SQLAlchemy 2.0



Episode Deep Dive
Guest Introduction and Background
Mike Bayer is the original creator and lead developer of SQLAlchemy, the hugely popular Python SQL toolkit and ORM that debuted back in 2006. He has spent years refining SQLAlchemy’s internals to handle the most advanced and diverse database use-cases, drawing on experience with complex data systems in industries like finance, content management, and more. In this episode, Mike shares deep insights into SQLAlchemy 2.0, talks about the philosophies of ORM design, and reflects on the evolution of Python itself.
What to Know If You’re New to Python
Here are a few suggestions to help you better follow along with the topics in this episode:
- Basic Python syntax and objects: Know how classes, methods, and functions work.
- Working with virtual environments: Helpful when installing and experimenting with SQLAlchemy and database drivers.
- Basic database queries: Understanding SQL
SELECT,INSERT, andJOINstatements will help clarify how ORMs automate these operations.
Key Points and Takeaways
- SQLAlchemy 2.0’s Core Philosophy and History
SQLAlchemy has been around since 2006, balancing ease of use with the power to generate complex SQL. Version 2.0 is the biggest update since its first release, modernizing many aspects of the library. Mike Bayer emphasizes that SQLAlchemy doesn't “hide” SQL but rather automates repetitive tasks, letting developers stay close to the database’s real capabilities.
- Links and Tools:
- Major 2.0 Changes and the 1.4 Transition
Version 1.4 set the stage for 2.0 by introducing new internals and a “future” API. With 2.0, many old and less-documented features are dropped or marked legacy. Developers are encouraged to switch to the modern APIs (e.g., the
select()function) for clearer, more explicit code.- Links and Tools:
- Async and Await Support
One of the headline features is native support for
async/await, which allows efficient non-blocking database I/O. Rather than rewriting the ORM core from scratch, the team wrapped SQLAlchemy’s internals with “greenlet” so async code runs seamlessly, and you can integrate with frameworks like FastAPI.- Links and Tools:
- Unified Query Syntax with
select()SQLAlchemy 2.0 encourages users to rely on the explicitselect()constructs rather than the oldersession.query(...)style. Under the hood, both produce similar query structures, butselect()leads to cleaner code, better static type checks, and clearer async usage.- Links and Tools:
- Context Managers and Transactions
The newer APIs embrace Python context managers (
withstatements) to handle connections and transactions. Developers can open a transaction withwith session.begin():and, if there’s no exception, it auto-commits at the end; otherwise it rolls back, improving reliability and readability.- Links and Tools:
- PEP 343: The “with” Statement (Reference on context managers)
- Links and Tools:
- Caching and Performance Improvements
SQLAlchemy 2.0 introduces a caching layer for query compilation and processing, reducing overhead on repeated statements. This layer means bigger features—like detecting cartesian joins—won’t slow apps down. Longer term, there are plans to incorporate Cython for even more speed gains.
- Links and Tools:
- Typing and Pydantic/SQLModel Modern Python uses type hints extensively, and SQLAlchemy is adapting with typed declarations on model fields. Projects like SQLModel and Pydantic leverage these type hints even further for validation and create a Pythonic approach to data models that integrate well with SQLAlchemy.
- Unit of Work and Transaction Handling
SQLAlchemy’s “Unit of Work” pattern automatically tracks database changes and flushes them in the proper order. This approach frees developers from manually managing insert vs. update order, especially with complex, self-referential data structures.
- Links and Tools:
- Python Memory and GC Considerations
Large ORM-based queries can trigger Python’s garbage collector. SQLAlchemy tries to eliminate circular references to minimize unnecessary GC cycles. Mike noted they have a test suite specifically to track down excessive GC calls and optimize object lifecycles.
- Links and Tools:
- Migration with Alembic Alembic is the official migration tool for SQLAlchemy. It automates generating and applying schema changes but still allows you to review the resulting scripts to handle complex database-specific DDL. Although it’s not as “magical” as certain Django or Rails tools, it’s highly flexible and robust.
- Links and Tools:
Interesting Quotes and Stories
- On SQLAlchemy’s Philosophy: “We really want you to be in SQL as much as possible, while letting SQLAlchemy automate the boring, repetitive stuff.” — Mike Bayer
- On the Transition to Async: “The async approach is basically an extra layer—we didn’t rewrite the ORM. We just made sure we can gracefully switch context under the hood.”
Key Definitions and Terms
- ORM (Object Relational Mapper): A technique for converting data between incompatible systems (objects in Python) and relational databases.
- Context Manager: A Python structure (using
with) that sets up a resource and automatically tears it down. - Greenlet: A lightweight coroutine library for Python that powers context switches, used here to wrap blocking operations in async code.
- Unit of Work: A design pattern that keeps track of everything you do during a business transaction that can affect the database.
Learning Resources
To explore Python and SQLAlchemy further, consider these courses from Talk Python Training.
- Python for Absolute Beginners: A comprehensive introduction if you are just starting out with Python.
- Building Data-Driven Web Apps with Flask and SQLAlchemy: Step-by-step guide to integrating SQLAlchemy into a modern Flask application.
- Async Techniques and Examples in Python: Learn Python’s
asyncio, threading, and multiprocessing for parallel data processing and more.
Overall Takeaway
SQLAlchemy 2.0 represents a major leap forward for Python’s most popular ORM. It brings new levels of clarity and performance, thanks to native async support, a unified query syntax, and improved transaction handling. Yet it continues to fulfill SQLAlchemy’s core mission: Let you remain close to SQL while offloading repetitive tasks. Whether you’re upgrading existing apps or starting fresh, the changes in 2.0 open the door to cleaner, more modern Python database code.
Links from the show
Mike on Twitter: @zzzeek
Migrating to SQLAlchemy 2.0: sqlalchemy.org
awesome-sqlalchemy: github.com
sqlalchemy-continuum versioning: readthedocs.io
enum support: github.com
alembic: sqlalchemy.org
GeoAlchemy: geoalchemy.org
sqltap profiling: github.com
Michael K.'s ORM GC "problem" example
pythons-gc-and-orms: github.com
nplusone: github.com
Unit of work: duckduckgo.com
ORM + Dataclasses: sqlalchemy.org
SQLModel: sqlmodel.tiangolo.com
Cython example: cython.org
Async SQLAlchemy example: sqlalchemy.org
ORM Usages Stats (see ORM section): jetbrains.com
Watch this episode on YouTube: youtube.com
Episode #344 deep-dive: talkpython.fm/344
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 SQLAlchemy is the most widely used ORM, Object Relational Mapper, for Python developers.
00:05 It's been around since February 2006, but we might just be in for the most significant
00:10 release since the first one, SQLAlchemy 2.0.
00:13 This version adds async and await support, new context manager-friendly features everywhere,
00:18 and a unified query syntax.
00:21 Mike Bayer is back to give us a glimpse of what's coming and why Python's database story
00:25 is just getting stronger.
00:27 This is Talk Python To Me, episode 344, recorded November 10th, 2021.
00:32 Welcome to Talk Python To Me, a weekly podcast on Python.
00:48 This is your host, Michael Kennedy.
00:50 Follow me on Twitter, where I'm @mkennedy, and keep up with the show and listen to past
00:54 episodes at talkpython.fm.
00:56 And follow the show on Twitter via at Talk Python.
00:59 We've started streaming most of our episodes live on YouTube.
01:03 Subscribe to our YouTube channel over at talkpython.fm/youtube to get notified about upcoming
01:09 shows and be part of that episode.
01:10 Mike, welcome back to Talk Python To Me.
01:15 It's been a little while.
01:16 Hi, how are you doing?
01:17 Hey, I'm doing really well.
01:18 When we last spoke, we did speak about SQLAlchemy, of course, but it was in April of 2015.
01:26 That's been a while.
01:27 So was that live version 1.1?
01:29 Something like that.
01:31 Yeah, yeah, yeah.
01:31 And that was episode five of the podcast that's been going for six years.
01:35 So really early days.
01:37 I appreciate you helping me kick off the show.
01:39 And can you believe it's still going?
01:40 That's crazy, huh?
01:41 Yeah.
01:41 Doing great.
01:42 I'm glad Python's popular enough that it can have its own podcast.
01:45 I'm pretty psyched about that.
01:46 I'm super psyched about that as well.
01:48 Maybe let's sort of start with that, actually.
01:51 Back then, Python was already popular, right?
01:54 2015, we'd already sort of hit that hockey stick growth curve that started around 2012.
01:59 But even so, does Python's popularity and growth and appeal surprise you these days?
02:06 No, it doesn't surprise me.
02:07 I'm pleased that it's growing in popularity.
02:11 I think the first thing that I saw about Python when I first got into it in the early 2000s
02:15 was it's really clear.
02:16 It's really unambiguous compared to everything else that I've used.
02:20 And I always wanted to be involved in a language that a quote-unquote regular people can get
02:26 involved with and people at a low level, high level can do things with it.
02:30 I didn't want to be focusing on a computer language that would only be very high level
02:34 math whizzes because I'm not a math person at all.
02:38 That's why I don't really do Haskell.
02:40 I wanted there to be because I worked in different jobs and I always would be, not always, but
02:44 often someone that was writing all the frameworks and the architectures and then all the other
02:48 people were using my frameworks.
02:50 But a lot of those people were not at the level that I was.
02:54 And I wanted to make sure that the stuff that I did was approachable.
02:57 Python's very approachable.
02:58 And the fact that now that the academic world and the media news world is getting very data
03:04 oriented, surprise, they're all using Python.
03:06 Yeah, yeah.
03:07 Surprise, surprise.
03:08 Yeah.
03:08 I missed exactly what I would have expected.
03:10 And of course, it might not have gone that way, but it was a pretty good bet.
03:13 So it's cool that there's a data science profession now and Python is at the center of it.
03:20 So I think that's really great.
03:22 It makes a lot of sense that it's at the center of it.
03:24 I do think it has this special appeal to people.
03:27 And I think it's made up of a couple of parts.
03:29 One is it's, you can be very effective with a partial understanding of Python.
03:33 Like you could not even understand what a class is and you could still do meaningful stuff,
03:37 right?
03:37 Which a lot of languages don't have that feature.
03:39 It has the packages, right?
03:40 All the, I haven't even checked.
03:42 Let me check it out.
03:43 How many packages are on PyPI these days?
03:46 338,000.
03:48 That's a few things to just grab and, you know, build with like Lego block style, some of which
03:54 you've contributed to up there.
03:55 So that's pretty awesome.
03:56 Some of the popular ones.
03:57 Yeah.
03:57 I think it's, I think it's fantastic.
03:59 So good to see people continuing to embrace it.
04:02 And you mentioned making it more accessible, right?
04:06 Like there's different things of accessibility.
04:08 There's, well, I can write four loops and do a list comprehension.
04:12 And that's pretty easy to understand.
04:14 There's another, like, I need to talk to a Postgres cluster and make it do things, right?
