Talk Python rewritten in Quart (async Flask)
, 18 min readTL;DR: We migrated talkpython.fm from Pyramid to Quart (async Flask). Why Quart over FastAPI or Django? Flask’s simplicity + Quart’s true async support. The migration took a few days, changed 5,000+ lines of code, and page response times dropped from 42ms to 8ms. I also created chameleon-flask so we didn’t have to rewrite our templates.
The code powering talkpython.fm is highly modern and leverages many new Python concepts. It makes extensive use of Pydantic with its entire data access layer powered the Beanie ODM. It has type hints at all the architectural boundaries (e.g. data access layer public functions). But we haven’t been able to fully take advantage of these benefits because our web framework has become frozen in time.
You see, Talk Python is was written in Pyramid. Pyramid has been a great framework, and I sincerely thank everyone involved in creating and maintaining it. I chose it back in 2015 when Pyramid was leading the way as one of few Python 3-first frameworks. But it hasn’t had a significant release or update since Feb 2021. Nine years on, Pyramid hasn’t adopted the newer concepts pushing Python forward. And as a result, neither could we. For a couple of years, I’ve considered this a latent risk of our tech stack. With all the infrastructure modernization I’ve just completed [see 1, 2, 3], it’s time to address this risk and see what we can do with all that Python 3.13+ has to offer.
Choosing a Python web framework in 2024
We have many good options for web frameworks today. There are the tried and true Django and Flask which continue to prove how loved they are with their staying power. And there are the frameworks that are built in an era of massive changes for Python - improvements if you ask me. The most well-known example of this is FastAPI. FastAPI is built to fully take advantage of current Python features like async/await and type annotations. Pydantic is central to FastAPI meaning their move to Rust brings high performance to FastAPI by default. There are many trade-offs to consider.
Before diving into why I made the choice I did, let’s talk about what I considered.
- FastAPI
- Litestar
- Django
- Hugo Static Site + Python
- Flask
FastAPI
As I’ve entertained the thoughts of updating our framework over the past few years, it’s always been FastAPI as my number one contender. It would go something like “maybe this quarter will be the one I rewrite the sites in FastAPI.” Notice, not rewrite in something. No, rewrite in FastAPI. So I’m a little surprised at myself for not picking it. I even wrote a full course on how to build awesome HTML page-based sites with FastAPI. So I know it’s possible. However, much of what is excellent about FastAPI is around its API story and our web apps are mostly server-side HTML pages.
To make this mismatch concrete, here’s a quick example. FastAPI uses Pydantic to automatically parse and validate data exchanged when views are call. This is a thing of beauty for APIs. For example, if you have a Pydantic model with a user_id field you say it’s an int, then Pydantic will make sure that field is passed and it is or can be converted to an int. If not, it’ll raise a validation exception returned to the API caller.
But if you have a web form (like a login page) you WANT the invalid data. You don’t like it, but you need to accept it, add a message that whatever the value was is malformed, missing, out of bounds, whatever. This means it’s tough to use Pydantic and those parameter features for these types of exchanges. Well, that’s mostly what the website does, so I decided to look around further.
Litestar
I interviewed the team at Litestar last year. There is so much I like about Litestar. They support typing and true async/await like FastAPI. They have a simple view programming model like Flask. They have lots of building blocks like Django. Litestar was a serious contender.
But I decided not to use it for one simple reason. A primary goal of this project was to move on from using a niche framework like Pyramid. I wanted a framework that if I needed to hire someone to help out with the code, there’s a high chance they are already using the same web framework. If I ever wanted to sell the company, the buyer would know the code base or, again, hire someone easily with experience in it. Most importantly, I’ll be continuing to use a framework that is still living and growing vibrantly. Litestar is definitely living and growing well, but in the test of finding lots of people with prior experience, there are other frameworks scoring much higher.
Django
You want popular and lots of users? It’s hard to pick something more well-known than Django. Let me show you some interesting stats. If you jump over to the Python Developer Survey, they ask about web frameworks. You can see that Flask is definitely the most popular, with Django close behind, right?
