Modern Python monorepo with uv and prek



Panelists


On this episode, I sit down with Jarek Potiuk and Amogh Desai, two of Airflow's top contributors, to go inside one of the largest open-source Python monorepos in the world and learn how they manage it with uv, pyproject.toml, and the latest packaging standards, so you can apply those same patterns to your own projects.
Episode Deep Dive
Guests
Jarek Potiuk is an Apache Airflow maintainer, PMC (Project Management Committee) member, Apache Software Foundation member, and Airflow security committee member. He is the number one all-time contributor to Apache Airflow by PR count and is one of the few developers fortunate enough to contribute to open source full time as his paid work. Jarek previously worked at Google, where he first encountered the monorepo approach at massive scale. He authored the four-part blog series "Modern Python Monorepo for Apache Airflow" on Medium and delivered a talk on the same topic at FOSDEM 2026.
Amogh Desai is a PMC member and committer on Apache Airflow, and one of the top 10 all-time contributors to the project. He works at Astronomer as a senior software engineer, where he contributes to Airflow's core development and supports companies running Airflow at scale. Amogh has been instrumental in the recent shared libraries work and the ongoing decomposition of the Airflow monorepo into isolated distributions.
What to Know If You're New to Python
If you are newer to Python and want to get the most out of this episode's analysis, here are a few things to understand going in:
- pyproject.toml is the modern standard configuration file for Python projects, replacing older files like setup.py and setup.cfg. It declares your project's metadata, dependencies, and build settings all in one place.
- Virtual environments are isolated Python installations that let you install packages for one project without affecting another. Tools like uv automate their creation and management.
- Packages and distributions in Python refer to reusable bundles of code that can be installed via pip or uv. A monorepo can contain many of these, each with its own pyproject.toml and release cycle.
- Pre-commit hooks are automated checks that run on your code before you commit changes to version control, catching issues like formatting errors, bad imports, or failing tests early.
Key Points and Takeaways
1. uv workspaces are the key enabler for modern Python monorepos
The single most impactful tool discussed in this episode is uv and specifically its workspace feature. A uv workspace lets you define a top-level pyproject.toml that lists all sub-packages in your monorepo, and uv then understands how they relate to each other. When you cd into any sub-package directory and run uv sync, it automatically builds a virtual environment containing only the dependencies declared by that package -- including other workspace packages from source, not from PyPI. This means if Airflow CTL does not depend on Airflow Core, you simply cannot import Core's code after syncing in the CTL directory. The result is true dependency isolation enforced by the tool, not by convention or linting rules alone. As Jarek put it, the developer experience is "just go to the directory and run uv sync -- that's basically it." uv also automatically uninstalls packages that should not be present, preventing the "mystery dependency" problem that plagued the old workflow.
- github.com/astral-sh/uv -- Extremely fast Python package and project manager, written in Rust
- docs.astral.sh/uv/concepts/workspaces/ -- uv workspaces documentation
2. A monorepo is not a monolith -- and modern tooling has settled the debate
One of the first and most important distinctions the guests draw is that a monorepo and a monolith are fundamentally different things. A monorepo keeps multiple independently buildable, testable, and releasable packages in a single repository. Each sub-package can have its own pyproject.toml, its own virtual environment, its own dependencies, and its own release cycle. Jarek first encountered this pattern at Google, where hundreds of products lived in a single repository despite being architecturally separate. His strong claim by the end of the episode is that the monorepo-versus-multirepo debate "is already solved" -- the reasons teams previously chose multirepo (isolation, independent workflows) are now handled by tooling like uv and prek, while all the benefits of co-location (unified testing, atomic cross-package changes, simpler CI) remain.
- medium.com/apache-airflow/modern-python-monorepo-for-apache-airflow-part-1-1fe84863e1e1 -- Part 1: Pains of big modular Python projects
- medium.com/apache-airflow/modern-python-monorepo-for-apache-airflow-part-2-9b53e21bcefc -- Part 2: Modern Python packaging standards and tools
3. Apache Airflow is a real, open-source proving ground you can study
Unlike talks that reference closed-source internal systems at large companies, everything discussed in this episode is open source and publicly accessible. Apache Airflow has over 1.2 million lines of Python (918,000 excluding comments), 120+ separate distributions inside one Git repository, 16,000 lines of TOML, 81,000 lines of YAML, and sees roughly 310 active pull requests per week with 200+ merged. This scale makes Airflow one of the largest and most active open-source Python monorepos in the world. Listeners can clone the repo and see exactly how the workspace is configured, how prek hooks are organized per-module, and how shared libraries are symlinked.
- github.com/apache/airflow -- Apache Airflow source code on GitHub
- github.com/mikeckennedy/tallyman -- Tallyman, the code analysis tool Michael used to generate the line-count breakdown
4. prek replaces pre-commit with speed, workspaces, and openness to contributions
prek is a Rust-based reimagining of the pre-commit framework. For Airflow, prek brought three critical improvements: raw speed from being a single compiled binary, workspace-aware hooks that can be defined per sub-module rather than in one monolithic YAML file, and shell tab-completion for hook names. The Airflow team had previously tried to contribute autocompletion and modular hooks to pre-commit but the maintainer declined those contributions. When they approached Joe (prek's author), the response was dramatically different -- autocompletion was added the next day, and workspace support followed within weeks. prek is already used by CPython, Apache Airflow, and FastAPI, and its collaborative development model was a major factor in the Airflow team's adoption.
- github.com/j178/prek -- prek on GitHub
- prek.j178.dev -- prek documentation
5. PEP 723 (inline script metadata) and PEP 735 (dependency groups) are foundational
Two Python Enhancement Proposals were highlighted as especially important for making the monorepo workflow practical. PEP 723 allows embedding dependency and Python version metadata directly inside a single .py file using a special comment block, which means CI scripts and pre-commit hooks can declare their own requirements without external configuration files. This dramatically simplified Airflow's pre-commit setup and reduced YAML. PEP 735 introduced dependency groups in pyproject.toml, letting you define named sets of requirements (like "dev" or "test") that are not included in the built package. Both Jarek and Amogh praised these PEPs, and Jarek noted that support for inline script metadata has now landed in pip 26 as well, making it a truly cross-tool standard.
- peps.python.org/pep-0723/ -- PEP 723: Inline script metadata
- peps.python.org/pep-0735/ -- PEP 735: Dependency Groups in pyproject.toml
6. Shared libraries via symlinks solve the DRY-vs-coupling tradeoff
One of the most innovative aspects of Airflow's monorepo is its "shared libraries" pattern. Common utilities like logging and configuration need to be reused across many distributions (DRY principle), but depending on a single shared package creates tight coupling and backward-compatibility headaches when distributions are released at different times. The solution: symlink the shared library source into each consuming distribution, and at build time, the code is vendored (embedded) directly into the target package. This means two distributions released weeks apart can each contain their own snapshot of the shared library without version conflicts. Jarek compared this to the distinction between static and dynamic libraries in C -- Airflow gets the equivalent of static linking for Python. The approach is maintained automatically by prek hooks that ensure symlinks, pyproject.toml entries, and hatch build configuration stay in sync.
- medium.com/apache-airflow/modern-python-monorepo-for-apache-airflow-part-4-c9d9393a696a -- Part 4: Shared "static" libraries in Airflow monorepo
7. Collaboration with tool authors shaped the ecosystem
A recurring theme is that the Airflow team did not just wait for tools to appear -- they actively shaped them. Jarek worked directly with Charlie Marsh (Astral/uv) and Joe (prek) to communicate Airflow's needs as one of the largest Python monorepos. Charlie even interviewed Jarek about their requirements. The Airflow team served as an early testing ground, filing issues and providing feedback on pre-release versions. This collaboration produced features (like uv workspaces and prek workspace-aware hooks) that benefit the entire Python ecosystem. Jarek's motto captures the philosophy well: "The best way to foresee the future is to shape it." Hatch, maintained by Ofek Lev, is also implementing compatible workspace support modeled after what uv established.
- github.com/pypa/hatch -- Hatch: Modern, extensible Python project management
8. The Apache Software Foundation provides a vendor-neutral governance model
Jarek explained that the Apache Software Foundation (ASF) is one of the oldest open-source foundations in the world (25+ years), and it operates on an individual-driven, meritocratic model. Members are people, not corporations, and all decision-making roles (PMC members, board members, VPs) are volunteer positions. The foundation is registered as a US public charity and legally cannot be sold or change its license. Airflow is one of over 200 PMCs under the ASF umbrella, and the foundation recently passed 10,000 committers. The ASF's motto is "community over code" -- believing that great code is a byproduct of great communities working together.
- apache.org -- The Apache Software Foundation
- astronomer.io -- Astronomer, the leading commercial contributor to Apache Airflow
9. AI-generated contributions are a growing challenge for open-source maintainers
Both guests acknowledged that AI-assisted code generation is a double-edged sword. The Airflow team themselves use AI tools extensively for writing code, and roughly a third of open pull requests in a given week are high quality and get merged. However, AI has also enabled a wave of low-effort, "shotgun" contributions from people seeking to pad their contributor profiles or claim bug bounties. Jarek referenced Daniel Stenberg's decision to close curl's bug bounty program for similar reasons. The Airflow team has published contribution guidelines, is working with GitHub on platform-level responses, and is collaborating with OSSF on security-focused policies. Their key principle: make it more expensive for reporters to submit low-quality issues than for maintainers to diagnose them.
10. Forcing isolation improved Airflow's internal architecture
An unexpected benefit of the monorepo restructuring was a significant improvement in Airflow's internal code architecture. Before the split, shared utilities had circular dependencies, implicit initialization order during imports, and "complete spaghetti" of cross-references. By requiring each distribution to declare its dependencies explicitly and enforcing isolation through uv workspaces, the team was forced to adopt dependency injection, explicit initialization via entry points, and factory patterns. Amogh noted this now gives each component a clear starting point, similar to a main() function in Go or Java. The result is code that is easier to reason about, onboard new contributors to, and maintain long-term.
