncio things and web scraping. They had to download a bunch of stuff.
02:06 Like it takes like a day to literally it takes all day or something. It was really crazy. And then
02:10 they said, well, now I'm using async and now my computer runs out of memory and crashes. It's
02:14 getting it so fast. Like that's a large difference right there. Right. So there's certainly a category
02:19 of things where it's amazing.
02:21 Yeah, I think the case we've seen it most useful for is definitely doing those sorts of like concurrent
02:27 web requests. Internally, it's also extraordinarily useful in monitoring situations where it's like you
02:33 want to be able to talk to a whole bunch of servers as fast as possible. And maybe the amount of stuff
02:38 that comes back from it is not as important as being able to just talk to them repeatedly.
02:42 Yeah.
02:42 But you're right. There's definitely a lot of cases where people are not necessarily using
02:46 it correctly or they're hoping to like add a little bit of async into an existing thing.
02:50 And that doesn't always work as well as just building something that's async from the start.
02:54 Yeah. And there's more frameworks these days that are welcoming of async from the start,
02:59 I guess. Yeah. We're going to talk. Yeah. We're going to talk about that. But before we get too
03:02 far down the main topic, let's just start with a little bit of background on you. How'd you get
03:05 into programming in Python?
03:06 Sure. So my first interaction with the computer was when I was, you know, maybe like five or six years
03:12 old. My parents had a TI-99/4A, which is like the knockoff Commodore attached to the television.
03:19 Yeah. And I think back to that, like, how could you have like legible text on the CRT TV?
03:26 It was pretty bad.
03:27 It's bad, right?
03:28 It's like my biggest memory of it is really just every time we would try to play a game and the
03:34 cartridge or tape or whatever wouldn't work correctly, it would just dump you at a basic
03:39 prompt where it's just expecting you to start typing some programming in. And like nobody in
03:44 my family had a manual or knew anything about programming at the time. There was like, I think
03:48 maybe we figured out that you could like print something to the screen, but nothing beyond that.
03:52 And it wasn't until we ended up getting a DOS computer, you know, a few years later that really
03:58 started to actually do some quote unquote real programming where we were writing like batch
04:04 scripts to do menus or like, you know, deciding what program to run or things like auto exec on a
04:11 floppy disk in order to boot into a game.
04:13 I was just thinking of all the auto exec bad stuff that we had to do like, oh, you want
04:17 to play Doom, but you've got you don't have enough high memory, whatever that was. And so
04:21 you've got to rearrange where the drivers are. I mean, what's what a weird way to just I want
04:25 to play a game. So I've got to rework where my drivers are.
04:28 Make sure you don't load your mouse driver when you're booting into this one game that doesn't
04:33 need the mouse because otherwise you run out of memory. Yeah, it was kind of crazy.
04:36 And my biggest memory of programming there was there was QBasic on it and it came with
04:41 this gorilla game where you just like throw bananas at another gorilla from like some sort
04:47 of like city skyline.
04:48 Like a King Kong knockoff, Donkey Kong knockoff type thing.
04:52 Yeah, exactly. And I would struggle to figure out how that was actually doing anything.
04:57 And he's like, I'd try to poke at it and figure it out as I went. Didn't really do that much,
05:01 but it was actually my first opportunity for quote unquote open source projects because
05:06 there's a video game that I really, really liked called NASCAR racing.
05:10 And one of the things that I learned was you is on the burgeoning part of the internet for
05:16 me, at least was people would host these mods for the game on like geo cities or whatever.
05:21 And so these, these would change like the models for the cars or the wheels or add tracks or
05:26 textures or whatever. And I actually wrote a batch script that would let you like at the
05:30 time that you wanted to play the game, pick which of the ones you had enabled because
05:34 you couldn't have them all enabled. So it would like, right.
05:37 It's basically just a batch script that would go and like copy a bunch of files around from
05:41 one place to another. And then when you're done with the menus or whatever, then it would
05:45 launch the game. And I remember posting that on geo cities and, you know, having the silly
05:51 little like JavaScript counter or whatever it was, take up to like a couple hundred page
05:56 views of people downloading just this script to switch mods in and out. And so that was
06:01 like the first real taste of like open source programming or open source projects that
06:05 I had, but that actually like led into the way that I really learned programming, which was
06:10 I wanted to have my own website that was more dynamic than what geo cities had.
06:14 And so I ended up basically picking up Pearl and eventually PHP to write your web pages that I hosted
06:22 on my own machine at home from like IIS and active.
06:26 And how did you get a, what did you do? Do you use like DynDNS or something like that?
06:31 Yes, exactly. Dying DNS. It was the jankiest setup, but it at least worked and I could impress
06:37 my friends and it wasn't until I got to college and I was working on my first internship where
06:43 the main project I was working on was essentially improving an open source bug tracker written
06:49 in PHP in order to make it do the things that my company wanted to be able to do in it. So
06:55 like adding a plugin system and things like that. And in the process of that, they, I eventually
07:00 became a maintainer of the project and they had a bunch of Python scripts for managing releases,
07:05 like doing things like creating the release tar balls, running other sort of like linter type
07:10 things over the code base. And that was my very first taste of Python. And I hated it because it
07:16 was just like, I couldn't get past the concept of like, you're forcing me to do white space.
07:21 Like how barbaric is this? But it actually didn't take long before I realized that that actually makes
07:27 the code more readable. It's like, you can literally pick up anybody else's Python script and it looks
07:32 almost exactly like how you would have done it yourself.
07:34 Yeah. And you've got a lot of the PEP 8 rules and tools that automatically re, you know,
07:39 format stuff into that. So it's very likely, you know, you've got black and PyCharm's reformat
07:45 and whatnot, right?
07:46 This was all before that. So I think this was when like Python 2.6 was the latest.
07:50 This was quite a while ago.
07:52 Right before the big diversion.
07:53 Yeah, yeah, exactly. Like I had no idea what Python 3 was until like 3.2 or 3.3 came out because
08:00 it was just sequestered in this world of writing scripts for whatever version of Python was on
08:05 my Linux box at the time.
08:06 Right. You know, I suspect in the early days, probably the editors were not as friendly or
08:10 accommodating, right? Like now, if you work with PyCharm or VS Code or something, you just write
08:15 code and it automatically does the formatting and the juggling and whatnot. And once you get used to it,
08:20 you don't really think that much about it. It just magically happens as you work on code.
08:23 I'm wanting to say at the time I was just doing something stupid like Notepad++ or,
08:29 you know, one of the other like really generic free text editors.
08:32 Like Notepad, but Consolas fonts.
08:34 Or it was Eclipse. It might have been Eclipse.
08:36 Yeah. Was it maybe PyDev?
08:38 I don't think I ever use a Python specific editor.
08:42 Like, yeah, I think I've tried PyCharm exactly once and I do just enough stuff that's not Python
08:48 that I don't want to deal with an IDE or editor that's not generalized.
08:53 Right. Sure. Makes sense.
08:54 Speaking of stuff you work on, what do you do day to day? What kind of stuff do you do?
