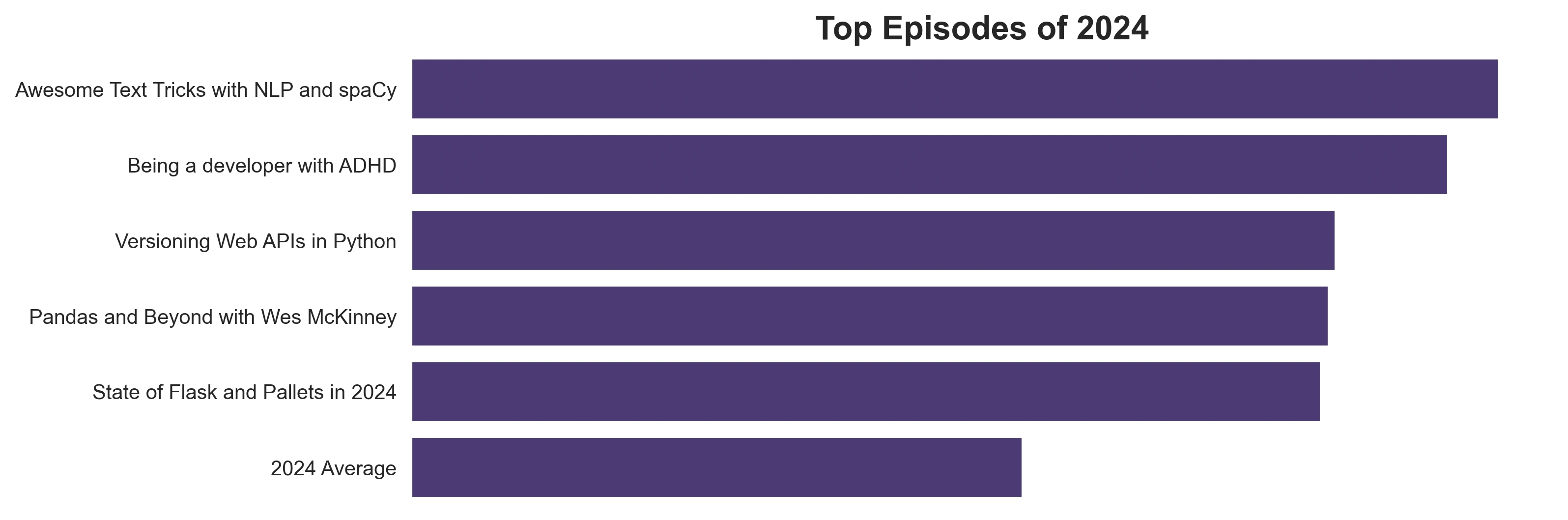
Top Talk Python Episodes of 2024
, 16 min readWe’re rapidly closing in on the end of 2024, and it’s been fun to dive into the podcast data and see if we can highlight some of our most well-received episodes of the year. In this post, I break down the details of our top 5 most popular episodes (by downloads). Here they are!
TL;DR: The top 5 Talk Python episodes of 2024 by downloads:
- Awesome Text Tricks with NLP and spaCy with Vincent D. Warmerdam
- Being a Developer with ADHD with Chris Ferdinandi
- Versioning Web APIs in Python with Stanislav Zmiev
- Pandas and Beyond with Wes McKinney
- State of Flask and Pallets in 2024 with David Lord
No. 1: Awesome Text Tricks with NLP and spaCy
The number one episode of all of 2024 is… Awesome Text Tricks with NLP and spaCy with Vincent D. Warmerdam!
Whether you’re new to NLP or an experienced data scientist, this episode offers practical steps to start parsing text, uncover hidden insights, and make NLP a productive part of your Python projects. Michael sits down with Vincent to explore how Python developers can get started with Natural Language Processing (NLP) using spaCy. They discuss practical text processing techniques, real-world use cases of NLP, and the emerging role of large language models (LLMs). Vincent also highlights his personal projects, including CalmCode (a platform for bite-sized developer courses and keyboard ergonomics) and Sample Space (a podcast spotlighting lesser-known ideas and tools within the data and machine-learning communities).