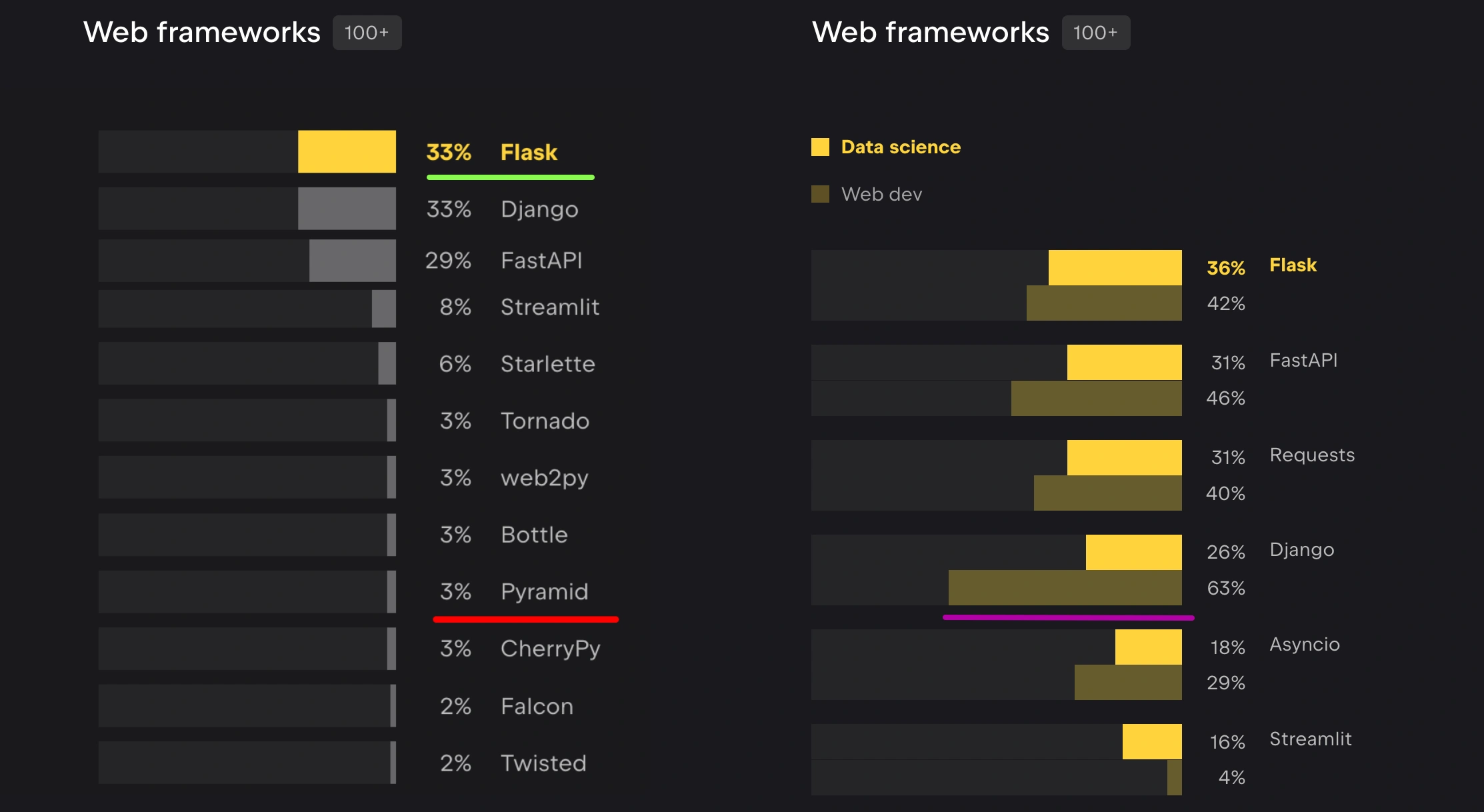
Actually no. Flask is the most popular across all disciplines. But see the purple line. Django is used 1.5x as often as Flask for web developers. Django is really popular amongst people who consider themselves web devs not just Python people who touch a web framework now and then. I also highlighted Pyramid for contrast.
But I didn’t pick Django, did I? Why not?