11. IDE integration requires helper scripts but works well
With 120+ sub-packages, IDEs like PyCharm and VS Code cannot automatically discover all source roots and test directories. The Airflow team maintains helper scripts that auto-discover every package in the monorepo and configure the IDE accordingly. For PyCharm/IntelliJ, the script writes XML configuration in the .idea directory to mark each package's src/ as a source root and tests/ as a test root. A community contributor created the equivalent script for VS Code. Running these scripts replaces what would otherwise be manually right-clicking on 120+ directories to "mark as sources root."
12. "Mini services" as a pragmatic middle ground
Michael expressed skepticism about microservice architectures, arguing they trade code complexity for DevOps complexity. Jarek offered his own term -- "mini services" -- as a more practical middle ground. The idea is that services should be meaningfully sized rather than excessively decomposed. The monorepo approach supports this by letting teams develop and test many services together in one place while still building and deploying them independently. This avoids both the rigidity of a monolith and the operational overhead of dozens of tiny microservices.
Interesting Quotes and Stories
"The discussion on monorepo versus multi-repo is already solved." -- Jarek Potiuk
"The best way to foresee the future is to shape it." -- Jarek Potiuk, on collaborating with tool authors like Charlie Marsh (uv) and Joe (prek)
"It's effortless, almost effortless compared to what we had years, maybe like five years ago, four years ago." -- Amogh Desai, on the developer experience after adopting uv workspaces
"We value building communities more than actually producing code. We believe producing code is just a byproduct of great communities working together." -- Jarek Potiuk, on the Apache Software Foundation's philosophy
"I don't think this would be possible with AI, in the sense that this has never been done before." -- Amogh Desai, on the shared libraries symlink approach being a novel solution that required human collaboration
"I'm not a big fan of microservice architectures. I kind of find it's trading code complexity for DevOps and deployment complexity. And I think we have better tools to manage code complexity than DevOps complexity." -- Michael Kennedy
"We need that -- and next day it was there. It's like a completely different approach." -- Jarek Potiuk, contrasting prek's responsiveness to feature requests versus their experience with pre-commit
Jarek shared the story of Airflow's CI and build system previously requiring over 10,000 lines of Bash scripts that he personally wrote and maintained. The team eventually converted these to Python through an outreach internship, but the real turning point came when uv and prek matured enough to replace much of that custom tooling entirely.
Amogh recalled the "nightmare" of switching branches or rebasing before the monorepo tooling was in place -- packaging would break, environments would become inconsistent, and he would frequently rant on Slack channels about things not working. The contrast with the current workflow, where uv sync handles everything, was stark.
The team also shared how Hugo van Kemenade, the CPython release manager, overheard their prek discussion at FOSDEM and subsequently converted CPython to use prek -- a perfect example of the open-source word-of-mouth effect.
Key Definitions and Terms
- Monorepo: A single version-controlled repository containing multiple independently buildable, testable, and releasable packages or projects. Not to be confused with a monolith.
- Monolith: A single, tightly coupled application deployed as one unit. Architecturally distinct from a monorepo.
- Workspace (uv): A feature that lets uv understand multiple related Python packages within a single repository, resolving inter-package dependencies from local source rather than PyPI.
- Distribution: In Python packaging, a built artifact (wheel or sdist) that can be installed via pip or uv. Each sub-package in Airflow's monorepo is its own distribution.
- PMC (Project Management Committee): The governing body for an Apache Software Foundation project, composed of individual volunteers who make technical and community decisions.
- Vendoring: Embedding a copy of a dependency's source code directly into your own package rather than declaring it as an external dependency. Airflow uses this via symlinks for shared libraries.
- PEP (Python Enhancement Proposal): The formal process for proposing changes to Python. PEPs discussed in this episode include 723 (inline script metadata) and 735 (dependency groups).
- Symlink (symbolic link): A filesystem reference that points to another file or directory. Airflow uses symlinks to share library code across distributions without creating package dependencies.
- DRY (Don't Repeat Yourself): A software design principle aimed at reducing duplication. In a monorepo context, DRY must be balanced against coupling between packages.
- Pre-commit hooks: Scripts that run automatically before a git commit is finalized, used to enforce code quality, formatting, and correctness checks.
- Inline script metadata (PEP 723): A standard for embedding dependency declarations directly in Python script files using specially formatted comments, enabling tools like uv to auto-install requirements when running a script.
Learning Resources
Here are courses from Talk Python Training that connect to topics covered in this episode, helping you go deeper on the tools, patterns, and Python fundamentals discussed:
- Managing Python Dependencies: Covers virtual environments, pip, and dependency management best practices -- the foundational concepts behind everything uv automates in this episode.
- Modern Python Projects: Walks through project structure, dependency management, testing, CI, and deployment -- all the building blocks you need before tackling a monorepo.
- Getting started with pytest: Testing is central to the monorepo workflow discussed here, where
uv run pytestin any sub-package runs isolated tests. This course teaches pytest from the ground up. - Up and Running with Git: Since the entire episode revolves around managing a massive Git repository, solid Git fundamentals are essential context.
- Python for Absolute Beginners: If you are just starting your Python journey, this course covers the foundational concepts you will need before exploring packaging, dependencies, and project structure.
Overall Takeaway
This episode delivers something rare in the monorepo conversation: a fully open, concrete, production-scale example you can study line by line. Apache Airflow's 1.2-million-line Python monorepo with 120+ distributions is not a theoretical exercise -- it is a living project with 300+ pull requests per week, maintained by a global community of volunteers. The message from Jarek and Amogh is clear and optimistic: the Python packaging ecosystem has matured to the point where the old tradeoffs that pushed teams toward multi-repo setups have largely disappeared. With uv workspaces providing dependency isolation, prek enabling modular per-package pre-commit hooks, and PEPs like 723 and 735 standardizing inline metadata and dependency groups, the tooling finally matches the ambition. Perhaps most inspiring is the collaborative spirit behind it all -- tool authors, open-source maintainers, and community contributors working together across projects to solve shared problems. Whether you are managing three packages or three hundred, the patterns demonstrated here are accessible, standards-based, and ready to adopt. As both guests said: just do it.
Links from the show
Amogh Desai: github.com
Jarek's GitHub: github.com
definition of a monorepo: monorepo.tools
airflow: airflow.apache.org
Activity: github.com
OpenAI: airflowsummit.org
Part 1. Pains of big modular Python projects: medium.com
Part 2. Modern Python packaging standards and tools for monorepos: medium.com
Part 3. Monorepo on steroids - modular prek hooks: medium.com
Part 4. Shared “static” libraries in Airflow monorepo: medium.com
PEP-440: peps.python.org
PEP-517: peps.python.org
PEP-518: peps.python.org
PEP-566: peps.python.org
PEP-561: peps.python.org
PEP-660: peps.python.org
PEP-621: peps.python.org
PEP-685: peps.python.org
PEP-723: peps.python.org
PEP-735: peps.python.org
uv: docs.astral.sh
uv workspaces: blobs.talkpython.fm
prek.j178.dev: prek.j178.dev
your presentation at FOSDEM26: fosdem.org
Tallyman: github.com
Watch this episode on YouTube: youtube.com
Episode #540 deep-dive: talkpython.fm/540
Episode transcripts: talkpython.fm
Theme Song: Developer Rap
🥁 Served in a Flask 🎸: talkpython.fm/flasksong
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Monorepos. You've heard the talks, you've read the blog posts, maybe you've seen a few glimpses into how Google or Meta organized their massive code bases, but it's often in the abstract and behind closed doors.
00:11 What if you could crack open a real production monorepo, one with over a million lines of Python code and over a hundred sub-packages, and actually see what's being built step-by-step using modern tools and standards?
00:24 Well, that's exactly what Apache Airflow gives us. On this episode, I sit down with Jarek Potiuk and Amogh Desai, two of Airflow's top contributors, to go inside one of the largest open-source Python monorepos in the world and learn how they manage it with uv, pyproject.toml, and the latest packaging standards, so you can apply the same patterns to your own projects.
00:47 This is Talk Python To Me, episode 540, recorded February 10th, 2026.
00:52 Welcome to Talk Python To Me, the number one Python podcast for developers and data scientists.
01:14 This is your host, Michael Kennedy. I'm a PSF fellow who's been coding for over 25 years. Let's connect on social media.
01:21 You'll find me and Talk Python on Mastodon, Bluesky, and X. The social links are all in your show notes.
01:28 You can find over 10 years of past episodes at talkpython.fm, and if you want to be part of the show, you can join our recording live streams.
01:35 That's right, we live stream the raw, uncut version of each episode on YouTube.
01:40 Just visit talkpython.fm/youtube to see the schedule of upcoming events.
01:44 Be sure to subscribe there and press the bell so you'll get notified anytime we're recording.
01:48 This episode is brought to you by our Agentic AI Programming for Python course.
01:53 Learn to work with AI that actually understands your code base and build real features.
01:58 Visit talkpython.fm/Agentic-AI.
02:02 Hello, hello, Jarek, Amogh. Welcome to Talk Python To Me.
02:06 Awesome to have Amogh, you here, and Jarek, you back.
02:09 Very nice to be again at Talk Python To Me. It's one of my favorite podcasts I listen to all the time.
02:15 Thank you, thank you.
02:15 It's my first, but yeah, thanks for having me, Mike.
02:18 Happy to have you here.
02:19 You and a team of people, given the scale of this project, have built an amazing, amazing product with Apache Airflow.
02:26 It's going to be really fun to dive into it, and specifically, we're going to focus on not building workflows exactly,
02:33 although I'm sure we'll talk about that somewhat.
02:35 The real goal, the thing that we're going to focus on, is how do you manage such a big project
02:40 with so many different internal packages that all depend upon each other and so on,
02:45 and monorepos, and that.
02:47 I've touched on monorepos before, but two things.