08:59 I'm a production engineer at Facebook on our internal Python foundation team. And so most of
09:06 what I do there is, you know, building infrastructure or developer tools, primarily enabling engineers,
09:12 data scientists, and AI or ML researchers to do what they do in Python every day. So some of that is like
09:21 building out the system that allows us to integrate open source third party packages into the Facebook
09:27 repository. Some of that is literally developing new open source tools for developers to use.
09:33 A while back, I built a tool called called Bowler that is basically a refactoring tool for Python. It's based off of lib2to3 that's in, you know, open source Python essentially gives you a way to make safe code modifications rather than using regular expressions, which are terrible.
09:52 Yeah, for sure. And based on like the AST or something like that. Yeah, exactly. Yeah. Okay.
09:56 And it's like the benefit of LibCST is that it takes in the concrete syntax tree. So it keeps track of all the white space comments and everything else. So that if you modify the tree in lib2to3, it will then allow you to write that back out exactly the way the file came in. Whereas the AST module would have thrown all of that, you know, metadata away.
10:18 Right, right. Formatting spaces, whatever. It doesn't care.
10:20 Yeah. And one of the newer projects I've worked on is called USort and it's microsort. Essentially, it's a replacement that we're using internally for isort because isort has some potentially destructive behaviors in its default configuration. And our goal was essentially to get import sorting done in a way that does not require adding comment directives all over the place.
10:45 Right, right, right, right.
11:15 And you can't just put a skip directive on that function call, because that just means isort won't try to sort that one, but it'll sort everything else around it as well. And so what we ended up seeing was a lot of developers doing things like isort skip file, and just turn off import sorting altogether.
11:31 One of the things of isort is like, first do no harm. It's trying its best to make sure that these common use cases are just treated normally and correctly from the start. In most cases, it's a much safer version of isort. It's not complete. It's not a 100% replacement, but it's the thing we've been using internally. And it's one of the cases where I'm proud of the way that we are helping to build better tools for the ecosystem.
11:56 Yeah, this is really, I never really thought about that problem. One thing that does drive me crazy is sometimes I'll need to change the Python path, so that future imports, regardless of your working directory behave the same if you don't have a package or something like that, right? Something simple.
12:11 That's super common in the AI and ML type of workflows.
12:14 Yeah, and I get all these warnings, like, you should not have code that is before an import. Like, well, but this one is about making the import work. If I don't put this, it's going to crash for some people if they run it weirdly and stuff like that, right?
12:25 Yeah.
12:25 Interesting. Yeah, very, very cool project. Nice. All right. So let's dive into async, huh?
12:30 Sure.
12:30 Yeah. So maybe a little bit of history. You know, Python, it's hard to talk about asynchronous programming in Python without touching on the gill, global interpreter lock, normally spoken as a bad word, but it's not necessarily bad. It has a purpose. It just its purpose is somewhat counter to making asynchronous code run really quick and in parallel.
12:49 I mean, it's one of those things where if you imagined what Python would be without the global interpreter lock, you end up having to do a lot more work to make sure that, let's say, if you had multi-threaded stuff going on, you'd have to do a lot more work to make sure that they're not clobbering some shared data. Like, you look at the way that you have to have synchronizations and everything else in Java or C++.
13:09 We don't generally need that in Python because the GIL prevents a lot of that bad behavior. And the current efforts to kind of remove the GIL that have been ongoing for the past eight to 10 years, in every single case, once you remove that GIL and add a whole bunch of other locks, the whole system is actually slower.
13:26 So this is one of those things where it's like, it does cause problems, but it also enables Python to be a lot faster than it would be otherwise.
13:34 And probably simpler.
13:35 Yeah.
13:35 Yeah. So the global interpreter lock, when I first heard about it, I thought of it as a threading thing and it sort of is, but you know, it's primarily says, let's create a system so that we don't have to do locks as we increment and decrement the ref count on variables. So basically all the memory management can happen without the overhead of taking a lock, releasing a lock, all that kind of weirdness.
13:56 Yeah.
13:56 So we've got like a bunch of early attempts. I mean, we've got threading and multiprocessing have been around for a while. There's gevent, Tornado, but then around, I guess, was it?
14:05 Python 3.4. We got asyncio, which is a little bit of a different flavor than, you know, like the computational threading or the computational multiprocessing side of async.
14:16 It's actually an interesting kind of throwback to the way that computing happened in like the 80s and early 90s, where like Windows 3.1 or classic macOS, essentially you can, you know, run your program or your process and you actually have to cooperatively give up control of the CPU in order for another program to work.
14:37 So there'd be a lot of cases where, like, if you had a bad behaving program, you'd end up not being able to do multitasking in, you know, these old operating systems because it was all cooperative.
14:47 In the case of asyncio, it's essentially taking that mechanism where you don't need to do a lot of context switching in threads or in processes.
14:57 And you're essentially letting a bunch of functions cooperatively coexist and essentially say when your function gets to a point where it's doing a network request and it's waiting on that network request,
15:08 your function then will nicely hand over control back to the asyncio framework, at which point the framework and event loop can go find the next task to work on that's not blocked on something.
15:20 Yeah. And it's very often doesn't involve threads at all or, you know, the one main thread, right?
15:24 Like, so, yeah, you know, it's not a way to create threading.
15:27 It's a way to allow stuff to happen while you're otherwise waiting.
15:31 Yeah. In the best case, you only ever have the one thread.
15:34 And now in reality, it doesn't work like that because a lot of our, you know, modern computing infrastructure is not built in an async way.
15:41 So like if you look at file access, there's basically no real way to do that asynchronously without threads.
15:47 But in the best case, like network requests and so forth, if you have the appropriate hooks from the operating system, then that can all be completely in one thread.
15:55 And that means you have a lot less overhead from the actual runtime and process from the operating system because you're not having to constantly throw a whole bunch of memory onto a stack and then pull off memory from another stack and try to figure out where you were when something interrupted you in the middle of 50 different operations.
16:16 This portion of Talk Python To Me is sponsored by Linode.
16:19 Simplify your infrastructure and cut your cloud bills in half with Linode's Linux virtual machines.
16:23 Develop, deploy, and scale your modern applications faster and easier.
16:27 Whether you're developing a personal project or managing large workloads, you deserve simple, affordable, and accessible cloud computing solutions.
16:35 As listeners of Talk Python To Me, you'll get a $100 free credit.
16:39 You can find all the details at talkpython.fm/Linode.
16:43 Linode has data centers around the world with the same simple and consistent pricing regardless of location.
16:49 Just choose the data center that's nearest to your users.
16:52 You'll also receive 24-7, 365 human support with no tiers or handoffs regardless of your plan size.
16:58 You can choose shared and dedicated compute instances, or you can use your $100 in credit on S3-compatible object storage, managed Kubernetes clusters, and more.
17:09 If it runs on Linux, it runs on Linode.
17:11 Visit talkpython.fm/Linode or click the link in your show notes, then click that create free account button to get started.