Key Themes & Topics
- Vincent’s Background and Projects
- Matlab to Python: Vincent shares how a late MATLAB license prompted him to learn Python and R, igniting his passion for open-source tools.
- Scikit-Lego: A community-driven extension of scikit-learn with helpful “Lego bricks” for experimental machine-learning features.
- Sample Space Podcast: Vincent interviews maintainers and contributors of interesting Python/data-science projects, aiming to support scikit-learn and its ecosystem.
- spaCy: Origins, Capabilities, and Use Cases
- Why spaCy? It’s a fast, production-oriented NLP library focusing on linguistic pipelines (tokenization, part-of-speech tagging, named-entity recognition, etc.) implemented largely in Cython.
- Getting Started: We discuss loading models (
en_core_web_sm, etc.) to gain immediate access to pre-trained pipelines. - Named Entity Recognition (NER): spaCy excels at identifying entities like people, locations, or products. Vincent notes that it can even spot programming libraries as “products” if the text is somewhat product-centric.
- Real-World Example: Podcast Transcript Analysis
- Talk Python Transcripts: With over nine years of show transcripts, Vincent demonstrates how to automatically detect which Python tools (e.g., Flask, pandas, FastAPI) are mentioned in each episode.
- Leverage Generators for Large Data: Rather than loading everything at once, spaCy can process text line-by-line or file-by-file with Python generators—ideal for handling large corpora.
- Rule-based + ML Hybrids: Sometimes a base spaCy model can incorrectly classify words like “Go” (verb vs. the programming language). Combining rule-based checks (e.g., “Go” is not a verb here) and spaCy’s statistical models yields better accuracy.
- LLMs vs. Classic NLP
- When to Use LLMs: Large language models such as GPT-4 or Claude can assist with tasks like labeling or initial discovery, but they can be overkill (and expensive) for simpler tasks such as straightforward classification or named-entity recognition.
- spaCy’s Speed & Local Control: spaCy is extremely fast, lightweight compared to an LLM, and can run locally without large GPU or compute requirements.
- “Disagreement” Method: A practical trick is comparing spaCy’s predictions with an LLM’s output. Any major disagreement flags “interesting” samples for manual annotation or deeper review.
- Vincent’s Tips for NLP Beginners
- Pick a Fun Data Set: Curiosity drives learning. Vincent suggests exploring domain data you care about, like a favorite forum or a set of transcripts (e.g., Talk Python’s archive).
- Focus on Generators: For big text corpora, process the data in streams or batches rather than in memory-heavy data frames.
- Avoid “LLM Maximalism”: Large language models are impressive but not always the correct tool. Combining smaller, specialized tools (like spaCy) with LLMs can be more efficient and cost-effective.
Learn more NLP with Vincent’s course

If you’re looking to dive into NLP, then you might also want to check out Vincent’s course over at Talk Python Training: Getting Started with NLP and spaCy. In just a couple hours and some focused practice, you’ll be putting many of these ideas to use on your own data set.
No. 2: Being a developer with ADHD
The second most popular episode of 2024 is Being a developer with ADHD with Chris Ferdinandi. This one was a big surprise to me. I was looking forward to talking to Chris about the topic. But I was also a little nervous that it wouldn’t resonate with the audience, being a bit too far afield of our core Python technical things we typically discuss. Boy, was I wrong!
In this episode, I talk to Chris about a topic beyond just code: living and thriving as a developer with ADHD. Chris has firsthand experience dealing with ADHD’s unique challenges, from difficulty with time management to hyperfocus “coding benders,” and has shared his journey and strategies for turning ADHD into a kind of “superpower.” Along the way, they also discuss workplace accommodations, working styles that suit ADHD brains, and tips for anyone who wants to better support developers living with ADHD.
Key Themes & Takeaways
- Understanding ADHD
- ADHD is an executive functioning disorder marked by difficulty regulating attention.
