Data Sci Tips and Tricks from CodeCut.ai



Episode Deep Dive
Guest introduction and background
Khuyen Tran is the creator of CodeCut.ai, a site and newsletter sharing daily, bite-size Python and data science snippets. Her work focuses on practical techniques that improve day-to-day workflows for data scientists and engineers, and she’s also the author of “Production Ready Data Science.” See her profile and projects on CodeCut and the CodeCut home page.
What to Know If You're New to Python
Here are a few episode-aligned primers so you get the most from the discussion:
- docs.astral.sh/uv/pip/packages/: uv is a fast package and project manager that simplifies installs and environments.
- hydra.cc/docs/intro/: Hydra manages configuration cleanly across dev and experiments.
- quarto.org/docs/computations/python.html: Quarto’s QMD format blends notebooks and scripts for reproducible articles.
- docs.pytest.org/en/stable/getting-started.html: pytest basics to start testing small units of logic from your data work.
Key points and takeaways
- CodeCut.ai’s micro-snippets approach
Khuyen explains how CodeCut distills one sharp idea per snippet so readers can learn quickly without context overload. She often compares a new tool or feature to something many people already know, which shortens the path to adoption. The site and newsletter emphasize clarity, visual explanation, and pragmatic examples you can paste into real projects the same day.- Links and tools:
- uv over pip/Poetry for speed and simplicity
The episode highlights uv as a fast, modern alternative for dependency management that can replace multiple tools in many setups. Its performance and single-tool ergonomics are especially attractive for data workflows where environment churn is common. The thrust is not “one true way,” but that uv meaningfully reduces friction for day-to-day installs and reproducible environments. - Treat configuration as a first-class artifact with Hydra
Rather than scattering settings across scripts and notebooks, Hydra centralizes configuration in a composable, overridable system. This helps when you need many similar experimental runs or when a project grows beyond quick prototypes. Using Hydra encourages cleaner separation of code, config, and data paths.- Links and tools:
- Notebooks and scripts are allies, not rivals
The conversation frames notebooks as great for exploration and narrative, and scripts/modules as better for structure and reuse. Quarto’s QMD documents bridge the gap by letting you write prose, code, and figures together while keeping execution reproducible. Publishing those QMDs to the web can preserve the narrative while hiding auxiliary code when you only want the result. - A practical publishing workflow: write in Quarto, publish to the web
Khuyen describes writing articles as executable documents, then publishing the rendered results to a website. This keeps the original source fully reproducible and lets you choose what code is shown versus executed behind the scenes. That split keeps posts approachable for readers while staying honest and repeatable for practitioners.- Links and tools:
- Logging you’ll actually use: loguru
The episode touches on pragmatic logging: simple setup, readable output, and signals that jump out during debugging. loguru offers colorized, structured-enough logs with low ceremony, which fits exploratory data apps and lightweight services. Pairing it with HTTP clients lets you see status codes and latency patterns at a glance.- Links and tools:
- Instrument your calls: Requests for quick diagnostics
For many teams, Requests is still the simplest way to talk to services and data APIs. In the show, we discuss using it alongside logging to highlight slow or failing calls with minimal code. That feedback loop makes your notebooks and scripts feel more like polished applications.- Links and tools:
- Bring tests into data projects with pytest
Even a small handful of tests around data cleaning functions and transformations pays dividends. The episode encourages using pytest for fast feedback and for protecting against regressions when refactoring notebooks into modules. Start tiny, test pure functions first, and expand as the project stabilizes.- Links and tools:
- Editor ergonomics matter: VS Code plus Quarto and Python
A straightforward setup using VS Code gives you a single window for code, docs, and execution. With Quarto extensions you can render QMDs and tune which parts appear in the final article. The less you context-switch, the more consistently you publish. - From prototype to production: write like future-you will read it
A theme throughout the episode is leveling up small daily habits: name things clearly, isolate I/O from logic, and capture configuration in files instead of copy-pasted cells. These habits make it easier to move a promising notebook into a CLI, job, or service without a rewrite. Khuyen’s emphasis is on sustainable speed rather than novelty for its own sake.- Links and tools:
- Curate once, help many: how comparisons accelerate learning
Khuyen often frames a new tool by comparing it with a familiar one. That pattern shows up across CodeCut and in the discussion, because it lowers the activation energy to try something new. Adopting this learning style in your team docs can make good practices spread faster.- Links and tools:
Interesting quotes and stories
"I am also the founder of CodeCut, where I share daily tips on both LinkedIn and through my newsletter." -- Khuyen Tran
"So let's start with an article called Goodbye pip and Poetry, Why uv Might Be All That You Need." -- Michael Kennedy
"Let's talk about this idea of managing configuration files with Hydra." -- Michael Kennedy
"So I write and also I run my code in Quarto." -- Khuyen Tran
"Compared to a notebook, it's a big QMD." -- Khuyen Tran
key definitions and terms
- uv: A fast Python package and project manager from Astral, often a drop-in for pip/Poetry with unified workflows. docs.astral.sh/uv/pip/packages/
- Hydra: A configuration framework that composes configs and lets you override them per run from files or the command line. hydra.cc/docs/intro/
- Quarto (QMD): A markdown-plus-code system that renders reproducible documents, blending notebook-style output with script-like controls. quarto.org/docs/computations/python.html
- pytest: A lightweight, scalable testing framework for Python projects and data workflows. docs.pytest.org/en/stable/getting-started.html
- loguru: A minimal-ceremony logging library with helpful defaults and readable output. loguru.readthedocs.io/en/stable/api/logger.html
Learning resources
Here are resources to go deeper on the skills and tools surfaced in this episode. These are practical, hands-on, and align with the themes we covered.
- Python for Absolute Beginners: training.talkpython.fm/courses/python-for-absolute-beginners
- Move from Excel to Python with Pandas: training.talkpython.fm/courses/move-from-excel-to-python-and-pandas
- Getting started with pytest: training.talkpython.fm/courses/getting-started-with-testing-in-python-using-pytest
- Visual Studio Code for Python Developers: training.talkpython.fm/courses/visual-studio-code-for-python-developers
- Polars for Power Users: training.talkpython.fm/courses/polars-for-power-users
Overall takeaway
Small, repeatable habits compound. CodeCut’s micro-snippets, uv for frictionless environments, Hydra for clean configuration, and Quarto for reproducible publishing all nudge your data work toward sturdier, faster outcomes without heavy ceremony. If you adopt even one of these ideas this week, your future self and your collaborators will feel the difference.
Links from the show
Khuyen Tran (GitHub): github.com
CodeCut: codecut.ai
Production-ready Data Science Book (discount code TalkPython): codecut.ai
Why UV Might Be All You Need: codecut.ai
How to Structure a Data Science Project for Readability and Transparency: codecut.ai
Stop Hard-coding: Use Configuration Files Instead: codecut.ai
Simplify Your Python Logging with Loguru: codecut.ai
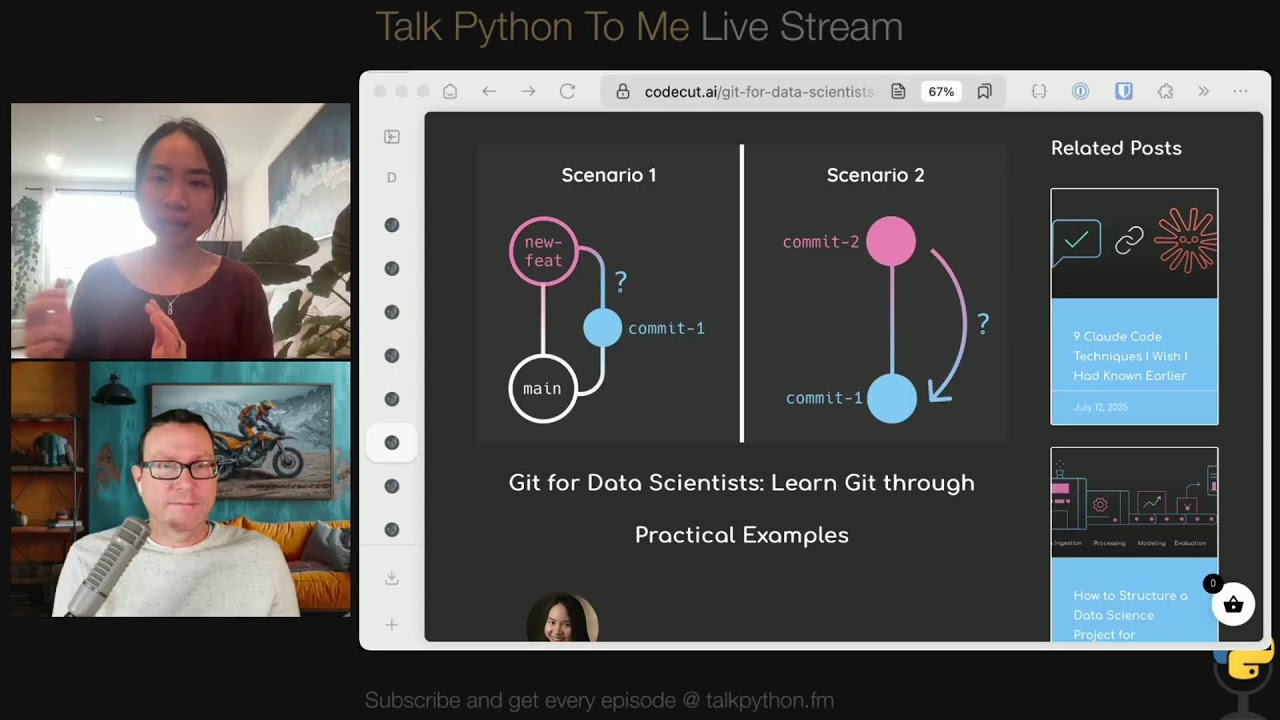
Git for Data Scientists: Learn Git Through Practical Examples: codecut.ai
Marimo (A Modern Notebook for Reproducible Data Science): codecut.ai
Text Similarity & Fuzzy Matching Guide: codecut.ai
Loguru (Python logging made simple): github.com
Hydra: hydra.cc
Marimo: marimo.io
Quarto: quarto.org
Show Your Work! Book: austinkleon.com
Watch this episode on YouTube: youtube.com
Episode #522 deep-dive: talkpython.fm/522
Episode transcripts: talkpython.fm
Theme Song: Developer Rap
🥁 Served in a Flask 🎸: talkpython.fm/flasksong
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 Today, we're turning tiny tips into big wins.