17:18 Right, if it starts swapping out the memory it's touching, it might swap out what's in the L1, L2, L3 caches.
17:27 Yeah, exactly.
17:28 It can have huge performance impacts, and it's just constantly cycling back and forth out of control a lot of times, right?
17:34 Yeah.
17:34 In a lot of our testing internally when I was working on things that would talk to lots and lots of servers,
17:39 it's like we would hit a point where somewhere between 64 and 128 threads would actually start to see less performance overall
17:48 because it just spends all of its time trying to context switch between all of these threads.
17:53 Right, right, right.
17:54 You're interrupting these threads at an arbitrary point in time because the runtime is trying to make sure that all of the threads are serviced equally.
18:01 But in reality, like half of these threads don't need to be given the context right now.
18:06 So by doing those sort of interrupts in context, which is when the runtime wants to rather than when the functions or requests are wanting to,
18:14 you end up with a lot of suboptimal behavior.
18:17 Yeah, interesting.
18:17 Yeah, and also things like locks, mutexes, and stuff don't work in this world because it's about what thread has access.
18:26 Well, all the codes on one thread.
18:27 So to me, the real zen of AsyncIO, at least for many really solid use cases, kind of like we touched on,
18:33 is it's all about scaling when you're waiting.
18:36 Yes.
18:36 If I'm waiting on something else, it's like completely free to just go to it.
18:40 If I'm calling microservices, external APIs, if I'm downloading something or uploading a file or talking to a database,
18:48 or even maybe accessing a file with something like aiofiles.
18:51 Yeah.
18:52 Yeah.
18:52 Yeah, there's a cool place called AI Awesome AsyncIO by TML Fear.
18:57 It's pretty cool.
18:58 Have you seen this place?
18:59 I have looked at it in the past.
19:01 I end up spending so much time looking at and building things.
19:04 It's like I haven't actually gotten a lot of opportunity to use a bunch of these.
19:09 Most of my time, I'm actually not working that high enough on the stack to make use of them.
19:13 Right, right, right.
19:14 These are a lot of more frameworks.
19:15 We do have some other neat things in there as well, like asyncssh.
19:19 I hadn't heard of that one.
19:20 But anyway, I'll put that in the show notes.
19:21 That's got, I don't know, 50, 60 libraries and packages for solving different problems with AsyncIO, which is pretty cool.
19:27 Yeah.
19:28 Whenever I talk about AsyncIO, one of the things I love to give a shout out to is this thing called Unsync.
19:32 Have you heard of Unsync?
19:34 I had not heard about it until I looked at the show notes.
19:36 But it sounds a lot like some of the things that I've seen people implement a lot of different cases.
19:42 It's a very filling a common sort of use case where you have, like I was saying earlier, where people want to mix AsyncIO into an existing synchronous application.
19:50 You do have to be very careful about how you do that, especially vice versa.
19:54 Or a lot of the stumbling blocks we've seen tend to be cases where you have synchronous code that calls some Async code that then wants to call some synchronous code, but on like another thread so that it's not blocked by it.
20:08 And you actually end up getting this like in-out sort of thing where you have like nested layers of AsyncIO.
20:15 I'm not sure how much this may or may not solve that.
20:18 I think this actually helps some with that as well.
20:21 Basically, the idea is there's two main things that it solves that I think is really neat.
20:24 One, it's like a unifying layer across multiprocessing, multithreading, and straight AsyncIO.
20:30 Right?
20:30 So you put a decorator onto a function.
20:32 If the function is an Async function, it runs it on AsyncIO.
20:36 If it's a regular function, it runs it on a thread.
20:38 And if you say it's a regular function, but it's computational, it'll run it on multiprocessing.
20:43 But it gives you basically an AsyncIO, Async and await API for it.
20:46 And it figures out how to run the loop and all.
20:48 Anyway, it's pretty cool.
20:49 Not what we're here to talk about, but it's definitely worth checking out while we're on the subject.
20:53 Ultimately, it gives you just a future that you can then either await or ask for the result from, right?
20:59 Yeah, exactly.
20:59 Exactly.
21:01 And the result, instead of saying, you've got to wait until it's finished before you can get the result,
21:04 you just go, give me the result.
21:06 And if it needs to, it'll just block.
21:07 So it's a nice way to sort of cap the AsyncIO.
21:10 You know, like one of the challenges of AsyncIO is, well, five levels down the call stack,
21:14 this thing wants to be Async.
21:15 So the next thing's Async.
21:17 So the next thing up is Async.
21:18 And like all of a sudden, everything's Async, right?
21:20 And so it was something like this.
21:22 I mean, you could do it yourself as well.
21:23 You can like just go create an event loop, run it.
21:26 And at this level, we're not going to be Async above it.
21:29 But we're coordinating stuff below using AsyncIO.
21:31 And here's where it stops.
21:33 Yeah.
21:33 It sounds like a nicer version of what I see dozens of when you have lots and lots of engineers
21:38 that aren't actually working on the same code base together, but they're all in the same
21:42 repository.
21:42 And we end up seeing these cases where everybody has solved the same use case.
21:46 So I do think this would be useful.
21:48 And I'm actually planning on sharing it with more people.
21:51 Yeah.
21:51 Yeah.
21:51 Check it out.
21:51 It's like a subtotal, I think, 126 lines of Python in one file.
21:56 But it's really cool, this unifying API.
21:58 All right.
21:58 I guess that probably brings us to OmniLib.
22:01 You want to talk about that for a little bit?
22:03 So this is what I thought would be fun to have you on the show to really focus on is like
22:07 AsyncIO, but then also you've created this thing called OmniLib, the OmniLib project that
22:12 has solves four different problems with AsyncIO.
22:15 And obviously you can combine them together, I would expect.
22:18 The origins of this really is like I had built the like aiosqlite was the first thing that
22:24 I wrote that was an Async framework.
22:26 And then I'd built a couple more.
22:28 And at one point I realized these projects are actually getting really popular and people
22:32 are using it, but they're just like one of the hundred things that are on my GitHub profile
22:38 and graveyard.
22:38 So I really felt like they needed to have their own separate place for like, these are the
22:43 projects that I'm actually proud of.
22:45 I thought that was actually a good opportunity to be able to make a dedicated like project
22:50 or organization for it.
22:53 And essentially say that everything under this I'm guaranteeing is going to be developed under
22:59 a very inclusive code of conduct that I personally believe in and want to try and also at the same
23:05 time make it more welcoming and supportive.
23:07 You know, other contributors, especially newcomers or other otherwise marginalized developers in
23:14 the ecosystem and try to be as friendly as possible with it.
23:17 And it's like, this is something that I tried to do beforehand and I just never really formalized
23:21 it on any of my projects other than like, here's a code of conduct file in the repository.
23:26 Yeah.
23:27 Yeah.
23:27 But this is like really one of the first times where I wanted to put all these together and
23:32 make sure that these are really like, this is going to be whether or not enough people
23:36 make it a community.
23:37 I want it to be welcoming from the outset.