- People with ADHD don’t lack attention; instead, they often experience either hyperfocus (zeroing in intensely on an activity) or inattention (inability to focus at all).
- There is a spectrum of symptoms—time blindness, impulsivity, emotional dysregulation, etc.—and it manifests differently in different individuals.
- Challenges in Developer Life
- Time Blindness & Task Switching: Meetings or interruptions can derail productivity for hours. Having back-to-back meetings or “pop-ins” is especially tough for ADHD brains.
- Estimation & Deadlines: Traditional sprint planning and daily check-ins (standups) can feel discouraging when productivity fluctuates dramatically day to day.
- Open Office Distractions: Chatty coworkers or frequent Slack pings can break deep work sessions, which are crucial for ADHD “flow.”
- Embracing the Advantages
- Hyperfocus: People with ADHD can tap into intense creativity and productivity when they find the problem exciting.
- Short Feedback Loops: Programming is often rewarding for ADHD brains because writing code and immediately seeing results can deliver fast “dopamine hits.”
- Practical Strategies & Tools
- Build a “Second Brain”: Tools like Notion, Obsidian, or simple to-do apps help offload ideas and reminders from short-term memory.
- Smartwatch Reminders: Setting timers or reminders on something like an Apple Watch can be a game-changer to avoid missed meetings and tasks.
- Simplify Productivity Systems: Overly complex workflows can become a new distraction. Stick to simple bullet lists, minimal plugins, and focused daily tasks.
- Work With, Not Against, ADHD: If you hit an “inertia” period, take a break and reset (exercise, get some sun exposure, etc.) rather than trying to force productivity.
- Work Environment & Accommodations
- Remote vs. In-Office: Many ADHD folks benefit from the flexibility of remote work, but a quiet, dedicated space is key. Others may find an office helps with accountability—everyone differs.
- Meeting Culture: If daily standups or frequent interruptions kill flow, discuss or request more asynchronous communication and meeting-free blocks or days.
- Legal Protections (US-specific): ADHD is covered under the Americans with Disabilities Act, allowing employees to request “reasonable accommodations.” Possible accommodations might include private offices, flexible scheduling, or fewer interruptions.
- ADHD Disclosure at Work
- Timing: You’re not required to disclose ADHD. If you do, it can be after you’ve observed you need certain accommodations or if you sense the team is supportive and inclusive.
- Benefits: Sometimes openness about ADHD can foster understanding and even highlight how your “super-focused” bursts benefit the team.
Resources & Where to Learn More
- Chris’s ADHD Site: ADHDforthewin.com (includes articles, tips, and a free daily newsletter with ADHD-focused guidance)
- Chris’s Dev Site: GoMakeThings.com (front-end dev tips, daily JavaScript newsletter)
- Compilation of ADHD Resources: ADHDforthewin.com/talkpython (Chris set up a custom page for Talk Python listeners containing self-assessments, recommended tools, and more)
Whether you or a teammate has ADHD—or you just want to improve your productivity—Chris’s insights show it’s about leveraging the highs of hyperfocus while having strategies to handle days when focus is elusive. By designing your schedule, office setup, and tasks to better align with ADHD brains, you can be happier, more productive, and more successful as a developer. Give the episode a listen.
No 3. Versioning Web APIs in Python
Versioning libraries can be hard. But often times versioning APIs is even harder. The client can’t choose to avoid upgrading when you roll out that new version of the website. Or can they?
Michael speaks with Stanislav Zmiev about API versioning—what it is, why it’s essential, and various strategies for doing it effectively in Python. Stanislav shares experiences from working at Monite (an “API-first” company) and dives into his open-source project Cadwyn, which applies a Stripe-like versioning philosophy to Python/FastAPI. API Versioning is not just about adding /v1/ or a header—it involves designing how you’ll handle breaking changes over time without burdening your users.
Key Themes & Takeaways
- Why API Versioning Matters
- As soon as you have real users integrating an API, you’ll need a way to evolve that API without breaking existing client code.
