State of Data Science in 2021



Episode Deep Dive
Guest Introduction and Background
Stan Seibert has a background in physics and particle physics research where he heavily used Python for data analysis, making him a prime example of a scientist-turned-software-engineer. He manages open-source teams at Anaconda working on projects like Numba, Dask, and recently Pyston (an initiative to speed up Python itself). His history spans using BASIC on an Osborne 1 computer as a kid to being at the forefront of data science tooling at Anaconda.
What to Know If You're New to Python
If you’re brand new to Python and want to follow along more easily:
- Understand basic Python data structures (lists, dictionaries, strings, numbers) as they’re frequently used in data science.
- Get comfortable with installing packages (e.g., via
piporconda) since data science relies on many external libraries (e.g., NumPy, pandas). - Learn about “environments” so you can avoid version conflicts—Conda or virtual environments help isolate different projects’ requirements.
Key Points and Takeaways
- State of Data Science Survey 2021 The discussion centers on Anaconda’s “State of Data Science in 2021” report, which surveyed thousands of data practitioners worldwide. The survey looked at the growing prevalence of data science across many industries, from tech and finance to automotive, and gauged how companies view investment, open-source usage, and the pandemic’s effect on data initiatives.
- Links and Tools:
- Role of Python in Data Science Growth Python and data science seem intertwined, with nearly a third of Python developers using macOS, significant Windows usage, and Linux in production. Python’s allure lies in it being both easy to start with and powerful enough for advanced numeric and AI tasks. Stan emphasized that Python’s ecosystem of libraries (NumPy, pandas, etc.) makes it an industry standard.
- Links and Tools:
- Anaconda Distribution and Conda Packaging Anaconda’s mission is to simplify packaging and distribution for scientific Python. Installing Fortran or C++ dependencies can be complicated—Conda abstracts that complexity. This approach especially benefits Windows users, historically the hardest environment to manage for science libraries.
- Links and Tools:
- ARM and Apple Silicon (M1) for Data Science Apple’s move to the M1 architecture is exciting but has introduced challenges for tooling. Many data science projects rely on lower-level C, C++, or Fortran, requiring significant changes to support M1 natively. Still, Rosetta 2 emulation is surprisingly fast—only around 20% slower for many tasks, buying developers time while the ecosystem catches up.
- Links and Tools:
- Supply Chain Security and Open Source Governance The survey revealed that about half of participants’ organizations use managed repositories or private mirrors for open-source packages. Others run vulnerability scanners or manual checks against public CVE databases. Data science teams now face the same supply chain security concerns as core dev teams.
- Links and Tools:
- Distributed Teams and Centers of Excellence Organizations use different models to embed data science across departments. Some rely on embedded data scientists within marketing, finance, or R&D; others create a data science “Center of Excellence” to define best practices and governance. Each approach balances domain expertise with consistent tooling.
- Links and Tools:
- Impact of COVID-19 on Data Science The pandemic influenced data science spending in diverse ways. Some companies shrank budgets due to uncertainty, while others increased spending as data-driven decisions became crucial. Whether data science was viewed as essential or experimental often dictated this difference.
- Links and Tools:
- WHO COVID-19 Data (for a broader data perspective)
- Links and Tools:
- Challenges Moving Models to Production Many teams struggle with recoding or integrating data science models with production stacks in Java, .NET, or other languages. Alternatively, they might want to transition from R to Python for performance or tooling reasons. This friction was one of the most common production blockers.
- Contributions to Open Source A high percentage of organizations now encourage open source engagement—about 65% according to the Anaconda survey. Having internal policies supporting contributions is a major shift from the past when many were wary of any open sourcing. This signals healthier ecosystems and better collaboration.
- Links and Tools:
- NumFOCUS (supports many Python data science packages)
- Conda Forge GitHub
- Links and Tools:
- Pyston and Python Performance Initiatives In addition to specialized JITs like Numba for numeric loops, broader efforts like Pyston aim to make Python faster overall. Anaconda recently hired the Pyston team to accelerate development. These projects complement CPython’s ongoing work to optimize Python 3.11 and beyond, underscoring the importance of performance in the data world.
- Links and Tools:
Interesting Quotes and Stories
- Stan on data cleaning: “No data set is perfect… You can’t ever clean the data just once, because what you’re doing is preparing it for the questions you’re going to ask.”
- Stan on ARM performance: “Rosetta 2 on average is sort of like a 20% speed hit, which for an entire architecture switch is amazing.”
- On open source: “Encourage your organization to look at the open source libraries they rely on most, and give back to the maintainers or projects that matter most to them.”
Key Definitions and Terms
- Conda / Conda Forge: A package manager and repository ecosystem that simplifies installing Python libraries with compiled dependencies across platforms.
- Rosetta 2: Apple’s translation layer allowing x86-based apps to run on Apple Silicon (M1) devices.
- Center of Excellence (CoE): A centralized group or department setting standards and best practices, in this context for data science.
- CVEs: Common Vulnerabilities and Exposures, referencing publicly disclosed security issues in software.
Learning Resources
Here are some resources to learn more and go deeper.
- Python for Absolute Beginners: A great place to truly start if you’re new to Python.
- Data Science Jumpstart with 10 Projects: Explore real projects to kick off your data science journey.
- Move from Excel to Python with Pandas: Transition your data wrangling from spreadsheets to Pythonic tools.
Overall Takeaway
Data science has matured in both reach and complexity, fueled in large part by Python’s robust ecosystem and user-friendly nature. The “State of Data Science in 2021” shows not just Python’s ongoing dominance, but also the unique roadblocks enterprises face—ranging from security best practices and environment setups to bridging domain expertise and technical implementation. Tools like Conda, plus new performance initiatives like Pyston, ensure that Python remains both accessible and powerful for data-driven discovery in the years to come.
Links from the show
State of data science survey results: know.anaconda.com
A Python Data Scientist’s Guide to the Apple Silicon Transition: anaconda.com
Numpy M1 Issue: github.com
A Python Developer Explores Apple's M1 (Michael's video): youtube.com
Watch this episode on YouTube: youtube.com
Episode #333 deep-dive: talkpython.fm/333
Episode transcripts: talkpython.fm
---== Don't be a stranger ==---
YouTube: youtube.com/@talkpython
Bluesky: @talkpython.fm
Mastodon: @talkpython@fosstodon.org
X.com: @talkpython
Michael on Bluesky: @mkennedy.codes
Michael on Mastodon: @mkennedy@fosstodon.org
Michael on X.com: @mkennedy
Episode Transcript
Collapse transcript
00:00 We know that Python and data science are growing in lockstep together, but exactly what's happening
00:05 in the data science space in 2021? Stan Siebert from Anaconda is here to give us a report on what
00:10 they found with their latest State of Data Science in 2021 survey. This is Talk Python To Me,
00:16 episode 333, recorded August 9th, 2021.
00:19 Welcome to Talk Python To Me, a weekly podcast on Python. This is your host, Michael Kennedy.
00:37 Follow me on Twitter where I'm @mkennedy and keep up with the show and listen to past episodes
00:42 at talkpython.fm and follow the show on Twitter via at talkpython. We've started streaming most of our
00:49 episodes live on YouTube. Subscribe to our YouTube channel over at talkpython.fm/youtube to get
00:54 notified about upcoming shows and be part of that episode. This episode is brought to you by Shortcut,
01:01 formerly known as clubhouse.io, and masterworks.io. And the transcripts are brought to you by Assembly
01:07 AI. Please check out what they're offering during their segments. It really helps support the show.
01:11 Stan, welcome to Talk Python To Me.
01:15 Hey, nice to be here.
01:16 Yeah, it's great to have you here. I'm super excited to talk about data science things,
01:21 Anaconda things, and we'll even squeeze a little one of my favorites, the Apple M1 stuff mixed in
01:27 with data science. So it should be a fun conversation.
01:30 I'm also very excited about the M1.
01:32 Nice. Yeah, we can geek out about that a little bit. That'll be fun. But before we get there,
01:37 let's just start with your story. How'd you get into programming in Python?
01:40 Yeah, programming started as a kid, you know, dating myself here. I learned to program
01:44 basic on the Osborne 1, a suitcase of a computer that we happened to have as a kid. And then
01:51 eventually picked up C and stuff like that. Didn't learn Python until college, mostly because I was
01:57 frustrated with Perl. I just found that Perl just never fit in my brain right. And so I was like,
02:03 well, what other scripting languages are there? And I found Python. And that was a huge game changer.
02:08 I didn't really use it professionally or like super seriously until grad school when I had a summer
02:14 research job. And I realized that this new thing called NumPy could help me get do my analysis.
02:19 And so that was when I really started to pick up Python seriously. And now here I am, basically.
02:25 Yeah, what were you studying in grad school?
02:26 I was doing physics. So I did particle physics and used Python quite extensively, actually,
02:33 throughout my research. And C++, unfortunately, for better or worse. So yeah, but that's how I end.