04:19 It doesn't matter how simple Python is.
04:21 When you talk to external systems, you to some degree take on the complexity of that external
04:27 system.
04:27 Right.
04:28 And I do think ORMs and in the NoSQL world, ODMs, if you will, really democratize that as
04:36 well.
04:36 You can write the code in the language you already know, and it does the database stuff,
04:41 including the slight mismatch of language features in SQL, like at parameter name versus
04:48 question mark type of variations, right?
04:51 Yeah.
04:52 What's interesting, that particular variation is not even necessary.
04:57 That's a quirk of the Python DB API that they decided to have different parameter styles.
05:01 So yeah, we wanted to make it so you wouldn't have to worry about that.
05:04 Yes.
05:04 As far as democratizing, you know, SQLAlchemy was always aiming to democratize as much as
05:10 it could to make things that are trivial and you shouldn't have to worry about like question
05:13 merge versus colon name.
05:15 You don't have to worry about that stuff.
05:16 But at the same time, I always came from all these different database shops where we had
05:20 to use every feature possible.
05:22 Yeah.
05:23 And it's always about exposing the database, the SQL.
05:27 And SQLAlchemy remains pretty different than most tools.
05:30 Any tool I've seen in Python, more or less, and probably tools in other languages that is
05:35 not trying to create this abstracted way.
05:37 You can't really know that there's some vaguely relational object store thing.
05:42 We really want you to be in SQL and you just happen to be able to write it in terms of Python
05:47 constructs where you can also write SQL strings.
05:49 And we're going to try to get that to have as much flexibility as possible.
05:55 There's a couple of interesting philosophies around SQLAlchemy or philosophies of SQLAlchemy
06:00 that you've imbued upon it.
06:02 And one of them is not to hide the database, right?
06:05 Because you often end up in this leak abstraction where it's like, oh, you can just forget there's
06:09 no database.
06:09 Oh, wait, is it too slow?
06:11 Well, now you're into some weird world where it's not a great fit, right?
06:14 So maybe we could talk a bit about the philosophies a bit before we get into what's new and where
06:20 things are going.
06:20 Yeah.
06:21 The basic philosophy has always been, and I think some years into it, I read some articles
06:25 that gave me some better terminology.
06:26 One of automation of working with a SQL database.
06:30 Like if you're going to write an application that talks to a database and you're going to
06:34 have 20 tables and say you're not using any ORM, you're just going to write
06:38 where you get the rush SQL.
06:39 You're going to find yourself writing the same insert statement, typing it out over and
06:44 over again.
06:44 Like I know that my table has 10 columns.
06:47 I'm going to type this insert statement.
06:48 That's what we call boilerplate.
06:49 Any program that anyone writes using nothing at all, they're going to write some function
06:53 to generate that insert statement, right?
06:56 Like people usually talk about select statements as like the ones they want to have more control
06:59 over.
07:00 But there's just the boring ones.
07:01 There's updates, inserts, and deletes, which are really boring.
07:03 There's all the DDL for creating tables and stuff.
07:06 That's very redundant.
07:08 Nobody needs to, you know, if you want to learn how to do that stuff, you should learn how to
07:12 do that stuff.
07:12 But if you have a hundred classes, you don't want to type in a hundred create table statements.
07:16 You don't want to have to do that.
07:17 It should be automated.
07:19 So the idea is that when you're working in this automated environment, you still know
07:23 everything that's what a create table statement is, what an insert is, you know what crud somewhat
07:28 is.
07:29 SQL, you would know it ideally, not to say, but ideally you would know how to write this
07:34 whole program without using anything.
07:35 Like you would know how to use raw SQL.
07:37 Right.
07:37 I would say a, probably a good rule of thumb for I've studied enough SQL.
07:42 I feel like I'm, I'm not hiding too much from myself by using an ORM would be if you could
07:49 get the ORM to print out its statement.
07:51 So in SQLAlchemy on the engine, if you set echo equals true, for example, and you know what
07:57 it does when you read the statements, you're like, okay, I'm not sure I would have exactly
08:02 seen to write the join that way, but okay, that makes sense.
08:05 I see why it's doing, I see what this update statement, these parameters mean.
08:08 Okay.
08:08 Like now let's just, let's be productive.
08:11 Right.
08:11 What do you think about it as a rule of thumb?
08:12 Echo equals true was when I first wrote SQLAlchemy, whenever I did for the first two weeks,
08:18 echo equals true was right there.
08:20 That was like the very first thing, like you will see the SQL.
08:23 Cause I had come from using, I think I'd probably use Hibernate for a while for Java.
08:27 Now it's 20 years later or 25, Hibernate I'm sure is very different, but at that time,
08:33 I didn't know how to see what the heck it was sending to the database.
08:36 I had no idea.
08:37 I'm sure there was a way to do it, but it wasn't like obvious.
08:40 It was like, you have to set up lockers and this and that and Java, this and Java, that.
08:43 And the idea with Hibernate and other, it was like, you shouldn't have to know that.
08:48 We do the SQL for you.
08:49 Why should you know that?
08:50 And yeah.
08:51 Yeah.
08:52 Use us correctly and we'll solve the problem.
08:54 Right.
08:55 I want to really one-to-one thing where you're writing this Python select dot where dot
09:00 whatever.
09:00 And it's like what you can one-to-one, if I had more videography skills and also a lot of
09:05 time, I'd write like, I'd make some kind of cartoon that shows boom where this, how the,
09:10 how it lines up at the statement.
09:11 Absolutely.
09:12 It was a, it's meant to not, it's not meant to hide anything.
09:15 It's meant to automate.
09:16 So if you had, it was just this term, the idea of a soda bottle company, like a soda company,
09:21 like you're selling soda, which not, soda's not good for you.
09:23 But if you had to bottle 4,000 bottles of soda, you would use a machine to do it.
09:27 It's not to say that you don't know how to pour soda into a bottle yourself, but you
09:31 need to scale it up.
09:32 Yeah.
09:33 It's about scaling up something that is very repetitive to be typing by hand.
09:37 And be consistent and repetitive and whatnot.
09:40 Absolutely.
09:41 Absolutely.
09:42 Yep.
09:42 A couple of comments from the audience real quick.
09:44 I just want to throw out there.
09:44 D Varazo says, hello from.
09:47 Danielle.
09:48 Yeah.
09:49 Yeah.
09:49 From Psycho PG.
09:50 Thank you for your kind wrapping.
09:51 And Jay Lee is just cheerleading for Python, which is awesome.
09:55 Yay for PyTox.
09:55 Awesome.
09:57 Hello, everyone out there.
09:58 So yeah, I think this is really a powerful thing to think about.
10:02 Just the reproducibility.
10:03 And also in terms of linking into the tooling, I think one thing people often miss about the
10:11 advantages.
10:11 Because sometimes you'll hear people say, you should never use an RM.
10:14 It's hiding too much from you.
10:16 Yeah.
10:16 Yeah.
10:17 Yeah.
10:17 Sure.
10:17 Yeah.
10:18 Sure.
10:18 Go.
10:18 I'm going to go do something.
10:20 You keep working on your strings.
10:22 So one of the things I can see that sometimes can easily get missed is refactoring tools.
10:29 Yeah.
10:30 Error checking.
10:30 Right.
10:30 If you write some kind of select statement on a class and you want to change that field
10:35 or that column, you change the field, which obviously maps over to the column.
10:39 But that also changes your entire code.
10:40 If you're using a proper editor that understands refactoring, like VS Code or PyCharm or something
10:46 like that, right?
10:46 Yeah.
10:47 A big thing with the refactoring and one of the things that we had to adapt to as it came
10:51 was PEP44, which is, I call it mypy, but it's not.
10:55 mypy is a tool that checks Python annotations.
10:57 And we call it the mypy thing.
10:59 It's really PEP44, which is that new thing where they're trying to have a kind of a layer
11:05 of typing, like a strongly typed, static typed, sorry, statically typed layer on top of your
11:13 Python script.
11:14 So if you're a library of Python, you have to work with the system now because people expect
11:19 it and the IDEs, I use VS Code now with, so that I keep forgetting the name of the engine,
11:26 but that's.
11:27 PyLance.
11:27 You know what it is?
11:27 Yeah, PyLance.
11:28 I can never remember that name, PyLance.
11:30 PyLance.
11:31 Think of a Lance.
11:32 PyLance.
11:33 PyLance uses the annotations a lot.
11:35 And I actually am seeing where it works and where it doesn't work.
11:39 And I think the refactoring tools are greatly improved by the fact that there is this concept
11:44 of static type annotations.
11:45 I think there's a lot of shortcomings in PEP44.
11:48 There's a lot of things that's like, eh, it's not great.
11:50 I'm not 100% optimistic on it, but I definitely, it's way better than nothing.
11:55 And there's some, also some features that are coming that are in PEPs that have not been
12:00 implemented.
12:00 This thing called variadic types that would allow us to actually be able to type your result
12:05 set coming back.
12:06 If you give it a select, we'll know the types in your result row.
12:09 I see.
12:10 Is that something like a generic or template type?
12:13 It's a generic that works like the tuple type.
12:16 Because you might notice in PEP44, you can't make your own tuple type.
12:20 The typing that's applied to tuple is actually, if you look at the mypy source, it's hard coded.
12:24 If equals tuple, then all these new special things.
12:27 So things like that, they need to fix.
12:30 Yeah, because rows from a database are essentially tuples.
12:32 So that's how we want to type them.
12:34 I do have a question.