00:02 Khuyen Tran, creator of CodeCut.ai, has shipped hundreds of bite-sized Python and data science snippets across four years.
00:11 We dig into open source tools you can use right now, cleaner workflows, and why notebooks and scripts don't have to be enemies.
00:19 If you want faster insights with fewer yak shaves, this one's packed with takeaways you can apply before lunch.
00:25 Let's get into it.
00:26 This is Talk Python To Me, Episode 522, recorded September 4th, 2025.
00:50 Welcome to Talk Python To Me, the number one podcast for Python developers and data scientists.
00:55 This is your host, Michael Kennedy.
00:57 I'm a PSF fellow who's been coding for over 25 years.
01:01 Let's connect on social media.
01:03 You'll find me and Talk Python on Mastodon, Bluesky, and X.
01:06 The social links are all in the show notes.
01:09 You can find over 10 years of past episodes at talkpython.fm.
01:13 And if you want to be part of the show, you can join our recording live streams.
01:17 That's right.
01:17 We live stream the raw, uncut version of each episode on YouTube.
01:22 Just visit talkpython.fm/youtube to see the schedule of upcoming events.
01:27 And be sure to subscribe and press the bell so you'll get notified anytime we're recording.
01:32 This episode is brought to you by Sentry.
01:34 Don't let those errors go unnoticed.
01:36 Use Sentry like we do here at Talk Python.
01:38 Sign up at talkpython.fm/sentry.
01:41 And it's brought to you by Agency.
01:44 Discover agentic AI with Agency.
01:46 Their layer lets agents find, connect, and work together.
01:49 Any stack, anywhere.
01:51 Start building the Internet of Agents at talkpython.fm/agency spelled A-G-N-T-C-Y.
01:58 I'm super excited to tell you that I just released my first solo book.
02:02 It's called Talk Python in Production.
02:05 It's the inside look at how we host all the Talk Python sites, APIs, and more.
02:10 The core idea is that I believe most hosting stories sold to developers and data scientists are way overcomplicated and overpriced.
02:18 You've heard me say that you're not Google and you're not Facebook, so you shouldn't run your infrastructure the way they do.
02:24 But if not that, then what?
02:26 This book is both a blueprint for what I chose at Talk Python and a story arc of 10 years of running our own infrastructure from complete newbie to pretty neat infrastructure as code DevOps style.
02:38 You'll find the book right on talkpython.fm.
02:41 Just click book in the nav bar.
02:43 I've made the first third of the book available for free for everyone to read online.
02:47 After that, you can grab the DRM-free EPUB and Kindle editions from that same page.
02:52 I hope this book resonates with you.
02:54 People have asked me to share the details of how I run our sites at Talk Python, and now here it is in detail.
03:01 If you're interested, grab the ebook at talkpython.fm.
03:04 Today, I'm working on the paperback version as well.
03:07 It should be out soon.
03:08 Getting the book is a great way to support the podcast.
03:11 Khuyen, welcome to Talk Python.
03:13 Great to have you here.
03:14 Happy to be here.
03:15 Yes, I'm happy to have you here. It's going to be a super fun data science topic. You've got a really cool project over at CodeCut.ai. And one of our listeners reached out and said, you have Khuyen on because she's doing amazing stuff over at CodeCut.ai. And I'm really getting a lot of value out of it. And I'd love to hear more about this project and maybe dive into some of the topics there.
03:40 So we're going to have a really great time talking about that.
03:42 But before we get to those, really quick introduction for everyone.
03:46 Who are you?
03:47 Yeah.
03:47 Hi, everybody.
03:48 I'm Quynh Truong.
03:49 I'm a developer advocate at Nixler.
03:52 I am also the founder of CodeCut, where I share daily tips on both LinkedIn and my news through my newsletter.
04:02 and I send out short tips which have about data science and Python in the form of code snippets that is very easy to digest in two minutes or three times a week.
04:17 Three times a week.
04:18 Yeah.
04:18 That's a lot.
04:19 Yes, it's a lot of work, but I have been doing it for four years, I think.
04:24 So I have been writing tips, writing Python snippets for like basically every day of the week on the weekday for four years.
04:35 Yeah, very fun.
04:36 And you also have longer form articles there.
04:39 Yes, that is correct.
04:40 I also enjoy writing long form articles that dive deeper into open source.
04:47 So majority of the time, like 95% of the time, I write about open source, Python, data science, so very specific.
04:55 And I like to really explore how, you know, what should data scientists use this tool and how they use it.
05:07 And my assumption for every article is data scientists are very busy.
05:12 And if they only have five minutes to read this article, they will be able to get some takeaway from this tool and be able to apply right away.
05:22 So you will see that as a common theme for snippets, micro snippets, as for a newsletter, like very short, very easy to digest.
05:30 As well as article, even though it's long form, but also very, like if they want to, they can skim it, get something out of it.
05:38 Or if they really want to like die deeper, you can sit down and like call along and most will work for getting out of it.
05:47 Yeah, I agree.
05:48 I read a bunch of your articles and I think you can certainly get it a lot even if you just have only time to skim them.
05:54 I learned a couple of extra new tools.
05:57 I think that we're going to have a lot of fun to talk about as well.
05:59 So how do people get your code snippets?
06:03 Is that through your newsletter or how you do that?
06:05 Yeah, people get my code snippets through my newsletter.
06:10 And if you go to the front page, see if you find how it looks like.
06:15 Yes, that's how it looks.
06:17 So just for the audience who's listening, so the form of my newsletter is I would, so I would extract like some specific feature out of the tool, right?
06:28 because if the one tool can have many features and you don't want to talk about all the features in one code snippet, it will be really difficult to digest.
06:37 So I pick one feature.
06:39 I compare it with something that people already know.
06:42 For example, in the screen we see we are comparing between a regular expression, REC-X, library, and DFLIP.
06:50 And we try, I want to compare something people already know, something that is less than all to highlight, okay we see the typical problem with the tool that people all know and here's a solution and this tool offers the solution and so that's true code snippet my my philosophy when it comes to teaching people is it's better to show than to tell so i put a lot of effort into making it very easy for people to when they look at the code snippet they can understand but of course there's supported text. So if you scroll down a bit more, you can see the format.
07:32 Yeah, we see the problem solutions. The problem is, I'll just read it out loud here.
07:37 RegEx pre-processing achieves exact matching but fails completely on typos like iPhone 14 Pro with like two double R max. Dolution diffused provides similarity scoring that tolerates typos and and character variations, enabling approximate matching where red X pairs.
08:00 And they can view the full article if you want.
08:02 But it needs to be digested within the newsletter.
08:06 Yeah, I think you could probably read that and get a good bit of information out of that in like one minute.
08:11 That's really nice.
08:12 And the idea you're highlighting here is like, sure, you can search if you're doing data science, text, NLP type of stuff.
08:19 If you search with regular expressions, you might find things.
08:22 But what if the spacing is different between them or somebody puts a comma or they put iPhone 14 without a space between the 14 and the iPhone, right?
08:32 Like all those things are really tricky to catch every variation.
08:35 So there's better tools like DiffLib, which we'll probably talk about again later in an article, right?
08:41 And in the article, I highlight a lot more tools.