02:39 I always ended up kind of being the software person on experiments. So when I was leaving academia,
02:45 going into software engineering kind of was a logical step for me.
02:49 I was studying math in grad school and did a lot of programming as well. And I sort of trended more and
02:56 more towards the computer side and decided that that was the path as well. But it's cool. A lot of the
03:01 sort of logical thinking, problem solving you learn in physics or math or whatever, they translate
03:06 pretty well to programming.
03:08 Yeah, yeah. And definitely, you know, working on large experiments, a lot of the sort of soft skills
03:14 of software engineering, things like how do you coordinate with people? How do you design software
03:18 for multiple people to use? That sort of thing. I actually, I inadvertently was learning how to be
03:22 a software manager as a physicist and then only realized it later when I went into industry.
03:29 And how about now? You're over at Anaconda, right?
03:31 Yeah. So, you know, maybe I'm doing the same thing. So now I'm both a developer and a manager
03:37 at Anaconda.
03:38 It's a direct path from like PhD physics, particle physics to programming to data science at Anaconda.
03:45 Is that how it goes?
03:45 Yeah. I mean, we employ a surprising number of scientists who are now software engineers.
03:51 And so I manage the team that does a lot of the open source at Anaconda. So we work on stuff like
03:57 Numba and Dask and various projects like that. Just recently hired the piston developers to broaden our
04:04 scope into more Python JIT optimization kind of stuff. So yeah, so I'm doing a mix of actual development on
04:11 some projects as well as just managing strategy, the usual kind of stuff.
04:16 Well, I suspect most people out there know what Anaconda is, but I have listeners who come from all
04:20 over, you know, what is Anaconda? It's kind of like a Python you download, but it's also,
04:25 it has its own special advantages, right?
04:28 Yeah. I mean, where we came out of and still is our main focus is how to get Python and just
04:35 broader data science tools. One of the interesting things about data science is it's not just Python.
04:40 Most of people are going to have to combine Python and maybe they don't realize it, but with Fortran
04:44 and C++ and all the things that underpin all of these amazing libraries. And so a lot of what we do is
04:49 try to get Python into the hands of data scientists is, you know, get them the latest things and make it
04:54 easy for them to install on whatever platform they're on. Windows, Mac, Linux, that sort of thing.
04:58 So the, you know, Anaconda has a, you know, a free, call it individual edition. It's basically a
05:05 package distribution and installer that lets you get started. And then you can, there are thousands
05:10 of Conda packages, Conda's packaging system. There are thousands of Conda packages that you can install
05:14 where, you know, we, or, you know, the broader community have done a lot of the hard work to
05:19 make sure all of those compiled packages are built to run on your system.
05:24 That's one of the real big challenges of the data science stuff is getting it compiled for your
05:29 system. Because if I use requests, it's, you know, pip install requests. I probably,
05:34 maybe it runs a setup high. Maybe it just comes down as a wheel. I don't know, but it's just pure
05:39 Python and there's not a whole lot of magic. If I'm really getting there far out there, maybe I'm
05:44 using SQLAlchemy and it has some C optimizations. It will try to compile. And if it doesn't, well,
05:49 it'll run some slower Python version probably. But in the data science world, you've got really heavy
05:55 dependencies, right? Like, as you said, stuff that requires a Fortran compiler on your computer.
05:59 I don't know if I have a Fortran compiler on my Mac. I'm pretty sure I don't. Maybe it's in there.
06:05 Probably not. Right. And as maybe C++, probably have a C++ compiler, but maybe not the right one.
06:12 Maybe not the right version. Maybe my path is not set up right. And plus it's slow, right? All of these
06:18 things are a challenge. So Anaconda tries to basically be, let's rebuild that stuff with a tool chain that
06:25 we know will work and then deliver you the final binaries, right? The challenge with that for a lot
06:29 of tooling is it's downloaded and installed to different machines with different architectures,
06:34 right? So you've gone and built stuff for macOS, you built stuff for Linux, you built stuff for
06:40 Windows and whatnot. Is that right?
06:42 Yeah. Yeah. Building software is non-trivial and no matter how much a developer tries to automate it so
06:50 that things just work, it helps to have someone do a little bit of quality control and a little bit of
06:56 just deciding how to set all the switches to make sure that you get a thing that works so that you
07:02 can just get going quickly. Early on, I remember in the sort of 2014, 2015 era, Anaconda was extremely
07:10 popular with Windows users who did not have a lot of good options for how to get this stuff.
07:14 Right.
07:15 Like with Linux, you could kind of get it together and get it going. If you were motivated on Windows,
07:19 it was often just like a very much, I don't know what to do. And so this making it sort of one-stop
07:26 shopping for all of these packages. And then another thing we wanted to do is make sure that there was a
07:29 whole community of package building around it. It wasn't just us. So things like Condo Forge is a
07:35 community of package builders that we are part of and hugely support. Because there's a long tail,
07:42 there's always going to be stuff that is going to be, you know, we're never going to get around to
07:45 packaging.
07:45 Right. There's important stuff that you're like, this is essential. So NumPy, Matplotlib, and so on.
07:52 Like you all take control of making sure that that one gets out. But there's some, you know,
07:57 biology library that people don't know about that you're not in charge of. And that's what the
08:03 Condo Forge plus Condo is, is like, sort of like pip and PyPI, but also in a slightly more structured way.
08:10 Yeah. Yeah. And that was why, you know, Condo was built to help make it so that it is possible for
08:14 this community to grow up, for people to package things that aren't Python at all that you might
08:18 need, all kinds of stuff like that. And yeah, they, you know, there's always going to be, you know,
08:24 in your specific scientific discipline. I mean, so for example, Bioconda is a really interesting
08:28 distribution of packages built by the bioinformatics community built on Condo, but they have all of the
08:34 packages that they care about. And many of which I've never heard of, aren't in common use, but are really important to that scientific discipline.
08:41 Out in the live stream, we have a question from Neil Heather. Hey Neil, I mentioned Linux, Windows,
08:47 macOS. Neil asked, does Anaconda work on Raspberry Pi OS as in ARM64?
08:53 Yeah. So the answer to that is Anaconda, not yet. Condo Forge does have a set of community built
09:01 packages for Raspberry Pi OS. The main challenge there is actually, we just a couple months ago
09:08 announced ARM64 support, but it was aimed at the server ARM machines that are running ARM 8.2
09:14 instruction set, which the Raspberry Pi is 8.0. And so the packages we built, which will work great on
09:21 server ARM, are missing, are using some instructions that Raspberry Pis can't support. But Condo Forge,
09:27 so if you go look up Condo Forge and Raspberry Pi, you'll find some instructions on how to install for
09:33 that.
09:33 ARM is interesting, right? So let's talk a little bit about that because I find that this whole Apple
09:40 Silicon move, you know, they created their M1 processor and they said, you know what, we're dropping
09:47 Intel, dropping x86, more importantly, and we're going to switch to basically iPad processors,
09:54 slightly amped up iPad processors that turn out to be really, really fast, which is actually
09:59 blew my mind and it was unexpected. But I think the success of Apple is actually going to encourage
10:07 others to do this as well. And it's going to add, you know, more platforms that things like
10:14 Anaconda, Condo Forge and stuff are going to have to support, right? So there's a cool article over here
10:21 by you on Anaconda called A Python Data Scientist's Guide to the Apple Silicon Transition.
10:28 Yeah, this was, you know, I've been, I'm a huge chip nerd, just due to background and thinking about
10:33 optimization and performance. And so this came out of, you know, some experiments I was doing
10:40 to just understand, I mean, we got some M1 Mac minis into our data center and started immediately
10:45 playing with them. And I realized I, after some, you know, I should take the stuff I was,
10:49 I was learning and finding and put it together in a document for other people because I couldn't find
10:53 this information anywhere organized in a way that was, you know, for me as a Python developer,
10:59 I was having a hard time putting it all together.
11:02 Right. There was some anecdotal stuff about just like, yeah, this kind of works for me,
11:07 or this is kind of fast or this kind of slow, but this is a little more,
11:10 here's the whole picture and what the history is and where it's going and what it means and
11:14 specifically focused on the Conda side of things. Right.
11:19 Yeah. And even just the Python side, it's, I mean, it's, it's sort of an interesting
11:23 problem of, you know, Python's an interpreted language. So you're like, well, I don't, I don't
11:27 have any machine code to worry about. Right. But the interpreter of course is compiled. So you at
11:32 least need that. And then many, many Python packages also contain compiled bits and you'll need those
11:37 two. And, and this is, this is an interesting broad problem for the whole, the whole Python
11:42 ecosystem to try and tackle because that's not too often a whole new platform kind of just appears,
11:46 you know, making it a whole new architecture takes a while.