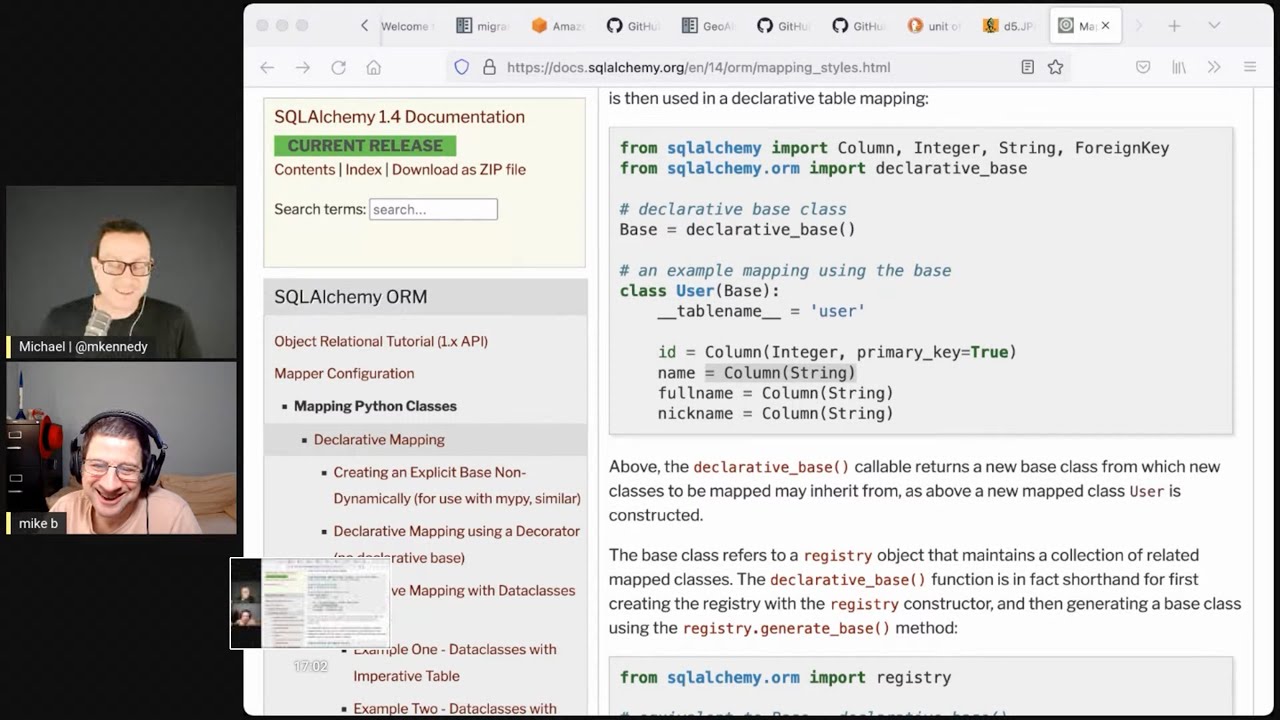
12:34 Since we're talking about the typing, I pulled up this super simple example here off of the
12:40 SQLAlchemy documentation.
12:41 It doesn't really matter.
12:42 It's just a class that drives from declare to base, has a table name, and then it has the
12:46 stuff that people probably know from many ORMs.
12:49 These descriptors, right?
12:50 So ID equals a column, which is of type integer, primary key equals true, name equals column, which
12:55 is a string and so on.
12:56 I'm going to tell you what I've been doing with this stuff lately.
12:59 And you tell me whether this is a good idea or a bad idea or whatever.
13:03 So what I've been doing is I've been writing this code as like this name one.
13:06 I would say name colon string equals column string.
13:11 So the Python code believes it's the type that's backed by the database, the column type.
13:16 So name is a string, ID colon, and even though it's really set to a descriptor of column integer
13:22 primary key equals true.
13:24 Have you seen this?
13:25 Is this a good idea?
13:25 Should I be doing this?
13:26 Yes.
13:27 I have done a lot of work on this concept.
13:29 And what you're doing is not incorrect, but there's a lot of complexities to it that require
13:36 a little more going on.
13:38 Right.
13:38 And to be clear, I'm not doing this for mypy.
13:40 I'm doing this just so my editor is more approachable to me on autocomplete.
13:44 Yes.
13:44 For the editor, I don't have the link handy.
13:46 I'd have to go searching on my computer.
13:47 So first of all, we do have a mypy plugin where you are able to use annotations like name colon
13:54 string, and it will automatically work them into the correct kind of thing to be recognized
13:59 also at the query level.
14:00 It doesn't work with PyLance.
14:03 And I have a new approach that I worked out with some other people for PyLance type stuff
14:08 where we won't need a plugin, where you won't be able to make...
14:11 We're not totally sure how we want to do it.
14:12 The point is that you would say name colon.
14:14 You wouldn't say stir.
14:17 You would use this other construct called mapping or maps rather and maps.
14:21 And then the map type is stir.
14:22 The reason you do that is because if you use the user class in a query, not as an instance,
14:28 it also has behaviors at the class level.
14:31 Right.
14:31 Like .desk for a descending source.
14:34 Yeah.
14:35 Like that kind of stuff.
14:35 Something like that, right?
14:36 Right.
14:37 So I'm trying to work out the best way to do this where you're not typing the same...
14:42 You're not repeating yourself because right now it's a little bit squirrely.
14:45 The class works completely in PyLance.
14:48 Everything that's expected both at the class level and at the instance level will work out.
14:52 It probably requires that when you do the declarative class, you would use a slightly different API.
14:58 The current proposal is instead of using uppercase column, it's this new thing called m.column.
15:04 We can always change the names and how it looks.
15:06 One of the flaws with that declarative model you see there is that when I came up with that
15:11 declarative idea many years ago, those column objects are not Python descriptor compatible at all.
15:17 They actually get replaced when you map the class.
15:20 It's totally...
15:21 Okay.
15:21 ...like a seal.
15:22 It's not that clean.
15:24 So I have ideas to make declarative cleaner and do more of what it's supposed to do without breaking the rules.
15:31 That's the thing about Python is that as the years have gone by, everyone, even newcomers, were all much more into not into being clean about code and being more verbose.
15:40 And typing is more verbose and asyncio is more verbose.
15:43 When we were doing Python in 06, 07, everything was like, done.
15:47 Just magic object.
15:49 Boom.
15:49 Magic object.
15:50 Nobody wanted to type anything, which was bad.
15:52 But we did totally because it was scripting language.
15:54 But nowadays, people are way more tolerant of more verbosity, more clarity.
15:58 And I'm trying to keep SQLAlchemy and my team, we're trying to keep it going along with that.
16:02 So the PEP 44 thing, the AsyncIO stuff, that's my knowledge dump for the typing thing.
16:08 That's fantastic.
16:10 That's a great insight.
16:11 It's a work in progress.
16:12 Do you think that people are more willing to accept a little more structure in the code now because the tooling is more there to help you write it?
16:21 Like I write my maybe C tab.
16:23 I don't write column of whatever, right?
16:26 Right.
16:26 Maybe it's the tooling because nowadays people use Python data classes and they want to use Python.
16:32 We have some support for Python data classes now.
16:35 And the syntaxes that they want me to implement, which we've done, are pretty verbose.
16:40 Because they want to have a data class where you have all your data class fields.
16:43 And then within the field, they want to have the mapping information.
16:46 And people are like, this is awesome.
16:47 And I'm like, great.
16:48 Because it's actually more verbose than I would prefer.
16:52 But people are way more tolerant of that.
16:54 So yeah, I guess their IDEs are spitting things down.
16:56 Or just people, the values are different now.
16:58 Kids these days.
16:59 This portion of Talk Python To Me is brought to you by TopTal.
17:05 Are you looking to hire a developer to work on your latest project?
17:10 Do you need some help with rounding out that app you just can't seem to get finished?
17:13 Maybe you're even looking to do a little consulting work of your own.
17:17 You should give TopTal a try.
17:18 You may know that we have mobile apps for our courses over at Talk Python on iOS and Android.
17:25 I actually used TopTal to hire a solid developer at a fair rate to help create those mobile apps.
17:31 It was a great experience and I can totally recommend working with them.
17:35 I met with a specialist who helped figure out my goals and technical skills that were required for the project.
17:40 Then they did all the work to find just the right person.
17:43 I had short interviews with two folks.
17:45 I hired the second one and we released our apps just two months later.
17:50 If you'd like to do something similar, please visit talkpython.fm/TopTal and click that hire top talent button.
17:58 It really helps support the show.
18:03 Is the goal with the data classes to try to have a more pure entity model that doesn't have column information and key index information?
18:11 There's some other layer that puts those together?
18:14 I haven't really played with that aspect.
18:16 Data classes.
18:17 I haven't really had the Kool-Aid with the data classes yet.
18:21 I think the idea is that it's this very clean data encapsulating object that has kind of prefab constructors and Reaper and validation.
18:31 It does have that kind of stuff.
18:33 That's right.
18:33 Comparison.
18:34 Yeah.
18:34 I might be thinking that Pydantic takes a little further.
18:37 Some murky stuff between data classes, Pydantic and SQLAlchemy.
18:41 Yeah.
18:41 They blend together in my mind a little as well.
18:43 It's all weird.
18:44 Yeah.
18:44 And there's a new product called SQL Model that seems to be pretty popular in that regard.
18:47 Yeah.
18:48 Built on SQLAlchemy.
18:49 Yeah.
18:50 Yeah.
18:50 Which is great.
18:51 It's totally awesome.
18:52 It's actually a more opinionated overlay of the ORM, which is also using Pydantic.
18:59 So that's good.
18:59 Yeah.
19:00 The thing you've got on the screen there is another way of, yeah, that's called a...
19:05 Yeah.
19:05 So it's a data class, but it also has the mapper registry.mapped on it, which is interesting.
19:11 It has some of its table metadata has not just the table name, but all the column information as well.
19:17 It's interesting.
19:18 It does have the same type declaration that I was trying to impose upon the traditional SQLAlchemy models.
19:24 Yeah.
19:24 That's one form of the data class model.
19:26 If you scroll down, the more inline embedded one is there.
19:30 Let me see if that's what it is.
19:31 Yeah.
19:32 That's the one that's even crazier, which the data class fields.
19:36 So you're fully a data class as far as what your IDE sees.
19:40 But then you have the SQLAlchemy mapping stuff inside.
19:43 So all of this is...
19:44 Well, time will tell which approach becomes the popular one.
19:48 Yeah.
19:49 Or people just use SQL model.
19:50 Because the people that like data classes tend to be using SQL model at Pydantic anyway.
19:55 Right.
19:56 Maybe they'll just...
19:56 They'll be there.
19:57 I don't really know.
19:57 Yeah.
19:57 I'm going to talk to Sebastian Ramirez maybe in December or January about SQL model.
20:02 Yeah.
20:03 SQL model is interesting because it basically takes Pydantic models and SQLAlchemy and merges
20:10 them together.
20:11 And Sebastian has a good feel for what a nice API looks like.
20:15 So I'm optimistic for this.
20:17 I haven't done anything with it, but it does look pretty neat.
20:20 What he had to do was he had to modify Pydantic's base class.
20:23 Because when I first looked, man, maybe like in this last past year about how Pydantic do
20:29 SQLAlchemy without having two separate models, I was like, okay, this base class has got a
20:33 whole thing, a lot of things going on that don't work with Python descriptors.
20:36 So it'd have to change.
20:37 And I think Sebastian did that, basically.
20:39 Okay.
20:39 Went in and changed how the init works so that it's compatible.
20:42 Yeah.
20:43 More power to him.
20:44 Yeah, more power to him.
20:45 Awesome.
20:45 I have enough to work on.
20:47 I can't.
20:47 This is like too much for me to also work on Pydantic.
20:50 So I'm glad someone else did it.
20:52 Yeah, absolutely.
20:52 Absolutely.
20:53 One more philosophy thing.
20:55 That is not it.
20:56 This is the one.
20:56 One more philosophy thing that I want to ask about or let you just speak to, because this
21:01 is a key element of how SQLAlchemy works.
21:04 There's other ORMs that work this way.
21:06 And then there's also this one, I think it's called Django.
21:10 People might have used the Django ORM before.
21:12 No.
21:13 That one is more of a traditional Ruby on Rails active record where I have a thing and I call
21:18 save on it.
21:19 Sure.
