
Chapter 4: One Big Server Rather Than Many Small Ones
We moved from simple PaaS hosting a single app on a server shared with an unknown number of other websites to running a bunch of independent small servers. This was motivated by the small commodity hardware promise of the cloud. That turns out to be a hassle without the imagined benefits - at least for Talk Python. So we're back to a single server. This time, it's dedicated to our entire suite of apps, and it's a big one: An eight vCPU and 16 GB RAM machine.
Switching to one big server rather than many small ones has unexpected benefits. At first, it may seem like having 8 servers with 1 CPU and 2GB RAM or 1 server with 8 CPUs and 16 GB RAM are roughly equivalent. They are not.
The price is nearly the same between the two setups. However, managing one server is simpler. Do you need to patch the Linux kernel? It's just one server to patch and reboot. As I mentioned before, in practice, we had to reboot all eight servers in close coordination anyway.
However, the most interesting benefit is a massive boost in performance. We have the same amount of compute in both setups. The load is distributed across the various websites and APIs. So it might seem like the same as before.
The key insight is that each of our apps spikes at different times and for different reasons. Therefore, each app has almost all 8 CPUs to handle its workload. In the cloud story of commodity hardware and many small servers, each app had only 1-2 CPUs max.
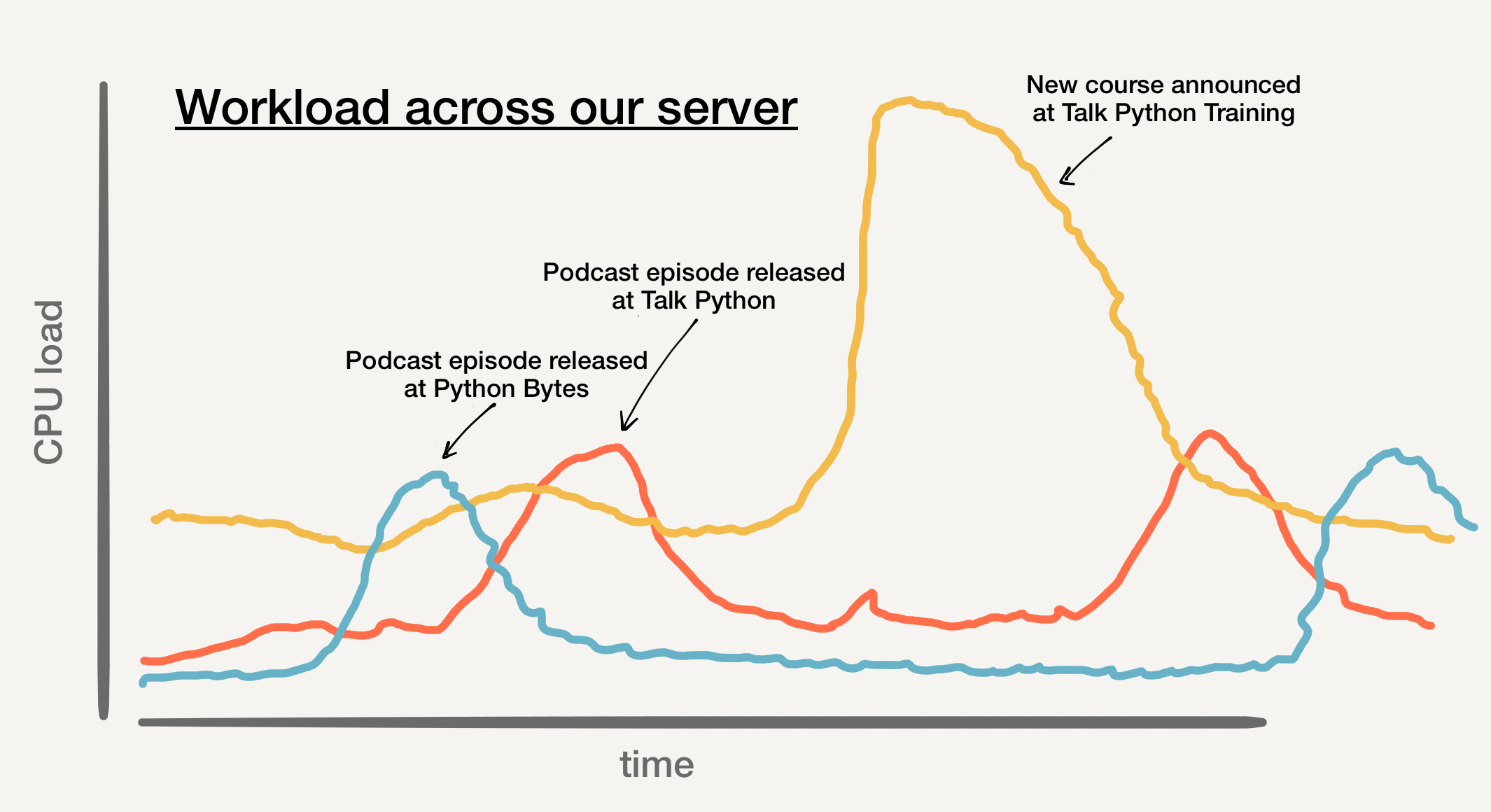
To visualize this shared load and compute available to every app, consider the spike when we announce a new course, the golden peak in the graph above. At its peak, the courses web app has almost 90% of the server capacity available to process the requests and keep everything snappy. This is because the other apps (Talk Python and Python Bytes shown in our graph) are just baseline busy at this moment.
The podcasts spike most when we release an episode. Python Bytes came out on Monday and Talk Python was released on Tuesday. Both of them in relative isolation as well.
If we were back in the "each app gets a dedicated 1-2 CPU server" days, their upper bound is much lower. Specifically, it would be almost 4x-8x lower. It's this peak capacity that you need to plan for.
Because all of these apps are running a server with 8 vCPUs, they can spike to use the whole machine minus the baseline workloads of everything else. In theory, these could all happen at exactly the same time, and we'd be back to our eight small servers situation. But it never does. They have their own drivers of traffic, and there is rarely much correlation across them.
So for the same price, we get a 4x-8x increase in peak performance for every one of our apps. These benefits also apply to our database running in the same Docker cluster.
In later chapters, I'll go into how we partition this server with Docker and how we manage each app in isolation. I'll show you tips to make your Docker builds and deploys extraordinarily fast for Python-based apps.
For this chapter, I'll leave you with this. Docker is merely a permissions abstraction for the most part. Each container sees an isolated file system, an isolated process list, and isolated network. But the apps themselves inside each container run using the same Linux kernel as apps on the host machine. There is effectively no difference, from a performance perspective, between running our apps in a cluster of Docker containers or just running them straight on this one big machine.
If you're choosing between a bunch of small VMs or one big one, I'd recommend you give this one big server concept a try. It's like "Leaving the cloud" but with the advantages of letting your cloud provider (Hetzner for us) handle all the physical data center and hardware requirements and ops. Yet, it's self-contained, and you can move it to any host whenever you want. Maybe day one you're at AWS EC2. Later, you might move to DigitalOcean. Finally, over to Hetzner, where you can get a 5x larger server for the same price. Options seriously open up once you disentangle your architecture from all the cloud-native services and hyperbole.