11:50 It absolutely does. I think there's a lot of interesting benefits to come. I do want to point
11:56 out for people listening. If you jump over to the PSF JetBrains Python developer survey,
12:02 the most recent one from 2020, and you look around a bit, you'll see that while we don't run
12:09 production stuff on macOS that much, 29% of the developers are using macOS to develop Python code.
12:18 Right. So Apple's pledged that we're going to take a hundred percent of this and move it over
12:24 to Silicon means almost a third of the people running Python in a couple of years will be under
12:31 this environment. Right. And even if you have a windows or Linux machine and you don't care about
12:36 macOS, you may be maintaining a package for people who do. Yeah. And that means Apple Silicon, right?
12:42 Yeah. And there's, I mean, it's, it's interesting. There's a whole, I mean, just other stuff you take
12:46 for granted you know, the availability of, of free continuous integration services that has been
12:54 transformative for the open source community. I mean, it's really improved the software quality that all
12:57 these open source projects can automatically run their tests and build packages every time there's a new
13:02 change. However, it's something like this comes out. And until you get, you know, arm Macs into these services and
13:10 if they're, you know, until they're freely available, a lot of the infrastructure of these open source
13:14 projects, they don't have a way to test on an M1 Mac except manually if they happen to have one and they
13:19 don't have a way to automate their build on an M1 Mac until that, until that sorts out. Yeah. And thinking
13:25 about the workflow here, there there's two challenges that this presents. One is you want to do a git push
13:32 production or git pushed to some branch or tag it. And that's going to trigger a CI build that might fork
13:38 off to run a windows compile, a Linux compile, a Mac compile, generate some platform
13:44 specific wheels with like Fortran compiled in there or whatever. And then you're going to ship that off.
13:49 If that CI system doesn't have an Apple Silicon machine, it can't build for Apple Silicon, right?
13:56 Yep. Yep.
13:57 And there was a time.
14:00 Yeah. Sorry. I mean, yeah. Well, where do you, you know, where do you get M1 in the cloud, right? As a
14:05 normal, I know there's a few hosted places, but as a, like a normal GitHub or an Azure, it's not common to just go grab a bunch
14:13 of those and pile them up. Right.
14:15 Yeah. And it'll take time. I mean, eventually in the same way that, you know, I was thinking back to,
14:19 you know, go back four or five years ago it was, there wasn't a whole lot of options for windows CI
14:25 available. There were a couple of providers and, and then there was sort of a huge change and then
14:31 pretty much everyone offered a windows option and they were faster and all of this stuff. And so I think,
14:36 but that took time. And, and I think that's the thing is, is these, the hardware is in people's hands now,
14:41 and it's just going to get more and more. And, and it's unclear how quickly we can catch up.
14:47 That's going to be a challenge for all of us.
14:49 It's absolutely going to be a challenge. It's, it's interesting. I hope that we, we get there soon.
14:54 The other problem in this same workflow is I was actually just looking at some NumPy issues,
15:02 specifically issue 18,143. I'm sure people have that right off the top of their head.
15:07 The title is please provide universal two wheels for macOS. And there's a huge, long comp conversation
15:15 about, I mean, this is like many, many lines of many, many messages in the thread. And one of the
15:22 problems they brought up is like, look, we can find a way to compile the binary bits, the C++ bits for M1,
15:30 but we can't test it. Like if we can't, we as developers cannot run this, this output, like it's,
15:36 it's a little sketchy to just compile and ship it to the world. And to be fair, this is on January 9th of
15:43 2021, when it was still hard, you know, these things were still shipping and still arriving there.
15:48 It was not like you just go to the Apple store and pick one up.
15:51 This portion of Talk Python To Me is brought to you by Shortcut, formerly known as clubhouse.io.
15:58 Happy with your project management tool? Most tools are either too simple for a growing engineering team
16:03 to manage everything, or way too complex for anyone to want to use them without constant prodding.
16:08 Shortcut is different though, because it's worse. No, wait, no, I mean, it's better.
16:12 Shortcut is project management built specifically for software teams. It's fast, intuitive, flexible,
16:18 powerful, and many other nice, positive adjectives. Key features include team-based workflows.
16:23 Individual teams can use default workflows or customize them to match the way they work.
16:29 Org-wide goals and roadmaps. The work in these workflows is automatically tied into larger company
16:34 goals. It takes one click to move from a roadmap to a team's work to individual updates and back.
16:40 Type version control integration. Whether you use GitHub, GitLab, or Bitbucket,
16:45 Clubhouse ties directly into them, so you can update progress from the command line.
16:49 Keyboard-friendly interface. The rest of Shortcut is just as friendly as their power bar,
16:54 allowing you to do virtually anything without touching your mouse. Throw that thing in the trash.
16:59 Iteration planning. Set weekly priorities and let Shortcut run the schedule for you with accompanying
17:05 burndown charts and other reporting. Give it a try over at talkpython.fm/shortcut.
17:11 Again, that's talkpython.fm/shortcut. Choose shortcut because you shouldn't have to project manage
17:18 your project management.
17:22 Yeah, as an interesting example, CondoForge was able to get Condo packages for Apple Silicon out pretty
17:29 quickly, but they did it with a clever sort of cross-compilation strategy where they were building
17:34 on x86 Macs the ARM packages and pushing them out. But they had enough people manually testing that they
17:44 had confidence in the process that it was okay. But that's very different than how they build other
17:48 packages, which are built and tested immediately, automatically. And if they fail tests, they don't
17:53 get uploaded. So that's, you know, it was, it was, it's a risk, but it helped get the software out in
17:58 people's hands quicker. But yeah, long-term we need to get these machines onto all these CI systems so
18:03 that we can use the same techniques we've built up over the years to ensure we have quality software.
18:08 I think we'll get there, but it's just going to take some time, right?
18:12 Yep. Yep. Yeah.
18:13 Let's see. Neil on Livestream says, speaking of open source, Apple is rumored to be hiring experts
18:19 in a risk. V or Fives have perhaps moved away from having to pay licensing fees to ARM. Yeah. I'm not
18:25 sure about that, but.
18:26 Yeah. I mean, it's a, what's interesting here is, is the, I mean, other, you know, chip architectures
18:32 have been around for a long, long time, but until very recently, you know, average users
18:38 didn't have to think about X86 versus ARM. ARM was for mobile phones and other, you know,
18:43 never had to worry about power PC or anything like that.
18:45 Not for real computers.
18:46 Yeah.
18:46 And so, but now once you, once, you know, going from one to two is a big step. Now the floodgates
18:53 are open and now we're thinking about, well, what else is out there? I mean, you know, risk
18:56 five, I'm not sure how you say, I think risk five is what you call it. Is, is an interesting
19:01 thing. And has even, you know, being a completely open standard, you don't have to even pay licensing
19:07 fees as mentioned. I don't know if Apple's going to make this transition again so quickly. But I,
19:15 I can guarantee you that, you know, everyone probably somewhere in a basement is thinking
19:19 about it, maybe doing some experiments. But yeah, chips move slowly, but it's interesting to think
19:24 about.
19:25 Yeah. That's not a thing you can change very frequently with drag developers along. I mean,
19:29 we're talking about all the challenges, you know, that are just down the pipeline from
19:34 that.
19:34 Yeah.
19:35 Very interesting. All right. Well, let's, let's just talk a few, a little bit about this.
19:38 First, you're excited about these as a data scientist.
19:42 Yeah. It's, it's there. I'm there really for sort of two reasons. I mean, one thing that's
19:46 interesting is just the power efficiency. I always, there was a talk long ago from the chief
19:51 scientist in NVIDIA, which really had an impression on me in which he, you know, paraphrasing roughly,
19:55 basically said that because everything is now power constrained power efficiency equals performance
20:02 in a way that is, you know, normally you just think, well, just put more power in there, but
20:06 that heat has to go somewhere. So you, you, we long since hit that wall. And so now you just have to
20:11 get more efficient to get more performance. Right.
20:13 That's an interesting opportunity.
20:15 You can get more, you can get like larger power supplies and larger computers. I have a
20:19 gaming SIM computer and it is so loud. If you get it going full power, like if the windows are open,
20:24 you can hear it outside the house. It's literally that loud. But at the same time, it's not just on
20:30 your personal computer, you know, in the cloud and places like that, right. You, you pay not just,
20:36 you know, how much performance you get. There's some sort of combination of how much energy does that
20:41 particular processor take to run. And if it's one fifth, you might be able to buy more cloud compute
20:47 per dollar.
20:48 Yeah. Power and cooling is a huge part of a computer, you know, data center expenses.
20:53 And even just, you know, it, you can only, you can put maybe, you know, one to 300 Watts into a CPU.
20:59 You're not, you're not going to put, you know, multiple kilowatts in there or something. And so
21:04 where, where is that? What else, what else can you do? And a lot of that is that, you know,
21:09 Moore's law is driven a lot by just every time you shrink the process, you do get more power
21:13 efficient. And, but now it's interesting to think about architectures that have been sort of thought
21:18 of that, that arm has come in into its own in a extremely power constrained environment. And so now
21:23 we're letting it loose on a laptop, which has way more power compared to a cell phone available.