08:44 So it's from like Red X to DiffLib.
08:47 And then if you want to like even better, then fuzzy matching, right?
08:51 And then if even you want semantic capture, and that's another tool.
08:56 And then, of course, you can go down all the spaCy route and into LLMs and like the whole spectrum, right?
09:04 But just knowing about this, because sometimes you don't want full machine learning.
09:09 You just want kind of like regular expressions, but not so hard.
09:12 That's correct.
09:12 Like something that gets the job done.
09:15 To me, the iNew tool is something that is like works right out of the box without a lot of boilerplate code and not too many dependencies.
09:25 Yeah, that's really, really important. So let's talk about the origins of CodeCut.ai.
09:30 Why did you start it?
09:31 So I started when I was in college, so four years. So I started to, I didn't start the website. So I start sharing my tips first i started on linkedin right so i make a commitment to myself that i'm gonna so i i initially i write a lot of articles and i i push out through two to three articles on towards data science every week and i i make the commitment i'm gonna do that every week and then i um i was not very active on linkedin and then i read a book called share your book and it say how know that how messy your work is you should just share and i was very into open source tools and i often you know just send a message to my friends say hey like check this out this is so cool uh and i was like what if i could share with more people so i started to you know put out some of the things that i excited about on linkedin and initially i was so afraid we were like what are talking about you don't know what you're talking about yeah but uh people also very excited about it and i i was like oh great like i shared something i'm excited about and i didn't have some other people and everybody excited about the tour i love that so i keep doing it initially i do it like every day so seven days per week share every day later i was okay i'll be myself the weekend off um but i started to do i think over 500 tips and then people was like where can i find the old one, right? Because if you want to, let's say, if you are interested in machine learning tools or data processing tools, how do you find it on LinkedIn? There's no way for you to categorize.
11:17 So I started to go back to most of my, it's, it's, there's so many. So I try as many as I can, put it into a website. So it was at the time I just find like some domain, it's called mass data simplified and then I just put a bunch there and then I sent out some newsletter so very very not Polish at all and but I just want to have a place to capture it and then later I figured out that people was a lot of time people do have typo when they type because it's very long um URL so I try to make it something very short and actually capture what I
11:55 we do in cold cut so it become cold cut yeah i like the aesthetic of it it looks nice it's got
12:01 this these soft warm colors thank you yeah i try to um you know keep everything kind of like a
12:08 cotton candy so like blue and pink yeah it does yeah cotton candy definitely comes through i can see that for sure what platform did you use to build it i use wordpress uh but i so for articles
12:19 I'm creating a workflow where basically I write all my articles in Quarto, like DocQS.
12:26 Yeah, yeah, yeah.
12:27 I realized that, so I write and also run my code in Quarto.
12:32 And then I use a WordPress API to push it to my article in blog.
12:39 So I do a lot.
12:42 It's easier than, I don't use a WordPress editor to create the article.
12:48 I use VS Code through QMD.
12:52 But for the aesthetic, why I like progress because I can drag and drop.
12:57 I'm not a front-end developer, but it works for me.
13:00 Yeah.
13:00 You know, it's interesting.
13:01 I think a lot of people who are developers get hung up feeling like they have to create their website in the same language or technology that they're an expert in.
13:12 If you're a Python developer, you're like, well, how do I create a website in Python for my blog or whatever language, right?
13:19 But I think there's a lot of value in just saying, it's just a tool, I'm just gonna pick it and it's gonna be great.
13:24 Like for example, I had for a long time, I had my stuff in WordPress under my own domain for my blog and other things.
13:31 And I finally decided to move on to Hugo, but Hugo is also not Go, it's not Python, it's Go.
13:39 And it's just build static sites.
13:40 And I think it's really, it's good if you know the technology, but it's certainly not something I think people should get overly.
13:47 No.
13:47 Hung up on because you lose out on good tools that way, right?
13:51 Yeah, exactly.
13:52 And I mean, you can learn, like, you can learn any language, right?
13:56 If you know one language, you can learn, you're kind of guessing another, especially now with AI.
14:01 Yeah, that's such an interesting topic.
14:03 I do think that's actually really changed a lot of things.
14:07 It's like, well, I could work with this, but I know I'll get stuck on something.
14:12 And now you can just ask an agentic AI, like, I'm stuck on this.
14:15 Okay, here you go.
14:17 And even if it's not perfect, it really, really helps handle, juggle different types of technology.
14:22 Yes, exactly.
14:24 Yeah, super cool.
14:25 So tell me more about this Quarto thing.
14:26 I didn't intend to talk about this, but I find it really interesting.
14:30 Do you write in Markdown?
14:31 Do you write in HTML?
14:32 What do you write in and then publish?
14:34 Yeah, okay.
14:35 So I write in Quarto.
14:37 It is in Markdown, right?
14:38 So somebody knows it's in Markdown, but it's basically really similar to.md.
14:44 The only difference is you can execute the code.
14:48 So my really favorite stack is in VS Code.
14:55 I have Quanto on the left side, and then I open a doc.qmd file.
15:01 People can just imagine it's like a doc.md file.
15:05 But you can click the button, and you can execute.
15:08 So it's very similar to a notebook, right?
15:12 But I like it.
15:15 I really enjoy running in Markdown.
15:17 And it's just like a very clean, right?
15:20 Compared to a notebook.
15:22 It's a big QMD.
15:23 You can think of like a Markdown notebook.
15:26 Just Markdown.
15:27 And you can execute the code.
15:29 And then after I have the image, I have the code, everything.
15:37 I will create some Python functions to clean it up a bit.
15:42 For example, if there's some cell that I wrote, I don't want to show it on WordPress, on my website, I will say echo is false, right?
15:54 It's just like a comment, Python comment on the top of the cell, as you will not show in the website, which is great.
16:01 And then I can just run publish to WordPress and it's publish to WordPress.
16:05 What is nice about it is let's say later some of the content is I want to change.
16:11 Let's say in three articles, I mentioned something, like a link to something, but now it's broken.
16:18 So what I can do is I can just like, you know, click search by all the instances of it, update it.
16:25 And then I run the function sync to WordPress and then it will sync.
16:30 And hey, I don't need to manually go through each of it.
16:34 Yeah, that's really nice.
16:35 And it'll just fix all the articles that needed to be changed.
16:38 Yeah.
16:38 Okay.
16:40 This portion of Talk Python To Me is brought to you by Sentry.
16:43 Over at Talk Python, Sentry has been incredibly valuable for tracking down errors in our web apps, our mobile apps, and other code that we run.
16:52 I've told you the story how more than once I've learned that a user was encountering a bug through Sentry and then fixed the bug and let them know it was fixed before they contacted me.
17:01 That's pretty incredible.
17:02 Let me walk you through the few simple steps that you need to add error monitoring and distributed tracing to your Python web app.
17:09 Let's imagine we have a Flask app with a React front end, and we want to make sure there are no errors during the checkout process for some e-commerce page.
17:18 I don't know about you, but anytime money and payments are involved, I always get a little nervous writing code.
17:23 We start by simply instrumenting the checkout flow.
17:26 To do that, you enable distributed tracing and error monitoring in both your Flask backend and your React frontend.
17:33 Next, we want to make sure that you have enough context that the front-end and back-end actions can be correlated into a single request.
17:41 So we enrich a Sentry span with data context.
17:44 In your React checkout.jsx, you'd wrap the submit handler in a Sentry start span call.
17:50 Then it's time to see the request live in a dashboard.
17:52 We build a real-time Sentry dashboard.
17:55 You spin up one using span metrics to track key attributes like cart size, checkout duration, and so on, giving you one pain for both performance and error data.
18:05 That's it.
18:05 When an error happens, you open the error on Sentry and you get end-to-end request data and error tracebacks to easily spot what's going on.
18:13 If your app and customers matter to you, you definitely want to set up Sentry like we have here at Talk Python.
18:19 Visit talkpython.fm/sentry and use the code TALKPYTHON, all caps, just one word.
18:25 That's talkpython.fm/sentry, code TALKPYTHON.
18:29 Thank you to Sentry for supporting the show.
18:32 Notebooks are awesome.
18:33 And the idea of notebooks are, you know, they really changed the game, I think, a lot.
18:38 But you don't necessarily want to see all of that when your goal is mostly writing, right?
18:44 Like you don't necessarily need to see all the import statements if you're only going to focus on one cell worth of code.
18:51 It's not about the import, right?
18:53 Right.
18:53 Especially when my goal is to make it as easy as possible for data scientist to scheme.
18:59 And, you know, when you skip, you're on block of code, you're like, okay, I skip, I'm done.
19:03 Like, I'll read this the next time.
19:06 But my goal is always raise small code snippet and highlight the core features of the tool.
19:12 And a lot of time, like, you need to hide the unnecessary code, right, you know, for that to happen.
19:19 Yeah, yeah, I totally agree.