02:50 I think this makes a really interesting discussion for listeners out there.
02:53 One, this is going to be very concrete with exact steps, and it's even open source.
02:58 You can go check it out and play with it.
03:00 And two, the tooling and the standards have changed significantly since I talked about this three or four years ago,
03:06 making much of what we're going to talk about possible, right?
03:09 Absolutely.
03:09 Yeah.
03:10 Now, before we dive into that, of course, let's do quick introductions.
03:15 Jarek, it's been a while since you've been on the show.
03:16 Who are you?
03:17 Tell people who you are.
03:18 I'm an Apache Airflow maintainer, one of the PMC members as well, and also one of the Apache Software Foundation members.
03:26 I've got this nice, thin new logo of Apache Software Foundation that we got at FOSDEM.
03:30 I'm also an Apache Airflow security committee member, which is an important aspect for what we are discussing today
03:38 because of supply chain and dependencies and lots of security, potential security issues these dependencies bring.
03:48 One of the few lucky people to contribute to open source full-time and get paid for it,
03:53 which is amazing.
03:54 Maybe another podcast one day about that, because I think that's also an interesting one.
03:59 Yeah, I have something like that, a topic somewhat like that brewing.
04:02 So, yeah, potentially to have you back for that.
04:04 Hey, I'm Amogh Desai.
04:05 Again, similar to Jarek, I'm a PMC member and a computer at Apache Airflow.
04:10 And I'm also part of, I'm one of the top 10 contributors to the project,
04:15 top 10 all-time contributors to the project, Jarek being number one.
04:18 So I work at Astronomer as a senior software engineer, where I get to live in both worlds.
04:24 One is contributing to Airflow's code development and also supporting the companies that are trying to run Airflow at scale.
04:31 Awesome. What is Astronomer? Tell people about that.
04:33 It's a company where most of our, we're a company which is almost one of the leading contributors
04:39 to Apache Airflow and also the leading consumer of it.
04:42 We supply and we provide a managed distribution of, corporate managed distribution of Apache Airflow inside Astro.
04:49 And yeah, I think we have a data platform as well to try and make your lives easier to use Airflow at scale.
04:56 And let me ask to it, two comments.
04:59 So Airflow has a number of stakeholders and commercial stakeholders who are hosting Airflow as a service as well.
05:06 And, you know, like using Airflow, we have contributions from all over the place.
05:10 Astronomer by far, like the biggest number of contributions and fantastic open source stakeholder.
05:15 We like very much focused on making Apache Airflow, like truly vendor neutral Apache project.
05:21 Like I'm always amazed how well this works.
05:25 And the second thing, the number one, I'm cheating a bit.
05:27 Like, you know, I do a lot of small PRs.
05:29 This is how you get the number one.
05:30 I guess it depends how you measure it, huh?
05:32 You know, you could always just do one ginormous AI PR that's like a hundred thousand lines of code in your PR
05:39 and people would love you for it.
05:40 And you'd be a mega contributor.
05:42 Oh, yeah.
05:43 Well, not.
05:44 He does both.
05:45 The funny part is Jarek does both.
05:47 His velocity amazes me or, I don't know, shocks me sometimes.
05:50 He does massive PRs and also like a lot of tiny ones.
05:54 And by the time I'm looking, there are like three more out of it.
05:56 I don't know how he does it.
05:57 We're going to get to a bit of how much traffic there is on Airflow in terms of like open source activity.
06:04 It's some, it's a little bit.
06:05 Before we move on though, Jarek, what is the Apache Software Foundation?
06:09 What is this Apache thing that you're talking about?
06:12 And why is Airflow part of it?
06:13 Very quickly.
06:14 It's a foundation.
06:15 One of the oldest foundations, open source foundation in the world.
06:18 25, 26, seven years now.
06:20 I think the main thing about Apache Software Foundation is that it's individual driven.
06:24 So every member is an individual, not a corporate, as opposed to like Linux Software Foundation,
06:29 where members are corporates.
06:30 And people make decisions in both foundation and projects or PMCs, so-called project management committees.
06:39 And Airflow is one of the PMCs.
06:41 So one of the project management committees, which has PMC members.
06:45 We are both PMC members and we have like 50 other individuals or 60.
06:50 I can't remember like the number of changes.
06:52 Like we are inviting new ones all the time.
06:54 We make decisions as humans, as individuals, not the corporates who are employing us, for example,
06:59 because it's a meritocracy-based system where people have merit and the merit doesn't expire
07:07 and the merit doesn't belong to individuals, not to the corporates.
07:11 That's one of the big, like pretty much all the open source software out there, like has some Apache Foundation
07:18 or Apache Complement in it.
07:20 It started with Apache Server 20, 30 years ago almost.
07:24 But now we have more than 200 PMCs.
07:27 We just passed 10,000 committers mark two months ago, I think.
07:32 So like lots of individuals, lots of people contributing to the foundation.
07:36 And the main thing about foundation is community over code.
07:39 So we value building communities more than actually producing code.
07:42 We believe producing code is just byproduct of great communities working together.
07:48 And ASF is a charity, is a public good charity in the US registered in Delaware.
07:53 So we actually cannot be sold.
07:55 We cannot change our license.
07:56 Nothing like that can happen because of the status of foundation.
07:59 And a really positive force for open source, right?
08:01 Oh, absolutely.
08:02 Absolutely.
08:02 When I first got into like learning how ASF works, I said like that it has no chance to work.
08:08 Like there is no way it works.
08:10 It's too idealistic.
08:11 There's no way.
08:12 Absolutely.
08:12 And nobody in the foundation who makes decisions gets any money.
08:16 So like everyone is a volunteer.
08:18 All the PMC members, all the committers, all the board members, all president, all the VVPs,
08:23 those are all volunteer driven roles.
08:26 And those are the people who make decisions.
08:28 We just pay a few people in infrastructure and security.
08:31 That's basically it.
08:31 Let's start by just talking about high level abstract.
08:35 What is a monorepo?
08:36 I think it's so easy to make that sound like the same thing as a monolith.
08:42 You're like, oh yeah, monorepo, monolith, same thing, right?
08:44 And yet you're shaking your head.
08:46 The first time I met personally a monorepo, maybe I can continue with that, but that was
08:50 like at Google.
08:51 I worked at Google years ago and I was surprised coming to Google that all the code there is
08:57 in a single monorepo.
08:59 Even though like we have like hundreds of products and all the stuff you see.
09:03 It's got to be a lot of code, right?
09:05 Like a giant, giant repo.
09:07 Like now they have like maybe four.
09:09 I don't know.
09:10 Like I've heard some stories.
09:11 I don't work there for a long time now.
09:13 But that for me, that was a sign that like you don't really have to split and dice and
09:17 slice your repositories into many, many small ones.
09:21 Even if you have like non-monolithical product, it all can be kept in a single source, single
09:27 repository, separate source trees maybe, separate like we'll talk about how we do it in
09:32 Airflow.
09:33 But it's a way how you can bind it together and have it tested together and have it developed
09:38 together.
09:39 Even though each piece is pretty much separate and you can work on them separately.
09:44 That's the monorepo.
09:45 As opposed to multirepo, which is like when you have multiple repositories consisting of
09:49 whatever comes up as a product.
09:51 Yeah.
09:52 Everything that Jarek said plus just a small addition, which is each of the component or
09:57 the tiny bit of a monorepo can have its own build artifacts, its dependencies.
10:03 It can also have its own release cycle or a release vehicle.
10:06 That's the only addition, but everything is put together as a big puzzle just to keep the
10:10 puzzle together.
10:11 You know, not every monorepo is Python, but in Python terms, it could have its own pyproject.toml,
10:16 potentially its own virtual environment.
10:18 The nomenclature ironies of this is often the monorepo, I think, makes more sense when
10:24 you are working with lots of small parts, right?
10:27 Where the monolith, maybe it has a couple of things, but it doesn't depend real deeply.
10:31 The more interconnections you have and the harder it is to manage those versions, the more something
10:36 like this makes sense, right?
10:38 People really make a connection between isolated work on part of the system into having to have
10:45 separate repository for that, which is completely not the case.
10:48 Like you can actually have an isolated sub part of the repository, even if it's Git.
10:53 Git doesn't have like, you have some modules and sub repos and all that stuff.
10:56 But even like in a single Git repository, you can easily have like start working and focusing
11:01 on a small part of the whole monorepo and only care about that.
11:06 That's what the monorepo is.
11:09 I'm going to go ahead and put it out there.
11:10 I'm not a big fan of microservice architectures.
11:13 I kind of find it's trading code complexity for DevOps and deployment complexity.
11:20 And I think we have better tools to manage code complexity than DevOps complexity.
11:24 But something like this does help you manage those kinds of deployments as well better, right?
11:30 I use the term mini-series, not microservices.
11:33 Microservices is just too much.
11:35 But then you can have a lot of mini-series, a number of mini-services, but not micro.
11:39 Like micro was just too much of a mainstream.
11:42 I can get on board with that.
11:43 Amak, what do you think?
11:44 I like that as well, mini-services.
11:46 Maybe you should coin that too.
11:47 It's the microservices that are too small.
11:49 It feels to me like the equivalent of when you're trying to write unit tests and you're
11:53 like, oh, what if I get a customer and I set their first name?
11:57 And then I check that their first name is set.
11:58 Like, what are you doing?
11:59 You don't need to check that assignment works.
12:00 This is too, you're just too much in the weeds.
12:03 You know what I mean?
12:03 This is what AI agents do now all the time.
12:06 Like, no.
12:08 Yeah, think of the code coverage.
12:09 Just think of the code coverage.
12:10 Come on.
12:10 You've got some goals to hit.
12:12 You said 80% code coverage.
12:13 It's on top of it.
12:14 Yeah.
12:15 That sets the stage.
12:16 Let's talk a little bit about specifically how Apache Airflow has come to need this, basically.
12:23 Right?