I have a lot of respect for Django and what it’s done for the Python community. Especially for the community that Django has fostered. It has the Django Girls, Djangonauts, the DSF, and DjangoCon. It’s a beacon of how to run an open source project with a strong community.
All of that said, here are some of the reasons:
- It’s not my stack. I prefer to use MongoDB over Postgres (mostly because it’s operationally much simpler in the long term - no migrations, etc). But I also love Pydantic, strong typing, async/await and more. A lot of this isn’t present or goes against the grain of Django. For example, I know you can use Mongo with it. But you lose most of the model benefits along the way, kind of like the situation with FastAPI laid out above.
- It’s not my style. Django has these great building blocks, like the admin backend. But for me, building a fancy, powerful backend is easy. I don’t want what looks like Excel over my tables. I want something bespoke. I know for many people, they want to avoid this at all costs and Django is a lifesaver. For me, it is not.
- It’s not fully async (neither is flask, we’ll get to that). Until recently Django did not support async/await. This is one of the main features I want to move to in an upgrade. While Django is getting closer, they still don’t have async DB support which is honestly the single most important thing that could be async. However, given that I’m not even using an RDBMS, it doesn’t apply. But if I decided “fine, I’ll use Postgres” I’d still miss out on async.
- It seems oddly complicated to get started. I know people say Django is simple. But it’s way less simple than Flask. In flask, all you do is an
app.get('/')and you’re off to the races. In Django you have settings files, routing files, sub-applications that get installed (like auth), and all of this is disconnected in ways that seem disjointed to me.
Could I figure it out and get used to it? Of course. But I also just love the pure and simple nature of Flask.
Hugo Static Site + Python
An unusual option that is increasingly appealing to me is a pure static site. The more I look at things, I could probably get away with writing 70% of our sites in Hugo, an incredible static site framework. There are important data-driven parts of Talk Python. In the podcast we have a whole ad backend, analytics backend, and even a miniature bit.ly type of thing for our internal use (e.g. talkpython.fm/htmx).
But most of the user facing, user interacting portions could be static. And the other parts could be a Python app. We could use multiple destinations inside nginx such as talkpython.fm/r/htmx so anything starting with /r/ could be a totally separate web app seamless to the users. Similarly for /downloads/… and so on.
But there are also concepts that would take more manual work. For example, guests have their own page, as do the episodes. There is a many-to-many relationship, and updating one when we do the other is tricky (though not impossible) for static sites.
So no to Hugo, but the devops and scaling side of static sites is very appealing.
Choosing Flask, sort of
So in the end, the framework I chose was Flask. For me, Flask checked all the boxes. First of all, it’s very, very well known, being the number one framework in the Python developer survey. I think that Flask is having a resurgence. Many of the other Python developers whom I respect have talked about how Flask was what they were either moving to or supporting more. I also had a great conversation with David Lord. David is the maintainer of Flask. It appeared on the podcast under “State of Flask and Pallets in 2024”. It’s pretty amazing to see what the Pallets team is up to these days.
The other important thing about Flask is that it fits the way I like to write web apps. You create an app, you put a decorator @app.get onto a function and the rest is up to you. It doesn’t prescribe how you write the code inside your web app. You want to call an API? Use requests. Great. Or use HTTPX and get async benefits as well. For your database you can use async MongoDB with Beanie, you could use Postgres, you could use SQLite, or you could just use some in-memory data structure it’ll work the same. In web framework parlance, Flask is a microservice. That’s what I’m looking for.
Finally, Flask truly supports asynchronous web apps. Directly, you can use asynchronous view methods in Flask. However, those don’t really run concurrently in the way you would imagine. On its own, this would be a deal breaker. But the Quart framework, which is almost flask with a different name, truly supports async and await. Moreover, it’s also a supported part of the Pallets organization, just like Flask.
From the Flask documentation about async and await:
Each request still ties up one worker, even for async views. […] the number of requests your application can handle at one time will remain the same.
And just a little lower in the same doc:
When to use Quart instead: Flask’s async support is less performant than async-first frameworks due to the way it is implemented. If you have a mainly async codebase it would make sense to consider Quart. Quart is a reimplementation of Flask based on the ASGI standard instead of WSGI. This allows it to handle many concurrent requests, long running requests, and websockets without requiring multiple worker processes or threads.