19:21 People can get hung up on completeness, and it really takes away from the essence of just, like, skimming it.
19:26 And also, I think that this workflow, it sounds like this is one of the things that made it possible for you to do this frequently, like three, four times a week instead of getting overwhelmed, right?
19:39 Yeah, I really need to learn so many tricks in order to, I guess it's a good thing, right?
19:44 It pushed me to be more productive.
19:46 Like I learned a bunch of shortcuts because, you know, without shortcuts, I cannot get things done quickly.
19:52 So I know a lot of VSCO shortcuts.
19:55 And like I use a text expansion tool.
19:58 It's called Expansal.
19:59 And it's game changer.
20:01 I can like, you know, like view the code.
20:03 This article, right?
20:04 If you can just colon, doc, something, something, like two words.
20:10 And then it's expand the whole text.
20:12 And then you can fill in the blank.
20:14 Yeah, I need to learn multiple tricks.
20:17 And also like just automate things is how I can get it out.
20:21 But yeah, what I still find is, so by doing that, right, I can actually focus on the essence of the blog, which is to make it as easy as possible to digest as well as researching, which is very important.
20:38 Yeah, absolutely.
20:39 I love your philosophy here.
20:41 I can see why the site is popular.
20:45 And, you know, the show your work, I think that's a great philosophy as well.
20:48 It's like get it out there even if it's messy and get it out there even if it's incomplete, right?
20:53 That's the idea?
20:53 Yes, exactly.
20:54 And I really do recommend it for especially people who try to find a job, right?
21:00 At the time, I kind of like another side effect of it is you show people what you know.
21:07 Because so many people, they know a lot, but they don't share, right?
21:13 And if you let employers to find you by guessing what you know or look at your resume, it's very hard because now with AI, everybody has very polished, very nice resume.
21:27 So why should they choose you over another person?
21:30 But by showing your work, by showing even the messy one, they will be able to see, okay, this is what they're interested in.
21:37 This is what makes them excited about.
21:39 And this is what they know.
21:40 then they will be able to imagine how they can use you in their company.
21:45 And that's how, because of me sharing my articles, as well as LinkedIn posts early on in when I was in college, I was able to get multiple internships in data science.
21:57 Yeah, super neat.
21:58 And, you know, you're in developer relations, and I think there's a strong communication aspect of that as well.
22:04 And this is just another example of like, yeah, you want to hire me for this thing, I'm already doing it, right?
22:09 Like one of my first important jobs I got, I was doing a lot of speaking at user groups and meetups.
22:15 They weren't called meetups then because meetup.com didn't exist, but you know, they were meetups and I got a message from a company and they said, Hey, we saw you're talking to this place and that place and you're doing that for free.
22:27 We'd pay you if you want to do this for a job.
22:29 I'm like, great.
22:31 Where do I sign up?
22:32 I didn't even have to apply.
22:33 They just reached out to me and the timing was perfect because I had quit my longtime job a week before and I'm like okay well I was about to start looking for a new job but I guess
22:41 wow you're so brave you look for a new job after you quit your job that's very brave when you like intended to take a break or something no I was not as brave as it
22:53 sounded I am my wife got her PhD and finished and she was getting her first professor job on the other side of the country and so I was like well I'll wait till we get there and look for a job because it was San Diego to New Jersey level of travel.
23:09 It was far, right?
23:10 So I figured I'll find something there.
23:12 I see.
23:12 And then you got a new job.
23:14 Yeah, yeah.
23:14 I think I'd quit my job, but I was still working for a month because I knew I was going to be moving in a while.
23:21 And so like, okay, guys, I'm leaving in a month, six weeks or whatever.
23:25 And about that time, people reached out.
23:27 So it was a perfect, perfect deal.
23:28 I see.
23:29 But just like you said, it's because of the stuff I was doing out in public, right?
23:33 Right.
23:34 Yeah.
23:34 Yeah. Okay. So let's dive in. Let's dive into CodeCut here. And the idea I thought is maybe we could just go through a handful of articles. We picked 10. I don't know how much time we have to go through all of them. We probably can get through all of them, but I think this will give people an idea of what they can get from CodeCut. But also I just think there's a bunch of interesting data science ideas and tools. Yeah. Kind of like that diff lib that we talked about. So I think it'll be a good blend of that type of stuff to talk about. So let's start with an article called Goodbye pip and Poetry, Why uv Might Be All That You Need. So tell us about this and then we can dive
24:11 in a bit. Yeah, so I think a lot of people have heard of uv, which is like dependency management tool. But let me, for people who don't know about it, just kind of give some quick reason why uv is might be something that you want to look into so a lot of data scientists know conda and no peep right i think poultry is a little bit less common um but uh for a while poultry is like a modern tool that allows you to do is manage so many things right like um dependency management and virtual environment and you can um it handle anyway so there's a lot of things in poultry but uv is but something that i didn't like about poultry is it's pretty slow for dependency management but when it comes to uv is quick every like it replaces many things and even if you are using you don't want to learn new tool basically you can just use uv pip install something something and you have a speed boost um and it's yeah so i i grow entire article about uv and i also compared with the existing tools to give people some motivation on switching it to uv.
25:32 It's so easy to switch, so why not?
25:34 Yeah, I think I am a huge fan of uv.
25:36 I actually just interviewed Charlie Marsh for his next project, pyx.
25:40 Oh, nice.
25:41 Two days ago, yeah.
25:42 So uv is going to get even better.
25:45 I just pulled up the performance story for uv compared to poetry and Pipsync.
25:51 And yeah, it's, what is that?
25:53 20 times faster than poetry and way faster than everything else.
25:57 Insane.
25:58 Yeah.
25:58 Rust because of the rust.
26:00 I think rust.
26:01 And then also they just rethought the caching and other.
26:07 They just, it's rust plus a bunch of new ideas that came together to make it work really, really well.
26:12 And honestly, I feel a little bit, I feel a little bit bad for the other tools.
26:15 Like I'm a big fan of pip-tools and PipX.
26:19 Me too.
26:20 And, you know, those things are really great.
26:22 And we'll come back and talk about them a bit, I think, as well.
26:25 But I think those tools laid the foundation for what uv is doing.
26:30 And uv sort of naturally brought these together.
26:32 But whenever I think of the contributors and maintainers of those projects, I feel a little bit bad because they're not getting as much love as they used to.
26:39 But they're still great.
26:40 But uv is definitely making a splash.
26:43 Yeah, that's a good way to think about it.
26:45 I get excited about new tools very quickly.
26:48 I don't often think about how the maintainers of the old data tools are less popular think.
26:55 Yeah, it's the natural way of things, I think, but it's also tough.
27:01 So the speed is important.
27:02 One thing I think is interesting, while I think this is especially interesting for data science, and you touched on this already, is I come more from the web API side of Python, I would say.
27:14 And over there, it's been pip all day long.
27:16 It's been pip the whole time.
27:17 But in the data science side, it's really largely been Conda, Anaconda distributions, that kind of thing, Conda environments.
27:27 There's been kind of this separation.
27:30 And obviously, those are all pulling from the same projects.
27:33 They're all on GitHub and so on.
27:35 But there has been a little bit of a difference.
27:37 And I feel like uv has made a really big splash in data science and kind of bringing those two worlds back together.
27:44 What do you think?
27:45 Yeah, I agree.
27:45 I actually have an article a long time ago.
27:49 I think it's probably in cold court still.
27:51 It's called Peep vs. Conduct vs. Coalty.
27:54 So basically, I was trying to give a very fair comparison.
27:58 I was in favor of Coalty.
28:01 But, you know, I compared everything.
28:04 And something that I had, to be honest, I was not a fan of Conduct.
28:10 And after the comparison, I was not even more of a fan of Conduct because I felt like it's very heavy.
28:16 You can use, I think, Miniconda, so it's quicker.
28:19 But at the same time, it installs many dependencies that you didn't ask for.
28:25 So it's kind of like a solution where you have a lot of dependencies out of the box, right?
28:30 But I find that a lot of times, you didn't ask for some dependencies installed, so you don't really have control over what's being installed as well as the way that it solves dependencies or not.
28:43 I find it's very slow.
28:45 But with, so, so poultry was better because, you know, it's cleaner.
28:50 You can see like what you put in.
28:52 You can see like everything in a file.
28:55 Like there's a separate file, right?
28:57 One for, one is what, piproject.com and one is a log.
29:02 You want to see all the sub-dependencies.
29:04 And now uv is, to me, it's like that.
29:08 But to like poultry, but better.
29:11 the fact that it can run very fast. So one drawback of poetry was sometimes it's think very hard about and take a long time to solve, install new dependencies.
29:24 And also, you replace X, you know, like it kind of like an all-in-one-place tool, which is, I think, very necessary, especially for, I mean, for everybody who use Python, but For data scientists, you know, they already have so many things going on and tell them to learn, you know, good practices.