21:19 You went with this thing called unit of work, which is a little more transactional.
21:23 Like I'm going to do a bunch of stuff and then all together it happens.
21:26 Yeah.
21:26 Maybe just speak to that real quick before we talk about it to you.
21:28 When I was going to do SQLAlchemy, the main thing that I had worked on a lot at work
21:33 was a lot of fancy selects.
21:34 I hadn't done much work with the persistence side, but I read this book by Martin Fowler
21:39 called Patterns and Enterprise Architecture.
21:41 I read it as well.
21:41 It was quite an interesting book back then.
21:43 Yeah.
21:43 And I had actually never, even though I had used Hibernate, I had never heard of unit of
21:47 work.
21:47 And I was like, wow, that looks cool.
21:50 I'm going to write that.
21:52 Because one of the philosophies was like, insert update deletes are really boring.
21:56 And even saying update.save is really boring.
21:59 You're going to, because I, we worked, I was working on a content management system for Major
22:03 League Baseball.
22:03 And when you work with CMS, you have a lot of tree-based hierarchical structures with lots
22:09 of self-referential stuff.
22:10 When you persist self-referential structures in the database with auto-incommented primary
22:14 keys, you've got to get one row, get the primary key back, put it there, put it in there.
22:18 Everything's got to be done in a very specific order.
22:20 Yeah.
22:20 Yeah.
22:21 Like I tried to call save on this, but that didn't work because I needed to call save first
22:25 there.
22:25 And it's like, ah, this is crazy, right?
22:27 So it's like, why would I want to do, why?
22:28 I shouldn't have to do that either.
22:29 I should just have this thing that like, here's everything in a transaction, just push it.
22:32 And it, you know, took a very long time to get it right.
22:36 It has a couple of little chinks in the armor, a couple of cases that you might have to drop
22:41 it to call it flush explicitly, but we never get bugs with the unit of work stuff.
22:46 If you look at unitofwork.py, it hasn't changed in years.
22:50 Yeah.
22:51 It took a long time in the beginning.
22:52 And then I wrote it a few times and we thought it was really bad early on.
22:56 It was very hard to get it right.
22:58 Yeah.
22:58 A lot of edge cases, right?
22:59 I can imagine.
23:00 People can do any sequence of things and then you have to make it right.
23:04 Yeah.
23:04 Mostly that we support these joint table inheritance models were very hard for me to get my head
23:08 around how to persist that.
23:09 And then just took a long, it just took a long time because it grew organically.
23:13 You know, you're coding.
23:14 You're not, you're doing.
23:14 I'm glad you wrote that instead of me.
23:16 So thank you.
23:17 Yeah.
23:17 Yeah.
23:18 I wouldn't be able to do it today.
23:19 You got to be deep in it, right?
23:21 Yeah.
23:22 Comment from Brandon Brenner.
23:24 Hey, Brandon.
23:24 Because I use SQL model in a demo project and it was so easy to use.
23:28 Very nice.
23:29 All right.
23:29 So I think probably the big news over here is 2.0 or as you like to put it at your recent
23:38 talk, the 1.4 inning.
23:39 The 1.4 inning.
23:41 Very early stages are on the site.
23:44 In the library tab is a development thing where development docs are.
23:49 Nice.
23:49 And the current release is a 1.4 or whatever.
23:52 1.4.
23:52 It has a lot of these features in there already, right?
23:55 Yes.
23:56 All of the, just about everything in SQL 2.0 internally is available in 1.4.
24:02 We did the whole of the internals first and added all the stuff so that 1.4 could be a
24:07 transitional release so that all this, all the behind the scenes would be getting tested
24:12 and people use the new APIs and transition over.
24:15 Is 2.0 going to drop some of the older APIs hard?
24:17 Many.
24:18 Yeah.
24:18 Yeah.
24:19 Okay.
24:19 Yeah.
24:20 So people who have looked, 1.4 has this big migration thing where if you're
24:26 on 1.3, which is pretty common, you can go to 1.4 pretty easily without much problems.
24:30 But right.
24:31 When you're on this thing, we have this whole thing that is inspired by the Python 2.3 process
24:38 and at the same time tries to not make some of the, what I thought were mistakes of the
24:44 Python 2.3 process.
24:45 So what this is based on is that 1.4 has a environment variable you can turn on in your
24:51 console or whatever.
24:52 A called SQL can be worn 2.0, something like that.
24:55 And when you turn that on, you're in now, you're in now in warnings mode.
24:58 You will get all kinds of warnings about all kinds of APIs that either have changed or are
25:03 going away or use this one or that one.
25:05 So a lot has happened.
25:06 But at the same time, the reason that's maybe not as scary as you might think is that all
25:10 the APIs that are being deprecated are APIs that I've already taken out of the docs years
25:14 ago.
25:14 Like the APIs that I've been telling people for years, don't do that anymore.
25:19 We don't, we're not going to do that.
25:20 So it's a lot of old stuff that is not what we've featured in the docs.
25:24 Like basically the things we're taking on 2.0 are things that have annoyed me for years.
25:28 And there's a few changes in 2.0 that are a little more boom.
25:31 Like we changed how the engine is auto begin instead of auto commit, but it's 2.0 is basically
25:37 going to be, I think, better.
25:38 It's in line with this whole notion of people are, are appreciate more explicitness when things
25:43 are clear.
25:44 So 2.0 is going to remove a lot of implicit stuff, a lot of five ways to do the same thing
25:50 patterns.
25:50 It's going to narrow you down into one or two possible patterns for things.
25:54 Yeah.
25:55 That hasn't been a thing with SQLAlchemy, right?
25:56 There's a lot of ways to accomplish stuff.
25:59 Yeah.
25:59 Yeah.
25:59 Because I came from Perl.
26:00 I can't, I'm sorry.
26:01 I was doing Perl.
26:03 It's still the case that there's more than one way to do that.
26:06 You can't really get away from that totally.
26:07 Well, there's often there's the, I want the super simple, easy way, just call an ORM method
26:13 and then, oh, we got to rewrite the select statement to use the store procedure type.
26:18 There's usually a backdoor type of thing in a database world that has to happen at some
26:22 point, right?
26:22 Yeah.
26:23 Store procedure is a pretty dramatic example.
26:26 But yeah, these days the way is that when you write your code, it's going to be clear
26:29 where the SQL is being executed, where the IO happens.
26:34 In many ways, it actually was inspired by AsyncIO, where I had been tweeting a lot with people
26:39 into AsyncIO, which I was a little skeptical of it.
26:42 At the same time, what people appreciate about it is that it can show, you're very aware of
26:46 where the actual message to the database is happening.
26:50 This is where the message gets sent down.
26:51 Here's where it comes back.
26:52 When you say await, now.
26:54 Yeah.
26:55 Now it's happening.
26:56 Now, I think that's a little heavy handed, but at the same time, I appreciated that notion.
27:00 So with 2.0, I tried to work with that idea that we want to make it very clear.
27:03 Here's where you're making a SQL save it.
27:06 Here's where it's executing.
27:07 Here's where the results are.
27:08 And then also, here's where the transaction is.
27:11 Those are actually the biggest changes that you're going to know that you're in a transaction.
27:15 You're going to know when your transaction ended.
27:17 You're going to know if you committed it or if it just rolled back.
27:20 Yeah.
27:20 And you'll know.
27:21 And the code is going to be a little more verbose than SQL Alchemist here at .1.
27:25 But people are already writing code that way.
27:27 Because now that I've seen many years of people writing code, you know.
27:30 They're like, I really want to know when this happens.
27:31 So I'm going to be super explicit about it.
27:33 People don't want, they don't want excess bells and switches that don't seem to have any purpose.
27:39 But if your code is clear, basically being able to read the code and the intent is as clear as you can get it.
27:47 Without, this just does that.
27:48 We just know it does that.
27:50 That's where I'm trying to go.
27:52 And I'm somewhat freed by the fact that I know people are more tolerant of step A, step B, step C.
27:58 Sure.
27:58 A little less magic, yeah.
28:00 Yeah.
28:00 People are okay with it.
28:01 Now, they weren't okay with that tiptoe 12 years ago.
28:03 People are like, that's too much typing.
28:05 Sure.
28:05 So it's good.
28:06 I want to talk about this migration thing, like what a person does to go from a 1.3 application onward.
28:11 But I think that's getting a little bit ahead of ourselves.
28:14 What about we talk a little bit about, you know, what is, what are the major features coming in 2.0?
28:20 First of all, obviously, we're finally to Python 3 only.
28:23 Yeah.
28:24 What is it?
28:25 3.6?
28:26 That you're, has a minimum version?
28:27 We're going to make it 3.7.
28:28 3.7.
28:28 Okay.
28:29 3.7.
28:30 Yeah.
28:30 3.6 is EOL.
28:31 So.
28:31 Yeah.
28:32 In a case of a month or two.
28:33 Yeah.
28:33 Yeah.
28:33 No point to do that.
28:34 Yeah.
28:34 Just today, or I didn't merge it yet, but like we're ready to merge this gigantic Garrett
28:39 review that's going to take all the Unicode conversion crap out.
28:43 That was all Python 2.
28:45 Python 3 having native Unicode is tremendous for us because all the DB APIs do the Unicode now.
28:52 It was the new API.
28:53 So yeah, we, we have this new school caching system that I've talked about a bunch in the,
29:00 some of the talks I did recently.
29:01 Yeah.
29:02 Tell us about that a little bit.
29:03 Yeah.
29:03 That's in 1.4.
29:04 Is that like compiling the SQL statements and then like caching those results or what are
29:10 we talking about here?
29:10 It caches the, so when you run a SQLAlchemy statement, we have to take your Python code and
29:15 make a string out of it, which is the string we sent to the database.
29:18 We also have to look at that thing and figure out what kinds of results are we going to get
29:21 back?
29:22 Are we going to get strings and dates, injures and floats?
29:25 And then for those strings and states and floats and whatever, do we have to do any processing
29:29 on the rows?
29:29 We want to have that all set up because if you get 10,000 rows back, you want to make all
29:33 those decisions up front.
29:34 So that when you run 10,000 times, everything is as fast as possible.
29:39 Everything is already figured out.
29:40 When you do the ORM, that whole process becomes like way more complicated.
29:44 There's way more going on as eager loaders and there's more fancy kinds of types.
29:47 We might be taking columns and putting them into an object.
29:51 All of that stuff is time consuming.
29:54 And it all now in 1.4 lives behind what I call the cache wall, which means when the
29:59 caching is working, which it seems to work, it's only going to do that stuff once for a
30:04 statement that's been cached.
30:05 So when we run your statement, we're going to do a process that's still a little pricey,
30:09 which is to get a cache key from what you typed.
30:12 You've got to determine some sort of unique hash type of thing out of it.
30:15 It's a unique, it's actually a gigantic tuple right now.
30:18 And maybe it'll be a hash in some other release.
30:20 But for now, it's a giant tuple because Python's pretty good at that.
30:22 It's cheaper than running, than doing the whole compilation.