21:29 What could we do if we fed, you know, right into the socket in the wall?
21:33 Yeah. And you know, what happens when I put it in the data center?
21:36 Yeah.
21:38 So that's, that's, I think arm in the data center is going to be really important.
21:42 Yeah.
21:42 Yeah.
21:43 Yeah.
21:43 I think it's, it's definitely, I'd always expected that to come before the desktop.
21:49 To be honest, I was surprised as many people were by the, you know, suddenness of the Apple
21:55 transition. cause I had assumed this maybe would happen much after we all got used to arm
22:00 in the data center, where you're probably running Linux and it's easy to recompile compared
22:05 to, you know, Mac and stuff like that.
22:06 Yeah. That's what I thought as well. The payoff is so high, right? They spend so much energy
22:12 on both direct electricity, as well as then cooling from the waste heat, from that energy
22:18 that it's the payoff is just completely, completely clear. Right. All right. So let's see, a couple
22:24 of things that you pointed out that make a big difference here is obviously arm versus x86,
22:29 built in on chip GPU, the whole system as a system on a chip thing, rather than a bunch of pieces going
22:35 through motherboard is pretty interesting. But I think the, maybe the most interesting one has to do
22:41 with the acceleration, things like the Apple neural engine that's built in and whatnot.
22:46 It sounds like the data science libraries in general are not targeting the built-in neural
22:52 engines yet, but maybe, maybe they will in the future. I don't know.
22:55 Yeah. It's a, it's something that we're going to have to figure out because, I mean, I think it
22:59 was a bit of chicken the egg that, you know, until this happened, you didn't have this kind of
23:02 hardware just sitting on people's desks. and you weren't going to, you know, run, data science
23:07 stuff on your phone. So now that it's here now, the question is, okay, what can we do with it?
23:12 I mean, right now, for example, you know, for the Apple neural engine, you can take advantage
23:16 of it using something called Coromel tools, which actually did a webinar sometime back on,
23:22 and, and, but that's like for basically you've trained a model and you want to run inference on it
23:27 more efficiently and quickly. but that's, you know, that's it. There's a, there's an alpha,
23:31 release of TensorFlow. That's GPU accelerated. And it would take advantage of the, you know,
23:37 on the M one, if you're, if you're running it there, but that's super early. and, and there's,
23:41 a lot more opportunities like that, but again, that will take time to adapt.
23:45 It will. I suspect as there's bigger gains to be had, they'll probably more likely to be adopted.
23:53 Right. So for example, I have my Mac mini here that I just completely love, but it, it's not that
24:00 powerful say compared to like a GeForce video card or something like that. But if Apple announces
24:06 something like a, a huge Apple pro Mac pro, with many, many, you know, 128 cores instead of 16 or
24:14 whatever, right. Then all of a sudden in the neural engine, all of a sudden that neural engine becomes
24:18 really interesting, right? And maybe it's worth going to the extra effort of writing specific code for it.
24:23 Yeah. Yeah. Well, that's the other thing that's interesting about this is we've only seen one
24:27 of these chips and it is by definition, the slowest one that will ever be made. And so, it's,
24:34 it's, it's, we don't even know how, you know, what is it going to be like to scale up? I mean,
24:37 one of those things that is, you know, you, if you're targeting that big desktop user, how are
24:42 they going to scale this up? This, this all fit on one package. Can they still do that? Will they
24:46 have to split out into multiple packages? there's a lot of engineering challenges that they
24:51 have to solve and we're not sure how they're going to solve them yet out on the outside. So,
24:56 we're going to have to, we have to see. It's going to be exciting to see that come along here.
25:00 All right. So, let's touch on just a couple of things, getting Python packages for M1.
25:05 What are some of the options there? Yeah. So, so the status still is roughly how I have in
25:11 this article, which is basically you can use pip to install stuff if wheels have been built and a
25:16 number of packages like NumPy have started to catch up and have, wheels that will run on the M1.
25:21 another option which works surprisingly well is to just use an x86 Python packaging distribution.
25:27 I think that's actually what I'm doing because it just runs over Rosetta 2.
25:31 Yeah. And that, yeah, it just works. it is shocking. I mean, Rosetta 2 on average,
25:37 I'm finding a sort of like a 20% speed hit, which for an entirely entire architecture switch is amazing.
25:44 I've never seen that before. or you can use a condo forge has the, as I mentioned earlier,
25:50 their, their sort of experimental, macOS arm, package distribution, which doesn't have
25:55 everything, but has a lot of things, and is using them, you know, it is all built for arm.
26:00 It's, there's no translation or anything going on there.
26:02 Right. And on python.org, I believe the Python is that you, if you go and download, I believe it's,
26:09 a universal binary now for sure. So that means it'll, it'll adapt and just run on arm or run on x86.
26:17 You just get one binary. The, the numpy conversation was kind of around that as well,
26:23 I believe. All right. you got, you did some, performance analysis on the performance cores
26:28 versus efficiency cores. That was pretty interesting. And so that was pretty similar to hyper threading.
26:33 If you want to run Linux or windows, you basically got to go with Docker or parallels. And then I guess
26:38 maybe the last thing is like, let's wrap up this subtopic with like pros and cons for data scientists,
26:43 people out there listening. They're like, ah, I can't take hearing about how cool the M1 is anymore.
26:47 Maybe I'm going to have to get one of these. Like, should they like, what do you think as a data
26:51 scientist? Yeah. As a data scientist, my takeaway from all the testing was you should be really excited
26:55 about this, but I would wait unless you are doing what I would describe as a little bit of data science
27:00 on the side and not a huge amount. mainly because, you know, these, the, what they've proven is
27:05 the architecture has great performance and great battery life. The thing we still have to see is how are they
27:10 going to get more Ram in there? How are they going to get more cores in there? and, and then also
27:14 when is the rest of the ecosystem going to catch up on package support? so I, honestly, I, I'm,
27:19 you know, if you're interested in sort of bleeding edge, knowing what's coming, I would totally jump in.
27:23 if you want this for your day to day, I would probably still wait and see what comes out next.
27:27 because I think a data scientist especially is going to want some of the, you know, more cores and
27:32 more Ram, especially than what these machines offer. Right. There's always remote desktop or,
27:36 or SSH or something like that. Right. If you've got an Intel machine sitting around,
27:41 you can just connect over the network locally. Yeah. Yeah. Very cool. All right. Excellent.
27:45 I just want to give a quick mention that Paul Everitt from JetBrains and I did a Python developer
27:50 explores Apple's M1 way, way back in December 11th of 2020, right. When this thing came out.
27:56 so, people can check that. I'll put that in the show notes as well. All right. Let's talk about
28:01 the state of data science, 2021. How'd you all find out about this? How do you know the state?
28:07 Yeah. So, this is something we've been doing for a few years now. I mean, since we have
28:12 a big data scientist audience, you know, a couple of years back, we decided, Hey, let's,
28:17 let's ask them about what challenges they're seeing in their jobs, but, and then publish the results so
28:22 that the whole industry can learn a little bit more about what are data scientists seeing in their day-to-day
28:26 jobs that's, you know, going well, going poorly, where do they want to see improvements? What are
28:31 they, what are they sort of, feeling and thinking? So you got a bunch of people to come
28:36 fill out, the survey and give you some feedback and yeah, yeah, we, we, we, you know, 140 plus
28:44 countries. So we have pretty good, reach across the world. and, and, you know, more than 4,200
28:49 people took the survey. So it's, yeah, we got a lot of responses. It's always amazing to
28:55 see. Yeah. Quick side thought here, I guess. So you've got in that survey, which I'll link to the
29:00 PDF results in the show notes, you've got all the countries highlighted and obviously North America
29:06 is basically completely lit up as like a popular place of results. So as Western Europe, Australia,
29:12 and even Brazil, Africa is pretty, on the light on the side, what else can be done to get
29:19 sort of more Python, more data science going in Africa? Do you think you have any thoughts on that?
29:24 No, I don't. That's a good, that's an excellent question. I don't, that's actually might be a
29:28 good question for a future survey to be honest is, is I can speculate, you know, I don't know if it's,
29:33 you know, access to the computing or if it's bandwidth or, or if it's, you know,
29:39 resources available in the local languages. I mean, there's all sorts of possibilities.
29:43 One thing that is really nice about Python and data science is so much of the stuff is free,
29:47 right? So it's, it's not like, oh, you got to pay, you know, some huge Oracle database license to use
29:54 it or whatever. Right. So I mean, there's a real possibility of that. So yeah, I don't really know
29:59 either, but, let's see, there's the standard stuff about like education level. I guess one of the
30:05 areas maybe we could start on, it's just, you know, people who are doing data science,
30:09 where, where do they live in the organization, right? Are they the CEO? Are they vice president?