29:45 You know, let's say they want to upgrade, right, from Python 3.5 to 3.6 to 3.7 to, you know, use other tools to do it.
29:54 It seems like a lot.
29:55 If you can just use one tool and then you can run it, like upgrading in one command line, then we're not.
30:04 Yeah, 100%.
30:05 I think it's great.
30:07 it has a lot of compatibility with previous workflows.
30:11 For example, you can use uv pip install instead of using its project management thing, like with add and sync, right?
30:19 So you don't necessarily have to adopt its style.
30:22 You can just say, instead of pip install, you can say uv pip install.
30:26 One of the things that used to bother me, and I honestly just haven't looked for a while, about Ponda was coming from a non-data science side.
30:34 some of the libraries, say, like requests or Flask or something like that.
30:40 Yeah.
30:40 Pyramid.
30:41 Those were held back quite a bit because, you know, they try to make sure there's like a compatibility
30:48 between the versions that they ship through Condit, which is, I think that's good for like data science or reproducibility.
30:54 But when it comes to web frameworks, you've got to be super on top of updates in case there's a security vulnerability.
31:01 You know, you want to release that thing, the day the vulnerability is announced.
31:05 You want to upgrade your website because as soon as it's announced, people start scanning the internet for any website that could possibly be susceptible to that problem, right?
31:13 And so like the web tools were held back a lot.
31:16 So that's one of the reasons I never really embraced Conda.
31:19 Yeah, now that you mentioned it, another, I also found it as one thing I didn't like about Conda is, you know, like there's, let's say data science is like Pandas, right?
31:30 If this Pandas version is available, a lot of time, sometimes it's not available in Condor.
31:36 That's one thing.
31:37 But another thing is data scientists, they collaborate with other engineers.
31:42 So as someone, they need to hand over to the engineers, like machine learning engineers, data engineers, to use their code.
31:49 And I think in my previous company, they didn't use Condor.
31:55 So for them to need to install Condor, there's a way for you from Condor to peep.
32:01 But then the dependencies look very messy, and it's not like a one-to-one translation.
32:07 Sometimes you don't get the same environment.
32:11 Sure, interesting.
32:12 Not the trouble for handing over, right?
32:15 And reproducible is a big thing when it comes to data science, and dependencies play a big part of it.
32:22 So if you make it hard to reproduce the dependencies, then there will be some bugs.
32:29 there will be some errors and even work silent errors.
32:36 This portion of Talk Python To Me is brought to you by Agency.
32:39 Build the future of multi-agent software with Agency spelled A-G-N-T-C-Y.
32:44 Now an open source Linux foundation project, Agency is building the internet of agents.
32:49 Think of it as a collaboration layer where AI agents can discover, connect, and work across any framework.
32:56 Here's what that means for developers.
32:58 The core pieces engineers need to deploy multi-agent systems now belong to everyone who builds on agency.
33:04 You get robust identity and access management, so every agent is authenticated and trusted before it interacts.
33:11 You get open, standardized tools for agent discovery, clean protocols for agent-to-agent communication, and modular components that let you compose scalable workflows instead of wiring up brittle glue code.
33:24 Agency is not a walled garden.
33:26 You'll be contributing alongside developers from Cisco, Dell Technologies, Google Cloud, Oracle, Red Hat, and more than 75 supporting companies.
33:35 The goal is simple.
33:36 Build the next generation of AI infrastructure together in the open so agents can cooperate across tools, vendors, and runtimes.
33:44 Agencies dropping code, specs, and services with no strings attached.
33:49 Sound awesome?
33:50 Well, visit talkpython.fm/agency to contribute.
33:54 That's talkpython.fm/A-G-N-T-C-Y.
33:58 The link is in your podcast player's show notes and on the episode page.
34:01 Thank you, as always, to Agency for supporting Talk Python To Me.
34:06 Next article, let's talk about, I think this is a big one, reproducibility, maintainability, that kind of thing.
34:13 I mean, what you talked about there was kind of a good lead into it, right?
34:16 It's like the production engineers need to make sure that what they're running runs the same as what the data scientists have tested and come up with.
34:25 And if the situation is different, right, the runtime environment is different, well, maybe it's going to give different answers because of different versions or something.
34:33 Yeah, exactly. And dependency is a big thing, but there's also other things that come into it, right?
34:39 And we can talk about it too.
34:41 Yeah, so what are some of the core ideas of reproducibility?
34:45 Yeah, so reproducibility, I think, is, and at the heart of reproducibility is you want to, let's say, especially for data scientists, when they create code, right, create machine learning models, it depends on some, there's a lot when it packages dependencies, but also like depends on parameters that you use.
35:09 and like, you know, even you use everything the same from experiment to experiment, it can produce slightly different accuracy.
35:18 So you want to be able to, let's say one data scientist say, I got a 0.9 accuracy.
35:25 Then they give it, head it over to their teammate to deploy.
35:28 And then it's degrading the performance.
35:32 It's no longer have a 0.9 accuracy.
35:34 It probably can be, you know, without 0.8.
35:37 And so reproducibility is very important in terms of, you know, you want people, if you produce some result, you want other people to be able to reproduce the same results so that your company can profit out of it.
35:51 But another thing is choice, right? Let's say if you data center, you create something that is good, but then you hand it over and it's bad, then it reduces the choice from your co-workers.
36:07 The third thing about it is, let's say if data scientists create some project and then later they want to reuse it, right? Like for another project, they cannot reproduce the same results.
36:19 then it's kind of like throw it away, creating everything from scratch.
36:27 So it also time consuming.
36:30 And another big theme after producing, I think go hand in hand is maintainability.
36:36 But yeah, you can go ahead.
36:37 Yeah, no, I totally agree.
36:38 The maintainability part is super important as well.
36:42 And so what are some of the pieces that go into that?
36:44 I mean, the first thing that comes to mind for me is pinning your dependencies, either through using something like uv init, uv add, uv sync, or just a requirements.txt file or pinning your requirements, you know, through some other means like with poetry, but somehow clearly documenting what's used.
37:03 I think it can be easy for data scientists to just import some things in a notebook and then do a magic, well, uv pip install that right here and let's just keep going.
37:12 But then like, why won't it run later, you know?
37:15 Yeah, are you talking about maintainability or reproducibility?
37:18 Well, I was thinking maintainability, but both, yeah.
37:22 So maintainability, another thing is, another aspect that comes into maintainability is readability, right?
37:30 And I think this is a big thing for data scientists.
37:33 A lot of data scientists don't write readable code and modular code.
37:38 what you will see is like a big chunk of code with like nested if else or using global variables inside a function or not using function at all and there's a lot of duplicate in the code and I mean that is great for quick experimentation like you want to get something out of it but at the same time it's create a lot of technical debt in terms of this multiple thing that leads to not readable, right? So read and I can go deeper. I just want to list it out. Readability and then reproducibility. And readability, you want your code to be readable because data scientists collaborate with other engineers. And if your code and also another problem I saw is data scientists, they cannot read their old code in like a couple of months. They forgot. They won't be right. They're really like, what did I write? And they spend quite bit of time to understand what they write and if they cannot understand or they don't trust it right if you don't understand in a full level you cannot trust it and you cannot use the next project a lot of times they write things from scratch again so readability also if your code is not written well readability and reproducibility you cannot it's harder to reproduce the same result because let's say global variables, you use global variables and it affects your code, then it's hard.
39:09 You might introduce some external factors that make the code different the next time you run.
39:16 So, management really is very important and that comes with, sorry, write readable code, version control, dependencies management, configuration management, meaning you don't want a hard code the values into your code.
39:33 Yeah, this is a really great article here because it shows you so many tools and techniques, I think.
39:38 Yeah, thank you.
39:39 And I also, so writing a maintainable data science project has been my passion for a long period of time.
39:48 And it actually has become a book like this.
39:51 This is the article form, but I also recently wrote a book about this, finished a book about this.
39:57 It's called Production Ready Data Science.
39:59 Yeah, congratulations.
40:00 That's amazing.
40:01 When did you finish it?
40:02 When did you publish it?
40:04 Two months ago, I think.
40:05 Okay.
40:06 So really recently, yeah.
40:07 Very recently.
40:08 It took me quite a while.
40:10 I have other materials because I've been writing about this.
40:14 I have so many materials who put it together and also make it less in an article style.
40:21 Explaining more of the why before the how is also what I focus a lot on this book.
40:28 Yeah, that's a super important part.
40:30 Now, I am a huge fan of thinking a lot about readability and spending a lot of time on readability.
40:37 And I agree with you.
40:39 I think we're on the same page for sure on that one.
40:42 Because if your code is not readable, that doesn't mean it can't be read.
40:45 It just means it's harder to read, right?
40:47 If your code is not readable, it's harder to maintain it.
40:51 It's harder to see the bugs.