How do you know if you mainly have an async code base? Almost every single web app is an async code base. If you call a database, or you call an API, or you are doing some crazy microservice thing, all of these should be asynchronous calls, and you have an async code base. If you’re not doing any of these, it’s a very simple or specific and uncommon web app.
And that’s why talkpython.fm is running on Quart.
Upgrading in two steps
Once I decided that Quart was the right answer and that now was the right time, I created a separate GitHub branch and got to work. I realized there were two major stages to start using Quart properly.
First of all, I had to completely rewrite all the parts of my code that interacted with the web framework directly. For example, when somebody requests a page, the app might want to know if they’re logged in. In order to do that, you check for a cookie. Well, that’s different in Flask and Quart than it is in Pyramid. If you’re working with a URL, you need to get that from the request. Again, a very different paradigm on how to do this in Flask and Quart than in Pyramid.
The second significant change is to take advantage of Quart’s async capabilities. That meant rewriting a ton of code to use async and await and be asynchronous rather than the traditional synchronous kind that I had to write to work with Pyramid.
Here’s a pro tip.
There’s no reason these two things need to or should be done at the same time.
Quart, being something like a superset of Flask, will perfectly support synchronous methods for its views. So, what’s the plan of attack here? I have the views in the website categorized in the code base. For example, there are a bunch of views that have to do with episodes. There’s a bunch of views that have to do with the live streams and notifying people of the past ones, if there’s a current running one, and that sort of thing. So I just picked one of those categories and started rewriting it and got associated view working. And then I moved on to the next.
To make this a little more concrete, here are the actual categories which manifest via the excellent blueprint concept of Flask straight out of the web app.
import quart
# ...
def register_blueprints(app: quart.Quart):
# Needs to appear first.
app.register_blueprint(episodes_blueprint)
app.register_blueprint(home_blueprint)
app.register_blueprint(friends_blueprint)
app.register_blueprint(advertiser_blueprint)
app.register_blueprint(search_blueprint)
app.register_blueprint(stream_blueprint)
app.register_blueprint(sitemap_blueprint)
app.register_blueprint(policies_blueprint)
app.register_blueprint(account_blueprint)
app.register_blueprint(admin_blueprint)
app.register_blueprint(error_blueprint)
app.register_blueprint(hackers_blueprint)
# Redirector needs to be last in line.
app.register_blueprint(redirector_blueprint)
I started by picking simple blueprints that didn’t have terribly complex code. I got all of the views there working and then moved on to increasingly complicated ones, such as the episodes_blueprint. One nice benefit of this was that on the very first one, I had to solve some of these tricky problems. For example, the differences in how you access the request object or how you access cookies. But by the time I got to the next, more complicated one, some of those problems had already been solved, and I could just replicate what I used for the next set of views.
Pyramid to Quart migrated
It took a couple of days of very focused hard work to get the migration done. Here is the PR that made this happen. There were a lot of code changes.
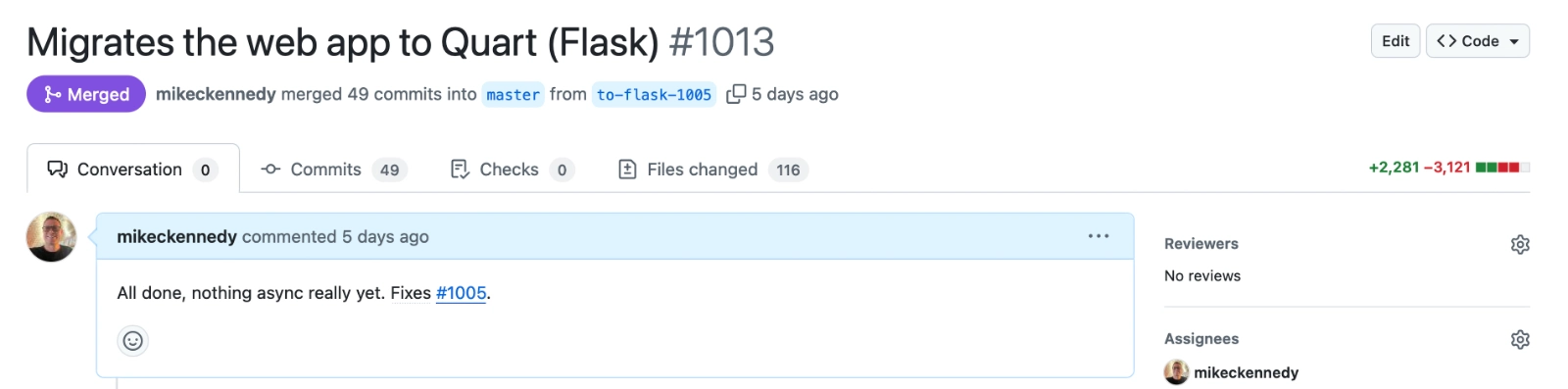
There were 49 commits and over 5,000 lines of code changed. Yikes! But it wasn’t as bad as that sounds. Once I got everything rolling, it was just a matter of sticking with it and following many of the patterns you saw in the beginning applied to other sections.