12:23 Like, you shared with me the pulse, the GitHub pulse for Apache Airflow.
12:27 And it's kind of worth looking at just how much open source interest and traffic there
12:33 is.
12:33 Who wants to kind of summarize this weekly pulse here?
12:37 This is not the best week in terms of the number of comments.
12:40 We have had even more red, but in the week of...
12:43 Wow.
12:43 Just one of those weeks.
12:45 Yeah.
12:46 One of the usual weeks.
12:47 Between Feb 3 and Feb 10, we have had about 310 active pull requests.
12:53 So, you can imagine that's about 40 plus pull requests a day.
12:57 A lot of them are being assisted by the AI revolution going on, but that's a lot of pull requests.
13:04 And we have merged about 200 of them.
13:06 About 100 are open.
13:08 And similarly with issues, right?
13:10 35 new issues.
13:11 Five issues per day.
13:12 That's a lot of traffic.
13:13 So, you can imagine the amount of review pressure each of the maintainers has here.
13:19 There's 300 pull requests spread across, I don't know, 120, 130, maybe 140 distributions.
13:26 And each of the distributions having like a swim lane owner who is actively trying to take a look at these pull requests.
13:33 So, it's just another week to be very honest.
13:36 It's more than 25 PRs a day, including weekends.
13:39 How many of these people are high value?
13:40 How many of these PRs are high value?
13:43 I guess I'm trying to get the sense of like, how much does this get accepted?
13:46 Are these just people throwing stuff out there that doesn't make sense for the direction of airflow?
13:50 Well, those merged all make sense because they are reviewed and merged by airflow maintainers.
13:55 And we are very serious about that.
13:56 So, like we don't merge anything that doesn't pass our bar, which is like very high and extremely high.
14:01 Like we have 170 track hooks which are checking if the PR is doing what we, if the code is doing what it was supposed to be doing and if it's architected properly.
14:11 And on top of that, we have individuals, people like, like among myself and maybe 50 other PMC members and committees who are reviewing it and making their comments and know the system enough to direct people.
14:25 So, they may make sense.
14:26 We do have recently, and that was a recurring them at the FOSDEM conference last week when I was there about like AI generated contributions.
14:34 And many of the AI generated contributions are not the best quality.
14:38 It's not like AI is bad quality.
14:41 Many of those are easier to produce and they might have bad quality.
14:45 So, we are now learning how to filter them out and how to make the, to handle them quickly.
14:50 But those are the actual high value PRs that we merged.
14:53 In terms of numbers, if you, if I may, the, it would be maybe a third of the open pull requests that are nice general trend.
15:01 That's pretty good, honestly.
15:02 Yep.
15:03 We have some guidelines published very recently.
15:05 And due to that, we have seen a dip in such, such quality of PRs.
15:09 We published some guidelines in our contribution guides about what will be the action taken if, you know, bad quality PRs are raised or non or PRs are raised where the author does not know the context, but the AI does.
15:22 I don't want to go down this rat hole.
15:24 People hear this enough lately, but I just, it's been in the news lately.
15:27 Open source projects have been kind of getting a barrage of AI submissions.
15:32 And I think that comes in a couple of flavors.
15:35 One, people who just want to get their name listed as a contributor, maybe it helps them with their job or whatever.
15:40 So there's like a small incentive there, but it's been really bad for bug bounties.
15:45 Like curl closed its bug bounty program because people were trying to make the 50 or $250 by finding some issue with AI.
15:52 Is that a problem for you all just taking the pulse of a big project like that?
15:56 It is.
15:57 I actually had a talk about that at the Global Vulnerability Intelligence Platform Summit just before Fosden.
16:03 So that was exactly like, I even quoted Daniel Stenberg and I met him there at FOSDEM, which like, that was really cool.
16:09 There are some different motivations of people who are submitting those those AI issues and we should fight with the in different ways with different approaches or like, you know, the respond to those motivations.
16:21 Somehow we have some ideas.
16:22 We have an open discussion in GitHub maintainers list right now.
16:27 And GitHub is trying to address it by like just discussing what they can do right now.
16:32 And that's the highest priority for them.
16:34 We have a discussion with OSSF for security kind of guidelines or policies for open source maintainers, how to deal with those issues.
16:42 And I'm sure we will work out some ways and toolings and most of all processes and like being assertive is one thing, like just saying no when the report doesn't meet all the bars immediately.
16:53 And, you know, directing people to the description is good enough of a, you know, barrier for, you know, getting kind of completely broken PRs because we have to just make it more expensive for the reporters than for the maintainers to diagnose the issues or decide if the issues are bad or good.
17:11 And I'm not necessarily saying that there's something inherently bad because AI wrote some of the code than a person.
17:17 AI can write really good code better than a lot of people I've seen.
17:20 But it has this sort of shotgun effect often of just like, I'm going to change all these files and it's not as focused and clear.
17:28 A lot of times it just it doesn't it doesn't get the Zen of it.
17:31 You know, Amogh, what do you think?
17:33 It'll generate code, which it thinks is good, but we don't really know the ripple effect and we want to avoid such things.
17:40 Such a long living app with lots of complexity. Right.
17:44 And we all are using the AI for generating the code, to be honest, like so like most of my code.
17:50 You should. Yeah, it's incredible. It's it's I pulled up this graphic here and I'll link to it in the show notes.
17:56 I just given people a sense, I got this little utility that I released this week called Tallymon, which like analyzes code and gives you sort of a more of a breakdown than just like this many lines or whatever.
18:07 So I want to just highlight maybe you all like can riff on this a little bit to give a sense.
18:12 So 100 or 1.2 million lines of Python, 918,000 excluding comments, maybe a little over counting the way this thing works, but still 200,000 restructured texts.
18:23 The one that really stood out to me, 81,000 lines of YAML and 16,000 lines of TOML.
18:28 You guys, that's impressive. And you know what?
18:32 Hat tip to just a just a sprinkle, just a hint of Java at 42 lines of Java.
18:38 But, you know, almost a million, just over a million lines of code without comments.
18:43 That's a big project. What do you think?
18:45 What happened when you joined?
18:47 I don't know. I think it was much less.
18:50 You did contribute a lot.
18:51 You can imagine so because of the number of packages we haven't read the monorepo discussion from earlier.
18:56 We have a lot of packages and the YAML might surprise you at first.
19:00 But if you actually go and see why the YAML, it's mostly for our providers.
19:05 So integration with other systems is something we call as providers.
19:08 And the spec of the providers is written in YAML.
19:11 And TOML, sure, will come to it very, very, very soon.
19:14 That's kind of why I pulled this up, actually, is the TOML aspect is quite interesting, which leave us with that number as we move on.
19:23 16,000 lines of TOML. That's a lot of pyproject.TOML going on right there, folks.
19:28 Oh, yes. And lots of it is generated, actually.
19:31 So like, because we actually generate quite a lot of the YAML and TOML that we have and keep it in the repo.
19:37 So we don't want to regenerate every time.
19:39 So like, we don't write YAML by hand.
19:43 Maybe we can start by introducing this by just giving a shout out to this series that you wrote over here on Medium.
19:50 Jarek, modern Python repo for Apache Airflow, parts one through four.
19:55 Yes, I initially started discussing this blog post idea with a few people.
20:00 Like, you know, like people are busy and I couldn't get people like to write it.
20:04 So I decided to write it myself.
20:06 Well, with a lot of AI help, of course.
20:09 It's not that everything is written by hand.
20:11 And when I wrote it, I realized it's like too big and I had to split it into four.
20:17 But the idea was like to document what we've done because because I think that a lot of people are struggling with like monorepo versus multirepo or like how they should do their repository in when they are the project grows.
20:29 And there were lots of discussions in the past, including here, one of the, you know, one of the podcasts of yours were monorepo versus multirepo.
20:37 And I can't remember who that was, but there was discussion about like going back and forth and like finding that people sometimes go back and then then go forth and like in different directions because there are different problems or approaches.
20:50 So I just wanted to document the reasoning why we are doing it, like why it's possible now because of the packaging ecosystem maturing for Python and uv and other tools coming into the space.
21:03 And then the last part was like really the kind of a little bit innovative approach that we do where the tooling is still not catching up with what we need and what we, what we, what we did.
21:12 So those are the kind of history why we are doing it.
21:16 The, you know, the packaging, the automated verification with prek.
21:22 So that was the third part.
21:23 And the fourth part was about like the, this chart, libraries, innovation, innovative concept, but we added for, for, for.
21:29 I'll link to the series as well as to a talk that you gave at FOSDEM that just got published, right?
21:34 Yes.
21:35 Yes.
21:36 And, they are, they have amazing system of recording and publishing stuff.
21:40 Like, like for the volunteer driven conference, thousand speakers.
21:44 Oh, that was, that's amazing.
21:45 That works.
21:46 Like probably some automation going on there.
21:48 Let's talk a little bit about, I guess the problems that you ran into because initially there were some challenges with the standards and tooling not be there.
21:56 And you actually, one of the takeaways, if people read the series or watch the talk is you actually had to work with some of the tool providers to make this possible.
22:05 So not only is it like, well, the tools have changed what we could do this.
22:09 It's you all have changed the tools a little bit through, you know, working closely, like, Hey, we've got this 1 million line project with a hundred dollars.
22:17 So not only is it a hundred sub modules or more help.
22:20 Like it's just your tools to support this.
22:22 Help me make this work.
22:23 Right.
22:24 What were some of the problems?
22:25 Let me start with this cooperation and maybe, you know, Amogh can also explain like what was before and after, because like he experienced that firsthand as a, as a user kind of this kind of repository structure.
22:34 But for me, the idea was like, I was working on it for years.
22:39 Like when we went to airflow to five years ago, we, or four years ago, I can't remember.
22:44 That's a long time.
22:45 And we didn't have all the tooling and we had to do pretty much everything that we do now with the, with monorepine uv by hand, by bash scripts by that time.
22:55 By that time, by that time, crazy.