40:52 It's harder to read.
40:53 All the things that you've pointed out.
40:54 And I think it's a little bit ironic that the notebook style of development
41:00 that is meant to communicate.
41:02 Like it's supposed to be more communication compared to regular programming, right?
41:06 It's got the markdown cells, it's got the pictures, it's got little tables for like df.head, that kind of stuff, right?
41:13 It's natural way of programming it leads to less maintainable reusable code, right?
41:19 Because it does not encourage functions.
41:22 So like it's really hard to do reuse if you don't think, oh, maybe I need to write a function in this cell, collapse the cell and then use the function later, right?
41:29 That happens, but not very much.
41:31 I was doing some research for, or just looking around, really.
41:36 Research is a little bit high, putting it in a high position compared to what it was.
41:41 I was looking around for some examples, and I found this really cool JPL collection of notebooks for studying, I think, galaxies, like studying the brightness of galaxies and trying to understand things about them.
41:53 They had a bunch of cool notebooks in there, and they were like 1,500 lines of code.
41:59 and stuff in there. One function. One. I'm like, oh, that is probably, I mean, maybe this is necessary, but it's probably not necessary. And this is JPL, right? This is like a polished published thing, not just a random notebook I ran across, right? The Jet Propulsion Laboratory
42:17 in Pasadena, which is, I consider them to be pretty amazing. So maybe speak to a little bit
42:24 about that, like this maintainability thing in juxtaposition with like notebook style.
42:28 Yeah, definitely. That's the thing. I think five years ago, I wrote an article that got very popular, but also a lot of controversy. It's called, I think, something about seven reasons why I switched from notebook to Python script or something.
42:46 So anyway, so the thing about Notebook is a lot of people argue, yeah, you can write functions.
42:53 It's just Python, right?
42:54 You can write functions.
42:55 You can write whatever you want, just like a Python script.
42:59 But the interactive style of it kind of discourages you from doing it.
43:04 Like, why should I write a function when I can just see the result and then I build upon it?
43:12 Because in Notable, what is so great about it is you can see the results and then you can build up upon it in the next cell, next cell, next cell.
43:19 So people are less likely to build a function, which like if you create a function, then like it's hide inside a function.
43:25 It's not execute the code.
43:27 So that's one thing.
43:29 Another thing problematic about Notable is it's encouraged hard coding.
43:35 You know, like a lot of time, because if you want to see the result, you want to put your value in there to see the result.
43:42 another thing is a very big problem is self execution right if you execute self the fact that it gives you the ability to execute in different
43:54 orders is nice but also a disadvantage in a way that if you run it in the wrong order then it will like you get like some can get some result right now that is different from result that you want to run
44:08 right if you forget to run a particular cell, you go back up, run that to refresh it, and then you skip back down.
44:14 Something in the middle was important and you don't rerun it. That's probably not good.
44:18 Yeah, exactly. And that's, I remember when I worked in notebook before, it just gave me a headache because I would run something. I said, oh, did I rerun this? Like, did I run that score or did I not?
44:30 Just to make sure I'll rerun it. So it's something, and then later when I come back to notebook, I was like, I'm not going to reuse this notebook again because I don't know what's going on here.
44:40 Yeah.
44:41 I don't want people to think that I'm completely anti-notebook.
44:44 I'm not.
44:45 But I do think that there are some techniques and some tips that you can use.
44:49 So when I was riffing on functions, one thing I think you could do, and you touched on it as well, is you could take the parts of your code that you want to reuse and put that in a Python script next to your notebook and import it, right?
45:02 And then you can use it.
45:03 A lot of times, I think there's a bunch of cells in notebooks that don't really have to do with the presentation or the important part.
45:11 They're just there like, well, I need to load this thing or I need to like clean up that or something.
45:15 And it has to go before what you actually want to show people.
45:19 You could put that in a script and you could just import it and then show the important part.
45:24 It's more readable, more reusable.
45:26 It's more modular.
45:27 Like in all ways, almost, it's better.
45:29 Yes, I agree.
45:31 The thing about, yeah, Sam, like notebook is great.
45:35 It's very good for presentation.
45:37 But I think the problem is a lot of time people use it more than what it's supposed to design for, which is, I mean, it's prototype, right?
45:44 It's to showcase something, to showcase it with either non-technical or technical people.
45:51 It's not used for like everything.
45:54 And I think that's a problem.
45:55 Like a lot of data scientists use it for everything, including writing production, writing code.
46:01 And again, that's another argument, right?
46:03 Like, can you shoot your production-ready code in notebooks?
46:07 And Netflix did that.
46:08 Netflix created production-ready code in notebooks, and that's great.
46:12 Paper mill and all that stuff, yeah.
46:14 Yeah, that technology allows you to do it.
46:17 I feel like it's still...
46:19 But then Temtem, it's a tool that if you use the right, then it will serve you.
46:24 Yeah, it's interesting.
46:26 Speaking of tools, I know you've talked a little bit about Marimo.
46:31 What do you think about that?
46:32 I think this is a really interesting one.
46:34 I just did a sort of, I did a course called Just Enough Python and it's software engineering for data scientists.
46:40 Nice.
46:41 And I was trying, thanks.
46:42 Yeah, and it's like, okay, a lot of themes that you talk about as well, like you should probably learn Git, you know, and so on.
46:48 But one of the things I really struggled with was I really wanted to use Marimo as the foundation, but, you know, 90% or more data scientists use Jupyter.
46:58 So I ended up using Jupyter, But I think Marimo actually might be a little bit better in terms of software engineering and a little bit better in terms of this order of operations you talked about.
47:10 Because Marimo tracks like, hey, this cell depends upon that cell.
47:12 So if you rerun this one, we've got to rerun that one first.
47:15 It'll catch those kind of things.
47:16 But you want to maybe talk about this real quick?
47:18 Because I know you wrote about it a little bit.
47:20 Yeah, I really like Marimo.
47:22 I think it's great.
47:23 It has been.
47:24 So I was actually in the middle of writing the book.
47:26 Right.
47:27 And I know that people, data scientists love Notebook and I don't want it to be like, Hey, let's just write Python script.
47:33 But at the same time, I really think that Notebook is really hard to write production radical.
47:39 And that's, you know, my book is about production radical.
47:42 So how do you find the middle ground between, you know, an interactive version of Notebook and production radical?
47:49 So Marimor came out and I dig deep into it.
47:52 It solved a lot of problems.
47:53 And first is a self-execution order, right?
47:57 So the problem in Notebook is, let's say you cell 1, cell 2, cell 3.
48:02 You change something in cell 1, for example.
48:06 You all run it, but then you change something in cell 1.
48:09 If you forgot to rerun cell 3, then the result is not going to reflect what you have changed in cell 1.
48:17 But with Marimor, it can detect the dependencies.
48:20 And if you change cell 1 and cell 3 depend on cell 1, depend on the variable in cell 1, then it will execute it automatically, which is great.
48:31 Another big thing is, you know, notebook, not disadvantage, notebook is JavaScript, right?
48:39 So it's very big, unreadable, hard to, if you want to use it or hand it over, reuse it.
48:48 It's really hard.
48:48 Right. It's so common to get a Git conflict when you try to pull a new version just because the output has changed.
48:55 And that shouldn't even be taken into account, right?
48:58 And yeah, that shouldn't be taken into account.
49:00 And also the output can be big.
49:02 But with Marimode, not only just a Python script under the hood.
49:07 So you have the...
49:09 And what great thing about Python script is you can reuse it.
49:14 You can import it in another Python script.
49:16 but also for CI/CD, right?
49:20 And you can write unit tests.
49:23 You know, like with unit tests are important, but with in Notebook, you can write unit tests.
49:28 There's a hacker out, but it's a hack.
49:32 And sometimes people need to put their tests inside Notebook, which is not modular, right?
49:38 It's not, it's make it very messy with code and then tests inside the same place.
49:45 But if you write notebook that is Python script under the hood, then you can write unit tests and you can run it with pytest.
49:53 Yeah, very cool.
49:54 I think this is a neat one.
49:56 I generally wanted to use it, but I'm like, but at the same time, I probably got to speak the same language of the people doing that.
50:03 Exactly.
50:03 Yeah, yeah.
50:05 Another thing I want to talk about here, actually this maintainability article has just got so much good stuff in it.
50:11 Something I think that might be new to folks is Hydra, right?
50:16 Let's talk about this idea of managing configuration files with Hydra.
50:21 Yeah, I love Hydra.
50:23 So Hydra is developed by Facebook Research, and I think I use it.
50:30 It has been my two goals.
50:31 So I have some core tools.
50:33 I go back for every data science project, and Hydra is one of them.
50:40 I guess if you think about Hydra is a configuration management tool, you can write your configuration inside a YAML file, and then you can call things.
50:53 You can access the variables inside the YAML file inside a Python script.