What about the HTML templates? Honestly, that was my biggest concern, migrating the Chameleon templates to Jinja. That is fraught with pitfalls, and honestly, I don’t want to move to Jinja. I love Chameleon, which is what Pyramid had me using from way back when.
So I created a new open source package that you can use with Flask and Quart that allows you to use Chameleon templates with zero code changes.
To use it, just drop a decorator (@template) on the view method in Flask and it handles the rest:
@app.get('/catalog/item/{item_id}')
@chameleon_flask.template('catalog/item.pt')
async def item(item_id: int):
item = service.get_item_by_id(item_id)
if not item:
return chameleon_flask.not_found()
return item.dict()
With this package you don’t have to touch the HTML at all. In practice, I was using a class-based way to deal with view methods in Pyramid and a method-based one in Quart, so I had to make a couple of minor changes, but that’s not because of the template language.
Once everything was converted to work properly in Quart and I was confident it was working well, I decided it was time to put it into production without async. I wanted to do this right away so that I could catch any errors I might have introduced that had to do with moving from Pyramid to Quart. I didn’t want to mix in what I knew would probably be some issues converting from synchronous to async code.
I did run into a couple of bugs, but they were very minor, and I don’t think they affected anyone. With our sweet Docker deployment setup, it only took literally about one minute to find the bug, fix it, and push it to production. Except for one tricky issue with caching. Caching is always hard, isn’t it?
Sync to Async
The conversion to Quart went really well and I was inspired to keep going and see what benefits we could get from moving from synchronous to asynchronous code. So I created another new branch in GitHub, a new issue, and started coding again in the same style, starting with one blueprint and then another and then another. I got each of them working as a group and then moved to the next.
This one is harder. A lot of the code is written to use view models, little classes that you can create inside of your view methods that do data exchange with the view, HTML template, URLs and routes and all those kinds of things. It’s hard to make that asynchronous because constructors cannot be async methods. But that’s where I had put a lot of the code.