23:40 Right.
23:40 That's really cool.
23:41 And you created your own special GitHub organization that you're putting it all under and stuff like
23:45 that.
23:46 So it's kind of the things that are graduated from your personal project.
23:49 Is that a story?
23:50 Yeah.
23:50 And kind of the threshold I tried to follow is like, if this is worth making a Sphinx documentation
23:56 site for, then it's worth putting on, you know, OmniLib project.
23:59 So they're not all asyncio.
24:01 That just happens to be where a lot of my interests and utility stands at.
24:06 So that's what most of them are, or at least the most popular ones.
24:10 But there are other projects that I have also in the back burner that will probably end up
24:15 there that maybe not as useful libraries or whatever, but either way, like I said, these
24:20 are the ones that I'm at least proud of.
24:21 Nice.
24:22 That's cool.
24:22 So you talked about the being there to support people who are getting into open source and
24:27 whatnot and having that code of conduct.
24:29 What other than that, is there like a mission behind this?
24:32 Like I want to make this category of tools or solve these types of problems, or is it just
24:37 these are the things that you've graduated?
24:39 It's something I've tried to think about.
24:41 I'm not 100% certain.
24:42 I would like it to have maybe more of a mission, but at the same time, it's like, especially
24:48 from things I've had to deal with at work, it's like, I don't want this to be a dumping
24:51 ground of stuff either.
24:52 Like I want this specifically, it's like, like in the opening statement, I want it to be a group
24:57 of high quality projects that are, you know, following this code of conduct.
25:00 So from that perspective, it's like, at the moment, it's like my personal interests are always
25:06 in building things where I find gaps in, you know, availability from other libraries.
25:11 So that's probably the closest to a mission of what belongs here is just things that haven't
25:16 been made yet.
25:17 Yeah.
25:17 Yeah.
25:18 Yeah.
25:18 But either way, I just want to have that, you know, dedication to the statement of like,
25:22 I want these to be high quality.
25:24 I want them to be tested.
25:25 I want them to be, you know, have continuous integration and testing and well-documented
25:30 and so forth.
25:31 Yeah.
25:31 Super cool.
25:32 All right.
25:32 So there's four main projects here on the homepage.
25:36 I mean, do you have the attribution one, but that's...
25:39 Like helper tool.
25:40 Exactly.
25:41 Let's talk about the things that maybe they're the AIO extension of.
25:45 So in Python, we have iter tools, right?
25:48 Which is like tools for easily creating generators and such out of collections and whatnot.
25:55 So you have aioitertools, which is awesome.
25:57 And then we have multiprocessing, which is a way around the GIL.
26:00 It's like, here's a function and some data, go run that in a sub process and then give me
26:04 the answer.
26:04 And because it's a sub process, it has its own sub GIL or its own separate GIL.
26:08 So it's all good.
26:09 So you have aiomultiprocess, which is cool.
26:11 And then one of the most widely used databases is SQLite, already built into Python, which
26:18 is super cool.
26:18 And so you have aiosqlite.
26:20 And then sort of extending that, that's like a raw SQLite, you know, raw SQL library that's
26:25 asynch.io.
26:26 Then you have AQL, which is more ORM-like.
26:29 I'm not sure it's 100% ORM.
26:31 You could categorize it for us, but it's like an ORM.
26:34 Yeah, I've definitely used like in quotes, in scare quotes, ORM-like.
26:39 Because I want it to be able to essentially be a combination of like well-typed table definitions
26:46 that you can then use to generate queries against the database.
26:50 As of right now, it's more like writing a, like a DSL that lets you write a backend agnostic
26:57 SQL statement.
26:58 Right.
26:59 Okay.
26:59 Yeah.
27:00 DSL domain specific language for people who aren't entirely sure.
27:02 Yeah.
27:03 So really it's essentially just stringing together a whole bunch of method calls on
27:07 a table object in order to get a SQL query out of it.
27:11 The end goal is to be able to have that actually be a full end-to-end thing where you've defined
27:17 your tables and you get objects back from it.
27:19 And then you can like call something on the objects to get them to update themselves back
27:23 into a database.
27:24 But I've been very hesitant to pick an API on it for how to actually get all that done
27:29 because trying to do that in an async fashion is actually really difficult to do it right.
27:34 And separately, like trying to do asyncio and have everything well-typed, you know, it's
27:40 like two competing problems that have to be solved.
27:43 Yeah.
27:44 I just recently started playing with SQLAlchemy's 2.0, 1.4 beta API where they're doing the
27:51 async stuff and it's quite different than the traditional SQLAlchemy.
27:54 So yeah, you can see the challenges there.
27:57 And it's also a case where it's like having something to generate the queries to me is more
28:02 important than having the thing that will actually go run the query, especially for a lot of internal
28:06 use cases.
28:06 We really just want something that will generate the query or we already have a system that
28:11 will talk to the database once you give it a query and parameters.
28:14 It's the piece of actually saying, defining what your table hierarchy or structure is,
28:20 and then being able to run stuff to get the actual SQL query out of it, but have that work
28:26 for both SQLite and MySQL or Postgres or whatever other backend you're using.
28:32 Having it be able to use the same code and generate the correct query based off of which
28:37 database you're talking to is the important part.
28:39 Yeah, cool.
28:40 Well, there's probably a right order to dive into these, but since we're already talking
28:43 about the AQL one a lot, maybe give us an example of what you can do with it.
28:48 Maybe talk us through, it's hard to talk about code on air, but just give us a sense of what
28:52 kind of code you write and what kind of things it does for us.
28:55 This is heavily built around the idea of using data classes.
29:00 In this case, it specifically uses attrs simply because that's what I was more familiar
29:04 with at the time that I started building this.
29:06 But essentially, you create a class with, you know, essentially, all of your columns specified
29:12 on that class with the name and the type.
29:15 Not like SQL.
29:16 But not like super heavy.
29:17 Or Django style.
29:18 Yeah, exactly.
29:19 Like native types like id colon int, name colon str, not sa.column dot, you know, sa.string
29:25 and so on, right?
29:25 Yeah, exactly.
29:26 Like I want this to look as close to a normal data class definition as possible and essentially
29:32 be able to decorate that.
29:33 And you get a special object back that when you use methods on it, like in this case, the
29:39 example is you're creating a contact.
29:41 So you list the integer id, the name of it, and the email.
29:45 And whatever the primary key doesn't really matter in this case.
29:48 Whether the id ends up getting auto incremented, again, doesn't really matter.
29:53 What we're really worried about is generating the actual queries.
29:56 And you're assuming like somebody's created the table.
29:58 It's already got a primary key for id.
30:01 It's auto incrementing or something like that.
30:03 Yeah.
30:03 And you just want to talk to the thing.
30:04 Yeah.
30:07 Talk Python To Me is partially supported by our training courses.
30:10 Do you want to learn Python, but you can't bear to subscribe to yet another service?
30:15 At Talk Python Training, we hate subscriptions too.