51:00 That is nothing new.
51:01 People know about there's a YAML muting library in Python that allows you to work with YAML.
51:08 But something I like about HIDL a lot is reduce the boilerplate code.
51:15 So you can just add an app like a decorator to your Python function.
51:21 And then it will be able to access everything underneath inside the Python function.
51:27 And instead of using a bracket notation, like for example, if to access a nested value, you might need to use mutual nested function.
51:38 But instead, you can use dot notation, which is very clean.
51:43 Other things are, oh, you can, as your project getting bigger, right?
51:48 I mean, for a small project, maybe a YAML is enough.
51:52 As your project getting bigger, let's say you have, you want to be able to use, especially in like data science experimentation, you want to use different values.
52:02 You want to experiment with different way of processing.
52:05 You want to experiment with different parameters for your models, and that can get messy.
52:10 Your YAML file becomes very big.
52:12 So a good way to handle this is you want to break it into smaller configuration.
52:20 But if you want to do that without Hydra, then you need to write Python functions to access it, to composite it, to put it together, put the pieces of puzzle together.
52:32 With Hydra, you can basically, everything is handled for you.
52:36 So you can break it apart and then you can refer to different part of the pieces.
52:41 You can, like in one YAML file, you can refer to the other part of the YAML file.
52:47 It's kind of like an import, right?
52:48 Import in Python.
52:49 And you can override it.
52:51 Another thing I realized, you can override the parameter from the command line.
52:56 Yeah, that's a cool feature.
52:57 Yeah, so you don't need to go back into the...
53:00 Because a lot of time you want to experiment with different parameters or inside the production environment and the development environment, you might use different parameters.
53:10 And if you can override from the command line, which is used a lot in, you know, different platforms, then that will be amazing.
53:20 Yeah, it's super neat.
53:21 Basically, you provide a bunch of default values instead of hard coding them.
53:25 And then if you need to override them, you can do that through the command line or you could just do it in code or whatever, right?
53:31 Yeah, exactly.
53:31 Yeah, excellent.
53:32 And you bring it all together here in your article, uv run process.
53:38 So you got your Hydra, you got your uv run coming together, all that stuff.
53:42 So you actually have a whole article.
53:44 I originally started talking about it because it was in the maintainability section.
53:47 But you have a whole article called Hydra for Python Configuration, right?
53:50 I, that, the other article is more like a high level, but then I have smaller articles that talk about each tool.
53:58 Super. Okay. Well, we're not making very good progress through this, but that's okay.
54:03 Because these are really interesting topics.
54:05 Another one that you talk a lot about is doing proper logging.
54:09 And you recommend Log Guru, which I love Log Guru. I think it's really great.
54:13 I used Log Book for a long time from Armin Roeneker.
54:16 But then I've been slowly moving towards Log Guru.
54:19 Nice.
54:20 Yeah, I really like.
54:21 So another thing about, you know, like a lot of data scientists, they use print, which nothing wrong with print.
54:28 Like, in fact, you shouldn't use, I think it's overkill.
54:33 You use print in a notebook, right?
54:35 But when it comes to like, if you want to run production ready code, if you have a bunch of prints, because a lot of times you had debugging prints, right?
54:43 And if, yeah, you can go back and delete them and everything.
54:47 But wouldn't it be great?
54:48 But then if you go back to the development environment, then you need to put it back.
54:53 Or if you don't do it at all, if you keep all the print inside your code, you go into development, now you have a bunch of noise when you see the output.
55:02 So with logging, just a simple way of you thinking about, I think a big advantage of logging is you can do logging and you can use different modes like debug, info, warning, error.
55:14 so you can set the level based on, you can show, let's say if you're in development environment, you want to show the debug level.
55:22 If you're going to the production environment, then you might want to do like the info level only.
55:29 But one drawback of logging is, I think it's quite a bit of boilerplate code.
55:37 That's the first thing.
55:37 So it really, even if you can pop in paste, even it's like one barrier.
55:44 you know, like one barrier to use logging.
55:46 Why should I do all of this code when I can just use print?
55:49 Right, it's got like, you got to register handlers and all sorts of funky stuff, yeah.
55:55 But what if you can have the advantage of print, like so easy to use and the benefit of logging?
56:03 Then that's why I'm such a big fan of Loggeroo, which have the best of both worlds and other things that it allows this beautiful app in the box.
56:12 So the login output, it looks colorful.
56:17 It's very easy to see.
56:20 With a standard login, you need to do a lot of, you know, what do you want to show?
56:24 You want to show this.
56:25 You want to show the lines of code.
56:27 You want to show the function where the output is coming from.
56:32 All of those configurations with LogGuru, you can just say from LogGuru import logger and then logger.info something, something.
56:40 and the output is very beautiful.
56:43 Yeah, I really like it.
56:44 You can basically just, if you wanted to kind of keep your print style, you don't have to, you can just import it and use it and it's prints, right?
56:52 Yeah.
56:52 The other thing, like you pointed out, this is a super big, for people who are primarily data scientists who haven't worked with logging a lot or new programming, instead of just saying logger print, you say logger debug or logger info or logger error.
57:05 And then you can say, production, just show me the errors or hey, something's going wrong.
57:09 Actually, show me all the warnings and the info.
57:13 And you can dial it up and down without changing the code.
57:16 So you can leave your effective print statements there and just turn them off with a configuration.
57:20 Maybe with Hydra, who knows?
57:21 Yeah.
57:22 Yeah, really nice.
57:22 And the color.
57:23 Yeah, the color is very nice as well.
57:25 It's very colorful.
57:26 Yeah.
57:27 And the color persists through files, by the way, right?
57:30 So if you have LogGuru logging to a file and then you tail the file in your terminal, you see the color still, which is awesome.
57:37 Oh, wow.
57:37 I didn't know that.
57:38 That's a new point.
57:40 Yeah, yeah.
57:41 Because some of my stuff is all logging with LogGuru and I tell it, the color comes through.
57:46 And it's so much easier.
57:49 Like, for example, on the website, one of the things that I'm logging to a separate file is what are the requests?
57:54 What is the response time?
57:56 What is the status code?
57:58 Is it a 500?
57:58 Is it 200?
58:00 Is it a 300?
58:00 You know, whatever, right?
58:01 All that.
58:02 And so I'll actually have it change the color based on what happens.
58:06 So if the message is a 500, it's a different color than if it's a 200.
58:09 Or if the response time is over 500 milliseconds, it changes color to like a warning sign versus if it's under.
58:16 And all that stuff comes through.
58:17 And it's like so nice with LogRoot.
58:19 So nice.
58:19 Yeah.
58:20 Especially when you have a lot of logs.
58:22 And that is very useful.
58:23 Yeah.
58:24 Absolutely.
58:24 Okay.
58:25 Git.
58:26 Let's talk about source control.
58:28 Yeah.
58:29 Version control, I think, is huge.
58:31 It's very useful.
58:33 And it's very important for data scientists, but I don't see it being used enough.
58:38 I was in, yeah, and the last thing I actually, I was a machine learning engineer in Accenture and working with clients.
58:47 So I was building kind of like a data science environment, data science tool that integrated with AWS SageMaker.
58:59 And it's funny how many data scientists are not using Git.
59:04 And they're multiple data science team.
59:07 And they want to communicate with each other.
59:09 They want to share their work.
59:11 But then every time they want to share their work, it's so hard for them because they don't have a source version control, which surprised me.
59:20 It's a big client.
59:22 I mean, it's a big question.
59:24 Why don't they use Git?
59:26 And if they do, it's not very good practices.
59:30 So that's why I want to educate data scientists more about Git.
59:36 And to me, Git is so important for several reasons.
59:42 First, let's say if you do something, right, you mess up some code.
59:49 Let me give an example of data scientists.
59:51 They produce, they write a model, they write code that produces a model that works great.
59:57 Then like later, they want to twist the parameters, maybe experiment with different type of processing, see if the model performance can increase.
01:00:08 And they mess it up.
01:00:10 The model decreases in performance and they have edited two or three files.
01:00:16 Now they need to, okay, what did I edit?
01:00:18 Now I need to revert it.
01:00:19 And if you don't already like save the last version that was working, you cannot just revert to it, right?
01:00:28 But with Git, you can, there's multiple things.
01:00:31 If you're just a solo data scientist, then you can revert it to the last working version.
01:00:37 But if you work with other data scientists, then you can share, you can also collaborate with them.
01:00:43 like different data scientists can work on different versions and then as they, all different features and when they ready for it to be published and they can merge it together, which is so much better when you do it with Git than manually going life to life.
01:01:01 I think, I agree with you.
01:01:02 I think data scientists don't use source control or version control enough.
01:01:07 And I think that even when people work alone on their own project, they should use, They should use Git or something else.
01:01:14 And honestly, they should just use Git these days because it's the lingua franca of everything that people are doing.