- “Versioning by Suffering”: Simply duplicating entire apps or directories for each version can become overwhelming as you accumulate versions.
- APIs need a balance between flexibility and stability—Stripe exemplifies one advanced approach.
- Conway’s Law & Designing for Versioning
- Conway’s Law: Your system design mirrors your organization’s structure.
- Reverse Conway Maneuver: If you want a clean, coherent API, first define the interface you want, then structure your teams and internal processes to align with it.
- Common Versioning Approaches
- Multiple Full Deployments: Copy the entire app/DB per version (very expensive).
- Duplicating Endpoints: E.g.
/v1/getOrdersvs./v2/getOrders—simple but not scalable if you have to maintain many versions. - Schema-Only Migrations: Keep one codebase/business logic, but transform requests/responses between old ↔ new schemas.
- Stripe’s Method: Each new version defines “gates” that convert data to the previous version (and vice versa) incrementally. Clients pinned to a specific version can remain there, while new versions continue to evolve.
- Introducing Cadwyn
- Cadwyn = “Cad” (Change-and-Apply DSL) + “Win” (winning at versioning?).
- Inspired by Stripe’s approach but adapted for FastAPI (and Pydantic) in Python.
- Core Ideas
- One “latest” version of your business logic.
- For each new API version, you create a small migration class describing how to convert old requests → new and new responses → old.
- Cadwyn uses code generation to manage typed Pydantic schemas for every version, so your editor/IDEs can handle them correctly.
- You end up with a single codebase for core logic plus a chain of micro-conversions—much more maintainable for 10–20 versions than copying endpoints.
- Tech Details & Pros/Cons
- Minimal Performance Cost: Old versions get chain-converted, but typically only affects a small minority of calls as most clients adopt newer versions over time.
- Typed Approach: Unlike some dynamic (Ruby) solutions, Cadwyn leverages Pydantic for strong schemas and mypy/VS Code for typed editor support.
- Header-based or Portal-based: By default, clients pass version info in a request header (similar to Stripe). One can also implement middlewares to automatically detect a user’s pinned version.
- Comparisons to Other Libraries
- FastAPI Versioning (DeanWay): Good for simpler or short-lived needs—duplicates endpoints as
/v1/,/v2/, etc. - Flask Rebar: A similar multi-endpoint duplication approach for Flask.
- Django REST Framework: Built-in versioning concepts, but you must implement details yourself.
- FastAPI Versioning (DeanWay): Good for simpler or short-lived needs—duplicates endpoints as
When to Use Cadwyn vs Simpler Tools
- 2–3 Versions, Short-Term: Simple duplications (like FastAPI Versioning) might suffice.
- Many Versions, Long Support: Cadwyn’s incremental “version gates” approach is more sustainable and scalable.
- API-First Companies with large client bases especially benefit from version chains that can live for years (e.g., Stripe’s model).
If you have an API that might someday need versioning, it’s worth spending the time to listen to all the details on this episode.
No 4. Pandas and Beyond with Wes McKinney
Whether you’re just dipping your toes in Pandas or exploring next-gen frameworks like Polars, Arrow, and Ibis, Wes McKinney’s insights underscore how far Python data tooling has come—and how much innovation still lies ahead.
In this Talk Python to Me episode, Michael Kennedy sits down with Wes McKinney, the original author of Pandas and a driving force behind the Apache Arrow and Ibis projects. They discuss Wes’s journey from quant finance to Python open-source, the engineering philosophies behind Python’s data science ecosystem, and the cutting-edge data tooling he’s working on now at Posit (formerly RStudio). They also explore how Apache Arrow revolutionizes shared memory and interoperability for big data, as well as how Ibis and emerging libraries like Polars factor into Python’s next wave of data processing.
Key Themes & Takeaways
- From Quant to Open Source Pioneer
- Wes started in quantitative finance around 2007-2008, discovering Python as a productive language for slicing and manipulating business-oriented (non-numerical) data.
