
Chapter 6: Running on Rust
I want to discuss some of the relatively low-level aspects of how we're running our Python web apps. Depending on where you are in your deployment / devops journey, this may be old hat for you or something completely new. Either way, you'll learn something in this chapter.
Let's look at an abstract view of our deployment architecture.
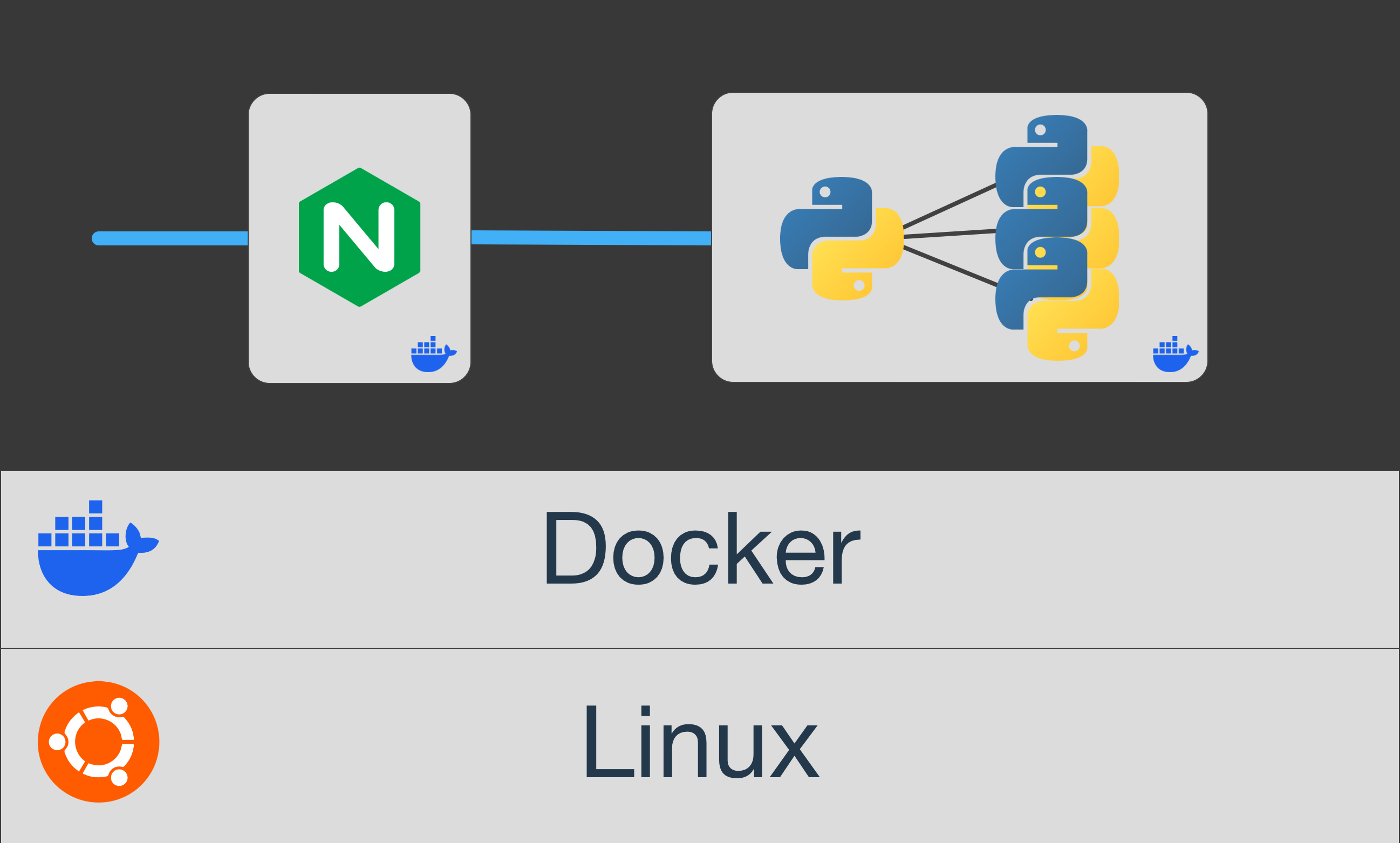
As I've discussed at length, we have our "one big Linux server" running in a VM in the cloud. In the last chapter, we covered how it's just docker-compose managing our assorted app stacks. Those are the two light gray sections forming the foundation. We are not going to cover those here. I will circle back to the Docker side of things later.