30:15 A good portion of them were, 50% is either senior folks or managers. That's kind of interesting,
30:22 right? Yeah, I can see it sort of coming out of, data science as helping in decision-making
30:28 and that sort of thing. And so I can, I can see it gravitating towards, the decision makers in an
30:34 organization. and, and that sort of thing. I mean, one of the interesting things that,
30:38 maybe as in a later, later one of the pages is, how spread out data science is across the
30:45 different departments as well. that there was, you know, obviously it and R and D show up higher
30:51 than the others. but you kind of see a long tail in all the departments. And, you know, my,
30:57 my theory on that is I think we're seeing data science evolving into sort of a profession and a
31:02 professional skill, if that makes sense. So in the same way that like every, you know,
31:06 knowledge workers are always expected to do writing and to know how to write. Yeah.
31:10 but we also hire professional technical writers. I think we're getting into a space where we'll
31:15 have everyone will need to have some numerical literacy and data science skills, even while we
31:21 also employ professional data scientists. Is it the new Excel? Like if I'm, if I'm a manager,
31:26 I, and I don't know how to use Excel, people are going to go, what is wrong with you? Why are you,
31:31 how did you get here? Right. You're going to have to know how to use a spreadsheet. I mean,
31:35 it could be Google sheets or whatever, but something like that to, you know, pull in data,
31:39 sum it up, put it in a graph and so on. And are you feel, are you seeing that more formal data science,
31:46 you know, Jupyter type stuff is kind of edging in on that world.
31:49 Yeah. It's, it's going to, again, I think we'll have to see sort of how the tools settle out.
31:53 one thing I know for sure is that you'll have to at least become familiar with the concept so
31:58 that even if the people doing the data science and reporting to you are using whatever their
32:03 favorite tool set is at least understanding their workflow and how data, you know, goes through that
32:08 life cycle and, you know, data cleaning and modeling and inference and all of those things,
32:13 you'll have to understand that at least enough to interpret what, what is being told and ask the
32:17 right questions about. Right. So if somebody comes to you and says, you asked me this question.
32:22 So I put together a Jupyter notebook that's using PyTorch forecasting. Maybe you can do none of those,
32:26 but you should kind of understand the realm of what that means. Something like that.
32:30 Yes. Yes. You'll have to know at least what steps they had to go through to get to your,
32:34 the answer. So you can ask good questions about, cause if you were a decision maker,
32:38 you need to be able to kind of defend your decision, which means you're going to have to
32:41 at least understand, you know, what went into the inputs into that decision.
32:45 Well, we bought that company cause Jeff over in business analytics said it was a good idea.
32:50 Turned out he, he didn't replace the, not a number section and that really broke it. So
32:55 this portion of talk Python is brought to you by masterworks.io. You have an investment portfolio
33:06 worth more than a hundred thousand dollars. Then this message is for you. There's a $6 trillion
33:10 asset class. That's in almost every billionaire's portfolio. In fact, on average, they allocate more
33:16 than 10% of their overall portfolios to it. It's outperformed the S and P gold and real estate by
33:23 nearly twofold over the last 25 years. And no, it's not cryptocurrency, which many experts don't
33:29 believe is a real asset class. We're talking about contemporary art. Thanks to a startup revolutionizing
33:35 fine art investing, rather than shelling out $20 million to buy an entire Picasso painting yourself,
33:41 you can now invest in a fraction of it. If you realize just how lucrative it can be,
33:45 contemporary art pieces returned 14% on average per year between 1995 and 2020, beating the S and P by
33:53 174%. Masterworks was founded by a serial tech entrepreneur and top 100 art collector. After he
34:00 made millions on art investing personally, he set out to democratize the asset class for everyone,
34:06 including you. Masterworks has been featured in places like the Wall Street Journal, the New York
34:11 Times and Bloomberg. With more than 200,000 members, demand is exploding. But lucky for you,
34:17 Masterworks has hooked me up with 23 passes to skip their extensive waitlist. Just head over to our
34:23 link and secure your spot. Visit talkpython.fm/masterworks or just click the link in your podcast
34:29 player's show notes. And be sure to check out their important disclosures at masterworks.io slash disclaimer.
34:37 I guess one of the requisite topics we should talk about is probably COVID-19 because that was going
34:42 to be over in a few weeks or months, but then it wasn't. So it's still ongoing. And one of the things
34:46 that you all asked about and studied was basically did COVID-19 and more specifically sort of the shutdown
34:53 as a result of it result in more data science, less data science, increased investment, not so much.
35:00 What did you all find there?
35:02 Yeah. So interestingly, I think we found that there was a sort of all different organizations
35:08 had every possible answer. So, you know, the, the, the, about a third decreased investment,
35:15 but a quarter increased investment and another quarter stayed the same. And so that's, you know,
35:21 there wasn't one definitive answer that everyone had for that, which is, I think probably has a lot
35:26 to do with where data science is at in their organization. I mean, on one hand, data
35:30 science is an activity that, is easy to do remotely. you can, you know, there are a lot
35:36 of jobs that you can't do remotely. Data science is one you could do remotely. So that, that part isn't
35:41 an obstacle so much. but is a lot of it also is, has to do with risk. I mean, everyone, when they,
35:46 when they face this was thinking in with their business hats on, what is the risk to my
35:51 organization of an unknown economic impact of this pandemic? And so a lot of places might have
35:57 viewed their data science as being, a risky still early kind of thing. And so let's pull back
36:03 a little bit. Let's not spend that money. Is it optional? Okay. We cancel it for a while. We put
36:07 it on hold. Yeah. Yeah. But, but clearly interesting for, for some organizations, it was so important.
36:11 They put more money in. and so it, it, a lot of it had to do with just where you're at in the
36:15 journey. I think industries, you found out where people were doing data science,
36:21 obviously technology, right? Tech companies. I'm guessing this is like Airbnb, Netflix,
36:26 those kinds of places. There's a lot of data science happening in those worlds. Academic was number two.
36:31 Yeah. I mean, data science is a, is still a actively researched thing. I mean, as we, as you see,
36:38 sometimes it's hard to keep up with all of the new advancements and changes and everything,
36:42 not just in the software, but in techniques. And so academia is super busy on this. you know,
36:47 banking is also a top one because, I kind of think of banking and finance as being some of the,
36:52 you know, the original, you know, corporate data scientists in some ways. and so obviously
36:58 there, it was interesting to see automotive actually score so highly. It's that's, that's the
37:03 one that surprised me as well. Automotive is 6% and the highest industry was 10%. So yeah,
37:08 that's really quite high. Yeah. I wonder how much of that is self-driving cars.
37:12 You know, I don't know that. I mean, the other one is, you know, as we've heard with the chip
37:17 shortages, supply chain logistics is an interesting use of data science to try and predict
37:22 how much supply of all the things you're going to have, where and when, and how should you
37:26 transport stuff. And I imagine car manufacturing is especially, challenging, especially now.
37:32 Interesting. Yeah. They, they really shot themselves in the foot, didn't they? When they said,
37:36 you know what, all these extra chips, people aren't going to need cars. They're not going
37:40 to buy cars during this downturn. So let's cancel our order. We'll just pick it back up in six months.
37:44 And six months later, there are no chips to be had. So, we have it. Yeah. I mean, GM,
37:49 I think it's even shutting down a significant portion of their production in the U S because
37:53 they're just out of chips, which is crazy. Antonio out in the live stream says he's doing
38:00 data science with his team in the energy oil and gas industry. And we're not the only ones.
38:05 Yeah. It's funny that doesn't appear in the list. we, we, we don't have energy, but they're,
38:09 they're, you know, down to 2%. again, all of the percentages are low because there's so many
38:14 industries and everyone was in all, it was all over the place, but yeah.
38:17 Team size is interesting. I think one of the things that it's interesting here is what I think of
38:22 software developers, they kind of cluster together in like development team groups, right? They've got
38:29 the software development department, maybe in a company or a team building a piece of software or
38:35 running a website. To me, data scientists feel like they might be more embedded within little groups.