30:24 And then we get the whole compilation from a cache if it's there.
30:28 And it's LRU cache.
30:29 So if it's not, we make it.
30:30 And it allows us to put more bells and whistles into the compiler.
30:35 We have this thing where it will now detect if your statement will produce Cartesian product,
30:40 meaning you have joins between tables that are not linked together.
30:43 And we have all kinds of other fun things the ORM can do that take a little more time to compile.
30:48 But now they're behind a cache.
30:49 So the performance is not really impacted too much.
30:53 And so that's exciting stuff.
30:55 And we're going to be looking at 2.0 to start using Cython to speed this up even more.
31:00 Oh, fantastic.
31:01 Yeah, it has C-Extensions that we wrote as C code years ago.
31:06 We're going to migrate those to Cython so that we can more quickly add new Cythonized code
31:12 for different sections to speed up to how those cache keys get built.
31:15 Yeah, it's one thing to say we're going to write some big chunk in a C layer.
31:19 It's another to say just that loop.
31:21 Could that loop be C, right?
31:24 And with Cython, you can kind of just do that, right?
31:27 You can do that.
31:27 You could do it quicker and without having to worry about all the memory reference counters.
31:32 C code in Python is pretty tedious.
31:35 I'm not really a spectacular C programmer anyway.
31:38 Well, and also a lot of people who might want to come contribute are probably not C developers.
31:42 They're Python developers first.
31:43 Yeah.
31:44 Yeah, Cython is pretty cool.
31:45 Cython is pretty cool.
31:47 Because you can really, if you just do Python, you can do it.
31:49 It's just like a strict Python.
31:51 Yeah.
31:51 It's pretty neat.
31:52 Yeah, it is.
31:52 And we found that some of the Cythonized versions of the functions are actually faster than RC code.
31:58 Really?
31:58 Which seems strange.
31:59 That's pretty strange.
32:00 Yeah, faster.
32:01 Because Cython, the people that did Cython optimized the crap out of it.
32:05 They know all these very esoteric Python C API things that, like literally, we have RC code
32:11 is not a lot of codes.
32:12 That's like a few hundred lines.
32:13 We'll call it a tuple get item or whatever it's called.
32:16 Cython has some, if we do this, then it's faster.
32:19 And it actually is.
32:21 I can't give you detail on, because I don't know, but like we did benching and Cython
32:26 was actually faster than RC code.
32:27 Yeah.
32:27 I remember way, way back when hearing, you know, people used to say, well, if you want
32:33 it to be fast, you have to write an assembler.
32:34 And then you can use C if you're not, if it's not going to be that fast, you can just use C,
32:38 right?
32:39 That's a different kind of fast.
32:40 Right.
32:40 Well, what I was.
32:41 To be clear.
32:41 What turned, of course, but to be, well, the interesting thing to me was there was this
32:46 switch when the compilers got good enough that you probably were slower writing
32:50 assembly for most people.
32:52 Right.
32:52 And I feel like the thing you're describing here is kind of like that transformation like
32:56 this.
32:56 The compiler understands the whole system better than if you were to try to do it yourself
33:01 at the same level.
33:02 They found.
33:02 Yeah.
33:02 They've apparently.
33:03 Yeah.
33:04 I don't know the specifics, but in some cases they've had figured out ways to make it even
33:08 faster.
33:08 So there's no reason to not use Cython.
33:10 Yeah.
33:10 You think of what people are doing with Cython, right?
33:12 Like they're running on supercomputers doing huge calculations that take.
33:17 So they have a strong motivation to make it a little bit faster here and there.
33:20 Right.
33:21 Yeah.
33:21 Look, here's the thing about Python.
33:22 Python is a high level scripting language.
33:24 It's interpreted always.
33:26 So it's already not.
33:28 I don't want to say that, but if you're really writing high frequency training software, you
33:33 probably want to use something like Rust or something.
33:36 Python's not really that.
33:38 It's a lot of things, but it's not high frequency training speed demon type that it's just it's
33:44 right.
33:44 You can make it do that.
33:45 But once you start wanting it to be sub millisecond, you might want to start.
33:51 But other than that, you're probably fine.
33:52 Yeah.
33:52 Yeah.
33:53 It's not going to.
33:54 I might be wrong.
33:55 It's not going to control the rockets five, but I guess maybe it does.
33:58 I don't know.
33:59 Yeah.
33:59 It's have to be that.
34:00 It's so useful for so much stuff that.
34:02 Yeah, absolutely.
34:03 Okay.
34:04 So that's really cool.
34:05 So you're thinking about switching some of your C code over to Cython, which is really
34:10 interesting.
34:10 And I didn't didn't see that one coming.
34:13 That's awesome.
34:13 The cache layer is cool.
34:15 So that way, if I call a function and in that function, I do a query statement in the ORM.
34:21 The first time that's expensive.
34:22 The second time it's not free, but less expensive.
34:25 Right.
34:25 Cheap ish.
34:26 Much less expensive.
34:27 Much less.
34:27 Okay.
34:28 Yeah.
34:28 Yeah.
34:29 We haven't sped up yet.
34:30 And I've been speaking this for many years is when you fetch rows from the ORM to create
34:35 the Python objects that are your classes, that's still more expensive than we'd like
34:40 it to be.
34:40 Yeah.
34:40 That's super expensive in terms in ORMs and ODMs.
34:44 If you select 10,000 rows out of a database, it's probably the serialization or deserialization.
34:49 That's the cost, right?
34:50 Completely.
34:50 Okay.
34:51 And we've made, I've made the loading way.
34:54 I spent years and years making it way faster by doing that whole thing where we pre-calculate
34:59 everything up front.
35:00 Like every, every like loader, we're not going to like every time you get a row, it's
35:04 like zip, zip, zip, zip, zip.
35:05 We have these little callables set up.
35:06 But still just to make the object, just to make a new class in Python is expensive.
35:11 It's pricey.
35:12 So still a brick of progress.
35:13 But yeah, the caching will not speed that up.
35:16 It'll speed up the overhead per query.
35:18 Which is still like every, every area you can speed it up is great.
35:21 Danielle out there says, Cython is also a great choice to forget about ref count and
35:26 Psycho PG2.
35:27 It took a while to find all the smaller leaks.
35:30 Yeah.
35:30 Ref counts are tough.
35:31 Ref counts are tough.
35:33 Yeah.
35:33 I'm pretty proud of myself that I did figure them out to some degree.
35:36 They're not as hard as Malik and Free, but the ref, it's an esoteric set of rules to
35:41 ref counts.
35:42 While we're down in the internals, let me ask you this.
35:43 If you've thought about this or experimented with this, any.
35:46 One thing as I dug into Python's memory model that I found to be really interesting is when
35:55 you create, you know, you have GC, the GC module, you can say GC get thresholds or set thresholds.
36:00 And the thresholds tell you what will trigger a garbage collection, not reference counting,
36:04 but a cycle detection type of thing.
36:07 Right.
36:07 Yeah.
36:07 The defaults, at least last I'd looked, I haven't looked in 3.10, but in 3.9, it was
36:12 700, 10, 10, which means 700 allocations.
36:17 And then for every 10 Gen 0 collections, there's a Gen 1 and every 10 Gen 1, there's a Gen 2
36:22 collection.
36:23 That 700 means if you allocate more, 700 more classes or dictionaries or tuples or whatever
36:31 than have been freed, a GC will run.
36:34 Yeah.
36:34 So if you select 10,000 rows out of a database, how many GCs are running?
36:39 I mean, that's a lot, right?
36:41 That's like 14 GCs.
36:43 If you're taking the 10,000 rows of putting them in a gigantic list, then it's not GCing much
36:46 at all because you're putting it all in a gigantic buffer.
36:48 You're going to have the size of your process growth.
36:51 But the, I mean, you're not freeing any, but the, and you're not ref count freeing any either,
36:55 but you're, you're allocating 700 more.
36:57 Yeah.
36:58 I think that triggers, I think that might trigger 14 GCs, unless I'm understanding it wrong.
37:02 You would know, I don't know anything about, I wouldn't know.
37:05 I know, all I know about GC is that it's going to happen.
37:07 Yeah.
37:08 I mean, the reference counting stuff is super straightforward, but the GC side, so I've always thought
37:13 about this around the database.
37:15 Even if you're just getting dictionaries, not ORM classes back.
37:19 Yeah.
37:19 If you're selecting a whole bunch of stuff, not only are you doing that serialization layer,
37:23 you're also incurring a bunch of GC because it's trying to preemptively run around and look
37:27 for cycles that might've been forming.
37:29 One thing you can do is make the code so that you don't have as many cycles.
37:32 And we actually do that.
37:33 We've had people post issues related to this.
37:36 So I said, I don't know much about GC.
37:38 I do know that if you can reduce reference cycles, you will have less of these asynchronous
37:42 GC runs happening.
37:43 So we had someone specifically came to me with a whole lot of use cases where he showed when
37:48 you run this little code, like all these GCs would happen.
37:50 And we went in there and got rid of a lot of cycles.
37:53 So we actually have a test suite in test slash AA profiling test man usage called cycle test,
37:59 something like that.
37:59 Okay.
38:00 And they're all these little whiz bangs that run, make a session and close it, do this,
38:04 then that, do this and that.
38:05 And then it will runs it in a harness that actually counting what GC is doing.
38:09 And it's asserting that there's only five GC calls and not 20.
38:12 Right.
38:12 Yeah.
38:13 That's fantastic.
38:13 We have a lot of that happening.
38:15 Yeah.
38:15 Interesting.
38:15 Yeah.
38:16 It's cool that you're, you're thinking about it.
38:18 I mean, on one hand, this is an external thing.
38:20 So you can control your data structures, but you can't totally control what people set
38:23 their GC to do.
38:24 But anyway, it's just something that I always think about when, when you're creating lots
38:28 of these ORM things, because a lot of the signals to the GC are like, oh, I got to get
38:32 busy.
38:32 But yeah, you're not even like, that's a single call to SQLAlchemy and I'm just waiting.
38:37 There's nothing else I can do to get out of the way.
38:39 You know what I mean?
38:39 We've just been around for so many years and people have come to us.
38:42 So we have all kinds of man usage and C profile stuff at our test suite to make sure this
38:47 does the call care of Stoke Grove here to make sure we don't do too many GCs.
38:50 We try to work on that as much as we can.
38:52 We have a new course over at Talk Python, HTMX plus Flask, modern Python web apps hold the
39:00 JavaScript.
39:00 HTMX is one of the hottest properties in web development today.
39:04 And for good reason.
39:05 You might even remember all the stuff we talked about with Carson Gross back on episode 321.
39:10 HTMX, along with the libraries and techniques we introduced in our new course, will have you
39:15 writing the best Python web apps you've ever written?
39:18 Clean, fast, and interactive, all without that front-end overhead.