For now, it's all about how we run our Python apps. Interestingly, this applies to many variations of running Python in production and is not specific to our philosophy. If you want to run them on bare metal or right on the VMs, that's perfect. If you're doing a big Kubernetes cluster, pod it together. It probably even works for certain PaaS setups you might stand up on one or more of your servers. For us, it's running in a set of Docker containers.
A production Python app server
Let's start with where Python runs. Surprisingly, not all of what we consider our web app will be Python-based. Our Python app, be that Flask, Django, or another framework, will not handle requests to static files even though we have registered static routes. Our Python web server also won't be handling SSL connections. In fact, our Python app server will never even connect to a browser or API client app.
Yet, it is essential to choose a production app server. Perhaps you have seen this warning when running a web app after following the quick start tutorial.
# Flask when executing app.run()
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
That's the warning from Flask when you call app.run(). What's the problem? These dev servers do not auto-start with our server (or container, in our case). They do not handle thread-based or process-based scale out. They don't recover from failure or fix hung requests and processes.
WSGI vs. ASGI
WSGI is shorthand for a Web Service Gateway Interface server. This fantastic convention-based API means that almost any Python web app can run on any server that implements WSGI. You're free to change your mind about which server to use without touching the source code. Combinations include Flask and uWSGI or Django and Gunicorn, among many others.
In 2015, web frameworks began to adopt the then-new async and await capabilities. These lined up perfectly with the IO-bound calls to databases and APIs central to web apps. However, the WSGI API didn't allow multiple requests to an asyncio event loop. It was a blocking call that couldn't be married to an async lifestyle (most notably FastAPI at the time). A new async-capable variant called ASGI came out, serving the same role as WSGI but for async frameworks.
When choosing a production app server, you'll need to know whether you need to support WSGI, ASGI, or both. Your web framework's documentation will have a section on deployment, giving you a hint here. For examples, see Flask's (WSGI), Quart's (ASGI), Django's (either), and FastAPI's (ASGI).
Michael's recommended Python app servers
There are many choices for your production WSGI or production ASGI servers. Some only do one or the other. Some do both, depending on how you configure them. I've used 3 in production for extended periods of time: uWSGI, Gunicorn + Uvicorn, and Granian.
You should NOT use uWSGI today. uWSGI was a great choice for 15 years. But it's no longer supported. I wrote about this on my personal blog in an essay entitled "We Must Replace uWSGI With Something Else" over at mkennedy.codes. Give it a read if you want to know more.
Today, I'm using Granian. But I will give you three recommendations:
- Gunicorn (WSGI only)
- Uvicorn (ASGI only)
- Granian (ASGI and WSGI)
Gunicorn - 9,800 GitHub Stars
Gunicorn - 'Green Unicorn' is a Python WSGI HTTP Server for UNIX. It's a pre-fork worker model. The Gunicorn server is broadly compatible with various web frameworks, simply implemented, light on server resources, and fairly speedy. This web server was excellent for our apps. See the Granian section to see why we are moving on. But if you're running pure WSGI apps and need to keep your memory footprint low, give this one a look.
Uvicorn - 8,600 GitHub Stars
Uvicorn comes from the same folks who created Starlette and APIStar. It's also the default recommendation for FastAPI. Until recently, the way to put Uvicorn into production was to use Gunicorn with Uvicorn workers. However, I no longer recommend this because if you want to run an ASGI server using Uvicorn, you should now use Uvicorn directly. As of August 23, 2024, Uvicorn is now a production ASGI server with worker scale-out and management.