38:41 There might be a data scientist in the marketing department, a data scientist in the DevOps
38:46 department and so on. is that maybe correct? Yeah. I think we've seen companies actually do both at
38:53 the same time, even where sometimes they'll have, I mean, one of the things we have listed is a data
38:56 science center of excellence. and, and what that ends up being is a, some sense, a group that
39:01 is pathfinding for an organization. They're saying, okay, these are the best practices. These are the
39:05 tools. This is what to do, figuring that out and then rolling it out to all the departments who have
39:10 their embedded data scientists who can take advantage of that. cause I think it's valuable to have a
39:14 data scientist embedded in the department because one of the most important things as a data scientist
39:18 is your understanding of the data you're analyzing and your familiarity with it. that I would,
39:23 I would really prefer the person analyzing, you know, car supply chains, understand what goes into
39:28 that and also no data science as opposed to a data scientist for whom it's all numbers and they don't
39:33 know. Right. If you could trade absolute expertise in Git versus really good understanding of the problem
39:40 domain, you're probably better off going, you know what, just keep zipping it up and just really answer
39:44 these questions. Well, I mean, you don't actually have to make that trade off, but I agree that domain
39:49 knowledge is more important here. Yeah. So it had the highest, so think of the departments where
39:55 data scientists live. It was pretty high than R and D and then this data center, center of excellence
40:01 you spoke about, then ops finance, administration, marketing, human resources. It's really spread out,
40:07 which is sort of what I was getting at before. Yeah. Yeah. So, so I think there are a lot of,
40:12 seeing a lot of organizations build their data science expertise, ground up department by
40:17 department and then maybe we'll coalesce some of it into, you know, a single, single department
40:22 at some point. Right. Maybe that department makes like the APIs for the rest of the sort of isolated
40:26 folks and so on. one that was interesting is how do you spend your time? I mean, you think about
40:31 these AI models or these plotly graphs and all these things that data scientists produce. Then there's the
40:37 quote that data cleaning is not the grunge work. It is the work, right? And you sort of have this chart
40:43 of like, how do you spend your time? And 22% is data preparation, 17% on top of that is data cleaning.
40:49 And so, yeah, that's pretty significant portion of just getting ready to ask questions.
40:54 Yeah. And that's, and that really, that that's the piece that requires that domain expertise to know
40:59 what you're looking at, what's relevant, what problems it'll have. No data set is perfect and,
41:04 and, no data set is perfect for all questions. And so, even if, you know,
41:10 you can't ever clean the data just once, cause what you're doing is preparing it for the questions
41:13 you're going to ask. And so you need someone who can, you know, understand what's going to happen
41:18 there and do that. And that's what, that's really the expertise you want. Yeah. Cool. Another topic
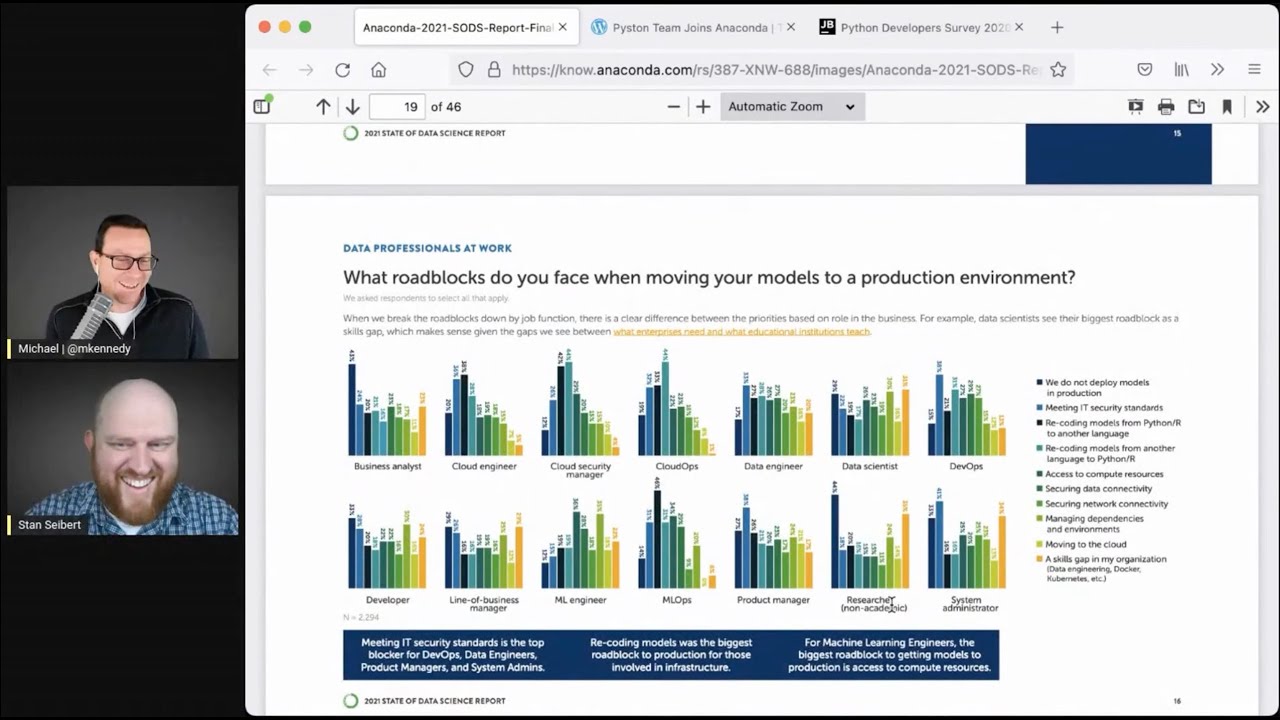
41:22 you asked about was, barriers to going to production. So, some pretty intense graphs,
41:28 many, many options across many categories, but basically you asked, what are the roadblocks do you
41:35 face when moving your models to a production environment? The, you know, intense graphs are really
41:39 that everyone has a slightly different perception of this depending on what seat they're in.
41:43 Are they, are they the analyst? Are they the data scientist? Are they the DevOps person? Everyone
41:48 has a different answer for what the roadblocks are. right. And, and which is makes sense because
41:53 you're going to see what is relevant to your job. when you, when you sum everyone up, you,
41:57 you kind of sort of see this even split across it security. Honestly, what I found interesting was that
42:04 there was both converting your model from Python or R into another language and also converting from
42:09 another language into Python and R. Yeah, exactly. So one of the challenges that people had was just
42:17 like you said, recoding models from Python or R into another language and then the exact reverse.
42:23 And they were almost exactly tied. 24% of the people said, Oh, I got to convert these Python
42:27 models to Java or whatever. The other people are like, he's got this Java model. I got to get into
42:32 Python so I can put it in FastAPI on the web. Right. Something like that.
42:36 Yeah. Anecdotally. I mean, I think the, the, the, you know, maybe we'll have to change the phrasing
42:40 of this question in the future because putting Python and R together might have, conflated a
42:45 couple of things potentially. cause so I just know anecdotal evidence. you know, we have
42:50 talked to customers who their data scientists wrote everything in R, but they didn't want to put R in
42:54 production and we're asking them to recode it into Python because Python was okay for production.
43:00 but I've also had the conversation. People are like, we don't have our data modeling in Python
43:04 and Python's not okay for production. Java is okay for production. and, and so it's, it's this weird
43:10 problem of companies have built up how they do deployments on specific languages. And those aren't
43:15 the languages that people are doing data science in all the time. Right. And I suspect in the Java
43:20 one, it's just like, we have a bunch of Java APIs and apps running and those people that do that stuff,
43:26 they run those apps and you're going to give us a model that's just going to fit into that world.
43:30 But if you are already running Python for your web servers, just put it in production. It's,
43:34 it's already right there, right? Yep. Yep. Yep. Yeah. Yeah. Quite interesting. Okay.
43:40 let's see. I'll flip through here and find a couple more. one was interesting. It was about open
43:45 source, enterprise adoption of open source. yeah, you may want to speak to the results there.
43:50 Yeah. I wish we could have asked this question 10 years ago, cause I think it would have been
43:54 fascinating to compare to now. Yeah. yeah. It's the trend that's super interesting. Yeah.
43:59 The, you know, the, one of the surprising things for me was the outcome that said,
44:03 well, less surprising was 87% of organizations said that they allow the use of open source inside
44:09 the organization. I think that's not too surprising. I mean, even just Linux is kind of like this sort
44:14 of baseline. How is your organization functioning without Linux? Yeah. and then almost what
44:19 programming language could you choose these days? That's not open source, right? You know, the,
44:25 you've got Java, you've got.net, like especially.net was one that wasn't open source is pretty
44:31 popular. Like too late. That's all open source and installed through package managers now. And then
44:35 then the move to Python. And yeah, I mean, I can hardly think of a language or a place to run where
44:41 you can't use some level of open source. Yeah. But the second question, which was,
44:46 does your employer encourage you to contribute to open source? I was surprised to see 65% said,
44:51 yes, that is a, a huge fraction and, is interesting because, that has not always
44:57 been that high. I know that we have spoken again to, you know, people who have said, Hey, you know,
45:02 my, I wish I could contribute, but my employer, we just don't have a policy for this or we don't have
45:07 a way to do that. Yeah. I used to hear that a lot, right. That it's just, it's, it's too complicated.