39:21 If you're a Python web developer that has wanted to build more dynamic, interactive apps, but
39:26 don't want to or can't write a significant portion of your app in rich front-end JavaScript frameworks,
39:31 you'll absolutely love HTMX.
39:34 Check it out over at talkpython.fm/HTMX or just click the link in your podcast player show notes.
39:41 I would say one of the things that makes me more excited than most of the other stuff here
39:46 is probably the async support that you have going on.
39:50 You want to talk a bit about that?
39:52 Yeah.
39:52 So when I was doing 2.0, I thought I wanted to be compatible with how async.io works because
39:58 I figured I would eventually do an async.io API for it.
40:01 But then I suddenly had this idea, why don't we just do the async.io thing?
40:05 And we do it doing this, we use this library called Greenlit.
40:09 The way the async.io works is that SQLAlchemy has async blocking API.
40:14 Yeah.
40:14 We call dbapi execute, it blocks, it comes back.
40:17 Usually the way you want to make that kind of thing work in an async non-blocking context
40:22 is you have to throw all the stuff into a thread pool.
40:25 You probably don't want to be in the wiki.
40:26 This is more old stuff.
40:28 Okay.
40:29 Whoops.
40:29 Yeah.
40:29 Like that one.
40:30 Click an async ORM at the top.
40:33 There we go.
40:34 This is the one I was looking for.
40:35 That's the most basic.
40:35 This is the one I wanted to show people.
40:37 Yes.
40:37 Not the session one, but the ORM.
40:40 Yeah.
40:41 This is ORM.
40:41 So what's important here is that the notion that we, 2.0 style has the thing where there's
40:47 a very specific place that execute happens.
40:49 Because with the query object that SQLAlchemy session.query, you could say query.all, query.one,
40:56 query.first.
40:56 I didn't want to have all this await this, await that, await everything.
40:59 With the new API, it's just, which is really the old API.
41:03 It's await execute.
41:04 And then you get your result back and then the result is buffered.
41:07 And the way this works that changed the whole asyncio equation for SQLAlchemy is that this
41:13 is not a rewrite of anything.
41:14 This is a layer on top of the completely blocking API stuff.
41:18 And it does not use threads.
41:20 It uses Greenlit.
41:21 Right.
41:22 When I went to look at what Greenlit actually does, Greenlit is compared to a thread, but
41:27 it's like a thread.
41:28 But when you see what it is, it doesn't really feel like a thread because it's like, it's
41:31 a little thing with code that you can context switch somewhere else.
41:34 More like, it's more like generators than it is like threads.
41:37 Like the weirdness of generators skipping around.
41:39 Yeah.
41:39 Exactly.
41:39 So the way Python asyncio has that await keyword, the await is your context switch in asyncio.
41:45 Now, I wanted the internals of SQLAlchemy to work in this context switching way, but to
41:50 integrate with await.
41:51 So we basically made a Greenlit wrapper that emulates await without actually using await.
41:57 So you're able to take SQLAlchemy's blocking internals, which ultimately go out to, when
42:03 you use SQLAlchemy asyncio, if you're going to use a DB API, actually it's not DB, it's
42:08 a database driver, that is also asyncio.
42:11 Currently, here goes the goal.
42:13 Async PG, AO SQLite, there's async my, and also there's one, oh, I can't remember the name
42:19 of it.
42:19 Wait, I can't remember the name, trying to get Danielle to, Psycho PG3.
42:23 I was teasing Danielle because he's on there.
42:26 There's going to be a Psycho PG3 that we're also going to support that does asyncio for
42:31 Postgres.
42:31 So you have asyncio driver, SQLAlchemy then adapts, it's the await calls into the synchronous
42:38 thing using the Greenlit thing.
42:40 And then on the outside, where you see on the screen there, is you have asyncio stuff.
42:45 And when I actually talked to some of the people that were involved with asyncio in Python,
42:49 they explained to me, you could do it the other way too.
42:51 You can have a synchronous API that calls into an async middle that goes back out to a
42:57 sync API.
42:58 And that's actually easier to do.
42:59 But since SQLAlchemy was already written in sync blocking style, we kept it that way.
43:02 Right.
43:02 It's a lot easier to wrap an async shell on something that's 15 years old and polished.
43:08 Right.
43:08 Then to say, we're going to do the inside all over again.
43:11 Yeah.
43:11 Yeah.
43:11 And the thing with async is that there were some SQLAlchemy based things on GitHub and
43:16 whatever that were basically taking our engine and connection, rewriting them as totally brand
43:20 new asyncio things.
43:21 Yeah.
43:21 And I always thought that's not, you can't maintain that.
43:24 It's protecting our code, taking about 30% of what it actually does and putting it up.
43:29 And I was like, that can't work.
43:31 There's got to be a way to get green.
43:33 Cause I had used G events and event lit a lot.
43:36 And I'm like, okay, I know if I'm going to do this.
43:38 I know it can context switch without using any way.
43:40 I know it can do it.
43:41 I just had to go in agreement and read the docs.
43:44 And I did that.
43:44 Yeah.
43:45 That's really cool.
43:46 I'm super excited to see this because it opens up using SQLAlchemy with some of the other
43:51 frameworks that really leverage it.
43:52 For example, FastAPI, but there's plenty of others as well.
43:56 Right.
43:56 Yeah.
43:56 Another cool thing about asyncio was that when I did the SQLAlchemy 1.4, which introduces
44:02 this new query ORM interface, but keeps the old one, which is not going to go away.
44:07 Cause there's just too much code in the old query interface.
44:09 But for asyncio, it's totally brand new greenfield development.
44:12 So I said with async, you've got to use our new API that automatically got a lot of people
44:16 to be testing the new way of working and got us to get people.
44:20 Cause the one thing that makes libraries really good is when a lot of people use them and finds
44:25 problems with them and add use cases and the library becomes mature.
44:29 So the asyncio thing has been enormously helpful to bring a lot of people to SQLAlchemy
44:33 who would not have been there.
44:35 A lot of people who were probably going to leave SQLAlchemy stayed.
44:37 Yeah.
44:38 And people using the new 2.0 thing.
44:40 SQL model probably wouldn't have been based on SQLAlchemy.
44:42 Not at all.
44:42 Yeah.
44:43 Yeah, exactly.
44:45 Because obviously, Sebastian needs that to integrate with FastAPI.
44:48 And the async is a core element there.
44:50 Audience, Daniel says, I wonder if other drivers are moving to expose native async interfaces
44:55 themselves.
44:56 Time to go back to DBC.
44:57 DBC, yeah.
44:58 That's the database special interest group.
45:00 Sure.
45:01 Daniel can go there.
45:03 I've not had much success when I go to the SAC, suggest things.
45:07 Yeah.
45:08 Let me talk about this async API a little bit for folks who are probably familiar with SQL
45:13 Alchemy's traditional API.
45:15 because there's a couple of things that stand out to me here.
45:19 One is, let's start simple here.
45:22 One is you have this concept of creating a select statement and then executing the statement
45:28 as opposed to like a query of a dot filter.
45:32 So there's this sort of this statement model that you build up.
45:37 Yeah.
45:37 You want to speak about that?
45:38 The original, the SQLAlchemy with query really is 95% the same statement model.
45:44 It's just the statement has the fetcher, the getter, the result fetching method stuck on
45:49 it.
45:49 And when we, when query came out, that was a historical thing.
45:54 The original idea of SQLAlchemy was that there was only going to be the select object.
45:58 And then you would use select object in with the session to get results.
46:02 And then it wasn't really very done very well.
46:05 It wasn't very flexible.
46:06 So people were coming to me with, why don't we use generative builder thing?
46:10 And that's what happened.
46:12 Cause I wasn't really, I was kind of, I was a little bit rudderless in those days.
46:15 So we had query and it took me quite a long time to realize, wait a second, query is basically
46:21 once query got much more fancy, it started as very simplistic, well, I could query for one
46:24 object and do this and that.
46:25 As I had to keep adding to it, it became clear that I was rebuilding select.
46:29 They met in the middle.
46:31 Yeah.
46:31 Then like, I'm just rebuilding select in exactly the same, but slightly different way.
46:35 And that bothered me for years.
46:37 So with 2.0, I finally took that on and did a really long, difficult refactoring to take
46:45 all of the guts of ORM query and put it into a different module called context that you don't
46:50 deal with.
46:51 And when you get the select object you see there, that indicates the exact same intent as query
46:57 a options filter.
46:59 And they both go to the same backend that does all the ORM figure it out stuff.
47:04 Right.
47:04 That's a little more elaborate to come up with the sequel that will be sent to the database.
47:08 One of the biggest refactoring was I've ever done.
47:11 And it was quite stressful when it seemed like I'm sitting dead ends is, oh, this is not going
47:14 to work.
47:15 Yeah.
47:15 I can imagine.
47:16 It was tough, but.
47:16 Yeah.
47:17 This is cool.
47:17 Yeah.
47:18 So basically the query of class dot that style is going away, right?
47:23 It's never going to go away because there's so much code in that style that it's basically
47:27 not, when you go to the website, it's not going to be in the tutorial.
47:30 It's going to, it'll be in reference docs.
47:32 So people that deal with that code could deal with it.
47:34 It'd be in some sort of middle ground where it's not fully deprecated, but it's not promoted
47:38 either.
47:38 Huh?
47:38 It's called legacy.
47:39 We've had different systems that stayed legacy for many years.
47:42 Makes sense.
47:42 It's very.
47:43 There's so much code written that way.
47:45 I totally agree.
47:45 Yeah.
47:46 I probably would never take it out.
47:47 So, but what I did do is when I do that, I try to make that code written such that it's
47:52 all by itself.
47:53 And it basically what query does now is it makes that select inside and sends it off.
47:58 So it's what you call eating your own dog food.
48:00 It means that the alternate API uses the real API internally.
48:05 So you're testing it either way.
48:06 Right.
48:06 Going back to our patterns talk, it's like an adapter for the select pattern.
48:11 Yeah.
48:11 Okay.
48:11 API.
48:12 Yeah.
48:12 Two other things that stand out here.
48:14 One is you create a session maker traditionally, and you create a session by calling it.
48:19 Here you have an async session maker, right?
48:22 To create them.
48:23 That's one of the differences.
48:24 That's not super different.
48:26 But the other one that is interesting to me is now these things are context managers, which
48:32 when I used to work with SQLAlchemy, traditional ones, I would create a class called a session
48:38 context just so I could do this in a with statement.
48:41 And here, obviously it's an async with statement, but that's just the async.
48:44 It's in the async aspect of it.
48:46 It's in the async aspect too.
48:47 Yeah.
48:47 I should mention that when SQLAlchemy in 2006, we were in Python 2.3, there were not context
48:53 managers.
48:54 They didn't come out until Python 2.5.
48:55 Right.
48:55 So you can't integrate with them if they don't exist in your API, right?
48:58 So I didn't.
48:59 So nothing was based on that.
49:00 SQL me 1.4 and 2.0, as much as possible, completely support the context manager model.