22:57 So like, if you run it three years ago, the, the, your code, you would see more than 10,000 lines of bash code, which I wrote.
23:04 But we, we since removed.
23:05 We since removed.
23:06 That is not joyful.
23:07 That doesn't spark joy.
23:08 That's why we removed it with some outreach internship actually.
23:11 And shout out to edit and, and Borna who were our outreach mentors who helped us to convert it to, to Python, which was really helpful.
23:19 That's how it started.
23:20 No tooling need because we grew, we wanted to have more providers, more integrations, and it already was quite difficult to manage if they are well part of single distribution.
23:30 So we have to split into many distributions, 60, I think at the beginning.
23:34 Now we have more than hundreds.
23:36 Now, when we did that, I, we had to do all manually and like working with that was like really cumbersome.
23:43 Maybe, you know, like I can switch to, to Amogh.
23:45 So he can say like the past experience and new experience because like he experienced the change himself.
23:50 Yeah.
23:51 The, the past experience was scary to be, to speak the least.
23:55 Whenever I, switch branches or have to rebase for whatever reason, I had a nightmare, a very bad time trying to, you know, package things together and try to run something.
24:05 And I think Jarek found me often, you know, ranting on the Slack channels that, Hey, this doesn't work.
24:09 Hey, that doesn't work.
24:10 What do we do?
24:11 Now it's, it's very easy.
24:13 It's, it's effortless, almost effortless compared to what we had years, maybe like five years ago, four years ago.
24:19 Yeah. Amazing.
24:20 How does GitHub deal?
24:21 I was the only one who actually managed the whole thing for years.
24:24 And I was like overwhelmed as well when people have problems, of course.
24:27 So then the change that we've done was not only with the tooling.
24:31 And as you mentioned, we were actually cooperating with Charlie from Astral, Charlie Marsh and with Joe from FEC because we had this need.
24:39 We had it implemented ourselves and then they could look at how we've done that and they could implement it properly in their tooling.
24:46 And we've been like exchanging the, you know, like Charlie was even interviewing me at some point of time, how we, how, what, what are our needs?
24:53 So I have for a long time, I have this, this motto that the best way to foresee future is to shape it.
25:00 And like, so we did shape the future by, you know, talking to those tool providers so that they can, or builders so that they could build it for us and work with us.
25:08 And we helped them to test them and everything like that.
25:10 But also it was like listening to Amog and other contributors, like all the problems they had or like, and then when I solved it, I wouldn't, I wouldn't also own solve it with the new tooling, but we also engaged all the more people from the, from the team, like Amog and few other active contributors.
25:27 And they were actually part of the whole process of conversion.
25:29 And they are now part of the team.
25:31 And now we can have this podcast while things are being broken in airflow right now.
25:36 And somebody is probably fixing it right as we speak.
25:38 So like, not me anymore.
25:40 So that's, those old, old things are really great.
25:42 This portion of Talk Python To Me is brought to you by us.
25:46 I want to tell you about a course I put together that I'm really proud of.
25:50 Agentic AI programming for Python developers.
25:53 I know a lot of you have tried AI coding tools and come away thinking, well, this is more hassle than it's worth.
26:00 And honestly, all the vibe coding hype isn't helping.
26:03 It's a smoke screen that hides what these tools can actually do.
26:07 This course is about agentic engineering.
26:09 Applying real software engineering practices with AI that understands your entire code base, runs your tests, and builds complete features under your direction.
26:19 I've used these techniques to ship real production code across Talk Python, Python bytes, and completely new projects.
26:27 I migrated an entire CSS framework on a production site with thousands of lines of HTML in a few hours.
26:33 I shipped a new search feature with caching and async in under an hour.
26:38 I built a complete CLI tool for Talk Python from scratch, tested, documented, and published to PyPI in an afternoon.
26:47 Real projects, real production code, both Greenfield and legacy.
26:51 No toy demos, no fluff.
26:53 I'll show you the guardrails, the planning techniques, and the workflows that turn AI into a genuine engineering partner.
27:00 Check it out at talkpython.fm/agentic dash engineering.
27:04 That's talkpython.fm/agentic dash engineering.
27:07 The link is in your podcast player's show notes.
27:10 How does GitHub deal with so many files and such a big project? Is it fine or is it a challenge?
27:18 Except yesterday, where half of the time GitHub was not at the end.
27:21 Except yesterday.
27:22 Yeah, for people who don't know, yesterday morning, at least morning US time, GitHub was having a moment.
27:27 Like, it was, I couldn't clone stuff.
27:29 I pulled up the random page on GitHub and got the 503 Unicorn.
27:35 It was not good, right?
27:36 Besides that, not excluding that time.
27:38 The Unicorn is actually a little bit like looking kind of angry at you.
27:41 That's one of the observations I had from yesterday.
27:44 I saw it so many times that it's like, it doesn't look nice.
27:47 But maybe GitHub.
27:48 I agree.
27:49 That's not a great error page.
27:50 Like, some error pages are amazing where it's like, you know, the coyote fell off of a cliff.
27:55 Woo!
27:56 You know, like, that one just looks like it's angry back at you.
27:58 Besides that, it's perfect.
28:00 Like, it works like seamlessly, no problems whatsoever with the size, with the numbers.
28:04 Like, we are very, very happy in general.
28:06 And of course, like, things like that happen.
28:08 There is nothing wrong.
28:09 Like, there is something wrong, but like, it's not like that, that it happens all the time.
28:12 Not really like GitHub.
28:13 It's super rare.
28:14 GitHub is an incredible service.
28:15 I mean, I know there's been some grief about the GitHub actions, but I put, that's a different, different conversation.
28:22 Right?
28:23 So let's talk about, next, about how the package standards have changed and how basically some of those things have made it possible.
28:31 And so in your talk, you pulled up a bunch of different peps, nine of them or something like that, that were about packaging, recently packaging standards and different things like that, that have made basically the structure that you're working with and the tools that do it possible.
28:45 Do you want to maybe highlight either of you, some of these things that stand out as, this one is really important.
28:50 The one which is maybe not super related to Monorepo, but it actually helped us a lot, like the pep723, the last, all the, one but last inline script metadata, which is like one of the biggest successes and the biggest kind of usages I see from PEP implemented.
29:07 It caught up very, very quickly. It allows us to, you know, embed inline script metadata into, into the Python scripts, which is like something that we've been dreaming of for years, especially for this kind of tooling, the FCI environment, et cetera, et cetera.
29:21 This is really, really helpful.
29:22 So that, that's the one that I would like to highlight.
29:24 But I, you know, I read all of them like many times, all the peps and they are difficult things to read, to read and understand, but they were like, we actually did all that we could to, you know, be like fully compliant with the, not only with the specification of those peps, but also with the kind of spirit of the specification, because sometimes things are not very precisely described and there are some interpretations and stuff.
29:46 So we just, we just made sure, and this is our, our goal as well.
29:50 Like we just make sure that all the PEP standards that are being published are actually very meticulously followed.
29:56 And we just try to adapt to any changes that are coming in the environment.
30:00 So we know how difficult it is if people are sticking to the old ways and like that's, that makes difficult for Python maintainers.
30:06 Mark, any other thoughts?
30:07 This one is a particularly very important one for us also because it simplifies our pre-commit configurations where earlier we had to,
30:15 you know, specify the dependencies as required.
30:19 So like whatever the particular version was, but now it's all in the script.
30:23 It's not, and the pre-commit remains as clean as it could just with the hook name and,
30:28 you know, the regex for the file filter and minimal configurations for it to work well.
30:34 And I think your dependency group is also the other pep.
30:37 I don't recall the name, but I recall the number.
30:40 I think it's six.
30:41 Oh, I can't remember all the numbers, but one of those.
30:43 That would be 735 folks, 735.
30:46 That's also particularly nice for us.
30:48 We can define the dependency groups in our by-projects and it's, it's nice to, it's really nice how it works with uv.
30:55 We're very happy with this particular dependency group as well as the inline scripts.
30:59 Right.
31:00 The inline scripts are cool.
31:01 I, you know, especially with uv these days, it really makes running some kind of Python code so much easier.
31:08 It's, it's almost as if everything is standard library.
31:12 I can give somebody a file.
31:13 I can say the way you run it.
31:14 No, no, no, no, no.
31:15 Don't.
31:16 I know it looks like you say Python, but don't say that.
31:18 You say uv run this and then, and that's it.
31:21 Like they didn't even have to have Python.
31:22 They might need 10 dependencies and so on it, but it doesn't matter.
31:26 Right.
31:27 Yeah.
31:28 And big standard.
31:29 It makes it also, you know, like other tools are doing the same or hatch run.
31:31 That's the same.
31:32 That's like, yeah, there is even like support for inline script metadata just released in latest
31:37 tip 26.
31:38 So like, it's all good because of the standards and not because a single particular tool does it in an opinionated way.
31:44 So this, this is really, really, really cool.
31:46 And there is one big benefit of those kinds of apps and this part, particularly inline script metadata.
31:52 It's like, we have less YAML.
31:54 Yeah.
31:55 You already have a lot of YAML, but less is better.
31:58 We have a lot still.
31:59 We can't come from that.
32:00 It's better than it was.
32:03 Yeah.
32:04 And so the dependency groups are like, you know, for dev or for tests or something like that.
32:09 Right.
32:10 So you can say like uv sync or uv pip install, and you can say like thing bracket dev or something like that.
32:19 Right.
32:20 The nice thing is about you think is that it sends the dev dependencies automatically without you even specifying that, which is like the best thing for development because you actually always want to have developer developing development tools with you.
32:31 That's a good point.
32:32 Yeah.
32:33 That's really cool.
32:34 That was the changes to Python itself through the peps.
32:37 But there's also tools and you've already mentioned some of them, both of them, but tools that make this possible, which I mean, I think uv has to be number one that goes on this list, right?
32:47 Like uv has really done some powerful stuff here.