45:11 I might leak something out. yeah. Or bring in some GPL stuff and mess up our commercial product
45:19 or whatever. Right. Yeah. So I don't know how all these companies have, have solved that internally,
45:24 but I am excited to see, that there's now a huge potential base of open source contributors
45:29 out there that, commercially that there wasn't before. I do think there's something about creating
45:34 a culture for software developers and data scientists where they want to be. And people don't want to be
45:39 in a place where they're forced to use just proprietary tools that are old and crusty, and they're not
45:44 allowed to share their work or talk about their work. And, you know, there's people who would do
45:48 that, but as a, I would love to be in that environment. Like that's not that feeling and,
45:52 you know, talent's hard to come by. So you, you will probably create environments that attract
45:56 the best developers and the best developers don't want to be locked in a basement told they can't share
46:02 or contribute to anything. Yeah. Yeah. I definitely agree with that. Another thing that's hot these days,
46:07 hot in the, as you don't want it, but it's a very hot potato style is, supply chain stuff and open
46:16 source pipeline issues. Right. And the survey actually mentioned that one of the problems that
46:21 people mentioned, one of the reasons that they don't want to use open source is they believed it
46:26 was insecure because our $20 billion bank is now depending on, you know, this project from Sarah
46:33 about padding numbers or whatever, right? Like if somebody takes over a thing, we're going to pip
46:39 install a virus into the core trading engine. That's going to be bad, right? Like that's an extreme
46:43 example, but you did ask about what people are doing to secure their, basically the code they're
46:48 acquiring through open source. Yeah. And this is something, I mean, we're interested in just
46:52 generally because there's a lot more focus on security and you see more reports about supply chain
46:56 attacks on software. And so we're curious how different organizations are tackling the problem.
47:01 obviously the most unsurprisingly, the most, popular answer at 45% was they use a
47:06 managed repository, which interpret to mean, basically it's kind of like you have a private
47:11 mirror of the packages that are approved in your organization and everyone pulls from there,
47:15 not from the internet directly. which is a, a, a smart approach because it gives you a natural
47:21 sort of gating, thing that you can do where there is an, there is a review process to bring new
47:26 software in there. and, and so there's a lot of, you know, things here. I mean,
47:31 obviously even commercially, we sell a repository for condo packages, for precisely this reason,
47:37 because, customers want some governance and are more than happy to, pay us. Yeah.
47:44 Team edition, is our on package, repository. and so this is a, this was an ask for customers,
47:51 which is why we, we built this product, is they were like, Hey, we want your stuff, but we want
47:55 it inside our firewall. We don't want to go directly to your public repo. You want to opt in to say,
48:00 yes, we want the new numpy, not just, Oh, somebody randomly pushed them, pushed something out. And so
48:06 we're going to just grab it and assume that it's good. Right. You can apply policies as well. That's
48:11 common as a lot of places will say no GPL software for various reasons. or they might say, Oh,
48:16 you know, if there are reported, you know, CVEs, these security, reports that, you know,
48:21 go through NIST, they might say, I want no packages with a CVE more severe than some level.
48:27 and those, the, every IT department wants some, some handles to control that kind of policy,
48:34 decision-making. And so, yeah, so that's obviously that, that I think that's why that's the most popular
48:39 option is it's the easiest, thing to get a handle on. It is. Yeah. You can set up a private
48:43 PI PI server. Yep. Pretty straightforward. there's a cool article on testdriven.io,
48:49 but yeah, the Conda and the Conda version that you all offer. That's pretty cool.
48:54 45% as high. I didn't expect that many companies to have a private repository. It's good, but I don't,
49:02 I just expected it to be, I don't know, lower. Yeah. I, although on the other side, you know,
49:07 that means 55% of those were just downloading random stuff from the internet. So, so it's good. I think
49:13 the message is getting out that you have to think about these things from a risk perspective.
49:16 Another was 33% of the organizations do manual checks against a vulnerability database.
49:22 Yeah. So this is, what I was describing earlier. The CVE databases are often a common,
49:28 vulnerability, manual checks. That's a lot of labor. so I, I, it'll be interesting to,
49:34 see how many places move to automating that in some fashion in order to, the hard part there
49:39 is those databases have, again, to data prep and data cleaning often to make use
49:45 of those public databases. You need to do some amount of curation because there's a lot of stuff
49:49 that ends up in there that's mistagged or unclear or whatever. and so a lot of this manual checking
49:55 is probably also just doing that curation. One of the things that's nice. Yeah. One of the things that's
49:59 nice is, GitHub will now do automatic PRs for security problems that it knows about at least.
50:05 Yeah. Those, that kind of automation is going to be really, important, I think in the future,
50:09 just because you can't manually go through all those things.
50:11 What are you seeing around source control? You know, source code algorithms, these are
50:17 really important and people want to keep them super secure, but if they put them on their own private
50:22 source code repositories, they lose a lot of benefits like automatic vulnerability checking and stuff like
50:28 that. What's the GitHub or GitLab versus other stuff, maybe enterprise GitHub. What's the trends there?
50:34 The, the interesting thing there is, is yeah. you know, everyone is using source control at
50:39 some point and they oftentimes they want it managed inside their firewall. And so yeah, things like
50:43 GitHub enterprise and things and GitLab are pretty popular for that. a lot of times I think what
50:48 a places will do is they'll use, some kind of the next item here, the 30% said they're
50:53 using a vulnerability scanner. A lot of those vulnerability scanners you can use on your own internal source
50:58 repositories. And so that way they're, they're not taking advantage of GitHub automatically doing that for them,
51:04 but, they at least have some solution probably for looking for stuff.
51:08 20% said they have no idea what they're doing. And then another 20% said we're not doing anything.
51:14 Well, I'm sure of it. Let's maybe close out this overview of the survey results here by talking about
51:22 Python, Python's popularity. Is it growing? Is it shrinking? Is everyone switching to Julia or have
51:29 they all gone to go? What are they doing? Yeah. So I think, I think Python's
51:34 advantage here is being a, pretty good at a lot of things. And so it ends up being a natural
51:39 meeting point of people who are interested in, you know, web development and data science or system
51:45 administration automation and all of that. So I think, I think Python still has some, some growth to go,
51:49 but I mean, what's interesting is, is, you know, in our survey, the second, I would say the second
51:53 most popular, was SQL, which has been around forever and is going nowhere.
51:58 Those are often used. Yeah, exactly. And they're often used in parallel, right? Like,
52:01 yeah, I'm going to do a SQL query and then run some Python code against the results, that type of thing.
52:07 Yeah. Yeah, definitely. I, I'm a big believer in that there is no one language for everything and
52:11 there never will be. but there is, you know, a lot of different options that people are
52:17 looking to. I mean, go make sense for a lot of sort of network service kind of things. I mean,
52:21 Kubernetes is built almost entirely out of go. but, I'm not sure if I'd want to do any data
52:27 science and go at this point. and so it's going to always be a mix. It might not even be that
52:33 you're doing one or the other. You might be doing both. Like for example, maybe you've written some core
52:38 engine and rust, but then you wrap it in Python to program against it. Right. It could be both.
52:44 I guess it could even be a more combination than that, but, yeah, the popularity of Python looks,
52:49 looks strong. So it looks like it's still right up near the top. I mean, obviously the group that you
52:55 pulled is somewhat self-selecting, right. But that's still a general trend outside of your space.
53:00 Yeah. Yeah. This is definitely going to be skewed to Python because otherwise,
53:03 why are you taking an anaconda survey? But, but still I think, yeah, it is definitely something you see broadly in the industry as well.
53:10 Well, speaking of a different languages and stuff out in the live stream,
53:13 Alexander Semenov says, just learned that I can use rust in JupyterLab with some help from Anaconda.
53:19 My mind is blown. Good job.
53:21 Yeah. That's the one thing I should mention about Python is one of the advantages is if you're using
53:26 Python, you're probably benefiting from most of the languages on the stack, even if you're not writing
53:30 them. And so the ability of Python to connect to anything is I think it's strength and why it
53:35 continues to top these lists. Yeah, absolutely. And then Paul out there has a question about the
53:43 commercial license. And I guess there was some changes to it. Can you maybe speak to that? I
53:47 don't really track the details well enough to say much.
53:49 Yeah. So what, what we did was, our, the Anaconda distribution packages have a,
53:57 terms of service that says, if you are in an organization above a certain size, we want
54:01 you to have a commercial license if you're using it in your business. I forgot the exact threshold,
54:05 where that's at. and, and the reason there was to help one support the development of
54:11 those packages. And I should say, by the way, that terms of service does not apply to Condo Forge.
54:15 Obviously those are community packages. but if you, if you want the assurances that
54:20 Anaconda is providing on those packages and you are a company of a certain size,
54:23 we would like you to have a commercial license, that allows us to support you more directly.
54:28 It allows us to fund, continued work on those packages. And that's, that's sort of, it was,
54:33 it's a sustainability thing, I think. but it, it's, for most people, it's not an issue.
54:39 cause they're either below that size or you're just using it individually.
54:42 Do you know what that size is? What that cutoff is?
54:44 I do not recall off the top of my head. And so I'm afraid to quote a number.