- Frustrated by the numeric focus of NumPy, Wes began building Pandas for tabular data, eventually open-sourcing it in 2009.
- What Is Pandas?
- Pandas offers Python users a DataFrame object to handle labeled, tabular data (think “spreadsheet in code”).
- It supports reading/writing from CSV, JSON, databases, etc., and provides powerful “vectorized” operations—groupbys, joins, filtering, transformations—for data cleaning and wrangling.
- Today, Pandas is a de-facto standard for data manipulation in Python—often your first line in a Jupyter Notebook is
import pandas as pd.
- Sustaining and Evolving Pandas
- By 2013, Wes transitioned leadership to other maintainers, allowing a volunteer core plus funded contributors (e.g. Anaconda, Quansight) to broaden and refine Pandas.
- Pandas is now used by over 1.6 million GitHub projects and has thousands of unique contributors—due in part to an intentional, friendly contributor culture.
- Apache Arrow: The Next-Gen Data Foundation
- Realizing that big data systems all implemented custom in-memory formats, Wes co-created Apache Arrow: a standard columnar format + libraries for high-performance, language-agnostic data interchange.
- Arrow separates “memory format” from “Python library,” so multiple languages and engines can share data zero-copy, accelerating analytics.
- Popular data engines—like DuckDB, Polars, RAPIDS—use Arrow to get optimal CPU and GPU cache efficiency.
- Ibis: A Unified API for SQL & Beyond
- Wes then created Ibis, which aims to give data scientists a single Pythonic dataframe API that can transpile to SQL or execute on multiple backends (like DuckDB, Spark, or Pandas) seamlessly.
- Rather than rewriting code for every platform, users just code in Ibis’s expression API, which compiles your queries to the appropriate engine.
- Polars, Dask, and the Dataframe Landscape
- Libraries such as Polars (Rust + Arrow-based) and Dask each offer improved performance or distributed execution.
- Some tools provide “pandas emulation,” i.e. the same methods/arguments, for easy drop-in replacements. Others (like Polars, Ibis) redesign the API to improve clarity or enable lazy evaluation.
- Posit and Future Directions
- Now at Posit, Wes is helping shape its Python strategy, bridging R’s Shiny and Quarto systems with Python’s data science stack, and fostering open-source sustainability.
- WebAssembly/
Pyodidealso excite him—running Python data analysis directly in the browser (no server needed!) opens new possibilities (e.g. in-browser SQL, DuckDB, Pandas, Polars).
Dive into the whole conversation with Wes and Michael in the podcast episode.
No 5. State of Flask and Pallets in 2024

Clocking in at number 5 for the year is State of Flask and Pallets in 2024 with David Lord. This episode turned out to be a seminal one for me. After speaking with David about the Flask ecosystem, it finally convinced me to get moving and convert talkpython.fm to Quart. You can read all about the journey in a detailed write up I did at Talk Python rewritten in Quart (async Flask).
With this episode, I hope you’re ready for an inside look at the latest happenings in Flask, one of Python’s most popular web frameworks. David Lord, Flask’s lead maintainer, takes us behind the scenes of recent performance boosts (like a 50% speedup in Werkzeug), the future of async support via Quart, and how the broader Pallets ecosystem is evolving under one umbrella. You’ll also hear about Pallets Eco, which aims to streamline and revive critical Flask extensions, and learn how you can contribute to this massive open-source effort. If you use Flask, want to keep your Python apps on the cutting edge, or just love data-driven insights from top maintainers, this episode is for you.
Flask and its sister libraries are faster, leaner, and more maintainable than ever. The pallets-eco initiative aims to keep the Flask extension ecosystem thriving. David and the Pallets team welcome new contributors, especially folks interested in type annotations, extension maintenance, or community support. Check out the Pallets Discord to get involved!
Pallets Organization
-
What is Pallets?
An open-source organization (not a company) maintaining:
- Flask (web framework)
- Werkzeug (WSGI / HTTP utilities)
- Jinja (templating engine)
- Click (command-line apps framework)
- MarkupSafe + It’sDangerous (helper libraries)
- Quart (async variant of Flask, recently joined Pallets)
-
Pallets has a team of volunteer maintainers, but David is the primary point of contact / bus factor.