Granian - 2,800 GitHub Stars
Granian is a Rust-based HTTP server for Python applications. It supports ASGI/3, RSGI (for Rust), and WSGI interface applications. It also implements HTTP/1 and HTTP/2 protocols and supports HTTPS and websockets. When you compare the popularity of Granian, it is newer and less used. But it's a clever wrapper around the pure Rust hyper server, used by 300,000 projects on GitHub, has 14,000 GitHub stars, and almost 400 contributors. Its core is very much battle-tested, like the above servers. I interviewed Granian's creator, Giovanni Barillari, over at Talk Python on episode 463 if you want to hear more about this server.
Today, Talk Python and assorted servers run on Granian, as mentioned above. Here's a little peek inside our server. You can see many Granian processes handling requests over there.
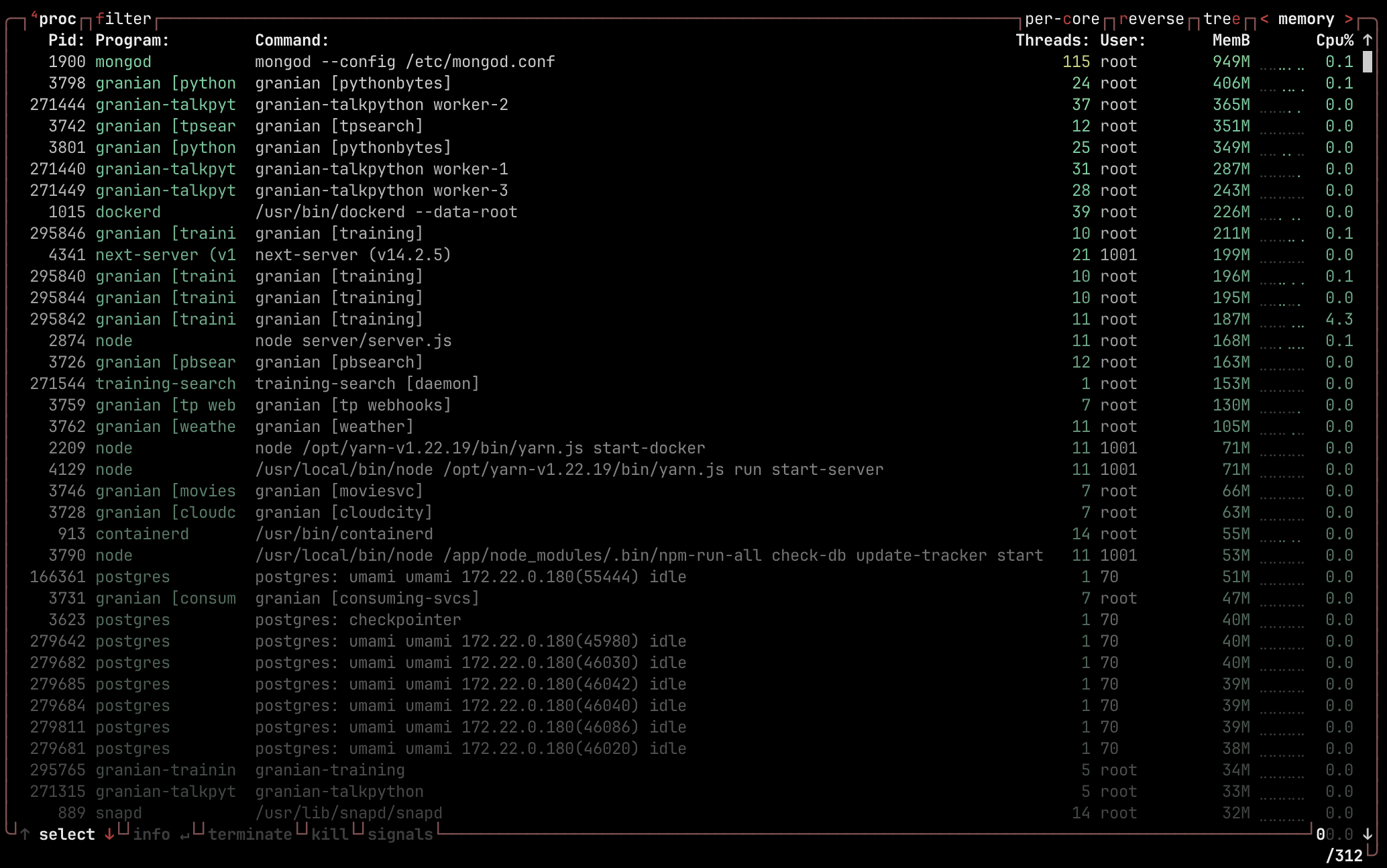
I count 18 Granian processes! We'll talk about why so many processes in a moment. But suffice it to say, Granian is powering all the Talk Python things at the moment.