30:18 That's why our course bundle gives you full access to the entire library of courses for
30:23 one fair price.
30:24 That's right.
30:25 With the course bundle, you save 70% off the full price of our courses and you own them
30:30 all forever.
30:31 That includes courses published at the time of the purchase, as well as courses released within
30:36 about a year of the bundle.
30:37 So stop subscribing and start learning at talkpython.fm/everything.
30:44 And so essentially you take this contact class that you've created and you can call a select
30:51 method on it that will then, you know, you can add an aware method to decide which contacts
30:57 you want to select.
30:58 There's other methods for changing the order or limits or furthermore, if you wanted to do
31:03 joins or other sorts of things.
31:05 It kind of expects that you know what general SQL syntax looks like because you string together
31:12 a bunch of stuff kind of in the same order that you would with a SQL query.
31:16 But the difference is that in this case, like when you're doing the where clause, rather than
31:20 having to do an arbitrary string that says, you know, column name like, and then some string
31:26 literal, in this case, you're saying like where contact dot email dot like, and then passing
31:32 the thing that you want to check against.
31:34 And the other alternative is you could if you wanted to look for a specific one, you could
31:39 say like where contact dot email equals equals, and then the value you're looking for.
31:44 And so you're kind of using or abusing Python's expression syntaxes to essentially build up
31:52 your query, definitely using a domain specific language in this case.
31:56 But essentially having the fluent API, once you string all this together, you have this query
32:01 object, which you can then, you know, pass to the appropriate engine to get an actual finalized
32:08 SQL query and the parameters that would get passed if you were doing a prepared query.
32:12 But you could also potentially like in the future, the goal was you would also be able
32:17 to make manage your connection with a QL and basically be able to tell it to run this query
32:24 on that connection.
32:25 And regardless, you'd be able to do this the same with SQLite or MySQL or whatever.
32:29 And the library is the part that handles deciding what specific part of the incompatible SQL languages
32:38 that they all use will actually be available.
32:41 Right.
32:41 Yeah.
32:42 Like, for example, MySQL uses question mark for the parameters.
32:45 Yeah.
32:46 SQL server uses, I think, at parameter name.
32:49 There's like, they all have their own little style.
32:51 It's not the same, right?
32:52 Yeah.
32:53 And some of that is kind of moot because of the fact that the most of the engine libraries
32:59 that we use commonly in Python, like AIO, MySQL or SQLite or whatever, they're already kind
33:05 unified around the, there's a specific PEP that defines what the database interface is going to look like.
33:13 Right.
33:13 The DB API 2 or whatever.
33:15 Yes, that.
33:16 So some of that work has already been done by the PEPs and by the actual database engines.
33:21 But there's a lot of cases where it's a little bit more subtle, like the semantics, especially around using a like expression.
33:28 MySQL does a case insensitive matching by default, but SQLite doesn't.
33:35 AQL tries to kind of like unify those where possible.
33:39 But also there's cases, especially when you're getting into joins or group buys, things like that, where the actual specific syntax being used will start to vary between the different backends.
33:50 And that's where we've had more issues, like especially the whole point of SQLite for a lot of people is as a drop in replacement to MySQL when you're running your unit tests.
33:58 And so you want your code to be able to do the same thing regardless of what database engine it's connected to.
34:03 And this is one way to do that.
34:04 Okay, that's cool.
34:05 Yeah, with SQLite, you can say the database lives in, you know, colon memory.
34:09 Yeah, exactly.
34:10 And then you can just tear it up for your unit tests and then it just goes away.
34:14 Nice.
34:14 So maybe that brings us to the next one, the aiosqlite.
34:18 Sure.
34:19 This one is all about async.io.
34:20 You can see from the example here.
34:22 You want to tell us about that?
34:23 Yeah, this was again, born out of, you know, a need for using SQLite, especially in testing frameworks and so forth to replace my SQL.
34:32 Cool.
34:33 And essentially what I was doing was taking the normal SQLite API from Python and essentially saying like, how would this look in an asyncio world?
34:44 Like if we were re-implementing SQLite from the ground up in an asyncio world, how can we do that?
34:50 And essentially, so in this case, we're heavily using async context managers and awaitables in order to actually run the database connection to SQLite on a separate thread and provide as much of an async interface to that as possible.
35:08 So when you connect to aiosqlite, it spawns a background thread that actually uses the standard SQLite library to connect to your database.
35:18 And then it has methods on that thread object that allow you to actually make calls into that database.
35:25 And those are essentially proxied through futures.
35:29 So if you want to execute a query, when you await that query execution, it will basically queue the function call on the other thread and basically tell it, here's the future to set when the result is ready.
35:45 So once the SQLite execution or cursor or whatever has actually completed doing what it's supposed to do on that background thread, it then goes back to the original threads event loop and says, you know, set this future to finished.
35:59 And so that allows the thing originally awaiting it to actually come back and do something with the result.
36:06 Yeah, it sounds a little tricky, but also super helpful.
36:08 And people might be thinking, didn't we just talk about the GIL and how threading doesn't really add much?
36:14 But when you're talking over the network or you're talking to other things, a lot of times the GIL can be released while you're waiting on the internal SQLite or something like that, right?
36:22 Yeah.
36:22 So the internal SQLite library on its own will release the GIL when it's calling into the underlying SQLite C library.
36:31 And that's where it's waiting.
36:32 So that's good.
36:32 Yeah.
36:33 The other side of this is that it's one thread.
36:36 I'm not really aware of anybody who's opening, you know, hundreds of simultaneous connections to a SQLite database.
36:43 The way that people expect to do with, say, like aiohttp or things like that.
36:48 So while it is, you know, potentially less efficient, if you wanted to do a whole bunch of parallel SQLite connections, the problem really is that SQLite itself is not thread safe.
36:59 So it has to have a dedicated thread for each connection.
37:02 Otherwise, you risk corruption of the backing database.
37:06 Which sounds not good.
37:07 Right.
37:07 Yeah.
37:07 It's like, basically, you end up either where two threads clobber each other or more specifically, what SQLite says is, if you absolutely try to talk to a connection from a different thread, the Python module will complain unless you've specifically told it, no, please don't complain.
37:24 I know it's unsafe, at which point SQLite will be really upset if you try to do a write or modification to that database.
37:31 So there are layers of protections against that, but it is one of the underlying limitations that we have to deal with in this case.
37:37 So if you wanted to have simultaneous connections to the same database, you really have to spin up multiple threads in order to make that happen safely.
37:45 You could always do some kind of thread pool type thing, like we're only going to allow eight connections at a time and you're just going to block until one of those becomes free and finished or whatever, right?
37:55 It's definitely a tricky thing.
37:57 So like the expected use case with aiosqlite is that you'll share the database connection between multiple workers.
38:04 So you'll like in the piece of your application that starts up, it would make the connection to the database and store that somewhere and then essentially pass that around.
38:13 And so aiosqlite is basically expecting to use a queue system to say whoever gets the query first is the one that, you know, gets to run it first.
38:22 And whoever asked for the query second, you know, is the second one to get it.