32:50 Right.
32:51 Again, Amogh can say like, I introduced it, but Amogh was the one to switch to use uv at some point of time.
32:56 Yep.
32:57 uv has been a game changer.
32:58 I think we were using poetry before this or Hatch.
33:01 I don't know.
33:02 No, not even that.
33:03 Just pitch.
33:04 Just pitch.
33:05 Just pitch.
33:06 Just pitch.
33:07 Just the image.
33:08 It's so good.
33:09 I don't even remember the last, you know, game changing aspect that uv brought in was this notion of workspaces.
33:13 It's something very simple.
33:14 You can compare it very similar to, you know, a co-working space or something similar where it's a unified environment where multiple interconnected pieces coexist and they're very easy to manage.
33:26 And that's something that eventually led us to splitting the whole repository across our distributions.
33:32 And that's the reason you see so many toml files.
33:35 So everything has a by project toml.
33:37 Everything defines the dependency groups it needs and development of a particular package is restricted only to its dependencies.
33:46 So you develop it, you run uv sync, you can run your by test using uv and everything that is supposed to run with it is running with it.
33:55 And any bad or, you know, cross imports are caught really easily.
33:59 So I think the workspace feature at least was the most important one for me.
34:05 And obviously the speed that it brings with it.
34:07 And that's impressive.
34:08 It is.
34:09 And I think this workspace concept, it's new to me.
34:13 I'll say it's new to me.
34:14 I don't know how new it is to other other folks.
34:16 So you've got this giant monorepo and how many different conceptually different packages or projects are in there right now?
34:26 120 plus.
34:27 It changes by day because Amogh is doing a lot to increase the number very, very quickly because we are just now in the middle of finishing some isolation kind of restructuring.
34:38 And Amogh is the one that that's why he's here also to lead the introduction of new packages that we or new distributions that we that we have like a shared libraries that we will talk about later.
34:48 So we have a lot of those.
34:49 Yes.
34:50 I think this is super important to dive into and how uv makes this possible.
34:54 And I think you said also Hatch, you talked with Ofek, who runs Hatch as well about this, right?
35:00 Yes.
35:01 Yes.
35:02 Hatch is also supporting workspaces, which are modeled mainly about what like after what uv has done.
35:07 We haven't tried it yet, but I've heard it's very, very similar or even like you can use it as a one to one replacement in some cases or maybe even in all.
35:16 But generally, I would love this eventually to become some kind of standard so that multiple tools are supporting this.
35:21 But but yes, there are a few other tools that we were considering before, but uv is by far the kind of like, yeah, well, we work together.
35:28 We shaped it together with the uv team.
35:30 So it definitely works well for us.
35:33 Yeah.
35:34 Amazing.
35:35 So let me describe this a little bit and then you all can can actually introduce it.
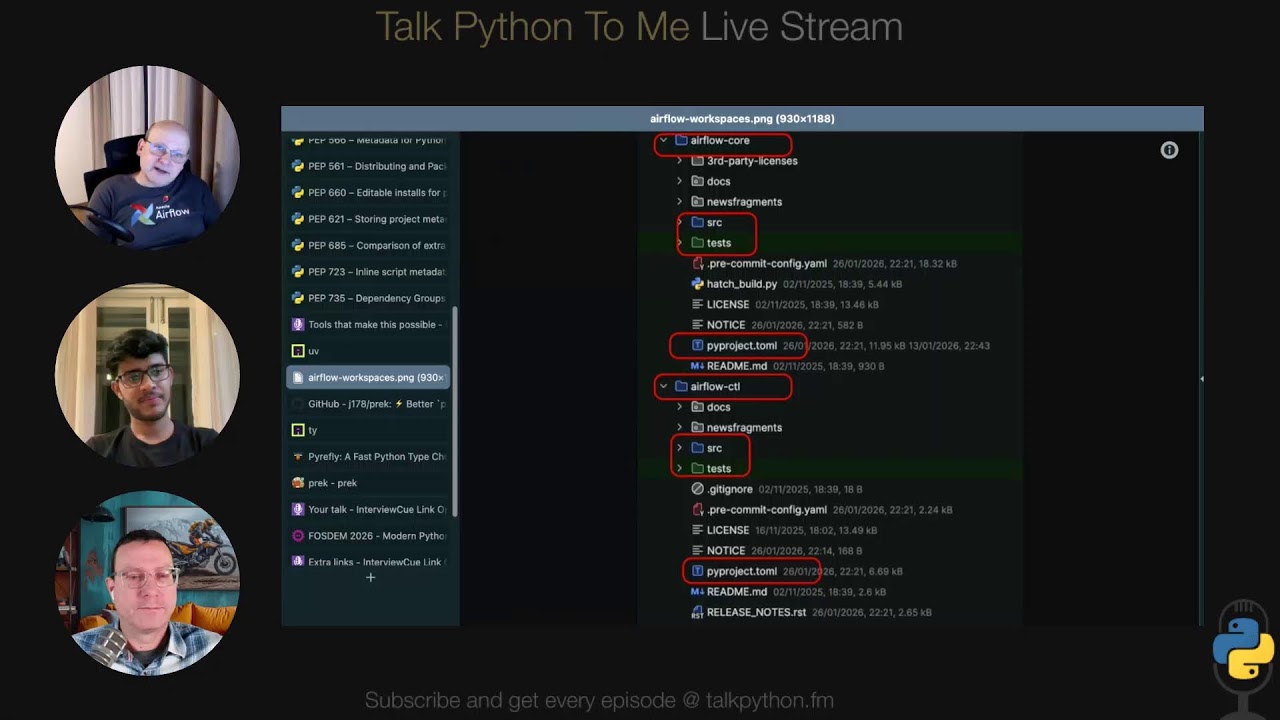
35:39 So the idea is we've got this mono repo with a bunch of different folders for the sections, right?
35:45 Like airflow dash CLI or CTL and airflow dash core and so on.
35:49 And you'd like to be able to kind of just jump into one section and treat it as a top level project, right?
35:56 It's got a pyproject.toml.
35:57 It's got a source file, tests and so on.
35:59 But the challenge is you can't just have a bunch of disconnected pieces like maybe airflow core depends on five other parts of it that are also themselves have their own pyproject.toml and different things.
36:12 And you've got to set up, you know, set up.
36:14 If you jump into the airflow core, you've got to set up the environment just right to be working on those other parts, right?
36:19 It sounds pretty tricky.
36:20 So how does how does that work?
36:22 Who wants to make sense of this for us?
36:24 It works perfectly.
36:25 Like it's super, super simple, actually.
36:27 You know, like the whole thing about the uv is like its simplicity of the of not of the concept.
36:33 The implementation is actually quite tricky.
36:35 But the way how you use it is very simple.
36:37 Just go to the directory and run uv sync.
36:39 That's basically it.
36:40 This is the directory you want to work on.
36:43 And it does exactly what you would expect it to do, which means that it syncs.
36:47 It actually updates the or recreates basically the virtual environment that you're using with all the dependencies that this particular distribution needs and anything that it needs.
36:56 As a transitive dependency as well.
36:58 So if it refers to another project project inside the workspace, it will also use it from there, not from like installed by by PyPI.
37:05 So you can immediately start working on this because everything after uv sync, everything is exactly as you expect for this particular subset of the repository that you were on.
37:14 And that's basically it.
37:16 This is all.
37:17 Like there is nothing more, basically.
37:18 That's it.
37:19 It works.
37:20 And you can, when you run uv sync pytest run, it will do exactly what you want.
37:25 So in this folder, because it will also uv, uv run py test, it will do exactly what you want because even uv run will automatically sync the virtual and very, very quickly to the one that your project needs.
37:38 And then it will just run pytest in this virtual environment and it will run all the tests in your project.
37:43 And that's basically it.
37:44 So it's like conceptually for the users is like, you don't have to do much, just uv sync.
37:49 And that's it.
37:50 I think one of the big challenges here is how do different parts of the project know about each other, right?
37:57 Yeah.
37:58 You said that it, it, it's similar links the different elements in.
38:01 The basic kind of workspace and implementation is just a workspace definition.
38:05 So you have to have the definition of workspace in the top level by project.
38:09 So there you have all of them listed.
38:11 You have links to it.
38:12 They have described where they are and uv will read the by project from the top level and will, will know what they are.
38:18 We'll, will know where to look for particular distributions.
38:21 So that's the, that's the simple discovery and the way how we know that we are using it from the sources and not from the, from the PyPI.
38:29 But then like the shared libraries as, as it's like something that we added on top of it and the sim links are on the top of it.
38:36 And this is kind of extra innovative thing that we are doing for something else that we need, but you know, we can, we can talk about that now or like I'm not can talk about.
38:44 This is really cool.
38:45 So one of the things that happens here is these different slices or subsections of the monorepo pyproject.toml that pyproject.toml depend, defines its true dependencies and its dev dependencies and so on.
38:59 So when you go and jump into a section, it will, uv will basically realign the virtual environment with whatever dependencies are supposed to be there from those things.
39:10 Right. So that means installing stuff, obviously, but actually what surprised me a little bit, not a lot, but like, Oh yeah, I guess it does do that.
39:17 That's cool. Is it actually uninstalled stuff. That's not explicitly put there, which I can imagine before that you could be like, well, this one part way down here depends on this weird library.
39:29 And somehow I used to be over there. Then I went back to the, this other piece and then I came back and I forgot where that even came from.
39:36 Like, why is that in my virtual environment? And like, how do I specify that? Probably juggling that was a big problem, right?
39:41 This, this like loading and unloading dependencies based on what part of the monorepo you're in.
39:47 And I think that actually makes it really much easier to deal with like this, this type of code structure.
39:52 Let me add to that one more thing, because it's also not only the dependencies that you might have from somewhere else, but also it's a cross dependencies between different distributions inside.
40:02 So for example, if our flow CTL does not use our flow core, if you go there and you think you will not be able to report and use any of the source code, which is in airflow core, because it's not a dependency of our flow CTL.