49:06 And the docs and the tutorials, if you look at the new 1.4 tutorial that's on the site, it's
49:12 all about context managers.
49:13 And all the try, accepts, and ready your own thing should go away.
49:17 You should use context managers now.
49:19 And what you see there with the async pattern, I've made it so that if you're using all the
49:23 new APIs, the context manager pattern with the engine and connection in core is mirrored to
49:30 the context manager pattern with the session and the session maker.
49:32 Nice.
49:33 And then it's also mirrored in the asyncio API.
49:36 So there's four different APIs.
49:37 There's core and ORM, sync and async.
49:39 And they all should have, as much as they can, the same, this means cone.
49:45 Yeah.
49:45 They have the same, as much as possible, they share the same context manager patterns.
49:50 And we want you to use context managers for everything now, for any kind of blocking.
49:54 And that's also how we can improve the transactional model so that you're really working the transaction
49:59 all the time with the core.
50:01 Because it's not a burden because you have context managers.
50:04 Things I see here.
50:04 I want to ask you about two bits of code and then take another question from the audience.
50:08 So you have a with session.begin and you do some inserts.
50:13 And then you don't say session.commit.
50:15 So the way this works, I'm presuming, tell me if I understand this right, is if it makes
50:20 it through the with block without an error, it commits.
50:23 If it makes it through the with block with an exception, it just doesn't commit and effectively
50:28 rolls it back.
50:28 That's what it does.
50:29 It does a rollback.
50:30 Yeah.
50:31 That's correct.
50:31 Yeah.
50:31 And we've had the begin context manager for a long time.
50:35 It's just, it wasn't totally consistent everywhere.
50:38 But it's always, we've had that for a long time.
50:40 Yeah.
50:40 But now I've made sure that all the opening and closing of a resource and the begin commit
50:45 of a resource are consistent.
50:47 And also there's always a way that you can open the resource and begin commit in one line.
50:53 Also the session maker has a begin on it now.
50:56 Super.
50:56 And you could do that.
50:57 The other thing I'm super familiar with execute, but then you also have stream, which looks
51:02 real similar.
51:02 What's the difference there?
51:04 Stream is asyncio only right now.
51:06 Stream is because it's important in many cases to get a result that's doing async streaming.
51:11 And when you're doing async streaming with a, you've got to have the await keyword.
51:15 So you can see the result object returned from session.stream is called an async result.
51:19 And all of the methods have the async annotation on them so that you see it's async for a in result.scalers.
51:26 Oh, I see.
51:27 So the things you interact with, the subsequent functions are themselves all async as well.
51:31 Okay.
51:32 Yeah.
51:32 That's cool.
51:32 Yes.
51:32 And what that will do is that will try to use a server-side cursor.
51:36 Yeah.
51:37 Yeah.
51:37 That's what I imagine.
51:37 That's cool.
51:38 You actually are.
51:39 Instead of trying to pull it all into memory, if you got a thousand rows back, you could start
51:43 pulling them more generator-like, right?
51:45 When you use a server-side cursor, you actually are genuinely not pulling everything into memory
51:48 first.
51:49 When you use the buffered result, you're getting everything into memory.
51:52 Yeah.
51:52 Which is normally okay.
51:53 Yeah.
51:54 Most of the time it's fine.
51:55 But if you want a whole bunch, oh, you're flowing it on.
51:58 Yeah.
51:58 Anyway, a lot of cool stuff there.
52:00 We'll get short on time.
52:02 Mr. Hypermagnetic out there asked, does SQLAlchemy support paginated results?
52:06 But that also leads us towards a little area I want to focus on just a couple of things as
52:10 well.
52:11 So yeah, maybe address that first.
52:13 Paginated results is one of those things that seems simple, but it's more of a quagmire
52:18 than you might expect.
52:19 There's different ways to do paginated results.
52:21 The way we all did it years ago was we used these functions that seem called limit and offset.
52:25 offset where limit will give you like 10 rows at a time and offset will start your result
52:29 set in the middle.
52:30 Once we work with bigger database, we all realize that offset is terrible because offset will
52:34 actually get the whole result set and scroll through it.
52:37 It does it on the server side, but it's still very slow.
52:38 So nowadays when you do pagination, you want to have some kind of approach where the query
52:42 you're doing is looking at some data in the data, some row, the data, some column in
52:49 the data you're querying.
52:50 So if you're paginating by date, page 10 would be where date is greater than this date
52:55 that from the previous page you just got.
52:57 That's one way.
52:58 Another way is to write SQL query that do this thing called window functions, where you can
53:02 figure out all the date or this whatever thing ahead of time.
53:05 Pagination implies, on that approach, implies that you have, or actually of any approach,
53:10 implies that you have an order by something.
53:13 So it's hard to make pagination be like this, like this result here, result.scalars to say
53:18 .paginate.
53:19 That's not really, you can make a very crappy version that does that, but it's not really,
53:24 it wouldn't really work that way.
53:25 There is, I should say there is a method in the result called partitions that will give
53:33 you chunks of a result at a time.
53:35 It's not quite the same as pagination because pagination is stateless, it's usually for web
53:39 applications where you're going to get a certain page of a result and then show them a web page
53:43 and then your whole SQL is over.
53:44 Right.
53:45 And then you're going to come back to that SQL later.
53:46 So we have features built in for partitioning of a single result set so that you get chunks
53:52 of that time, which is helpful.
53:53 Pagination is something you need to go look, there's some, I think maybe SQL Utils probably
53:59 has some helper functions for that.
54:01 We have some recipes in that wiki page that I told you to leave.
54:04 There's actually some recipes for pagination there.
54:07 I don't think pagination is like a turnkey.
54:09 It's got to be customized and people will write pagination frameworks and they're complicated
54:14 and they're hard to do.
54:15 So we leave those as an exercise for the community too, but we do have some recipes for that.
54:21 That's a great answer.
54:22 Okay.
54:23 Now for the last thing, I wanted to talk really quickly about this list from Dahlia called
54:29 Awesome SQLAlchemy.
54:30 It's one of these awesome lists that covers all these SQLAlchemy things like data structures
54:34 and types.
54:35 And I'm just throwing this at you and neither of us have a ton of experience with a lot of
54:40 these things, but I thought it'd be fun to just kind of go through them.
54:42 Some of the nice or interesting things that I've ran across here.
54:47 So it's a way to kind of wrap this up like some extras.
54:49 All right.
54:49 So one of them is SQLAlchemy Continuum, a versioning extension for SQLAlchemy.
54:56 I know what this is.
54:57 Yeah.
54:57 Yeah.
54:58 So it's probably based on one of the recipes that we have in the source distribution.
55:04 Version A, yeah.
55:05 It says the first line of SQLAlchemy already has a versioning extension.
55:08 The extension is very limited.
55:09 That's correct.
55:10 Everything he wrote there and everything they wrote there is correct.
55:13 I have some jobs in the banking industry where I was doing SQLAlchemy and we had some need
55:18 to version rows.
55:19 I need to know exactly audit this and when has it changed and how do I go back?
55:24 All that kind of stuff.
55:25 Right.
55:25 Yeah.
55:25 There's different models.
55:26 You can either take the rows as you get them and put them in an aircraft table, or you can
55:30 do this thing where you never update or delete a row.
55:33 You just insert a new row and you've got a temporal version scheme.
55:36 I have some recipes to do that in the example section because I did them at a job and I believe
55:41 Continuum builds upon those.
55:42 Fantastic.
55:43 To make a more robust, supported thing.
55:45 I don't know.
55:46 I've heard of Liquibase.
55:48 I don't know.
55:49 Yeah.
55:51 I forgot where Liquibase is.
55:52 I'm not a Java person either.
55:54 Yeah.
55:55 But yeah.
55:55 Okay.
55:56 Maybe.
55:56 It might be like that.
55:57 Here's another one that I ran across from that SQLAlchemy awesome list is SQLAlchemy
56:01 enum 3.4.
56:03 I'm guessing because it came from Python 3.4.
56:05 This package provides SQLAlchemy type to store.
56:07 I use a standard enum.enums.
56:10 Because a lot of times what happens is those things get turned into like numbers or other
56:14 weird things.
56:15 And here they get a little more type information, right?
56:18 Yeah.
56:18 Yeah.
56:18 This might be obsolete because we do support regular Python enums in our enum type.
56:23 Yeah.
56:24 We did it first.
56:24 This is looking like it's, well, seven months ago.
56:27 I don't know.
56:27 If someone's using this, they could stay because there are some enum features.
56:31 I've been notified that we don't do exactly the way.
56:34 There's some extra features that I forgot what they were, but there are some things that
56:37 enums do that we don't support.
56:39 Maybe it adds that on, yeah.
56:40 So maybe this probably does that better.
56:41 Yeah.
56:41 Enums are really a pain in the butt.
56:44 Yeah.
56:44 I know.
56:45 The data types.
56:45 I know.
56:46 All right.
56:47 The Python side's good, but the database side is.
56:49 Yeah.
56:50 Yeah.
56:50 It's always some sort of hack.
56:51 Yeah.
56:52 Alembic.
56:53 I mean, that's pretty well known to people, but that's obviously important because you've
56:57 got to keep your database and your models pretty closely in sync, right?
57:01 Yeah.
57:01 So we maintain Alembic.
57:03 I wrote Alembic years ago as SQLAlchemy Migrate was not really holding up to what we were
57:09 doing.
57:09 SQLAlchemy Migrate is part of OpenStack now.
57:12 And I actually have maintained that a little bit as well.
57:14 But Alembic was meant to be more of a bare bones, a straightforward, not too fancy tool.
57:20 It has become fancier.
57:22 And people that use it and get what it's about like it a lot.
57:26 It's never going to be as cool as South for Django.
57:29 Maybe an Alembic 3.
57:32 But that could happen.
57:35 It's not as automated as everybody would like.
57:38 It has a system that it will look at your models and look at the database and what we
57:43 call auto-generate your migrations.
57:44 But we don't guarantee those migrations are completely perfect.
57:48 You've got to go and look at them and fix them, which I still think it just did 95% of
57:53 the typing for you, of the work for you.
57:55 That's what it was meant to do.
57:56 Yeah, I think also it's helpful because it works in that realm of that's the area of
58:01 SQL I know less well, the DDL and that drop.
58:04 You know, how do I drop a table or a column and then re-add it under a different name without
58:09 losing data?
58:09 Like all that kind of stuff can be tricky.
58:10 Yeah, and a DDL is where a lot of the database vendor specific stuff is exposed.
58:15 Yeah.
58:15 Like all these crazy keywords and data types.
58:18 And it's less declarative and more imperative.
58:21 And so for Alembic, we just provide a model to create your migrations and it's been working
58:26 pretty well.
58:26 It's got a lot of features now, but it's again, a tool where if you don't know what DDL is,
58:31 you're going to have a bad time with Alembics.
58:34 Yeah, sure.
58:35 You should learn what database migrations look like in the alter table, alter column, and
58:39 know what that means.