38:26 So you're still doing it all on one thread and it's slightly less performant that way, but it's at least safe and still asynchronous at least.
38:33 Yeah, that's good.
38:33 Very nice.
38:34 And one of the things that looking at your example here, which I'll link in the show notes, of course, is Python has a lot of interesting constructs around async and await.
38:43 You know, a lot of languages, you know, you think C# or JavaScript or whatever.
38:47 It's kind of async function await function calls.
38:50 We're good.
38:51 But, you know, we've got async with, async for, a lot of interesting extensions to working with async and other constructs.
38:58 Yeah, it actually makes it really nice in some ways.
39:01 And essentially these are just syntactic wrappers around a whole bunch of magic methods on objects.
39:07 Right.
39:07 Like await thing, enter, do your thing, right?
39:10 Then await exit.
39:11 Right.
39:12 The nice part is that for some amount of extra work in the library, setting up all those magic methods everywhere and deciding, you know, the right way to use them.
39:21 The benefit at the end is that you have this very simple syntax for asynchronously iterating over the results of a cursor.
39:28 In that case, you don't have to care that after, you know, 64 elements of iteration, you've exhausted the local cache and now SQLite has to go back and fetch the next batch of 64 items.
39:40 In that case, it's like that's transparent to your application.
39:43 And that's where the coroutine that's iterating over that cursor would then hand back its control of the event loop.
39:50 And the next coroutine in waiting essentially is able to then, you know, wake up and go do its own thing, too.
39:56 Oh, how cool.
39:57 I didn't even really think of it that way.
39:58 That's neat.
39:58 Maybe next one to touch on would be aiomultiprocess.
40:02 Sure.
40:03 It just now crossed a thousand stars today or recently.
40:06 Oh, yeah.
40:07 Yeah, it did.
40:07 Yeah, very recently.
40:08 That's awesome.
40:08 That's my real pride and joy here is getting all those stars.
40:11 There's this interesting dichotomy set up between threading and multiprocessing in Python.
40:16 So with multi-threading, you're able to interleave execution.
40:20 So with the gil, it means that only one thread can actually be modifying Python objects or running Python code at any given time.
40:28 So you're essentially limited to one core of your CPU.
40:31 And these days, that's a big limitation, right?
40:33 Right, right.
40:34 Exactly.
40:34 Like I see servers on a regular basis that are like 64 to 100 cores.
40:39 So only using one of them is basically a non-starter.
40:42 You get a lot of people with pitchfork saying, why aren't we using Rust?
40:46 And so essentially what the alternative of this multiprocessing, where you're spinning up an individual process and each has its own gil,
40:53 this does allow you for CPU intensive things to basically use all of the available cores on your system.
41:01 So if you're crunching a whole bunch of numbers with NumPy or something like that,
41:05 you could use multiprocessing and saturate all of your cores with no problem.
41:10 In this case, essentially what happens is it spawns a child process or forks the child process on Linux.
41:16 And then it uses a pickle module in order to send data back and forth between the two.
41:21 And this is great.
41:23 And it's really transparent.
41:24 So it's super easy to write code for multiprocessing and make use of that.
41:29 But the issue becomes if you have a whole bunch of really small things, you start to have a big overhead with pickling of the data back and forth.
41:36 Right.
41:36 And the coordination back and forth is like really challenging, right?
41:40 Yeah.
41:40 So like if you're pickling a whole bunch of smaller objects, you actually end up with a whole bunch of overhead from the pickle module where you're serializing and deserializing and creating a bunch of objects and, you know, synchronizing them across those processes.
41:53 But the real problem is when you start to want to do things like network requests that are IO bound.
42:00 In an individual process, like with multithreading, you could probably do 60 to 100 simultaneous network requests.
42:07 Right.
42:07 But you guys maybe have more than 60 servers or something.
42:10 Sure.
42:10 Right.
42:11 But like if you're trying to do this with multiprocessing instead, where you have like a process pool and you give it a whole bunch of stuff to work on, each process is only going to work on one request at a time.
42:21 So you might spin up a process and it waits for a couple seconds while it's doing that network request and then it sends it back and you haven't really gained anything.
42:29 So if you actually really want to saturate all your cores, now you need a whole bunch more processes.
42:34 And that then has the problem of a lot of memory overhead.
42:37 Because even if you're using copy on write semantics with forking, the problem is that like Python goes and touches all the ref counts on everything and immediately removes any benefit of copy on write forked processes.
42:49 Right.
42:49 Which might do like the shared memory, right?
42:51 So if I create 10 of these things, like 95% of the memory just might be one copy.
42:55 But if you start touching ref counts and all sorts of stuff, you know, Instagram went so far as to disable the garbage collector.
43:01 Right.
43:02 To prevent that kind of stuff.
43:03 It was insane.
43:03 Yeah.
43:04 So it turns out that if you fork a process, as soon as you get into that new process, Python touches like 60 to 70% of the objects and it's in the pool of memory, which basically means it now has to actually copy all of the memory from all of those objects.
43:20 And so you don't actually get to share that much memory between the child and the parent process in the first place.
43:26 So if you try to spin up, you know, a thousand processes in order to saturate 64 cores, you are wasting a lot, a lot of memory.
43:35 So that's where I kind of built this piece of aiomultiprocess, where essentially what it's doing is it's spinning up a process pool and it only spins up one per core.
43:46 And then on each child process, it then also spins up an asyncio event loop.
43:51 Right.
43:51 And rather than giving a normal synchronous function as the thing that you're mapping to a whole bunch of data points, you give a coroutine.
43:59 And in this case, what aiomultiprocess is capable of doing is essentially keeping track of how many in-flight coroutines each child process is executing.
44:09 And essentially being able to say that, like, if you wanted to have 32 in-flight coroutines per process and you had 32 processes, then of course you have whatever 32 times 32 is.
44:22 I can't do that in my head because I'm terrible at math.
44:25 Essentially, you get, you know, the cross product of those two numbers.
44:31 And that's the number of actual concurrent things that you can do on aiomultiprocess.
44:35 So the idea is like, instead of creating a whole bunch of one-off run this thing with these inputs over there, you say, well, let's create a chunk.
44:45 Like, let's go 32 here, 32 there and run them, but do that in an async way.
44:50 So you're scaling the wait times.
44:52 Yeah, exactly.
44:53 Anyway, right.
44:54 Because you're probably doing network stuff.
44:55 Yeah.
44:56 And the benefit of this is essentially like you're scaling the benefits of asyncIO with the benefits of multiprocessing.
45:03 So for math, that's easier for me to figure out.
45:07 In reality, what we've seen is that you can generally do somewhere around 256 concurrent network requests on asyncIO on a single process before you really start to overload the event loop.
45:20 Have you looked at some of the other event loop implementations like uvloop or any of those alternate event loop functions?
45:28 So uvloop can make things faster, but the things that it makes faster are the parts that process like network request headers.