40:14 So uv sync will not only uninstall the dependencies that you have, but also uninstall the source code that you have from other parts of the repo, which is a fantastic thing for us.
40:23 And that was exactly what was missing before kind of isolation between those.
40:27 You only actually can from your source, you only can refer to the source code of those distribution that you depend on and nothing else from the monorepo.
40:36 So this means that it's like you can slice and dice your repository as you want.
40:41 So depending on in which the directory you are and when you run uv sync, you will have like subset, like the actual useful and the used subset from your repository.
40:51 And it can be completely different if you go to another directory, some of that can be overlapping, some of that can be completely different.
40:58 Depends like which dependencies are defined.
41:00 And this is like, this all magically happens, like by just defining the dependency in pyproject.
41:06 And uv sync will handle it for you in the workspace.
41:09 It's like exactly the reason why it's so useful for developers.
41:13 It helped us in our vision to actually, you know, decompose the project into multiple parts and avoid the classic problem of coupling, which every monorepo faces at some point in their lifecycle, because everything is out there.
41:27 Why don't we just, you know, have code leaks all over the place.
41:31 So this helps us prevent that.
41:33 And I cannot imagine a time how we did it earlier before uv.
41:36 I don't know if we did it, but if we did it, it would have been a really tough thing.
41:41 Yeah, there's a bunch of tools that you can, linters and code analysis things you can run on your code that breaks down for these different modules and these layers.
41:50 Here's like a directed graph of how this thing, and you can set up rules to say this should never cross that boundary, but these are just very, very vague things.
42:00 And this setup actually makes it so it's not accessible to your code.
42:04 If you didn't say it should be.
42:05 It's just built in exactly the definition of your distribution, which you anyhow have to do because like you have to define what the, what the dependencies are.
42:13 And yes, we did something like that before.
42:15 So we get a number of like rough rules or whatever.
42:18 Don't import here, import here.
42:21 We still have them for shared libraries, which we can talk about now, because I think this is an important modification of the concept.
42:28 So we do have some automated check for quality and for imports with prek, our Prec commit hook implementation.
42:36 But before that, it was just completely, completely like handwritten and unmaintainable.
42:42 People will not, we're not actually updating it with all the distributions you couldn't really, you know, follow when things change.
42:48 With PyProject Tom being the, for each distribution being the single source of truth, you don't have to do anything because the dependency is declared there.
42:56 And this is like the best part of, of uv understanding that and, and doing everything that is like reasonable in this case.
43:03 The other major tool involved here was prek, which it's a pre commit framework for running hooks, many languages, but especially Python relevant here written in Rust.
43:15 So it pairs well with uv, I suppose.
43:17 Oh yeah.
43:18 It was inspired by uv as well.
43:20 And, and Joe was mentioning, mentioned that, that he was actually contributing to uv before.
43:25 Great.
43:26 How's prek show up here?
43:27 I feel like this is leading towards what you were hinting at earlier.
43:30 It's a new name, prek.
43:31 So, yep.
43:32 This allows us to do a few things which pre commit did not do, or, you know, did not accept as suggestions.
43:39 So, one certain thing that prek offers is obviously it's written in Rust.
43:45 So speed is the obvious one is that we get.
43:48 But apart from that, we also get this notion of it pairing well with uv in terms of modularized hooks.
43:53 Earlier, we had all the hooks in one place in that, in the top level pre commit YAML, right?
44:00 And it was a big fight.
44:01 It was really big.
44:03 You can imagine.
44:04 So, yeah.
44:05 So this prek allowed us to, prek again, you know, it, it consumed the concept of workspaces here, I would say.
44:11 So it allowed you to define pre commit hooks or prek hooks within a module itself.
44:18 And this paired well with uv in the sense that when you have to run hooks that are bound to a certain distribution,
44:26 all you have to do is check in into the, you know, the sub module and just do a prek run.
44:31 It will run the relevant hooks for that particular module.
44:34 And the other, other thing that I really love about prek is auto completion, which is not something pre commit had.
44:41 So you can imagine that something fails in the CI, you have to copy that and copy the ID and try to kind of backtrack it in your repo as to which one is failing.
44:50 So it's, it used to be a nightmare, but now with the, you know, the tab completion, it's, it's amazing.
44:56 Nice. Are you talking about like shell autocomplete integration?
45:00 Yeah. Yeah. So, okay. I've seen.
45:02 I have some story about that very, very short.
45:04 So like we actually tried to get out the completion for hook names with, with Prec commit, which was the predecessor of prek.
45:11 Like prek was largely based on Prec commit, but somehow the author of it didn't accept even idea of us contributing it or actually had some very, very excessive expectations for that.
45:22 And we, you know, discussed and like, there were like, other people were also trying to convince the author to do that, but they refused.
45:29 He refused basically and refused to accept contributions.
45:32 Even when we spoke to Joe, that was like completely different stories.
45:36 Like we need that.
45:37 And next day it was there.
45:38 Like it's like completely different approach.
45:41 So, so this is, and then we said like, we need workspaces and like a few weeks later, because it took a little bit of time, it was there and we work together and we tested that.
45:49 And like, I raised, I don't know how many issues in the initial kind of pre-release version when, when we wanted to use it.
45:55 So I think the collaboration and being, you know, working together, listening to your users and be responding and actually working as an open source maintainers together.
46:04 This actually worked perfectly well here, both, both in uv and prek.
46:08 And this is why we love prek actually because, because we know we can rely, if something is not working, that it's going to be like, we can discuss and either submit a fix or, or, you know, Joe will do this or even like lots of other people can do it.
46:22 Because there was a few features that we wanted and somebody else implemented it.
46:26 And that wasn't Joe, they contributed prek because of this openness and, you know, being able to accept the needs of the users.
46:35 That was very, very important part, like why we moved to prek.
46:38 Yeah. I think Airflow was also one of the initial case studies for prek.
46:41 It's a project of that scale. And if you kind of satisfy that project's needs, you are, you're pretty good with most use cases.
46:48 I think that's quite both Prec and UVS.
46:51 Yeah. Right there at the top of the prek repo, it says, although Prec is pretty new, it's already powering real projects, you know, little things like CPython, Apache Airflow and FastAPI.
47:01 I know Hugo van Kemenade from the release manager of Python. So we met at Fosdem as well. And like, he was actually listening to our prek discussion and he converted, you know, CPython to use prek because of the, of the needs they had.
47:13 So like, it was all about, you know, people talking to each other, word of mouth and things like that.
47:19 You know, there's a feature listed here that just makes me jealous. One of the features of prek is a single binary with no dependencies that doesn't require Python or any other runtime to be installed.
47:29 Like how incredible would it be with Python if we had a, a Python --build app or something, you know what I mean?
47:36 You can put it at your thing and you get something you could distribute. I know uv solves a lot, but you still got to have uv installed.
47:43 And then, you know, like this, that is a huge advantage of things like Rust and go and some other languages.
47:49 It's both good and bad in some cases. So it's like, there are always trade-offs, different choice made by Python here.
47:55 I don't think it's like the best choice for, for Python. I think Python being script language, it's okay to have, you know, like dependencies and especially like inline script, script metadata almost did it because you just, you know, can install stuff.
48:09 And uv also, and the kind of tooling is also doing all the stuff like uv install or uv tool install, whatever.
48:16 And it would not only install the project, its dependencies, but also install Python that is needed to run it.
48:22 So like all this is really a matter of two weeks and it has improved dramatically over the last few years.
48:27 Yeah. I was pining for an option, not a only binary thing.
48:32 All right. So one thing I actually want to talk about going back to this workspaces thing real quick is what does it look like from a IDE or editor experience to work on this?
48:43 All right. Like you've got Python projects, you've got maybe VS Code workspaces where you can pull in different pieces. How do you all manage that?
48:52 I cannot talk for VS Code. I'm a Python user here, but we had to do a little bit of hacking, I would say, or more like a helper script for the IDs, right?
49:02 Because so we have a IDE helper script right in the repo and we recommend the users to run it so that the IDE knows what is where in terms of maintaining things, right?
49:12 Because in normal projects, there's usually just one source, one desk at the top level, but it has 120 plus.
49:19 And the helper script is, it does a pretty simple thing. It just auto discovers all the packages in the monorepo and adds this.
49:27 So IntelliJ and PyCharm both have a .IDR within each, a hidden folder within each of the projects that it opens.
49:35 And it has a, and it supports XML like format for IML where you can define certain things.
49:42 So this essentially does a very simple thing.
49:44 It just, for each package, it adds the module slash source as the source root and the module slash tests of the test.
49:52 It's as if you went through all 120 things and right clicked and said mark as sources root or something like that.
49:56 Yeah, we had this PyCharm script and then we have the same approach for VS Code.
50:00 So we have another script for VS Code as well, which was contributed by someone who uses VS Code because neither me or Amog are VS Code users.
50:08 PyCharm uses both of us.
50:09 But, you know, communities also and like somebody said, OK, I'll do it.
50:13 And there it was.
50:14 And they tested it.
50:15 And, you know, like that's, that was super cool actually.
50:17 So, yeah, it works well.
50:19 Also, the, you know, a little bit of words, probably we don't talk, we won't talk too much about like the, we don't have too much time, but the shared libraries concept a little bit might maybe it's the right time to introduce the concept.
50:32 Because, because we like one thing that Amog mentioned is like the, we have, we solve this coupling problem, but also we wanted to solve the dry problem.
50:41 And those two are always kind of mixture, like you get dry and then you get more dry and less coupling and like, like more dry and more coupling and like all these things are complex when you have lots of code interacting with each other.
50:54 Dry being the architectural philosophy of do not repeat yourself.
50:57 But if you're not repeating yourself, everything where if it exists somewhere, everything's got to depend on that somewhere and it starts to become more linked together.
51:04 Right.
51:05 So it's a little bit of like a, eat cake and have it too.