54:47 Yeah. Yeah. Sure. No, no worries. Cool. All right. Well, thanks for giving us that. I mean,
54:52 it seems fair that large companies benefiting from your tools contribute back. I think that statement
54:58 should be applied to open source in general. If, if your company is built on Python, you should give back
55:04 to the Python space. If your company is built on Java, it's Oracle. I don't know if they need help,
55:08 but you know, in general, if you're built on top of something, there's a lot of support you can give
55:13 back. Right. It's, it's kind of insane to me that, you know, banks that are worth many, many billions
55:17 of dollars do very little in terms of like directly supporting the people who they're built upon. Right.
55:24 they hire a pay for a couple of people building the core libraries. Like if you're using Flask,
55:31 right. Support the Flask, pallets organization, something like that.
55:34 Yeah. And then we in turn, you know, take that licensing money and some fraction of it goes to
55:38 num focus for, the broader sort of data science open source community. In addition to,
55:43 you know, us directly funding some open source projects as well.
55:45 All right. Well, we're about out of time, Stan, but let's talk real quickly about Piston because
55:50 Piston is not, rewriting Python and rust. It's not replacing it with Cython or just moving to go.
55:59 It's, it's about making core Python faster, right?
56:01 Yeah, this is something, I mean, we've been thinking about, performance in Python for a
56:06 long time. one of the early projects that, you know, Anaconda created is called number. It's a
56:12 Python compiler. It's focused on numerical use cases and it really is, does its best job, in
56:18 dealing with that kind of numerical loop heavy code. but it's not a, it's not going to optimize your
56:23 entire program, but optimize a specific functions. And so number has is very good at a very specific
56:28 thing. And so we've been thinking for a long time about how we could broaden our impact. And so when
56:33 I saw that, Piston, which I, you know, among many pilots on compiler projects had reemerged in
56:38 2020, with a new version written from scratch, based on Python 3.8, as a just in time
56:45 compiler in the interpreter. So it's designed to optimize any Python program. it can't necessarily do any
56:51 given thing, as fast as number might be for a specific, you know, numerical algorithm, but the
56:56 breadth is, is really what, is interesting to us. and so I saw this project had emerged,
57:01 Piston 2.0 kind of came on the scene. I started looking more closely at it and we started talking
57:05 with them. and we realized that there's a lot that I think the Piston Anaconda could do
57:10 together. And so, we, have hired the Piston team on, to our open source group.
57:15 So they are funded to work on Piston the same way we fund open source developers to work on other
57:20 projects. and so we're really, but the benefit that, there's other, help we can
57:25 give and resources and infrastructure that we can offer this project. And so we're really excited to
57:29 see where this is going to go from here. Yeah. I'm excited as well. All these different things that
57:33 people are doing to make Python faster for everyone, not just, well, let's try to recompile this loop,
57:39 but just you run Python and it just goes better. I think that's pretty exciting. You know, we've got
57:44 the cinder projects from Facebook. Yeah. This is a really good year for Python, optimization projects.
57:51 I should be careful about typing that into a search engine, but, but the cinder project is,
57:58 is not something that's publicly available really. it's not like a supported improvement,
58:03 but it's a, here's what they did at Instagram. There's a bunch of speed ups. Maybe you all can
58:07 bring some of that back into regular Python, but yeah, it's, there's a lot of these types of ideas.
58:12 And yeah, awesome. Looking forward to see what you'll do with this.
58:14 And, you know, the cPython core developers, have even announced that they're going to,
58:20 you know, undertaking a new effort to speed up cPython. and so we will, we're looking to collaborate
58:25 with them. they, they're going to have to, you know, figure out how, what they can do within
58:29 the confines of cPython, because you are the Python interpreter for the world.
58:35 Yeah.
58:35 And so you need, you need to be careful, but there's a lot they're going to do. And we're
58:39 going to try and share ideas as much as we can. because these are both open source projects.
58:43 Right. A lot of the challenges have been in compatibility, right? Like, oh, we could do this,
58:48 but then C extensions don't work. And those are also important for performance in, in big ways and
58:54 other stuff, but yeah, so they do have to be careful, but that's great. All right. Final comment,
58:58 real quick follow-up from Paul. I'd like my company to do more open source, more to do more to support
59:04 open source. Any advice on promoting that? Yeah. I think the best, first place to start
59:10 is identifying what open source does your company absolutely rely on. and especially if you can
59:15 find an open source project that you absolutely rely on, that doesn't seem to be getting a lot
59:19 of support, and then go look at those projects and see what are they, you know, do they have an
59:24 established way to donate funds? do they have, you know, other needs? that's something I
59:30 think that is easier to sell as you say, look, our organization absolutely depends on X, whatever
59:34 this is, as opposed to picking a project at random. it's easier to show a specific business
59:39 speed. Yeah. Yeah, for sure. You can say, look, this is the core thing that we do and it's built
59:43 on this rather than, oh, here's some projects I ran across. We should give some of our money away.
59:47 Yeah. That's a hard, harder sell to, stockholders, I guess. All right. Well,
59:52 Stan, this has been really fun. Let me ask you the final two questions before we get out of here.
59:56 if you're going to write some Python code, what editor do you use?
59:59 So if I'm on, if I'm on a terminal, it's Emacs. if I have an actual GUI desktop,
01:00:05 I'm usually using VS Code these days. And then notable PI PI package or conda package that you're like,
01:00:10 oh, this thing is awesome. People should know about whatever.
01:00:13 Yeah. you know, wearing my, my GPU fan hat. I think a lot more people should know about
01:00:18 CUPI. C U P Y it's a, Python package. That's basically if you took NumPy, but made it run on the
01:00:24 GPU. it's a, the easiest way I can think of to get started in GPU computing, because it just uses
01:00:30 NumPy calls that you're familiar with. so I would highly recommend if you are at all curious about
01:00:35 GPU computing, go check out Coupy. So over there on that computer I have over there, it has a G force,
01:00:40 but on this one, it obviously doesn't have Nvidia on my Mac. does that work? Cuda cores,
01:00:47 the CU part of that is for the Nvidia bits, right? What's my GPU story. If I don't have Nvidia on my
01:00:54 machine, not as clear. yeah, there, the, you know, CUDA has kind of come to dominate the space,
01:01:00 being sort of, first out of the gate, the, there's a lot more Python projects for CUDA.
01:01:06 I'm, there are not, really clear choices, I think for AMD or for like, you know, built in GPUs,
01:01:12 at this point. although I've definitely watched the space, you know, Intel is coming
01:01:17 out with their own GPUs, sort of this year and starting next year. and they have been
01:01:22 collaborating with various open source projects, including the number project, to build Python
01:01:26 tools to run on Intel GPUs, both embedded and discrete. So, yeah. Okay. So this may change
01:01:33 in the future. It'll be interesting to see. Final call to action. People are excited about,
01:01:37 you know, digging more into these results and learning more about the state of the industry.
01:01:41 What do they do? go search for a state of data science, Anaconda, and you'll find the results of the survey. I would, there's a lot of detail in there. So I would
01:01:49 definitely go through and take a look at all of the charts and things. Cause there's a,
01:01:53 there's all kinds of topics covered in there. Yeah. I think it's 46 pages or something. And we
01:01:58 just covered some of the highlights. So absolutely. All right, Stan. Well, thank you for being here.
01:02:02 It's been great to chat with you. Thanks. It's been great. You bet.
01:02:05 This has been another episode of talk Python to me. Our guest on this episode was Stan Siebert,
01:02:11 and it's been brought to you by shortcut masterworks.io and the transcripts were brought to you by
01:02:16 assembly AI. Choose shortcut, formerly clubhouse IO for tracking all of your projects work because you
01:02:23 shouldn't have to project manage your project management. Visit talkpython.fm shortcut. Make
01:02:29 contemporary art your investment portfolio's unfair advantage. With masterworks, you can invest in
01:02:35 fractional works of fine art. Visit talkpython.fm/masterworks. Do you need a great automatic
01:02:41 speech to text API? Get human level accuracy in just a few lines of code. Visit talkpython.fm slash
01:02:47 assembly AI. Want to level up your Python? We have one of the largest catalogs of Python video courses over
01:02:53 at talkpython. Our content ranges from true beginners to deeply advanced topics like memory
01:02:58 and async. And best of all, there's not a subscription in sight. Check it out for yourself at training.talkpython.fm.
01:03:05 Be sure to subscribe to the show, open your favorite podcast app, and search for Python. We should be
01:03:10 right at the top. You can also find the iTunes feed at /itunes, the Google Play feed at /play,
01:03:16 and the direct RSS feed at /rss on talkpython.fm. We're live streaming most of our recordings these
01:03:23 days. If you want to be part of the show and have your comments featured on the air, be sure to subscribe
01:03:28 to our YouTube channel at talkpython.fm/youtube. This is your host, Michael Kennedy. Thanks so much for
01:03:34 listening. I really appreciate it. Now get out there and write some Python code.
01:03:50 I really appreciate it. Now get out there and write some Python code. And I'll see you next time.