45:35 The real problem at the end of the day is that the way that the asyncIO framework and event loops work is that for each task that you give them,
45:43 it basically adds it to a round robin queue of all of the things that it has to work on.
45:48 So at the end of the day, if you want to run a thousand concurrent tasks, that's a thousand things that it has to go through in order before it gets to any one task.
45:57 Right.
45:57 And it's going around asking, are you done?
45:59 Are you done?
45:59 Yeah.
45:59 Or something like that, basically.
46:01 And if you're doing anything with the result of that network request before you actually return the real result from your coroutine,
46:09 then you're almost certainly going to be starving the event loop of or starving other coroutines on the same event loop of processing power.
46:17 And so what we've seen actually is you end up with cases where you technically time out the request because it's taken too long for Python or asyncIO to get back to the network request before it hits like a TCP interrupt or something like that.
46:32 That's interesting.
46:32 Yeah.
46:33 So this way you could say like, well, throw 10 processes or 20 processes at it and make that shorter.
46:38 If you're willing to run 256 network requests per process and you have 10 processes or 10 cores, then suddenly you can run 2,500 network requests simultaneously from asyncIO and Python.
46:52 At that point, you're probably saturating your network connection unless you're talking to mostly local hosts.
46:58 At Facebook, when you're talking about a monitoring system, that's actually what you're doing is you're almost certainly talking to things that have super low latency to talk to and super high bandwidth.
47:07 And so this was essentially the answer to that is like run asyncIO event, asyncIO event loops on a whole bunch of child processes, and then do a bunch of really like smart things to balance the load of the tasks that you're trying to run across all of those different processes in order to try and make them execute as quickly as possible.
47:29 And then also, whenever possible, try to reduce the amount of times that you're serializing things back and forth.
47:35 So one of the other common things that having more processes enables you to do is actually do some of the work to process, filter, aggregate that data in those child processes, rather than pickling all the data back to the parent process and then, you know, dealing with it and aggregating it there.
47:53 Right, because you've already got the like scale out for CPU cores.
47:56 Yeah, so it kind of gives like a local version of MapReduce, where essentially you're mapping work across all these child processes, and then inside each batch or whatever, you're aggregating that data into the result that you then send back up to the parent process, which can then process and aggregate that data further.
48:13 Yeah, super cool. You gave a talk on this at PyCon in Cleveland, one of the last real actual in-person PyCons.
48:20 Yeah, first one I've ever attended and the first one that I've ever given a talk at.
48:25 Yeah, that was a good one, the one in Cleveland.
48:27 Yeah, the room was absolutely massive and terrifying, and I don't know how I managed to do it all.
48:32 Yeah, it's just kind of block it out, block it out. But no, it's all good. Cool, yeah, so I'll link to that as well. People can check that out. And it really focuses on this aiomultiprocess part, right?
48:41 Yeah. Nice. All right, last of the AIO things at OmniLib is aioitertools.
48:48 Yeah, so you kind of hinted on this before, like iter tools is mostly a bunch of helpers that let you process lists of things or iterables in nicer ways. And aioitertools is just basically taking the built in functions, like iterating, getting the next thing from an iterable or mapping, or chaining between multiple iterables or whatever.
49:11 And essentially bringing that into an async first world. So all of the functions in aioitertools will accept both like normal standard iterators or lists or whatever, as well as async iterables or generators or whatever.
49:27 And essentially, it up converts everything to an async iterable, and then gives you more async iterable interfaces to work on these.
49:36 So I know how to create a generator with like yield. So I can have a function, it does a thing, and then it goes through some process and it says yield an item, like here's one of the things in the list.
49:46 That's already really good because it does like lazy loading, but it doesn't scale the waiting time, right? It just waits.
49:52 So for the async generator, what's the difference there?
49:55 In this case, Never tried one of those.
49:57 If you just call the function async def and then have a yield statement in it, it creates an async generator, which is just an async iterable object that similar to how when you call a coroutine, it's an object, but it doesn't actually run until you await it.
50:13 With an async generator, calling it creates the generator object, but you don't actually...
50:18 Then the async part is done, right? At that point.
50:20 Well, it's like it doesn't, it still doesn't even start running it until you actually start to use the async for some other async iteration to then iterate over it.
50:30 If you're using the async iterator, you still get the lazy loading of everything like with a normal generator, but you also have the potential for your thing to be interrupted.
50:38 The common use case here or the expected use case would be if you're doing something like talking to a whole bunch of network hosts and you want to return the results as they come in,
50:50 as an async iterable, then you could use something like aioitertools to then do things like batch up those results or run another coroutine across every result as it comes in, things like that.
51:02 The other added benefit in here is that there's also a concurrency limited version of gather.
51:08 So as I said earlier, when you have a whole bunch of tasks, you're actually making the event loop do a whole bunch more work.
51:13 One of the common things I've seen is that people will spawn 5000 tasks and each task or they'll all have some semaphore that limits how many of them can execute at once.
51:24 But you still have 5000 tasks that the event loop is trying to service.
51:28 And so you're giving a whole bunch of overhead every time it wants to switch between things.
51:33 It's got to potentially go through up to 5000 of them before it gets to one that it can actually service.
51:38 So the concurrency limited version of gather that aioitertools has lets you specify some limit, like only run 64 things at a time.
51:47 And so it will, you know, try to fetch the first 64 things of all of the coroutines or awaitables that you give it.
51:55 And it will start to yield those values as they come in.
51:57 But essentially, it's making sure that the event loop would never see more than 64 active tasks at a time, at least from that specific use of it.
52:05 Yeah, yeah, they're just hanging out of memory.
52:07 They don't really get thrown into the running task.
52:10 So one of the challenges or criticisms almost I've seen around asyncio is that it doesn't allow for any back pressure or whatever, right?
52:20 Like if I'm talking to a database, it used to be that the web front end would have like some kind of performance limit.
52:25 It could only go so hard against the database.
52:27 But if you do just await it, like all the traffic just piles in until it potentially can't take it anymore.
52:33 And it sounds like this has some mechanisms to address that kind of generally speaking.
52:38 That's at least the general intent of it is to be able to use this concurrency limit to try and prevent overloading either the event loop or your network or whatever.
52:47 So even if you have 5000 items, by setting the limit to 64, you know that, you know, you're only going to be doing that many at a time.
52:55 And then you can combine that that concurrency limited gather with something like the result of that is its own async iterable.
53:02 And then you could also combine that with things like chain or other things in order to mix that in with the rest of the like iter tools functional lifestyle, if you will.
53:13 Yeah, yeah, yeah.
53:14 Super cool.
53:15 I can imagine that these might find some way to work together.
53:18 You might have some asyncio, aioitertools thing that then you feed off to aiomultiprocess or something like that.
53:26 Do you put these together any?
53:28 Yeah, exactly.
53:29 These are definitely a whole bunch of tools that I've put together in various different use cases.
53:33 Yeah, very neat.
53:34 All right.
53:35 Well, we're getting quite near the end of the show.
53:37 I think we've talked about a lot about these very, very cool libraries.