58:41 And then Alembic will be pretty smooth.
58:42 And there actually are extensions for Alembic.
58:44 I saw it wasn't on that list.
58:45 There's an extension called Alembic Utils.
58:47 Oh, nice.
58:47 Which are extensions for Alembic for Postgres that also build upon some recipes that are
58:52 in these docs here.
58:52 And I recommend looking at that too.
58:55 All right.
58:55 There's a couple we can go quick on.
58:57 There's one for talking to Amazon Redshift as a provider.
59:00 That's pretty cool.
59:01 There's Form Alchemy, which...
59:04 Is this still maintained?
59:05 This is an old one.
59:06 Form Alchemy is 12 years old.
59:08 All right.
59:09 This is what it is.
59:09 It's old.
59:10 Maybe it still works, but let's leave that one alone.
59:12 It probably still works.
59:13 Yeah, probably.
59:13 It looks like it's had...
59:14 HTML hasn't changed since then.
59:16 Just style some CSS on it.
59:17 All right.
59:18 GeoAlchemy is pretty popular for people doing geospatial work.
59:22 Yep.
59:22 So there's GeoAlchemy.
59:23 There's GeoAlchemy 2.
59:24 I'm not sure of the relationship.
59:26 Which one is which?
59:27 Who works on which one?
59:28 GeoAlchemy seems like it might have...
59:31 It might not...
59:32 I'm not sure how much it's maintained.
59:33 I think it's maintained.
59:33 I would like it to be much more well-maintained.
59:36 I think it supports...
59:37 It's pretty Postgres-centric, but there are geo things for SQL Server and Oracle and MySQL.
59:43 I would like to see that stuff supported as well.
59:45 GeoAlchemy, I don't hear much about.
59:47 But I think it's a good project.
59:49 One for some growth, perhaps.
59:51 SQL tab.
59:52 SQL profiling and introspection for applications using SQLAlchemy.
59:57 Wow.
59:58 Have you seen this?
59:58 Cool.
59:58 I have not seen this either.
01:00:00 What is it doing?
01:00:01 So when you do a request, I think what it's doing, it stores what the page did.
01:00:06 So it says here there's 12 queries.
01:00:08 It spent like 20 milliseconds.
01:00:11 And then you click on each one and it'll show you the select statements and like the actual SQL.
01:00:16 So it's probably profiling from the client side.
01:00:17 Yeah.
01:00:18 Yeah, yeah, yeah.
01:00:19 I think so.
01:00:19 As far as the database.
01:00:20 Yeah, yeah.
01:00:20 That's nice.
01:00:21 If you're just timing it, yeah.
01:00:22 That's cool.
01:00:23 I wonder if it does things like explain.
01:00:25 I don't totally know, but it looks like it has a whiskey integration, which is cool.
01:00:29 This is another one related sort of that helps.
01:00:32 It's called N plus one.
01:00:34 Oh, yeah.
01:00:35 N plus one is the.
01:00:37 That's cool.
01:00:37 Yeah, it's a problem that many ORMs run into when people don't realize they're doing lazy loading and they don't do a join.
01:00:44 And it can be super indirect.
01:00:46 Like here I got a query of a list and I sent the list off to the HTML template.
01:00:50 And the HTML template did a loop and talked about some property on the thing.
01:00:54 And then there's a bunch of more database queries or something crazy, right?
01:00:58 Yeah.
01:00:58 Interesting that it seems to work for multiple lower ends.
01:01:01 Yeah, SQLAlchemy, PeeWee, and Django.
01:01:03 So I guess it's streaming and maybe just taps into the APIs of all those different tools.
01:01:08 Yeah, probably someone's added a layer for each.
01:01:09 Yeah, I guess you could do it in a kind of a distant way heuristically.
01:01:13 If you want to see the same query to the same table over and over again, maybe that's what it's looking for.
01:01:18 Yeah, perhaps.
01:01:19 Where it could do that without necessarily looking at SQLAlchemy and saying lazy logo called.
01:01:23 If it just looks at the SQL, there's probably ways to do it.
01:01:25 But that's an intricate problem.
01:01:27 But that seems like a really useful tool.
01:01:29 Yeah, it does.
01:01:30 And also I saw in there, we'll just close it out with this.
01:01:32 I saw in there, they mentioned the Pyramid debug toolbar, the Flask debug toolbar, and the Django debug toolbar.
01:01:38 And I can't speak to Django.
01:01:39 I don't think I've even run the Flask one.
01:01:41 But the Pyramid one has a, like, you can open it up and say, what were the SQLAlchemy queries of this page?
01:01:47 And actually see how many queries.
01:01:49 And if you're on a page and it says, look, there's 51 queries.
01:01:52 You're like, I thought I did one.
01:01:53 What just happened?
01:01:53 How did I get 51?
01:01:54 Like, well, you got 50 elements and an N plus one.
01:01:58 Debugtubo, I haven't really worked with it.
01:01:59 But yeah, we have a lot of people dealing with it.
01:02:02 Yeah, yeah.
01:02:02 We have to fix issues with it.
01:02:04 I don't actually write any web applications anymore.
01:02:06 I just do this.
01:02:07 So I don't get to do that.
01:02:08 I don't get to see that stuff.
01:02:09 Oh, really cool.
01:02:10 I also don't use them very much anymore either.
01:02:12 I find that I don't need that support as much as I did in the early days.
01:02:15 But I do remember them being quite valuable early on.
01:02:17 All right, Mike.
01:02:19 Well, there's more stuff we could go into.
01:02:20 But what a cool conversation.
01:02:23 And thank you so much for releasing the 2.0 stuff, for adding the async support.
01:02:27 It really opens up a lot more use cases.
01:02:29 I think that are going to be interesting for people.
01:02:31 So, yeah, it's fantastic.
01:02:33 Yeah, my pleasure.
01:02:33 The async worked out really well.
01:02:35 I'm really happy about that.
01:02:36 Now, before you get out of here, let me ask you the final two questions.
01:02:38 You kind of alluded to this already.
01:02:40 If you're going to write some code, what Python editor do you use?
01:02:43 I'm on VS Code right now.
01:02:45 I was on Sublime for a long time.
01:02:47 Years ago, I used TextMate.
01:02:49 I do use VI and Vim a lot.
01:02:52 But if I have lots of windows open, right now it's VS Code.
01:02:55 Fantastic.
01:02:56 And then notable IPI package.
01:02:59 Anything come to mind?
01:03:00 I mean, we kind of threw out a whole bunch.
01:03:01 Probably not.
01:03:02 Did I put anything?
01:03:03 I'm going to click to that.
01:03:04 I didn't put anything down.
01:03:04 How about your favorite out of the list that I threw up there?
01:03:08 Tell me, like, out of the awesome ones, which one stood out the most to you?
01:03:12 Oh, that N plus one thing looks really interesting.
01:03:13 All right.
01:03:13 Awesome.
01:03:14 So N plus one with the plus spelled out.
01:03:16 And the one also spelled out.
01:03:17 Yeah.
01:03:18 That's cool.
01:03:18 Yeah.
01:03:19 Yeah.
01:03:19 Very good.
01:03:20 All right.
01:03:20 Well, final call to action.
01:03:21 People have a bunch of SQLAlchemy code that they've written, but it's probably for the
01:03:25 older style.
01:03:26 It's probably not async and so on.
01:03:27 What do you tell them?
01:03:28 Yeah.
01:03:29 We have a brand new tutorial on the current website.
01:03:32 If you go to just docs.seqlalchemy.org.
01:03:34 On the left side, it'll have this 1.4 slash 2.0 tutorial that kind of represents SQLAlchemy
01:03:40 all over again using all the newest concepts.
01:03:44 I would look at that and just get to know it and also point out problems.
01:03:48 Yeah.
01:03:49 This is a new tutorial.
01:03:50 So this supersedes the old tutorials.
01:03:52 And it's going to talk about core and ORM at the same time.
01:03:55 This is a complete brand new rewrite from the ground up.
01:03:58 It took many weeks to do it.
01:03:59 And then there's also the migration guide.
01:04:01 But if you go through this tutorial, you'll really see what the new way of working is supposed
01:04:05 to look like and what the idea is what's supposed to be.
01:04:08 If you look at the, if you read the tutorial and assume you don't have any SQLAlchemy code,
01:04:12 assume you're just learning it from scratch, see what it's like.
01:04:14 See, wow, wow, this is different.
01:04:15 Or you might see, oh, I never knew that was like that.
01:04:18 Because it really tries to represent the library from the first principles, so to speak,
01:04:24 up to ORM stuff.
01:04:26 All right.
01:04:27 Well, I'm excited about all these new features.
01:04:29 Even the embracing of context managers everywhere.
01:04:32 It looks great to me.
01:04:33 So yeah, thanks for being here.
01:04:35 And thanks for sharing this with everyone.
01:04:36 Yeah, my pleasure.
01:04:37 Bye.
01:04:37 This has been another episode of Talk Python To Me.
01:04:41 Thank you to our sponsors.
01:04:43 Be sure to check out what they're offering.
01:04:45 It really helps support the show.
01:04:47 With TopTal, you get quality talent without the whole hiring process.
01:04:51 Start 80% closer to success by working with TopTal.
01:04:55 Just visit talkpython.fm/toptal to get started.
01:04:59 Do you need a great automatic speech-to-text API?
01:05:02 Get human-level accuracy in just a few lines of code.
01:05:05 Visit talkpython.fm/assemblyai.
01:05:07 Want to level up your Python?
01:05:09 We have one of the largest catalogs of Python video courses over at Talk Python.
01:05:13 Our content ranges from true beginners to deeply advanced topics like memory and async.
01:05:19 And best of all, there's not a subscription in sight.
01:05:21 Check it out for yourself at training.talkpython.fm.
01:05:24 Be sure to subscribe to the show.
01:05:26 Open your favorite podcast app and search for Python.
01:05:29 We should be right at the top.
01:05:31 You can also find the iTunes feed at /itunes, the Google Play feed at /play, and the
01:05:36 direct RSS feed at /rss on talkpython.fm.
01:05:39 We're live streaming most of our recordings these days.
01:05:43 If you want to be part of the show and have your comments featured on the air, be sure to
01:05:47 subscribe to our YouTube channel at talkpython.fm/youtube.
01:05:51 This is your host, Michael Kennedy.
01:05:53 Thanks so much for listening.
01:05:54 I really appreciate it.
01:05:55 Now get out there and write some Python code.
01:05:57 Bye.
01:05:58 Bye.
01:05:59 Bye.
01:06:00 Bye.
01:06:01 Bye.
01:06:02 Bye.
01:06:03 Bye.
01:06:04 Bye.
01:06:05 Bye.
01:06:06 Bye.
01:06:07 Bye.
01:06:08 Bye.
01:06:09 Bye.
01:06:10 Bye.
01:06:11 Bye.
01:06:12 Bye.
01:06:13 Bye.
01:06:14 you you Thank you.
01:06:17 Thank you.