Flask
- Popularity
- ~66–75+ million downloads/month (PyPI stats).
- Huge user base, from personal side projects to large-scale production systems (even NASA uses it!).
- Maintainer Experience
- Very high impact; every release can affect millions of developers.
- Over time, community best practices like pinned dependencies have emerged (to limit “surprise” breaks).
- Inbox zero maintenance model for issues & PRs works, but it is stressful at scale.
- Quart Integration
- Quart is the “async-first Flask,” has become a Pallets project.
- Long-term plan: unify Flask and Quart enough that you
import Flaskorimport Quartfrom the same codebase. - You still must pick either “sync” or “async” style for your single app, but code-sharing and API design are converging.
Werkzeug
- Purpose: Provides the low-level WSGI & HTTP functionality that Flask builds upon (routing, request/response objects, etc.).
- Major Recent Changes
- String/Bytes Handling Cleanup
- Historically had tons of code branches to accommodate Python 2 vs. Python 3 differences.
- Removing these legacy checks boosted performance ~50% (fewer conversions, simpler code).
- Dropped Internal urllib copy
- Werkzeug used to embed and heavily modify Python’s stdlib
urllibcode (for Python 2 compatibility). - By removing that vendor copy and using the modern standard library directly, gained ~30% speed improvement and simpler maintenance.
- Werkzeug used to embed and heavily modify Python’s stdlib
- String/Bytes Handling Cleanup
Jinja & Click
-
Both are extremely popular:
- Jinja: templating for HTML, emails, text files, etc.
- Click: CLI framework for Python.
-
Still large backlogs (more open issues than, e.g., Werkzeug and Flask).
-
David aims to bring them closer to “inbox zero,” but these libraries remain stable and widely used even though they have older open issues.
-
Typing: Looking for help from Python type-hint experts to strengthen type annotations.
Quart
- Async framework: Seamless ASGI usage (compared to Flask’s WSGI).
- Officially a Pallets project now.
- Goal is more code sharing (sans-IO design) with Flask’s internals for maintainability and less code duplication.
Pallets-Eco (Extension Ecosystem)
-
Many popular Flask extensions (e.g.,
Flask-SQLAlchemy,Flask-Admin,Flask-Mail, etc.) are essential to the Flask community but are also in various states of maintenance/burnout. -
Pallets-Eco is a new initiative, similar to Django’s “Jazzband,” to help unify & standardize these extensions.
- The plan: if an old extension’s maintainers are overwhelmed, they can move it under
pallets-eco.
- The plan: if an old extension’s maintainers are overwhelmed, they can move it under
-
Pallets team will help find new maintainers and unify CI, build, release workflows, so it’s easy for volunteers to jump in and keep those extensions alive.
Tooling & Publishing
-
Trusted Publishers on PyPI + GitHub Actions used for all Pallets libraries.
- Eliminates manual steps for packaging & release.
- Minimizes the risk of supply-chain attacks or local-credential theft.
- Greatly simplifies cutting new releases quickly (one or two button presses).
Sustainability & Roadmap
-
David is prioritizing maintainability and contributor onboarding over new big features.
-
“Contributor on-ramp” approach:
- Bring code, docs, and issues down to a well-structured baseline.
- Publish clear maintainer documentation.
- Encourage folks to help with the extension ecosystem if Flask itself is near “inbox zero.”
-
Long-term, Pallets continues to aim for “small, composable, stable tools” rather than forcing everything into Flask’s core.
If you’re a Python web developer, there is a ton to learn from this episode. Give it a listen.
Conclusion
This 9th year of Talk Python To Me has been an amazing one. It’s always an honor to spend time with these great Python developers. I want to say thank you to everyone who has been a guest on the show and especially to you, the listeners who keep tuning in and making the podcast possible. Happy New Years! – Michael Kennedy.