I chose Granian over my other recommended app servers because of the performance stats. In particular, not the average best times but because of the lower worst times. Here is a performance table from the Granian GitHub repo.
| Server | Total requests | RPS | avg latency | max latency |
|---|---|---|---|---|
| Granian ASGI [GET] (c64) | 412,041 | 41,213 | 1.549ms | 4.255ms |
| Uvicorn H11 [GET] (c64) | 75,123 | 7,513 | 8.5ms | 22.009ms |
| Uvicorn Httptools [GET] (c128) | 339,905 | 34,045 | 3.745ms | 23.819ms |
| Hypercorn [GET] (c128) | 48,884 | 4,893 | 26.054ms | 42.096ms |
While Granain handles the highest requests per second (RPS), the difference between average latency and max latency is close at roughly 2.8x compared to others, such as Uvicorn, with a 6.8x gap. That's what encouraged me to give Granian a try. And because of ASGI/WSGI, switching between these servers is just changing the start-up command. There is effectively zero lock-in.
Scaling Python app servers
Why does the diagram at the top of this chapter have one Python logo that takes a request and then talks to a bunch of other Python logos (aka apps)? That is called a web garden (as opposed to a web farm). Web gardens are especially important because of Python's GIL. These gardens are a common way to take fuller advantage of your hardware and keep things running smoothly even if some request hammers the server. You create a few copies of your production Python app server (in our case, Granian), each running a copy of your web app.
You can also get scale-out via asyncio, as discussed at the opening of this chapter, and via threads. These options are not either-or. You can combinatorially leverage them with multiple threads per worker and each of those threads processing async/await requests. Even when frameworks like Flask fully embrace free-threaded Python, all of these techniques will still have a place.
While you have plenty to go on with this discussion and the various framework's documentation, I thought you might like a glimpse into the actual commands we're running for our servers. Here is the Python production app server's (AKA Granian's) command.
# Command to run talkpython.fm in a production app server.
granian talkpython.talk_python_app:app \
--host 0.0.0.0 --port 8801 \
--interface asgi \
--no-ws
--workers 3 \
--runtime-mode st \
--loop uvloop \
--workers-lifetime 43200 --respawn-interval 30 \
--process-name "granian-talkpython" \
--log --log-level info
This is the command you'd run directly or via a systemd service. Note that you'll need the setproctitle package for the process-name to work.
Of course, we're using Docker and not running this directly. So you'd enter this into the ENTRYPOINT command of the Dockerfile instead:
# Command to run talkpython.fm in
# a Docker container.
ENTRYPOINT [ \
"/venv/bin/granian",\
"talkpython.talk_python_app:app", \
"--host","0.0.0.0", \
"--port","8801", \
"--interface","asgi", \
"--no-ws", \
"--workers","3", \
"--threading-mode", "workers", \
"--loop","uvloop", \
"--log-level","info",\
"--log", \
"--workers-lifetime", "10800", \
"--respawn-interval", "30", \
"--process-name", "granian-talkpython" \
]