So I had to add a two step process to creating classes. First the constructor (__init(self)__) and then anything that talks to a DB happens in a follow on async def load_async(self) method. Now a typical view method looks like this:
@episodes_blueprint.get('/<int:show_id>')
async def show_by_number(show_id: int):
vm = ShowEpisodeViewMode(show_id, -1)
await vm.load_async()
if vm.episode is None:
quart.abort(404)
return webutils.redirect_to(vm.episode.details_action_url, permanent=True)
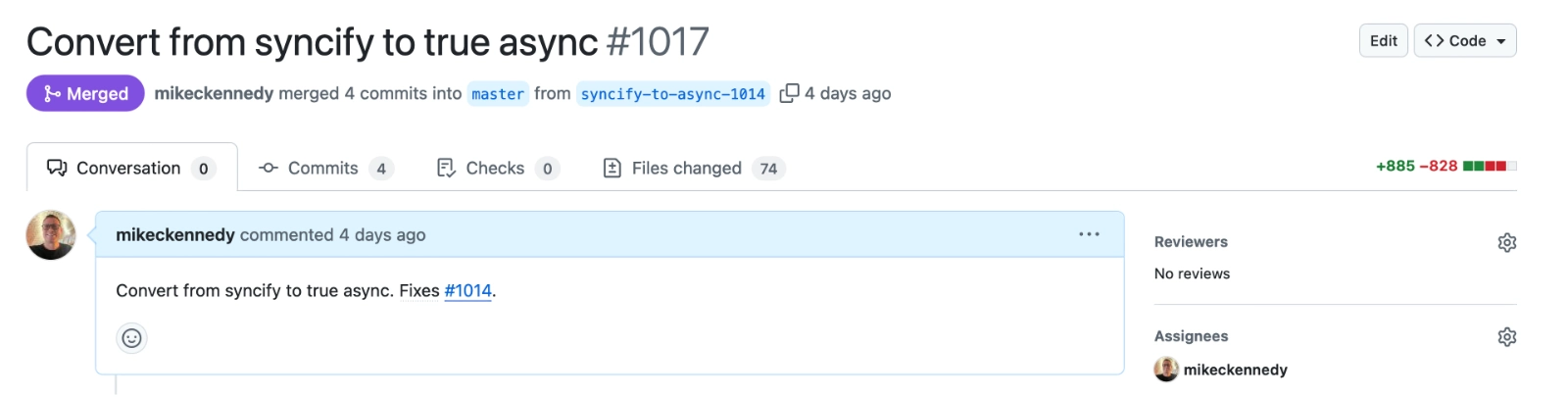
Even though it was tricky, it took one day. And this time only around 1,700 lines of code changed. That’s still a lot, and it’s the tricky async type of code. Another interesting observation is that even though it’s fewer lines of code changed, it’s almost double the number of files changed. Because once you start down the async path, this pattern goes up and down vertically through the whole stack.
Was it worth it?
Looking back now, was it worth doing all of this to move frameworks? 100% yes! It removed some of those nagging worries about being dependent on an older, less active framework. And it opens up the future to use new and innovative Python libraries that might need changes to the framework in order to work. The biggest example of this, of course, is async and await, but there are surely more to come. For example, what are the chances that Pyramid gets rewritten to make sure that free-threaded Python works well with it? Probably not great, but I bet Quart will be.
The new async and await code has been performing super well. Here is a before and after picture straight from our logs.
Before: 42ms HTTP 200 => “GET /episodes/show/472/state-of-flask-and-pallets-in-2024” 29.35 KB at 2024-11-13 19:29:29 from 19.200.1.50 via …
After: 8ms HTTP 200 => “GET /episodes/show/268/analyzing-dozens-of-notebook-environments” 28.10 KB at 2024-11-14 10:33:18 from 80.22.100.101 via …
There’s no real good reason to expect that a single async call should be faster than the previous synchronous one. But something I have not mentioned yet is our data access framework, the Beanie ODM for MongoDB, only supports async. So we had to do some extra work to juggle synchronous to async and back calls in the data layer which added some overhead, but not as much as we see here. So it is definitely a performance boost and a scalability boost.
This need for complex code that allows you to call async code from synchronous code was just one of the things that I was complaining about at the opening of this write-up regarding being stuck on an older framework.
It’s not all unicorns and rainbows, however. Using the awesome locust.io framework to do load testing show it’s not really that different in terms of the total number of requests per second the old and new versions can handle. I think the reason here is probably because our MongoDB response times are so incredibly fast. Almost every one of our queries is sub-millisecond. We’re not waiting a long time on the database. Hence, the async, “do other stuff while you’re waiting” aspect doesn’t really come into play. If you had database queries that took hundreds of milliseconds or seconds, I think you would see a boost here.
Testing for correctness, again
Even this trickier migration did not have many bugs. There were only two bugs that I ran into for this portion. And they both had to do with when you submitted a form and got the response page on the other side of it.
The reason there were so few mistakes that got into production was that I wrote a program that would take the sitemap talkpython.fm/sitemap.xml and then request every single page to make sure that it got a 200 or a redirect or something expected and not a crash or 404. The website was very tested in an end-to-end way before it got rolled out for either of these two conversions. Yeah, we have unit tests. But they are not the same as every HTML template rendered with the data returned from its view method that was generated from the database. That’s just not the kind of things that unit tests test.