53:41 So before we get out of here, though, we touched on this at the beginning, but I'll ask you this as one of the two main questions at the end of the show.
53:47 If you're going to write some Python code, what editor do you use?
53:50 The snarky answer is anything with a Vim emulation mode.
53:53 That was the thing that I learned in college.
53:55 And I specifically avoided answering that earlier when we were talking about it.
54:01 But that's what I learned when I was writing a whole bunch of PHP code.
54:04 And that's what I used for years.
54:06 And then eventually I found Sublime Text.
54:09 And I really liked that.
54:10 But it kind of seemed dead in the water.
54:12 Adam came out, but Adam was slow.
54:15 And so these days I'm using VS Code primarily because it has excellent Python integration, but also because it has a lot of like Facebook builds a lot of things that we used to have on top of Adam called Nuclide, which especially were a lot of like remote editing tools.
54:31 Okay.
54:32 We've rebuilt a lot of those on top of VS Code because VS Code is faster, nicer, you know, has better ongoing support from the community and so forth.
54:40 Nice.
54:40 Yeah.
54:40 VS Code seems like the natural successor to Adam.
54:43 Yeah.
54:43 And like I said before, it's like I had tried PyCharm at one point, but it's one of those cases where I touch just enough stuff that's not Python that I really want my tools to work and function the same way regardless.
54:55 And so VS Code has the better sort of like broader language support where it's like there's some days where I just have to write a bash script and I want it to be able to do nice things for bash or, you know, I use it as a markdown editor and it has a markdown preview.
55:09 Things like that.
55:10 Yep.
55:10 All right.
55:11 Cool.
55:11 Sounds good.
55:11 And then notable PyPI package.
55:13 I mean, I guess we spent a lot of time on four of them, right?
55:15 Yeah.
55:16 I've also talked about microsort, usort.
55:18 Yeah.
55:19 So the joke answer is I have a package called aioseinfeld that's built on top of aiosqlite.
55:25 And essentially you give it a database of Seinfeld scripts and you can search for things by actor or by keyword of what they're saying.
55:35 And it will essentially give you back some elements of dialogue from a script that contains your search query.
55:42 And this is powering a site I have called seinfeldquote.com, which is basically just a really old bootstrap template that lets you search for pieces of Seinfeld quotes.
55:53 I also implemented a chat bot in Discord for some of my friends that also uses this.
55:59 The more serious answer would be the other one that we didn't talk about from OmniLib, which is attribution, which is essentially a quick program to automate the generation of change logs and to automate the process of cutting a release for a project.
56:14 And so I use this on all of the OmniLib projects.
56:16 And essentially I type one command attribution release.
56:20 I'm sorry, attribution tag and then a version number.
56:23 And it will drop a dunder version.py in the project directory.
56:29 It will create a get tag.
56:32 It lets you then type in what you want the release notes to be.
56:35 It's assuming, you know, a markdown format.
56:37 And then once it's made that tag, then it regenerates the change log for that tag and retags it appropriately.
56:44 And so you get this really nice thing where the actual tag of the project has both the updated change log and the appropriate version number file.
56:52 So you only ever type the version in once.
56:55 You only ever type the release notes in once.
56:57 And it gives you, you know, as much help and automation around that as possible.
57:02 Oh, yeah.
57:02 Okay, very cool.
57:03 That's a good one.
57:04 All right.
57:04 Final call to action.
57:05 If people are excited about AsyncIO, maybe some of the stuff at OmniLib, they want to get started.
57:10 What do you tell them?
57:11 If they want to get started on the projects, going to omnilib.dev is the easiest way to find the ones that are currently hosted on the project.
57:19 We're always welcoming of code review from the community.
57:22 So even if you're, you know, not a maintainer, if you are interested in reviewing pull requests and giving feedback on things, always welcoming of that.
57:32 There's never enough time in my own personal life to review everything or respond to everything.
57:36 Otherwise, if there are things in these projects that you are interested in adding, like new features or fixing bugs or whatever, either open an issue or just create a pull request.
57:46 And I am more than happy to engage in design decisions or discussions or whatever.
57:52 Make sure that ideally, if you open an issue first, make sure you're not wasting your time on a pull request that's going in the wrong direction.
57:59 Right, right.
57:59 Because people might have this idea, but you're like, this is really inconsistent where this project is going to go or whatever.
58:05 So even if it's perfect, you can't accept it, right?
58:08 So good advice.
58:09 If it's just like a bug fix or something, then, you know, probably just worth creating a pull request and I'm not going to bite your head off.
58:15 But otherwise, the only other thing I would say is that LGBTQ things are very personal to me.
58:22 And so I would ask that if you're in a position to do so, that you please donate to an LGBTQ charity that will help in the community.
58:30 There's two that I really like.
58:32 One is called Power On.
58:34 And that's a charity that donates technology to LGBTQ youth.
58:39 They're either homeless or disadvantaged.
58:41 And they have that at poweronlgbtq.org.
58:45 And then the other one is the Trevor Project, which is crisis intervention and a suicide hotline for LGBTQ youth.
58:52 And that's at thetrevorproject.org.
58:54 Yeah, awesome.
58:55 Those are just two examples, but there are plenty.
58:57 Worst case, just donate to a food bank near you.
58:59 Cool.
59:00 Yeah, that's a great advice.
59:01 Great call to action.
59:02 Seems like your projects are also really open to new contributors, people getting into open source.
59:06 So participating in that way seems like a great thing.
59:10 Fantastic.
59:10 All right, John.
59:11 Well, thank you so much for being on Talk Python.
59:13 It's been great to have you here.
59:14 Thank you for having me so much.
59:15 I really appreciate it.
59:16 This has been another episode of Talk Python To Me.
59:19 Our guest on this episode was John Reese, and it's been brought to you by Linode and Talk Python Training.
59:25 Simplify your infrastructure and cut your cloud bills in half with Linode's Linux virtual machines.
59:30 Develop, deploy, and scale your modern applications faster and easier.
59:33 Visit talkpython.fm/Linode and click the Create Free Account button to get started.
59:38 Want to level up your Python?
59:40 We have one of the largest catalogs of Python video courses over at Talk Python.
59:44 Our content ranges from true beginners to deeply advanced topics like memory and async.
59:49 And best of all, there's not a subscription in sight.
59:52 Check it out for yourself at training.talkpython.fm.
59:54 Be sure to subscribe to the show.
59:57 Open your favorite podcast app and search for Python.
59:59 We should be right at the top.
01:00:01 You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:00:06 and the direct RSS feed at /rss on talkpython.fm.
01:00:10 We're live streaming most of our recordings these days.
01:00:14 If you want to be part of the show and have your comments featured on the air,
01:00:17 be sure to subscribe to our YouTube channel at talkpython.fm/youtube.
01:00:21 This is your host, Michael Kennedy.
01:00:23 Thanks so much for listening.
01:00:24 I really appreciate it.
01:00:26 Now get out there and write some Python code.
01:00:28 I'll see you next time.
01:00:48 Thank you.