51:08 Like we want to have dry code and not to repeat it for like common utilities, like logging, configuration, whatever, all the things that are kind of common between all the different distributions.
51:18 But also we didn't want to depend on a single version of those, because if we do, then it means that we have to make sure that the backwards compatibility is maintained.
51:26 Because like when we install different version of different distributions coming from different time of repository, they might use different version of those shared libraries.
51:35 And like how to make sure that they don't have breaking changes and stuff like so this is all the whole level of complexity between like how to manage the dependencies there and manage versions, especially manage the backwards compatibility.
51:48 So we figured out that with some very simple approach, we tried a few different approaches, but like, like one of the approaches was using the vendor link library from pip and from Byton, no, from pip, from pip.
52:01 And the second one, and that's the one we came up, we finally implemented, was like using Simlinks to share the code between different distributions.
52:09 And that's a very innovative approach that I hope will make it into some kind of standard eventually.
52:14 So like we came up with this approach where we actually have cake and eat it too, like, which is like pretty amazing if you fought with like for years with this kind of common dependency issues that and backwards compatibility.
52:27 So in our case, like the Simlink approach we have, it needs some pre-processing of by project DOM.
52:33 Some parts of the PyProject DOM are generated to make it actually work.
52:37 But this is all automated with prek, which is like, we don't have to think about that even.
52:41 And once we do that, and once we create some Simlinks between different parts of code, like one library, one distribution is Simlinks in code from the shared distribution.
52:50 The end result is that this code gets automatically vendored in during the building of the package, which means that we actually have the same library in different package, in different version, in different distributions.
53:02 So distribution released a week ago will have a shared configuration from a week ago.
53:08 But another distribution will have the same shared configuration code from today if it's released today.
53:14 And we can install them together.
53:16 And all of them have effectively, like if they had a different version of the same library installed.
53:22 It's as if the Airflow-CTL said it had a dependency on core and it pinned that version to something, but a different part of the repo pinned it to a different.
53:31 And they can both kind of coexist.
53:34 But it's actually all within the same code file.
53:36 That's insane.
53:37 OK.
53:38 And this is like largely, like it's nothing new.
53:40 It's largely inspired by how the libraries work in C and like traditional kind of building code.
53:46 Like you have dynamic libraries and static libraries.
53:49 So this is like essentially equivalent of static libraries where you take the code of the version that you compile the stuff in and put it inside the final binary.
53:59 And then it results like in Rust, the kind of single binary thing.
54:02 So it's a little bit like, so we have a little bit of this single binary by doing that in the sense that we automatically vendor in all the, you know, shared dependencies that we have in the same distribution.
54:15 So it's kind of hybrid, but it's always like, so Rust is a little bit too far because everything is single binary.
54:21 In our case, we have a bit of both.
54:23 Like we can use libraries dynamically, but we can also embed libraries as shared inside the single distribution.
54:29 That's very cool.
54:30 That's wild.
54:31 Amogh?
54:32 Sounds like you were instrumental in this, Pari.
54:34 That's the nice thing about the approach that was chosen, right?
54:37 We all came together as a community on this one.
54:40 And we had one email, DevList discussion one fine day that, hey, we want to achieve something like this, which more or less was something everyone agreed upon.
54:50 So people started chiming in and we started trying different things out.
54:53 The first one, obviously using the rendering tool from Pip.
54:57 Somebody did a POC on that, but it felt like it's going to be difficult to achieve that long term.
55:02 And also it could be brittle.
55:04 So Jarek came up with this particular option with Simlinks, which again was discussed within the community.
55:10 A few of us picked this PR up, passed it locally, played around and gave the feedback.
55:16 So I don't think this would be possible with AI in the sense that this has never been done before.
55:23 Or something like this, where a community comes together and solves a rather difficult problem, is something that makes me really happy.
55:31 And also something that all of us are working towards a common goal while also bound by our corporate hats, right?
55:38 Is something that is again, really nice to see.
55:41 We have about how 11, I think at this point, we have about 11 to 12 shared libraries where the main notion here is to reimagine Airflow as a independent server and more like a control plane and execution plane.
55:54 What we did with Airflow three and this shared libraries is helping us achieve that model.
56:01 And we have about 11 to 12 of them.
56:03 And I think a few more coming very soon.
56:05 But yeah, that's yeah, it's been nice working on the shared libraries.
56:10 It's yeah.
56:11 Is this something that people can take and adopt into their monorepo if they want to live that life?
56:16 Absolutely.
56:17 Yeah.
56:18 It's just that it's really like one or two kind of prek hooks which are maintaining the consistency.
56:23 And like, so that you don't forget to add this symlink here and that kind of I project com definition here and or that hatch definition for the hatch link to actually embed your symlink code into the final distribution.
56:38 So like there are like a few pieces that have to be put together from existing libraries.
56:43 So that's basically it.
56:44 And once you do it, it's just that those are the funny thing is like those shared libraries are just standalone distributions.
56:51 You can actually build them separately as a library as well.
56:54 We could potentially even, you know, like just use them as library as well.
56:58 No problem whatsoever because they are just standard plane distributions or any other.
57:02 We just happen to take the source code of it and then embed it in into the target distribution that wants to use it rather than, you know, link to it by dependency.
57:11 So that's basically other than that.
57:13 It's it's it's a kind of completely standard library and or standard distribution.
57:18 And one one more thing that is really important to add here is like this also has a side effect, but I think a very nice one.
57:24 And Amo can confirm that because he has been doing a lot of that is like we actually come up with like way better internal architecture.
57:31 Or because of that, because a lot of those shared libraries, they depended on each other, sometimes in a circular fashion.
57:38 Sometimes it really dependent, like which import you did first, like what happened, like what was initialized.
57:43 And I was like complete spaghetti of dependencies between generally independent pieces of functionality.
57:49 Right now, by having shared libraries, we are actually forcing ourselves to make it make them isolated.
57:56 We are changing the way how we initialize them.
57:59 For example, we are injecting all the configuration rather than using them from inside the library, because like configuration libraries and other libraries.
58:06 So you don't want to depend on the other libraries.
58:08 So it's and it's really nice.
58:09 I think it comes.
58:11 The result is that really the architecture of Airflow internally is so much better because of that.
58:17 So less surprises and explicit initialization is like something that we'll have to do rather than implicit initialization, initialization during imports, which which has always been plaguing as a big issue.
58:28 Certainly, it also allows you to imagine each component having an entry point, per se, where you have an initial starting point and it initializes everything it needs by injecting and calling certain factories, which makes a very clean for anyone visiting the project.
58:45 Also, they look at something and they know the entry point very clearly that, hey, this is how it starts.
58:49 This is what it initializes.
58:50 You know, it reminds me of like Golang or Java projects where they have a nice, nice main where in Python, Python, it's not really the same way.
58:59 All right. Well, I think that's about it for all the time we have.
59:02 I guess let's close it out with one final thought.
59:05 Here's just people who are maybe inspired by your design, by the way you put together Airflow and this monorepo concept, especially Python people.
59:15 What do you what do you say to them?
59:17 Final thoughts here.
59:18 I mean, like there was always discussion.
59:20 Like we had lots of discussions internally, even some of the teams members in Airflow.
59:24 They let's split the repository into smaller one.
59:27 Like let's make more of them because it's going to make things easier.
59:30 I was always the monorepo fan and and I made a lot of work to make it possible.
59:35 But that was a very, very difficult thing.
59:37 It's changed.
59:38 So like the reasons why you would like to have multiple repos are gone now if you're using the right tooling.
59:44 And only the benefits or mostly the benefits from having it in one place where you can test everything together and work on it together, remain.
59:51 All the rest is basically gone.
59:53 So for me, the discussion monorepo versus multirepo is already solved.
59:57 Yeah, just do it.
59:58 We it's not even.
01:00:00 So personally, I've been using the read me that we have present in the shared libraries as a context for my ID.
01:00:07 So it's turning out to be very nice for the shared library split, for example.
01:00:12 All I have to do is just provide it the context and tell it, hey, just just construct the structure for me and I can do everything else.
01:00:20 So it's that easy.
01:00:21 We have all the things in place.
01:00:23 We are in the right area to do it.
01:00:24 So just do it.
01:00:25 Very inspiring.
01:00:26 Thank you for being here.
01:00:28 Awesome for this look inside.
01:00:31 And it's Apache Airflow.
01:00:32 It's on GitHub.
01:00:33 People can go look and see.
01:00:34 It's not just a talking vaguely about some internal project.
01:00:38 Right.
01:00:39 So people can go check it out.
01:00:40 All right.
01:00:41 See you later.
01:00:42 Thanks.
01:00:43 Thanks.
01:00:45 This has been another episode of Talk Python To Me.
01:00:48 Thank you to our sponsors.
01:00:49 Be sure to check out what they're offering.
01:00:50 It really helps support the show.
01:00:52 This episode is brought to you by our Agentic AI Programming for Python course.
01:00:57 Learn to work with AI that actually understands your code base and build real features.
01:01:02 Visit talkpython.fm/agentic-ai.
01:01:06 If you or your team needs to learn Python, we have over 270 hours of beginner and advanced
01:01:11 courses on topics ranging from complete beginners to async code, Flask, Django, HTMX, and even
01:01:18 LLMs.
01:01:18 Best of all, there's no subscription in sight.
01:01:21 Browse the catalog at talkpython.fm.
01:01:24 And if you're not already subscribed to the show on your favorite podcast player, what
01:01:28 are you waiting for?
01:01:29 Just search for Python in your podcast player.
01:01:31 We should be right at the top.
01:01:32 If you enjoy that geeky rap song, you can download the full track.
01:01:35 The link is actually in your podcast blur show notes.
01:01:38 This is your host, Michael Kennedy.
01:01:39 Thank you so much for listening.
01:01:41 I really appreciate it.
01:01:42 I'll see you next time.
01:02:11 Bye.
01:02:11 Thank you.