01:01:21 But it lets you do exactly what you're talking about.
01:01:24 And it's not just, oh no, I have to go back.
01:01:27 But I think a really important part of people, speaking to the people who don't really use it that much,
01:01:32 or they only use it in their professional settings in the team maybe, I think it lets you be fearless in exploring new ideas, right?
01:01:40 Like, all right, I'm going to commit this version.
01:01:42 and then let me just terrorize my code and like try something crazy and oh my gosh it worked great we'll keep it if it doesn't work nothing lost you can 100% go back and if people don't if they're
01:01:52 not i mean that's a good reason even by yourself right yeah yeah exactly and it's i feel like it's so easy uh you can do git add commit that i mean um there's a lot of thing you can do with git but i think to just learn some basic git add git commit git push that's it yeah yeah there's not
01:02:10 you don't have to learn there's maybe five or six commands you got to learn mostly your tools that you're working with um you mentioned vs code it's got awesome get oh yeah integration and pycharm and others yeah yeah absolutely i think that's really really nice um let me give you two more ideas and see how these land with you okay or why i think git is now more important than ever yeah number one if you're doing any agentic coding here's another reason to use like a proper editor instead of a notebook as well, potentially. But you can go and say, hey, AI agent, I would like you to change this and add this feature and do this thing. And it'll just go and go for 10, 15 minutes.
01:02:51 What I find a lot of times with these agentic coding things is they make great progress. You're like, wow, this is amazing. It makes more great progress. Like, how is this even possible? I live in the future. And then the next step is, oh no, it broke it all. You know what I mean? And you're like yeah oh yeah you have the same experience yes and i love that you go into this topic because
01:03:10 that's kind of i think of the mathematics i have been mentioned it's more important than ever now that you have ai you're working with ai because um two different things right a lot of time you wanted to do something and then it broke so you want to go back to the previous version that's one thing another thing is if you commit very frequently then you can see what it changed and you can get before you commit it or you push.
01:03:37 Because so many, I think it's so frequently that I do something that is not optimal.
01:03:43 For example, multiple nested.
01:03:46 Like with AI, a lot of time, it overcomplicates the solution.
01:03:51 It makes it so many tries, except, except, and if else, or like it used, it's hard code.
01:03:57 It's just bad practices.
01:03:59 But if you control, you use version control, you can see like the difference, like the last call and the new call, and you can catch it before you commit.
01:04:10 And yeah, it's more important than ever.
01:04:13 Yeah, you're 100% right.
01:04:14 You're right on it.
01:04:16 I find that when I'm doing the agentic coding side of things, I actually have the source control tab open in my editor, not the files tab, but the source control.
01:04:25 And as it's going, I'll see what files are changed and I'll start like looking at the diffs.
01:04:29 Even while it's still working, I'm like, oh, it's on a good path.
01:04:32 oh no, it shouldn't be doing this.
01:04:34 And either you ask it to fix it or you just go, no, I'm reverting it.
01:04:37 Yeah, I added a feature to the website.
01:04:40 Not a super big one, but kind of touched a lot of files.
01:04:43 I think there was 15 commits to achieve that change because every time a major, I'm like, okay, the AI has gotten something right.
01:04:50 I'm like, save that to get.
01:04:51 Yes.
01:04:52 Because it's exactly like you described.
01:04:55 It's awesome.
01:04:55 Yeah, I experienced the same.
01:04:57 Like I would have so many commits for like one feature change Because also something that I tell to do is, you know, just let's say if I want to implement like something I really like to do is go very thoroughly with like planning very, very thoroughly in advance before even code to ensure that everything is what I expected.
01:05:23 And then I let it run.
01:05:24 Right.
01:05:25 And what I did depends on what I do.
01:05:29 but recently I tried to develop like a workflow to go from, you know, my code into newsletter.
01:05:36 So I wanted to implement something and I want to be, I want to be able to walk away and go back and be able to go back to each. So I break into phases, like let's say I break into five phases, right? The easiest phase and the more complicated phase, like the nicer hair feature.
01:05:56 Now I want to go back into each phase and see if it breaks.
01:05:59 I want to know when it breaks.
01:06:02 So for every phase, I ask it to commit so that if I want to, if it breaks somewhere, I can go back to the previous version, which also another thing that you can ask it to commit.
01:06:14 Yeah, yeah.
01:06:15 That's interesting.
01:06:15 I haven't thought about asking it to commit.
01:06:17 That's cool.
01:06:18 I'll give you one final reason to use Git in the agentic world.
01:06:23 And then I think we're out of time.
01:06:24 We're going to have to call it.
01:06:25 but this has been a great conversation.
01:06:28 One other thing you talked about, like, oh, it's made good progress and then something didn't work and you can actually tell it.
01:06:34 You gave your example.
01:06:35 Let me make this more concrete.
01:06:36 You gave your example of, oh, I made some changes as, forget the AI, right?
01:06:40 I made some changes.
01:06:41 It turns out that the performance fell apart.
01:06:44 I edited three files.
01:06:45 I couldn't quite remember what was wrong.
01:06:47 You could go to an agentic AI and say, please look at my local Git history from this commit forward and try to understand why the performance fell apart.
01:06:57 And I bet you it will have some really good ideas, if not know exactly why.
01:07:01 And it can just, it will do what we described for us in reverse.
01:07:04 Like it'll just look at the Git history and go, this changed, this changed.
01:07:07 Oh, if this changed, I bet it had this effect.
01:07:09 And then, right.
01:07:09 So you can leverage it in reverse and feed it to the AI to get understanding too.
01:07:14 Yeah, yeah.
01:07:14 That's such a great use case that you just talked about a lot of time.
01:07:18 You're like, okay, use GitDip.
01:07:20 Look at the difference and tell me what's wrong.
01:07:23 That's another thing that I use very often.
01:07:28 Also, another thing on top of it is, let's say it doesn't code the way you, like everybody has the old preferred style to do things, right?
01:07:36 So sometimes you can edit it and you tell it, okay, look at your implementation and my implementation and just kind of taking notes of the difference so that the next time it will be able to create more similar to the style you're looking for.
01:07:53 Yeah. Yeah, that's a great idea. I feel like we honestly could talk about this for hours, but we're out of time. We're out of time, Khuyen. So thank you for being here. I think let's leave it with this. Let's leave it with two things. First of all, maybe final call to action. People are interested in CodeCut.ai, all of the stuff you've created. How do they get started with all of your resources?
01:08:13 Yes. So just go to my website, CodeCut, so C-O-D-E-C-U-T dot A-I.
01:08:20 And then you will see how to sign up for newsletter.
01:08:24 There's also a book tab that if you want to be interested in production, ready data science, you can buy it there.
01:08:31 It's currently on sales.
01:08:33 It's Labor Day week, so 20% off.
01:08:36 And yeah, that's it.
01:08:38 And if you want to read my blog, go to blog.
01:08:40 If you want to see a sample of my code snippet, go to short post.
01:08:45 Everything is very easy to navigate.
01:08:47 Just go to Word.ai.
01:08:49 Fantastic.
01:08:49 All right.
01:08:49 Well, thank you so much for being here and sharing all your experience and your work.
01:08:53 Really, congratulations on CodeCut.
01:08:55 It's a cool project.
01:08:56 Thank you so much.
01:08:57 You bet.
01:08:58 See you later.
01:08:58 We'll see you.
01:08:59 Bye.
01:09:00 This has been another episode of Talk Python To Me.
01:09:03 Thank you to our sponsors.
01:09:04 Be sure to check out what they're offering.
01:09:06 It really helps support the show.
01:09:08 Take some stress out of your life.
01:09:10 Get notified immediately about errors and performance issues in your web or mobile applications with Sentry.
01:09:16 Just visit talkpython.fm/sentry and get started for free.
01:09:21 And be sure to use the promo code talkpython, all one word.
01:09:25 Agency. Discover agentic AI with agency.
01:09:28 Their layer lets agents find, connect, and work together, any stack, anywhere.
01:09:33 Start building the internet of agents at talkpython.fm/agency, spelled A-G-N-T-C-Y.
01:09:39 If you or your team needs to learn Python, we have over 270 hours of beginner and advanced courses on topics ranging from complete beginners to async code, Flask, Django, HTML, and even LLMs.
01:09:52 Best of all, there's not a subscription in sight.
01:09:55 Browse the catalog at talkpython.fm.
01:09:57 Be sure to subscribe to the show.
01:09:59 Open your favorite podcast player app.
01:10:01 Search for Python.
01:10:02 We should be right at the top.
01:10:04 If you enjoy the Geeky Rap theme song, you can download the full track.
01:10:07 The link is your podcast player show notes.
01:10:10 This is your host, Michael Kennedy.
01:10:11 Thank you so much for listening.
01:10:13 I really appreciate it.
01:10:14 Now get out there and write some Python code.
01:10:29 We'll be right back.